文章目录
- 一、依赖注入_Autowired
- 1.配置类中@Bean 方式注入
- 1.1)注入实例
- 1.2)自动注入的匹配原则
- 2.组件扫描实现自动注入 @Autowired
- 3.set方法注入
- 二、接口解耦_自动注入规则
- 1)利用接口解耦
- 2)@Autowired的注入规则
- 3)@Qualifier注解在调用类中指定对应的组件
- 三、同时使用@Bean和@Component_Druid连接池
- 1.@Bean和@Component同时使用
- 2、Druid
- 2.1)Druid数据库连接池
- 2.2)示例
- 四、读取Properties_@Value
- 1.properties文件env读取
- 2.@Value读取配置
- 2.1 @Value放在形参中配置
- 总结:
- 1.工作中@Bean麻烦,@Component使用更多
- 2. String sql1="select 'Hello Druid'"; 可测试数据库连接情况;
- 3.[Druid和HikariCP对比](https://blog.csdn.net/weixin_38943725/article/details/122716340)
- 3.1 性能方面:HikariCP因为细节方面优化力度较大,性能方面强于Druid
- 3.2 功能丰富程度方面:Druid功能更全面除了具有连接池的基本功能以外,还支持sql级监控,支持扩展,防止SQL注入等功能。
- 3.3 使用热度:Druid在国内使用较多,国内有很多生产实践。HikariCP是spring boot 2.0以后默认连接池,在国外使用较多。
一、依赖注入_Autowired
1.配置类中@Bean 方式注入
1.1)注入实例
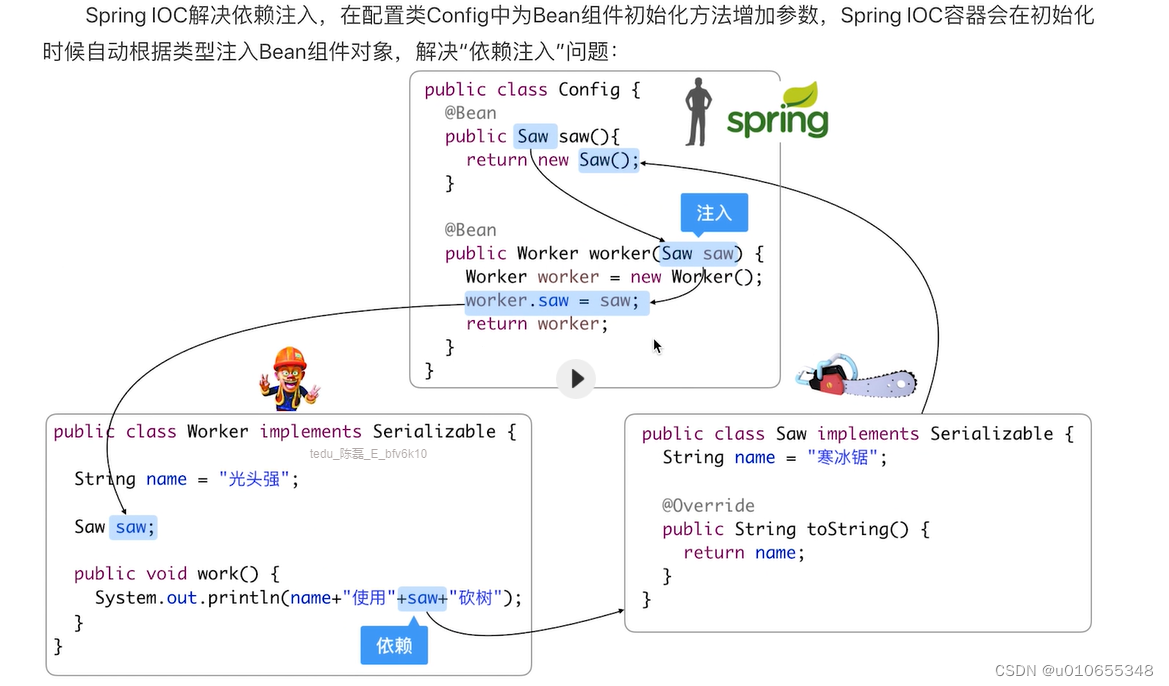
配置类:
public class Config {@Beanpublic Saw saw(){return new Saw();}@Beanpublic Worker worker(Saw saw){Worker worker=new Worker();worker.saw = saw;return worker;}
}
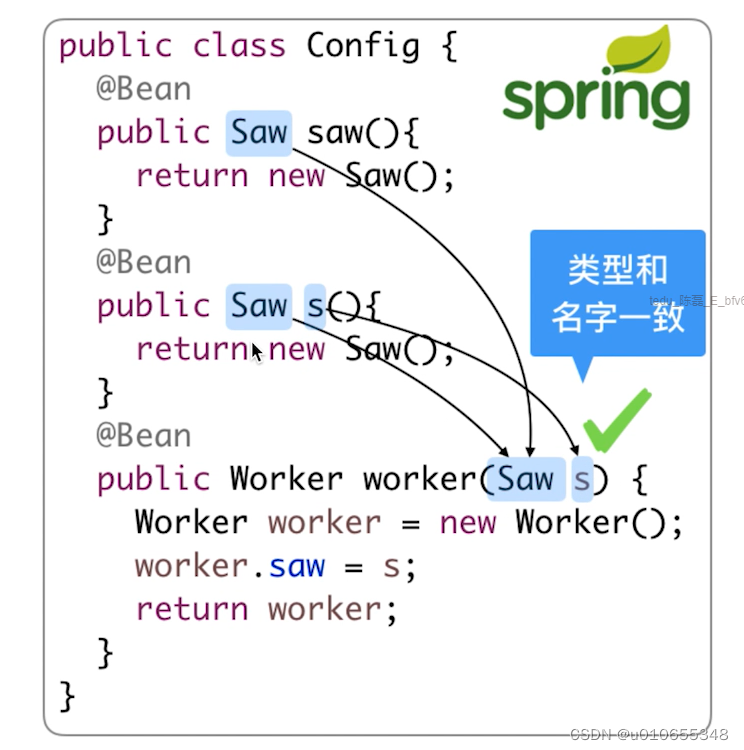
1.2)自动注入的匹配原则

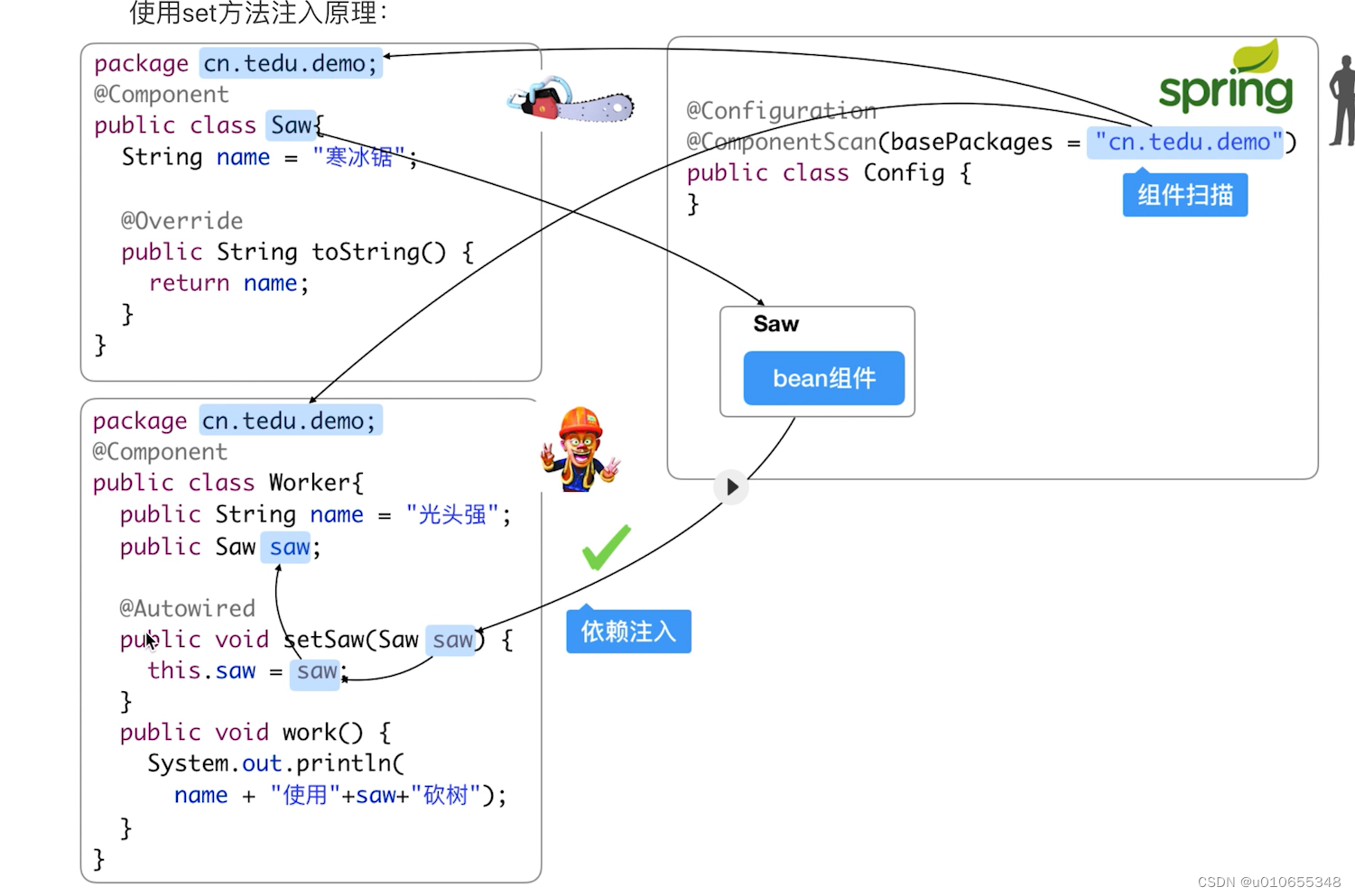
2.组件扫描实现自动注入 @Autowired
配置类:
@Configuration
@ComponentScan(basePackages = "cn.tedu.demo")public class Config {}
Saw组件类:
@Component
public class Saw implements Serializable {String name="寒冰锯";@Overridepublic String toString() {return name;}
}
Woker组件类:
@Component
public class Worker implements Serializable {String name="光头强";@Autowiredpublic Saw saw;public void work(){System.out.println(name+"使用..."+saw+"...砍树");}
}
3.set方法注入
二、接口解耦_自动注入规则
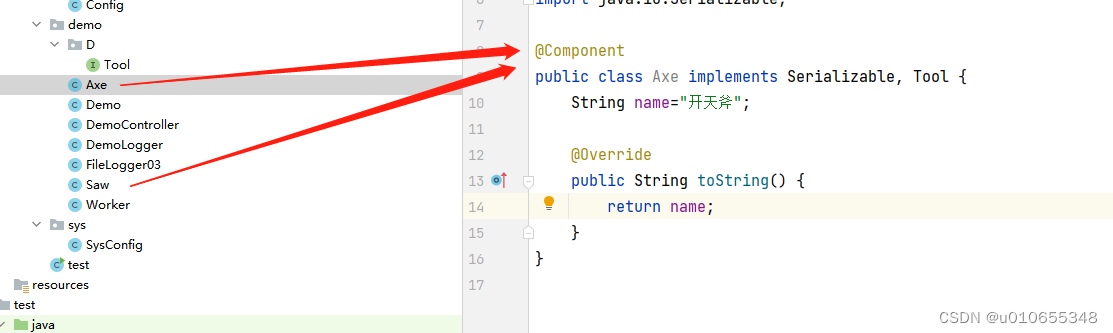
1)利用接口解耦

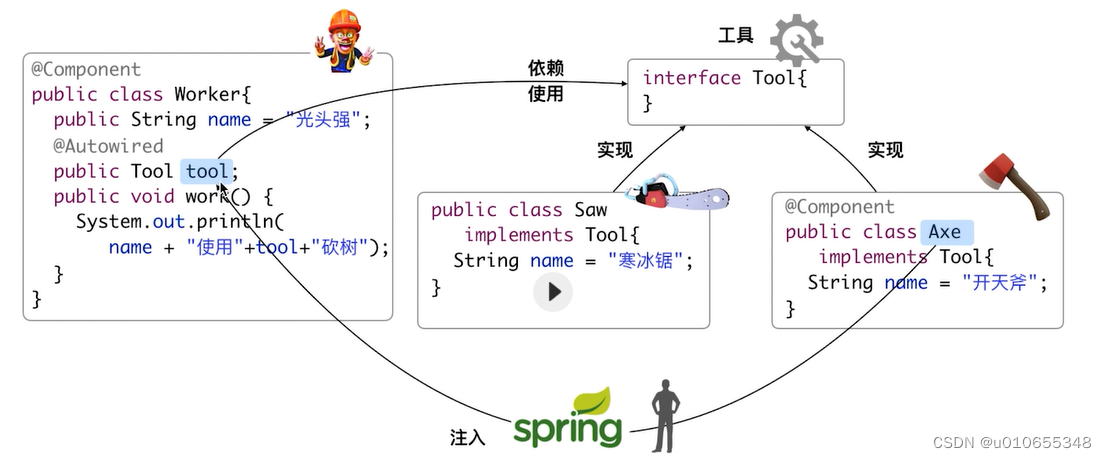
那个类上使用了@Component标注,Tool就指向那个
配置类:
@Configuration
@ComponentScan(basePackages = "cn.tedu.demo")public class Config {}
2)@Autowired的注入规则
组件上面都加@Component的情况,

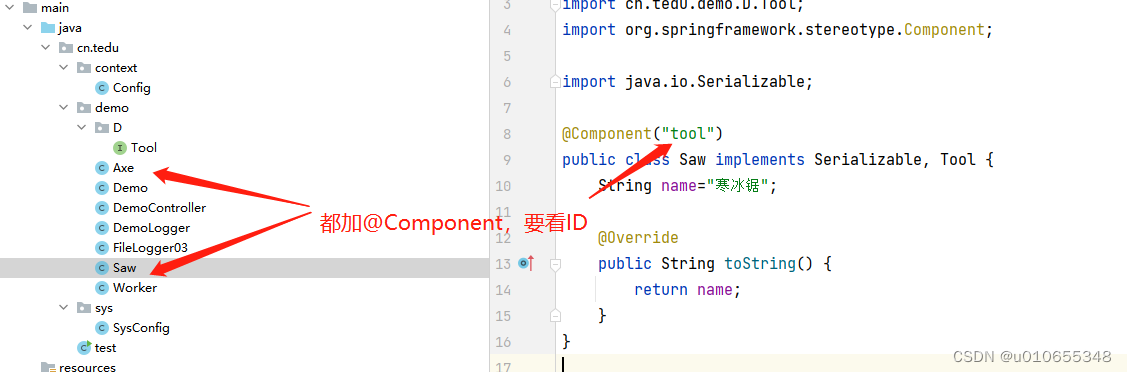
3)@Qualifier注解在调用类中指定对应的组件
组件类都是@Component

三、同时使用@Bean和@Component_Druid连接池
1.@Bean和@Component同时使用
@Bean组件注入到@Component;
@Component组件注入到@Bean;
以上两种情况都可以;
Config配置类:
@Configuration
public class SysConfig {@Beanpublic Date myDate(){return new Date();}
}
Worker组件类:
@Component
public class Worker implements Serializable {String name="光头强";@Autowired@Qualifier("axe")public Tool tool;@Autowiredprivate Date dt; public void work(){System.out.println(name+"使用..."+tool+"...砍树");System.out.println(dt);}
}
2、Druid
2.1)Druid数据库连接池

2.2)示例
POM配置
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.15</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.28</version></dependency>
Config类配置:
@Configuration
@ComponentScan(basePackages = "cn.tedu.demo")public class Config {@Bean(initMethod="init", destroyMethod="close")public DataSource dataSource(){DruidDataSource dt =new DruidDataSource();dt.setDriverClassName("com.mysql.cj.jdbc.Driver");dt.setUrl("jdbc:mysql://localhost:3306/tedu?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true");dt.setUsername("root");dt.setPassword("root");dt.setMaxActive(10);dt.setInitialSize(2);return dt;}
}
测试类代码:
@Testpublic void testDruid(){DataSource ds = ctx.getBean("dataSource", DataSource.class);try(Connection conn = ds.getConnection()) {String sql="select * from student";Statement st= conn.createStatement();ResultSet rs=st.executeQuery(sql);while (rs.next()){System.out.println(rs.getString(2));}} catch (Exception e) {e.printStackTrace();}}
四、读取Properties_@Value
1.properties文件env读取
配置类代码:
@Configuration
@ComponentScan(basePackages = "cn.tedu.demo")
@PropertySource("classpath:jdbc.properties")
public class Config {@AutowiredEnvironment env;@Bean(initMethod = "init", destroyMethod = "close")public DataSource dataSource(){DruidDataSource dt =new DruidDataSource();dt.setDriverClassName(env.getProperty("db.driver"));dt.setUrl(env.getProperty("db.url"));dt.setUsername(env.getProperty("db.username"));dt.setPassword(env.getProperty("db.password"));dt.setMaxActive(env.getProperty("db.maxActive",Integer.class));dt.setInitialSize(env.getProperty("db.initSize",Integer.class));return dt;}
}
jdbc.properties代码:
db.driver=com.mysql.cj.jdbc.Driver
db.url=jdbc:mysql://localhost:3306/tedu?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
db.username=root
db.password=root
db.maxActive=10
db.initialSize=2
2.@Value读取配置
2.1 @Value放在形参中配置
配置类:
@Configuration
@ComponentScan(basePackages = "cn.tedu.demo")
@PropertySource("classpath:jdbc.properties")
public class Config {@AutowiredEnvironment env;@Bean(initMethod = "init", destroyMethod = "close")public DataSource dataSource(@Value("${db.driver}") String driver,@Value("${db.url}") String url,@Value("${db.username}") String username,@Value("${db.password}") String password,@Value("${db.maxActive}") int maxActive,@Value("${db.initSize}") int initSize){DruidDataSource dt =new DruidDataSource();dt.setDriverClassName(driver);dt.setUrl(url);dt.setUsername(username);dt.setPassword(password);dt.setMaxActive(maxActive);dt.setInitialSize(initSize);return dt;}
}