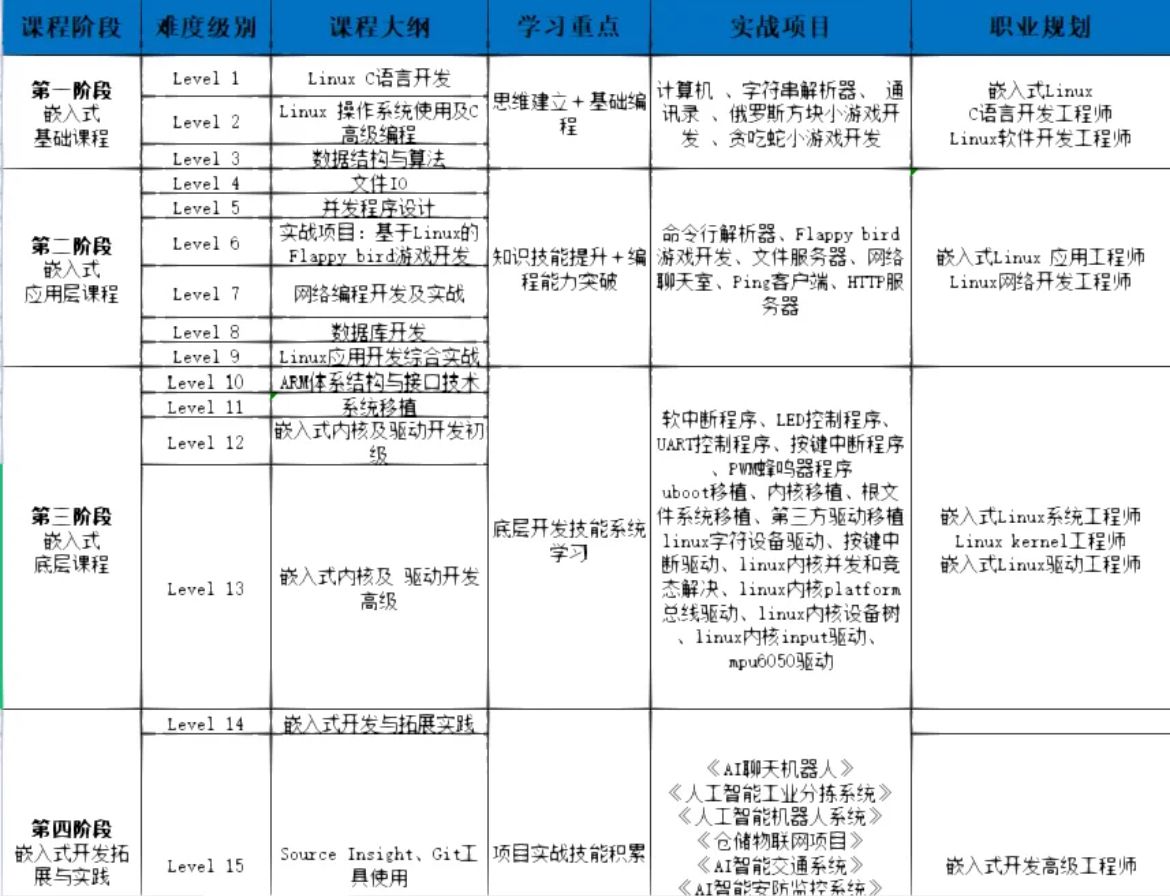
题目
给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
示例 1:
- 输入: nums = [1,1,1,2,2,3], k = 2
- 输出: [1,2]
示例 2:
- 输入: nums = [1], k = 1
- 输出: [1]
提示:
- 你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。
- 你的算法的时间复杂度必须优于 $O(n \log n)$ , n 是数组的大小。
- 题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的。
- 你可以按任意顺序返回答案。
思路
这题有两个关键要搞清的点:
- 如何求每个元素出现的次数?
- 如何得到topk个出现次数的元素?
首先得到每个元素出现的次数是多少,练习了那么久,自然而然想到用字典结构去存储每个元素及对应的出现次数, 线性扫一遍即可。
第二个是如何根据这个字典得到出现次数最多的topk个元素,我们首先可能会想到排序,但是排序有个坏处就是需要把所有元素都参与进来排序,而当k远远小于nums长度时,我们没必要对所有元素排序,只需要找到前k个元素就行了,所以排序在这里不是最优选择。有一种结构就能每次让我们取到最大值/最小值,只需要取k次元素就可以得到答案了,它就是堆!
我们只需要维护一个大小为k的堆用来保存答案,那么用大顶堆还是小顶堆呢?如果用大顶堆,当推入的元素超过k时,最大的元素就需要被删除,就得不到我们需要的答案了,所以需要用小顶堆。当推入元素会使当前堆长度超过k时,我们只需要把最小的元素推出去,这样到最后堆中剩下的肯定都是nums中topk个出现次数最大的元素了。
class Solution:def topKFrequent(self, nums: List[int], k: int) -> List[int]:h = []d = dict()# 统计每个数出现的次数for i in range(len(nums)):d[nums[i]] = d.get(nums[i], 0) + 1# 维护大小为k的小根堆for num, v in d.items():# 这里把出现次数放到第一个位置,小根堆会默认以第一个位置进行排序heapq.heappush(h, (v, num))# 如果当前堆长度超过k,则把堆顶元素推出来,从而保证当前堆内总是最大的k个元素if len(h)>k:heapq.heappop(h)res = [0]*k# 答案要求是降序,而小根堆正序输出是升序,所以小根堆应该倒序输出for i in range(k-1, -1, -1):res[i] = heapq.heappop(h)[1]return res事实上,我们直接把所有元素都推到一个大根堆中,再取k次堆顶元素也是可以的,而且在力扣上效率是一样的。
class Solution:def topKFrequent(self, nums: List[int], k: int) -> List[int]:d = dict()# 统计每个数出现的次数for i in range(len(nums)):d[nums[i]] = d.get(nums[i], 0) + 1h = [(-1*v, num) for num, v in d.items()]heapq.heapify(h)res = [0]*kfor i in range(k):res[i] = heapq.heappop(h)[1]return res其实还可以更暴力一点,直接库函数,效率和上面一样,不过这样就失去了训练的意义了,在掌握了前两种写法后可以玩一玩库函数。
class Solution:def topKFrequent(self, nums: List[int], k: int) -> List[int]:d = dict()# 统计每个数出现的次数for i in range(len(nums)):d[nums[i]] = d.get(nums[i], 0) + 1h = [(v, num) for num, v in d.items()]res = heapq.nlargest(k,h)return [v for num, v in res]