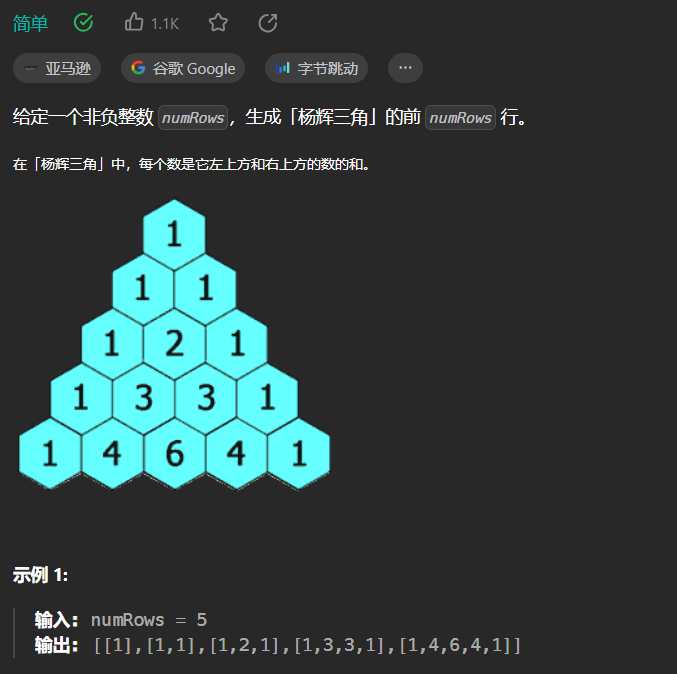
引言
这是一篇对结构体的详细介绍,这篇文章对结构体声明、结构体的自引用、结构体的初始化、结构体的内存分布和对齐规则、库函数offsetof、以及进行内存对齐的原因、如何修改默认对齐数、结构体传参进行介绍和说明。
✨ 猪巴戒:个人主页✨
所属专栏:《C语言进阶》
🎈跟着猪巴戒,一起学习C语言🎈
目录
引言
结构体的声明
结构体的基础
结构的声明
匿名结构体类型
结构体的自引用
typedef作用于结构体的问题
结构体变量的定义和初始化
多个元素的初始化要用大括号{ }
结构体的内存对齐
1.对齐规则
1.例子
2.例子
3.例子
4.例子
offsetof
offsetof的使用
编辑
为什么要存在内存对齐
修改默认对齐数
结构体传参
结构体的声明
结构体的基础
结构是一些值的集合,这些值被称为成员变量。结构的每个成员可以是不同类型的变量。
在一个变量中,要存放性别、年龄、成绩、地址多种类型的数据时,C语言允许用户自己建立由不同类型数据组成的组合型的数据结构,它称为结构体。
结构的声明
结构体是怎么声明的呢?
struct tag
{member_list;
}variable_list; //分号不能丢struct Student
{//学生的相关信息char name[20];int age;
}s1,s2;- tag,Student是结构体名
- member_list是成员表列
- struct是声明结构体类型是必须使用的关键字,不能省略
- s1,s2变量就是学生变量。
- { }后面要记得把“ ;”带上
struct tag就是一个结构体类型,我们可以根据自己的需要建立结构体类型,struct Teacher,struct Student等结构体类型,各自包含不同的成员。
如果将s1,s2放在main函数的外面,那么s1,s2就是全局变量。
struct Student
{//学生的相关信息char name[20];int age;
}s1,s2;int main()
{return 0;
}
匿名结构体类型
结构体在声明的时候省略了结构体标签(tag),没有名字的结构体类型只能使用一次,被称为匿名结构体类型。
由于没有名字,编译器会把下面的两个代码当成完全不同的两个类型。
所以,p = &x.
会因为类型不同报错。
struct
{char name[20];int age;
}s1;struct
{char name[20];int age;
}a[20],*p;
结构体的自引用
结构体的自引用用到数据结构中的链表。
数据结构中有顺序表、链表的概念,
顺序表
数据在内存中是顺序排放的,可以逐个根据地址找到下一个数据。
链表
数据在内存中的存放是没有规律的但是存放数据,会分为两个部分,
一个部分叫数据域,存放有效数据,
另一个部分叫指针域,用来存放下一个数据的地址,可以通过地址直接找到下一个数据。
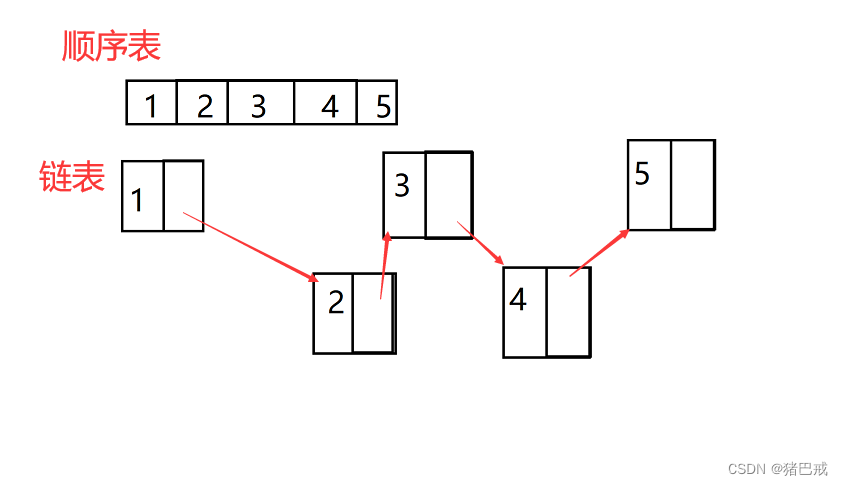
我们通过链表就可以实现结构体的自引用。
struct Node
{int data;struct Node* next;
};
typedef作用于结构体的问题
下面在结构体自引用使用的改成中,夹杂了typedef对匿名结构体类型重命名,看看下面的代码,有没有问题?
typedef struct Node
{int data;Node* next;
}Node;答案是不行的,因为Node是对前面的匿名结构体类型的重命名产生的,但是在匿名结构体内部提前使用Node类型来创建成员变量,这是不行的。
typedef struct Node
{int data;struct Node* next;
}Node;
结构体变量的定义和初始化
struct Point是结构体类型,它相当于一个模型,是没有占据具体空间的,
当我们建立结构体变量p1,它相当于具体的房屋,在内存中储存数据。
struct Point
{int x;int y;
}p1 = { 2,3 };
多个元素的初始化要用大括号{ }
在结构体中,如果存在多个元素的变量,我们初始化时要使用大括号。
像数组一样,arr[] = { 0, 1, 2, 3, 4 };
- 打印结构体,s1是struct Stu的变量,name是s1的成员变量,用s1.name表示s1结构体的name变量
- s是struct Stu中的成员变量,用s1.s.n表示在结构体struct score的成员变量n。
struct score
{int n;char ch;
};
struct Stu
{char name[20];int age;struct score s;
};int main()
{struct Stu s1 = { "zhangsan",20,{100,'q' } };printf("%s %d %d %c\n", s1.name, s1.age, s1.s.n, s1.s.ch);return 0;
}
结构体的内存对齐
如何计算结构体的大小?
结构体的内存分布是怎样的?
1.对齐规则
首先掌握结构体的对齐规则
1. 结构体的第⼀个成员对⻬到和结构体变量起始位置偏移量为0的地址处
2. 其他成员变量要对⻬到某个数字(对⻬数)的整数倍的地址处。
对⻬数 = 编译器默认的⼀个对⻬数 与 该成员变量⼤⼩的较⼩值。
- VS 中默认的值为 8
- Linux中 gcc 没有默认对⻬数,对⻬数就是成员⾃⾝的⼤⼩
3. 结构体总⼤⼩为最⼤对⻬数(结构体中每个成员变量都有⼀个对⻬数,所有对⻬数中最⼤的)的整数倍。
4. 如果嵌套了结构体的情况,嵌套的结构体成员对⻬到⾃⼰的成员中最⼤对⻬数的整数倍处,结构体的整体⼤⼩就是所有最⼤对⻬数(含嵌套结构体中成员的对⻬数)的整数倍。
只是文字的说明,免不了晦涩难懂,接下来用例子来给大家讲解
1.例子
#include <stdoi.h>
struct S1
{char c1;int i;char c2;
};
int main()
{printf("%d\n", sizeof(struct S1));return 0;
}
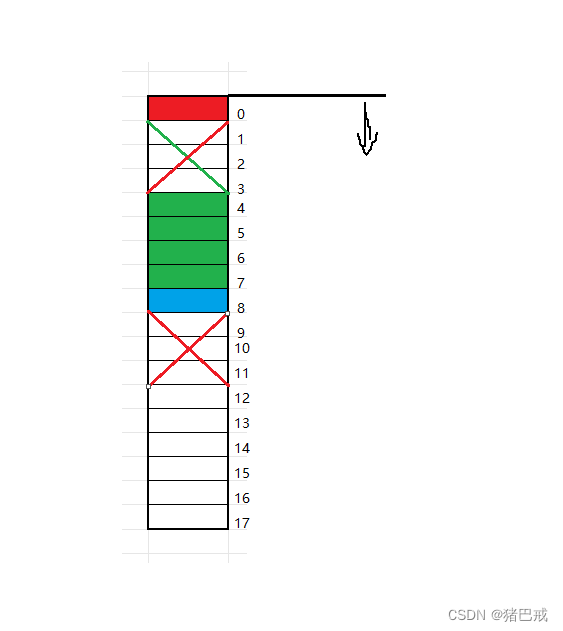
解析:
右边表示的是偏移量,
1.第一个成员char c1要对齐到和结构体变量起始位置偏移量为0的地址处,占一个字节
2.其他成员要对齐到对齐数的整数倍的地址处
对⻬数 = 编译器默认的⼀个对⻬数 与 该成员变量⼤⼩的较⼩值。
VS中的默认对齐数是8.
int i的大小是4个字节,对齐数就是4。int i 的地址要对齐到为偏移量整数倍的地址,也就是4的整数倍,偏移量为4的地址。int i 是4个字节,那占据的地址偏移量为4~7
char c2 的大小是1个字节,对齐数是1。1可以为任意偏移量的整数倍。所以char c2的地址的偏移量就是8.
3.结构体的大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)的整数倍
成员变量有char c1,int i ,char c2。它们的对齐数分别是1,4,1。因此最大对齐数为4。
结构体总大小为最大对齐数的整数倍,现在偏移量是0~8,一共是9个字节,要凑成4的整数倍,就是12个字节,在浪费3个字节就可以了,地址偏移量9~11一共是3个字节。
这个结构体的内存就储存在偏移量为0~11的空间。
2.例子
#include<stdio.h>
struct S2
{char c1;char c2;int i;
};
int main()
{printf("%d\n",sizeof(struct S2));return 0;
} 
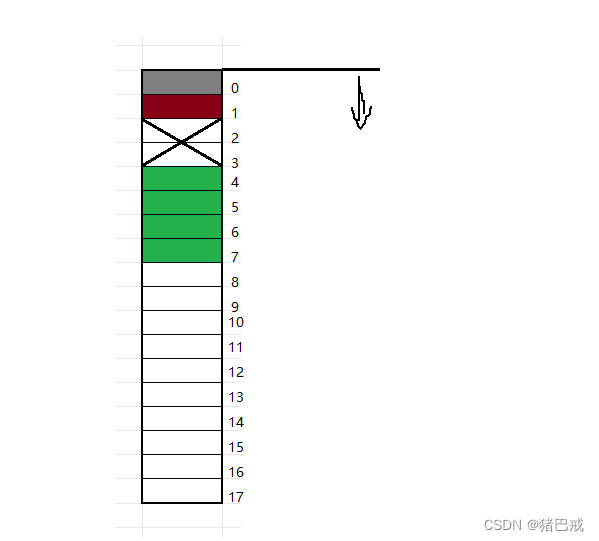
解析:
右边表示的是偏移量,
1.第一个成员char c1要对齐到和结构体变量起始位置偏移量为0的地址处,占一个字节
2.其他成员要对齐到对齐数的整数倍的地址处
对⻬数 = 编译器默认的⼀个对⻬数 与 该成员变量⼤⼩的较⼩值。
VS中的默认对齐数是8.
char c1 的大小是1个字节,对齐数就是1。char c1的地址要对齐到为偏移量整数倍的地址,也就是1的整数倍,偏移量为1的地址。
int i 的大小是4个字节,对齐数是4。int i 的地址就要移到偏移量为4的倍数的地址。所以int i 的地址的偏移量就是4.int i 是4个字节,那占据的地址偏移量为4~7
3.结构体的大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)的整数倍
成员变量有char c1,int i ,char c2。它们的对齐数分别是1,4,1。因此最大对齐数为4。
结构体总大小为最大对齐数的整数倍,现在偏移量是0~7,刚好是8个字节,是4的倍数。
这个结构体的内存就储存在偏移量为0~7的空间。
3.例子
#include<stdio.h>
struct S3
{double d;char c;int i;
};
int main()
{printf("%d\n",sizeof(struct S3));return 0;
}
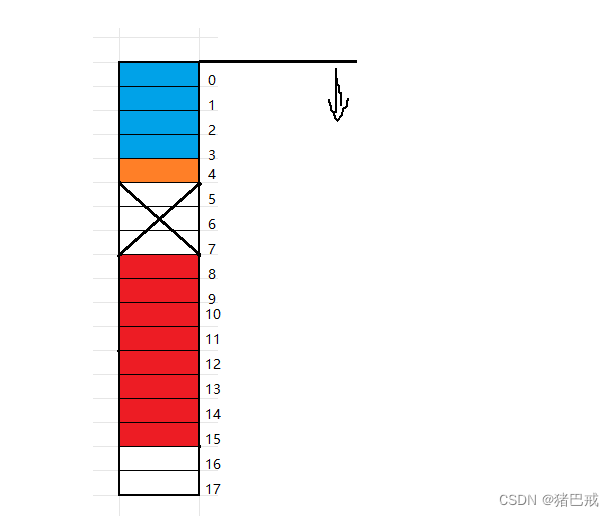
解析:
1.第一个成员要对齐到结构体变量起始位置偏移量为0的地址处,double d占8个字节,所以占据的内存空间是偏移量为0~7的地址
2.其他成员要对齐到对齐数的整数倍的地址处
char c的大小是1个字节,任意偏移量都可以为1的整数倍,所以char c的地址是下一位,偏移量为8的地址。
int i 的大小是4个字节,要对齐到偏移量为4的倍数的地址,也就是偏移量为12,int i 占据的内存空间为偏移量为12~15的地址。
3.结构体的大小为最大对齐数的整数倍。
最大对齐数是double的对齐数,也就是8。现在的结构体占16个字节(偏移量为0~15),刚好是8的倍数。
4.例子
这个例子包括了嵌套结构体的情况,嵌套的结构体成员对⻬到⾃⼰的成员中最⼤对⻬数的整数倍处,结构体的整体⼤⼩就是所有最⼤对⻬数(含嵌套结构体中成员的对⻬数)的整数倍。
#include<stdio.h>
struct S3
{double d;char c;int i;
};
struct S4
{char c1;struct S3 s3;double d;
};
int main()
{printf("%d\n",sizeof(struct S4));return 0;
} 
解析:
1.第一个成员要对齐到结构体变量起始位置偏移量为0的地址处,char c1占1个字节,占据偏移量为0的空间。
2.嵌套的结构体成员对⻬到⾃⼰的成员中最⼤对⻬数的整数倍处,结构体的整体⼤⼩就是所有最⼤对⻬数(含嵌套结构体中成员的对⻬数)的整数倍。
接下来是struct s3,要对齐自己成员的最大对齐数,double d的对齐数为8个字节,对齐到偏移量为8的地址,
3.其他成员要对齐到对齐数的整数倍的地址处,嵌套的结构体成员也是这样,double d占据8个字节,占据偏移量为8~15的地址。
char c对齐偏移量16,占据一个字节。
int i 的对齐数为4,对齐偏移量为20,占据4个字节,就是偏移量为20~23的空间。
struct S3整理完,继续到struct S4,轮到double d
double d的对齐数为8,对齐偏移量24,占据8个字节,占据空间偏移量为24~31。
4.结构体的大小为最大对齐数的整数倍。
当前空间一共是32个字节(0~31),结构体struct S4,struct S3中的成员的最大对齐数是8。因此结构体的大小要是最大对齐数的整数倍。32刚好是8的整数倍。
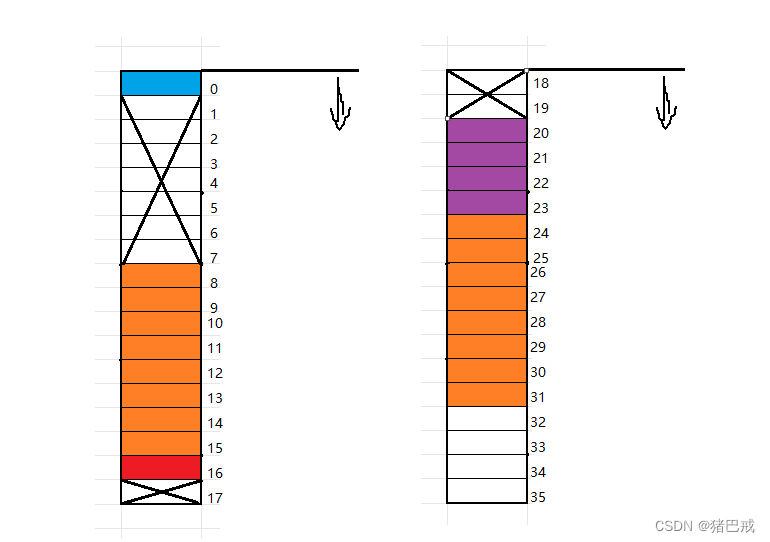
offsetof
返回成员的偏移量 ,头文件<stddef.h>
offsetof (type,member)
offsetof的使用
type是类型,
#include <stdio.h>
#include <stddef.h>
struct S1
{char c1;int i;char c2;
};
int main()
{printf("%d\n", offsetof(struct S1, c1));printf("%d\n", offsetof(struct S1, i));printf("%d\n", offsetof(struct S1, c2));return 0;
}
为什么要存在内存对齐
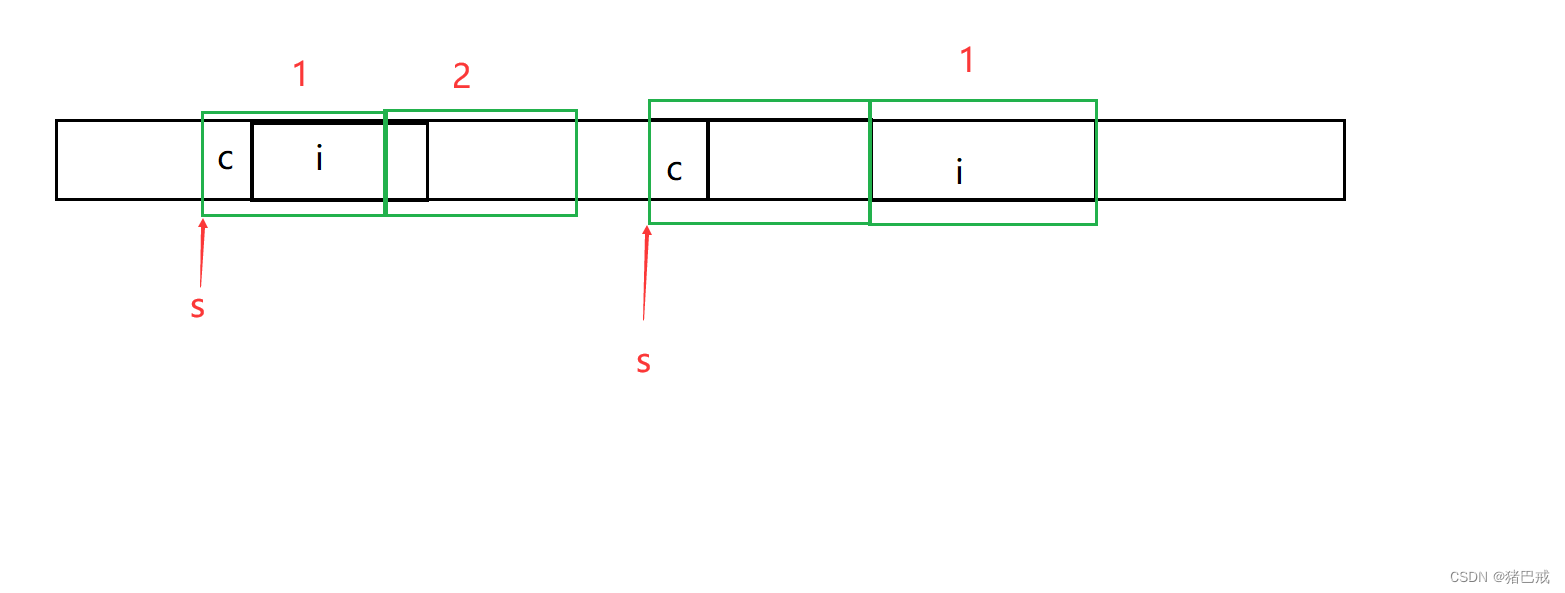
总体来说:结构体的内存对⻬是拿空间来换取时间的做法。
以32为机器为例,32位机器一次可以访问32位比特位的数据,
如果没有对齐规则,就像左边,机器要访问两次才可以得到 int i 的值,
有对齐规则,就像右边,想要访问 i ,只需要访问一次就足够了。
对齐规则的思想:把数据放在机器可以一次访问得到数据的空间内,使访问更具效率。
修改默认对齐数
当结构体的对齐方式不适合时,我们也可以修改默认对齐数。
- 在括号填写数字,对默认对齐数进行修改。
- 如果()内没有数字,则时将默认对齐数恢复到默认值。
#pragma pack()下面的struct S原本是占据12个字节的空间,对默认对齐数进行修改后,只占据6个字节的空间。
#include <stdio.h>
#pragma pack(1)//设置默认对⻬数为1
struct S
{char c1;int i;char c2;
};
#pragma pack()//取消设置的对⻬数,还原为默认
int main()
{//输出的结果是什么?printf("%d\n", sizeof(struct S));return 0;
}
结构体传参
- 传值调用,将数据通过参数传过去,然后函数print会创立独立的空间,对传过来的数据进行存储
- 传址调用,将数据的地址传过去,函数通过指向数据的地址对数据进行使用,不需要再建立空间对数据进行存放。
#include<stdio.h>
struct S
{int data[1000];int num;
};
void print1(struct S ss)
{int i = 0;for (i = 0; i < 3; i++){printf("%d ", ss.data[i]);}printf("%d\n", ss.num);
}
void print2(struct S* ps)
{int i = 0;for (i = 0; i < 3; i++){printf("%d ", ps->data[i]);}printf("%d\n", ps->num);
}
int main()
{struct S s = { {1,2,3},100 };print1(s);print2(&s);return 0;
}
上面的传值调用print1 和 传址调用print2 函数那哪个更好?
原因:函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。如果传递⼀个结构体对象的时候,结构体过⼤,参数压栈的的系统开销⽐较⼤,所以会导致性能的下降。