这是鼎叔的第六十七篇原创文章。行业大牛和刚毕业的小白,都可以进来聊聊。
欢迎关注本专栏和微信公众号《敏捷测试转型》,星标收藏,大量原创思考文章陆续推出。
对于Scrum和用户故事实践的最大难点,我相信是如何估算用户故事的大小,如何拆解它?过大的用户故事会带来一系列的沟通复杂度和潜在质量风险,最好的用户故事是不超过2-3开发人日就能够完成的。本文重温行业经典的估算和拆解方法,并从测试人员的角度思考它。
相关文章请看:聊聊用户故事和测试启发。
故事的大小
用户故事从大到小,可以分类为Epic(史诗故事,需求梳理阶段时的宏大目标),Feature(特性故事,迭代规划的重点目标),User Story(用户故事,迭代中要完成的具体价值点)。注意,也有些敏捷书籍把Epic的规模放在Feature之下,鼎叔采用的是大规模敏捷框架的定义,认为Epic规模更大。

常见的拆分模式
当用户故事太大,无法放入一个迭代中,我们可以用各种手段进行拆分,确保拆分的每个用户故事都有其价值,并可以独立地端到端验收。
以渐进的方式逐步拆分故事,更小粒度的故事有利于团队更准确地对工作量进行估算,更早交付解决方案中价值最高的那部分。
常见的9种用户故事拆分方法,如下。
-
按工作流步骤拆分。哪怕只是一部分工作流,对用户也是有体验感知的,可以及时提供反馈。如网上预定机票这个故事,可以拆分为:查找预定航班,生成订单,获取出票结果信息,系统发送订票成功短信等。
-
按业务规则变化拆分。如积分兑换这个故事,可以1 按积分兑换,2 按部分积分+现金兑换。
-
按主要/次要工作拆分。比如支持信用卡支付机票费用这个故事,可以先支持微信支付,再支持其他主要支付方式。
-
按业务简单和复杂划分。比如商品搜索功能,可以1 按商品名称搜索,2 按其他商品属性的高级搜索。
-
按照处理数据变化来划分。比如网站的内容管理功能,可以 1 支持中文,2支持英文,3 支持其他语言。
-
按照界面变化来划分。比如先输出最简单的UI界面,再输出精美配色的UI界面。
-
按照性能规格来划分。先从慢速中把用户价值做出来,再进行性能优化改进。如1 完成XX功能显示, 2 在10秒内完成XX功能显示。
-
按照操作边界来划分。例如数据的增删改查,1 完成数据的查询,2 完成数据的增加和删除,3 完成数据的修改。
-
拆出一个探针故事。对于我们知之甚少的比较大的故事,我们先在一段时间内做一个探针实验,得到初步的调查结论。
估算用户故事的方法
估算用户故事的大小是团队协作的难点,基本的出发点是越小的故事,估算误差越小,越大的故事,估算精度越低。就好像评估星球的体积大小。这就是我们经常利用斐波拉契数列来收敛估算结果的原因,如下图,以最小星球体积为1,其他星球的大小只能在这个序列中挑选估值:1,2,3,5,8,13,21,34... ...

用户故事的大小估算方法,通常是集体评估的方式,只做相对大小的评估,可利用斐波拉契扑克牌和T恤尺寸等方法进行估算。
开始估算故事之前,需要PO给大家阅读或讲解这个故事的目的,验收标准,如果有交互原型等信息更佳。成员可以针对这个故事进行提问,PO和技术leader可以解答。
成员集体估算是背靠背的,即同时摊开手中的牌,看大小是否一致。先找一个最简单的开发需求来做估算,看看能否对齐成员间的基准,对齐后再估算更大的故事。
发生估算分歧时,会让双方解释原因,重新估算或投票,最多只能估算三轮。
集体估算不是集体承诺,估算无需精确度量,目标是求稳,长期估算结果趋同即可,眼前有一些分歧很正常。整个过程,便于大家对于需求背后的价值和复杂度形成共识,互相学习。
我们可以默认一个故事点就是一个工程师人天可以完成的研发工作(包括设计,编码,测试修复,研讨等),它并不是按沉浸式满负荷工作时长(理想人日)来估计的,有一定的buffer(折扣,通常是10%或20%),考虑到人员有临时请假,团队外会议和杂事打扰的事项。但是这个折扣如果过高就需要集体改进了。

技术团队在一个迭代中的工作人日总数是已知的,即迭代工作日*人数,这就是“迭代速率”。
从行业经验来看,史诗故事的大小范围通常是55-144之间(按斐波拉契数列),特性故事点在13-55之间,用户故事点在1-13之间。
注意:很多团队默认测试人力不是瓶颈,因此估算故事点数只考虑开发侧工作量,人数也只统计开发人员。
其他团队的做法是,故事点数考虑所有测试工作,人数也包含了专职测试人员。
这两类做法我认为都是正确的。
迭代开发速率的监控和改进
当团队完成所有用户故事的大小估算,将总故事点数除以迭代速率,就得到我们要几个迭代才能完成所有交付计划。
在未来的每个迭代,都度量我们实际完成了多少个故事点,就能判断我们在迭代初期预估需求工作量的偏差率如何。注意,迭代中没有完成的故事,相应的完成故事点就是0!
初期预估的迭代速率,后期调整优化后会稳定下来,然后随着敏捷改进措施的实施可能会有一定程度的提升。
项目经理需要关注迭代中的工作燃尽图表,分析是什么原因导致计划中的测试任务完成过程不太符合预期,比如,测试任务为什么迟迟没有开始,前期测试进程为什么被阻塞,测试工作量估算明显和实际不符合,等等,这个分析过程对于未来的测试速率估算准确性,对于提高人员效率,将大有裨益。迭代燃尽图如下所示,理想情况下,它是一个下降的曲线,随着剩余工作的完成,烧尽至零。

下图是产品需求的价值路线图,完整的描述了产品从愿景到发布,整个生命周期的价值是如何实现的。
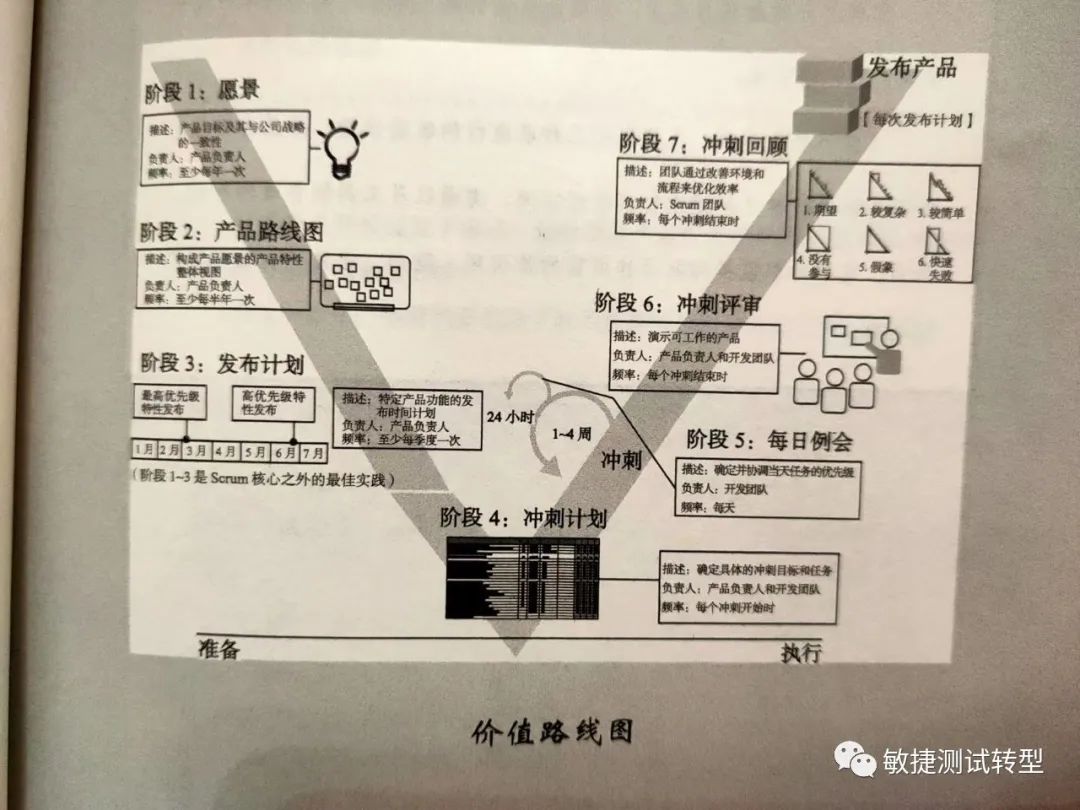
下面详细解答用户故事实践中的几个热门问题。
交付故事点能用来绩效考核么?
建议不要用于绩效考核。
之所以要团队集体估算,就是减少对个人故事的追踪,和个人绩效挂钩,会导致个人在评估时降低要求,同时阻碍团队内的互助合作。
从团队角度看,也不建议通过交付故事点数来横向考核团队。每个团队的人员成熟度和经验不同,业务难度不同,都会形成一个适合自己的开发吞吐节奏,这个节奏越舒服,越有利于产能最大化和自主改进。
但是通过跨团队的故事点实践对比,故事点交付代码规模小、质量相对低的团队,可以像指标高的团队学习,但还是要保持自身的稳定节奏和交付满意度。
迭代规划的故事优先级怎么定?
既然一个迭代只能排入一定大小的故事集合(不超过预期速率),那该排入哪些用户故事呢?只看产品负责人的优先级排序么?
当然,产品负责人应该是最终拍板者,但是技术团队可以合作给出参考意见:
1 哪些故事对用户的利益能产生最大化效果?每个故事都有用户价值说明,PO或者团队对用户价值评估大小(即:给出相对价值点)
2 候选故事的成本。性价比高的故事可以优先,即价值点/故事点的值最大的优先。
3 故事之间的内聚性如何?高内聚的故事集中完成,可能有利于提升研发效率和用户体验。
4 哪个故事的实现能支持近期发布计划?
针对每次计划完成的用户故事,我们可以用MoSCow规则来做优先级分类,即:Must 必须有,Should have 应该有,Could have 可以有,Won't have这次不会有。
如何判断用户故事是否要在本迭代完成,可以基于这几个维度思考:如果不能完成,风险有多大?推迟这个故事,会给其他故事带来什么影响?基于当前产品架构,能帮用户提高价值的故事可以提高优先级。
迭代中想变更交付需求怎么办?
敏捷研发欢迎变化,当一个更紧急的需求插入本迭代时,先估算插入需求的故事点,再从迭代相对低优先级故事中,拿出同样大小的故事集合即可。这种应对方式比传统研发管控方法更灵活,更简单,更准确。
冗余需求是如何产生的?
纵观交付满意度低的团队,除了需求太大,还经常有需求冗余的问题。所谓冗余,就是上线后用户使用率很低的需求。据业界统计,64%的软件特性从未被使用到。敏捷团队在识别需求价值,拆解用户故事和排期之前,PO(产品责任人)要关注这些冗余现象,并积极沟通,思考降低需求冗余的方法:
- 业务方代表担心功能遗漏带来的风险,要求把各种功能都加上。
-
客户缺乏安全感,通过加需求作为谈判技巧。
- 业务方/客户图省事,或者公司由麻烦的预算制度,所以一次性尽可能把需求都提上。之前分享过,和需求大小挂钩付费的合同,功能足够用就可以结束合同,这样更有利于保障交付的效率,降低开发浪费。客户沟通合作和建立信任,要高于事无巨细的合同谈判。用户故事不能再拆解了么?用户故事是需求价值交付的最小单元。但是,从研发分工的角度,用户故事可以拆解为任务这个最小单元,完成一系列的任务后,用户故事才算完成。具体任务可以是:设计,单测,系统测试,归档等等,可以在团队的DoD(完成定义)中约定每个故事需要完成哪些类型的任务。在任务的跟进中要注意跟进的是团队集体交付的结果,避免追踪个人的进度。任务的评估耗时可以以理想小时为单位,建议一个任务卡不超过1理想人天,以便通过看板及时更新。
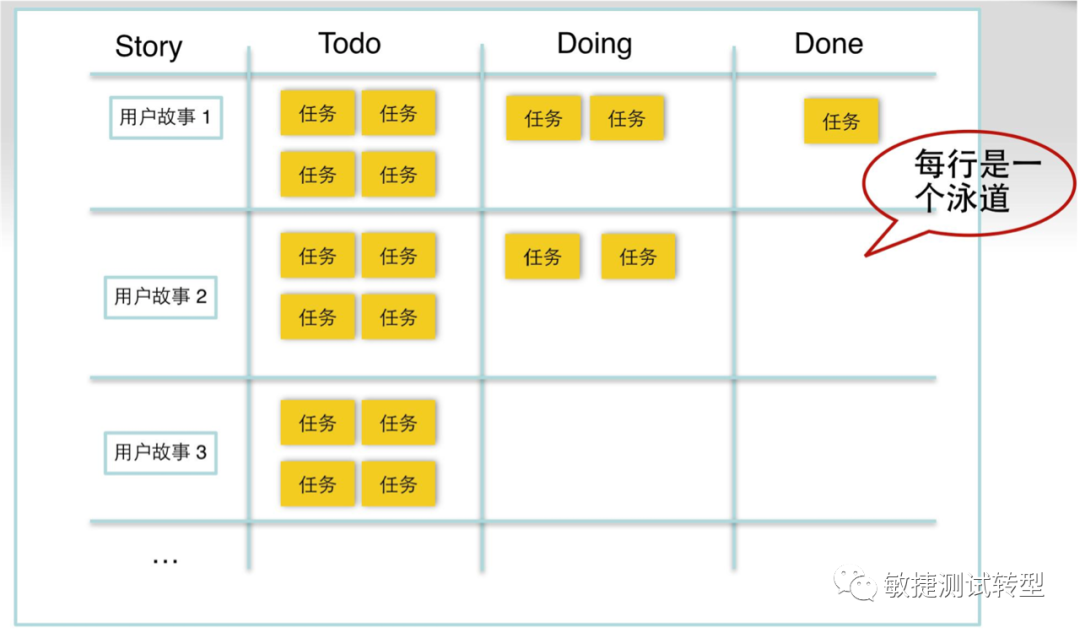
-






![[分布式] Ceph实战应用](https://img-blog.csdnimg.cn/7cadfc84100d415d8aec0faacdec083f.png)