3. 线性神经网络
回归(regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。 在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。
在机器学习领域中的大多数任务通常都与预测(prediction)有关。 当我们想预测一个数值时,就会涉及到回归问题。 常见的例子包括:预测价格(房屋、股票等)、预测住院时间(针对住院病人等)、 预测需求(零售销量等)。 但不是所有的预测都是回归问题。 在后面的章节中,我们将介绍分类问题。分类问题的目标是预测数据属于一组类别中的哪一个。
3.1. 线性回归
线性回归的基本元素
Here is the text extracted from the file:
3.1.1. 线性回归的基本元素
线性回归(linear regression)可以追溯到19世纪初,它在回归的各种标准工具中最简单而且最流行。线性回归基于几个简单的假设:首先,假设自变量x和因变量y之间的关系是线性的,即y可以表示为x中元素的加权和,这里通常允许包含观测值的一些噪声;其次,我们假设任何噪声都比较正常,如噪声遵循正态分布。
为了解释线性回归,我们举一个实际的例子:我们希望根据房屋的面积(平方英尺)和房龄(年)来估算房屋价格(美元)。为了开发一个能预测房价的模型,我们需要收集一个真实的数据集。这个数据集包括了房屋的销售价格、面积和房龄。在机器学习的术语中,该数据集称为训练数据集(training data set)或训练集(training set)。每行数据(比如一次房屋交易相对应的数据)称为样本(sample),也可以称为数据点(data point)或数据样本(data instance)。我们把试图预测的目标(比如预测房屋价格)称为标签(label)或目标(target)。预测所依据的自变量(面积和房龄)称为特征(feature)或协变量(covariate)。
通常,我们使用n来表示数据集中的样本数。对索引为i的样本,其输入表示为x(i) = [x1(i), x2(i)]⊤,其对应的标签是y(i)。
1.线性模型
线性假设是指目标(房屋价格)可以表示为特征(面积和房龄)的加权和,如下面的式子:
中的warea和wage称为权重(weight),权重决定了每个特征对我们预测值的影响。b称为偏置(bias)、偏移量(offset)或截距(intercept)。偏置是指当所有特征都取值为0时,预测值应该为多少。即使现实中不会有任何房子的面积是0或房龄正好是0年,我们仍然需要偏置项。如果没有偏置项,我们模型的表达能力将受到限制。 严格来说,(3.1.1)是输入特征的一个仿射变换(affine transformation)。仿射变换的特点是通过加权和对特征进行线性变换(linear transformation), 并通过偏置项来进行平移(translation)。
给定一个数据集,我们的目标是寻找模型的权重w和偏置b:当给定从x的同分布中取样的新样本特征时,这组权重向量和偏置能够使得新样本预测标签的误差尽可能小。输出的预测值由输入特征通过线性模型的仿射变换决定,仿射变换由所选权重和偏置确定。
而在机器学习领域,我们通常使用的是高维数据集,建模时采用线性代数表示法会比较方便。当我们的输入包含d个特征时,我们将预测结果y^(通常使用“尖角”符号表示y的估计值)表示为:
将所有特征放到向量x中,并将所有权重放到向量w中,我们可以用点积形式来简洁地表达模型:
在 (3.1.3)中,向量x对应于单个数据样本的特征。用符号表示的矩阵X可以很方便地引用我们整个数据集的n个样本。其中,X的每一行是一个样本,每一列是一种特征。
对于特征集合X,预测值y^(通常使用“尖角”符号表示y的估计值)可以通过矩阵-向量乘法表示为:
y^ = Xw + b
这个过程中的求和将使用广播机制 (广播机制在2.1.3节中有详细介绍)。给定训练数据特征X和对应的已知标签y,线性回归的目标是找到一组参数w和b:当给定从X的同分布中取样的新样本特征时,这组权重向量和偏置能够使得新样本预测标签的误差尽可能小。
虽然我们相信给定x预测y的最佳模型会是线性的,但我们很难找到一个有n个样本的真实数据集,其中对于所有的1 ≤ i ≤ n,y(i)完全等于w⊤x(i) + b。无论我们使用什么手段来观察特征X和标签y,都可能会出现少量的观测误差。因此,即使确信特征与标签的潜在关系是线性的,我们也会加入一个噪声项来考虑观测误差带来的影响。
在开始寻找最好的模型参数w和b之前,我们还需要两个东西: (1)一种模型质量的度量方式;(2)一种能够更新模型以提高模型预测质量的方法。
2.损失函数
在我们开始考虑如何用模型拟合数据之前,我们需要确定一个拟合程度的度量。损失函数(loss function)能够量化目标的实际值与预测值之间的差距。通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。回归问题中最常用的损失函数是平方误差函数。当样本i的预测值为y^(i),其相应的真实标签为y(i)时,平方误差可以定义为以下公式:
常数1⁄2不会带来本质的差别,但这样在形式上稍微简单一些(因为当我们对损失函数求导后常数系数为1)。由于训练数据集并不受我们控制,所以经验误差只是关于模型参数的函数。为了进一步说明,来看下面的例子。 我们为一维情况下的回归问题绘制图像,如图3.1.1所示。
由于平方误差函数中的二次方项,估计值y^(i)和观测值y(i)之间较大的差异将导致更大的损失。为了度量模型在整个数据集上的质量,我们需计算在训练集n个样本上的损失均值(也等价于求和)。
在训练模型时,我们希望寻找一组参数(w*, b*),这组参数能最小化在所有训练样本上的总损失。如下式
:
3. 解析解
线性回归刚好是一个很简单的优化问题。 与我们将在本书中所讲到的其他大部分模型不同,线性回归的解可以用一个公式简单地表达出来, 这类解叫作解析解(analytical solution)。 首先,我们将偏置b合并到参数w中,合并方法是在包含所有参数的矩阵中附加一列。 我们的预测问题是最小化||y - Xw||^2。 这在损失平面上只有一个临界点,这个临界点对应于整个区域的损失极小点。 将损失关于w的导数设为0,得到解析解:
像线性回归这样的简单问题存在解析解,但并不是所有的问题都存在解析解。 解析解可以进行很好的数学分析,但解析解对问题的限制很严格,导致它无法广泛应用在深度学习里。
4. 随机梯度下降
即使在我们无法得到解析解的情况下,我们仍然可以有效地训练模型。 在许多任务上,那些难以优化的模型效果要更好。 因此,弄清楚如何训练这些难以优化的模型是非常重要的。
本书中我们用到一种名为梯度下降(gradient descent)的方法, 这种方法几乎可以优化所有深度学习模型。 它通过不断地在损失函数递减的方向上更新参数来降低误差。
梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值) 关于模型参数的导数(在这里也可以称为梯度)。 但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。 因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本, 这种变体叫做小批量随机梯度下降(minibatch stochastic gradient descent)。
在每次迭代中,我们首先随机抽样一个小批量B, 它是由固定数量的训练样本组成的。 然后,我们计算小批量的平均损失关于模型参数的导数(也可以称为梯度)。 最后,我们将梯度乘以一个预先确定的正数η,并从当前参数的值中减掉。
我们用下面的数学公式来表示这一更新过程(∂表示偏导数):
总结一下,算法的步骤如下: (1)初始化模型参数的值,如随机初始化; (2)从数据集中随机抽取小批量样本且在负梯度的方向上更新参数,并不断迭代这一步骤。 对于平方损失和仿射变换,我们可以明确地写成如下形式:
公式(3.1.10)中的w和x都是向量。 在这里,更优雅的向量表示法比系数表示法(如w1, w2, ..., wd)更具可读性。 |B|表示每个小批量中的样本数,这也称为批量大小(batch size)。 η表示学习率(learning rate)。 批量大小和学习率的值通常是手动预先指定,而不是通过模型训练得到的。 这些可以调整但不在训练过程中更新的参数称为超参数(hyperparameter)。 调参(hyperparameter tuning)是选择超参数的过程。 超参数通常是我们根据训练迭代结果来调整的, 而训练迭代结果是在独立的验证数据集(validation dataset)上评估得到的。
在训练了预先确定的若干迭代次数后(或者直到满足某些其他停止条件后), 我们记录下模型参数的估计值,表示为w^, b^。 但是,即使我们的函数确实是线性的且无噪声,这些估计值也不会使损失函数真正地达到最小值。 因为算法会使得损失向最小值缓慢收敛,但却不能在有限的步数内非常精确地达到最小值。
线性回归恰好是一个在整个域中只有一个最小值的学习问题。 但是对像深度神经网络这样复杂的模型来说,损失平面上通常包含多个最小值。 深度学习实践者很少会去花费大力气寻找这样一组参数,使得在训练集上的损失达到最小。 事实上,更难做到的是找到一组参数,这组参数能够在我们从未见过的数据上实现较低的损失, 这一挑战被称为泛化(generalization)。
5.用模型进行预测
给定“已学习”的线性回归模型,现在我们可以通过房屋面积x1和房龄x2来估计一个(未包含在训练数据中的)新房屋价格。给定特征估计目标的过程通常称为预测(prediction)或推断(inference)。
本书将尝试坚持使用预测这个词。虽然推断这个词已经成为深度学习的标准术语,但其实推断这个词有些用词不当。在统计学中,推断更多地表示基于数据集估计参数。当深度学习从业者与统计学家交谈时,术语的误用经常导致一些误解。
2. 矢量化加速
在训练我们的模型时,我们经常希望能够同时处理整个小批量的样本。 为了实现这一点,需要我们对计算进行矢量化, 从而利用线性代数库,而不是在Python中编写开销高昂的for循环。
%matplotlib inline
import math
import time
import numpy as np
import torch
from d2l import torch as d2l
# 为了说明矢量化为什么如此重要,我们考虑对向量相加的两种方法。 我们实例化两个全为1的10000维向量。 在一种方法中,我们将使用Python的for循环遍历向量; 在另一种方法中,我们将依赖对+的调用。
# 由于在本书中我们将频繁地进行运行时间的基准测试,所以我们定义一个计时器:n = 100000
a = torch.ones([n])
b = torch.ones([n])
class Timer: #@save"""记录多次运行时间"""def __init__(self):self.times = []self.start()def start(self):"""启动计时器"""self.tik = time.time()def stop(self):"""停止计时器并将时间记录在列表中"""self.times.append(time.time() - self.tik)return self.times[-1]def avg(self):"""返回平均时间"""return sum(self.times) / len(self.times)def sum(self):"""返回时间总和"""return sum(self.times)def cumsum(self):"""返回累计时间"""return np.array(self.times).cumsum().tolist()
# 现在我们可以对工作负载进行基准测试。
# 首先,我们使用for循环,每次执行一位的加法。c = torch.zeros(n)
timer = Timer()
for i in range(n):c[i] = a[i] + b[i]
f'{timer.stop():.5f} sec'
# '0.89696 sec'
# 或者,我们使用重载的+运算符来计算按元素的和。
timer.start()
d = a + b
f'{timer.stop():.5f} sec'
# '0.00019 sec'
# 结果很明显,第二种方法比第一种方法快得多。 矢量化代码通常会带来数量级的加速。 另外,我们将更多的数学运算放到库中,而无须自己编写那么多的计算,从而减少了出错的可能性。直接张量之间运算
3. 正态分布与平方损失
接下来,我们通过对噪声分布的假设来解读平方损失目标函数。
正态分布和线性回归之间的关系很密切。 正态分布(normal
distribution),也称为高斯分布(Gaussian distribution),
最早由德国数学家高斯(Gauss)应用于天文学研究。
简单的说,若随机变量x具有均值μ和方差σ^2(标准差σ),其正态分布概率密度函数如下:
下面我们定义一个Python函数来计算正态分布。
def normal(x, mu, sigma):p = 1 / math.sqrt(2 * math.pi * sigma**2)return p * np.exp(-0.5 / sigma**2 * (x - mu)**2)
# 再次使用numpy进行可视化
x = np.arange(-7, 7, 0.01)# 均值和标准差对
params = [(0, 1), (0, 2), (3, 1)]
d2l.plot(x, [normal(x, mu, sigma) for mu, sigma in params], xlabel='x',ylabel='p(x)', figsize=(4.5, 2.5),legend=[f'mean {mu}, std {sigma}' for mu, sigma in params])就像我们所看到的,改变均值会产生沿x轴的偏移,增加方差将会分散分布、降低其峰值。
均方误差损失函数(简称均方损失)可以用于线性回归的一个原因是:
我们假设了观测中包含噪声,其中噪声服从正态分布。 噪声正态分布如下式:
, 其中,
。
因此,我们现在可以写出通过给定的x观测到特定y的似然:
现在,根据极大似然估计法,参数w和b的最优值是使整个数据集的似然最大的值:
根据极大似然估计法选择的估计量称为极大似然估计量。
虽然使许多指数函数的乘积最大化看起来很困难,
但是我们可以在不改变目标的前提下,通过最大化似然对数来简化。
由于历史原因,优化通常是说最小化而不是最大化。
我们可以改为最小化负对数似然-logP(y|X)。
由此可以得到的数学公式是:
现在我们只需要假设σ是某个固定常数就可以忽略第一项,
因为第一项不依赖于w和b。
现在第二项除了常数1/σ^2外,其余部分和前面介绍的均方误差是一样的。
幸运的是,上面式子的解并不依赖于σ。
因此,在高斯噪声的假设下,最小化均方误差等价于对线性模型的极大似然估计。
4. 从线性回归到深度网络
到目前为止,我们只谈论了线性模型。 尽管神经网络涵盖了更多更为丰富的模型,我们依然可以用描述神经网络的方式来描述线性模型, 从而把线性模型看作一个神经网络。 首先,我们用“层”符号来重写这个模型。
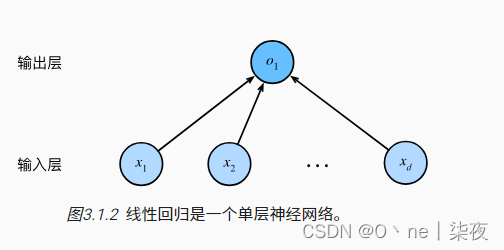
神经网络图
深度学习从业者喜欢绘制图表来可视化模型中正在发生的事情。 在 图3.1.2中,我们将线性回归模型描述为一个神经网络。 需要注意的是,该图只显示连接模式,即只显示每个输入如何连接到输出,隐去了权重和偏置的值。

小结
-
机器学习模型中的关键要素是训练数据、损失函数、优化算法,还有模型本身。
-
矢量化使数学表达上更简洁,同时运行的更快。
-
最小化目标函数和执行极大似然估计等价。
-
线性回归模型也是一个简单的神经网络。
题目
- 假设我们有一些数据x1, ..., xn ∈ R。我们的目标是找到一个常数b,使得最小化∑i(xi - b)^2。
- 找到最优值b的解析解。
- 这个问题及其解与正态分布有什么关系?
-
找到最优值b的解析解:
要找到使$\sum_i (x_i - b)^2$最小的$b$,可以将导数设为0:
$\frac{d}{db} \sum_i (x_i - b)^2 = -2 \sum_i (x_i - b) = 0$
解得:$b = \frac{1}{n}\sum_i x_i$,即$b$等于所有$x_i$的均值。
-
这个问题及其解与正态分布有关系:
$b$使残差平方和$\sum_i (x_i - b)^2$最小,等价于最大化观测数据$x_i$来自均值为$b$,方差为常数的正态分布的似然。
- 推导出使用平方误差的线性回归优化问题的解析解。为了简化问题,可以忽略偏置b(我们可以通过向X添加所有值为1的一列来做到这一点)。
- 用矩阵和向量表示法写出优化问题(将所有数据视为单个矩阵,将所有目标值视为单个向量)。
- 计算损失对w的梯度。
- 通过将梯度设为0、求解矩阵方程来找到解析解。
- 什么时候可能比使用随机梯度下降更好?这种方法何时会失效?
-
优化问题表示:
-
计算梯度:
-
梯度设为0,解方程得:
-
当样本量少,计算解析解的代价小于随机梯度下降,否则随机梯度下降更有效。当$X^TX$不可逆时解析解会失效。
- 假定控制附加噪声ε的噪声模型是指数分布。也就是说,p(ε) = (1/2)exp(-|ε|)
- 写出模型-logP(y|X)下数据的负对数似然。
- 请试着写出解析解。
- 提出一种随机梯度下降算法来解决这个问题。哪里可能出错?(提示:当我们不断更新参数时,在驻点附近会发生什么情况)请尝试解决这个问题。
-
-
负对数似然:
-
没有解析解
-
可以使用随机梯度下降,但存在收敛到非最小点的风险。可以试试平方 Loss 作为替代。
-
下面是torch代码实现:
import torch# 生成数据
X = torch.randn(100, 10)
y = torch.randn(100)# 定义模型
w = torch.randn(10, requires_grad=True)
b = torch.randn(1, requires_grad=True)# 定义损失函数
def loss_fn(y_pred, y):return torch.sum((y_pred - y)**2)# 训练
optimizer = torch.optim.SGD([w, b], lr=1e-3)
for iter in range(100):y_pred = X @ w + bloss = loss_fn(y_pred, y)loss.backward()optimizer.step()optimizer.zero_grad()# 输出训练后的参数
print(w)
print(b)这个代码实现了最小化平方损失来训练线性回归模型,并输出了训练后的权重w和偏置b。我们可以看到随机梯度下降可以用于求解这个线性回归问题。
3.2. 线性回归的从零开始实现
在了解线性回归的关键思想之后,我们可以开始通过代码来动手实现线性回归了。 在这一节中,我们将从零开始实现整个方法, 包括数据流水线、模型、损失函数和小批量随机梯度下降优化器。 虽然现代的深度学习框架几乎可以自动化地进行所有这些工作,但从零开始实现可以确保我们真正知道自己在做什么。 同时,了解更细致的工作原理将方便我们自定义模型、自定义层或自定义损失函数。 在这一节中,我们将只使用张量和自动求导。 在之后的章节中,我们会充分利用深度学习框架的优势,介绍更简洁的实现方式。
1. 生成数据集
参考资料:3.1. 线性回归 — 动手学深度学习 2.0.0 documentation



![[Docker异常篇]解决Linux[文件异常]导致开机Docker服务无法启动](https://img-blog.csdnimg.cn/a764c87021b44f44a5c845ddee522d15.png)