注意:
1、排序:将一组无序序列,调整为有序的序列。所谓有序,就是说,要么升序要么降序。
2、列表排序:将无序列表变成有序列表。
3、列表这个类里,内置排序方法:sort( ),只可以对列表进行排序;而python内置函数sorted( )可以对序列进行排序,即:可以对列表、字符串、集合、字典、元组进行排序。
4、常见的排序算法:
推荐:快速排序、堆排序、归并排序
不推荐:冒泡排序、选择排序、插入排序
其它排序:希尔排序、计数排序、基数排序。
一、冒泡排序 ——时间复杂度: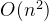
例如,想要得到一个升序的列表,(默认升序)则依次比较相邻的两个数,如果前面的数比后面的数大,则交换这两个数,一趟下来,最大的数跑到了最后,即:一趟下来,无序区减少一个数,有序区增加一个数。
相反,如果想得到降序,则依次比较相邻的两个数,如果前面的数比后面的数小,则交换这两个数。对于代码,只需要把
li[j] > li[j + 1] 改为
li[j] < li[j + 1]即可。
它是原地排序,不需要新建列表,而是在原来列表上通过交换来进行排序。
代码:
以升序为例,分别用三种方式表示列表:推荐第三种!!!
1、列表写死:
def bubble_sort(li):for i in range(len(li) - 1): # 总共要排n-1趟for j in range(len(li)-1-i): # 每趟里,依次比较相邻的两个数if li[j] > li[j + 1]:li[j], li[j + 1] = li[j + 1], li[j]l1 = [1, 4, 3, 2]
bubble_sort(l1)
print(l1)# 结果:
[1, 2, 3, 4]2、列表不写死,用生成随机整数方式生成列表
import randomdef bubble_sort(li):for i in range(len(li) - 1): # 总共要排n-1趟for j in range(len(li) - 1 - i): # 每趟里,依次比较相邻的两个数if li[j] > li[j + 1]:li[j], li[j + 1] = li[j + 1], li[j]l1 = [random.randint(1, 10) for i in range(4)] # 从1~10里,随机生成4个数
print("待排序列为:", l1)
bubble_sort(l1)
print("冒泡排序后:", l1)# 结果:
待排序列为: [8, 1, 3, 6]
冒泡排序后: [1, 3, 6, 8]3、列表由用户输入
(1)排成升序:
def bubble_sort(li):for i in range(len(li) - 1): # 总共要循环n-1趟for j in range(len(li) - 1 - i): # 每趟里,依次比较相邻的两个数if li[j] > li[j + 1]: # !!!排成升序li[j], li[j + 1] = li[j + 1], li[j]l1 = list(map(int, (input().split()))) # 用户输入列表
bubble_sort(l1)
print(l1) # 输出最后的排序结果输入:7 4 2 1# 结果:
[1, 2, 4, 7]!!优化1:想要看到每一趟排序完的结果:
def bubble_sort(li):for i in range(len(li) - 1): # 总共要循环n-1趟for j in range(len(li) - 1 - i): # 每趟里,依次比较相邻的两个数if li[j] > li[j + 1]:li[j], li[j + 1] = li[j + 1], li[j]print("第%s趟排序后的结果:%s" % (i, li)) # !!!l1 = list(map(int, (input().split()))) # 用户输入列表
bubble_sort(l1)
print("最终排序结果:", l1) # 输出最后的排序结果# 输入:
7 4 2 1
# 结果:
第0趟排序后的结果:[4, 2, 1, 7]
第1趟排序后的结果:[2, 1, 4, 7]
第2趟排序后的结果:[1, 2, 4, 7]
最终排序结果: [1, 2, 4, 7]可知,三趟下来,列表就拍好序了,所以,n个数,一共需要排n-1趟。
效果图:

(2)排成降序:只需要把上面 > 改成 <
def bubble_sort(li):for i in range(len(li) - 1): # 总共要循环n-1趟for j in range(len(li) - 1 - i): # 每趟里,依次比较相邻的两个数if li[j] < li[j + 1]: # !!!排成降序li[j], li[j + 1] = li[j + 1], li[j]print("第%s趟排序后的结果:%s" % (i, li)) # !!!l1 = list(map(int, (input().split()))) # 用户输入列表
bubble_sort(l1)
print("最终排序结果:", l1) # 输出最后的排序结果# 输入:1 3 5 7# 结果:
第0趟排序后的结果:[3, 5, 7, 1]
第1趟排序后的结果:[5, 7, 3, 1]
第2趟排序后的结果:[7, 5, 3, 1]
最终排序结果: [7, 5, 3, 1]!!优化2:上面代码有一个弊端,例如:现对[5, 6, 7, 1,2, 3]进行排序
def bubble_sort(li):for i in range(len(li) - 1): # 总共要循环n-1趟for j in range(len(li) - 1 - i): # 每趟里,依次比较相邻的两个数if li[j] > li[j + 1]:li[j], li[j + 1] = li[j + 1], li[j]print("第%s趟排序后的结果:%s" % (i, li)) # !!!l1 = list(map(int, (input().split()))) # 用户输入列表
bubble_sort(l1)
print("最终排序结果:", l1) # 输出最后的排序结果# 输入:5 6 7 1 2 3
# 结果:
第0趟排序后的结果:[5, 6, 1, 2, 3, 7]
第1趟排序后的结果:[5, 1, 2, 3, 6, 7]
第2趟排序后的结果:[1, 2, 3, 5, 6, 7]
第3趟排序后的结果:[1, 2, 3, 5, 6, 7]
第4趟排序后的结果:[1, 2, 3, 5, 6, 7]
最终排序结果: [1, 2, 3, 5, 6, 7]可以看到:
第0趟排序后的结果:[5, 6, 1, 2, 3, 7]
第1趟排序后的结果:[5, 1, 2, 3, 6, 7]
第2趟排序后的结果:[1, 2, 3, 5, 6, 7]
第3趟排序后的结果:[1, 2, 3, 5, 6, 7]
第4趟排序后的结果:[1, 2, 3, 5, 6, 7]
最终排序结果: [1, 2, 3, 5, 6, 7]
其实,第三趟排序完,列表已经排好了,但是这里又多排了第4趟,这就是它的弊端,所以代码可以进行优化,一趟下来,如果没有元素发生交换,则说明,列表已排好序,直接输出即可。
具体做法:加个标志位。
def bubble_sort(li):for i in range(len(li) - 1): # 总共要循环n-1趟tag = False # !!!for j in range(len(li) - 1 - i): # 每趟里,依次比较相邻的两个数if li[j] > li[j + 1]:li[j], li[j + 1] = li[j + 1], li[j]tag = True # !!!print("第%s趟排序后的结果:%s" % (i, li)) # !!!if not tag: # !!!returnl1 = list(map(int, (input().split()))) # 用户输入列表
bubble_sort(l1)
print("最终排序结果:", l1) # 输出最后的排序结果# 输入:5 6 7 1 2 3
# 结果:
第0趟排序后的结果:[5, 6, 1, 2, 3, 7]
第1趟排序后的结果:[5, 1, 2, 3, 6, 7]
第2趟排序后的结果:[1, 2, 3, 5, 6, 7]
第3趟排序后的结果:[1, 2, 3, 5, 6, 7]
最终排序结果: [1, 2, 3, 5, 6, 7]可见,此时第4趟没有了。
注解:
def bubble_sort(li):for i in range(len(li) - 1): # 总共要循环n-1趟tag = Falsefor j in range(len(li) - 1 - i): # 每趟里,依次比较相邻的两个数if li[j] > li[j + 1]:li[j], li[j + 1] = li[j + 1], li[j]tag = Trueif not tag:returnl1 = list(map(int, (input().split()))) # 用户输入列表
bubble_sort(l1)
print("最终排序结果:", l1) # 输出最后的排序结果# 输入:5 6 7 1 2 3
# 结果:
最终排序结果: [1, 2, 3, 5, 6, 7]逻辑运算符:not的用法:not就是取反
例1:
tag = True
print(not tag) # not就是取反# 结果:
False例2:
tag = Trueif not tag: print(tag)
# 结果: 控制台什么都没有进程已结束,退出代码 0解释:if not tag:
if 是条件判断语句,如果要执行 if 下面的代码,说明 if 后面的东西是 True。
而这里 tag = True , not tag就是False
整条判断语句就是 if False,说明 if 后面的东西是False,所以if 下面的代码就不会执行,这里也就不会输出tag的值了。
改下:改成 tag = False
tag = False
print(not tag)
if not tag: # not tag=True,这句话就是if True: 式子成立print(tag)# 结果:
True
False