读程序员的README笔记08_依赖管理
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/267171.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
OpenCV-opencv下载安装和基本操作
文章目录 一、实验目的二、实验内容三、实验过程OpenCV-python的安装与配置python下载和环境配置PIP镜像安装Numpy安装openCV-python检验opencv安装是否成功 openCV-python的基本操作图像输入和展示以及写出openCV界面编程单窗口显示多图片鼠标事件键盘事件滑动条事件 四、实验…
uniCloud(一) 新建项目、初始化服务空间、云对象访问测试
一、新建一个带有unicloud 二、创建一个服务空间
1. 右键uniCloud,关联云服务空间
我当前没有服务空间,需要新建一个服务空间,之后将其关联。初始化服务空间需要的时间有点长 服务空间初始化成功后,刷新HBuilder,勾选…
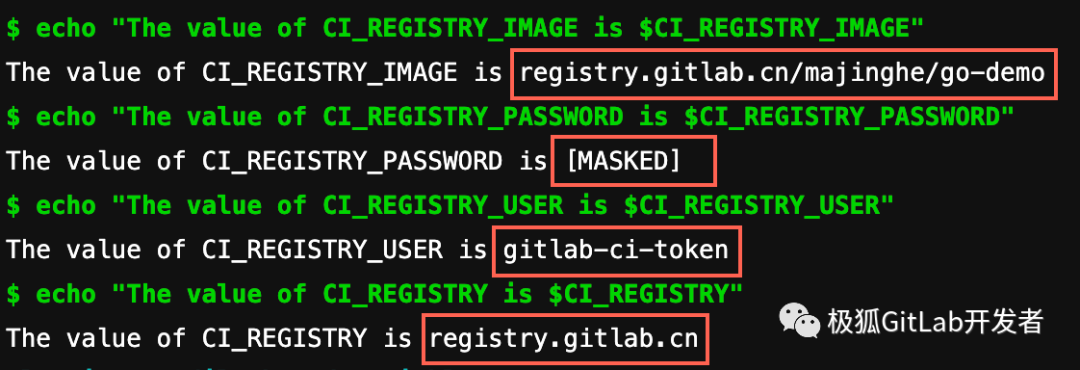
极狐GitLab CI/CD 变量黑魔法之预定义变量
目录
预定义变量
commit 相关
Job 相关
Pipeline 相关
镜像仓库有关 极狐GitLab CI/CD 变量是指一系列的环境变量,用来帮助我们控制 CI/CD Job 或 Pipeline 的行为,存储一些可以复用的信息,避免在 .gitlab-ci.yml 中形成硬编码。
极狐G…

Citespace、vosviewer、R语言的文献计量学可视化分析
文献计量学是指用数学和统计学的方法,定量地分析一切知识载体的交叉科学。它是集数学、统计学、文献学为一体,注重量化的综合性知识体系。特别是,信息可视化技术手段和方法的运用,可直观的展示主题的研究发展历程、研究现状、研究…

【后端学前端】第二天 css动画 动感菜单(css变量、过渡动画、过渡延迟、js动态切换菜单)
目录 1、学习信息 2、源码
3、变量
1.1 定义变量
1.2 使用变量
1.3 calc() 函数
4、定位absolute和fixed
5、transform 和 transition,动画
5.1 变形transform
5.2 transition
5.3 动画animation
6、todo 1、学习信息
视频地址:css动画 动感菜…

111. 二叉树的最小深度
目录
解法:
官方解法:
方法一:深度优先搜索
思路及解法
复杂度分析
时间复杂度:
空间复杂度:
方法二:广度优先搜索
思路及解法
复杂度分析
时间复杂度:
空间复杂度: 给定…

MyBatis:缓存
MyBatis 缓存一级缓存二级缓存注 缓存
缓存,是数据交换的缓冲区(临时保存数据的地方)。即将数据(数据一般为频繁查询且不易改变)保存在计算机内存中,下次读取数据时直接从内存中获取,以避免频繁…
Word插件-好用的插件-批量插入图片-大珩助手
现有100张图片,需要批量插入word中,并在word中以每页6张图片的形式呈现,请问怎样做?
使用word大珩助手,多媒体-插入图片,根据图片的长宽,选择连续图片、一行2个图或一行3个图,可一次…

Network 灰鸽宝典【目录】
目前已有文章 11 篇 Network 灰鸽宝典专栏主要关注服务器的配置,前后端开发环境的配置,编辑器的配置,网络服务的配置,网络命令的应用与配置,windows常见问题的解决等。 文章目录 canvas理论基础canvas高级应用示例canv…

开箱即用的C++决策树简单实现
一个数据结构期末作业(有兴趣用的话可以高抬贵手star下⭐~)GitHub - mcxiaoxiao/c-Decision-tree: 决策树c简单实现 🌳 c-Decision-tree 附大作业/课设参考文档.doc
🌳 c-Decision-tree
Introduction 🙌
c-Decision…

Java架构师系统架构提升扩展性
目录 1 导语2 架构扩展性-应用扩展3 架构扩展性-数据扩展4 组织可扩展性5 流程可扩展性6 多快好省-扩展性实现方案7单体应用从数百节点到数万节点的扩展历程8 总结想学习架构师构建流程请跳转:Java架构师系统架构设计
1 导语 理解业务需求,对未来的业务发展有清晰的预见性。…

Spring Boot监听redis过期的key
Redis支持过期监听,可以实现监听过期数据,实现过程如下
1、pom依赖 <!-- Redis--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></depend…