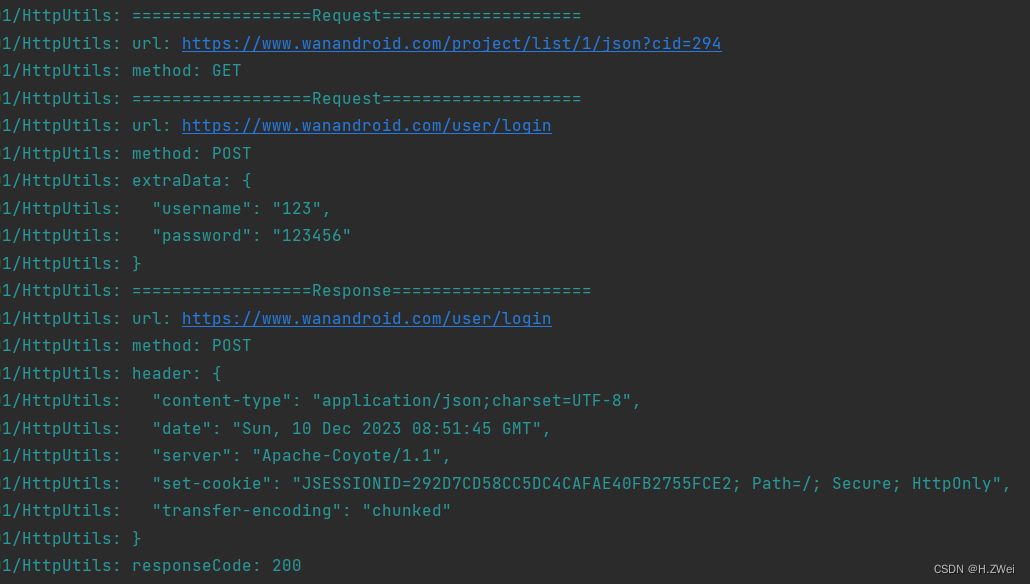
Apache Kafka Streams 是一款强大的实时流处理库,为构建实时数据处理应用提供了灵活且高性能的解决方案。本文将深入探讨 Kafka Streams 的核心概念、详细原理,并提供更加丰富的示例代码,以帮助读者深入理解和应用这一流处理框架。
1. Kafka Streams 简介
Kafka Streams 是 Apache Kafka 生态系统中的一部分,它不仅简化了流处理应用的构建,还提供了强大的功能,如事件时间处理、状态管理、交互式查询等。其核心理念是将流处理与事件日志结合,使应用程序能够实时处理数据流。
2. 核心概念
2.1 流(Stream)与表(Table)
在 Kafka Streams 中,流(Stream)代表了一个不断产生记录的有序数据流,而表(Table)则表示一个不断更新的记录集。这两者共同构成了 Kafka Streams 应用程序的基础。
2.2 处理拓扑(Processing Topology)
处理拓扑是 Kafka Streams 应用程序的处理逻辑图。它由一系列节点和边组成,每个节点执行特定的处理操作,如过滤、映射、聚合等。处理拓扑定义了数据流的流向和处理流程。
3. 示例代码:单词计数应用
以下是一个更详细的单词计数示例,演示了如何通过 Kafka Streams 进行单词计数:
// 构建拓扑
StreamsBuilder builder = new StreamsBuilder();// 创建输入流
KStream<String, String> textLines = builder.stream("input-topic");// 扁平化并转换为小写
KStream<String, String> words = textLines.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")));// 分组并计数
KTable<String, Long> wordCounts = words.groupBy((key, word) -> word).count();// 将结果发送到输出主题
wordCounts.toStream().to("output-topic", Produced.with(Serdes.String(), Serdes.Long()));// 构建 Kafka Streams 应用程序
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
在这个示例中,我们详细展示了构建拓扑、创建输入流、进行数据处理以及将结果发送到输出主题的完整流程。这使读者能够更清晰地理解 Kafka Streams 的应用程序结构。
4. 处理时间和状态管理
Kafka Streams 支持处理事件时间,并提供了丰富的状态存储和管理功能。以下是一个处理事件时间的示例,演示了如何对窗口内的事件进行计数:
KStream<String, String> events = builder.stream("events-topic");KTable<Windowed<String>, Long> eventCounts = events.groupByKey().windowedBy(TimeWindows.of(Duration.ofMinutes(5))).count();eventCounts.toStream().map((key, value) -> new KeyValue<>(key.key(), value)).to("event-counts-topic", Produced.with(Serdes.String(), Serdes.Long()));
这个示例中,使用 windowedBy 方法定义了一个时间窗口,并对窗口内的事件进行计数。这展示了 Kafka Streams 如何处理事件时间,支持各种时间窗口的操作。
5. 交互式查询
Kafka Streams 提供了强大的交互式查询功能,允许应用程序动态地查询处理拓扑中的状态。
以下是一个简单的查询示例:
KTable<String, Long> wordCounts = ... // 从处理拓扑中获取单词计数表InteractiveQueries interactiveQueries = new InteractiveQueries(streams, streams.localThreadsMetadata());
ReadOnlyKeyValueStore<String, Long> keyValueStore = interactiveQueries.getQueryableStore("word-counts-store", QueryableStoreTypes.keyValueStore());Long count = keyValueStore.get("example-word");
这个示例展示了如何通过交互式查询获取处理拓扑中的状态,并动态地获取单词计数。这为读者提供了更详尽的了解,使其能够更好地应用交互式查询功能。
6. 容错与可靠性
Kafka Streams 内置了容错机制,确保应用程序在发生故障时能够进行状态恢复。通过与 Kafka 的集成,Kafka Streams 实现了端到端的精确一次语义,确保应用程序的可靠性。
7. 全局状态与连接器
Kafka Streams 支持全局状态存储,使得应用程序能够跨多个流处理任务共享状态。以下是一个示例,展示了如何在全局状态存储中维护一个全局计数器:
// 创建全局计数器
GlobalKTable<String, Long> globalTable = builder.globalTable("global-table-topic");// 处理数据流
KStream<String, String> dataStream = builder.stream("data-topic");
dataStream.leftJoin(globalTable,(key, value) -> key, // 数据流的键(valueFromStream, valueFromTable) -> valueFromStream + " : " + valueFromTable).to("output-topic", Produced.with(Serdes.String(), Serdes.String()));
这个示例中,通过 globalTable 方法创建了一个全局表,并在数据流中使用 leftJoin 操作将数据流的每个记录与全局表进行连接。这使得应用程序能够在全局状态存储中查找和使用全局数据。
8. 容器化与弹性扩展
Kafka Streams 应用程序可以轻松地容器化,并通过弹性扩展适应不同规模的工作负载。
以下是一个简单的示例,演示了如何使用 Docker Compose 启动多个 Kafka Streams 实例:
version: '2'services:kafka-streams-app-1:image: your-kafka-streams-imageenvironment:- APPLICATION_ID=streams-app-1- BOOTSTRAP_SERVERS=kafka-broker-1:9092- ...# 其他配置项kafka-streams-app-2:image: your-kafka-streams-imageenvironment:- APPLICATION_ID=streams-app-2- BOOTSTRAP_SERVERS=kafka-broker-2:9092- ...# 其他配置项# 更多 Kafka Streams 实例...
这个示例中,通过 Docker Compose 同时启动了多个 Kafka Streams 应用程序实例,每个实例可以根据需要进行横向扩展,以适应大规模的数据处理需求。
9. 集成测试与模拟数据
为了确保 Kafka Streams 应用程序的正确性,集成测试和模拟数据是不可或缺的一部分。
以下是一个简单的集成测试示例,演示了如何使用 TopologyTestDriver 进行测试:
Topology topology = createTopology(); // 创建拓扑
TopologyTestDriver testDriver = new TopologyTestDriver(topology, config);// 发送模拟输入数据
testDriver.pipeInput(recordFactory.create("input-topic", key, value));// 验证输出结果
ProducerRecord<String, String> outputRecord = testDriver.readOutput("output-topic", keyDeserializer, valueDeserializer);
assertEquals(expectedOutput, outputRecord.value());// 关闭测试驱动器
testDriver.close();
这个示例中们使用 TopologyTestDriver 来模拟输入数据并验证输出结果,确保 Kafka Streams 应用程序的逻辑正确性。
10. 性能调优与监控
Kafka Streams 提供了丰富的性能调优和监控工具,以确保应用程序在高负载下稳定运行。通过配置合适的参数和监控指标,可以优化应用程序的性能并提高整体吞吐量。详细的性能调优和监控策略将有助于应对不同规模和复杂度的流处理任务。
总结
通过深度探索 Kafka Streams 的各个方面,本文为大家提供了更加详细的理解和应用指南。Kafka Streams 不仅提供了强大的流处理功能,还支持容器化、全局状态共享、弹性扩展等特性,使其成为构建实时流处理应用的理想选择。通过学习这些详细的示例和最佳实践,能够更好地应用 Kafka Streams,构建出高性能、可靠且易于维护的实时流处理系统。