在前后端分离项目中,经常需要把ORM模型转化为字典,再将字典转化为JSON格式的字符串。在遇到sqlalchemy_serializer之前,我都是通过类似Java中的反射原理,获取当前ORM模型的所有字段,然后写一个to_dict方法来将字段以及他的值封装成字典。大概的代码如下所示:
def to_dict(self):return {c.name: str(getattr(self, c.name)) for c in self.__table__.columns}
这种做法虽然一定程度上方便了开发,但也是带着枷锁跳舞,存在以下几个弊端:
-
无法优雅的排除不需要序列化的字段。
-
无法优雅的序列化多表之间的关系。
直到后来我遇到了sqlalchemy_serializer,泪流满面,这不就是我苦苦寻找的ORM模型序列化库吗?使用他序列化ORM模型,让我带你看看有多爽!
一、安装:
sqlalchemy-serializer已经上架PyPi,因此通过pip命令即可安装:
pip install SQLAlchemy-serializer
二、基本使用:
如果想要让某个ORM模型能被序列化,那么只需要在定义模型的时候,让他继承自sqlalchemy_serializer.SerializerMixin即可,示例代码如下:
from sqlalchemy_serializer import SerializerMixinclass UserModel(db.Model, SerizlizerMixin):__tablename__ = "user"id = db.Column(db.String(100), primary_key=True, default=shortuuid.uuid)email = db.Column(db.String(50), unique=True, nullable=False)username = db.Column(db.String(50), nullable=False)password = db.Column(db.String(200), nullable=False)
SerizlizerMixin会给ORM模型添加一个to_dict方法,此时你可以通过一行代码将ORM模型序列化成字典:
user = UserModel.query.filter(...).one()
user_dict = user.to_dict()
上述代码中将把UsrModel中所有字段都序列化成字典。
三、排除字段:
模型中有的字段不需要被序列化,比如用户的密码,那么这时候可以通过设置rules参数,或者only参数来指定序列化规则。比如排除password,那么可以通过如下代码方式实现:
user = UserModel.query.filter(...).one()
user_dict = user.to_dict(rules=('-password',))
上述代码中在调用to_dict方法的时候,传递了rules参数,并且设置了-password,其中的-号代表排除的意思,意思是不要序列化password。如果在绝大部分场景下都不需要某些字段,可以把这个规则写在模型定义中,这样所有序列化的时候,都会遵循这个序列化规则。比如:
class UserModel(db.Model, SerizlizerMixin):serialize_rules = ("-password", )__tablename__ = "user"id = db.Column(db.String(100), primary_key=True, default=shortuuid.uuid)email = db.Column(db.String(50), unique=True, nullable=False)username = db.Column(db.String(50), nullable=False)password = db.Column(db.String(200), nullable=False)
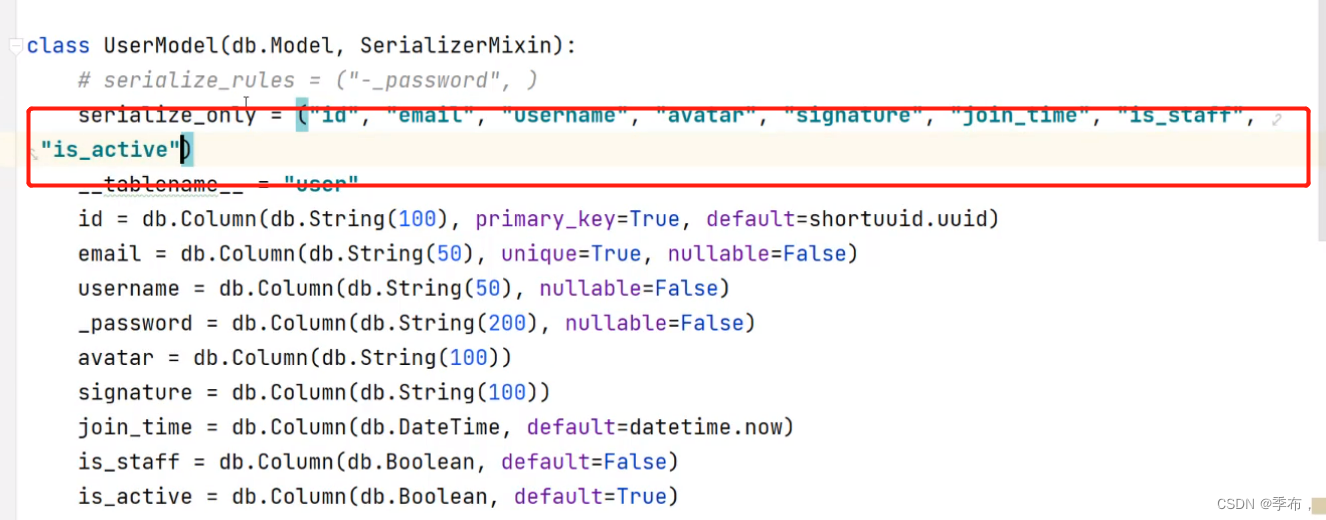
如果需要排除的字段太多了,我们可以通过设置serialize_only属性来标记仅仅序列化某些字段。比如:
class UserModel(db.Model, SerizlizerMixin):serialize_only = ("id", "username")__tablename__ = "user"id = db.Column(db.String(100), primary_key=True, default=shortuuid.uuid)email = db.Column(db.String(50), unique=True, nullable=False)username = db.Column(db.String(50), nullable=False)password = db.Column(db.String(200), nullable=False)
上述代码在序列化的时候,就只会序列化id和username两个字段了。
四、递归序列化模型和树:
sqlalchemy_serializer会默认序列化定义好关系的模型,比如有UserModel和PostModel两个模型:
class UserModel(db.Model, SerizlizerMixin):serialize_rules = ("-posts",)__tablename__ = "user"id = db.Column(db.String(100), primary_key=True, default=shortuuid.uuid)username = db.Column(db.String(50), nullable=False)class PostModel(db.Model, SerializerMixin):__tablename__ = "post"id = db.Column(db.String(100), primary_key=True, default=shortuuid.uuid)title = db.Column(db.String(100), nullable=False)content = db.Column(db.Text, nullable=False)author_id = db.Column(db.String(100), db.ForeignKey("user.id"))author = db.relationship("UserModel", backref="posts")
在序列化PostModel的时候,也会自动递归序列化author,并且author的值有id和username两个字段。这里有个细节需要注意,就是UserModel必须要排除posts。因为PostModel中的author字段,通过backref给UserModel绑定了一个posts字段,如果不排除posts,那么在序列化author的时候,又会序列化posts,造成循环递归序列化。
五、高级用法:
基本上学会以上用法后,99%的场景都没有问题了。如果你在使用sqlalchemy_serializer还有其他业务需求,比如格式化日期的输出、字段扁平化等,那么可以再仔细阅读一下sqlalchemy_serializer的官方文档:官方文档
项目中引用

将登录后数据序列化返回
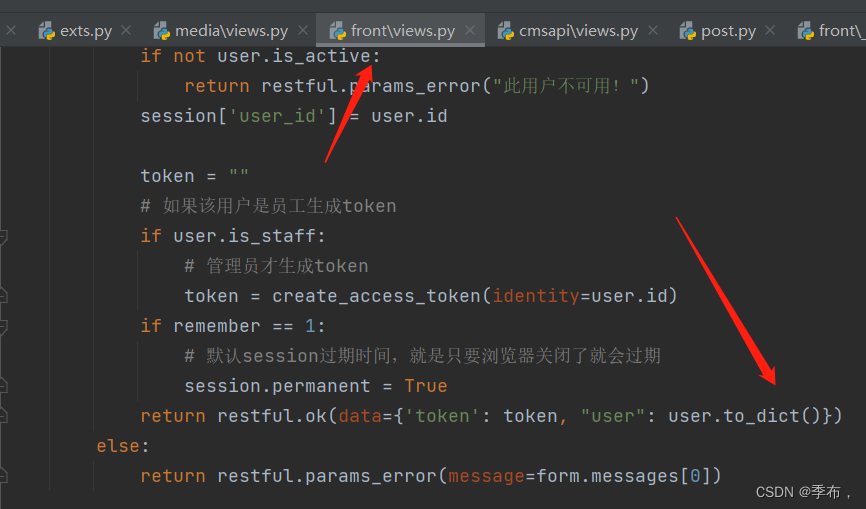
序列化后的数据,此时看到的跟该用户相关的评论,帖子也序列化了,这就会循环序列化

可以设置仅序列化的字段