一、说明
LLM和Transformer系列:
- LLM:《第 1 部分》只是一个记忆技巧吗?
- LLM;超越记忆《第 2 部分 》
- LLM:《第 3 部分》从数学角度评估封闭式LLM的泛化能力
- 第 6 部分 — 对 LLM 的对抗性攻击。数学和战略分析-CSDN博客
- 第 7 部分 — 增强 LLM 安全性的策略:数学和伦理框架-CSDN博客
- 第 9 部分 — 内存增强 Transformer 网络:数学见解

二、为什么高级神经网络需要记忆?
随着神经网络,特别是深度学习模型变得越来越复杂,它们处理和解释大量数据的能力呈指数级增长。然而,传统神经网络架构(包括 CNN(卷积神经网络)和 RNN(循环神经网络)等流行模型)经常遇到困难的一个领域是有效处理长期依赖性并保留扩展序列的上下文。这就是记忆的概念,特别是显性记忆和长期记忆变得至关重要的地方。
2.1 标准模型中内隐记忆的缺点
- 序列长度的限制:像 RNN 甚至 Transformer 这样的传统模型,尽管有自注意力机制,但记住和利用很长序列中的信息的能力有限。这种限制是由于梯度消失问题及其存储机制的固有设计造成的,这些机制更适合短期而不是长期数据保留。
- 长序列中的上下文稀释:在长文本生成或复杂时间序列分析等任务中,模型在序列中进展得越远,上下文就变得越稀释。这种稀释会导致关键信息丢失,从而难以保持一致性和准确性。
- 计算效率低下:在没有显式记忆机制的情况下重复处理长序列会导致计算效率低下。模型最终会重新处理相同的信息,增加计算时间和资源使用量,而性能却没有相应的提高。
2.2 显性记忆的优点
- 增强的长期依赖性处理:显式记忆允许模型存储和访问长序列上的重要信息,绕过标准架构中短期记忆的限制。这种能力对于需要大量历史数据参考的任务尤其重要,例如人工智能中的语言建模和复杂的决策过程。
- 改进的上下文保留和一致性:通过维护专用的内存存储,神经网络可以引用和利用序列中较早的上下文,保持主题和上下文的一致性,这对于故事生成或维护对话人工智能中的对话上下文等应用至关重要。
- 计算效率:拥有专用内存组件可以实现更高效的数据处理。网络无需重新计算或重新处理信息,而是可以直接访问相关历史数据,减少冗余并节省计算资源。
- 适应性和灵活性:显式内存模块可以设计为动态适应手头的任务,使它们更加灵活,能够应对传统模型无法有效解决的各种挑战。
三、内存模块设计
3.1 内存矩阵
符号和概念:考虑内存矩阵M ∈R N × D,其中N表示内存槽的数量,D表示嵌入维度。M中的每一行Mi代表一个单独的内存插槽。这个矩阵不仅仅是一个被动的存储单元,而且是学习过程中的主动组成部分。N和D的选择平衡了内存容量和计算可行性之间的权衡。
3.2 内存写入
写入键值对生成:该过程首先从 Transformer 的输出生成写入键kw εR D和相应的值vw εR D 。这一步至关重要,因为kw充当内存矩阵中的寻址机制,而vw代表要存储的内容。
寻址和更新:内存槽的寻址是通过softmax函数定义的:
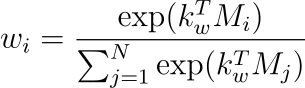
其中,wi表示写入密钥kw对第i个内存插槽的亲和力或权重。此 softmax 函数确保了可微分和概率的寻址方法,这是通过反向传播进行训练的关键。
更新规则:内存槽的更新规则由下式给出:
![]()
其中,λ是一个衰减因子,控制旧信息被遗忘的速度。这种衰减因子引入了一种正则化形式,防止记忆受到最近输入的过度影响,同时仍然允许它随着时间的推移进行适应。
3.3 内存读取
读取密钥生成:读取密钥kr εR D由解码器的输入生成。kr的生成类似于kw ,但通常源自 Transformer 架构的不同部分,反映了检索当前解码步骤相关信息的需要。
内容检索:内容检索过程在数学上表述为:

该方程反映了软检索机制。项 exp( krT Mi ) 衡量读取密钥kr和每个内存槽Mi之间的相似度,并使用 softmax 确保归一化权重。所得向量c是所有内存槽的加权和,为当前任务提供上下文相关的信息。
四、与 Transformer 集成
显式记忆模块与 Transformer 的自注意力机制的集成涉及对传统注意力计算的复杂改变。本节详细介绍了这些更改及其数学含义。
3.1 自注意力中的扩展矩阵
扩展查询、键和值:我们使用内存模块M中的内容和检索到的内存内容c来扩充 Transformer 的标准查询Q、键K和值V矩阵。这导致扩展矩阵Q ', K ', V ' 定义为:
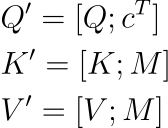
其中,cT表示检索的内存内容向量c的转置。cT与Q的串联将记忆中的上下文信息直接集成到注意力机制中。
3.2 改进的注意力计算
重新表述的注意力操作:Transformer 中的注意力机制传统上被定义为查询、键和值的函数。随着记忆模块的集成,注意力操作修改如下:
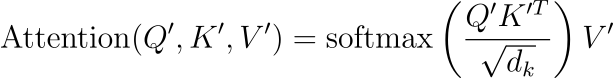
在此等式中,dk是缩放因子,通常是关键向量的维数,用于防止点积的幅度变得太大。这种缩放对于保持数值稳定性至关重要。
对注意力权重的影响:将记忆内容包含在查询矩阵Q ′ 中意味着注意力权重现在不仅反映输入序列不同部分的相关性(如标准 Transformer 中那样),还反映不同记忆槽的相关性。这使得模型能够在当前输入和内存中存储的相关历史信息之间动态调整其焦点。
数学含义:扩展矩阵导致了用于计算注意力权重的更高维空间。这种增加的维度可以捕获更复杂的关系和依赖关系,这在以前的标准 Transformer 架构中是不可能的。
五、深入应用和案例研究
5.1 增强语言建模
故事生成中的上下文连续性:在生成故事等长文本时,保持主题和人物的一致性具有挑战性。记忆增强 Transformer 可以有效地存储和检索叙事元素,确保连贯且连续的故事流程。
5.2 高级时间序列预测
捕捉长期趋势和季节性:传统模型通常难以解释时间序列数据的长期依赖性。我们提出的架构中的显式内存模块可以存储历史模式和季节性趋势,从而显着提高预测准确性。
六、先进的内存管理技术
6.1 动态内存槽分配
6.1.1 自适应内存:
自适应内存机制根据任务的复杂程度动态调整内存槽的数量N。这可以用函数来数学表示
![]()
其中任务复杂度是输入序列复杂性的度量。
这种自适应过程可能涉及计算学习模型来评估最佳性能所需的内存容量,从而产生可以形式化为优化问题的动态调整大小算法。
6.1.2 槽位相关性评分:
引入相关性评分函数R : Mi →R,它根据每个内存槽Mi在任务中的当前和历史效用为其分配分数。
该评分可以是各种因素的函数,例如访问频率、新近度和上下文相关性,并且可以表示为
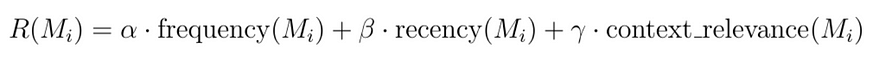
其中α、β、γ是加权系数。
6.2 记忆衰退和遗忘机制
6.2.1 受控遗忘:
在内存更新规则中引入衰减因子λ ∈[0,1]:
![]()
这种衰减机制对遗忘过程进行数学建模,其中λ接近 1 表示遗忘较慢,接近 0 表示遗忘较快。λ的选择可以是动态的,基于Mi中信息的相关性和实用性。
6.3 内存内容优化
6.3.1 内存管理的强化学习:
采用强化学习 (RL) 框架来优化内存操作。在这个框架中,内存管理动作(存储、检索、遗忘)可以被视为强化学习问题中的动作,模型在任务上的表现作为奖励信号。
制定一个优化问题,其目标是最大化取决于内存使用有效性的奖励函数R。RL 代理学习策略π ( a ∣ s ),将状态(当前内存和任务状态)映射到操作(内存读/写操作)以最大化预期奖励:
![]()
这种基于强化学习的方法使模型能够学习何时以及存储或检索什么内容的复杂策略,从而在即时性能和长期记忆效率之间取得平衡。
七、讨论
混合内存增强 Transformer 模型的开发标志着在克服传统 Transformer 架构的局限性方面取得了重大进步,特别是在处理长期依赖关系方面。该模型的数学框架结合了复杂的内存管理和优化技术,为从复杂的自然语言任务到复杂的时间序列分析等各个领域提供了有希望的可能性。
未来的研究将集中于进一步完善该架构,优化其效率和可扩展性,并探索其在各种数据密集型领域的适用性。该模型具有巨大的潜力,可以彻底改变我们处理需要大量内存和上下文保留的任务的方式,为顺序数据处理领域开辟了新的视野。