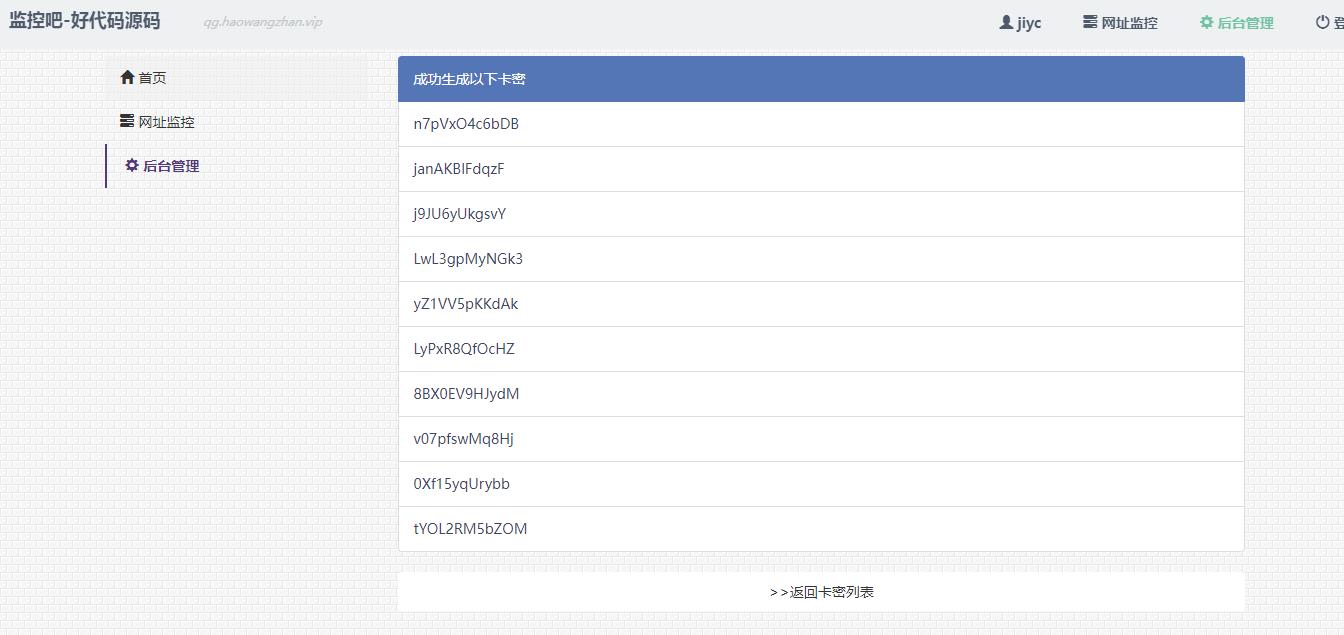
前言
我们最终决定从头开始构建一些东西。我们的想法是,与其专注于保存成堆的数据,如关系数据库、键值存储、搜索索引或缓存,不如专注于将数据视为不断发展和不断增长的流,并围绕这个想法构建一个数据系统——实际上是一个数据架构。 事实证明,这个想法的适用范围比我们预期的要广泛。尽管 Kafka 最初是在社交网络的幕后为实时应用程序和数据流提供支持的,但现在您可以在每个可以想象的行业中看到它成为下一代架构的核心。大型零售商正在围绕连续的数据流重新设计其基本业务流程;汽车公司正在收集和处理来自联网汽车的实时数据流;银行也在围绕 Kafka 重新思考其基本流程和系统。 我们开始将 Kafka 视为一个流式处理平台:一个允许您发布和订阅数据流、存储它们并处理它们的系统,而这正是 Apache Kafka 的构建目的。习惯这种思考数据的方式可能与你习惯的方式略有不同,但事实证明,它是构建应用程序和架构的一个非常强大的抽象。Kafka 经常被拿来与现有的几个技术类别进行比较:企业消息传递系统、大数据系统(如 Hadoop)以及数据集成或 ETL 工具。这些比较中的每一个都有一定的道理,但也有些不足。 Kafka 就像一个消息传递系统,它允许您发布和订阅消息流。这样,它类似于 ActiveMQ、RabbitMQ、IBM 的 MQSeries 和其他产品等产品。但即使有这些相似之处,Kafka 与传统消息传递系统也有许多核心差异,这使它完全是另一种动物。这里有三个很大的区别:首先,它作为一个现代分布式系统工作,作为一个集群运行,可以扩展以处理即使是最大型公司的所有应用程序。这让您拥有一个可以弹性扩展以处理公司所有数据流的中央平台,而不是运行数十个单独的消息传递代理,手动连接到不同的应用程序。其次,Kafka 是一个真正的存储系统,可以随心所欲地存储数据。这在将其用作连接层方面具有巨大的优势,因为它提供了真正的交付保证——它的数据是复制的、持久的,并且可以随心所欲地保留。最后,流处理领域显著提高了抽象级别。消息传递系统大多只是分发消息。借助 Kafka 中的流处理功能,您可以使用更少的代码从流中动态计算派生流和数据集。这些差异使 Kafka 本身就足够了,以至于将其视为“又一个队列”是没有意义的。 关于Kafka的另一种观点,也是我们设计和构建Kafka的动机之一,是将其视为Hadoop的一种实时版本。Hadoop 允许您以非常大规模的方式存储和定期处理文件数据。Kafka 允许您存储和持续处理数据流,也可以大规模存储和处理。在技术层面上,肯定有相似之处,许多人将流处理的新兴领域视为人们使用Hadoop及其各种处理层所做的批处理的超集。这种比较忽略了连续、低延迟处理所开启的用例与批处理系统自然产生的用例完全不同。虽然Hadoop和大数据以分析应用程序为目标,通常在数据仓库领域,但Kafka的低延迟特性使其适用于直接为业务提供动力的核心应用程序。这是有道理的:企业中的事件一直在发生,并且能够在事件发生时对它们做出反应,从而更容易构建直接为企业运营提供动力的服务,反馈到客户体验中,等等。
第一章 遇见Kafka
每个企业都由数据驱动。我们接收信息,分析它,操纵它,并创造更多的输出。每个应用程序都会创建数据,无论是日志消息、指标、用户活动、传出消息还是其他内容。每个字节的数据都有一个故事要讲,一些重要的东西将为接下来要做的事情提供信息。为了知道那是什么,我们需要将数据从创建位置获取到可以分析的位置。我们每天都在亚马逊等网站上看到这种情况,我们对感兴趣的商品的点击会转化为稍后向我们展示的推荐。
我们做得越快,我们的组织就越敏捷,响应速度就越快。我们在移动数据上花费的精力越少,我们就越能专注于手头的核心业务。这就是为什么管道是数据驱动型企业中的关键组件。我们如何移动数据变得几乎与数据本身一样重要。
每当科学家不同意时,都是因为我们没有足够的数据。然后,我们可以就获取什么样的数据达成一致;我们获取数据;数据解决了问题。要么我是对的,要么你是对的,要么我们都错了。我们继续前进。
—Neil deGrasse Tys
1 发布和订阅消息Publish/Subscribe Message
在讨论Apache Kafka 的细节之前,我们有必要了解发布/订阅消息传递的概念以及它的重要性。发布/订阅消息传递是一种模式,其特征是一段数据(消息)的发送者(发布者)不专门将其定向到接收者。相反,发布者以某种方式对消息进行分类,并且接收者(订阅者)订阅以接收某些类别的消息。发布/订阅系统通常有一个代理,一个发布消息的中心点,以促进这一点。
1.1 How It Starts
发布/订阅的许多用例都是以相同的方式开始的:使用简单的消息队列或进程间通信通道。例如,您创建一个需要在某处发送监视信息的应用程序,因此您将应用程序与在仪表板上显示指标的应用的直接连接写入其中,并通过该连接推送指标,如图 1-1 所示.
Figure 1-1. A single, direct metrics publisher
这是一个简单问题的简单解决方案,在您开始监视时有效。不久之后,您决定要长期分析指标,但这在仪表板中效果不佳。您启动一个新服务,该服务可以接收指标、存储指标并对其进行分析。为了支持这一点,您可以修改应用程序以将指标写入两个系统。到现在为止,您又有三个正在生成指标的应用程序,它们都与这两个服务建立相同的连接。您的同事认为对服务进行主动轮询以发出警报也是一个好主意,因此您可以在每个应用程序上添加一个服务器,以根据请求提供指标。一段时间后,您就会有更多的应用程序使用这些服务器来获取单个指标并将其用于各种目的。此体系结构可能看起来很像图 1-2,但连接更难跟踪。
Figure 1-2. Many metrics publishers, using direct connection
这里积累的技术债务是显而易见的,所以你决定偿还其中的一部分。您可以设置一个应用程序,该应用程序从所有应用程序接收指标,并提供一个服务器来查询这些指标,以便为需要它们的任何系统查询这些指标。这将体系结构的复杂性降低到类似于图 1-3 的水平。恭喜你,你已经构建了一个发布-订阅消息传递系统!

Figure 1-3. A metrics publish/subscribe system
1.2 个人队列系统
在你用指标发动这场战争的同时,你的一位同事也在用日志消息做类似的工作。另一个公司一直致力于跟踪前端网站上的用户行为,并将这些信息提供给从事机器学习的开发人员,并创建一些报告以供管理。你们都遵循了类似的路径,即构建系统,将信息的发布者与该信息的订阅者分离。图 1-4 显示了这样一个基础结构,其中包含三个独立的发布/订阅系统。

Figure 1-4. Multiple publish/subscribe systems
这当然比使用点对点连接(如图 1-2 所示)要好得多,但存在大量重复。您的公司正在维护多个用于对数据进行排队的系统,所有这些系统都有其各自的错误和限制。您还知道,即将推出更多消息传递用例。您想要的是一个单一的集中式系统,允许发布通用类型的数据,这些数据将随着您的业务增长而增长.
2 进入Kafka(Enter Kafka)
Apache Kafka 是一个发布/订阅消息传递系统,旨在解决这个问题。它通常被描述为“分布式提交日志”,或者最近被描述为“分布式流媒体平台”。文件系统或数据库提交日志旨在提供所有事务的持久记录,以便可以重放它们以一致地构建系统状态。同样,Kafka 中的数据是持久、有序地存储的,并且可以确定性地读取。此外,数据可以在系统内分发,以提供针对故障的额外保护,以及扩展性能的重要机会。
2.1 消息和批处理
Kafka 中的数据单位称为消息。如果你从数据库背景接近 Kafka,你可以把它看作是类似于一行或一条记录。就 Kafka 而言,消息只是一个字节数组,因此其中包含的数据对 Kafka 没有特定的格式或含义。消息可以有一个可选的元数据位,称为密钥。密钥也是一个字节数组,与消息一样,对 Kafka 没有特定的含义。当以更可控的方式将消息写入分区时,将使用密钥。最简单的此类方案是生成密钥的一致哈希值,然后通过获取哈希模的结果(主题中的分区总数)来选择该消息的分区号。这可确保具有相同密钥的消息始终写入同一分区。第 3 章将更详细地讨论密钥。
为了提高效率,消息会批量写入 Kafka。批处理只是消息的集合,所有这些消息都生成到同一个主题和分区。每条消息在网络上的单独往返将导致过多的开销,将消息收集到一个批处理中可减少这种情况。当然,这是延迟和吞吐量之间的权衡:批处理越大,每单位时间可以处理的消息就越多,但传播单个消息所需的时间就越长。批处理通常也会被压缩,以牺牲一些处理能力为代价提供更高效的数据传输和存储。
2.2 模式
虽然消息是 Kafka 本身的不透明字节数组,但建议对消息内容施加额外的结构或模式,以便易于理解。有许多选项可用于消息架构,具体取决于应用程序的个性化需求。Javascript 对象表示法 (JSON) 和可扩展标记语言 (XML) 等简单系统易于使用且易于阅读。但是,它们缺少可靠的类型处理和架构版本之间的兼容性等功能。许多 Kafka 开发人员倾向于使用 Apache Avro,这是一个最初为 Hadoop 开发的序列化框架。Avro 提供紧凑的序列化格式;与消息有效负载分开且不需要在更改时生成代码的架构;以及强大的数据类型和模式演进,具有向后和向前兼容性。
一致的数据格式在 Kafka 中很重要,因为它允许将写入和读取消息解耦。当这些任务紧密耦合时,必须更新订阅消息的应用程序,以便与旧格式并行处理新数据格式。只有这样,才能更新发布消息的应用程序以利用新格式。通过使用定义良好的模式并将它们存储在一个公共存储库中,可以在没有协调的情况下理解 Kafka 中的消息。第 3 章更详细地介绍了模式和序列化。
2.3 主题和分区
Kafka 中的消息分为多个主题。主题最接近的类比是数据库表或文件系统中的文件夹。此外,主题还细分为多个分区。回到“提交日志”描述,分区是单个日志。消息以仅追加的方式写入其中,并按从头到尾的顺序读取。请注意,由于一个主题通常具有多个分区,因此无法保证整个主题中的消息时间顺序,仅在单个分区内。图 1-5 显示了一个具有四个分区的主题,每个分区的末尾都附加了写入。分区也是 Kafka 提供冗余和可伸缩性的方式。每个分区可以托管在不同的服务器上,这意味着单个主题可以在多个服务器上水平扩展,以提供远远超出单个服务器能力的性能。
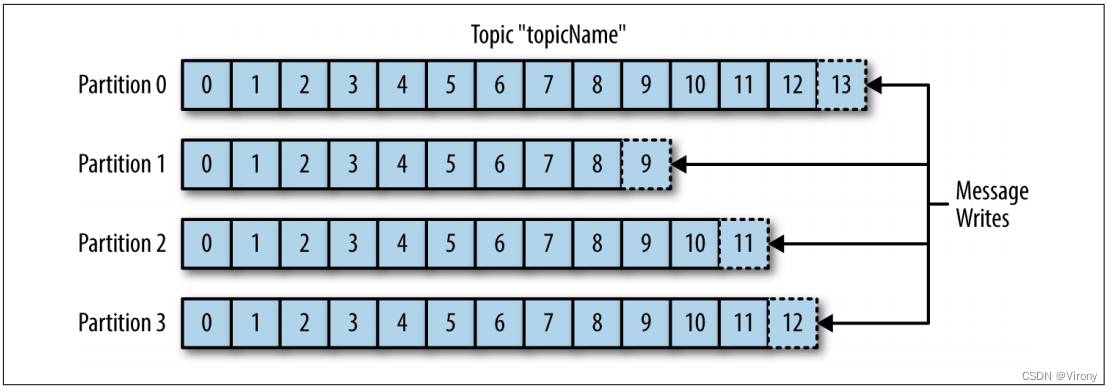
图1-5 具有多个分区的主题的表示形式
在讨论 Kafka 等系统中的数据时,经常使用术语 stream。大多数情况下,无论分区数如何,流都被视为单个数据主题。这表示从生产者到使用者的单一数据流。在讨论流处理时,这种引用消息的方式最为常见,即框架(其中一些是 Kafka Streams、Apache Samza 和 Storm)实时对消息进行操作。这种操作方法可以与离线框架(即 Hadoop)设计为在以后处理批量数据的方式进行比较。第11章提供了流处理的概述。
2.4 生产者和消费者
Kafka 客户端是系统的用户,有两种基本类型:生产者和消费者。还有用于数据集成的高级客户端 API、Kafka Connect API 和用于流处理的 Kafka Streams。高级客户端使用生产者和使用者作为构建块,并在其上提供更高级别的功能。
生产者创建新消息。在其他发布/订阅系统中,这些可能被称为发布者或编写者。通常,将生成针对特定主题的消息。默认情况下,生产者不关心特定消息写入哪个分区,而是将消息均匀地平衡到主题的所有分区。在某些情况下,生产者会将消息定向到特定分区。这通常是使用消息键和分区程序完成的,分区程序将生成密钥的哈希值并将其映射到特定分区。这确保了使用给定密钥生成的所有消息都将写入同一分区。生产者还可以使用遵循其他业务规则的自定义分区程序将消息映射到分区。第3章更详细地介绍了生产者。
消费者阅读消息。在其他发布/订阅系统中,这些客户端可能称为订阅者或读取器。使用者订阅一个或多个主题,并按照消息的生成顺序读取消息。使用者通过跟踪消息的偏移量来跟踪它已经使用了哪些消息。偏移量是 Kafka 在生成每条消息时添加到每条消息的另一位元数据(一个不断增加的整数值)。给定分区中的每条消息都有一个唯一的偏移量。通过将每个分区的最后消耗消息的偏移量存储在 Zookeeper 或 Kafka 本身中,使用者可以在不丢失其位置的情况下停止和重新启动。
消费者是消费者组的一部分,消费者组是一个或多个共同消费主题的消费者。该组确保每个分区仅由一个成员使用。在图 1-6 中,单个组中有三个使用者使用一个主题。其中两个使用者分别从一个分区工作,而第三个使用者从两个分区工作。使用者到分区的映射通常称为使用者对分区的所有权。
这样,消费者可以横向扩展以消费具有大量消息的主题。此外,如果单个使用者发生故障,组的其余成员将重新平衡正在使用的分区,以接管缺少的成员。第 4 章将更详细地讨论消费者和消费者群体。

图1-6 从主题中读取的消费者组
2.5 代理和集群
单个 Kafka 服务器称为代理。代理从生产者接收消息,为它们分配偏移量,并将消息提交到磁盘上的存储。它还为使用者提供服务,响应分区的提取请求,并使用已提交到磁盘的消息进行响应。根据特定的硬件及其性能特征,单个代理可以轻松处理数千个分区和每秒数百万条消息。
Kafka 代理被设计为作为集群的一部分运行。在代理集群中,一个代理还将充当集群控制器(从集群的活动成员中自动选出)。控制器负责管理操作,包括将分区分配给代理和监视代理故障。分区由集群中的单个代理拥有,该代理称为分区的领导者。一个分区可能会分配给多个代理,这将导致该分区被复制(如图 1-7 所示)。这提供了分区中消息的冗余,以便在代理发生故障时,另一个代理可以接管领导权。但是,在该分区上运行的所有使用者和生产者都必须连接到领导者。第 6 章详细介绍了群集操作,包括分区复制。

Apache Kafka 的一个关键特性是保留,即在一段时间内持久存储消息。Kafka 代理配置了主题的默认保留设置,可以将消息保留一段时间(例如 7 天),或者直到主题达到特定大小(以字节为单位)(例如 1 GB)。达到这些限制后,邮件将过期并删除,以便保留配置是随时可用的最小数据量。还可以使用自己的保留设置来配置各个主题,以便仅存储消息,只要它们有用。例如,跟踪主题可能会保留几天,而应用程序指标可能只保留几个小时。主题也可以配置为日志压缩,这意味着 Kafka 将只保留使用特定键生成的最后一条消息。这对于更改日志类型的数据很有用,其中只有上次更新才有意义。
2.6 多集群
随着 Kafka 部署的增长,拥有多个集群通常是有利的。这有几个原因可能有用:
-
数据类型的隔离
-
隔离满足安全要求
-
多个数据中心(灾难恢复)
特别是在使用多个数据中心时,通常需要在它们之间复制消息。这样,在线应用程序就可以访问两个站点上的用户活动。例如,如果用户更改了其配置文件中的公共信息,则无论搜索结果显示在哪个数据中心,该更改都需要可见。或者,可以将监控数据从多个站点收集到托管分析和警报系统的单个中心位置。Kafka 集群中的复制机制设计为仅在单个集群内工作,而不是在多个集群之间工作。 Kafka 项目包括一个名为 MirrorMaker 的工具,用于此目的。从本质上讲,MirrorMaker 只是一个 Kafka 消费者和生产者,通过队列链接在一起。消息从一个 Kafka 集群使用,并为另一个 Kafka 集群生成。图 1-8 显示了使用 MirrorMaker 的体系结构示例,该体系结构将来自两个本地群集的消息聚合到一个聚合群集中,然后将该群集复制到其他数据中心。该应用程序的简单性掩盖了它在创建复杂数据管道方面的能力,这将在第 7 章中进一步详细介绍。
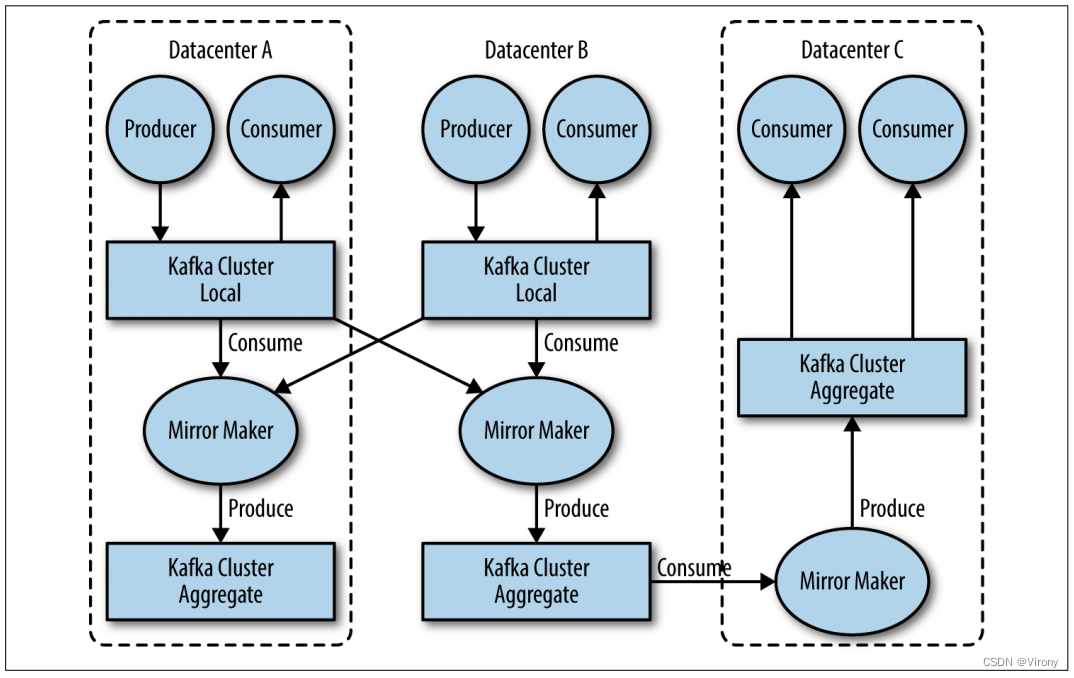
图 1-8 多数据中心结构
3 为什么是kafka?(Why Kafka?)
发布/订阅消息传递系统有很多选择,那么是什么让 Apache Kafka 成为一个不错的选择呢?
3.1 多生产者
Kafka 能够无缝地处理多个生产者,无论这些客户端使用多个主题还是同一个主题。这使得该系统非常适合聚合来自许多前端系统的数据并使其保持一致。例如,通过多个微服务向用户提供内容的网站可以具有单个页面视图主题,所有服务都可以使用通用格式写入该主题。然后,使用者应用程序可以接收网站上所有应用程序的单个页面视图流,而无需协调来自多个主题的使用,每个主题一个主题。
3.2 多消费者
除了多个生产者之外,Kafka 还设计用于多个使用者读取任何单个消息流而不会相互干扰。这与许多队列系统形成鲜明对比,在许多队列系统中,一旦消息被一个客户端使用,任何其他客户端就无法使用它。多个 Kafka 使用者可以选择作为组的一部分运行并共享流,从而确保整个组只处理一次给定的消息。
3.4 基于磁盘的保留
Kafka 不仅可以处理多个使用者,而且持久的消息保留意味着使用者并不总是需要实时工作。邮件将提交到磁盘,并将使用可配置的保留规则进行存储。这些选项可以按主题进行选择,从而允许不同的消息流具有不同的保留量,具体取决于使用者的需求。持久保留意味着,如果消费者因处理速度慢或流量激增而落后,则不会有丢失数据的危险。这也意味着可以对使用者执行维护,使应用程序在短时间内脱机,而不必担心消息在生产者上备份或丢失。消费者可以停止,消息将保留在 Kafka 中。这使他们能够重新启动并从中断的地方继续处理消息,而不会丢失数据。
3.5 可伸缩
Kafka 灵活的可扩展性使其可以轻松处理任何数量的数据。用户可以从单个代理开始作为概念验证,扩展到由三个代理组成的小型开发集群,然后使用包含数十甚至数百个代理的更大集群进入生产环境,随着数据规模的扩大,该集群会随着时间的推移而增长。可以在集群联机时执行扩展,而不会影响整个系统的可用性。这也意味着由多个代理组成的集群可以处理单个代理的故障,并继续为客户端提供服务。对于需要容忍更多同时故障的群集,可以配置更高的复制因子。第 6 章将更详细地讨论复制。
3.6 高性能
所有这些功能结合在一起,使 Apache Kafka 成为在高负载下具有出色性能的发布/订阅消息传递系统。生产者、使用者和代理都可以横向扩展,以便轻松处理非常大的消息流。这可以在完成此操作的同时,仍然提供从生成消息到向使用者提供的亚秒级消息延迟。
4 数据生态系统(The Data Ecosystem)
许多应用程序都参与到我们为数据处理而构建的环境中。我们以应用程序的形式定义了输入,这些应用程序创建数据或以其他方式将其引入系统。我们以指标、报告和其他数据产品的形式定义了输出。我们创建循环,一些组件从系统中读取数据,使用来自其他来源的数据对其进行转换,然后将其引入数据基础架构以在其他地方使用。这是针对多种类型的数据完成的,每种类型的数据都具有独特的内容、大小和使用质量。
Apache Kafka 为数据生态系统提供了循环系统,如图 1-9 所示。它在基础结构的各个成员之间传输消息,为所有客户端提供一致的接口。当与提供消息模式的系统结合使用时,生产者和使用者不再需要任何类型的紧密耦合或直接连接。随着业务案例的创建和解散,可以添加和删除组件,生产者无需担心谁在使用数据或使用应用程序的数量。
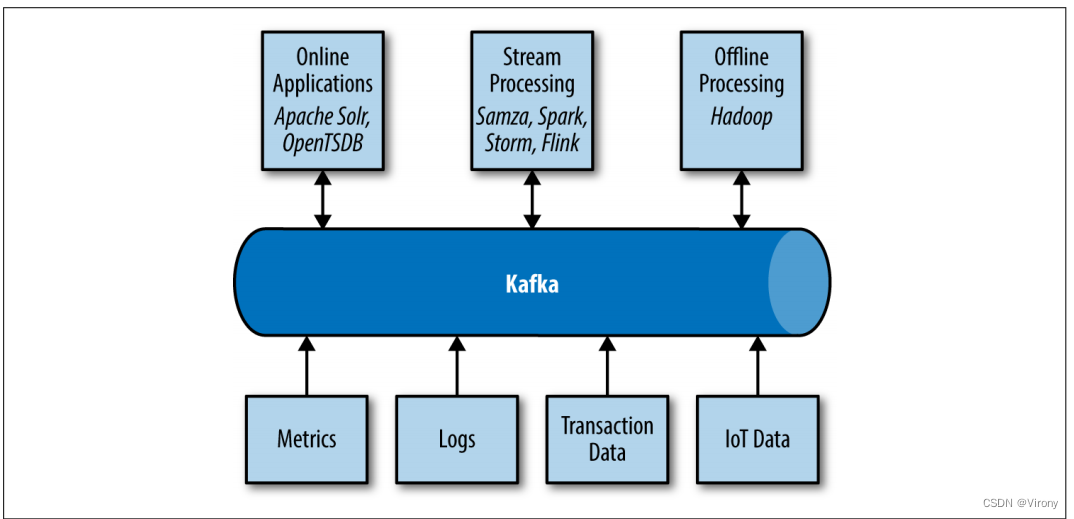
图1-9 大数据生态系统
4.1 用例
4.1.1 活动跟踪
Kafka的原始用例,正如它在LinkedIn上设计的那样,是用户活动跟踪。网站的用户与前端应用程序交互,前端应用程序会生成有关用户正在执行的操作的消息。这可以是被动信息,例如页面浏览量和点击跟踪,也可以是更复杂的操作,例如用户添加到其配置文件中的信息。这些消息将发布到一个或多个主题,然后由后端的应用程序使用。这些应用程序可能会生成报告、提供机器学习系统、更新搜索结果或执行提供丰富用户体验所需的其他操作。
4.1.2 消息
Kafka 还用于消息传递,其中应用程序需要向用户发送通知(例如电子邮件)。这些应用程序可以生成消息,而无需担心消息的格式或实际发送方式。然后,单个应用程序可以读取要发送的所有消息并一致地处理它们,包括: • 使用通用外观设置消息格式(也称为装饰) • 将多条消息收集到要发送的单个通知中 • 应用用户对接收消息方式的首选项 为此,使用单个应用程序可以避免在多个应用程序中复制功能的需要,并允许进行聚合等操作,否则这是不可能的。
4.1.3 指标和日志记录
Kafka 也是收集应用程序和系统指标和日志的理想选择。在这个用例中,让多个应用程序生成相同类型的消息的能力大放异彩。应用程序会定期将指标发布到 Kafka 主题,这些指标可供系统用于监控和告警。它们还可以在Hadoop等离线系统中使用,以执行长期分析,例如增长预测。日志消息可以以相同的方式发布,并且可以路由到专用的日志搜索系统,如 Elastisearch 或安全分析应用程序。Kafka 的另一个额外好处是,当目标系统需要更改时(例如,需要更新日志存储系统),无需更改前端应用程序或聚合方式。
4.1.4 提交日志
由于 Kafka 基于提交日志的概念,因此可以将数据库更改发布到 Kafka,并且应用程序可以轻松监控此流以在发生实时更新时接收实时更新。此更改日志流还可用于将数据库更新复制到远程系统,或将来自多个应用程序的更改合并到单个数据库视图中。持久保留在这里对于为更改日志提供缓冲区非常有用,这意味着在使用应用程序发生故障时可以重播它。或者,日志压缩主题可用于通过仅保留每个键的单个更改来提供更长的保留期。
4.1.5 流处理
另一个提供多种类型应用程序的领域是流处理。虽然几乎所有 Kafka 的使用都可以被认为是流处理,但该术语通常用于指代在 Hadoop 中提供类似功能以映射/减少处理的应用程序。Hadoop通常依赖于长时间(数小时或数天)的数据聚合。流处理对数据进行实时操作,与生成消息一样快。流框架允许用户编写小型应用程序来操作 Kafka 消息,执行诸如计数指标、对消息进行分区以供其他应用程序高效处理或使用来自多个源的数据转换消息等任务。第 11 章介绍了流处理。
5 Kakfa的起源(Kafka’s Origin)
Kafka 的创建是为了解决 LinkedIn 的数据管道问题。它旨在提供一个高性能的消息传递系统,该系统可以处理多种类型的数据,并实时提供有关用户活动和系统指标的干净、结构化的数据。 数据确实为我们所做的一切提供了动力。 ——Jeff Weiner,LinkedIn 首席执行官
5.1 LinkedIn的问题
与本章开头描述的示例类似,LinkedIn 有一个用于收集系统和应用程序指标的系统,该系统使用自定义收集器和开源工具在内部存储和呈现数据。除了 CPU 使用率和应用程序性能等传统指标外,还有一个复杂的指标请求跟踪功能,该功能使用监视系统,可以自省单个用户请求如何通过内部应用程序传播。然而,监控系统存在许多故障。这包括基于轮询的指标收集、指标之间的较大间隔,以及应用程序所有者无法管理自己的指标。该系统是高接触的,大多数简单的任务都需要人工干预,并且不一致,不同系统中同一测量的指标名称不同。
同时,创建了一个用于跟踪用户活动信息的系统。这是一个 HTTP 服务,前端服务器将定期连接到该服务,并将一批消息(XML 格式)发布到 HTTP 服务。然后,这些批处理被移至脱机处理,这是解析和整理文件的位置。这个系统有很多缺陷。XML 格式不一致,解析它的计算成本很高。更改跟踪的用户活动类型需要在前端和离线处理之间进行大量协调工作。即便如此,系统也会因架构的变化而不断中断。跟踪建立在每小时批处理的基础上,因此无法实时使用。
监视和用户活动跟踪不能使用相同的后端服务。监控服务过于笨拙,数据格式不适合活动跟踪,用于监控的轮询模型与用于跟踪的推送模型不兼容。同时,跟踪服务过于脆弱,无法用于指标,而面向批处理的处理也不是实时监控和警报的正确模型。但是,监视和跟踪数据具有许多共同特征,并且信息的相关性(例如特定类型的用户活动如何影响应用程序性能)是非常可取的。特定类型的用户活动的下降可能表明为其提供服务的应用程序存在问题,但处理活动批处理的延迟数小时意味着对这些类型问题的响应缓慢。
首先,对现有的现成开源解决方案进行了彻底调查,以找到一种新系统,该系统将提供对数据的实时访问,并横向扩展以处理所需的消息流量。原型系统是使用 ActiveMQ 建立的,但当时它无法处理规模。对于LinkedIn使用它的方式来说,这也是一个脆弱的解决方案,在ActiveMQ中发现了许多缺陷,这些缺陷会导致经纪人暂停。这将备份与客户端的连接,并干扰应用程序向用户提供请求的能力。我们决定继续为数据管道使用自定义基础结构。
5.2 Kafka的诞生
LinkedIn的开发团队由首席软件工程师Jay Kreps领导,他之前负责分布式键值存储系统Voldemort的开发和开源发布。最初的团队还包括 Neha Narkhede 和后来的 Jun Rao。他们共同着手创建一个消息传递系统,该系统可以满足监视和跟踪系统的需求,并为未来进行扩展。主要目标是:
• 使用推挽模型将生产者和消费者解耦
• 在消息传递系统中为消息数据提供持久性,以允许多个使用者
• 针对消息的高吞吐量进行优化
• 允许系统的水平扩展随着数据流的增长而增长
结果是一个发布/订阅消息传递系统,它有一个典型的消息传递系统接口,但存储层更像是一个日志聚合系统。结合采用 Apache Avro 进行消息序列化,Kafka 可以有效地处理每天数十亿条消息的指标和用户活动跟踪。Kafka 的可扩展性帮助 LinkedIn 的使用量增长超过 1 万亿条消息(截至 2015 年 8 月),每天消耗超过 1 PB 的数据。
5.3 开源
Kafka 于 2010 年底在 GitHub 上作为开源项目发布。随着它开始在开源社区中受到关注,它于 2011 年 7 月被提议并被接受为 Apache 软件基金会孵化器项目。Apache Kafka 于 2012 年 10 月从孵化器毕业。从那时起,它一直在不断工作,并在LinkedIn之外找到了一个强大的贡献者和提交者社区。Kafka 现在被用于世界上一些最大的数据管道中。2014 年秋天,Jay Kreps、Neha Narkhede 和 Jun Rao 离开了 LinkedIn,创立了 Confluent,这是一家专注于为 Apache Kafka 提供开发、企业支持和培训的公司。这两家公司,以及开源社区中其他公司不断增长的贡献,继续开发和维护 Kafka,使其成为大数据管道的首选。
5.4 名称
人们经常问 Kafka 是如何得名的,以及它是否与应用程序本身有关。杰伊·克雷普斯(Jay Kreps)提出了以下见解: 我认为,既然 Kafka 是一个针对写作而优化的系统,那么使用作家的名字是有意义的。我在大学里上过很多点亮的课,喜欢弗朗茨·卡夫卡。另外,对于一个开源项目来说,这个名字听起来很酷。 所以基本上没有太多的关系。
6 开始kafka(Getting Started with Kafka)
现在我们已经了解了 Kafka 及其历史,我们可以设置它并构建我们自己的数据管道。在下一章中,我们将探讨如何安装和配置 Kafka。 我们还将介绍选择运行 Kafka 的正确硬件,以及在迁移到生产操作时要记住的一些事项。
第二章 安装Kafka
本章介绍如何开始使用 Apache Kafka 代理,包括如何设置 Apache Zookeeper,Kafka 使用它来存储代理的元数据。本章还将介绍 Kafka 部署的基本配置选项,以及选择运行代理的正确硬件的标准。最后,我们将介绍如何将多个 Kafka 代理作为单个集群的一部分安装,以及在生产环境中使用 Kafka 时的一些具体问题.
1 First Things First
2 代理配置(Broker Configuration)
Kafka 发行版提供的示例配置足以运行独立服务器作为概念证明,但对于大多数安装来说还不够。Kafka 有许多配置选项,可以控制设置和调整的所有方面。许多选项可以保留为默认设置,因为它们涉及 Kafka 代理的调优方面,除非您有特定的用例要使用,并且需要调整这些设置的特定用例.
2.1 常用代理
在单个服务器上为独立代理以外的任何环境部署 Kafka 时,应检查多个代理配置。这些参数处理代理的基本配置,并且必须更改其中的大多数参数才能在与其他代理的集群中正常运行。
2.1.1 broker.id
每个 Kafka 代理都必须有一个整数标识符,该标识符是使用 broker.id 配置设置的。默认情况下,此整数设置为 0,但可以是任何值。最重要的是,整数在单个 Kafka 集群中必须是唯一的。此数字的选择是任意的,如果需要,可以在代理之间移动以执行维护任务。一个好的准则是将此值设置为主机固有的值,以便在执行维护时,将代理 ID 号映射到主机就不费力了。例如,如果主机名包含唯一编号(如 host1.example.com、host2.example.com 等),则对于 broker.id 值来说,这是一个不错的选择。
2.1.2 port
示例配置文件在 TCP 端口 9092 上使用侦听器启动 Kafka。可以通过更改端口配置参数将其设置为任何可用端口。请记住,如果选择低于 1024 的端口,则必须以 root 身份启动 Kafka。不建议以 root 身份运行 Kafka。
2.1.3 zookeeper.connect
用于存储代理元数据的 Zookeeper 的位置是使用 zookeeper.connect 配置参数设置的。示例配置使用在本地主机上的端口 2181 上运行的 Zookeeper,该端口指定为 localhost:2181。此参数的格式是以分号分隔的 hostname:port/path 字符串列表,其中包括: • hostname,Zookeeper 服务器的主机名或 IP 地址。 • 端口,服务器的客户端端口号。 • /path,一个可选的 Zookeeper 路径,用作 Kafka 集群的 chroot 环境。如果省略,则使用根路径。 如果指定了 chroot 路径且不存在,那么它将在启动时在代理中创建。
2.1.4 log.dirs
Kafka 将所有消息持久化到磁盘,这些日志段存储在 log.dirs 配置中指定的目录中。这是本地系统上以逗号分隔的路径列表。如果指定了多个路径,那么代理将以“最少使用”的方式将分区存储在这些路径上,并将一个分区的日志段存储在同一个路径中。请注意,在以下情况下,代理会将一个新分区放置在当前存储的分区数最少的路径中,而不是使用的最少磁盘空间量:
-
num.recovery.threads.per.data.dir
Kafka 使用可配置的线程池来处理日志段。目前,此线程池用于: • 正常启动时,打开每个分区的日志段 • 在发生故障后启动时,检查并截断每个分区的日志段 • 关闭时,要干净地关闭日志段 默认情况下,每个日志目录仅使用一个线程。由于这些线程仅在启动和关闭期间使用,因此设置更多线程以并行化操作是合理的。具体来说,当从不干净的关闭中恢复时,这可能意味着在重新启动具有大量分区的代理时相差几个小时!设置此参数时,请记住,配置的数字是使用 log.dirs 指定的每个日志目录。这意味着,如果 num.recovery.threads.per.data.dir 设置为 8,并且在 log.dirs 中指定了 3 个路径,则总共有 24 个线程。
2.1.6 auto.create.topics.enable
默认的 Kafka 配置指定在以下情况下,代理应自动创建主题: • 当制作者开始向主题写入消息时 • 当消费者开始阅读来自主题的消息时 • 当任何客户端请求主题的元数据时 在许多情况下,这可能是不希望的行为,特别是因为无法通过 Kafka 协议验证主题的存在而不导致它被创建。如果要显式管理主题创建(无论是手动还是通过预配系统),则可以将 auto.create.topics.enable 配置设置为 false。
2.2 默认主题
Kafka 服务器配置为创建的主题指定了许多默认配置。其中几个参数(包括分区计数和消息保留)可以使用管理工具(在第 9 章中介绍)按主题进行设置。服务器配置中的默认值应设置为适用于群集中大多数主题的基线值.
2.2.1 num.partitions
num.partitions 参数确定创建新主题时使用的分区数,主要是在启用自动主题创建(默认设置)时。此参数默认为一个分区。请记住,主题的分区数只能增加,不能减少。这意味着,如果一个主题需要的分区数少于 num.partitions,则需要注意手动创建该主题(在第 9 章中讨论)。 如第 1 章所述,分区是在 Kafka 集群中扩展主题的方式,因此使用分区计数非常重要,该分区计数将在添加代理时平衡整个集群中的消息负载。许多用户的分区计数等于集群中代理数的倍数。这允许分区均匀地分配给代理,代理将均匀地分配消息负载。但是,这不是必需的,因为您还可以通过具有多个主题来平衡消息负载。
2.2.2 log.retention.ms
Kafka 保留消息多长时间的最常见配置是按时间。默认值在配置文件中使用 log.retention.hours 参数指定,并设置为 168 小时或一周。但是,允许使用另外两个参数:log.retention.minutes 和 log.retention.ms。这三者都指定了相同的配置,即可以删除邮件的时间量,但建议使用的参数是 log.retention.ms,因为如果指定了多个单位,则较小的单位大小将优先。这将确保为 log.retention.ms 设置的值始终是使用的值。如果指定了多个单位,则较小的单位大小将优先。
2.2.3 log.retention.bytes
使消息过期的另一种方法是基于保留的消息的总字节数。此值是使用 log.retention.bytes 参数设置的,并且按分区应用。这意味着,如果您有一个包含 8 个分区的主题,并且 log.retention.bytes 设置为 1 GB,则为该主题保留的数据量最多为 8 GB。请注意,所有保留都是针对单个分区执行的,而不是针对主题执行的。这意味着,如果一个主题的分区数被扩展,如果使用 log.retention.bytes,保留期也会增加。
2.2.4 log.segment.bytes
前面提到的日志保留设置对日志段进行操作,而不是对单个消息进行操作。当消息生成到 Kafka 代理时,它们将附加到分区的当前日志段中。一旦日志段达到 log.segment.bytes 参数指定的大小(默认为 1 GB),将关闭该日志段并打开一个新日志段。关闭日志段后,可以考虑将其过期。较小的日志段大小意味着必须更频繁地关闭和分配文件,这会降低磁盘写入的整体效率。
如果主题的生成率较低,则调整日志段的大小可能很重要。例如,如果一个主题每天只接收 100 MB 的消息,并且 log.segment.bytes 设置为默认值,则填充一个段需要 10 天。由于消息在日志段关闭之前不会过期,因此如果 log.retention.ms 设置为 604800000(1 周),则实际上最多会保留 17 天的消息,直到关闭的日志段过期。这是因为,一旦日志段使用当前 10 天的消息关闭,该日志段必须保留 7 天,然后才能根据时间策略过期(因为在段中的最后一条消息过期之前,无法删除该段)。
2.2.5 log.segment.ms
控制何时关闭日志段的另一种方法是使用 log.segment.ms 参数,该参数指定应关闭日志段的时间量。与 log.retention.bytes 和 log.retention.ms 参数一样,log.segment.bytes 和 log.segment.ms 不是互斥属性。Kafka 将在达到大小限制或达到时间限制时关闭日志段,以先到者为准。默认情况下,log.seg ment.ms 没有设置,这导致仅按大小关闭日志段。
2.2.6 message.max.bytes
Kafka 代理限制可生成消息的最大大小,由 message.max.bytes 参数配置,默认为 1000000 或 1 MB。尝试发送大于此值的消息的生产者将收到来自代理的错误,并且该消息将不被接受。与代理上指定的所有字节大小一样,此配置处理压缩的消息大小,这意味着生产者可以发送远大于此值的未压缩消息,前提是它们压缩到配置的消息.max.bytes 大小以下。 增加允许的消息大小会对性能产生明显影响。较大的消息意味着处理网络连接和请求的代理线程将在每个请求上工作更长时间。较大的消息也会增加磁盘写入的大小,这将影响 I/O 吞吐量。
3 Hardware Selection
为 Kafka 代理选择合适的硬件配置与其说是科学,不如说是一门艺术。Kafka 本身对特定的硬件配置没有严格的要求,并且可以在任何系统上运行而不会出现问题。但是,一旦性能成为一个问题,有几个因素会影响整体性能:磁盘吞吐量和容量、内存、网络和 CPU。一旦确定了哪些类型的性能对你的环境最关键,你将能够选择符合你预算的优化硬件配置。
3.1 磁盘吞吐量
生产者客户机的性能将最直接地受到用于存储日志段的代理磁盘的吞吐量的影响。Kafka 消息在生成时必须提交到本地存储,大多数客户端会等到至少一个代理确认消息已提交后,才会考虑发送成功。这意味着更快的磁盘写入将等于更低的生成延迟。
在磁盘吞吐量方面,显而易见的决定是使用传统的旋转硬盘驱动器 (HDD) 还是固态磁盘 (SSD)。SSD 的寻道和访问时间大大缩短,并将提供最佳性能。另一方面,HDD 更经济,每单位提供更多容量。您还可以通过在代理中使用更多 HDD 来提高 HDD 的性能,无论是通过具有多个数据目录,还是在独立磁盘冗余阵列 (RAID) 配置中设置驱动器。其他因素,例如特定的驱动器技术(例如,串行连接存储或串行 ATA)以及驱动器控制器的质量,都会影响吞吐量。
3.2 磁盘容量
容量是存储讨论的另一面。所需的磁盘容量取决于任何时候需要保留的消息数。如果代理预计每天接收 1 TB 的流量,保留期为 7 天,则代理将需要至少 7 TB 的可用存储空间用于日志段。除了希望为流量波动或随时间增长而维护的任何缓冲区外,还应考虑其他文件至少 10% 的开销。
存储容量是调整 Kafka 集群大小和确定何时扩展集群时要考虑的因素之一。集群的总流量可以通过每个主题具有多个分区来平衡,这将允许额外的代理在单个代理上的密度不足以增加可用容量。关于需要多少磁盘容量的决策也将由为群集选择的复制策略来决定(第 6 章将对此进行更详细的讨论)。
3.3 内存
Kafka 消费者的正常操作模式是从分区的末尾读取,消费者被赶上并落后于生产者,如果有的话。在这种情况下,使用者正在读取的消息以最佳方式存储在系统的页面缓存中,因此读取速度比代理必须从磁盘重新读取消息的速度更快。因此,为系统提供更多可用于页面缓存的内存将提高使用者客户端的性能。
Kafka 本身不需要为 Java 虚拟机 (JVM) 配置太多堆内存。即使是每秒处理 X 条消息和每秒 X 兆比特数据速率的代理也可以使用 5 GB 的堆运行。系统内存的其余部分将由页面缓存使用,并且通过允许系统缓存正在使用的日志段,使 Kafka 受益。这是不建议将 Kafka 与任何其他重要应用程序并置在系统上的主要原因,因为它们必须共享页面缓存的使用。这将降低 Kafka 的使用者性能。
3.4 网络
可用的网络吞吐量将指定 Kafka 可以处理的最大流量。这通常是群集大小调整的控制因素,与磁盘存储相结合。由于 Kafka 对多个消费者的支持,入站和出站网络使用之间固有的不平衡,使情况变得复杂。生产者可以每秒为给定主题写入 1 MB,但可以有任意数量的使用者在出站网络使用量上创建乘数。其他操作,如群集复制(在第 6 章中介绍)和镜像(在第 8 章中讨论)也会增加要求。如果网络接口达到饱和,群集复制滞后的情况并不少见,这可能会使群集处于易受攻击的状态。
3.5 CPU
处理能力不如磁盘和内存重要,但会在一定程度上影响代理的整体性能。理想情况下,客户端应压缩消息以优化网络和磁盘使用率。但是,Kafka 代理必须解压缩所有消息批次,以便验证单个消息的校验和并分配偏移量。然后,它需要重新压缩消息批处理,以便将其存储在磁盘上。这就是 Kafka 对处理能力的大部分要求的来源。然而,这不应该是选择硬件的主要因素。
4 Kafka in the Clould
Kafka 的常见安装是在云计算环境中,例如 Amazon Web Services (AWS)。AWS 提供了许多计算实例,每个实例都有不同的 CPU、内存和磁盘组合,因此必须优先考虑 Kafka 的各种性能特征,以便选择要使用的正确实例配置。一个好的起点是所需的数据保留量,其次是生产者所需的性能。如果需要非常低的延迟,则可能需要具有本地 SSD 存储的 I/O 优化实例。否则,临时存储(如 AWS Elastic Block Store)可能就足够了。做出这些决定后,可用的 CPU 和内存选项将适合性能。
实际上,这意味着对于 AWS 来说,m4 或 r3 实例类型都是常见的选择。m4 实例将允许更长的保留期,但磁盘的吞吐量会更低,因为它位于弹性块存储上。使用本地 SSD 驱动器时,r3 实例将具有更好的吞吐量,但这些驱动器将限制可保留的数据量。为了两全其美,有必要升级到 i2 或 d2 实例类型,它们的成本要高得多。
5 Kafka Cluster
单个 Kafka 服务器非常适合本地开发工作或概念验证系统,但将多个代理配置为一个集群具有显著的好处,如图 2-2 所示。最大的好处是能够跨多个服务器扩展负载。紧随其后的是使用复制来防止由于单个系统故障而导致的数据丢失。复制还允许在 Kafka 或底层系统上执行维护工作,同时仍保持客户端的可用性。本节重点介绍如何仅配置 Kafka 集群。第 6 章包含有关数据复制的更多详细信息。

图2-2 一个简单的kafka集群
5.1 多少个代理?
Kafka 集群的适当大小由多个因素决定。要考虑的第一个因素是保留消息需要多少磁盘容量,以及单个代理上有多少可用存储空间。如果集群需要保留 10 TB 的数据,并且单个代理可以存储 2 TB,则最小集群大小为 5 个代理。此外,使用复制将使存储需求至少增加 100%,具体取决于所选的复制因子(参见第 6 章)。这意味着配置了复制的同一集群现在需要包含至少 10 个代理。 另一个要考虑的因素是集群处理请求的能力。例如,网络接口的容量是多少,如果数据有多个使用者,或者流量在数据保留期内不一致(例如,高峰时段的流量突发),它们是否可以处理客户端流量。如果单个代理上的网络接口在高峰期使用到 80% 的容量,并且该数据有两个使用者,则除非有两个代理,否则使用者将无法跟上峰值流量。如果在群集中使用复制,则这是必须考虑的数据的附加使用者。还可能希望横向扩展到集群中的更多代理,以处理由较少的磁盘吞吐量或可用系统内存引起的性能问题.
5.2 代理配置
代理配置中只有两个要求允许多个 Kafka 代理加入单个集群。首先,所有代理必须对 zookeeper.connect 参数具有相同的配置。这指定了群集存储元数据的 Zookeeper 集合和路径。第二个要求是集群中的所有代理都必须具有唯一的 broker.id 参数值。如果两个代理尝试使用相同的 broker.id 加入同一集群,则第二个代理将记录错误并无法启动。运行群集时还使用了其他配置参数,具体来说,就是控制复制的参数,这些参数将在后面的章节中介绍。
5.3 操作系统调优
虽然大多数 Linux 发行版都具有开箱即用的内核调优参数配置,这些配置对于大多数应用程序来说都相当有效,但可以对 Kafka 代理进行一些更改以提高性能。这些主要围绕虚拟内存和网络子系统,以及用于存储日志段的磁盘挂载点的特定问题。这些参数通常在 /etc/sysctl.conf 文件中配置,但您应该参考 Linux 发行版的文档,了解有关如何调整内核配置的具体详细信息。
-
虚拟内存
通常,Linux 虚拟内存系统会自动针对系统的工作负载进行自我调整。我们可以对交换空间的处理方式以及脏内存页进行一些调整,以针对 Kafka 的工作负载进行调整。 与大多数应用程序(特别是那些关注吞吐量的应用程序)一样,最好避免以(几乎)所有成本进行交换。将内存页交换到磁盘所产生的成本将对 Kafka 性能的各个方面产生明显影响。此外,Kafka 大量使用系统页面缓存,如果 VM 系统交换到磁盘,则没有足够的内存分配给页面缓存。 避免交换的一种方法是根本不配置任何交换空间。交换不是必需的,但如果系统上发生灾难性事件,它确实提供了一个安全网。交换可以防止操作系统由于内存不足而突然终止进程。因此,建议将 vm.swappiness 参数设置为一个非常低的值,例如 1。该参数是 VM 子系统使用交换空间而不是从页面缓存中删除页面的可能性的百分比。最好是减小页面缓存的大小而不是交换。
调整内核处理必须刷新到磁盘的脏页的方式也有好处。Kafka 依靠磁盘 I/O 性能为生产者提供良好的响应时间。这也是日志段通常放在快速磁盘上的原因,无论是具有快速响应时间的单个磁盘(例如,SSD)还是具有大量 NVRAM 用于缓存的磁盘子系统(例如,RAID)。结果是,在刷新后台进程开始将脏页写入磁盘之前,可以减少允许的脏页数。这是通过将 =vm.dirty_background_ratio 值设置为低于默认值 10 来实现的。该值是系统内存总量的百分比,在许多情况下,将此值设置为 5 是合适的。但是,此设置不应设置为零,因为这将导致内核不断刷新页面,从而消除内核缓冲磁盘写入以抵御底层设备性能临时峰值的能力。
在内核强制同步操作将其刷新到磁盘之前允许的脏页总数也可以通过更改 vm.dirty_ratio 的值来增加,将其增加到默认值 20 以上(也是系统总内存的百分比)。此设置的可能值范围很广,但 60 到 80 之间是一个合理的数字。此设置确实会带来少量风险,无论是在未刷新的磁盘活动量方面,还是在强制同步刷新时可能导致长时间的 I/O 暂停方面。如果选择了更高的vm.dirty_ratio设置,强烈建议在 Kafka 集群中使用复制来防止系统故障。 在为这些参数选择值时,明智的做法是查看 Kafka 集群在负载下运行时随时间推移的脏页数,无论是在生产环境中还是在模拟环境中。可以通过检查 /proc/vmstat 文件来确定当前的脏页数:
# cat /proc/vmstat | egrep "dirty|writeback"nr_dirty 3875nr_writeback 29nr_writeback_temp 0#
-
磁盘
除了选择磁盘设备硬件以及 RAID 的配置(如果使用)之外,选择用于此磁盘的文件系统可能会对性能产生下一个最大的影响。有许多不同的文件系统可用,但本地文件系统最常见的选择是 EXT4(第四个扩展文件系统)或扩展文件系统 (XFS)。最近,XFS 已成为许多 Linux 发行版的默认文件系统,这是有充分理由的——对于大多数工作负载,它的性能优于 EXT4,并且需要最少的调整。EXT4 可以很好地执行,但它需要使用被认为不太安全的调整参数。这包括将提交间隔设置为比默认值 5 更长的时间,以强制降低刷新频率。EXT4 还引入了块的延迟分配,这在系统故障的情况下带来了更大的数据丢失和文件系统损坏的可能性。XFS 文件系统也使用延迟分配算法,但它通常比 EXT4 使用的算法更安全。XFS 还为 Kafka 的工作负载提供了更好的性能,而无需在文件系统执行的自动调优之外进行调优。在批处理磁盘写入时,它的效率也更高,所有这些因素结合在一起,可提供更好的整体 I/O 吞吐量。 无论为保存日志段的挂载选择哪种文件系统,都建议为挂载点设置 noatime 挂载选项。文件元数据包含三个时间戳:创建时间 (ctime)、上次修改时间 (mtime) 和上次访问时间 (atime)。默认情况下,每次读取文件时都会更新 atime。这将生成大量磁盘写入。atime 属性通常被认为没什么用处,除非应用程序需要知道文件自上次修改以来是否被访问过(在这种情况下,可以使用实时选项)。Kafka 根本不使用 atime,因此禁用它是安全的。在挂载上设置 noatime 将阻止这些时间戳更新发生,但不会影响对 ctime 和 mtime 属性的正确处理。
-
网络
对于任何生成大量网络流量的应用程序来说,调整 Linux 网络堆栈的默认调整都很常见,因为默认情况下不会针对大型高速数据传输调整内核。事实上,Kafka 的建议更改与大多数 Web 服务器和其他网络应用程序的建议更改相同。第一个调整是更改为每个套接字的发送和接收缓冲区分配的默认内存量和最大内存量。这将显著提高大型传输的性能。每个套接字的发送和接收缓冲区默认大小的相关参数是 net.core.wmem_default 和 net.core.rmem_default,这些参数的合理设置为 131072,即 128 KiB。发送和接收缓冲区最大大小的参数为 net.core.wmem_max 和 net.core.rmem_max,合理的设置为 2097152 或 2 MiB。请记住,最大大小并不表示每个套接字都会分配这么多缓冲区空间;如果需要,它只允许这么多。除了套接字设置之外,还必须使用 net.ipv4.tcp_wmem 和 net.ipv4.tcp_rmem 参数分别设置 TCP 套接字的发送和接收缓冲区大小。它们使用三个空格分隔的整数进行设置,这些整数分别指定最小、默认和最大大小。最大大小不能大于使用 net.core.wmem_max 和 net.core.rmem_max为所有套接字指定的值。每个参数的示例设置是“4096 65536 2048000”,即最小 4 KiB、默认值 64 KiB 和最大缓冲区 2 MiB。根据 Kafka 代理的实际工作负载,您可能希望增加最大大小,以允许更大的网络连接缓冲。
还有其他几个网络调整参数可供设置。通过将 net.ipv4.tcp_window_scaling 设置为 1 来启用 TCP 窗口扩展将允许客户端更有效地传输数据,并允许在代理端缓冲该数据。将 net.ipv4.tcp_max_syn_backlog 的值增加到默认值 1024 以上将允许接受更多数量的同时连接。将 net.core.netdev_max_backlog 的值增加到大于默认值 1000 可以帮助突发网络流量,特别是在使用多千兆位网络连接速度时,允许更多数据包排队等待内核处理它们。
6 Production Concerns(生产问题)
一旦您准备好将 Kafka 环境从测试中移出并进入生产操作,还需要考虑一些事情,这将有助于设置可靠的消息传递服务。
6.1 垃圾回收器选项
调整应用程序的 Java 垃圾回收选项一直是一门艺术,需要有关应用程序如何使用内存的详细信息,以及大量的观察和试错。值得庆幸的是,随着 Java 7 和 Garbage First(或 G1)垃圾回收器的引入,这种情况发生了变化。G1 旨在自动适应不同的工作负载,并在应用程序的整个生命周期内为垃圾回收提供一致的暂停时间。它还通过将堆分割成较小的区域,而不是在每次暂停时收集整个堆,从而轻松处理大型堆大小。 G1 在正常操作中以最少的配置完成所有这些工作。G1 有两个配置选项用于调整其性能:
-
MaxGCPauseMillis 此选项指定每个垃圾回收周期的首选暂停时间。它不是固定的最大值 - 如果需要,G1 可以并且将超过此时间。此值默认为 200 毫秒。这意味着 G1 将尝试安排 GC 循环的频率,以及每个循环中收集的区域数,因此每个循环大约需要 200 毫秒。
-
启动HeapOccupancyPercent 此选项指定在 G1 开始收集周期之前可能正在使用的总堆的百分比。默认值为 45。这意味着 G1 在使用 45% 的堆之前不会启动收集周期。这包括新 (Eden) 和旧区域的总使用量。
Kafka 代理在利用堆内存和创建垃圾对象方面相当高效,因此可以将这些选项设置得更低。已发现本节中提供的 GC 优化选项适用于具有 64 GB 内存的服务器,在 5GB 堆中运行 Kafka。对于 MaxGCPauseMillis,此代理可以配置为 20 毫秒的值。InitiatingHeapOccupancyPercent 的值设置为 35,这会导致垃圾回收的运行时间略早于默认值。 Kafka 的启动脚本不使用 G1 收集器,而是默认使用并行的 new 和 confary 标记和清除垃圾回收。通过环境变量可以很容易地进行更改。使用本章前面的 start 命令,按如下方式对其进行修改:
# export JAVA_HOME=/usr/java/jdk1.8.0_51# export KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseG1GC-XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35-XX:+DisableExplicitGC -Djava.awt.headless=true"# /usr/local/kafka/bin/kafka-server-start.sh -daemon/usr/local/kafka/config/server.properties#
6.2 数据中心布局
对于开发系统,Kafka 代理在数据中心内的物理位置并不是一个大问题,因为如果集群在短时间内部分或完全不可用,则不会产生那么严重的影响。然而,在提供生产流量时,停机意味着损失,无论是由于用户服务丢失还是用户所操作的遥测丢失。这时,在 Kafka 集群中配置复制变得至关重要(参见第 6 章),这也是考虑代理在数据中心机架中的物理位置很重要的时候。如果在部署 Kafka 之前没有解决,则可能需要昂贵的维护来移动服务器。 Kafka 代理在将新分区分配给代理时没有机架感知。这意味着它不能考虑到两个代理可能位于同一个物理机架中,或位于同一个可用区中(如果在 AWS 等云服务中运行),因此可以轻松地将分区的所有副本分配给在同一机架中共享相同电源和网络连接的代理。如果该机架发生故障,这些分区将脱机且客户端无法访问。此外,由于不干净的领导人选举,它可能导致额外的恢复数据丢失(第 6 章中对此有更多介绍)。 最佳做法是将集群中的每个 Kafka 代理安装在不同的机架中,或者至少不共享基础设施服务(如电源和网络)的单点故障。这通常意味着至少部署将运行具有双电源连接(到两个不同电路)和双网络交换机(服务器本身具有绑定接口以实现无缝故障转移)的代理的服务器。即使使用双连接,将代理放在完全独立的机架中也有好处。有时,可能需要对需要脱机的机架或机柜执行物理维护(例如移动服务器或重新布线电源连接)。
6.3 在 Zookeeper 上共置应用程序
Kafka 利用 Zookeeper 来存储有关代理、主题和分区的元数据信息。对 Zookeeper 的写入仅在对消费者组成员身份的更改或对 Kafka 集群本身的更改时执行。这个流量是最小的,它并不能证明对单个 Kafka 集群使用专用的 Zookeeper 集合是合理的。事实上,许多部署将对多个 Kafka 集群使用单个 Zookeeper 集合(对每个集群使用 chroot Zookeeper 路径,如本章前面所述)。 但是,在某些配置下,消费者和 Zookeeper 存在问题。使用者可以选择使用 Zookeeper 或 Kafka 进行提交偏移量,还可以配置提交之间的间隔。如果使用者使用 Zookeeper 进行偏移,则每个使用者将每隔一段时间对其使用的每个分区执行一次 Zookeeper 写入。偏移提交的合理间隔为 1 分钟,因为这是使用者组在使用者失败时读取重复消息的时间段。这些提交可能是 Zookeeper 流量的大量,尤其是在具有许多使用者的集群中,需要考虑在内。如果 Zookeeper 集合体无法处理流量,则可能需要使用更长的提交间隔。但是,建议使用最新 Kafka 库的使用者使用 Kafka 进行偏移,从而消除对 Zookeeper 的依赖。 除了对多个 Kafka 集群使用单个集成之外,如果可以避免,不建议与其他应用程序共享集成。Kafka 对 Zookeeper 延迟和超时很敏感,与集合的通信中断将导致代理的行为不可预测。这很容易导致多个代理同时脱机,如果它们失去 Zookeeper 连接,这将导致脱机分区。它还会给集群控制器带来压力,在中断过去很久之后,例如在尝试执行代理的受控关闭时,可能会显示为细微的错误。其他可能因大量使用或操作不当而给 Zookeeper 集成带来压力的应用程序应隔离到它们自己的集成中。
7 总结
在本章中,我们学习了如何启动和运行 Apache Kafka。我们还介绍了为您的经纪商选择合适的硬件,以及在生产环境中进行设置的具体问题。现在,您已经有了一个 Kafka 集群,我们将逐步了解 Kafka 客户端应用程序的基础知识。接下来的两章将介绍如何创建客户端,以便向 Kafka 生成消息(第 3 章),以及再次使用这些消息(第 4 章)
第三章 Kafka 生产者:向 Kafka 写入消息
无论您将 Kafka 用作队列、消息总线还是数据存储平台,您都将始终通过编写将数据写入 Kafka 的生产者、从 Kafka 读取数据的使用者或充当这两个角色的应用程序来使用 Kafka。
例如,在信用卡交易处理系统中,将有一个客户端应用程序,可能是一个在线商店,负责在付款时立即将每笔交易发送到 Kafka。另一个应用程序负责立即根据规则引擎检查此事务,并确定该事务是被批准还是被拒绝。然后,可以将批准/拒绝响应写回 Kafka,并将响应传播回发起事务的在线商店。第三个应用程序可以从 Kafka 读取交易和审批状态,并将它们存储在数据库中,分析师可以在以后查看决策并可能改进规则引擎。
Apache Kafka 附带了内置的客户端 API,开发人员可以在开发与 Kafka 交互的应用程序时使用这些 API。
在本章中,我们将学习如何使用 Kafka 生产器,首先概述其设计和组件。我们将展示如何创建 KafkaProducer 和 ProducerRecord 对象,如何向 Kafka 发送记录,以及如何处理 Kafka 可能返回的错误。然后,我们将回顾用于控制生产者行为的最重要的配置选项。最后,我们将更深入地了解如何使用不同的分区方法和序列化程序,以及如何编写自己的序列化程序和分区程序。
在第 4 章中,我们将研究 Kafka 的消费者客户端和从 Kafka 读取数据。
1. 生产者概览
应用程序可能需要将消息写入 Kafka 的原因有很多:记录用户活动以进行审计或分析、记录指标、存储日志消息、记录来自智能设备的信息、与其他应用程序异步通信、在写入数据库之前缓冲信息等等。
这些不同的用例也意味着不同的要求:是每条消息都至关重要,还是我们可以容忍消息丢失?我们可以不小心复制消息吗?是否有任何严格的延迟或吞吐量要求需要支持?
在我们前面介绍的信用卡交易处理示例中,我们可以看到,永远不要丢失一条消息或重复任何一条消息至关重要。延迟应该很低,但可以容忍高达 500 毫秒的延迟,并且吞吐量应该非常高 - 我们预计每秒处理多达 100 万条消息。 另一个用例可能是存储来自网站的点击信息。在这种情况下,可以容忍一些消息丢失或一些重复项;只要不影响用户体验,延迟就可能很高。换句话说,我们不介意消息到达 Kafka 是否需要几秒钟的时间,只要在用户点击链接后立即加载下一页即可。吞吐量将取决于我们预期的网站活动水平。 不同的要求将影响您使用创建者 API 将消息写入 Kafka 的方式以及您使用的配置。 虽然生产者 API 非常简单,但当我们发送数据时,生产者会进行更多的事情。向 Kafka 发送数据的主要步骤如图 3-1 所示。

图3-1 Kafka 生产者组件的高级概述
我们通过创建一个 ProducerRecord 来开始向 Kafka 生成消息,该记录必须包含我们想要将记录发送到的主题和一个值。或者,我们还可以指定键和/或分区。发送 ProducerRecord 后,生产者要做的第一件事就是将键和值对象序列化为 ByteArrays,以便它们可以通过网络发送。
接下来,将数据发送到分区程序。如果我们在 ProducerRecord 中指定了一个分区,则分区程序不会执行任何操作,而只是返回我们指定的分区。如果我们没有这样做,分区程序将为我们选择一个分区,通常基于 ProducerRecord 键。选择分区后,创建者就知道记录将转到哪个主题和分区。然后,它将记录添加到一批记录中,这些记录也将发送到同一主题和分区。一个单独的线程负责将这些批次的记录发送到相应的 Kafka 代理。
当代理收到消息时,它会发回响应。如果消息已成功写入 Kafka,它将返回一个 RecordMetadata 对象,其中包含主题、分区和分区内记录的偏移量。如果代理未能写入消息,它将返回错误。当生产者收到错误时,它可能会再重试发送消息几次,然后放弃并返回错误。
2. 构建 Kafka 生产者
将消息写入 Kafka 的第一步是创建一个生产者对象,其中包含要传递给生产者的属性。Kafka 生产者有三个必需属性:
-
bootstrap.servers
生产者将用于与 Kafka 集群建立初始连接的代理的主机:端口对列表。此列表不需要包含所有代理,因为生产者将在初始连接后获得更多信息。但建议至少包含两个,这样如果一个代理出现故障,生产者仍然可以连接到集群。
-
key.serializer
一个类的名称,该类将用于将我们将生成的记录的密钥序列化到 Kafka。Kafka 代理期望字节数组作为消息的键和值。但是,生产者接口允许使用参数化类型将任何 Java 对象作为键和值发送。这使得代码非常可读,但这也意味着生产者必须知道如何将这些对象转换为字节数组。key.serializer 应设置为实现org.apache.kafka.common.serialization.Serializer 接口的类的名称。生产者将使用此类将键对象序列化为字节数组。Kafka 客户端包包括 ByteArraySerializer(它的作用不大)、StringSerializer 和 IntegerSerializer,因此如果您使用通用类型,则无需实现自己的序列化程序。即使您打算只发送值,也需要设置 key.serializer。
-
value.serializer
一个类的名称,该类将用于将我们将生成的记录的值序列化为 Kafka。将 key.serializer 设置为将消息键对象序列化为字节数组的类的名称,将 value.serializer 设置为将序列化消息值对象的类。
以下代码片段演示如何通过仅设置必需参数并对其他所有内容使用默认值来创建新的生产者:
private Properties kafkaProps = new Properties(); (1)kafkaProps.put("bootstrap.servers", "broker1:9092,broker2:9092");kafkaProps.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); (2)kafkaProps.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");producer = new KafkaProducer<String, String>(kafkaProps) (3)
(1) 我们从 Properties 对象开始。
(2) 由于我们计划使用字符串作为消息键和值,因此我们使用内置的 StringSerializer。
(3) 在这里,我们通过设置适当的键和值类型并传递 Properties 对象来创建一个新的生产者。
通过如此简单的界面,很明显,对生产者行为的大部分控制都是通过设置正确的配置属性来完成的。Apache Kafka 文档涵盖了所有配置选项,我们将在本章后面介绍重要的选项。
一旦我们实例化了一个生产者,就该开始发送消息了。发送消息的主要方法有三种:
-
即发即弃(Fire-and-forget)
我们向服务器发送消息,并不真正关心它是否成功到达。大多数情况下,它会成功到达,因为 Kafka 是高可用性的,生产者将自动重试发送消息。但是,使用此方法,某些消息会丢失。
-
同步发送(Synchronous send)
我们发送一条消息,send() 方法返回一个 Future 对象,我们使用 get() 等待 future 并查看 send() 是否成功。
-
异步发送(Asynchronous send)
我们使用回调函数调用 send() 方法,当它收到来自 Kafka 代理的响应时会触发该函数。
在下面的示例中,我们将了解如何使用这些方法发送消息,以及如何处理可能发生的不同类型的错误。
虽然本章中的所有示例都是单线程的,但多个线程可以使用一个生产者对象来发送消息。您可能希望从一个生产者和一个线程开始。如果需要更高的吞吐量,可以添加更多使用同一生产者的线程。一旦这不再增加吞吐量,您可以向应用程序添加更多生产者以实现更高的吞吐量。
3. 向 Kafka 发送消息
发送消息的最简单方法如下:
ProducerRecord<String, String> record =new ProducerRecord<>("CustomerCountry", "Precision Products","France"); (1)try {producer.send(record); (2)} catch (Exception e) {e.printStackTrace(); (3)}
(1)生产者接受 ProducerRecord 对象,因此我们首先创建一个对象。ProducerRecord 有多个构造函数,我们将在后面讨论。在这里,我们使用一个需要我们向其发送数据的主题的名称(始终是一个字符串)以及我们发送到 Kafka 的键和值(在本例中也是字符串)。键和值的类型必须与序列化程序和创建者对象匹配。
(2)我们使用生产者对象 send() 方法来发送 ProducerRecord。正如我们在图 3-1 的创建者体系结构图中看到的那样,消息将放置在缓冲区中,并将在单独的线程中发送到代理。send() 方法返回一个带有 RecordMetadata 的 Java Future 对象,但由于我们只是忽略了返回的值,因此我们无法知道消息是否成功发送。当以静默方式丢弃消息是可以接受的时,可以使用这种发送消息的方法。在生产应用程序中,情况通常并非如此。
3.1 同步发送消息
同步发送消息的最简单方法如下:
ProducerRecord<String, String> record =new ProducerRecord<>("CustomerCountry", "Precision Products", "France");try {producer.send(record).get(); (1)} catch (Exception e) {e.printStackTrace(); (2)}
(1) 在这里,我们使用 Future.get() 来等待 Kafka 的回复。如果记录未成功发送到 Kafka,此方法将引发异常。如果没有错误,我们将得到一个 RecordMetadata 对象,我们可以使用它来检索消息写入到的偏移量。
(2) 如果在向 Kafka 发送数据之前出现任何错误,在发送时,如果 Kafka 代理返回了不可重试的异常,或者我们用尽了可用的重试次数,我们将遇到异常。在这种情况下,我们只打印我们遇到的任何异常。
KafkaProducer 有两种类型的错误。可重试的错误是可以通过再次发送消息来解决的错误。例如,可以解决连接错误,因为可能会重新建立连接。当为分区选择新的领导者时,可以解决“无领导者”错误。KafkaProducer 可以配置为自动重试这些错误,因此仅当重试次数用尽且错误未解决时,应用程序代码才会获得可重试的异常。重试无法解决某些错误。例如,“邮件大小过大”。在这些情况下,KafkaProducer 不会尝试重试,而是会立即返回异常。
3.2 异步发送消息
假设我们的应用程序和 Kafka 集群之间的网络往返时间为 10 毫秒。如果我们在发送每条消息后等待回复,发送 100 条消息大约需要 1 秒。另一方面,如果我们只是发送所有消息而不等待任何回复,那么发送 100 条消息几乎不需要任何时间。在大多数情况下,我们真的不需要回复 - Kafka 在写入记录后发回记录的主题、分区和偏移量,而发送应用程序通常不需要这样做。另一方面,我们确实需要知道何时未能完全发送消息,以便我们可以抛出异常、记录错误,或者将消息写入“错误”文件以供以后分析。
为了异步发送消息并仍然处理错误场景,生产者支持在发送记录时添加回调。以下是我们如何使用回调的示例:
private class DemoProducerCallback implements Callback { (1)@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if (e != null) {e.printStackTrace(); (2)}}}ProducerRecord<String, String> record =new ProducerRecord<>("CustomerCountry", "Biomedical Materials", "USA"); (3)producer.send(record, new DemoProducerCallback()); (4)
(1)要使用回调,您需要一个实现 org.apache.kafka 的类。clients.producer.Callback 接口,该接口具有单个函数 onCompletion()
(2)如果 Kafka 返回错误,则 onCompletion() 将出现非 null 异常。这里我们通过打印来“处理”它,但生产代码可能会有更健壮的错误处理功能。
(3)记录与以前相同。
(4)记录与以前相同。
(5)我们在发送记录时传递一个 Callback 对象。
4.配置生产者
到目前为止,我们看到的生产者的配置参数很少,只有必需的 bootstrap.servers、URI 和序列化程序。 生产者有大量的配置参数;大多数都记录在 Apache Kafka 文档中,并且许多具有合理的默认值,因此没有理由修改每个参数。但是,某些参数对生产者的内存使用、性能和可靠性有重大影响。我们将在这里回顾这些内容。
-
acks acks 参数控制在生产者认为写入成功之前必须接收记录的分区副本数。此选项对邮件丢失的可能性有重大影响。acks 参数有三个允许的值:
-
如果 acks=0,则生产者不会等待代理的回复,然后假设消息已成功发送。这意味着,如果出现问题并且经纪人没有收到消息,生产者将不知道它,并且消息将丢失。但是,由于生产者不等待来自服务器的任何响应,因此它可以以网络支持的速度发送消息,因此此设置可用于实现非常高的吞吐量。
-
如果 acks=1,则生产者将在主副本收到消息的那一刻收到来自代理的成功响应。如果无法将消息写入领导者(例如,如果领导者崩溃并且尚未选出新的领导者),则生产者将收到错误响应,并可以重试发送消息,从而避免潜在的数据丢失。如果领导者崩溃,并且没有此消息的副本被选为新的领导者(通过不干净的领导者选举),则消息仍可能丢失。在这种情况下,吞吐量取决于我们是同步发送消息还是异步发送消息。如果我们的客户端代码等待来自服务器的回复(通过调用发送消息时返回的 Future 对象的 get() 方法),它显然会显着增加延迟(至少通过网络往返)。如果客户端使用回调,则延迟将被隐藏,但吞吐量将受到正在进行的消息数量的限制(即,在从服务器接收回复之前,生产者将发送多少条消息)。
-
如果 acks=all,则一旦所有同步副本都收到消息,生产者将收到来自代理的成功响应。这是最安全的模式,因为您可以确保多个代理拥有该消息,并且即使在崩溃的情况下,该消息也会继续存在(第 5 章中有关此内容的更多信息)。但是,我们在 acks=1 案例中讨论的延迟会更高,因为我们将等待多个代理接收消息。
-
-
buffer.memoery
这将设置生产者将用于缓冲等待发送到代理的消息的内存量。如果应用程序发送消息的速度快于传递到服务器的速度,则生产者可能会耗尽空间,并且根据 block.on.buffer.full 参数(在版本 0.9.0.0 中替换为 max.block.ms),允许阻塞一段时间然后抛出异常,则其他 send() 调用将阻止或抛出异常。
-
compression.type
默认情况下,邮件是以未压缩的方式发送的。此参数可以设置为 snappy、gzip 或 lz4,在这种情况下,在将数据发送到代理之前,将使用相应的压缩算法来压缩数据。Snappy 压缩是由 Google 发明的,旨在提供不错的压缩比、低 CPU 开销和良好的性能,因此建议在性能和带宽都受到关注的情况下使用。Gzip 压缩通常会使用更多的 CPU 和时间,但会产生更好的压缩率,因此建议在网络带宽受到更多限制的情况下进行压缩。通过启用压缩,可以降低网络利用率和存储,这通常是向 Kafka 发送消息时的瓶颈。
-
retries
当生产者从服务器收到错误消息时,该错误可能是暂时的(例如,缺少分区的领导者)。在这种情况下,retries 参数的值将控制生产者在放弃并通知客户端问题之前重试发送消息的次数。默认情况下,生产者将在两次重试之间等待 100 毫秒,但您可以使用 retry.backoff.ms 参数进行控制。我们建议测试从崩溃的代理中恢复所需的时间(即,所有分区获得新领导者的时间),并设置重试次数和它们之间的延迟,以便重试所花费的总时间将长于 Kafka 集群从崩溃中恢复所需的时间,否则, 制片人会过早放弃。并非所有错误都会由生产者重试。有些错误不是暂时性的,不会导致重试(例如,“消息太大”错误)。通常,由于生产者会为您处理重试,因此在您自己的应用程序逻辑中处理重试是没有意义的。您需要将精力集中在处理不可重试的错误或重试尝试已用尽的情况上。
-
batch.size
当多条记录发送到同一分区时,生产者会将它们批处理在一起。此参数控制将用于每个批处理的内存量(以字节为单位,而不是消息数)。当批处理已满时,将发送批处理中的所有消息。但是,这并不意味着生产者将等待批次装满。生产者将发送半满批次,甚至只发送一条消息的批次。因此,将批处理大小设置得太大不会导致发送消息延迟;它只会为批处理使用更多内存。将批大小设置得太小会增加一些开销,因为生产者需要更频繁地发送消息。
-
linger.ms
linger.ms 控制在发送当前批处理之前等待其他消息的时间。KafkaProducer 在当前批次已满或达到 linger.ms 限制时发送一批消息。默认情况下,只要有发送方线程可用于发送消息,生产者就会发送消息,即使批处理中只有一条消息也是如此。通过将 linger.ms 设置为高于 0,我们指示生产者等待几毫秒,在将其他消息发送到代理之前向批处理添加其他消息。这会增加延迟,但也会增加吞吐量(因为我们一次发送更多消息,因此每条消息的开销更少)
-
client.id
这可以是任何字符串,代理将使用它来标识从客户端发送的消息。它用于日志记录和指标,以及配额。
-
max.in.flight.requests.per.connection
这控制了生产者在不收到响应的情况下向服务器发送的消息数。设置此高值可以增加内存使用率,同时提高吞吐量,但设置得太高会降低吞吐量,因为批处理效率会降低。将此值设置为 1 将保证消息将按照发送消息的顺序写入代理,即使发生重试也是如此。
-
timeout.ms, request.timeout.ms, and metadata.fetch.timeout.ms
这些参数控制生产者在发送数据 (request.timeout.ms) 和请求元数据(例如我们正在写入的分区的当前领导者 (metadata.fetch.timeout.ms))时等待服务器回复的时间。如果达到超时而没有回复,生产者将重试发送或以错误(通过异常或发送回调)进行响应。timeout.ms 控制代理等待同步副本确认消息以满足 acks 配置的时间 - 如果时间过去而没有必要的确认,代理将返回错误。
-
max.block.ms
此参数控制生产者在调用 send() 和通过 partitionsFor() 显式请求元数据时将阻塞多长时间。当生成者的发送缓冲区已满或元数据不可用时,这些方法将阻止。当达到 max.block.ms 时,将引发超时异常。
-
max.request.size
此设置控制生产者发送的生产请求的大小。它限制了可以发送的最大消息的大小和生产者可以在一个请求中发送的消息数。例如,如果默认最大请求大小为 1 MB,则您可以发送的最大消息为 1 MB,或者生产者可以将 1,000 条大小为 1 K 的消息批处理到一个请求中。此外,代理对它将接受的最大消息的大小 (message.max.bytes) 有自己的限制。通常最好让这些配置匹配,这样生产者就不会尝试发送被代理拒绝的大小的消息。
-
receive.buffer.bytes and send.buffer.bytes
这些是套接字在写入和读取数据时使用的 TCP 发送和接收缓冲区的大小。如果这些值设置为 -1,则将使用 OS 默认值。当生产者或使用者与不同数据中心的代理通信时,增加这些链接是一个好主意,因为这些网络链接通常具有更高的延迟和更低的带宽。
5. 序列化程序
如前面的示例所示,生产者配置包括强制序列化程序。我们已经了解了如何使用默认的 String 序列化程序。Kafka 还包括整数和 ByteArray 的序列化器,但这并不涵盖大多数用例。最终,您将希望能够序列化更通用的记录。 我们将首先展示如何编写自己的序列化程序,然后介绍Avro序列化程序作为推荐的替代方案。
5.1 自定义序列化程序
当您需要发送到Kafka 的对象不是简单的字符串或整数时,您可以选择使用 Avro、Thrift 或 Protobuf等通用序列化库来创建记录,或者为已使用的对象创建自定义序列化。强烈建议使用泛型序列化库。为了了解序列化程序的工作原理以及为什么使用序列化库是个好主意,让我们看看编写自己的自定义序列化程序需要什么。 假设您不是只记录客户名称,而是创建一个简单的类来表示客户:
public class Customer {private int customerID;private String customerName;public Customer(int ID, String name) {this.customerID = ID;this.customerName = name;}public int getID() {return customerID;}public String getName() {return customerName;}}
现在假设我们要为此类创建一个自定义序列化程序。它看起来像这样:
import org.apache.kafka.common.errors.SerializationException;import java.nio.ByteBuffer;import java.util.Map;public class CustomerSerializer implements Serializer<Customer> {@Overridepublic void configure(Map configs, boolean isKey) {// nothing to configure}@Override/**We are serializing Customer as:4 byte int representing customerId4 byte int representing length of customerName in UTF-8 bytes (0 if name is Null)N bytes representing customerName in UTF-8*/public byte[] serialize(String topic, Customer data) {try {byte[] serializedName;int stringSize;if (data == null)return null;else {if (data.getName() != null) {serializeName = data.getName().getBytes("UTF-8");stringSize = serializedName.length;} else {serializedName = new byte[0];stringSize = 0;}}ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + stringSize);buffer.putInt(data.getID());buffer.putInt(stringSize);buffer.put(serializedName);return buffer.array();} catch (Exception e) {throw new SerializationException("Error when serializing Customer to byte[] " + e);}}@Overridepublic void close() {// nothing to close}}
使用此 CustomerSerializer 配置生产者将允许您定义 ProducerRecord<String、Customer>,并发送 Customer 数据并将 Customer 对象直接传递给生产者。这个例子非常简单,但你可以看到代码是多么脆弱。例如,如果我们有太多的客户,并且需要将 customerID 更改为 Long,或者如果我们决定向 Customer 添加 startDate 字段,那么在维护新旧消息之间的兼容性方面将遇到严重问题。调试不同版本的序列化程序和解串程序之间的兼容性问题相当具有挑战性,需要比较原始字节数组。更糟糕的是,如果同一家公司的多个团队最终将客户数据写入 Kafka,他们都需要使用相同的序列化程序并同时修改代码。
出于这些原因,我们建议使用现有的序列化程序和反序列化程序,例如 JSON、Apache Avro、Thrift 或 Protobuf。在下一节中,我们将介绍 Apache Avro,然后展示如何序列化 Avro 记录并将它们发送到 Kafka。
5.2 使用 Apache Avro 进行序列化
Apache Avro 是一种与语言无关的数据序列化格式。该项目由 Doug Cutting 创建,旨在提供一种与大量受众共享数据文件的方法。
Avro 数据在与语言无关的架构中描述。架构通常以 JSON 描述,序列化通常为二进制文件,但也支持序列化为 JSON。Avro 假定在读取和写入文件时存在架构,通常是通过将架构嵌入到文件本身中。
Avro 最有趣的功能之一,也是它非常适合在 Kafka 等消息传递系统中使用的原因之一是,当写入消息的应用程序切换到新架构时,读取数据的应用程序可以继续处理消息,而无需进行任何更改或更新。 假设原始架构为:
{"namespace": "customerManagement.avro","type": "record","name": "Customer","fields": [{"name": "id", "type": "int"},{"name": "name", "type": "string""},{"name": "faxNumber", "type": ["null", "string"], "default": "null"} (1)]}
(1) id 和 name 字段是必填字段,而传真号码是可选的,默认为 null。
我们使用了这个模式几个月,并以这种格式生成了几TB的数据。现在假设我们决定在新版本中,我们将升级到二十一世纪,并且将不再包含传真号码字段,而是使用电子邮件字段。
新架构为:
{"namespace": "customerManagement.avro","type": "record","name": "Customer","fields": [{"name": "id", "type": "int"},{"name": "name", "type": "string"},{"name": "email", "type": ["null", "string"], "default": "null"}]}
现在,升级到新版本后,旧记录将包含“faxNumber”,新记录将包含“email”。在许多组织中,升级过程缓慢且需要数月时间。因此,我们需要考虑仍然使用传真号码的升级前应用程序和使用电子邮件的升级后应用程序将如何能够处理 Kafka 中的所有事件。
读取应用程序将包含对类似于 getName()、getId() 和 getFaxNumber 的方法的调用。如果遇到使用新模式编写的消息,get Name() 和 getId() 将继续工作,无需修改,但 getFax Number() 将返回 null,因为消息将不包含传真号码。
现在假设我们升级了我们的阅读应用程序,它不再具有 getFax Number() 方法,而是 getEmail()。如果它遇到使用旧模式编写的消息,getEmail() 将返回 null,因为旧消息不包含电子邮件地址。
此示例说明了使用 Avro 的好处:即使我们更改了消息中的架构,但未更改读取数据的所有应用程序,也不会出现异常或中断性错误,也无需对现有数据进行昂贵的更新。
但是,此方案有两个注意事项: • 用于写入数据的架构和读取应用程序预期的架构必须兼容。Avro 文档包含兼容性规则。 • 反序列化程序将需要访问写入数据时使用的架构,即使它与访问数据的应用程序预期的架构不同。在 Avro 文件中,写入架构包含在文件本身中,但对于 Kafka 消息,有一种更好的方法来处理这个问题。我们接下来会看看。
5.3 将 Avro Records 与 Kafka 配合使用
与 Avro 文件不同,在 Avro 文件中存储整个架构与相当合理的开销相关联,将整个架构存储在每条记录中通常会使记录大小增加一倍以上。但是,Avro 在读取记录时仍要求存在整个架构,因此我们需要将架构定位到其他位置。为了实现这一点,我们遵循一个通用的架构模式,并使用一个架构注册表。Schema Registry 不是 Apache Kafka 的一部分,但有几个开源选项可供选择。在此示例中,我们将使用 Confluent 架构注册表。您可以在 GitHub 上找到架构注册表代码,也可以将其作为 Confluent Platform 的一部分进行安装。如果您决定使用架构注册表,那么我们建议您查看文档。 这个想法是将用于将数据写入 Kafka 的所有模式存储在注册表中。然后,我们只需将模式的标识符存储在我们生成给 Kafka 的记录中。然后,使用者可以使用标识符将记录从架构注册表中提取出来,并反序列化数据。关键是所有这些工作(将架构存储在注册表中并在需要时将其拉出)都是在序列化程序和反序列化程序中完成的。向 Kafka 生成数据的代码只是使用 Avro 序列化程序,就像使用任何其他序列化程序一样。图 3-2 演示了此过程。

图3-2 Avro 记录序列化和反序列化的流程图
下面是如何向 Kafka 生成生成的 Avro 对象的示例(有关如何在 Avro 中使用代码生成,请参阅 Avro 文档):
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer","io.confluent.kafka.serializers.KafkaAvroSerializer");props.put("value.serializer","io.confluent.kafka.serializers.KafkaAvroSerializer"); (1)props.put("schema.registry.url", schemaUrl); (2)String topic = "customerContacts";int wait = 500;Producer<String, Customer> producer = new KafkaProducer<String,Customer>(props); (3)// We keep producing new events until someone ctrl-cwhile (true) {Customer customer = CustomerGenerator.getNext();System.out.println("Generated customer " +customer.toString());ProducerRecord<String, Customer> record =new ProducerRecord<>(topic, customer.getId(), cus•tomer); (4)producer.send(record); (5)}
(1)我们使用 KafkaAvroSerializer 通过 Avro 序列化我们的对象。请注意,AvroSerializer 也可以处理原语,这就是为什么我们以后可以使用 String 作为记录键,而使用 Customer 对象作为值。
(2)schema.registry.url 是一个新参数。这仅指向我们存储架构的位置。
(3)客户是我们生成的对象。我们告诉生产者,我们的记录将包含 Customer 作为值。
(4)我们还实例化 ProducerRecord,将 Customer 作为值类型,并在创建新记录时传递 Customer 对象。
(5)就是这样。我们将记录与 Customer 对象一起发送,KafkaAvroSerializer 将处理其余的工作。
如果更喜欢使用泛型 Avro 对象而不是生成的 Avro 对象,该怎么办?不用担心。在这种情况下,您只需要提供架构:
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer","io.confluent.kafka.serializers.KafkaAvroSerializer"); (1)props.put("value.serializer","io.confluent.kafka.serializers.KafkaAvroSerializer");props.put("schema.registry.url", url); (2)String schemaString = "{\"namespace\": \"customerManagement.avro\", \"type\": \"record\", " + (3)"\"name\": \"Customer\"," +"\"fields\": [" +"{\"name\": \"id\", \"type\": \"int\"}," +"{\"name\": \"name\", \"type\": \"string\"}," +"{\"name\": \"email\", \"type\": [\"null\",\"string\"], \"default\":\"null\" }" +"]}";Producer<String, GenericRecord> producer =new KafkaProducer<String, GenericRecord>(props); (4)Schema.Parser parser = new Schema.Parser();Schema schema = parser.parse(schemaString);for (int nCustomers = 0; nCustomers < customers; nCustomers++) {String name = "exampleCustomer" + nCustomers;String email = "example " + nCustomers + "@example.com"GenericRecord customer = new GenericData.Record(schema); (5)customer.put("id", nCustomer);customer.put("name", name);customer.put("email", email);ProducerRecord<String, GenericRecord> data =new ProducerRecord<String,GenericRecord>("customerContacts", name, customer);producer.send(data);}}
(1)我们仍然使用相同的 KafkaAvroSerializer。
(2)我们提供同一架构注册表的 URI。
(3)但现在我们还需要提供 Avro 架构,因为它不是由 Avro 生成的对象提供的。
(4)我们的对象类型是 Avro GenericRecord,我们使用架构和要写入的数据对其进行初始化。
(5)然后,ProducerRecord 的值只是一个 GenericRecord,它计算我们的架构和数据。序列化程序将知道如何从此记录中获取架构,将其存储在架构注册表中,并序列化对象数据。
6.分区
在前面的示例中,我们创建的 ProducerRecord 对象包括主题名称、键和值。Kafka 消息是键值对,虽然可以创建仅包含主题和值的 ProducerRecord,但默认情况下键设置为 null,但大多数应用程序都会使用键生成记录。密钥有两个目标:它们是与消息一起存储的附加信息,它们还用于确定将消息写入哪个主题分区。具有相同密钥的所有消息都将转到同一分区。这意味着,如果一个进程只读取主题中分区的子集(第 4 章将详细介绍),则单个键的所有记录都将由同一进程读取。若要创建键值记录,只需创建 ProducerRecord,如下所示:
ProducerRecord<Integer, String> record =new ProducerRecord<>("CustomerCountry", "Laboratory Equipment", "USA");
使用 null 键创建消息时,只需将键省略即可:
ProducerRecord<Integer, String> record =new ProducerRecord<>("CustomerCountry", "USA"); (1)
(1)在这里,键将简单地设置为 null,这可能表示窗体上缺少客户名称。
当键为 null 并使用默认分区程序时,记录将随机发送到主题的可用分区之一。循环算法将用于在分区之间平衡消息。 如果存在密钥并使用默认分区程序,则 Kafka 将对密钥进行哈希处理(使用自己的哈希算法,因此在升级 Java 时哈希值不会更改),并使用结果将消息映射到特定分区。由于始终将键映射到同一分区非常重要,因此我们使用本主题中的所有分区来计算映射,而不仅仅是可用分区。这意味着,如果在向特定分区写入数据时该分区不可用,则可能会出现错误。这是相当罕见的,正如您将在第 6 章讨论 Kafka 的复制和可用性时看到的那样。 只有当主题中的分区数不变时,键到分区的映射才是一致的。因此,只要分区数保持不变,就可以确保,例如,有关用户045189的记录将始终写入分区 34。这允许在从分区读取数据时进行各种优化。但是,当您向主题添加新分区时,这不再得到保证 - 旧记录将保留在分区 34 中,而新记录将写入其他分区。当分区键很重要时,最简单的解决方案是创建具有足够分区的主题(第 2 章包括有关如何确定大量分区的建议),并且永远不要添加分区。
6.1 实施自定义分区策略
到目前为止,我们已经讨论了默认分区程序的特征,这是最常用的特征。但是,Kafka 并不限制您只对分区进行哈希处理,有时有充分的理由以不同的方式对数据进行分区。例如,假设您是一家 B2B 供应商,而您最大的客户是一家生产名为 Bananas 的手持设备的公司。假设您与客户“Banana”有如此多的业务往来,以至于您每天超过10%的交易都是与该客户进行的。如果您使用默认的哈希分区,Banana财务会计软件的记录将被分配到与其他账户相同的分区,导致一个分区大约是其他分区的两倍。这可能会导致服务器空间不足、处理速度变慢等。我们真正想要的是给Banana财务会计软件一个自己的分区,然后使用哈希分区将其余的账户映射到分区。
下面是自定义分区程序的示例:
import org.apache.kafka.clients.producer.Partitioner;import org.apache.kafka.common.Cluster;import org.apache.kafka.common.PartitionInfo;import org.apache.kafka.common.record.InvalidRecordException;import org.apache.kafka.common.utils.Utils;public class BananaPartitioner implements Partitioner {public void configure(Map<String, ?> configs) {} (1)public int partition(String topic, Object key, byte[] keyBytes,Object value, byte[] valueBytes,Cluster cluster) {List<PartitionInfo> partitions =cluster.partitionsForTopic(topic);int numPartitions = partitions.size();if ((keyBytes == null) || (!(key instanceOf String))) (2) throw new InvalidRecordException("We expect all messages to have customer name as key")if (((String) key).equals("Banana"))return numPartitions; // Banana will always go to last partition// Other records will get hashed to the rest of the partitionsreturn (Math.abs(Utils.murmur2(keyBytes)) % (numPartitions - 1))}public void close() {}}
(1) 分区程序接口包括 configure、partition 和 close 方法。在这里,我们只实现了分区,尽管我们确实应该通过配置传递特殊的客户名称,而不是在分区中对其进行硬编码。
(2) 我们只需要 String 键,因此如果不是这种情况,我们会抛出异常。
7.旧生产者 API
在本章中,我们讨论了 Java 创建者客户端,它是 org.apache.kafka.clients 包的一部分。但是,Apache Kafka 仍然有两个用 Scala 编写的旧客户端,它们是 kafka.producer 包和核心 Kafka 模块的一部分。这些生产者称为 SyncProducer(根据 acks 参数的值,它可能会等待服务器在发送其他消息之前确认每条消息或一批消息)和 AsyncProducer(在后台批处理消息,在单独的线程中发送消息,并且不向客户端提供有关成功的反馈)。
由于当前的生产者支持这两种行为,并为开发人员提供了更高的可靠性和控制力,因此我们不会讨论较旧的 API。如果您有兴趣使用它们,请三思而后行,然后参考 Apache Kafka 文档以了解更多信息。
8.总结
本章的开头是一个简单的生产者示例,只需 10 行代码即可将事件发送到 Kafka。我们通过添加错误处理和试验同步和异步生产来增加简单示例。然后,我们探索了最重要的生产者配置参数,并了解了它们如何修改生产者的行为。我们讨论了序列化器,它让我们可以控制写入 Kafka 的事件的格式。我们深入研究了 Avro,这是序列化事件的众多方法之一,但也是 Kafka 非常常用的方法之一。在本章的最后,我们讨论了 Kafka 中的分区,并举例说明了高级自定义分区技术。
现在我们知道了如何将事件写入 Kafka,在第 4 章中,我们将学习有关从 Kafka 使用事件的所有信息.
第四章 Kafka 使用者:从 Kafka 读取数据
需要从 Kafka 读取数据的应用程序使用 KafkaConsumer 订阅 Kafka 主题并接收来自这些主题的消息。从 Kafka 读取数据与从其他消息传递系统读取数据略有不同,并且涉及的独特概念和想法很少。如果不首先了解这些概念,就很难理解如何使用消费者 API。我们将首先解释一些重要概念,然后我们将通过一些示例来展示使用者 API 可用于实现具有不同需求的应用程序的不同方式。
4.1 Kafka 消费者概念
为了了解如何从 Kafka 读取数据,首先需要了解它的消费者和消费者群体。以下各节将介绍这些概念。
4.1.1 消费者和消费者群体
假设您有一个应用程序,需要从 Kafka 主题读取消息,对它们运行一些验证,并将结果写入另一个数据存储。在这种情况下,您的应用程序将创建一个使用者对象,订阅相应的主题,然后开始接收消息、验证消息并写入结果。这可能在一段时间内效果很好,但是如果生产者向主题写入消息的速率超过了应用程序可以验证它们的速率,该怎么办?如果仅限于单个使用者读取和处理数据,则应用程序可能会越来越落后,无法跟上传入消息的速率。显然,有必要从主题中扩大消费规模。就像多个生产者可以写入同一个主题一样,我们需要允许多个消费者从同一个主题中读取数据,并在它们之间拆分数据。
Kafka 使用者通常是使用者组的一部分。当多个消费者订阅一个主题并属于同一个消费组时,该组中的每个消费者都会收到来自该主题中不同分区子集的消息。
让我们以具有四个分区的主题 T1 为例。现在假设我们创建了一个新的消费者 C1,它是组 G1 中唯一的消费者,并使用它来订阅主题 T1。使用者 C1 将从所有四个 t1 分区获取所有消息。请参见图 4-1。
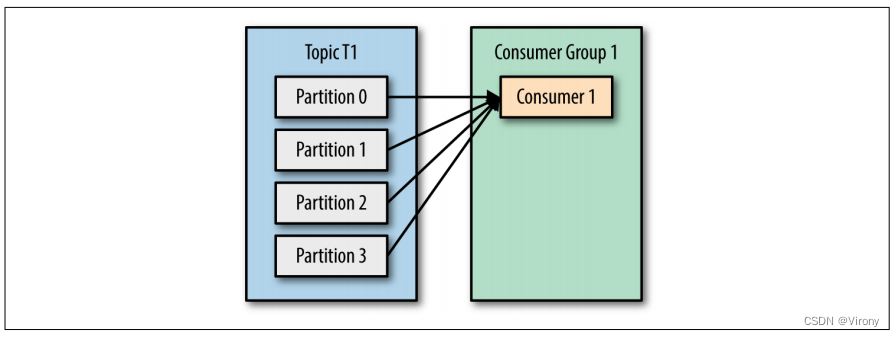
图4-1 一个具有四个分区的消费者组
如果我们将另一个消费者 C2 添加到组 G1,则每个消费者将只能从两个分区获取消息。也许来自分区 0 和 2 的消息会转到 C1,而来自分区 1 和 3 的消息会转到使用者 C2。请参见图 4-2。
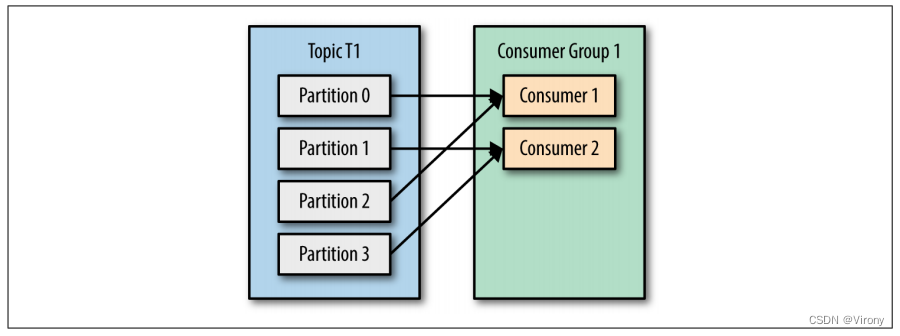
图4-2 四个分区拆分为两个使用者组
如果 G1 有 4 个使用者,则每个使用者都将从单个分区读取消息。请参见图 4-3。
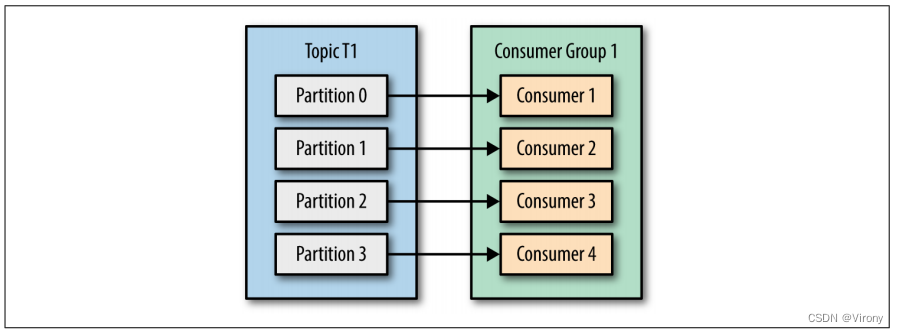
图4-3 四个使用者组,每个使用者组一个分区
如果我们向具有单个主题的单个组添加的消费者多于分区,则某些消费者将处于空闲状态,根本得不到任何消息。请参见图 4-4。

图4-4 消费者组多于分区意味着错过的消息
我们从 Kafka 主题扩展数据使用的主要方法是向使用者组添加更多使用者。Kafka 使用者通常会执行高延迟操作,例如写入数据库或对数据进行耗时的计算。 在这些情况下,单个使用者不可能跟上数据流入主题的速率,通过让每个使用者只拥有分区和消息的子集来添加更多分担负载的使用者是我们的主要扩展方法。这是创建具有大量分区的主题的一个很好的理由 - 它允许在负载增加时添加更多使用者。请记住,在主题中添加的消费者数量超过分区数量是没有意义的,因为某些消费者只是处于空闲状态。第 2 章包括一些关于如何在主题中选择分区数的建议。
除了添加使用者以扩展单个应用程序之外,有多个应用程序需要从同一主题读取数据是很常见的。事实上,Kafka 的主要设计目标之一是使 Kafka 主题生成的数据可用于整个组织的许多用例。在这些情况下,我们希望每个应用程序都能获取所有消息,而不仅仅是一个子集。要确保应用程序获取主题中的所有消息,请确保应用程序具有自己的使用者组。与许多传统的消息传递系统不同,Kafka 可以在不降低性能的情况下扩展到大量使用者和使用者组。
在前面的示例中,如果我们添加一个新的消费者组 G2 和单个消费者,则该消费者将获得主题 T1 中的所有消息,而与 G1 正在执行的操作无关。G2 可以有多个消费者,在这种情况下,它们将获得一个分区的子集,就像我们在 G1 中显示的那样,但 G2 作为一个整体仍将获得所有消息,而不管其他消费者组如何。请参见图 4-5。

图4-5 添加新的使用者组可确保不会丢失任何消息
总而言之,您需要为每个应用程序创建一个新的使用者组,该应用程序需要来自一个或多个主题的所有消息。将使用者添加到现有使用者组以扩展从主题读取和处理消息,因此组中的每个额外使用者将仅获得消息的子集。
4.1.2 使用者组和分区重新平衡
正如我们在上一节中看到的,使用者组中的使用者共享他们订阅的主题中分区的所有权。当我们将新的使用者添加到组中时,它开始使用以前由另一个使用者使用的分区中的消息。当消费者关闭或崩溃时,也会发生同样的事情;它离开该组,它过去使用的分区将由剩余的使用者之一使用。当使用者组正在使用的主题被修改时(例如,如果管理员添加新分区),也会将分区重新分配给使用者。
将分区所有权从一个使用者转移到另一个使用者称为重新平衡。重新平衡很重要,因为它们为消费者组提供了高可用性和可伸缩性(允许我们轻松安全地添加和删除消费者),但在正常事件过程中,它们是相当不可取的。在重新平衡期间,消费者不能使用消息,因此重新平衡基本上是整个消费者组不可用的短暂窗口。此外,当分区从一个使用者移动到另一个使用者时,使用者将失去其当前状态;如果它正在缓存任何数据,它将需要刷新其缓存,从而减慢应用程序的速度,直到使用者再次设置其状态。在本章中,我们将讨论如何安全地处理再平衡以及如何避免不必要的再平衡。
使用者维护使用者组中的成员身份和分配给它们的分区的所有权的方式是将检测信号发送到指定为组协调器的 Kafka 代理(对于不同的使用者组,此代理可能不同)。只要使用者定期发送检测信号,就假定它处于活动状态,并且正在处理来自其分区的消息。当使用者轮询(即检索记录)并提交已使用的记录时,将发送检测信号。
如果使用者停止发送检测信号的时间足够长,则其会话将超时,组协调器将认为它已死并触发重新平衡。如果使用者崩溃并停止处理消息,则组协调器将需要几秒钟的时间(没有心跳)才能确定它已死并触发重新平衡。在这几秒钟内,不会处理来自死使用者拥有的分区的任何消息。当干净地关闭一个消费者时,消费者会通知组协调员它要离开了,组协调员会立即触发再平衡,减少处理中的差距。在本章的后面部分,我们将讨论控制检测信号频率和会话超时的配置选项,以及如何设置这些选项以满足您的要求。
-
最新 Kafka 版本中检测信号行为的更改
在 0.10.1 版本中,Kafka 社区引入了一个单独的心跳线程,该线程也将在轮询之间发送心跳。这允许您将检测信号频率(以及消费者组检测到消费者崩溃且不再发送检测信号所需的时间)与轮询频率(由处理从代理返回的数据所需的时间决定)分开。使用较新版本的 Kafka,您可以配置应用程序在离开组并触发重新平衡之前可以在不轮询的情况下运行多长时间。此配置用于防止实时锁定,即应用程序未崩溃,但由于某种原因无法取得进展。此配置独立于 session.time out.ms,后者控制检测使用者崩溃和停止发送检测信号所需的时间。
本章的其余部分将讨论旧行为的一些挑战,以及程序员如何处理这些挑战。本章讨论如何处理处理记录所需的时间较长的应用程序。这与运行 Apache Kafka 0.10.1 或更高版本的读者不太相关。如果您使用的是新版本,并且需要处理需要更长时间才能处理的记录,则只需调整 max.poll.interval.ms 以便它能够处理轮询新记录之间的更长延迟。
4.2 创建 Kafka 消费者
开始消费记录的第一步是创建一个 KafkaConsumer 实例。创建 KafkaConsumer 与创建 KafkaProducer 非常相似,即使用要传递给使用者的属性创建一个 Java Properties 实例。我们将在本章后面深入讨论所有属性。首先,我们只需要使用三个必需的属性:bootstrap.servers、key.deserializer 和 value.deserializer。
第一个属性 bootstrap.servers 是 Kafka 群集的连接字符串。它的使用方式与 KafkaProducer 中的使用方式完全相同(有关如何定义它的详细信息,您可以参考第 3 章)。另外两个属性 key.deserializer 和 value.deserializer 与为生产者定义的序列化程序类似,但您需要指定可以接受字节数组并将其转换为 Java 对象的类,而不是指定将 Java 对象转换为字节数组的类。
还有第四个属性,它不是严格强制性的,但现在我们将假装它是强制性的。该属性为 group.id,它指定 KafkaConsumer 实例所属的使用者组。虽然可以创建不属于任何消费者组的消费者,但这种情况并不常见,因此在本章的大部分时间里,我们将假设消费者是组的一部分。
以下代码片段演示如何创建 KafkaConsumer:
Properties props = new Properties();props.put("bootstrap.servers", "broker1:9092,broker2:9092");props.put("group.id", "CountryCounter");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
如果你读过关于创建生产者的第 3 章,你在这里看到的大部分内容应该很熟悉。我们假设我们使用的记录将具有 String 对象作为记录的键和值。此处唯一的新属性是 group.id,这是此使用者所属的使用者组的名称。
4.3 订阅主题
创建消费者后,下一步是订阅一个或多个主题。subcribe() 方法将主题列表作为参数,因此使用起来非常简单:
consumer.subscribe(Collections.singletonList("customerCountries"));
(1) 在这里,我们只需创建一个包含单个元素的列表:主题名称 customerCountries。
也可以使用正则表达式调用 subscribe。该表达式可以匹配多个主题名称,如果有人使用匹配的名称创建新主题,则几乎会立即发生重新平衡,消费者将开始从新主题消费。这对于需要从多个主题使用的应用程序非常有用,并且可以处理主题将包含的不同类型的数据。使用正则表达式订阅多个主题最常用于在 Kafka 和其他系统之间复制数据的应用程序。
要订阅所有测试主题,我们可以调用:
consumer.subscribe("test.*");
4.4 轮询循环
使用者 API 的核心是一个简单的循环,用于轮询服务器以获取更多数据。一旦消费者订阅了主题,轮询循环就会处理协调、分区重新平衡、检测信号和数据获取的所有细节,从而为开发人员留下一个干净的 API,该 API 只需从分配的分区返回可用数据。消费者的主体如下所示:
try {while (true) { (1)ConsumerRecords<String, String> records = consumer.poll(100); (2)for (ConsumerRecord<String, String> record : records) (3){log.debug("topic = %s, partition = %s, offset = %d,customer = %s, country = %s\n",record.topic(), record.partition(), record.offset(),record.key(), record.value());int updatedCount = 1;if (custCountryMap.countainsValue(record.value())) {updatedCount = custCountryMap.get(record.value()) + 1;}custCountryMap.put(record.value(), updatedCount)JSONObject json = new JSONObject(custCountryMap);System.out.println(json.toString(4)) (4)}}} finally {consumer.close(); (5)}
(1)这确实是一个无限循环。使用者通常是长时间运行的应用程序,它们会不断轮询 Kafka 以获取更多数据。在本章的后面,我们将展示如何干净利落地退出循环并关闭消费者。
(2)这是本章中最重要的一行。就像鲨鱼必须继续移动或死亡一样,消费者必须继续轮询 Kafka,否则它们将被视为死亡,它们正在消耗的分区将交给组中的另一个消费者继续消费。我们传递的参数 poll() 是一个超时间隔,用于控制 poll() 在消费者缓冲区中没有数据时阻塞多长时间。如果设置为 0,poll() 将立即返回;否则,它将等待指定的毫秒数,以便数据从代理到达。
(3) poll() 返回记录列表。每条记录都包含记录来自的主题和分区、分区内记录的偏移量,当然还有记录的键和值。通常,我们希望循环访问列表并单独处理记录。poll() 方法采用超时参数。这指定了轮询返回所需的时间,无论是否包含数据。该值通常由应用程序对快速响应的需求驱动,即您希望以多快的速度将控制权返回给执行轮询的线程?
(4)处理通常以在数据存储中写入结果或更新存储的记录而告终。在这里,目标是保持每个县的客户的运行计数,因此我们更新了一个哈希表并将结果打印为 JSON。一个更实际的例子是将更新结果存储在数据存储中。
(5)在退出之前,务必关闭消费者()。这将关闭网络连接和套接字。它还将立即触发重新平衡,而不是等待组协调器发现使用者停止发送检测信号并且可能已死亡,这将花费更长的时间,因此会导致使用者无法使用来自分区子集的消息的时间更长。
轮询循环的作用不仅仅是获取数据。第一次使用新使用者调用 poll() 时,它负责查找 GroupCoordinator、加入使用者组并接收分区分配。如果触发了再平衡,它也将在轮询循环中处理。当然,让消费者保持活力的心跳是从投票循环中发送的。出于这个原因,我们试图确保我们在迭代之间所做的任何处理都是快速和高效的。
-
线程安全
不能在一个线程中拥有属于同一组的多个使用者,也不能让多个线程安全地使用同一个使用者。每个线程一个使用者是规则。若要在一个应用程序中运行同一组中的多个使用者,需要在自己的线程中运行每个使用者。将消费者逻辑包装在自己的对象中,然后使用 Java 的 ExecutorService 启动多个线程,每个线程都有自己的消费者,这很有用。Confluent 博客有一个教程,展示了如何做到这一点。
4.5 配置使用者
到目前为止,我们专注于学习消费者 API,但我们只查看了几个配置属性——只有必需的 bootstrap.servers、group.id、key.deserializer 和 value.deserializer。所有使用者配置都记录在 Apache Kafka 文档中。大多数参数具有合理的默认值,不需要修改,但有些参数会影响使用者的性能和可用性。让我们来看看一些更重要的属性。
-
fetch.min.bytes
此属性允许使用者指定在提取记录时希望从代理接收的最小数据量。如果代理收到来自使用者的记录请求,但新记录的字节数少于 min.fetch.bytes,则代理将等到有更多消息可用后再将记录发送回使用者。这减少了使用者和代理的负载,因为在主题没有太多新活动(或一天中的较低活动时间)的情况下,他们必须处理较少的来回消息。如果使用者在可用数据不多时使用过多的 CPU,则需要将此参数设置为高于默认值,或者在有大量使用者时减少代理上的负载。
-
fetch.max.wait.ms
通过设置 fetch.min.bytes,您可以告诉 Kafka 等到它有足够的数据要发送后再响应使用者。fetch.max.wait.ms 可让您控制等待多长时间。默认情况下,Kafka 将等待长达 500 毫秒。这会导致长达 500 毫秒的额外延迟,以防没有足够的数据流向 Kafka 主题来满足要返回的最小数据量。如果要限制潜在的延迟(通常是由于 SLA 控制应用程序的最大延迟),可以将 fetch.max.wait.ms 设置为较低的值。如果将 fetch.max.wait.ms 设置为 100 毫秒,将 fetch.min.bytes 设置为 1 MB,则 Kafka 将收到来自消费者的提取请求,并在有 1 MB 数据返回时或 100 毫秒后(以先发生者为准)响应数据。
-
max.partition.fetch.bytes
此属性控制服务器将返回每个分区的最大字节数。默认值为 1 MB,这意味着当 KafkaConsumer.poll() 返回 ConsumerRecords 时,记录对象将最多使用分配给使用者的每个分区的 max.partition.fetch.bytes。因此,如果一个主题有 20 个分区,而您有 5 个使用者,则每个使用者需要有 4 MB 的内存可用于使用者记录。在实践中,如果组中的其他使用者 fail.max.partition.fetch.bytes 必须大于代理将接受的最大消息(由代理配置中的 max.message.size 属性确定),或者代理可能具有使用者无法使用的消息,则每个使用者将需要处理更多分区,因此您需要分配更多内存。 在这种情况下,消费者将挂起试图阅读它们。设置 max.partition.fetch.bytes 时的另一个重要考虑因素是使用者处理数据所需的时间。正如您所记得的,使用者必须足够频繁地调用 poll(),以避免会话超时和随后的重新平衡。如果单个 poll() 返回的数据量非常大,则使用者可能需要更长的时间来处理,这意味着它将无法及时到达轮询循环的下一次迭代以避免会话超时。如果发生这种情况,两个选项是降低最大 partition.fetch.bytes 或增加会话超时。
-
session.timeout.ms
消费者在仍被视为活着的情况下与经纪人失去联系的时间默认为 3 秒。如果超过 session.timeout.ms 次使用者没有向组协调器发送检测信号,则认为它已死,组协调器将触发使用者组的重新平衡,以将分区从死使用者分配给组中的其他使用者。此属性与 heartbeat.interval.ms 密切相关。heartbeat.interval.ms 控制 KafkaConsumer poll() 方法向组协调器发送检测信号的频率,而 session.timeout.ms 控制使用者可以在多长时间内不发送检测信号。因此,这两个属性通常一起修改,heatbeat.interval.ms 必须低于 session.timeout.ms,并且通常设置为超时值的三分之一。因此,如果 session.timeout.ms 是 3 秒,heartbeat.interval.ms 应该是 1 秒。将 session.timeout.ms 设置为低于默认值将允许使用者组更快地检测故障并从故障中恢复,但也可能导致不必要的重新平衡,因为使用者需要更长的时间来完成轮询循环或垃圾回收。将 session.timeout.ms 设置得更高将减少意外重新平衡的机会,但也意味着需要更长的时间才能检测到真正的故障。
-
auto.offset.reset
此属性控制使用者在开始读取没有提交偏移量的分区时的行为,或者如果它具有的已提交偏移量无效(通常是因为使用者关闭的时间太长,以至于具有该偏移量的记录已经从代理中过期)。默认值为“latest”,这意味着在缺少有效偏移量的情况下,使用者将开始从最新记录(使用者开始运行后写入的记录)读取。另一种选择是“最早”,这意味着缺少有效的偏移量,使用者将从头开始读取分区中的所有数据。
-
enable.auto.commit
在本章前面,我们讨论了提交偏移量的不同选项。此参数控制使用者是否自动提交偏移量,默认值为 true。如果您希望控制何时提交偏移量,请将其设置为 false,这对于最大限度地减少重复项和避免丢失数据是必要的。如果将 enable.auto.commit 设置为 true,则可能还需要控制使用 auto.commit.interval.ms 提交偏移量的频率。
-
partition.assignment.strategy
我们了解到,分区是分配给使用者组中的使用者的。PartitionAssignor 是一个类,它给定使用者和订阅的主题,决定将哪些分区分配给哪个使用者。默认情况下,Kafka 有两种赋值策略:
-
Range
将它订阅的每个主题中的连续分区子集分配给每个使用者。因此,如果使用者 C1 和 C2 订阅了两个主题,即 T1 和 T2,并且每个主题都有三个分区,则将从主题 T1 和 T2 为 C1 分配分区 0 和 1,而 C2 将从这些主题分配分区 2。由于每个主题的分区数不均匀,并且每个主题的分配是独立完成的,因此第一个使用者最终比第二个使用者拥有更多的分区。每当使用范围分配并且使用者数量不会整齐地划分每个主题中的分区数时,就会发生这种情况。
-
RoundRobin
从所有订阅的主题中获取所有分区,并按顺序将它们逐个分配给使用者。如果 C1 和 C2 之前使用循环分配,则 C1 将具有来自主题 T1 的分区 0 和 2 以及来自主题 T2 的分区 1。C2 将具有来自主题 T1 的分区 1 和来自主题 T2 的分区 0 和 2。通常,如果所有使用者都订阅了相同的主题(一种非常常见的情况),则循环分配最终将导致所有使用者具有相同数量的分区(或最多 1 个分区差异)。
partition.assignment.strategy 允许您选择分区分配策略。默认值为 org.apache.kafka.clients.consumer.RangeAssignor,它实现了上述 Range 策略。您可以将其替换为 org.apache.kafka.clients.consumer.RoundRobinAssignor。更高级的选项是实现您自己的赋值策略,在这种情况下,partition.assignment.strategy 应指向您的类的名称。
-
-
client.id
这可以是任何字符串,代理将使用它来标识从客户端发送的消息。它用于日志记录和指标,以及配额。
-
max.poll.records
这控制了对 poll() 的单次调用将返回的最大记录数。这有助于控制应用程序在轮询循环中需要处理的数据量。
-
receive.buffer.bytes and send.buffer.bytes
这些是套接字在写入和读取数据时使用的 TCP 发送和接收缓冲区的大小。如果这些值设置为 -1,则将使用 OS 默认值。当生产者或使用者与不同数据中心的代理通信时,增加这些链接可能是一个好主意,因为这些网络链接通常具有更高的延迟和更低的带宽。
4.6 提交和偏移
每当我们调用 poll() 时,它都会返回写入 Kafka 的记录,而我们组中的消费者尚未读取。这意味着我们有一种方法可以跟踪组的消费者读取了哪些记录。如前所述,Kafka 的一个独特特性是它不像许多 JMS 队列那样跟踪来自消费者的确认。相反,它允许使用者使用 Kafka 来跟踪他们在每个分区中的位置(偏移量)。
我们将更新分区中当前位置的操作称为提交。
使用者如何提交偏移量?它向 Kafka 生成一条消息,发送到一个特殊的 __consumer_offsets 主题,其中包含每个分区的已提交偏移量。只要您的所有消费者都启动、运行并流失,这就不会产生任何影响。但是,如果消费者崩溃或新的消费者加入消费者组,这将触发重新平衡。重新平衡后,可能会为每个使用者分配一组新的分区,而不是之前处理的分区。为了知道从哪里开始工作,使用者将读取每个分区的最新提交偏移量,并从那里继续。
如果提交偏移量小于客户端处理的上一条消息的偏移量,则上次处理的偏移量和提交偏移量之间的消息将被处理两次。请参见图 4-6。

图4-6 重新处理的消息
如果提交偏移量大于客户端实际处理的最后一条消息的偏移量,则使用者组将丢失上次处理的偏移量和提交偏移量之间的所有消息。请参见图 4-7。
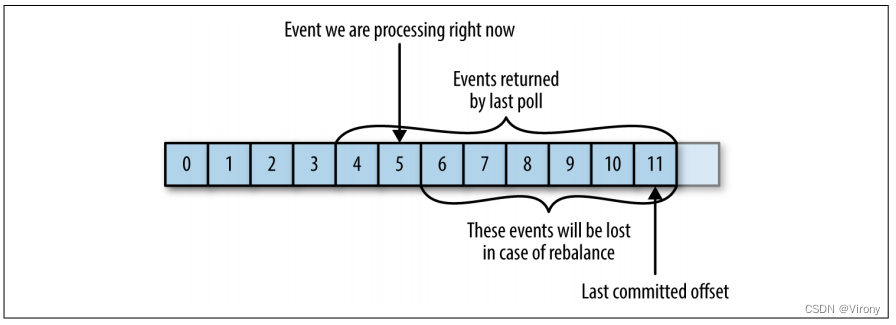
图4-7 偏移量之间的丢失消息
显然,管理偏移量对客户端应用程序有很大影响。KafkaConsumer API 提供了多种提交偏移量的方法:
4.6.1 自动提交
提交偏移量的最简单方法是允许使用者为您执行此操作。如果配置 enable.auto.commit=true,则使用者将每 5 秒提交一次客户端从 poll() 接收到的最大偏移量。五秒间隔是默认间隔,通过设置 auto.commit.interval.ms 进行控制。就像使用者中的其他所有内容一样,自动提交由轮询循环驱动。每当您轮询时,使用者都会检查是否该提交,如果该提交,它将提交上次轮询中返回的偏移量。
但是,在使用这个方便的选项之前,重要的是要了解后果。
请注意,默认情况下,自动提交每 5 秒发生一次。假设我们在最近一次提交后 3 秒,并触发了重新平衡。重新平衡后,所有消费者将从上次承诺的抵消量开始消费。在本例中,偏移量为 3 秒,因此在这 3 秒内到达的所有事件都将被处理两次。可以将提交间隔配置为更频繁地提交并减少复制记录的窗口,但不可能完全消除它们。
启用自动提交后,对轮询的调用将始终提交上一次轮询返回的最后一个偏移量。它不知道实际处理了哪些事件,因此在再次调用 poll() 之前始终处理 poll() 返回的所有事件至关重要。(就像 poll() 一样,close() 也会自动提交偏移量。这通常不是问题,但在处理异常或过早退出轮询循环时要注意。
自动提交很方便,但它们不能为开发人员提供足够的控制权来避免重复消息。
4.6.2 提交当前偏移
大多数开发人员对提交偏移量的时间进行更多控制,既可以消除丢失消息的可能性,也可以减少重新平衡期间重复的消息数。使用者 API 可以选择在对应用程序开发人员有意义的点提交当前偏移量,而不是基于计时器。
通过设置 auto.commit.offset=false,仅当应用程序明确选择这样做时,才会提交偏移量。最简单、最可靠的提交 API 是 commitSync()。此 API 将提交 poll() 返回的最新偏移量,并在提交偏移量后返回,如果由于某种原因提交失败,则抛出异常。
请务必记住,commitSync() 将提交 poll() 返回的最新偏移量,因此请确保在处理完集合中的所有记录后调用 commitSync(),否则可能会丢失如前所述的消息。触发重新平衡时,从最近一批开始到重新平衡的所有消息都将被处理两次。
以下是在处理完最新一批消息后,我们将如何使用 commitSync 提交偏移量:
while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records){System.out.printf("topic = %s, partition = %s, offset =%d, customer = %s, country = %s\n",record.topic(), record.partition(),record.offset(), record.key(), record.value()); (1)}try {consumer.commitSync(); (2)} catch (CommitFailedException e) {log.error("commit failed", e) (3)}}
(1)假设通过打印记录的内容,我们已经完成了对记录的处理。您的应用程序可能会对记录执行更多操作 - 修改记录、扩充记录、聚合记录、在仪表板上显示记录或通知用户重要事件。您应该根据用例确定何时“完成”记录。
(2)完成“处理”当前批处理中的所有记录后,我们调用 commitSync 来提交批处理中的最后一个偏移量,然后再轮询其他消息。
(3)commitSync 会重试提交,只要没有无法恢复的错误。如果发生这种情况,除了记录错误之外,我们无能为力。
4.6.3 异步提交
手动提交的一个缺点是,在代理响应提交请求之前,应用程序将被阻塞。这将限制应用程序的吞吐量。可以通过降低提交频率来提高吞吐量,但随后我们会增加重新平衡将创建的潜在重复项的数量。
另一种选择是异步提交 API。我们无需等待代理响应提交,只需发送请求并继续:
while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records){System.out.printf("topic = %s, partition = %s,offset = %d, customer = %s, country = %s\n",record.topic(), record.partition(), record.offset(),record.key(), record.value());}consumer.commitAsync(); (1)}
(1)提交最后一个偏移量并继续。
缺点是,虽然 commitSync() 将重试提交,直到成功或遇到不可重试的失败,但 commitAsync() 不会重试。它不重试的原因是,当 commitAsync() 收到来自服务器的响应时,可能已经有后来的提交成功了。想象一下,我们发送了一个提交偏移量 2000 的请求。存在暂时的通信问题,因此代理永远不会收到请求,因此从不响应。同时,我们处理了另一批,并成功提交了偏移量 3000。如果 commitA sync() 现在重试以前失败的提交,则在处理并提交偏移量 3000 后,它可能会成功提交偏移量 2000。在重新平衡的情况下,这将导致更多的重复。
我们提到了这种复杂性以及正确提交顺序的重要性,因为 commitAsync() 还为您提供了一个选项,用于传递将在代理响应时触发的回调。通常使用回调来记录提交错误或将其计入指标中,但如果要使用回调进行重试,则需要注意提交顺序的问题:
while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records) {System.out.printf("topic = %s, partition = %s,offset = %d, customer = %s, country = %s\n",record.topic(), record.partition(), record.offset(),record.key(), record.value());}consumer.commitAsync(new OffsetCommitCallback() {public void onComplete(Map<TopicPartition,OffsetAndMetadata> offsets, Exception exception) {if (e != null)log.error("Commit failed for offsets {}", offsets, e);}}); (1)}
(1)我们发送提交并继续,但如果提交失败,则将记录失败和偏移量。
-
Retrying Async Commits
为异步重试获得正确的提交顺序的一个简单模式是使用单调递增的序列号。每次提交时增加序列号,并将提交时的序列号添加到 commitAsync 回调中。当您准备发送重试时,请检查回调获得的提交序列号是否等于实例变量;如果是,则没有更新的提交,重试是安全的。如果实例序列号更高,请不要重试,因为已发送了较新的提交。
4.6.4 结合同步和异步提交
通常,偶尔在不重试的情况下提交失败并不是一个大问题,因为如果问题是暂时的,那么接下来的提交就会成功。但是,如果我们知道这是关闭使用者或重新平衡之前的最后一次提交,我们希望额外确保提交成功。
因此,一种常见的模式是在关机前将 commitAsync() 与 commitSync() 组合在一起。以下是它的工作原理(当我们进入有关再平衡侦听器的部分时,我们将讨论如何在重新平衡之前提交):
try {while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records) {System.out.printf("topic = %s, partition = %s, offset = %d,customer = %s, country = %s\n",record.topic(), record.partition(),record.offset(), record.key(), record.value());}consumer.commitAsync(); (1)}} catch (Exception e) {log.error("Unexpected error", e);} finally {try {consumer.commitSync(); (2)} finally {consumer.close();}}
(1)虽然一切都很好,但我们使用 commitAsync。速度更快,如果一次提交失败,下一次提交将作为重试。
(2)但是,如果我们要关闭,则没有“下一次提交”。我们调用 commitSync(),因为它将重试,直到成功或遭受不可恢复的失败。
4.6.5 提交指定偏移量
提交最新偏移量仅允许您在完成批处理后提交。但是,如果您想更频繁地提交呢?如果 poll() 返回一个巨大的批处理,并且您希望在批处理的中间提交偏移量,以避免在发生重新平衡时必须再次处理所有这些行,该怎么办?您不能只调用 commitSync() 或 commitAsync() — 这将提交返回的最后一个偏移量,您尚未处理该偏移量。
幸运的是,使用者 API 允许您调用 commitSync() 和 commitAsync() 并传递您希望提交的分区和偏移量的映射。如果您正在处理一批记录,并且从主题“customers”中的分区 3 收到的最后一条消息偏移量为 5000,则可以调用 commitSync() 为主题“customers”中的分区 3 提交偏移量 5000。由于使用者可能使用多个分区,因此需要跟踪所有分区的偏移量,这会增加代码的复杂性。
下面是特定偏移量的提交的样子:
private Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>(); (1)int count = 0;....while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records){System.out.printf("topic = %s, partition = %s, offset = %d,customer = %s, country = %s\n",record.topic(), record.partition(), record.offset(),record.key(), record.value()); (2)currentOffsets.put(new TopicPartition(record.topic(),record.partition()), newOffsetAndMetadata(record.offset()+1, "no metadata")); (3)if (count % 1000 == 0) (4)consumer.commitAsync(currentOffsets, null); (5)count++;}}
(1)这是我们将用于手动跟踪偏移量的映射。
(2)请记住,println 是您对使用的记录进行的任何处理的替代。
(3)读取每条记录后,我们使用预期要处理的下一条消息的偏移量更新偏移量映射。这是我们下次开始阅读的地方。
(4)在这里,我们决定每 1,000 条记录提交一次电流偏移量。在应用程序中,您可以根据时间或记录内容提交。
(5)我选择调用commitAsync(),但commitSync()在这里也是完全有效的。当然,在提交特定偏移量时,您仍然需要执行我们在前几节中看到的所有错误处理。
4.7 重新平衡侦听器
正如我们在上一节中提到的关于提交偏移量,使用者希望在退出之前以及分区重新平衡之前做一些清理工作。
如果你知道你的使用者即将失去对分区的所有权,你将需要提交你处理的最后一个事件的偏移量。如果你的使用者维护了一个缓冲区,其中包含它只是偶尔处理的事件(例如,我们在解释 pause() 功能时使用的 currentRecords 映射),你将需要在失去分区所有权之前处理你积累的事件。也许您还需要关闭文件句柄、数据库连接等。
使用者 API 允许您在使用者中添加或删除分区时运行自己的代码。为此,您可以在调用我们之前讨论的 subscribe() 方法时传递 ConsumerRebalanceListener。ConsumerRebalance Listener 有两种方法可以实现:
-
public void onPartitionsRevoked(Collection<TopicPartition> partition
在重新平衡开始之前和使用者停止使用消息之后调用。这是您要提交偏移量的地方,因此下一个获得此分区的人将知道从哪里开始。
-
public void onPartitionsAssigned(Collection<TopicPartition> partition
在将分区重新分配给代理之后,但在使用者开始使用消息之前调用。
此示例将展示如何使用 onPartitionsRevoked() 在失去分区所有权之前提交偏移量。在下一节中,我们将展示一个更复杂的示例,该示例还演示了 onPartitionsAssigned() 的使用:
private Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();private class HandleRebalance implements ConsumerRebalanceListener { (1)public void onPartitionsAssigned(Collection<TopicPartition>partitions) { (2)}public void onPartitionsRevoked(Collection<TopicPartition>partitions) {System.out.println("Lost partitions in rebalance.Committing currentoffsets:" + currentOffsets);consumer.commitSync(currentOffsets); (3)}}try {consumer.subscribe(topics, new HandleRebalance()); (4)while (true) {ConsumerRecords<String, String> records =consumer.poll(100);for (ConsumerRecord<String, String> record : records){System.out.printf("topic = %s, partition = %s, offset = %d,customer = %s, country = %s\n",record.topic(), record.partition(), record.offset(),record.key(), record.value());currentOffsets.put(new TopicPartition(record.topic(),record.partition()), newOffsetAndMetadata(record.offset()+1, "no metadata"));}consumer.commitAsync(currentOffsets, null);}} catch (WakeupException e) {// ignore, we're closing} catch (Exception e) {log.error("Unexpected error", e);} finally {try {consumer.commitSync(currentOffsets);} finally {consumer.close();System.out.println("Closed consumer and we are done");}}
(1)我们首先实现一个 ConsumerRebalanceListener。
(2)在这个例子中,当我们得到一个新分区时,我们不需要做任何事情;我们将开始使用消息。
(3)但是,当我们即将因重新平衡而丢失分区时,我们需要提交偏移量。请注意,我们提交的是已处理的最新偏移量,而不是仍在处理的批处理中的最新偏移量。这是因为当我们仍处于批处理的中间时,分区可能会被撤销。我们正在为所有分区提交偏移量,而不仅仅是我们将要丢失的分区 - 因为偏移量是针对已经处理的事件的,所以这没有什么坏处。 我们使用 commitSync() 来确保在重新平衡进行之前提交偏移量。
(4)最重要的部分:将 ConsumerRebalanceListener 传递给 subscribe() 方法,以便消费者调用它。
4.8 使用具有特定偏移量的记录
到目前为止,我们已经了解了如何使用 poll() 开始使用每个分区中最后一个提交偏移量的消息,并继续按顺序处理所有消息。但是,有时您希望从不同的偏移量开始读取。
如果要从分区的开头开始读取所有消息,或者想要一直跳到分区末尾并开始仅使用新消息,则可以使用专门用于此的 API:seekToBeginning(TopicPartition tp) 和 seekToEnd(TopicPartition tp)。
但是,Kafka API 还允许您查找特定的偏移量。这种能力可以以多种方式使用;例如,要返回几条消息或跳过几条消息(也许落后的时间敏感应用程序会希望跳过到更相关的消息)。此功能最令人兴奋的用例是当偏移量存储在 Kafka 以外的系统中时。
想想这个常见的场景:你的应用程序正在从 Kafka 读取事件(可能是网站中用户的点击流),处理数据(可能删除指示来自自动化程序而不是用户的点击的记录),然后将结果存储在数据库、NoSQL 存储或 Hadoop 中。假设我们真的不想丢失任何数据,也不想在数据库中存储相同的结果两次。
在这些情况下,使用者循环可能如下所示:
while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records){currentOffsets.put(new TopicPartition(record.topic(),record.partition()),record.offset());processRecord(record);storeRecordInDB(record);consumer.commitAsync(currentOffsets);}}
在此示例中,我们非常偏执,因此我们在处理每条记录后提交偏移量。但是,在记录存储在数据库中之后,但在我们提交偏移量之前,我们的应用程序仍有可能崩溃,从而导致再次处理记录并且数据库包含重复项。
如果有一种方法可以将记录和偏移量都存储在一个原子操作中,则可以避免这种情况。要么同时提交记录和偏移量,要么两者都不提交。只要将记录写入数据库,将偏移量写入 Kafka,这是不可能的。
但是,如果我们在一个事务中同时将记录和偏移量写入数据库,那会怎样?然后,我们将知道,要么我们完成了记录并提交了偏移量,要么我们还没有完成,并且将重新处理记录。
现在唯一的问题是,如果记录存储在数据库中而不是 Kafka 中,那么当记录被分配分区时,我们的消费者如何知道从哪里开始读取?这正是 seek() 的用途。当使用者启动或分配新分区时,它可以在数据库中查找偏移量并 seek() 到该位置。
下面是一个框架示例,说明其工作原理。我们使用 ConsumerRebalanceLister 和 seek() 来确保我们从存储在数据库中的偏移量开始处理:
public class SaveOffsetsOnRebalance implementsConsumerRebalanceListener {public void onPartitionsRevoked(Collection<TopicPartition>partitions) {commitDBTransaction(); (1)}public void onPartitionsAssigned(Collection<TopicPartition>partitions) {for(TopicPartition partition: partitions)consumer.seek(partition, getOffsetFromDB(partition)); (2)}}}consumer.subscribe(topics, new SaveOffsetOnRebalance(consumer));consumer.poll(0);for (TopicPartition partition: consumer.assignment())consumer.seek(partition, getOffsetFromDB(partition)); (3)while (true) {ConsumerRecords<String, String> records =consumer.poll(100);for (ConsumerRecord<String, String> record : records){processRecord(record);storeRecordInDB(record);storeOffsetInDB(record.topic(), record.partition(),record.offset()); (4)}commitDBTransaction();}
(1) 我们在这里使用一个虚构的方法在数据库中提交事务。这里的想法是,当我们处理记录时,数据库记录和偏移量将入到数据库中,我们只需要在即将丢失分区时提交事务,以确保这些信息被持久化。
(2) 我们还有一个假想的方法来从数据库中获取偏移量,然后在获得新分区的所有权时,我们寻找()到这些记录。
(3) 当消费者第一次启动时,在我们订阅主题后,我们调用一次 poll() 以确保我们加入一个消费者组并获得分配的分区,然后我们立即在分配给我们的分区中寻找正确的偏移量。请记住,seek() 只更新我们消费的位置,因此下一个 poll() 将获取正确的消息。如果 seek() 中存在错误(例如,偏移量不存在),则 poll() 将抛出异常。
(4) 另一种假想的方法:这次我们更新一个表,在数据库中存储偏移量。在这里,我们假设更新记录很快,因此我们对每条记录进行更新,但提交速度很慢,因此我们仅在批处理结束时提交。但是,这可以通过不同的方式进行优化。
有许多不同的方法可以通过在外部存储中存储偏移量和数据来实现精确一次语义,但所有这些方法都需要使用 ConsumerRebalance Listener 和 seek() 来确保偏移量及时存储,并且使用者从正确的位置开始读取消息。
4.9 但是我们如何退出
在本章的前面,当我们讨论轮询循环时,我告诉过你不要担心消费者在无限循环中轮询的事实,我们将讨论如何干净地退出循环。因此,让我们讨论一下如何干净利落地退出。
当您决定退出轮询循环时,您将需要另一个线程来调用 consumer.wakeup()。如果在主线程中运行使用者循环,则可以从 ShutdownHook 完成此操作。请注意,consumer.wakeup() 是唯一可以安全地从其他线程调用的使用者方法。调用 wakeup 将导致 poll() 退出并显示 WakeupException,或者如果在线程未等待轮询时调用了 consumer.wakeup(),则在下一次迭代调用 poll() 时将抛出异常。不需要处理 WakeupException,但在退出线程之前,必须调用 consumer.close()。如果需要,关闭使用者将提交偏移量,并将向组协调器发送一条消息,表明使用者将离开组。使用者协调器将立即触发重新平衡,您无需等待会话超时,即可将要关闭的使用者的分区分配给组中的另一个使用者。
下面是使用者在主应用程序线程中运行时退出代码的样子。此示例有点截断,但您可以在 http://bit.ly/2u47e9A 查看完整示例。
Runtime.getRuntime().addShutdownHook(new Thread() {public void run() {System.out.println("Starting exit...");consumer.wakeup(); try {mainThread.join();} catch (InterruptedException e) {e.printStackTrace();}}});...try {// looping until ctrl-c, the shutdown hook willcleanup on exitwhile (true) {ConsumerRecords<String, String> records =movingAvg.consumer.poll(1000);System.out.println(System.currentTimeMillis() + "-- waiting for data...");for (ConsumerRecord<String, String> record :records) {System.out.printf("offset = %d, key = %s,value = %s\n",record.offset(), record.key(),record.value());}for (TopicPartition tp: consumer.assignment())System.out.println("Committing offset atposition:" +consumer.position(tp));movingAvg.consumer.commitSync();}} catch (WakeupException e) {// ignore for shutdown } finally {consumer.close(); System.out.println("Closed consumer and we are done");}}
(1) ShutdownHook 在单独的线程中运行,因此我们可以采取的唯一安全操作是调用唤醒以打破轮询循环。
(2) 另一个调用唤醒的线程将导致轮询引发 WakeupException。您需要捕获异常以确保应用程序不会意外退出,但无需对其进行任何操作。
(3) 在退出使用器之前,请确保将其干净地关闭
4.10 解串器
如上一章所述,Kafka 生产者要求序列化程序将对象转换为字节数组,然后将其发送到 Kafka。同样,Kafka 使用者需要反序列化程序将从 Kafka 接收的字节数组转换为 Java 对象。在前面的示例中,我们只是假设每条消息的键和值都是字符串,我们在使用者配置中使用了默认的 StringDeserializer。
在关于 Kafka 生产者的第 3 章中,我们了解了如何序列化自定义类型,以及如何使用 Avro 和 AvroSerializers 从架构定义生成 Avro 对象,然后在向 Kafka 生成消息时序列化它们。现在,我们将了解如何为自己的对象创建自定义反序列化程序,以及如何使用 Avro 及其反序列化程序。
很明显,用于向 Kafka 生成事件的序列化程序必须与使用事件时将使用的反序列化程序匹配。使用 IntSerializer 进行序列化,然后使用 StringDeserializer 进行反序列化不会有好结果。这意味着,作为开发人员,您需要跟踪用于写入的序列化程序每个主题,并确保每个主题仅包含您使用的反序列化程序可以解释的数据。这是使用 Avro 和架构存储库进行序列化和反序列化的好处之一 - AvroSerializer 可以确保写入特定主题的所有数据都与主题的架构兼容,这意味着可以使用匹配的反序列化程序和架构对其进行反序列化。在生产者或使用者端,兼容性方面的任何错误都可以通过适当的错误消息轻松捕获,这意味着您无需尝试调试字节数组的序列化错误。
我们将首先快速演示如何编写自定义反序列化程序,尽管这是不太常见的方法,然后我们将继续介绍如何使用 Avro 反序列化消息键和值的示例。
-
自定义解串器
让我们采用我们在第 3 章中序列化的相同自定义对象,并为它编写一个反序列化程序:
public class Customer {private int customerID;private String customerName;public Customer(int ID, String name) {this.customerID = ID;this.customerName = name;}public int getID() {return customerID;}public String getName() {return customerName;}}自定义反序列化程序将如下所示:
import org.apache.kafka.common.errors.SerializationException;import java.nio.ByteBuffer;import java.util.Map;public class CustomerDeserializer implementsDeserializer<Customer> { @Overridepublic void configure(Map configs, boolean isKey) {// nothing to configure}@Overridepublic Customer deserialize(String topic, byte[] data) {int id;int nameSize;String name;try {if (data == null)return null;if (data.length < 8)throw new SerializationException("Size of data received by IntegerDeserializer is shorter than expected");ByteBuffer buffer = ByteBuffer.wrap(data);id = buffer.getInt();String nameSize = buffer.getInt();byte[] nameBytes = new Array[Byte](nameSize);buffer.get(nameBytes);name = new String(nameBytes, 'UTF-8');return new Customer(id, name); } catch (Exception e) {throw new SerializationException("Error when serializing Customer to byte[] " + e);}}@Overridepublic void close() {// nothing to close}}(1) 使用者还需要实现 Customer 类,并且该类和序列化程序都需要在生产和使用应用程序上匹配。在具有许多使用者和生产者共享数据访问权限的大型组织中,这可能变得具有挑战性。
(2) 我们只是在这里颠倒了序列化程序的逻辑 - 我们从字节数组中获取客户 ID 和名称,并使用它们来构造我们需要的对象。
使用此序列化程序的使用者代码将类似于以下示例:
Properties props = new Properties();props.put("bootstrap.servers", "broker1:9092,broker2:9092");props.put("group.id", "CountryCounter");props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer","org.apache.kafka.common.serialization.CustomerDeserializer");KafkaConsumer<String, Customer> consumer = new KafkaConsumer<>(props);consumer.subscribe("customerCountries")while (true) {ConsumerRecords<String, Customer> records =consumer.poll(100);for (ConsumerRecord<String, Customer> record : records){System.out.println("current customer Id: " +record.value().getId() + " andcurrent customer name: " + record.value().getName());}}同样,请务必注意,不建议实现自定义序列化程序和解串程序。它把生产者和消费者紧密地联系在一起,脆弱且容易出错。更好的解决方案是使用标准消息格式,例如 JSON、Thrift、Protobuf 或 Avro。现在,我们将了解如何将 Avro 反序列化程序与 Kafka 使用者一起使用。有关 Apache Avro、其模式和模式兼容性功能的背景信息,请参阅第 3 章。
-
将 Avro 反序列化与 Kafka 使用者配合使用
假设我们使用的是 Avro 中 Customer 类的实现,如第 3 章所示。为了从 Kafka 使用这些对象,您需要实现一个类似于以下内容的消费应用程序:
Properties props = new Properties();props.put("bootstrap.servers", "broker1:9092,broker2:9092");props.put("group.id", "CountryCounter");props.put("key.serializer","org.apache.kafka.common.serialization.StringDeserializer");props.put("value.serializer","io.confluent.kafka.serializers.KafkaAvroDeserializer"); (1)props.put("schema.registry.url", schemaUrl); (2)String topic = "customerContacts"KafkaConsumer consumer = newKafkaConsumer(createConsumerConfig(brokers, groupId, url));consumer.subscribe(Collections.singletonList(topic));System.out.println("Reading topic:" + topic);while (true) {ConsumerRecords<String, Customer> records = consumer.poll(1000); (3)for (ConsumerRecord<String, Customer> record: records) {System.out.println("Current customer name is: " +record.value().getName()); (4)}consumer.commitSync();}(1) 我们使用 KafkaAvroDeserializer 来反序列化 Avro 消息。
(2) schema.registry.url 是一个新参数。这仅指向我们存储架构的位置。这样,使用者就可以使用创建者注册的架构来反序列化消息。
(3) 我们将生成的类 Customer 指定为记录值的类型。
(4) record.value() 是一个 Customer 实例,我们可以相应地使用它。
4.11 独立使用者:为什么以及如何在没有组的情况下使用使用者
到目前为止,我们已经讨论了使用者组,其中分区会自动分配给使用者,并在使用者在组中添加或删除时自动重新平衡。通常,这种行为正是您想要的,但在某些情况下,您想要更简单的东西。有时,您知道您有一个使用者,它始终需要从主题中的所有分区或主题中的特定分区读取数据。在这种情况下,没有理由进行分组或重新平衡 - 只需分配特定于使用者的主题和/或分区,使用消息,并偶尔提交偏移量。
当您确切地知道使用者应该读取哪些分区时,您不会订阅某个主题,而是为自己分配几个分区。使用者可以订阅主题(并成为使用者组的一部分),也可以为自己分配分区,但不能同时为两者分配分区。
下面是一个示例,说明使用者如何为自己分配特定主题的所有分区并从中使用:
List<PartitionInfo> partitionInfos = null;partitionInfos = consumer.partitionsFor("topic"); (1)if (partitionInfos != null) {for (PartitionInfo partition : partitionInfos)partitions.add(new TopicPartition(partition.topic(),partition.partition()));consumer.assign(partitions); (2)while (true) {ConsumerRecords<String, String> records =consumer.poll(1000);for (ConsumerRecord<String, String> record: records) {System.out.printf("topic = %s, partition = %s, offset = %d,customer = %s, country = %s\n",record.topic(), record.partition(), record.offset(),record.key(), record.value());}consumer.commitSync();}}
(1) 我们首先向集群询问本主题中可用的分区。如果只计划使用特定分区,则可以跳过此部分。
(2) 一旦我们知道我们想要哪些分区,我们就用列表调用 assign()。
除了缺乏重新平衡和需要手动查找分区之外,其他一切都像往常一样。请记住,如果有人向主题添加新分区,则不会通知使用者。您需要通过定期检查 consumer.partitionsFor() 来处理这个问题,或者只是在添加分区时反弹应用程序。
4.12 较旧的使用者 API
在本章中,我们讨论了 Java KafkaConsumer 客户端,它是 org.apache.kafka.clients 包的一部分。在撰写本文时,Apache Kafka 仍然有两个用 Scala 编写的旧客户端,它们是 kafka.consumer 包的一部分,该包是核心 Kafka 模块的一部分。这些使用者称为 SimpleConsumer(不是很简单)。SimpleConsumer 是 Kafka API 的精简包装器,允许您从特定分区和偏移量中使用。另一个旧 API 称为高级使用者或 ZookeeperConsumerConnector。高级消费者与当前消费者有些相似,因为它具有消费者组,并且会重新平衡分区,但它使用 Zookeeper 来管理消费者组,并且不会像现在这样为您提供对提交和重新平衡的控制。
由于当前的使用者支持这两种行为,并为开发人员提供了更高的可靠性和控制力,因此我们不会讨论较旧的 API。如果您有兴趣使用它们,请三思而后行,然后参考 Apache Kafka 文档了解更多信息。
4.13 总结
本章首先,我们深入解释了 Kafka 的消费者群体,以及他们允许多个消费者共享从主题中读取事件的工作的方式。在理论讨论之后,我们用一个消费者订阅一个主题并不断阅读事件的实际例子来进行讨论。然后,我们研究了最重要的消费者配置参数以及它们如何影响消费者行为。我们在本章的很大一部分时间里讨论了抵消以及消费者如何跟踪它们。在编写可靠的消费者时,了解消费者如何提交抵消至关重要,因此我们花时间解释了可以做到这一点的不同方法。然后,我们讨论了使用者 API 的其他部分,处理重新平衡和关闭使用者。
最后,我们讨论了消费者用来将存储在 Kafka 中的字节转换为应用程序可以处理的 Java 对象的反序列化器。我们详细讨论了 Avro 反序列化程序,尽管它们只是您可以使用的一种反序列化程序,因为它们最常用于 Kafka。
现在您已经知道如何使用 Kafka 生成和使用事件,下一章将介绍 Kafka 实现的一些内部结构。
第五章 Kafka 内部结构
为了在生产环境中运行 Kafka 或编写使用它的应用程序,没有必要了解 Kafka 的内部结构。但是,了解 Kafka 的工作原理确实可以在故障排除或尝试理解 Kafka 行为方式的原因时提供上下文。由于涵盖每一个实现细节和设计决策超出了本书的范围,因此在本章中,我们将重点讨论与 Kafka 从业者特别相关的三个主题: • Kafka 复制的工作原理 • Kafka 如何处理来自生产者和消费者的请求 • Kafka 如何处理文件格式和索引等存储 在调优 Kafka 时,深入了解这些主题将特别有用——了解调谐旋钮控制的机制对于精确地使用它们而不是随意摆弄它们大有帮助。
5.1 集群成员身份
Kafka 使用 Apache Zookeeper 来维护当前属于集群成员的代理列表。每个代理都有一个唯一标识符,该标识符可以在代理配置文件中设置,也可以自动生成。每次代理进程启动时,它都会通过创建一个临时节点在 Zookeeper 中注册其 ID 来注册自己。不同的 Kafka 组件订阅 Zookeeper 中注册代理的 /brokers/ids 路径,以便在添加或删除代理时收到通知。
如果您尝试使用相同的 ID 启动另一个代理,您将收到一个错误 — 新代理将尝试注册,但会失败,因为我们已经有相同代理 ID 的 Zookeeper 节点。
当代理失去与 Zookeeper 的连接时(通常是由于代理停止,但也可能由于网络分区或长时间的垃圾回收暂停而发生),代理在启动时创建的临时节点将自动从 Zookeeper 中删除。正在监视代理列表的 Kafka 组件将收到代理已消失的通知。
即使代理停止时表示代理的节点消失了,代理 ID 仍存在于其他数据结构中。例如,每个主题的副本列表(请参阅第 97 页的“复制”)包含副本的代理标识。这样,如果您完全丢失了一个代理,并使用旧代理的 ID 启动了一个全新的代理,它将立即加入集群,以取代缺少的代理,并为其分配了相同的分区和主题。
5.2 控制器
控制器是 Kafka 代理之一,除了通常的代理功能外,它还负责选举分区领导者(我们将在下一节中讨论分区领导者及其作用)。通过在 ZooKeeper 中创建一个名为 /controller 的临时节点,在集群中启动的第一个代理成为控制器。当其他代理启动时,它们也会尝试创建此节点,但收到“节点已存在”异常,这会导致它们“意识到”控制器节点已经存在,并且集群已经具有控制器。代理在控制器节点上创建一个 Zookeeper 监视,以便收到有关此节点更改的通知。这样,我们保证集群一次只有一个控制器。
当控制器代理停止或失去与 Zookeeper 的连接时,临时节点将消失。集群中的其他代理将通过 Zookeeper 监视收到控制器消失的通知,并将尝试在 Zookeeper 中创建控制器节点。在 Zookeeper 中创建新控制器的第一个节点是新控制器,而其他节点将收到“节点已存在”异常,并在新控制器节点上重新创建监视。每次选择控制器时,它都会通过 Zookeeper 条件递增操作接收一个新的、更高的控制器纪元编号。代理知道当前的控制器纪元,如果它们从具有较旧编号的控制器接收到消息,它们就会忽略它。
当控制器注意到代理离开集群时(通过观察相关的 Zookeeper 路径),它知道该代理上有 leader 的所有分区都需要一个新的 leader。它遍历所有需要新领导者的分区,确定新领导者应该是谁(只是该分区副本列表中的下一个副本),并向包含这些分区的新领导者或现有追随者的所有代理发送请求。该请求包含有关分区的新领导者和追随者的信息。每个新领导者都知道它需要开始服务来自客户端的生产者和消费者请求,而追随者知道他们需要开始复制来自新领导者的消息.
当控制器注意到代理已加入集群时,它会使用代理标识来检查此代理上是否存在副本。如果存在,控制器会将更改通知新代理和现有代理,并且新代理上的副本将开始复制来自现有主节点的消息。
总而言之,Kafka 使用 Zookeeper 的临时节点功能来选择控制器,并在节点加入和离开集群时通知控制器。控制器负责在发现节点加入和离开集群时在分区和副本中选举领导者。控制器使用纪元来防止出现“裂脑”的情况,即两个节点认为每个节点都是当前控制器。
5.3 复制
复制是 Kafka 架构的核心。Kafka 文档中的第一句话将其描述为“分布式、分区、复制的提交日志服务”。复制至关重要,因为它是 Kafka 在单个节点不可避免地发生故障时保证可用性和持久性的方式。
正如我们已经讨论过的,Kafka 中的数据是按主题组织的。每个主题都进行了分区,每个分区可以有多个副本。这些副本存储在代理上,每个代理通常存储数百甚至数千个属于不同主题和分区的副本。
有两种类型的副本:
-
主副本
每个分区都有一个被指定为领导者的副本。所有生产和消费请求都经过领导者,以保证一致性。
-
追随者副本
分区中所有非领导者的副本都称为追随者。追随者不服务于客户请求;他们唯一的工作是复制领导者的消息,并及时了解领导者的最新消息。如果一个分区的 leader 副本崩溃,其中一个 follower 副本将被提升为该分区的新 leader.
领导者负责的另一项任务是了解哪些追随者副本与领导者保持同步。追随者试图通过在消息到达时复制来自领导者的所有消息来保持最新状态,但由于各种原因,他们可能无法保持同步,例如当网络拥塞减慢复制速度时,或者当代理崩溃并且该代理上的所有副本开始落后时,直到我们启动代理,他们可以再次开始复制。
为了与主节点保持同步,副本会发送主节点 Fetch 请求,这与消费者为了使用消息而发送的请求类型完全相同。为了响应这些请求,领导者将消息发送到副本。这些 Fetch 请求包含副本接下来要接收的消息的偏移量,并且将始终按顺序排列。
副本将请求消息 1,然后是消息 2,然后是消息 3,并且在获取之前的所有消息之前,它不会请求消息 4。这意味着,当副本请求消息 4 时,领导者可以知道副本获取了消息 3 之前的所有消息。通过查看每个副本请求的最后一个偏移量,领导者可以判断每个副本落后了多远。如果副本在 10 秒内未请求消息,或者如果副本已请求消息但在 10 秒内未赶上最新消息,则副本将被视为不同步。如果副本无法跟上主节点的步伐,则在发生故障时,它不能再成为新的主节点 — 毕竟,它不包含所有消息。
与此相反,即持续要求最新消息的副本称为同步副本。只有同步副本才有资格被选为分区主节点,以防现有主节点发生故障。
跟随者在被视为不同步之前可以处于非活动状态或落后的时间量由 replica.lag.time.max.ms 配置参数控制。这允许的滞后对领导者选举期间的客户端行为和数据保留有影响。我们将在第 6 章讨论可靠性保证时深入讨论这一点。
除了当前主处理器之外,每个分区都有一个首选主主服务器,即最初创建主题时作为主处理器的副本。它是首选的,因为当第一次创建分区时,领导者在代理之间是平衡的(我们解释了在本章后面的代理之间分发副本和领导者)。
因此,我们预计,当首选领导者确实是集群中所有分区的领导者时,负载将在代理之间均匀平衡。默认情况下,Kafka 配置了 auto.leader.rebalance.enable=true,它将检查首选领导者副本是否不是当前领导者,而是同步的,并触发领导者选举以使首选领导者成为当前领导者。
-
寻找首选领导者
确定当前首选领导者的最佳方法是查看分区的副本列表(您可以在 kafka-topics.sh 工具的输出中查看分区和副本的详细信息。我们将在第 10 章中讨论此工具和其他管理工具。列表中的第一个副本始终是首选的引线。无论谁是当前领导者,即使使用副本重新分配工具将副本重新分配给不同的代理,也是如此。事实上,如果您手动重新分配副本,请务必记住,您首先指定的副本将是首选副本,因此请确保将这些副本分散在不同的代理上,以避免某些代理因领导者而使其他代理不处理其公平份额的工作。
5.4请求处理
Kafka 代理所做的大部分工作是处理从客户端、分区副本和控制器发送到分区领导者的请求。Kafka 有一个二进制协议(通过 TCP),该协议指定请求的格式以及代理如何响应它们 - 无论是在请求成功处理时还是在代理在处理请求时遇到错误时。客户端始终启动连接并发送请求,代理处理请求并响应它们。从特定客户端发送到代理的所有请求都将按照接收顺序进行处理——这种保证允许 Kafka 充当消息队列,并为其存储的消息提供排序保证。
所有请求都有一个标准标头,其中包括: • 请求类型(也称为 API 密钥) • 请求版本(因此经纪人可以处理不同版本的客户端和据此回应) • 相关 ID:唯一标识请求的数字,也出现在响应和错误日志中(ID 用于故障排除) • 客户端 ID:用于标识发送请求的应用程序
我们不会在这里描述该协议,因为它在 Kafka 文档中有非常详细的描述。但是,了解代理如何处理请求会很有帮助 - 稍后,当我们讨论如何监视 Kafka 和各种配置选项时,您将了解指标和配置参数引用哪些队列和线程。
对于代理侦听的每个端口,代理都会运行一个接受器线程,该线程创建连接并将其移交给处理器线程进行处理。处理器线程数(也称为网络线程数)是可配置的。网络线程负责从客户端连接接收请求,将它们放入请求队列中,并从响应队列中获取响应并将其发送回客户端。有关此过程的可视化,请参见图 5-1。
将请求放入请求队列后,IO 线程将负责拾取并处理它们。最常见的请求类型是:
-
生成请求 由生产者发送,包含客户端写入 Kafka 代理的消息。
-
提取请求 由使用者和追随者副本在从 Kafka 代理读取消息时发送。

图5-1 Apache Kafka 内部的请求处理
produce 请求和 fetch 请求都必须发送到分区的 leader 副本。如果代理收到特定分区的 produce 请求,并且此分区的 leader 位于不同的代理上,那么发送 produce 请求的客户端将收到 “Not a Leader for Partition” 的错误响应。如果特定分区的 fetch 请求到达没有该分区的领导者的代理,则也会发生相同的错误。Kafka 的客户端负责向代理发送 produce 和 fetch 请求,该代理包含请求相关分区的领导者。
客户端如何知道将请求发送到何处?Kafka 客户端使用另一种称为元数据请求的请求类型,其中包括客户端感兴趣的主题列表。服务器响应指定主题中存在哪些分区、每个分区的副本以及哪个副本是领导者。元数据请求可以发送到任何代理,因为所有代理都有一个包含此信息的元数据缓存。
客户端通常会缓存此信息,并使用它来将生成请求和提取请求定向到每个分区的正确代理。他们还需要偶尔通过发送另一个元数据请求来刷新此信息(刷新间隔由 meta data.max.age.ms 配置参数控制),以便他们知道主题元数据是否更改,例如,是否添加了新代理或将某些副本移动到了新代理(图 5-2)。此外,如果客户端收到其请求之一的“Not a Leader”错误,它将在尝试再次发送请求之前刷新其元数据,因为该错误表明客户端正在使用过时的信息,并且正在向错误的代理发送请求。

图 5-2. 客户端路由请求
5.4.1 生产请求
正如我们在第 3 章中看到的,一个名为 acks 的配置参数是需要确认收到消息的代理数量,然后才能将其视为成功写入。可以将生产者配置为在消息仅被领导者 (acks=1)、所有同步副本 (acks=all) 或消息发送而不等待代理接受它的那一刻 (acks=0) 时将消息视为“成功写入”。
当包含分区的主要副本的代理收到此分区的 produce 请求时,它将首先运行一些验证: • 发送数据的用户是否具有该主题的写入权限? • 请求中指定的确认数是否有效(只允许 0、1 和“all”)? • 如果 acks 设置为 all,是否有足够的同步副本来安全地写入消息?(如果同步副本的数量低于可配置的数量,代理可以配置为拒绝新消息;我们将在第 6 章中更详细地讨论这一点,届时我们将讨论 Kafka 的持久性和可靠性保证。
然后它会将新消息写入本地磁盘。在 Linux 上,消息被写入文件系统缓存,并且无法保证它们何时被写入磁盘。Kafka 不会等待数据持久化到磁盘上,而是依靠复制来实现消息持久性。
将消息写入分区的领导者后,代理会检查 acks 配置,如果 acks 设置为 0 或 1,则代理将立即响应;如果 acks 设置为 all,则请求将存储在名为 Purgatory 的缓冲区中,直到 leader 观察到 follower 副本复制了消息,此时将向客户端发送响应。
5.4.2 提取请求
代理处理提取请求的方式与处理生产请求的方式非常相似。客户端发送一个请求,要求代理从主题、分区和偏移量列表发送消息,例如“请向我发送从主题 Test 分区 0 中的偏移量 53 开始的消息,以及从主题 Test 的分区 3 中的偏移量 64 开始的消息。客户端还指定代理可以为每个分区返回的数据量的限制。该限制很重要,因为客户端需要分配内存来保存从代理发回的响应。如果没有此限制,代理可能会发回足够大的回复,从而导致客户端内存不足。
正如我们之前所讨论的,请求必须到达请求中指定的分区的领导者,客户端将发出必要的元数据请求,以确保它正确地路由提取请求。当领导者收到请求时,它首先检查请求是否有效 - 此特定分区是否存在此偏移量?如果客户端请求的消息太旧,以至于它已从分区中删除,或者偏移量尚不存在,那么代理将以错误进行响应。
如果偏移量存在,代理将从分区中读取消息,直至达到客户端在请求中设置的限制,并将消息发送到客户端。Kafka 使用零拷贝方法将消息发送到客户端,这意味着 Kafka 将消息从文件(或者更可能是 Linux 文件系统缓存)直接发送到网络通道,而无需任何中间缓冲区。这与大多数数据库不同,在大多数数据库中,数据在发送到客户端之前存储在本地缓存中。此技术消除了复制字节和管理内存缓冲区的开销,并大大提高了性能。
除了为代理可以返回的数据量设置上限外,客户端还可以为返回的数据量设置下限。例如,将下限设置为 10K 是客户端告诉代理“只有在您至少有 10K 字节发送给我时才返回结果”的方式。当客户端从流量不多的主题中读取数据时,这是降低 CPU 和网络利用率的好方法。客户端不是每隔几毫秒向代理发送一次请求请求,请求数据,但得到的消息很少或没有返回,而是客户端发送请求,代理等待,直到有相当数量的数据并返回数据,然后客户端才会请求更多数据(图 5-3)。总体上读取的数据量相同,但来回次数要少得多,因此开销也更少。

图5-3 代理延迟响应,直到积累足够的数据
当然,我们不希望客户永远等待经纪人获得足够的数据。一段时间后,只获取现有的数据并对其进行处理而不是等待更多数据是有意义的。因此,客户端还可以定义一个超时来告诉代理“如果您没有满足在 x 毫秒内发送的最小数据量,只需发送您得到的数据。
同样有趣的是,并非所有存在于分区领导者上的数据都可供客户端读取。大多数客户端只能读取写入所有同步副本的消息(从属副本,即使它们是使用者,也不受此限制,否则复制将不起作用)。我们已经讨论过,分区的领导者知道哪些消息被复制到哪个副本,并且在将消息写入所有同步副本之前,它不会发送给使用者 - 尝试获取这些消息将导致空响应而不是错误。
造成此行为的原因是,尚未复制到足够多副本的消息被视为“不安全”——如果领导者崩溃并且另一个副本取代了它,则这些消息将不再存在于 Kafka 中。如果我们允许客户端读取仅存在于领导者上的消息,我们可能会看到不一致的行为。例如,如果使用者读取了一条消息,而领导者崩溃了,并且没有其他代理包含此消息,则该消息将消失。其他使用者将无法读取此消息,这可能会导致与阅读该消息的使用者不一致。相反,我们会等到所有同步副本都收到消息,然后才允许使用者读取它(图 5-4)。此行为还意味着,如果代理之间的复制由于某种原因而变慢,则新消息到达使用者将需要更长的时间才能到达(因为我们首先等待消息复制)。此延迟限制为 replica.lag.time.max.ms - 副本在复制新消息时可以延迟的时间量,同时仍被视为同步。

图5-4 使用者只能看到复制到同步副本的消息
5.4.3 其他要求
我们刚刚讨论了 Kafka 客户端最常用的请求类型:元数据、生产和获取。重要的是要记住,我们谈论的是客户端通过网络使用的通用二进制协议。虽然 Kafka 包括由 Apache Kafka 项目的贡献者实现和维护的 Java 客户端,但也有其他语言的客户端,例如 C、Python、Go 等。您可以在 Apache Kafka 网站上看到完整列表,它们都使用此协议与 Kafka 代理通信。
此外,Kafka 代理本身之间也使用相同的协议进行通信。这些请求是内部请求,不应由客户端使用。例如,当控制器宣布分区有新的领导者时,它会向新的领导者(因此它将知道开始接受客户端请求)和追随者(以便他们知道跟随新的领导者)发送 Leader AndIsr 请求。
Kafka 协议目前处理 20 种不同的请求类型,并且还会添加更多请求类型。该协议在不断发展 - 随着我们添加更多客户端功能,我们需要扩展协议以匹配。例如,过去,Kafka 使用者使用 Apache Zookeeper 来跟踪他们从 Kafka 收到的偏移量。因此,当使用者启动时,它可以检查 Zookeeper 中是否有从其分区读取的最后一个偏移量,并知道从哪里开始处理。出于各种原因,我们决定停止使用 Zookeeper,而是将这些偏移量存储在一个特殊的 Kafka 主题中。为此,我们必须向协议添加多个请求:OffsetCommitRequest、Offset FetchRequest 和 ListOffsetsRequest。现在,当应用程序调用 commitOffset() 客户端 API 时,客户端不再写入 Zookeeper;相反,它会将 OffsetCommitRequest 发送到 Kafka。
主题创建仍然由命令行工具完成,这些工具直接更新 Zookeeper 中的主题列表,代理会观察 Zookeeper 中的主题列表以了解何时添加新主题。我们正在努力改进 Kafka 并添加一个 Create TopicRequest,该请求将允许所有客户端(即使是没有 Zookeeper 库的语言)通过直接询问 Kafka 代理来创建主题。
除了通过添加新的请求类型来改进协议外,我们有时还会选择修改现有请求以添加一些功能。例如,在 Kafka 0.9.0 和 Kafka 0.10.0 之间,我们决定通过将信息添加到元数据响应中来让客户端知道当前控制器是谁。因此,我们在元数据请求和响应中添加了一个新版本。现在,0.9.0 客户端发送版本 0 的元数据请求(因为版本 1 在 0.9.0 客户端中不存在),并且代理(无论是 0.9.0 还是 0.10.0)都知道使用版本 0 响应进行响应,该响应没有控制器信息。这很好,因为 0.9.0 客户端不需要控制器信息,无论如何都不知道如何解析它。如果您有 0.10.0 客户端,它将发送版本 1 元数据请求,而 0.10.0 代理将响应包含控制器信息的版本 1 响应,0.10.0 客户端可以使用该响应。如果 0.10.0 客户端向 0.9.0 代理发送版本 1 元数据请求,那么代理将不知道如何处理较新版本的请求,并且会以错误进行响应。这就是我们建议在升级任何客户端之前升级代理的原因 - 新代理知道如何处理旧请求,但反之亦然。
在版本 0.10.0 中,我们添加了 ApiVersionRequest,它允许客户端询问代理支持每个请求的哪个版本,并相应地使用正确的版本。正确使用此新功能的客户端将能够使用它们所连接的代理支持的协议版本与较旧的代理进行通信。
5.5物理存储
Kafka 的基本存储单元是分区副本。分区不能在多个代理之间拆分,甚至不能在同一代理上的多个磁盘之间拆分。因此,分区的大小受单个挂载点上可用空间的限制。(如果使用 JBOD 配置,则挂载点将由单个磁盘组成,如果配置了 RAID,则由多个磁盘组成。请参阅第 2 章。
配置 Kafka 时,管理员会定义一个存储分区的目录列表,即 log.dirs 参数(不要与 Kafka 存储错误日志的位置混淆,后者在 log4j.properties 文件中配置)。通常的配置包括 Kafka 将使用的每个挂载点的目录。
让我们看看 Kafka 如何使用可用目录来存储数据。首先,我们要看一下如何将数据分配给集群中的代理和代理中的目录。然后,我们将了解代理如何管理文件,尤其是如何处理保留保证。然后,我们将深入研究文件并查看文件和索引格式。最后,我们将介绍日志压缩,这是一项高级功能,允许将 Kafka 转换为长期数据存储,并描述它是如何工作的。
5.5.1 分区分配
创建主题时,Kafka 首先决定如何在代理之间分配分区。假设您有 6 个代理,并且您决定创建一个具有 10 个分区和复制因子为 3 的主题。Kafka 现在有 30 个分区副本要分配给 6 个代理。进行分配时,目标是: • 在代理之间平均分布副本 - 在我们的示例中,确保为每个代理分配 5 个副本。 • 确保对于每个分区,每个副本都位于不同的代理上。如果分区 0 在代理 2 上有领导者,我们可以将跟随者放在代理 3 和 4 上,但不能放在 2 上,也不能放在 3 上。 • 如果代理具有机架信息(在 Kafka 版本 0.10.0 及更高版本中可用),则尽可能将每个分区的副本分配给不同的机架。这可确保导致整个机架停机的事件不会导致分区完全不可用。
为此,我们从随机代理(假设 4)开始,然后开始以循环方式为每个代理分配分区,以确定领导者的位置。因此,分区领导者 0 将在代理 4 上,分区 1 领导者将在代理 5 上,分区 2 将在代理 0 上(因为我们只有 6 个代理),依此类推。然后,对于每个分区,我们将副本放置在与主分区的偏移量递增的位置。如果分区 0 的领导者在代理 4 上,则第一个跟随者将位于代理 5 上,第二个跟随者将在代理 0 上。分区 1 的领导者位于代理 5 上,因此第一个副本位于代理 0 上,第二个副本位于代理 1 上。当考虑到机架意识时,我们不是按数字顺序选择经纪人,而是准备一个机架交替经纪人列表。假设我们知道代理 0、1 和 2 位于同一机架上,而代理 3、4 和 5 位于单独的机架上。 我们不是按 0 到 5 的顺序选择代理,而是按 0、3、1、4、2、5 对它们进行排序 - 每个代理后面跟着来自不同机架的代理(图 5-5)。在这种情况下,如果分区 0 的主节点位于代理 4 上,则第一个副本将位于代理 2 上,而代理 2 位于完全不同的机架上。这很好,因为如果第一个机架脱机,我们知道我们仍然有一个幸存的副本,因此该分区仍然可用。对于我们所有的副本都是如此,因此我们保证了在机架故障情况下的可用性。

图 5-5. 分配给不同机架上的代理的分区和副本
一旦我们为每个分区和副本选择了正确的代理,就该决定将哪个目录用于新分区了。我们对每个分区独立执行此操作,规则非常简单:我们计算每个目录上的分区数,并将新分区添加到分区最少的目录中。这意味着,如果添加新磁盘,则将在该磁盘上创建所有新分区。这是因为,在事情平衡之前,新磁盘将始终具有最少的分区。
-
注意磁盘空间
请注意,将分区分配给代理时不考虑可用空间或现有负载,并且将分区分配给磁盘时会考虑分区数,但不考虑分区的大小。这意味着,如果某些代理比其他代理具有更多的磁盘空间(可能是因为集群是较旧和较新的服务器的混合),某些分区异常大,或者同一代理上有不同大小的磁盘,则需要小心分区分配。
5.5.2 文件管理
保留是 Kafka 中的一个重要概念,Kafka 不会永久保留数据,也不会等待所有使用者阅读消息后再删除数据。相反,Kafka 管理员会为每个主题配置一个保留期,即在删除消息之前存储消息的时间量,或者在清除旧消息之前要存储的数据量。
由于在大文件中查找需要清除的消息,然后删除文件的一部分既耗时又容易出错,因此我们将每个分区拆分为多个段。默认情况下,每个区段包含 1 GB 的数据或一周的数据,以较小者为准。当 Kafka 代理写入分区时,如果达到段限制,我们将关闭文件并启动一个新文件。
我们当前写入的区段称为活动区段。活动区段永远不会被删除,因此,如果您将日志保留期设置为仅存储一天的数据,但每个区段包含 5 天的数据,则您实际上会将数据保留 5 天,因为我们无法在区段关闭之前删除数据。如果您选择存储数据一周并每天滚动一个新段,您将看到我们每天都会滚动一个新段,同时删除最旧的段,因此大多数情况下分区将有七个段。
正如您在第 2 章中所学到的,Kafka 代理将对每个分区中的每个段(甚至是非活动段)保留一个打开的文件句柄。这通常会导致大量打开的文件句柄,并且必须相应地调整操作系统。
5.5.3 文件格式
每个段都存储在一个数据文件中。在文件中,我们存储 Kafka 消息及其偏移量。磁盘上数据的格式与我们从生产者发送到代理以及后来从代理发送到消费者的消息的格式相同。在磁盘和网络上使用相同的消息格式,允许 Kafka 在向消费者发送消息时使用零拷贝优化,并避免解压缩和重新压缩生产者已经压缩的消息。
除了键、值和偏移量之外,每条消息还包含消息大小、允许我们检测损坏的校验和代码、指示消息格式版本的魔术字节、压缩编解码器(Snappy、GZip 或 LZ4)和时间戳(在 0.10.0 版中添加)等内容。时间戳由创建者在发送消息时提供,或由代理在消息到达时提供,具体取决于配置。
如果生产者发送的是压缩消息,则单个生产者批处理中的所有消息将压缩在一起,并作为“包装器消息”的“值”发送(图 5-6)。因此,代理接收一条消息,并将其发送给消费者。但是,当使用者解压缩消息值时,它将看到批处理中包含的所有消息,以及它们自己的时间戳和偏移量。这意味着,如果您在生产者上使用压缩(推荐!),则发送更大的批处理意味着通过网络和代理磁盘进行更好的压缩。这也意味着,如果我们决定改变消费者使用的消息格式(例如,在消息中添加时间戳),线路协议和磁盘格式都需要改变,Kafka 代理需要知道如何处理文件因升级而包含两种格式的消息的情况。

图 5-6. 普通消息和包装器消息
Kafka 代理附带了 DumpLogSegment 工具,该工具允许您查看文件系统中的分区段并检查其内容。它将显示每条消息的偏移量、校验和、魔术字节、大小和压缩编解码器。您可以使用以下命令运行该工具:
bin/kafka-run-class.sh kafka.tools.DumpLogSegments
如果选择 --deep-iteration 参数,它将显示有关包装器消息中压缩的消息的信息。
5.5.4 指标
Kafka 允许使用者开始从任何可用的偏移量获取消息。这意味着,如果使用者请求从偏移量 100 开始的 1 MB 消息,则代理必须能够快速找到偏移量 100 的消息(可以在分区的任何段中),并开始从该偏移量读取消息。为了帮助代理快速找到给定偏移量的消息,Kafka 为每个分区维护一个索引。索引将偏移映射到段文件和文件中的位置。
索引也被分解为多个段,因此我们可以在清除消息时删除旧的索引条目。Kafka 不会尝试维护索引的校验和。如果索引损坏,只需重新读取消息并记录偏移量和位置,即可从匹配的日志段重新生成索引。如果需要,管理员删除索引段也是完全安全的,它们将自动重新生成。
5.5.5 压缩
通常,Kafka 会将消息存储一段时间,并清除早于保留期的消息。但是,想象一下您使用 Kafka 为客户存储送货地址的情况。在这种情况下,存储每个客户的最后一个地址比仅存储上周或一年的数据更有意义。这样,您就不必担心旧地址,并且您仍然可以为一段时间未搬家的客户保留该地址。另一个用例可以是使用 Kafka 存储其当前状态的应用程序。每次状态更改时,应用程序都会将新状态写入 Kafka。从崩溃中恢复时,应用程序会从 Kafka 读取这些消息以恢复其最新状态。在这种情况下,它只关心崩溃前的最新状态,而不关心运行时发生的所有更改。
Kafka 支持此类用例,允许删除主题上的保留策略,删除早于保留时间的事件,压缩策略仅存储主题中每个键的最新值。显然,将策略设置为 compact 仅在应用程序生成同时包含键和值的事件的主题上才有意义。如果主题包含空键,则压缩将失败。
5.5.6 压缩的工作原理
每个日志都分为两部分(请参阅图 5-7):
-
干净 之前压缩过的消息。此部分仅包含每个键的一个值,该值是之前压缩的最新值
-
脏 在上次压缩之后写入的消息。

图 5-7. 用干净和肮脏的部分隔断
如果在 Kafka 启动时启用了压缩(使用笨拙的 log.cleaner.enabled 配置),则每个代理将启动一个压缩管理器线程和多个压缩线程。它们负责执行压缩任务。这些线程中的每一个都选择脏消息与总分区大小比率最高的分区,并清理此分区。
为了压缩分区,清理线程读取分区的脏部分并创建内存中映射。每个映射条目都由消息密钥的 16 字节哈希值和具有相同密钥的上一条消息的 8 字节偏移量组成。这意味着每个映射条目仅使用 24 个字节。如果我们查看一个 1 GB 的段,并假设该段中的每条消息占用 1 KB,则该段将包含 100 万条这样的消息,我们只需要一个 24 MB 的映射来压缩该段(我们可能需要的要少得多——如果键重复,我们将经常重用相同的哈希条目并使用更少的内存)。这是相当有效的!
配置 Kafka 时,管理员会配置压缩线程可用于此偏移映射的内存量。尽管每个线程都有自己的映射,但该配置适用于所有线程的总内存。如果为压缩偏移映射配置了 1 GB,并且有 5 个更干净的线程,则每个线程将获得 200 MB 的偏移映射。Kafka 不要求分区的整个脏部分适合为此映射分配的大小,但至少必须适合一个完整的段。否则,Kafka 将记录错误,管理员需要为偏移映射分配更多内存或使用更少的清理线程。如果只有几个段适合,Kafka 将首先压缩适合地图的最旧段。其余的将保持脏污并等待下一次压实。
一旦清理线程构建了偏移图,它将开始读取干净的片段,从最旧的开始,并根据偏移图检查它们的内容。对于每条消息,如果偏移映射中存在消息的键,则检查该消息。如果映射中不存在该键,则我们刚刚读取的消息的值仍然是最新的,我们会将该消息复制到替换段。如果映射中确实存在该键,则省略该消息,因为分区中稍后有一条具有相同键但值较新的消息。复制所有仍包含其密钥最新值的消息后,我们将替换段交换为原始段,然后继续下一个段。在该过程结束时,每个键只剩下一条消息,即具有最新值的消息。请参见图 5-8。
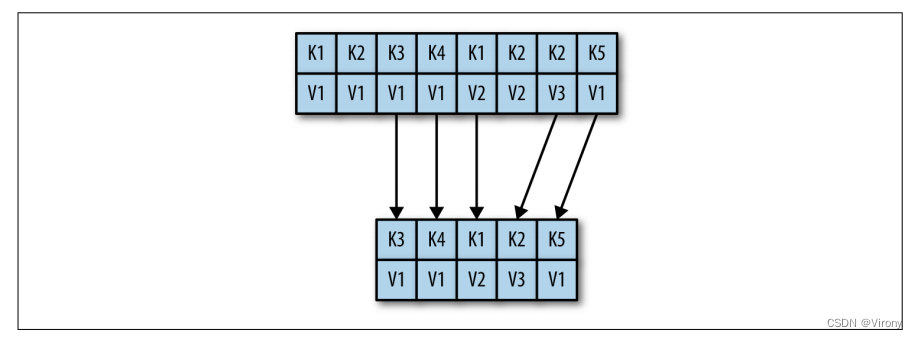
图 5-8. 压缩前后的分区段
5.5.7 已删除的事件
如果我们始终保留每个密钥的最新消息,那么当我们真的想删除特定密钥的所有消息时,例如如果用户离开了我们的服务,并且我们在法律上有义务从我们的系统中删除该用户的所有痕迹,我们该怎么办?
为了从系统中完全删除密钥,甚至不保存最后一条消息,应用程序必须生成包含该密钥和 null 值的消息。当清理线程找到这样的消息时,它将首先执行正常压缩,并仅保留具有 null 值的消息。它会将此特殊消息(称为逻辑删除)保留一段可配置的时间。在此期间,使用者将能够看到此消息,并知道该值已被删除。因此,如果使用者将数据从 Kafka 复制到关系数据库,它将看到逻辑删除消息,并知道从数据库中删除用户。在设定的时间之后,清理线程将删除逻辑删除消息,并且密钥将从 Kafka 中的分区中消失。给消费者足够的时间来查看逻辑删除消息是很重要的,因为如果我们的使用者关闭了几个小时并错过了逻辑删除消息,那么它在使用时根本看不到密钥,因此不知道它已从 Kafka 中删除或将其从数据库中删除。
5.5.8 何时压缩主题?
与删除策略从不删除当前活动分段的方式相同,压缩策略从不压缩当前分段。消息只能在非活动区段上进行压缩。
在 0.10.0 及更早版本中,当 50% 的主题包含脏记录时,Kafka 将开始压缩。目标是不要过于频繁地压缩(因为压缩会影响主题的读/写性能),但也不要留下太多脏记录(因为它们会占用磁盘空间)。将主题使用的 50% 的磁盘空间浪费在脏记录上,然后一次性压缩它们似乎是一种合理的权衡,管理员可以对其进行调整。
在未来的版本中,我们计划添加一个宽限期,在此期间,我们保证消息将保持未压缩状态。这将使需要查看写入主题的每条消息的应用程序有足够的时间来确保它们确实看到了这些消息,即使它们有点滞后。
5.6总结
显然,Kafka 的内容比我们在本章中所能涵盖的要多,但我们希望这能让您了解我们在项目上所做的设计决策和优化,并可能解释您在使用 Kafka 时遇到的一些更晦涩的行为和配置。
如果你真的对 Kafka 内部感兴趣,那么阅读代码是无可替代的。Kafka 开发者邮件列表 (dev@kafka.apache.org) 是一个非常友好的社区,总有人愿意回答有关 Kafka 真正工作方式的问题。当你在阅读代码时,也许你可以修复一两个错误——开源项目总是欢迎贡献。
第六章 可靠的数据交付
可靠的数据交付是系统的属性之一,不能作为事后的想法。与性能一样,它必须从第一个白板图开始设计成一个系统。你不能在事后就强调可靠性。更重要的是,可靠性是系统的一个属性,而不是单个组件的属性,因此即使我们谈论的是 Apache Kafka 的可靠性保证,您也需要牢记整个系统及其用例。在可靠性方面,与 Kafka 集成的系统与 Kafka 本身一样重要。而且,由于可靠性是一个系统问题,因此不能只由一个人负责。Kafka 管理员、Linux 管理员、网络和存储管理员以及应用程序开发人员等所有人必须协同工作,才能构建可靠的系统。
Apache Kafka 在可靠的数据传输方面非常灵活。我们知道 Kafka 有许多用例,从跟踪网站中的点击到信用卡支付。一些用例需要最大的可靠性,而另一些用例则优先考虑速度和简单性而不是可靠性。Kafka 被编写为具有足够的可配置性,其客户端 API 足够灵活,可以进行各种可靠性权衡。
由于它的灵活性,在使用 Kafka 时也很容易不小心搬起石头砸自己的脚——相信你的系统是可靠的,而实际上并非如此。在本章中,我们将首先讨论不同类型的可靠性以及它们在 Apache Kafka 上下文中的含义。然后我们将讨论 Kafka 的复制机制以及它如何为系统的可靠性做出贡献。然后,我们将讨论 Kafka 的代理和主题,以及如何针对不同的用例配置它们。然后,我们将讨论客户端、生产者和消费者,以及如何在不同的可靠性场景中使用它们。最后,我们将讨论验证系统可靠性的主题,因为仅仅相信系统是可靠的是不够的,必须对假设进行彻底的测试。
6.1 可靠性保证
当我们谈论可靠性时,我们通常从保证的角度来谈论,这是系统在不同情况下保证保留的行为。
最广为人知的可靠性保证可能是 ACID,它是关系数据库普遍支持的标准可靠性保证。ACID 代表原子性、一致性、隔离性和持久性。当供应商解释他们的数据库符合 ACID 标准时,这意味着数据库保证了有关交易行为的某些行为。
这些保证是人们信任关系数据库及其最关键应用程序的原因 - 他们确切地知道系统承诺了什么以及它在不同条件下的行为方式。他们了解这些保证,并可以依靠这些保证编写安全的应用程序。
了解 Kafka 提供的保证对于那些寻求构建可靠应用程序的人来说至关重要。这种理解使系统的开发人员能够弄清楚它在不同故障条件下的行为方式。那么,Apache Kafka 保证了什么? • Kafka 为分区中的消息提供顺序保证。如果消息 B 是在消息 A 之后写入的,使用同一分区中的同一个生产者,那么 Kafka 保证消息 B 的偏移量将高于消息 A,并且消费者将在消息 A 之后读取消息 B。 • 当生成的消息被写入分区的所有同步副本(但不一定刷新到磁盘)时,它们被视为“已提交”。生产者可以选择在消息完全提交、写入领导者或通过网络发送消息时接收已发送消息的确认。 • 只要至少有一个副本保持活动状态,提交的消息就不会丢失。 • 使用者只能读取已提交的消息。
这些基本保证可以在构建可靠系统时使用,但其本身并不能使系统完全可靠。构建可靠的系统需要权衡取舍,而 Kafka 的构建是为了允许管理员和开发人员通过提供允许控制这些权衡的配置参数来决定他们需要多少可靠性。权衡通常涉及可靠且一致地存储消息的重要性,而不是其他重要考虑因素,例如可用性、高吞吐量、低延迟和硬件成本。接下来,我们将回顾 Kafka 的复制机制,介绍术语,并讨论如何在 Kafka 中构建可靠性。之后,我们回顾一下刚才提到的配置参数。
6.2 复制
Kafka 的复制机制(每个分区具有多个副本)是 Kafka 所有可靠性保证的核心。将消息写入多个副本是 Kafka 在发生崩溃时提供消息持久性的方式。
我们在第 5 章中深入解释了 Kafka 的复制机制,但让我们回顾一下这里的亮点。
每个 Kafka 主题都细分为多个分区,这些分区是基本的数据构建块。分区存储在单个磁盘上。Kafka 保证分区内事件的顺序,分区可以是联机(可用)或脱机(不可用)。每个分区可以有多个副本,其中一个副本是指定的主副本。所有事件都生成到主副本并从中使用。其他副本只需要与领导者保持同步,并按时复制所有最近的事件。如果主节点不可用,则其中一个同步副本将成为新的主节点。
如果副本是分区的领导者,或者它是以下的追随者,则副本被视为同步: • 与 Zookeeper 有一个活动会话 - 这意味着,它在过去 6 秒内向 Zookeeper 发送了检测信号(可配置)。 • 在过去 10 秒内从领导者获取消息(可配置)。 • 获取了过去 10 秒内从领导者那里获取的最新消息。也就是说,追随者仍然从领导者那里收到消息是不够的;它必须几乎没有滞后。
如果副本失去与 Zookeeper 的连接、停止获取新消息或落后且无法在 10 秒内赶上,则该副本将被视为不同步。当不同步的副本再次连接到 Zookeeper 并赶上写入领导者的最新消息时,它会恢复同步。这通常在临时网络故障得到修复后很快发生,但如果存储副本的代理关闭较长时间,则可能需要一段时间。
-
不同步的副本
看到一个或多个副本在同步和不同步状态之间快速切换,这肯定表明群集有问题。原因通常是 Java 垃圾回收在代理上的配置错误。错误配置的垃圾回收可能会导致代理暂停几秒钟,在此期间它将失去与 Zookeeper 的连接。当代理失去与 Zookeeper 的连接时,它将被视为与集群不同步,从而导致翻转行为。
稍微滞后的同步副本可能会减慢生产者和使用者的速度,因为他们会等待所有同步副本在提交消息之前获取消息。一旦副本不同步,我们就不再等待它收到消息。它仍然落后,但现在对性能没有影响。问题在于,同步副本越少,分区的有效复制因子就越低,因此停机或数据丢失的风险也就越高。
在下一节中,我们将看看这在实践中意味着什么。
6.3 代理配置
6.3.1 复制因子
主题级配置为 replication.factor。在代理级别,您可以控制自动创建的主题的 default.replication.factor。
在此之前,在整本书中,我们始终假设主题的复制因子为 3,这意味着每个分区在三个不同的代理上复制 3 次。这是一个合理的假设,因为这是 Kafka 的默认设置,但这也是用户可以修改的配置。即使在主题存在之后,您也可以选择添加或删除副本,从而修改复制因子。
如果复制因子为 N,则允许您丢失 N-1 个代理,同时仍能够可靠地读取和写入主题数据。因此,复制因子越高,可用性越高,可靠性越高,灾难越少。另一方面,对于 N 的复制因子,您将至少需要 N 个代理,并且您将存储 N 个数据副本,这意味着您将需要 N 倍的磁盘空间。我们基本上是在交易硬件的可用性。
那么,如何确定主题的正确副本数 答案取决于主题的重要性以及您愿意为更高的可用性支付多少费用。这也取决于你的偏执程度。
如果您完全可以接受在重新启动单个代理时特定主题不可用(这是集群正常操作的一部分),那么复制因子 1 可能就足够了。不要忘记确保您的管理层和用户也同意这种权衡 - 您节省了磁盘或服务器,但失去了高可用性。复制因子为 2 意味着您可以丢失一个代理,但仍然正常,这听起来已经足够了,但请记住,丢失一个代理有时会(主要是在旧版本的 Kafka 上)使集群进入不稳定状态,迫使您重新启动另一个代理 — Kafka Controller。这意味着,如果复制因子为 2,则可能会被迫进入不可用状态,以便从操作问题中恢复。这可能是一个艰难的选择。
出于这些原因,对于可用性存在问题的任何主题,我们建议将复制因子设为 3。在极少数情况下,这被认为不够安全——我们已经看到银行使用五个副本运行关键主题,以防万一。
复制品的放置也非常重要。默认情况下,Kafka 将确保分区的每个副本都位于单独的代理上。但是,在某些情况下,这还不够安全。如果分区的所有副本都放置在同一机架上的代理上,并且架顶式交换机行为异常,则无论复制因素如何,都将失去分区的可用性。为了防止机架级的不幸,我们建议将代理放置在多个机架中,并使用 broker.rack broker 配置参数来配置每个代理的机架名称。如果配置了机架名称,Kafka 将确保分区的副本分布在多个机架上,以保证更高的可用性。在第 5 章中,我们详细介绍了 Kafka 如何在代理和机架上放置副本,如果您有兴趣了解更多信息
6.3.2 不洁的领袖选举
此配置仅在代理级别(实际上在集群范围)级别可用。参数名称为 unclean.leader.election.enable,默认情况下设置为 true。
如前所述,当分区的主节点不再可用时,将选择其中一个同步副本作为新的主节点。从某种意义上说,这种领导者选举是“干净的”,因为它保证不会丢失已提交的数据 — 根据定义,已提交的数据存在于所有同步副本上。
但是,当除了刚刚变得不可用的 leader 之外,不存在任何同步副本时,我们该怎么办? 在以下两种情况之一中,可能会发生这种情况: • 分区有三个副本,两个跟随者变得不可用(假设两个代理崩溃)。在这种情况下,当生产者继续向领导者写入时,所有消息都会被确认并提交(因为领导者是唯一的同步副本)。现在,假设领导者不可用(哎呀,另一个代理崩溃)。在此方案中,如果其中一个不同步的追随者首先启动,则我们有一个不同步的副本作为分区的唯一可用副本。 • 该分区有三个副本,由于网络问题,两个追随者落后了,因此即使他们已启动并复制,他们也不再同步。领导者继续接受消息作为唯一的同步副本。现在,如果主节点不可用,则两个可用副本将不再同步。
在这两种情况下,我们都需要做出一个艰难的决定:
• 如果我们不允许不同步的副本成为新的主节点,则分区将保持脱机状态,直到我们将旧主节点(以及最后一个同步副本)重新联机。在某些情况下(例如,需要更换存储芯片),这可能需要数小时。
• 如果我们允许不同步的副本成为新的领导者,我们将丢失在副本不同步时写入旧领导者的所有消息,并且还会导致使用者出现一些不一致。为什么?想象一下,虽然副本 0 和 1 不可用,但我们将偏移量为 100-200 的消息写入副本 2(然后是前导)。现在,副本 3 不可用,副本 0 重新联机。副本 0 只有消息 0-100,没有 100-200。如果我们允许副本 0 成为新的领导者,它将允许生产者编写新消息并允许消费者读取它们。所以,现在新领导人有全新的消息 100-200。首先,让我们注意,一些消费者可能已经阅读了 100-200 条旧消息,一些消费者获得了 100-200 条新消息,而另一些消费者则两者兼而有之。在查看下游报告等内容时,这可能会导致非常糟糕的后果。此外,复制品 2 将重新上线并成为新领导者的追随者。此时,它将删除它收到的任何位于当前领导者之前的消息。这些消息将来将不会提供给任何消费者。
总之,如果我们允许不同步的副本成为领导者,我们就有可能丢失数据和数据不一致。如果我们不允许它们成为领导者,我们将面临较低的可用性,因为我们必须等待原始领导者可用,然后分区才能重新联机。
将 unclean.leader.election.enable 设置为 true 意味着我们允许不同步的副本成为领导者(称为不干净的选举),因为我们知道当这种情况发生时我们会丢失消息。如果将其设置为 false,则选择等待原始领导者重新联机,从而导致可用性降低。在数据质量和一致性至关重要的系统中,我们通常会看到不干净的领导者选举被禁用(配置设置为 false)——银行系统就是一个很好的例子(大多数银行宁愿在几分钟甚至几小时内无法处理信用卡付款,也不愿冒着处理错误付款的风险)。在可用性更重要的系统中,例如实时点击流分析,通常会启用不干净的领导者选举。
6.3.3 最小同步副本数
主题和代理级配置都称为 min.insync.replicas。正如我们所看到的,在某些情况下,即使我们将一个主题配置为具有三个副本,我们也可能只剩下一个同步副本。如果此副本不可用,我们可能不得不在可用性和一致性之间做出选择。这绝不是一个容易的选择。请注意,部分问题在于,根据 Kafka 的可靠性保证,当数据写入所有同步副本时,即使 all 意味着只有一个副本,如果该副本不可用,数据可能会丢失。
如果要确保将提交的数据写入多个副本,则需要将同步副本的最小数目设置为更高的值。如果一个主题有三个副本,并且您将 min.insync.replicas 设置为 2,则只有在三个副本中至少有两个同步时,您才能写入主题中的分区。
当所有三个副本同步时,一切都会正常进行。如果其中一个副本不可用,也是如此。但是,如果三个副本中的两个不可用,则代理将不再接受生产请求。相反,尝试发送数据的生成者将收到 NotEnoughReplicasException。使用者可以继续读取现有数据。实际上,通过此配置,单个同步副本将变为只读。这防止了产生和消费数据的不良情况,只是在发生不干净的选举时才消失。为了从这种只读情况中恢复,我们必须使两个不可用分区中的一个再次可用(也许重新启动代理),并等待它赶上并同步。
6.4 在可靠的系统中使用生产者
即使我们以最可靠的配置配置代理,如果我们不将生产者配置为可靠,整个系统仍然可能会意外丢失数据。
下面是两个示例方案来演示这一点:
• 我们为代理配置了三个副本,并且禁用了不干净的领导者选举。因此,我们永远不应该丢失任何一条提交到 Kafka 集群的消息。但是,我们将生产者配置为使用 acks=1 发送消息。我们从生产者发送一条消息,它已写入领导者,但尚未写入不同步副本。领导者向生产者发回了回复,说“消息已成功写入”,并在数据复制到其他副本之前立即崩溃。其他副本仍被视为同步(请记住,在声明副本不同步之前需要一段时间),其中一个副本将成为领导者。由于消息未写入副本,因此它将丢失。但是生成应用程序认为它已成功编写。系统是一致的,因为没有消费者看到消息(它从未提交,因为副本从未得到它),但从生产者的角度来看,消息丢失了。
• 我们为代理配置了三个副本,并且禁用了不干净的领导者选举。我们从错误中吸取了教训,并开始使用 acks=all 生成消息。假设我们试图向 Kafka 写入一条消息,但是我们写入的分区的领导者刚刚崩溃,并且仍然有一个新的分区正在选举。Kafka 将回复“Leader not Available”。此时,如果生成者未正确处理错误,并且在写入成功之前不重试,则消息可能会丢失。再一次,这不是代理可靠性问题,因为代理从未收到消息;这不是一个一致性问题,因为消费者也从未得到过信息。但是,如果生产者没有正确处理错误,可能会导致消息丢失。那么,我们如何避免这些悲惨的结果呢?如示例所示,每个编写生成到 Kafka 的应用程序的人都必须注意两件重要的事情:
• 使用正确的 acks 配置来满足可靠性要求
• 正确处理配置和代码中的错误 我们在第 3 章中深入讨论了生产者模式,但让我们再次回顾一下重点。
6.4.1 发送致谢
生产者可以在三种不同的确认模式之间进行选择:
• acks=0 表示如果生产者设法通过网络发送消息,则认为消息已成功写入 Kafka。如果您发送的对象无法序列化或网卡出现故障,您仍然会收到错误,但如果分区处于脱机状态或整个 Kafka 集群决定休长假,则不会收到任何错误。这意味着,即使在预期的干净领导者选举的情况下,您的制作者也会丢失消息,因为它不会知道在选举新领导者时领导者不可用。使用 acks=0 运行非常快(这就是为什么你会看到很多使用此配置的基准测试)。您可以获得惊人的吞吐量并利用大部分带宽,但如果您选择这条路线,您肯定会丢失一些消息。
• acks=1 表示领导者在收到消息并将其写入分区数据文件(但不一定同步到磁盘)的那一刻将发送确认或错误。这意味着,在领导者选举的正常情况下,当领导者当选时,您的生产者将获得 LeaderNotAvailableException,如果生产者正确处理此错误(请参阅下一节),它将重试发送消息,并且消息将安全到达新的领导者。如果主节点崩溃,并且某些已成功写入主节点并确认的消息在崩溃之前未复制到后续消息,则可能会丢失数据。
• acks=all 表示领导者将等到所有同步副本收到消息后再发回确认或错误。结合代理上的 min.insync.replica 配置,这允许您控制在确认消息之前获取消息的副本数。这是最安全的选择 - 在消息完全提交之前,生产者不会停止尝试发送消息。这也是最慢的选项 - 生产者等待所有副本获取所有消息,然后才能将消息批次标记为“完成”并继续。可以通过对生成者使用异步模式和发送更大的批处理来缓解这些影响,但此选项通常会降低吞吐量。
6.4.2 配置创建者重试
在生产者中处理错误分为两部分:生产者自动为您处理的错误,以及您作为使用生产者库的开发人员必须处理的错误。
生产者可以为您处理代理返回的可重试错误。当生产者向代理发送消息时,代理可以返回成功或错误代码。这些错误代码分为两类:重试后可以解决的错误和无法解决的错误。例如,如果代理LEADER_NOT_AVAILABLE返回错误代码,则生产者可以尝试再次发送错误 - 可能选择了新的代理,并且第二次尝试将成功。这意味着 LEADER_NOT_AVAILABLE 是可重试的错误。另一方面,如果代理返回INVALID_CONFIG异常,那么再次尝试相同的消息不会更改配置。这是不可重试错误的示例。
通常,如果您的目标是永不丢失消息,则最佳方法是将生产者配置为在遇到可重试错误时继续尝试发送消息。为什么?因为缺少领导者或网络连接问题等问题通常需要几秒钟才能解决,如果你只是让生产者继续尝试直到成功,你就不需要自己处理这些问题。我经常被问到“我应该将生产者配置为重试多少次?”,答案实际上取决于在生产者抛出重试 N 次并放弃的异常后你打算做什么。如果你的答案是“我会发现异常并重试更多”,那么你肯定需要将重试次数设置得更高,让生产者继续尝试。当答案是“我只删除消息;没有必要继续重试“或”我只是把它写在别的地方,以后再处理。请注意,Kafka 的跨 DC 复制工具(MirrorMaker,我们将在第 8 章中讨论)默认配置为无休止地重试(即重试 = MAX_INT),因为作为一个高度可靠的复制工具,它不应该只是丢弃消息。
请注意,重试发送失败的消息通常会带来一个小风险,即两条消息都已成功写入代理,从而导致重复。例如,如果网络问题阻止了代理确认到达生产者,但消息已成功写入和复制,则生产者会将缺少确认视为临时网络问题,并重试发送消息(因为它无法知道消息已收到)。在这种情况下,代理最终将收到两次相同的消息。重试和仔细的错误处理可以保证每条消息至少存储一次,但在当前版本的 Apache Kafka (0.10.0) 中,我们不能保证它会存储一次。许多实际应用程序为每条消息添加一个唯一标识符,以便在使用消息时检测重复项并清除它们。其他应用程序使消息具有幂等性,这意味着即使发送两次相同的消息,也不会对正确性产生负面影响。例如,消息“帐户值为 110 美元”是幂等的,因为多次发送它不会更改结果。“向帐户添加 10 美元”消息不是幂等的,因为它会在您每次发送时更改结果。
6.4.3 其他错误处理
使用内置的生产者重试是一种在不丢失消息的情况下正确处理各种错误的简单方法,但作为开发人员,您仍然必须能够处理其他类型的错误。这些包括:
• 不可重试的代理错误,例如有关消息大小的错误、授权错误等。
• 在将消息发送到代理之前发生的错误,例如序列化错误
• 当生产者用尽所有重试尝试时发生的错误,或者由于在重试时使用所有可用内存来存储消息而导致生产者使用的可用内存已填满到限制时发生的错误
在第 3 章中,我们讨论了如何为同步和异步消息发送方法编写错误处理程序。这些错误处理程序的内容特定于应用程序及其目标 - 您是否丢弃了“不良消息”?日志错误?将这些消息存储在本地磁盘上的目录中?触发对另一个应用程序的回调?
这些决策特定于您的体系结构。请注意,如果错误处理程序所做的只是重试发送消息,则最好依赖生产者的重试功能
6.5 在可靠的系统中使用消费者
现在我们已经学会了如何在考虑 Kafka 的可靠性保证的同时生成数据,是时候看看如何使用数据了。
正如我们在本章的第一部分所看到的,数据只有在提交到 Kafka 后才可供消费者使用,这意味着它被写入所有同步副本。这意味着消费者获得的数据保证是一致的。消费者唯一要做的就是确保他们跟踪他们阅读了哪些消息,哪些消息没有阅读。这是在使用消息时不丢失消息的关键。
从分区读取数据时,使用者正在获取一批事件,检查批处理中的最后一个偏移量,然后从收到的最后一个偏移量开始请求另一批事件。这保证了 Kafka 使用者将始终以正确的顺序获取新数据,而不会丢失任何事件。
当一个使用者停止时,另一个使用者需要知道从哪里拾取工作 - 前一个使用者在停止之前处理的最后一个偏移量是多少?“其他”使用者甚至可以是重启后的原始使用者。这并不重要 - 一些消费者将从该分区中获取消费,并且它需要知道从哪个偏移量开始。这就是为什么消费者需要“承诺”他们的抵消。对于它正在使用的每个分区,使用者存储其当前位置,因此他们或其他使用者将知道在重新启动后在哪里继续。消费者丢失消息的主要方式是,当他们为已阅读但尚未完全处理的事件提交偏移量时。这样,当另一个使用者拿起工作时,它将跳过这些事件,并且它们永远不会被处理。这就是为什么仔细注意何时以及如何提交偏移量至关重要的原因。
-
已提交消息与已提交偏移量
这与已提交消息不同,如前所述,已提交消息是写入所有同步副本并可供使用者使用的消息。提交偏移量是使用者发送到 Kafka 的偏移量,以确认它接收并处理了分区中的所有消息,直到此特定偏移量。
在第 4 章中,我们详细讨论了消费者 API,并介绍了提交偏移量的许多方法。在这里,我们将介绍一些重要的注意事项和选择,但有关使用 API 的详细信息,请参阅第 4 章。
6.5.1 用于可靠处理的重要使用者配置属性
有四个使用者配置属性非常重要,以便为使用者配置所需的可靠性行为。
第一个是 group.id,正如第4章中详细解释的那样。其基本思想是,如果两个使用者具有相同的组 ID 并订阅了相同的主题,则每个使用者都会被分配该主题中分区的子集,因此只会单独读取消息的子集(但所有消息都将由整个组读取)。如果您需要消费者单独查看其订阅主题中的每条消息,则需要一个唯一的 group.id。
第二个相关配置是 auto.offset.reset。此参数控制当未提交偏移量时(例如,当使用者首次启动时)或当使用者请求代理中不存在的偏移量时,使用者将执行的操作(第 4 章解释了这是如何发生的)。这里只有两个选项。如果选择最早,则使用者将在分区没有有效偏移量时从分区的开头开始。这可能会导致使用者两次处理大量消息,但它可以保证最大限度地减少数据丢失。如果选择“最新”,则使用者将从分区末尾开始。这最大限度地减少了消费者的重复处理,但几乎肯定会导致消费者错过一些消息。
第三个相关配置是 enable.auto.commit。这是一个重大决定:是要让使用者按计划为您提交偏移量,还是计划在代码中手动提交偏移量?自动偏移提交的主要好处是,在实现使用者时,无需担心一件事。如果您在使用者轮询循环中对已使用的记录进行所有处理,则自动偏移量提交可保证您永远不会提交未处理的偏移量。(如果您不确定消费者轮询循环是什么,请参阅第 4 章。自动偏移提交的主要缺点是,您无法控制可能需要处理的重复记录数(因为使用者在处理某些记录后但在自动提交启动之前停止)。如果您做了任何花哨的事情,例如将记录传递到另一个线程以在后台进行处理,则自动提交可能会为使用者已读取但可能尚未处理的记录提交偏移量。
第四个相关配置与第三个相关配置相关联,并且是 auto.commit.interval.ms。如果选择自动提交偏移量,则此配置允许您配置提交偏移量的频率。默认值为每 5 秒一次。通常,更频繁地提交会增加一些开销,但会减少使用者停止时可能发生的重复次数。
6.5.2 在使用者中显式提交偏移量
如果使用自动偏移量提交,则无需担心显式提交偏移量。但是,如果您决定需要对偏移量提交的时间进行更多控制,则需要考虑如何提交偏移量,或者是为了最大程度地减少重复项,或者因为您在主使用者轮询循环之外进行事件处理。
我们不会在这里讨论提交偏移量所涉及的机制和 API,因为它们在第 4 章中进行了深入的介绍。相反,我们将回顾在开发消费者以可靠地处理数据时的重要考虑因素。我们将从简单且可能显而易见的点开始,然后转向更复杂的模式。
-
始终在处理事件后提交偏移量 如果您在轮询循环中执行所有处理,并且不维护轮询循环之间的状态(例如,用于聚合),这应该很容易。您可以在轮询循环结束时使用自动提交配置或提交事件。
-
提交频率是发生崩溃时性能和重复次数之间的权衡 即使在最简单的情况下,即在轮询循环中执行所有处理,并且不维护轮询循环之间的状态,也可以选择在一个循环中多次提交(甚至可能在每个事件之后)或选择仅每几个循环提交一次。提交有一些性能开销(类似于使用 acks=all 的 production),因此这完全取决于适合您的权衡。
-
确保您确切地知道您正在提交哪些偏移量 在轮询循环中间提交时的一个常见陷阱是在轮询时意外提交最后一个偏移读取,而不是处理的最后一个偏移。请记住,在消息处理后始终提交偏移量至关重要 - 为已读但未处理的消息提交偏移量可能会导致使用者丢失消息。第 4 章提供了一些示例来说明如何做到这一点。
-
再平衡 在设计应用程序时,请记住,消费者会发生重新平衡,您需要正确处理它们。第 4 章包含一些示例,但更大的情况是,这通常涉及在撤销分区之前提交偏移量,以及清理在分配新分区时维护的任何状态。
-
使用者可能需要重试 在某些情况下,在调用轮询和处理记录后,某些记录未完全处理,需要稍后处理。例如,您可能尝试将记录从 Kafka 写入数据库,但发现该数据库当时不可用,您可能希望稍后重试。请注意,与传统的发布/订阅消息传递系统不同,您提交偏移量,而不是确认单个消息。这意味着,如果您未能处理记录 #30 并成功处理了记录 #31,则不应提交记录 #31,这将导致提交 #31 之前的所有记录,包括 #30,这通常不是您想要的。相反,请尝试遵循以下两种模式之一。
当您遇到可重试的错误时,一种选择是提交您成功处理的最后一条记录。然后,将仍需要处理的记录存储在缓冲区中(以便下一次轮询不会覆盖它们),并继续尝试处理记录。在尝试处理所有记录时,您可能需要继续轮询(有关说明,请参阅第 4 章)。您可以使用使用者 pause() 方法来确保其他轮询不会返回其他数据,从而更轻松地重试。
第二种选择是,当遇到可重试的错误时,将其写入单独的主题并继续。可以使用单独的使用者组来处理来自重试主题的重试,或者一个使用者可以同时订阅主主题和重试主题,但在重试之间暂停重试主题。此模式类似于许多邮件系统中使用的死信队列系统。
-
使用者可能需要维护状态 在某些应用程序中,需要在多个轮询调用之间维护状态。例如,如果要计算移动平均值,则需要在每次轮询 Kafka 以查找新事件后更新平均值。如果重新启动流程,您不仅需要从最后一个偏移量开始消耗,还需要恢复匹配的移动平均线。一种方法是在提交偏移量的同时将最新的累积值写入“结果”主题。这意味着当线程启动时,它可以在启动时拾取最新的累积值,并从中断的地方拾取。然而,这并不能完全解决问题,因为 Kafka 还没有提供交易。在写入最新结果之后和提交偏移量之前,您可能会崩溃,反之亦然。一般来说,这是一个相当复杂的问题,与其自己解决,不如看看像 Kafka Streams 这样的库,它为聚合、联接、窗口和其他复杂分析提供了类似 DSL 的高级 API。
-
处理时间长
有时处理记录需要很长时间。例如,也许您正在与可以阻塞的服务进行交互,或者执行非常复杂的计算。请记住,在某些版本的 Kafka 使用者中,您不能停止轮询超过几秒钟(有关详细信息,请参见第 4 章)。即使您不想处理其他记录,也必须继续轮询,以便客户端可以将检测信号发送到代理。在这些情况下,一种常见的模式是,如果可能的话,将数据移交给具有多个线程的线程池,以便通过并行处理来加快速度。将记录移交给工作线程后,您可以暂停使用者并继续轮询,而无需实际获取其他数据,直到工作线程完成。完成后,您可以恢复使用者。由于使用者从不停止轮询,因此检测信号将按计划发送,并且不会触发重新平衡.
-
精确一次交付 某些应用程序不仅需要至少一次语义(意味着不会丢失数据),还需要恰好一次语义。虽然 Kafka 目前不提供完整的“恰好一次”支持,但消费者几乎没有一些技巧可以保证 Kafka 中的每条消息都会被写入外部系统一次(请注意,这不会处理在将数据生成到 Kafka 时可能发生的重复)。
最简单且可能最常见的方法是将结果写入对唯一键有一定支持的系统。这包括所有键值存储、所有关系数据库、Elasticsearch,可能还有更多数据存储。将结果写入关系数据库或弹性搜索等系统时,记录本身包含唯一键(这很常见),或者您可以使用主题、分区和偏移量组合创建唯一键,该组合唯一标识 Kafka 记录。如果将记录写入为具有唯一键的值,并且后来又意外地再次使用相同的记录,则只会写入完全相同的键和值。数据存储将覆盖现有数据存储,您将获得与没有意外重复相同的结果。这种模式称为幂等写入,非常常见且有用。
当写入具有事务的系统时,可以使用另一个选项。关系数据库是最简单的例子,但 HDFS 具有原子重命名,通常用于相同的目的。这个想法是在同一事务中写入记录及其偏移量,以便它们保持同步。启动时,检索写入外部存储的最新记录的偏移量,然后使用 consumer.seek() 从这些偏移量中再次开始消费。第 4 章包含如何做到这一点的示例。
6.6 验证系统可靠性
一旦您完成了确定可靠性要求、配置代理、配置客户端以及以最适合您的用例的方式使用 API 的过程,您就可以放松并在生产环境中运行所有内容,确信不会错过任何事件,对吧?
您可以这样做,但我们建议先进行一些验证。我们建议进行三层验证:验证配置、验证应用程序和监视生产中的应用程序。让我们看一下这些步骤中的每一个,看看你需要验证什么以及如何验证。
6.6.1 验证配置
在与应用程序逻辑隔离的情况下测试代理和客户端配置很容易,建议这样做有两个原因: • 它有助于测试您选择的配置是否能满足您的要求。 • 通过系统的预期行为进行推理是一种很好的练习。本章有点理论化,因此检查您对理论在实践中的应用的理解很重要。
Kafka 包含两个重要的工具来帮助进行此验证。org.apache.kafka.tools 包中包括 VerifiableProducer 和 Verifiable Consumer 类。这些工具可以作为命令行工具运行,也可以嵌入到自动化测试框架中。
这个想法是,可验证的生产者生成一系列消息,其中包含从 1 到您选择的值的数字。您可以像配置自己的生产者一样配置它,设置正确的确认次数、重试次数和生成消息的速率。当您运行它时,它将根据收到的确认来打印发送到代理的每条消息的成功或错误。可验证的使用者执行补充检查。它使用事件(通常是由可验证的生产者生成的事件),并按顺序打印出它使用的事件。它还打印有关提交和重新平衡的信息。 您还应该考虑要运行哪些测试。例如: • 领袖选举:如果我杀死了领袖会怎样?生产者和消费者需要多长时间才能重新开始正常工作? • 控制器选择:重新启动控制器后,系统需要多长时间才能恢复? • 滚动重启:我可以在不丢失任何消息的情况下逐个重启代理吗? • 不干净的领导者选举测试:当我们一个接一个地杀死一个分区的所有副本(以确保每个副本都不同步),然后启动一个不同步的代理时会发生什么?为了恢复运营,需要做些什么?这是可以接受的吗? 然后,选择一个方案,启动可验证的生产者,启动可验证的使用者,并运行整个方案,例如,终止要在其中生成数据的分区的领导者。如果您希望短暂暂停,然后一切正常恢复而不会丢失消息,请确保生产者生成的消息数和使用者使用的消息数匹配。 Apache Kafka 源代码存储库包括一个广泛的测试套件。套件中的许多测试都基于相同的原则 - 例如,使用可验证的生产者和使用者来确保滚动升级正常工作。
6.6.2 验证应用程序
一旦您确定您的代理和客户端配置满足您的要求,就该测试您的应用程序是否提供您需要的保证了。这将检查自定义错误处理代码、偏移提交、重新平衡侦听器以及应用程序逻辑与 Kafka 客户端库交互的类似位置等内容。 当然,因为它是您的应用程序,因此我们只能提供这么多关于如何测试它的指导。希望在开发过程中对应用程序进行集成测试。无论验证应用程序如何,我们都建议在各种故障条件下运行测试: • 客户端失去与服务器的连接(系统管理员可以帮助您模拟网络故障) • 领导人选举 • 代理的滚动重启 • 消费者的滚动重启 • 生产者滚动重启 对于每个方案,你都将具有预期的行为,这是你在开发应用程序时计划看到的行为,然后你可以运行测试以查看实际发生的情况。例如,在计划使用者滚动重启时,可以计划在使用者重新平衡时短暂暂停,然后继续使用不超过 1,000 个重复值。您的测试将显示应用程序提交偏移量和处理重新平衡的方式是否真的以这种方式工作。
6.6.3 监控生产中的可靠性
测试应用程序很重要,但它并不能取代持续监控生产系统以确保数据按预期流动的需要。第 9 章将介绍有关如何监控 Kafka 集群的详细建议,但除了监控集群的运行状况外,监控客户端和通过系统的数据流也很重要。
首先,Kafka 的 Java 客户端包含允许监控客户端状态和事件的 JMX 指标。对于生成者来说,可靠性最重要的两个指标是每条记录的错误率和重试率(聚合)。请密切关注这些情况,因为错误率或重试率上升可能表明系统存在问题。此外,还可以监视生成者日志中是否存在发送在 WARN 级别记录的事件时发生的错误,并说出类似“在主题分区 [topic-1,3] 上生成相关 ID 为 5689 的响应时出错,重试(还剩两次尝试)之类的内容。错误:...”。如果看到剩余尝试次数为 0 的事件,则表示生成器的重试次数已用完。根据第 121 页“在可靠系统中使用生产者”一节中的讨论,您可能希望增加重试次数,或者首先解决导致错误的问题。
在消费者方面,最重要的指标是消费者滞后。此衡量指标指示使用者与提交到代理上分区的最新消息之间的距离。理想情况下,滞后始终为零,消费者将始终阅读最新消息。在实践中,由于调用 poll() 会返回多条消息,然后消费者在获取更多消息之前花时间处理它们,因此滞后总是会有所波动。重要的是确保消费者最终能够迎头赶上,而不是越来越落后。由于消费者滞后的预期波动,因此在指标上设置传统警报可能具有挑战性。Burrow是LinkedIn的消费者滞后检查器,可以使这更容易。
监控数据流还意味着确保及时使用所有生成的数据(您的要求将决定“及时方式”的含义)。为了确保及时使用数据,您需要知道数据的生成时间。Kafka 对此有所帮助:从 0.10.0 版本开始,所有消息都包含一个时间戳,用于指示事件的生成时间。如果运行的客户端版本较早,建议记录每个事件的时间戳、生成消息的应用的名称以及创建消息的主机名。这将有助于以后追踪问题的根源。
为了确保在合理的时间内使用所有生成的消息,您将需要生成代码的应用程序来记录生成的事件数(通常为每秒事件数)。使用者既需要记录使用的事件数(也是每秒事件数),还需要使用事件时间戳记录从事件生成时间到使用事件时间的滞后。然后,您将需要一个系统来协调来自生产者和消费者的每秒事件数(以确保在途中不会丢失任何消息),并确保在合理的时间内生成事件的时间间隔。为了更好地进行监视,可以在关键主题上添加监视使用者,该主题将对事件进行计数,并将其与生成的事件进行比较,因此,即使没有人在给定时间点使用事件,也可以准确监视生产者。这些类型的端到端监控系统实施起来可能具有挑战性且耗时。据我们所知,此类系统没有开源实现,但 Confluent 作为 Confluent 控制中心的一部分提供了商业实现。
6.7 总结
正如我们在本章开头所说,可靠性不仅仅是 Kafka 特定功能的问题。您需要构建一个完整的可靠系统,包括应用程序架构、应用程序使用生产者和使用者 API 的方式、生产者和使用者配置、主题配置和代理配置。要使系统更可靠,总是需要在应用程序复杂性、性能、可用性或磁盘空间使用方面进行权衡。通过了解所有选项和常见模式并了解用例的要求,您可以就应用程序和 Kafka 部署所需的可靠性以及哪些权衡对您有意义做出明智的决策。
第七章 构建数据管道
当人们讨论使用 Apache Kafka 构建数据管道时,他们通常会提到几个用例。首先是构建一个数据管道,其中 Apache Kafka 是两个端点之一。例如,将数据从 Kafka 获取到 S3 或将数据从 MongoDB 获取到 Kafka。第二个用例涉及在两个不同的系统之间构建管道,但使用 Kafka 作为中介。例如,将数据从 Twitter 发送到 Elasticsearch,方法是先将数据从 Twitter 发送到 Kafka,然后再从 Kafka 发送到 Elasticsearch。
当我们在 0.9 版本中将 Kafka Connect 添加到 Apache Kafka 之后,是在我们看到 Kafka 在 LinkedIn 和其他大型组织的两个用例中使用之后。我们注意到,将 Kafka 集成到数据管道中存在每个组织都必须解决的特定挑战,因此决定向 Kafka 添加 API 来解决其中一些挑战,而不是强迫每个组织从头开始解决这些问题。
Kafka 为数据管道提供的主要价值在于,它能够在管道的各个阶段之间充当一个非常大、可靠的缓冲区,有效地将管道中数据的生产者和消费者解耦。这种解耦,再加上可靠性、安全性和效率,使 Kafka 非常适合大多数数据管道。
-
将数据集成置于上下文中
一些组织将 Kafka 视为管道的端点。他们着眼于诸如“如何将数据从 Kafka 获取到 Elastic?这是一个合理的问题,特别是如果你在 Elastic 中有需要的数据,而且这些数据目前在 Kafka 中,我们将研究如何做到这一点。但是,我们将通过在更大的上下文中查看 Kafka 的使用来开始讨论,该上下文包括至少两个(可能更多)不是 Kafka 本身的端点。我们鼓励任何面临数据集成问题的人都要考虑大局,而不是只关注眼前的端点。专注于短期集成是您最终导致复杂且维护成本高昂的数据集成混乱的原因。
在本章中,我们将讨论在构建数据管道时需要考虑的一些常见问题。这些挑战并非 Kafka 所特有,而是一般的数据集成问题。尽管如此,我们将展示为什么 Kafka 非常适合数据集成用例,以及它如何解决其中的许多挑战。我们将讨论 Kafka Connect API 与普通的生产者和消费者客户端有何不同,以及何时应该使用每种客户端类型。然后,我们将深入了解 Kafka Connect 的一些细节。虽然对 Kafka Connect 的完整讨论超出了本章的范围,但我们将展示基本用法示例,以帮助您入门,并为您提供在哪里了解更多信息的指导。最后,我们将讨论其他数据集成系统以及它们如何与 Kafka 集成。
7.1 构建数据管道时的注意事项
虽然我们无法在这里详细介绍构建数据管道的所有细节,但我们想强调一些在设计软件架构以集成多个系统时要考虑的最重要的事情。
7.1.1 及时
一些系统希望他们的数据每天大量到达一次;其他人则希望数据在生成后几毫秒到达。大多数数据管道都介于这两个极端之间。良好的数据集成系统可以支持不同管道的不同时效要求,并且随着业务需求的变化,也可以使不同时间表之间的迁移更加容易。Kafka 是一个具有可扩展且可靠存储的流数据平台,可用于支持从近乎实时的管道到每小时批处理的任何内容。生产者可以根据需要频繁和不频繁地写入 Kafka,消费者还可以在最新事件到达时阅读和交付它们。或者消费者可以批量工作:每小时运行一次,连接到 Kafka,并读取前一小时累积的事件。
在这种情况下看待 Kafka 的一个有用方法是,它充当了一个巨大的缓冲区,将生产者和消费者之间的时间敏感性要求解耦。生产者可以实时写入事件,而使用者则处理成批的事件,反之亦然。这也使得施加背压变得微不足道——Kafka 本身对生产者施加背压(在需要时延迟确认),因为消费率完全由消费者驱动。
7.1.2 可靠性
我们希望避免单点故障,并允许从各种故障事件中快速自动恢复。数据管道通常是数据到达关键业务系统的方式;超过几秒钟的故障可能会造成巨大的破坏,尤其是当及时性要求更接近频谱的几毫秒末端时。可靠性的另一个重要考虑因素是交付保证 - 某些系统可以承受丢失数据的后果,但大多数情况下需要至少交付一次,这意味着来自源系统的每个事件都将到达其目的地,但有时重试会导致重复。通常,甚至需要一次付 - 来自源系统的每个事件都将到达目标,而不会丢失或重复。
我们在第 6 章中深入讨论了 Kafka 的可用性和可靠性保证。正如我们所讨论的,Kafka 可以单独提供至少一次,当与具有事务模型或唯一键的外部数据存储结合使用时,可以提供一次。由于许多端点都是数据存储,它们为“恰好一次”交付提供正确的语义,因此基于 Kafka 的管道通常可以作为“恰好一次”实现。值得强调的是,Kafka 的 Connect API 通过提供用于在处理偏移量时与外部系统集成的 API,使连接器能够更轻松地构建端到端的一次性管道。事实上,许多可用的开源连接器都支持“恰好一次”交付。
7.1.3 高吞吐量和变化吞吐量
我们正在构建的数据管道应该能够扩展到非常高的吞吐量,这在现代数据系统中通常是必需的。更重要的是,如果吞吐量突然增加,他们应该能够适应。
由于 Kafka 充当了生产者和消费者之间的缓冲区,我们不再需要将消费者吞吐量与生产者吞吐量耦合。我们不再需要实现复杂的背压机制,因为如果生产者的吞吐量超过消费者的吞吐量,数据就会在 Kafka 中积累,直到消费者能够赶上。Kafka 通过独立添加消费者或生产者进行扩展的能力使我们能够动态且独立地扩展管道的任何一侧,以匹配不断变化的需求。
Kafka 是一个高吞吐量的分布式系统,即使在适度的集群上也能够每秒处理数百兆字节的数据,因此无需担心我们的管道不会随着需求的增长而扩展。此外,Kafka Connect API 专注于并行化工作,而不仅仅是横向扩展。我们将在以下各节中介绍平台如何允许数据源和接收器在多个执行线程之间拆分工作,并使用可用的 CPU 资源,即使在单台计算机上运行时也是如此。
Kafka 还支持多种类型的压缩,允许用户和管理员随着吞吐量要求的增加控制网络和存储资源的使用。
7.1.4 数据格式
数据管道中最重要的考虑因素之一是协调不同的数据格式和数据类型。支持的数据类型因数据库和其他存储系统而异。您可能在 Kafka 中使用 Avro 将 XML 和关系数据加载到 Kafka 中,然后在将数据写入 Elasticsearch 时将数据转换为 JSON,在写入 HDFS 时将数据转换为 Parquet,在写入 S3 时将数据转换为 CSV。
Kafka 本身和 Connect API 在数据格式方面是完全不可知的。正如我们在前几章中所看到的,生产者和使用者可以使用任何序列化程序以适合您的任何格式表示数据。Kafka Connect 有自己的内存对象,包括数据类型和模式,但正如我们即将讨论的那样,它允许可插入转换器允许以任何格式存储这些记录。这意味着,无论您对 Kafka 使用哪种数据格式,它都不会限制您对连接器的选择。
许多源和接收器都有架构;我们可以从包含数据的源中读取架构,存储它,并使用它来验证兼容性,甚至更新接收器数据库中的架构。一个典型的例子是从MySQL到Hive的数据管道。如果有人在 MySQL 中添加了一列,那么当我们将新数据加载到其中时,一个很棒的管道将确保该列也被添加到 Hive 中。
此外,将数据从 Kafka 写入外部系统时,接收器连接器负责将数据写入外部系统的格式。某些连接器选择使此格式可插入。例如,HDFS 连接器允许在 Avro 和 Parquet 格式之间进行选择。
仅仅支持不同类型的数据是不够的;通用数据集成框架还应处理各种源和接收器之间的行为差异。例如,Syslog 是推送数据的源,而关系数据库需要框架来提取数据。HDFS 是仅追加的,我们只能向其写入数据,而大多数系统允许我们追加数据和更新现有记录。
7.1.5 转换
转换比其他要求更具争议性。构建数据管道通常分为两类:ETL 和 ELT。ETL 代表 Extract-Transform-Load,意味着数据管道负责在数据通过时对数据进行修改。它具有节省时间和存储的明显好处,因为您不需要存储数据、修改数据并再次存储数据。根据转换的不同,这种好处有时是真实的,但有时会将计算和存储的负担转移到数据管道本身,这可能是可取的,也可能是不可取的。这种方法的主要缺点是,管道中数据发生的转换束缚了那些希望在管道下游处理数据的人的手。如果在MongoDB和MySQL之间构建管道的人员决定过滤某些事件或从记录中删除字段,则访问MySQL中数据的所有用户和应用程序将只能访问部分数据。如果他们需要访问缺少的字段,则需要重新生成管道,并且需要重新处理历史数据(假设它可用)。
ELT 代表 Extract-Load-Transform,表示数据管道只执行最小的转换(主要围绕数据类型转换),目的是确保到达目标的数据与源数据尽可能相似。 这些也称为高保真管道或数据湖架构。在这些系统中,目标系统收集“原始数据”,所有必需的处理都在目标系统上完成。这样做的好处是,该系统为目标系统的用户提供了最大的灵活性,因为他们可以访问所有数据。这些系统往往也更容易排除故障,因为所有数据处理都局限于一个系统,而不是在管道和其他应用程序之间拆分。缺点是转换会占用目标系统的 CPU 和存储资源。在某些情况下,这些系统成本高昂,并且有强烈的动机在可能的情况下将计算从这些系统中移出。
7.1.6 安全
安全性始终是一个问题。在数据管道方面,主要的安全问题是: • 我们能否确保通过管道的数据是加密的?这主要是针对跨数据中心边界的数据管道的问题。 • 谁可以对管道进行修改? • 如果数据管道需要从访问控制的位置读取或写入,它是否可以正确进行身份验证? Kafka 允许对网络上的数据进行加密,因为它从源到 Kafka 以及从 Kafka 到接收器。它还支持身份验证(通过 SASL)和授权,因此您可以确保如果主题包含敏感信息,则未经授权的人不会将其通过管道传递到安全性较低的系统中。Kafka 还提供审计日志来跟踪未经授权的和授权的访问。通过一些额外的编码,还可以跟踪每个主题中的事件来自何处以及谁修改了它们,因此您可以为每条记录提供整个世系。
7.1.7故障处理
假设所有数据始终是完美的是危险的。提前计划故障处理非常重要。我们能否防止有缺陷的记录进入管道?我们可以从无法解析的记录中恢复吗?不良记录能否得到修复(可能由人工)并重新处理?如果不良事件看起来与正常事件完全相同,而您只是在几天后才发现问题,该怎么办?
由于 Kafka 会长时间存储所有事件,因此可以在需要时及时返回并从错误中恢复。
7.1.8 耦合和敏捷性
数据管道的最重要目标之一是分离数据源和数据目标。意外耦合可能有多种发生方式:
-
临时管道
一些公司最终会为他们想要连接的每对应用程序构建一个自定义管道。例如,他们使用 Logstash 将日志转储到 Elastic-search,使用 Flume 将日志转储到 HDFS,使用 GoldenGate 将数据从 Oracle 转储到 HDFS,使用 Informatica 将数据从 MySQL 和 XML 转储到 Oracle,等等。这会将数据管道与特定端点紧密耦合,并造成一团糟的集成点,需要花费大量精力来部署、维护和监控。这也意味着公司采用的每个新系统都需要建立额外的管道,增加采用新技术的成本,并抑制创新。
-
元数据丢失
如果数据管道不保留架构元数据,并且不允许架构演变,则最终会在源生成数据的软件与在目标位置使用数据的软件紧密耦合。如果没有架构信息,这两种软件产品都需要包含有关如何解析和解释数据的信息。如果数据从 Oracle 流向 HDFS,并且 DBA 在 Oracle 中添加了一个新字段,而没有保留架构信息并允许架构演变,则从 HDFS 读取数据的每个应用程序都将中断,或者所有开发人员都需要同时升级其应用程序。这两种选择都不是敏捷的。通过管道中对架构演变的支持,每个团队都可以按照自己的节奏修改其应用程序,而不必担心事情会中断。
-
极致加工
正如我们在讨论数据转换时提到的,某些数据处理是数据管道固有的。毕竟,我们正在不同的系统之间移动数据,在这些系统中,不同的数据格式是有意义的,并且支持不同的用例。但是,过多的处理会将所有下游系统与构建管道时做出的决策联系起来。决定保留哪些字段、如何聚合数据等。随着下游应用程序需求的变化,这通常会导致管道不断变化,这并不敏捷、高效或安全。更敏捷的方法是尽可能多地保留原始数据,并允许下游应用在数据处理和聚合方面做出自己的决策。
7.2 何时使用 Kafka Connect 与生产者和消费者
在写入 Kafka 或从 Kafka 读取数据时,您可以选择使用传统的生产者和消费者客户端(如第 3 章和第 4 章所述),或者使用 Connect API 和连接器(我们将在下面介绍)。在我们开始深入研究 Connect 的细节之前,有必要停下来问问自己:“我什么时候使用哪个?
正如我们所看到的,Kafka 客户端是嵌入到您自己的应用程序中的客户端。它允许应用程序将数据写入 Kafka 或从 Kafka 读取数据。当可以修改要将应用程序连接到的应用程序的代码时,以及想要将数据推送到 Kafka 或从 Kafka 拉取数据时,请使用 Kafka 客户端。
您将使用 Connect 将 Kafka 连接到您未编写且无法或不会修改其代码的数据存储。Connect 将用于将数据从外部数据存储拉取到 Kafka 中,或将数据从 Kafka 推送到外部存储。对于已存在连接器的数据存储,非开发人员可以使用 Connect,他们只需配置连接器即可。
如果需要将 Kafka 连接到数据存储,但连接器尚不存在,则可以选择使用 Kafka 客户端或 Connect API 编写应用程序。建议使用 Connect,因为它提供了开箱即用的功能,如配置管理、偏移存储、并行化、错误处理、对不同数据类型的支持以及标准管理 REST API。编写一个将 Kafka 连接到数据存储的小型应用程序听起来很简单,但您需要处理许多有关数据类型和配置的小细节,这些细节使任务变得不重要。Kafka Connect 为您处理了大部分工作,让您能够专注于将数据传输到以及来自外部商店。
7.3 Kafka 连接
Kafka Connect 是 Apache Kafka 的一部分,它提供了一种可扩展且可靠的方式来在 Kafka 和其他数据存储之间移动数据。它提供了 API 和运行时来开发和运行连接器插件,这些插件是 Kafka Connect 执行并负责移动数据的库。Kafka Connect 作为工作进程集群运行。在辅助角色上安装连接器插件,然后使用 REST API 配置和管理使用特定配置运行的连接器。连接器启动其他任务以并行移动大量数据,并更有效地使用工作器节点上的可用资源。源连接器任务只需从源系统读取数据,并向工作进程提供 Connect 数据对象。接收器连接器任务从辅助角色获取连接器数据对象,并负责将其写入目标数据系统。Kafka Connect 使用转换器来支持以不同格式在 Kafka 中存储这些数据对象 - JSON 格式支持是 Apache Kafka 的一部分,而 Confluent Schema Registry 提供 Avro 转换器。这允许用户选择数据存储在 Kafka 中的格式,而与他们使用的连接器无关。
本章不可能深入探讨 Kafka Connect 及其许多连接器的所有细节。这本身就可以填满一整本书。但是,我们将概述 Kafka Connect 及其使用方法,并指出其他资源以供参考。
7.3.1 运行 Connect
Kafka Connect 随 Apache Kafka 一起提供,因此无需单独安装。对于生产用途,特别是如果您计划使用 Connect 移动大量数据或运行多个连接器,则应在单独的服务器上运行 Connect。在这种情况下,请在所有机器上安装 Apache Kafka,只需在某些服务器上启动代理,然后在其他服务器上启动 Connect。
启动 Connect worker 与启动代理非常相似 - 使用属性文件调用启动脚本:
bin/connect-distributed.sh config/connect-distributed.properties
Connect 辅助角色有几个关键配置: • bootstrap.servers::Connect 将使用的 Kafka 代理列表。连接器会将其数据通过管道传递到这些代理或从这些代理传递数据。您不需要指定集群中的每个代理,但建议至少指定三个代理。 • group.id::具有相同组 ID 的所有工作线程都属于同一 Connect 集群。在群集上启动的连接器将在任何辅助角色上运行,其任务也将如此。 • key.converter 和 value.converter:: Connect 可以处理存储在 Kafka 中的多种数据格式。这两种配置为将存储在 Kafka 中的消息的键和值部分设置转换器。默认值是使用 Apache Kafka 中包含的 JSONConverter 的 JSON 格式。这些配置也可以设置为 AvroConverter,它是 Confluent 架构注册表的一部分。
一些转换器包括特定于转换器的配置参数。例如,JSON 消息可以包含架构,也可以是无架构的。要支持其中任何一个,您可以分别设置 key.converter.schema.enable=true 或 false。通过将 value.converter.schema.enable 设置为 true 或 false,可以将相同的配置用于值转换器。Avro 消息也包含架构,但您需要使用 key.converter.schema.registry.url 和 value.converter.schema.registry.url.rest.host.name 和 rest.port 连接器配置架构注册表的位置,通常通过 Kafka Connect 的 REST API 进行配置和监控。您可以为 REST API 配置特定端口。
一旦工作线程启动并且您有一个集群,请通过检查 REST API 确保它已启动并运行:
gwen$ curl http://localhost:8083/{"version":"0.10.1.0-SNAPSHOT","commit":"561f45d747cd2a8c"}
访问基本 REST URI 应返回您正在运行的当前版本。我们正在运行 Kafka 0.10.1.0(预发行版)的快照。我们还可以检查哪些连接器插件可用:
gwen$ curl http://localhost:8083/connector-plugins[{"class":"org.apache.kafka.connect.file.FileStreamSourceConnector"},{"class":"org.apache.kafka.connect.file.FileStreamSinkConnector"}]
我们运行的是普通的 Apache Kafka,因此唯一可用的连接器插件是文件源和文件接收器。
让我们看看如何配置和使用这些示例连接器,然后我们将深入研究需要设置外部数据系统才能连接到的更高级示例。
-
独立模式
请注意,Kafka Connect 也具有独立模式。它类似于分布式模式 - 您只需运行 bin/connect-standalone.sh 而不是 bin/connect-distributed.sh。您还可以在命令行上传入连接器配置文件,而不是通过 REST API。在此模式下,所有连接器和任务都在一个独立工作线程上运行。在独立模式下使用 Connect 进行开发和故障排除通常更容易,以及连接器和任务需要在特定计算机上运行的情况(例如,syslog 连接器侦听端口,因此您需要知道它在哪些计算机上运行)。
7.3.2 连接器示例:文件源和文件接收器
此示例将使用属于 Apache Kafka 的文件连接器和 JSON 转换器。要继续操作,请确保您已启动并运行 Zookeeper 和 Kafka。
首先,让我们运行一个分布式 Connect worker。在实际生产环境中,您需要至少运行其中的两个或三个来提供高可用性。在此示例中,我只启动一个:
bin/connect-distributed.sh config/connect-distributed.properties
现在是时候启动文件源了。例如,我们将它配置为读取 Kafka 配置文件——基本上是将 Kafka 的配置通过管道传输到 Kafka 主题中:
echo '{"name":"load-kafka-config", "config":{"connector.class":"FileStream•Source","file":"config/server.properties","topic":"kafka-config-topic"}}' | curl -X POST -d @- http://localhost:8083/connectors --header "content•Type:application/json"{"name":"load-kafka-config","config":{"connector.class":"FileStream•Source","file":"config/server.properties","topic":"kafka-config•topic","name":"load-kafka-config"},"tasks":[]}
为了创建连接器,我们编写了一个 JSON,其中包含连接器名称、load-kafka-config 和连接器配置映射,其中包括连接器类、要加载的文件以及要将文件加载到的主题。
让我们使用 Kafka 控制台使用者来检查我们是否已将配置加载到主题中:
gwen$ bin/kafka-console-consumer.sh --new --bootstrap-server=localhost:9092 --topic kafka-config-topic --from-beginning
如果一切顺利,您应该会看到以下内容:
{"schema":{"type":"string","optional":false},"payload":"# Licensed to the Apache Software Foundation (ASF) under one or more"}<more stuff here>{"schema":{"type":"string","optional":false},"pay•load":"############################# Server Basics #############################"}{"schema":{"type":"string","optional":false},"payload":""}{"schema":{"type":"string","optional":false},"payload":"# The id of the broker. This must be set to a unique integer for each broker."}{"schema":{"type":"string","optional":false},"payload":"broker.id=0"}{"schema":{"type":"string","optional":false},"payload":""}<more stuff here>
从字面上看,这是 config/server.properties 文件的内容,因为它已逐行转换为 JSON,并由我们的连接器放置在 kafka-config-topic 中。请注意,默认情况下,JSON 转换器会在每条记录中放置一个架构。在这种特定情况下,架构非常简单 - 只有一列,名为 payload 类型为 string,并且它包含每条记录的文件中的一行。
现在,让我们使用文件接收器转换器将该主题的内容转储到文件中。生成的文件应与原始 server.properties 文件完全相同,因为 JSON 转换器会将 JSON 记录转换回简单的文本行:
echo '{"name":"dump-kafka-config", "config":{"connector.class":"FileStreamSink","file":"copy-of-server•properties","topics":"kafka-config-topic"}}' | curl -X POST -d @- http://local•host:8083/connectors --header "content-Type:application/json"{"name":"dump-kafka-config","config":{"connector.class":"FileStreamSink","file":"copy-of-server•properties","topics":"kafka-config-topic","name":"dump-kafka-config"},"tasks":[]}
请注意源配置中的更改:我们使用的类现在是 File StreamSink 而不是 FileStreamSource。我们仍然有一个 file 属性,但现在它指的是目标文件而不是记录的源,并且您指定主题,而不是指定主题。请注意多个主题 - 您可以使用接收器将多个主题写入一个文件,而源只允许写入一个主题。
如果一切顺利,您应该有一个名为 copy-of-server-properties 的文件,它与我们用来填充 kafka-config-topic 的 config/server.properties 完全相同。
若要删除连接器,可以运行:
curl -X DELETE http://localhost:8083/connectors/dump-kafka-config
如果在删除连接器后查看 Connect 辅助角色日志,应会看到所有其他连接器重新启动其任务。它们正在重新启动,以便在工作线程之间重新平衡剩余任务,并确保在删除连接器后具有等效的工作负载。
7.3.3 连接器示例:MySQL 到 Elasticsearch
现在我们有了一个简单的示例,让我们做一些更有用的事情。让我们拿一个 MySQL 表,将其流式传输到 Kafka 主题,然后从那里将其加载到 Elasticsearch 并为其内容编制索引。
我们正在MacBook上运行测试。要安装 MySQL 和 Elasticsearch,我们只需运行:
brew install mysqlbrew install elasticsearch
下一步是确保您拥有连接器。如果运行的是 Confluent OpenSource,则应已将连接器作为平台的一部分安装。否则,您可以从 GitHub 构建连接器:
1. Go to https://github.com/confluentinc/kafka-connect-elasticsearch2. Clone the repository3. Run mvn install to build the project4. Repeat with the JDBC connector
现在,获取在构建每个连接器的目标目录下创建的 jar,并将它们复制到 Kafka Connect 的类路径中:
gwen$ mkdir libsgwen$ cp ../kafka-connect-jdbc/target/kafka-connect-jdbc-3.1.0-SNAPSHOT.jar libs/gwen$ cp ../kafka-connect-elasticsearch/target/kafka-connect•elasticsearch-3.2.0-SNAPSHOT-package/share/java/kafka-connect-elasticsearch/* libs/
如果 Kafka Connect 工作程序尚未运行,请确保启动它们,并检查是否列出了新的连接器插件:
gwen$ bin/connect-distributed.sh config/connect-distributed.properties &gwen$ curl http://localhost:8083/connector-plugins[{"class":"org.apache.kafka.connect.file.FileStreamSourceConnector"},{"class":"io.confluent.connect.elasticsearch.ElasticsearchSinkConnector"},{"class":"org.apache.kafka.connect.file.FileStreamSinkConnector"},{"class":"io.confluent.connect.jdbc.JdbcSourceConnector"}]
我们可以看到,现在我们的 Connect 集群中提供了其他连接器插件。JDBC源需要MySQL驱动程序才能使用MySQL。我们从 Oracle 网站下载了适用于 MySQL 的 JDBC 驱动程序,解压缩了包,并在复制连接器时将 mysql-connector-java-5.1.40-bin.jar 复制到 libs/ 目录。
下一步是在 MySQL 中创建一个表,我们可以使用 JDBC 连接器将其流式传输到 Kafka 中:
gwen$ mysql.server restartmysql> create database test;Query OK, 1 row affected (0.00 sec)mysql> use test;Database changedmysql> create table login (username varchar(30), login_time datetime);Query OK, 0 rows affected (0.02 sec)mysql> insert into login values ('gwenshap', now());Query OK, 1 row affected (0.01 sec)mysql> insert into login values ('tpalino', now());Query OK, 1 row affected (0.00 sec)mysql> commit;Query OK, 0 rows affected (0.01 sec)
正如你所看到的,我们创建了一个数据库,一个表,并插入了几行作为示例。
下一步是配置我们的 JDBC 源连接器。我们可以通过查看文档来了解哪些配置选项可用,但我们也可以使用 REST API 来查找可用的配置选项:
gwen$ curl -X PUT -d "{}" localhost:8083/connector-plugins/JdbcSourceConnector/config/validate --header "content-Type:application/json" | python -m json.tool{"configs": [{"definition": {"default_value": "","dependents": [],"display_name": "Timestamp Column Name","documentation": "The name of the timestamp column to useto detect new or modified rows. This column may not benullable.","group": "Mode","importance": "MEDIUM","name": "timestamp.column.name","order": 3,"required": false,"type": "STRING","width": "MEDIUM"},<more stuff>
我们基本上要求 REST API 验证连接器的配置,并向其发送一个空配置。作为回应,我们得到了所有可用配置的 JSON 定义。我们通过 Python 传输输出,使 JSON 更具可读性。
牢记这些信息后,就可以创建和配置我们的 JDBC 连接器了:
echo '{"name":"mysql-login-connector", "config":{"connector.class":"JdbcSource•Connector","connection.url":"jdbc:mysql://127.0.0.1:3306/test?user=root","mode":"timestamp","table.whitelist":"login","vali•date.non.null":false,"timestamp.column.name":"login_time","topic.pre•fix":"mysql."}}' | curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"{"name":"mysql-login-connector","config":{"connector.class":"JdbcSourceConnec•tor","connection.url":"jdbc:mysql://127.0.0.1:3306/test?user=root","mode":"timestamp","table.whitelist":"login","validate.non.null":"false","timestamp.column.name":"login_time","topic.prefix":"mysql.","name":"mysql•login-connector"},"tasks":[]}
让我们通过从 mysql.login 主题中读取数据来确保它正常工作:
gwen$ bin/kafka-console-consumer.sh --new --bootstrap-server=localhost:9092 --topic mysql.login --from-beginning<more stuff>{"schema":{"type":"struct","fields":[{"type":"string","optional":true,"field":"username"},{"type":"int64","optional":true,"name":"org.apache.kafka.connect.data.Time•stamp","version":1,"field":"login_time"}],"optional":false,"name":"login"},"pay•load":{"username":"gwenshap","login_time":1476423962000}}{"schema":{"type":"struct","fields":[{"type":"string","optional":true,"field":"username"},{"type":"int64","optional":true,"name":"org.apache.kafka.connect.data.Time•stamp","version":1,"field":"login_time"}],"optional":false,"name":"login"},"pay•load":{"username":"tpalino","login_time":1476423981000}}
如果收到错误,指出该主题不存在或看不到任何数据,请检查 Connect 辅助角色日志中是否存在错误,例如:
[2016-10-16 19:39:40,482] ERROR Error while starting connector mysql-login•connector (org.apache.kafka.connect.runtime.WorkerConnector:108)org.apache.kafka.connect.errors.ConnectException: java.sql.SQLException: Access denied for user 'root;'@'localhost' (using password: NO)at io.confluent.connect.jdbc.JdbcSourceConnector.start(JdbcSourceConnec•tor.java:78)
需要多次尝试才能正确获取连接字符串。其他问题可能涉及类路径中是否存在驱动程序或读取表的权限。 请注意,在连接器运行时,如果在登录表中插入其他行,则应立即看到它们反映在 mysql.login 主题中。
将 MySQL 数据导入 Kafka 本身就很有用,但让我们通过将数据写入 Elasticsearch 来让事情变得更有趣。
首先,我们启动 Elasticsearch,并通过访问其本地端口来验证它是否已启动:
gwen$ elasticsearch &gwen$ curl http://localhost:9200/{"name" : "Hammerhead","cluster_name" : "elasticsearch_gwen","cluster_uuid" : "42D5GrxOQFebf83DYgNl-g","version" : {"number" : "2.4.1","build_hash" : "c67dc32e24162035d18d6fe1e952c4cbcbe79d16","build_timestamp" : "2016-09-27T18:57:55Z","build_snapshot" : false,"lucene_version" : "5.5.2"},"tagline" : "You Know, for Search"}
现在让我们启动连接器:
echo '{"name":"elastic-login-connector", "config":{"connector.class":"Elastic•searchSinkConnector","connection.url":"http://localhost:9200","type.name":"mysql-data","topics":"mysql.login","key.ignore":true}}' | curl -X POST -d @- http://localhost:8083/connectors --header "content•Type:application/json"{"name":"elastic-login-connector","config":{"connector.class":"Elasticsearch•SinkConnector","connection.url":"http://localhost:9200","type.name":"mysql•data","topics":"mysql.login","key.ignore":"true","name":"elastic-login•connector"},"tasks":[{"connector":"elastic-login-connector","task":0}]}
这里需要解释的配置很少。connection.url 只是我们之前配置的本地 Elasticsearch 服务器的 URL。默认情况下,Kafka 中的每个主题都将成为单独的 Elasticsearch 索引,与主题同名。在主题中,我们需要为我们正在编写的数据定义一个类型。我们假设一个主题中的所有事件都属于同一类型,所以我们只是对 type.name=mysql-data 进行硬编码。我们向 Elasticsearch 写入的唯一主题是 mysql.login。当我们在MySQL中定义表时,我们没有给它一个主键。因此,Kafka 中的事件具有 null 键。由于 Kafka 中的事件缺少键,因此我们需要告诉 Elasticsearch 连接器使用主题名称、分区 ID 和偏移量作为每个事件的键。
让我们检查一下是否创建了包含 mysql.login 数据的索引:
gwen$ curl 'localhost:9200/_cat/indices?v'health status index pri rep docs.count docs.deleted store.size pri.store.sizeyellow open mysql.login 5 1 3 0 10.7kb 10.7kb
如果索引不存在,请在 Connect 辅助角色日志中查找错误。缺少配置或库是导致错误的常见原因。如果一切顺利,我们可以在索引中搜索我们的记录:
gwen$ curl -s -X "GET" "http://localhost:9200/mysql.login/_search?pretty=true"{"took" : 29,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"failed" : 0},"hits" : {"total" : 3,"max_score" : 1.0,"hits" : [ {"_index" : "mysql.login","_type" : "mysql-data","_id" : "mysql.login+0+1","_score" : 1.0,"_source" : {"username" : "tpalino","login_time" : 1476423981000}}, {"_index" : "mysql.login","_type" : "mysql-data","_id" : "mysql.login+0+2","_score" : 1.0,"_source" : {"username" : "nnarkede","login_time" : 1476672246000}}, {"_index" : "mysql.login","_type" : "mysql-data","_id" : "mysql.login+0+0","_score" : 1.0,"_source" : {"username" : "gwenshap","login_time" : 1476423962000}} ]}}
如果在 MySQL 中向表添加新记录,它们将自动出现在 Kafka 的 mysql.login 主题和相应的 Elasticsearch 索引中。
现在,我们已经了解了如何构建和安装 JDBC 源代码和 Elasticsearch 接收器,我们可以构建和使用适合我们用例的任意一对连接器。Confluent 维护着我们所知道的所有连接器的列表,包括由公司和社区连接器编写和支持的连接器。您可以在列表中选择要试用的任何连接器,从 GitHub 存储库构建它,配置它(基于文档或从 REST API 拉取配置),然后在 Connect 工作器群集上运行它。
-
构建自己的连接器
连接器 API 是公共的,任何人都可以创建新的连接器。事实上,这就是大多数连接器成为连接器中心的一部分的方式——人们构建了连接器并向我们介绍了它们。因此,如果您希望与之集成的数据存储在应用中心中不可用,我们建议您编写自己的数据存储。您甚至可以将其贡献给社区,以便其他人可以发现和使用它。讨论构建连接器所涉及的所有细节超出了本章的范围,但您可以在官方文档中了解它。我们还建议将现有连接器视为起点,并可能使用 maven archtype 进行快速启动。我们始终鼓励您在 Apache Kafka 社区邮件列表 (users@kafka.apache.org) 上寻求帮助或展示您最新的连接器。
7.3.4 深入了解 Connect
要了解 Connect 的工作原理,您需要了解三个基本概念以及它们如何交互。正如我们之前所解释的,并通过示例演示了如何使用 Connect,您需要运行一个工作线程集群和启动/停止连接器。我们之前没有深入研究的另一个细节是转换器对数据的处理——这些是将 MySQL 行转换为 JSON 记录的组件,连接器将其写入 Kafka 中。
让我们更深入地了解每个系统以及它们如何相互交互。
-
连接器和任务 连接器插件实现了连接器 API,该 API 包括两部分:
-
连接 连接器负责三件重要的事情:
-
确定将为连接器运行多少个任务
-
决定如何在任务之间拆分数据复制工作
-
从工作线程获取任务的配置并将其传递
例如,JDBC 源连接器将连接到数据库,发现要复制的现有表,并据此决定需要多少个任务 - 选择 max.tasks 配置和表数中的较低者。一旦它决定了将运行多少个任务,它将为每个任务生成一个配置,同时使用连接器配置(例如 connection.url)和它为每个要复制的任务分配的表列表。taskConfigs() 方法返回映射列表(即我们要运行的每个任务的配置)。然后,工作线程负责启动任务并为每个任务提供自己唯一的配置,以便从数据库中复制唯一的表子集。请注意,当您通过 REST API 启动连接器时,它可以在任何节点上启动,随后它启动的任务也可能在任何节点上执行。
-
-
任务 任务负责实际将数据传入和传出 Kafka。所有任务都是通过接收来自工作线程的上下文来初始化的。源上下文包括一个对象,该对象允许源任务存储源记录的偏移量(例如,在文件连接器中,偏移量是文件中的位置;在 JDBC 源连接器中,偏移量可以是表中的主键 ID)。接收器连接器的上下文包括允许连接器控制从 Kafka 接收的记录的方法,这些方法用于应用背压,以及在外部重试和存储偏移量,以便精确一次交付。初始化任务后,将使用 Properties 对象启动,该对象包含 Connector 为任务创建的配置。任务启动后,源任务将轮询外部系统,并返回工作线程发送到 Kafka 代理的记录列表。接收器任务通过工作线程从 Kafka 接收记录,并负责将记录写入外部系统。
-
-
工人 Kafka Connect 的工作进程是执行连接器和任务的“容器”进程。它们负责处理定义连接器及其配置的 HTTP 请求,以及存储连接器配置、启动连接器及其任务以及传递相应的配置。如果工作进程停止或崩溃,Connect 集群中的其他工作线程将识别该进程(使用 Kafka 使用者协议中的检测信号),并将在该工作线程上运行的连接器和任务重新分配给其余工作线程。如果新工作线程加入 Connect 集群,其他工作线程会注意到这一点,并向其分配连接器或任务,以确保所有工作线程之间的负载公平平衡。辅助角色还负责自动提交源连接器和接收器连接器的偏移量,并在任务引发错误时处理重试。
了解工作线程的最佳方式是认识到连接器和任务负责数据集成的“移动数据”部分,而工作线程负责 REST API、配置管理、可靠性、高可用性、扩展和负载均衡。
与传统的使用者/生产者 API 相比,这种关注点分离是使用 Connect API 的主要优势。有经验的开发人员知道,编写从 Kafka 读取数据并将其插入数据库的代码可能需要一两天的时间,但如果您需要处理配置、错误、REST API、监控、部署、纵向扩展和缩减以及处理故障,则可能需要几个月的时间才能正确完成。如果使用连接器实现数据复制,则连接器将插入到处理大量无需担心的复杂操作问题的工作线程中。
-
Converters and Connect 的数据模型 Connect API 的最后一块拼图是连接器数据模型和转换器。Kafka 的 Connect API 包括一个数据 API,该 API 包括数据对象和描述该数据的架构。例如,JDBC 源从数据库中读取一列,并根据数据库返回的列的数据类型构造 Connect Schema 对象。然后,它使用架构构造一个包含数据库记录中所有字段的 Struct。对于每一列,我们将列名和值存储在该列中。每个源连接器都执行类似的操作 - 从源系统读取事件并生成一对 Schema 和 Value。接收器连接器则相反,获取架构和值对,并使用架构分析值并将其插入目标系统。
尽管源连接器知道如何基于数据 API 生成对象,但仍然存在一个问题,即 Connect worker 如何在 Kafka 中存储这些对象。这就是转换器的用武之地。当用户配置工作线程(或连接器)时,他们会选择要用于在 Kafka 中存储数据的转换器。目前,可用的选项是 Avro、JSON 或字符串。JSON 转换器可以配置为在结果记录中包含架构或不包含架构,因此我们可以同时支持结构化和半结构化数据。当连接器将数据 API 记录返回给辅助角色时,辅助角色随后使用配置的转换器将记录转换为 Avro 对象、JSON 对象或字符串,然后将结果存储到 Kafka 中。
接收器连接器会发生相反的过程。当 Connect worker 从 Kafka 读取记录时,它会使用配置的转换器将记录从 Kafka 中的格式(即 Avro、JSON 或字符串)转换为 Connect Data API 记录,然后将其传递到接收器连接器,接收器连接器将其插入到目标系统中。
这允许 Connect API 支持存储在 Kafka 中的不同类型的数据,而与连接器实现无关(即,只要转换器可用,任何连接器都可以与任何记录类型一起使用)。
-
偏移管理
偏移管理是辅助角色为连接器执行的便捷服务之一(除了通过 REST API 进行部署和配置管理)。这个想法是,连接器需要知道它们已经处理了哪些数据,并且它们可以使用 Kafka 提供的 API 来维护有关哪些事件已经处理的信息。对于源连接器,这意味着连接器返回给 Connect worker 的记录包括逻辑分区和逻辑偏移量。这些不是 Kafka 分区和 Kafka 偏移量,而是源系统中需要的分区和偏移量。例如,在文件源中,分区可以是文件,偏移量可以是文件中的行号或字符号。在 JDBC 源中,分区可以是数据库表,偏移量可以是表中记录的 ID。编写源连接器所涉及的最重要的设计决策之一是确定一种在源系统中对数据进行分区和跟踪偏移量的好方法,这将影响连接器可以实现的并行度级别,以及它是否可以提供至少一次或恰好一次的语义。
当源连接器返回记录列表(包括每条记录的源分区和偏移量)时,工作线程会将记录发送到 Kafka 代理。如果代理成功确认了记录,则工作线程将存储它发送到 Kafka 的记录的偏移量。存储机制是可插拔的,通常是 Kafka 主题。这允许连接器在重新启动或崩溃后从最近存储的偏移量开始处理事件。
接收器连接器具有相反但相似的工作流:它们读取 Kafka 记录,这些记录已具有主题、分区和偏移标识符。然后,他们调用连接器 put() 方法,该方法应将这些记录存储在目标系统中。如果连接器报告成功,则使用通常的使用者提交方法将提供给连接器的偏移量提交回 Kafka。
框架本身提供的偏移跟踪应该使开发人员更容易编写连接器,并保证在使用不同连接器时具有某种程度的一致行为。
7.4 Kafka Connect 的替代品
到目前为止,我们已经非常详细地研究了 Kafka 的 Connect API。虽然我们喜欢 Connect API 提供的便利性和可靠性,但它们并不是进出 Kafka 获取数据的唯一方法。让我们看看其他替代方案以及它们何时常用。
7.4.1 为其他数据存储载入框架
虽然我们喜欢认为卡夫卡是宇宙的中心,但有些人不同意。有些人围绕Hadoop或Elasticsearch等系统构建大部分数据架构。这些系统有自己的数据摄取工具——Flume for Hadoop 和 Logstash 或 Fluentd for Elasticsearch。当 Kafka 是体系结构不可或缺的一部分,并且目标是连接大量源和接收器时,我们建议使用 Kafka 的 Connect API。如果你实际上正在构建一个以Hadoop为中心或以Elastic为中心的系统,而Kafka只是该系统的众多输入之一,那么使用Flume或Logstash是有意义的。
7.4.2 基于 GUI 的 ETL 工具
从 Informatica 等老式系统、Talend 和 Pentaho 等开源替代方案,甚至 Apache NiFi 和 StreamSets 等更新的替代方案,都支持 Apache Kafka 作为数据源和目标。如果您已经在使用这些系统,那么使用它们就很有意义了——例如,如果您已经使用 Pentaho 完成了所有工作,您可能对仅为 Kafka 添加另一个数据集成系统不感兴趣。如果您使用基于 GUI 的方法来构建 ETL 管道,它们也很有意义。这些系统的主要缺点是,它们通常是为涉及的工作流而构建的,如果您只想在 Kafka 中获取数据,那么它们将是一个有点繁重且复杂的解决方案。正如第 139 页的“转换”部分所提到的,我们认为数据集成应该专注于在所有条件下忠实地传递消息,而大多数 ETL 工具会增加不必要的复杂性。我们鼓励您将 Kafka 视为一个可以处理数据集成(使用 Connect)、应用程序集成(与生产者和消费者)和流处理的平台。Kafka 可以替代仅集成数据存储的 ETL 工具。
7.4.3 流处理框架
几乎所有的流处理框架都包括从 Kafka 读取事件并将其写入其他一些系统的能力。如果您的目标系统受支持,并且您已经打算使用该流处理框架来处理来自 Kafka 的事件,那么使用相同的框架进行数据集成似乎是合理的。这通常会节省流处理工作流中的一个步骤(无需将处理后的事件存储在 Kafka 中,只需将它们读出并写入另一个系统即可),其缺点是更难对丢失和损坏的消息等问题进行故障排除。
7.5 总结
在本章中,我们讨论了如何使用 Kafka 进行数据集成。首先介绍了使用 Kafka 进行数据集成的原因,然后介绍了数据集成解决方案的一般注意事项。我们展示了为什么我们认为 Kafka 及其 Connect API 非常适合。然后,我们举了几个例子来说明如何在不同的场景中使用 Kafka Connect,花了一些时间研究 Connect 是如何工作的,然后讨论了 Kafka Connect 的一些替代方案。
无论您最终采用哪种数据集成解决方案,最重要的功能始终是它能够在所有故障条件下传递所有消息。我们相信 Kafka Connect 非常可靠——基于它与 Kafka 久经考验的可靠性功能的集成——但重要的是你要像我们一样测试你选择的系统。确保您选择的数据集成系统能够在进程停止、计算机崩溃、网络延迟和高负载的情况下幸存下来,而不会丢失任何消息。毕竟,数据集成系统只有一项工作——传递这些消息。
当然,虽然可靠性通常是集成数据系统时最重要的要求,但这只是一项要求。在选择数据系统时,首先要查看您的要求(有关示例,请参阅第 136 页上的“构建数据管道时的注意事项”),然后确保您选择的系统满足这些要求。但这还不够,您还必须充分了解您的数据集成解决方案,以确保您正在以支持您的需求的方式使用它。Kafka 支持至少一次语义是不够的;您必须确保不会意外地以可能最终不完全可靠的方式配置它。
第八章 跨集群数据镜像
在本书的大部分内容中,我们将讨论单个 Kafka 集群的设置、维护和使用。但是,在一些情况下,体系结构可能需要多个群集。
在某些情况下,集群是完全分开的。它们属于不同的部门或不同的用例,没有理由将数据从一个集群复制到另一个集群。有时,不同的 SLA 或工作负载使得调整单个集群以服务于多个用例变得困难。其他时候,有不同的安全要求。这些用例相当简单 — 管理多个不同的集群与多次运行单个集群相同。
在其他用例中,不同的集群是相互依赖的,管理员需要在集群之间不断复制数据。在大多数数据库中,在数据库服务器之间连续复制数据称为复制。由于我们使用“复制”来描述属于同一集群的 Kafka 节点之间的数据移动,因此我们将 Kafka 集群之间的数据复制称为镜像。Apache Kafka 内置的跨集群复制器称为 MirrorMaker。
在本章中,我们将讨论全部或部分数据的跨集群镜像。我们将首先讨论跨集群镜像的一些常见用例。然后,我们将展示一些用于实现这些用例的架构,并讨论每种架构模式的优缺点。然后,我们将讨论 MirrorMaker 本身以及如何使用它。我们将分享操作技巧,包括部署和性能调优。最后,我们将讨论 MirrorMaker 的一些替代方案。
8.1 跨集群镜像的用例
以下是何时使用跨集群镜像的示例列表。
-
区域和中央集群 在某些情况下,公司在不同的地理区域、城市或大陆拥有一个或多个数据中心。每个数据中心都有自己的 Kafka 群集。某些应用程序只需与本地群集通信即可工作,但某些应用程序需要来自多个数据中心的数据(否则,您将不会考虑跨数据中心复制解决方案)。在很多情况下,这是一项要求,但典型的例子是一家根据供需关系修改价格的公司。该公司可以在其所在的每个城市拥有一个数据中心,收集有关当地供需的信息,并相应地调整价格。然后,所有这些信息将被镜像到一个中央集群,业务分析师可以在其中运行公司范围的收入报告。
-
冗余 (DR) 应用程序仅在一个 Kafka 集群上运行,不需要来自其他位置的数据,但您担心整个集群可能由于某种原因而不可用。您希望拥有第二个 Kafka 集群,其中包含第一个集群中存在的所有数据,因此在紧急情况下,您可以将应用程序定向到第二个集群并像往常一样继续。
-
云迁移 如今,许多公司都在本地数据中心和云提供商中开展业务。通常,应用程序在云提供商的多个区域上运行,以实现冗余,有时还会使用多个云提供商。在这些情况下,每个本地数据中心和每个云区域中通常至少有一个 Kafka 集群。每个数据中心和区域中的应用程序使用这些 Kafka 群集在数据中心之间高效传输数据。例如,如果新应用程序部署在云中,但需要一些数据,这些数据由本地数据中心运行的应用程序更新并存储在本地数据库中,则可以使用 Kafka Connect 将数据库更改捕获到本地 Kafka 集群,然后将这些更改镜像到云 Kafka 集群,新应用程序可以在其中使用它们。这有助于控制跨数据中心流量的成本,并改善流量的治理和安全性。
8.2 多集群架构
现在我们已经看到了一些需要多个 Kafka 集群的用例,让我们看看我们在实现这些用例时成功使用的一些常见架构模式。在介绍体系结构之前,我们将简要概述跨数据中心通信的现实情况。我们将要讨论的解决方案可能看起来过于复杂,而不了解它们在面对特定网络条件时需要权衡取舍。
8.2.1 跨数据中心通信的一些现实
以下是跨数据中心通信时要考虑的一些事项的列表:
-
高延迟 两个 Kafka 集群之间的通信延迟随着两个集群之间的距离和网络跳数的增加而增加。
-
带宽有限 广域网 (WAN) 的可用带宽通常远低于您在单个数据中心内看到的带宽,并且可用带宽可能每分钟都在变化。此外,更高的延迟使得利用所有可用带宽更具挑战性。
-
成本较高 无论您是在本地还是在云中运行 Kafka,集群之间的通信成本都会更高。这在一定程度上是因为带宽有限,增加带宽的成本可能高得令人望而却步,还因为供应商在数据中心、区域和云之间传输数据所收取的价格。
Apache Kafka 的代理和客户端都在单个数据中心内进行设计、开发、测试和调整。我们假设代理和客户端之间的低延迟和高带宽。这在默认超时和各种缓冲区的大小调整中很明显。因此,不建议(除非在特定情况下,我们将在后面讨论)在一个数据中心安装一些 Kafka 代理,而在另一个数据中心安装其他代理。
在大多数情况下,最好避免向远程数据中心生成数据,并且这样做时,需要考虑更高的延迟和更多网络错误的可能性。您可以通过增加生产者重试次数来处理错误,并通过增加在尝试发送记录之间保存记录的缓冲区的大小来处理更高的延迟。
如果我们需要集群之间的任何类型的复制,并且我们排除了代理间通信和生产者-代理通信,那么我们必须允许代理-消费者通信。事实上,这是最安全的跨集群通信形式,因为在网络分区阻止消费者读取数据的情况下,记录在 Kafka 代理中保持安全,直到通信恢复并且消费者可以读取它们。不存在因网络分区而意外丢失数据的风险。尽管如此,由于带宽有限,如果一个数据中心中有多个应用程序需要从另一个数据中心的 Kafka 代理读取数据,我们更愿意在每个数据中心安装一个 Kafka 集群,并在它们之间镜像一次必要的数据,而不是让多个应用程序在 WAN 中使用相同的数据。我们将详细讨论如何调整 Kafka 以实现跨数据中心通信,但以下原则将指导我们接 下来将讨论的大多数体系结构: • 每个数据中心不少于一个集群 • 在每对数据中心之间复制每个事件一次(除非因错误而重试) • 如果可能,请从远程数据中心使用,而不是生产到远程数据中心
8.2.2 中心辐射型体系结构
此体系结构适用于存在多个本地 Kafka 集群和一个中央 Kafka 集群的情况。请参见图 8-1。

图 8-1. 中心辐射型体系结构
此体系结构还有一个更简单的变体,只有两个集群 - 一个领导者和一个追随者。请参见图 8-2。

图 8-2. 中心辐射型体系结构的简单版本
当数据在多个数据中心生成并且某些使用者需要访问整个数据集时,将使用此体系结构。该体系结构还允许每个数据中心中的应用程序仅处理该特定数据中心的本地数据。但它不会提供对每个数据中心的整个数据集的访问。
此体系结构的主要优点是,数据始终生成到本地数据中心,并且每个数据中心的事件仅镜像一次,即镜像到中央数据中心。处理来自单个数据中心的数据的应用程序可以位于该数据中心。需要处理来自多个数据中心的数据的应用程序将位于镜像所有事件的中央数据中心。由于复制始终朝一个方向进行,并且每个使用者始终从同一集群读取数据,因此此体系结构易于部署、配置和监控。
这种架构的主要缺点是其优点和简单性的直接结果。一个区域数据中心中的处理器无法访问另一个区域数据中心的数据。为了更好地理解为什么这是一个限制,让我们看一下这个架构的一个示例。
假设我们是一家大型银行,在多个城市设有分支机构。假设我们决定将用户配置文件及其帐户历史记录存储在每个城市的 Kafka 集群中。我们将所有这些信息复制到一个中央集群,用于运行银行的业务分析。当用户连接到银行网站或访问其本地分行时,系统会路由他们向本地集群发送事件,并从同一本地集群读取事件。但是,假设用户访问不同城市的分支机构。由于用户信息在他访问的城市中并不存在,因此分支将被迫与远程集群进行交互(不推荐),或者无法访问用户的信息(真的很尴尬)。因此,此模式的使用通常仅限于可在区域数据中心之间完全分离的数据集部分。
实现此体系结构时,对于每个区域数据中心,中央数据中心上至少需要一个镜像进程。此过程将使用来自每个远程区域集群的数据,并将其生成到中央集群。如果多个数据中心存在同一主题,则可以将该主题中的所有事件写入中央群集中一个同名的主题,也可以将每个数据中心的事件写入单独的主题。
8.2.3 主动-主动架构
当两个或多个数据中心共享部分或全部数据,并且每个数据中心都能够生成和使用事件时,将使用此体系结构。请参见图 8-3。
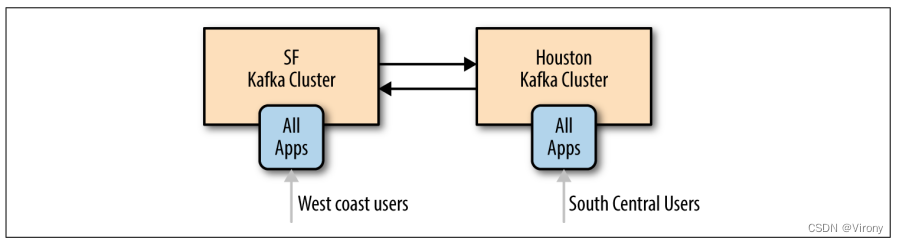
图 8-3. 主动-主动架构模型
此体系结构的主要优点是能够从附近的数据中心为用户提供服务,这通常具有性能优势,而不会因数据可用性有限而牺牲功能(正如我们在中心辐射型体系结构中看到的那样)。第二个好处是冗余和弹性。由于每个数据中心都具有所有功能,因此,如果一个数据中心不可用,则可以将用户定向到其余数据中心。这种类型的故障转移只需要用户的网络重定向,通常是最简单、最透明的故障转移类型。
此体系结构的主要缺点是在多个位置异步读取和更新数据时,难以避免冲突。这包括镜像事件的技术挑战,例如,我们如何确保同一事件不会无休止地来回镜像?但更重要的是,在两个数据中心之间保持数据一致性将很困难。以下是您将遇到的困难的几个例子:
• 如果用户将事件发送到一个数据中心,并从另一个数据中心读取事件,则他们编写的事件可能尚未到达第二个数据中心。对于用户来说,看起来他只是将一本书添加到他的愿望清单中,点击了愿望清单,但这本书不在那里。因此,当使用此体系结构时,开发人员通常会找到一种方法将每个用户“粘贴”到特定的数据中心,并确保他们大多数时间使用相同的群集(除非他们从远程位置连接或数据中心不可用)。 • 来自一个数据中心的事件表示用户订购了图书 A,而来自第二个数据中心的或多或少同一时间的事件表示同一用户订购了图书 B。镜像后,两个数据中心都有两个事件,因此我们可以说每个数据中心都有两个冲突的事件。两个数据中心上的应用程序都需要知道如何处理这种情况。我们是否选择一个事件作为“正确”事件?如果是这样,我们需要关于如何选择一个的一致规则,以便两个数据中心上的应用程序得出相同的结论。我们是否认为两者都是真的,只是简单地向用户发送两本书,并让另一个部门处理退货?亚马逊过去常常以这种方式解决冲突,但例如,处理股票交易的组织却不能。最小化冲突并在冲突发生时处理冲突的具体方法特定于每个用例。重要的是要记住,如果你使用这种架构,你会遇到冲突,需要处理它们。
如果您找到了处理从多个位置异步读取和写入同一数据集的挑战的方法,则强烈建议使用此体系结构。它是我们所知道的最具可扩展性、弹性、灵活性和成本效益的选择。因此,找出避免复制周期、将用户大部分保留在同一数据中心以及在发生冲突时处理冲突的解决方案是非常值得的。
主动-主动镜像(尤其是对于两个以上的数据中心)的部分挑战是,每对数据中心和每个方向都需要一个镜像过程。使用 5 个数据中心时,需要维护至少 20 个镜像进程,更有可能维护 40 个,因为每个进程都需要冗余才能实现高可用性。
此外,您还需要避免无休止地来回镜像同一事件的循环。为此,可以为每个数据中心提供每个“逻辑主题”一个单独的主题,并确保避免复制源自远程数据中心的主题。例如,逻辑主题用户将是一个数据中心的主题 SF.users,另一个数据中心的 NYC.users。镜像过程会将主题 SF.users 从 SF 镜像到 NYC,并将主题 NYC.users 从 NYC 镜像到 SF。因此,每个事件只会镜像一次,但每个数据中心将同时包含 SF.users 和 NYC.users,这意味着每个数据中心将包含所有用户的信息。如果消费者希望使用所有用户事件,则需要使用 .users 中的事件。考虑此设置的另一种方法是将其视为每个数据中心的单独命名空间,其中包含特定数据中心的所有主题。在我们的示例中,我们将有 NYC 和 SF 命名空间。
请注意,在不久的将来(也许在你阅读本书之前),Apache Kafka 将添加记录标头。这将允许使用事件的原始数据中心标记事件,并使用此标头信息来避免无休止的镜像循环,并允许单独处理来自不同数据中心的事件。您仍然可以通过使用记录值的结构化数据格式来实现此功能(Avro 是我们最喜欢的示例),并使用它来在事件本身中包含标记和标头。但是,这在镜像时确实需要额外的努力,因为现有的镜像工具都不支持您的特定标头格式。
8.2.4 主备架构
在某些情况下,对多个集群的唯一要求是支持某种灾难场景。也许你在同一数据中心有两个群集。您将一个集群用于所有应用程序,但您需要另一个集群,该集群包含原始集群中(几乎)所有事件,如果原始集群完全不可用,则可以使用这些事件。或者,也许您需要地理弹性。您的整个业务都在加利福尼亚州的数据中心运行,但您需要在德克萨斯州建立第二个数据中心,该数据中心通常不会做太多事情,并且可以在发生地震时使用。德克萨斯州数据中心可能会有一个非活动(“冷”)副本,管理员可以在紧急情况下启动这些应用程序,这些应用程序将使用第二个群集(图 8-4)。这通常是法律要求,而不是企业实际计划做的事情,但您仍然需要做好准备。

图 8-4. 主备架构
这种设置的好处是设置简单,而且它几乎可以在任何用例中使用。您只需安装第二个集群并设置一个镜像过程,将所有事件从一个集群流式传输到另一个集群。无需担心数据访问、冲突处理和其他架构复杂性。
缺点是浪费了一个好的集群,而且 Kafka 集群之间的故障转移实际上比看起来要困难得多。最重要的是,目前不可能在 Kafka 中执行集群故障转移,而不会丢失数据或发生重复事件。通常两者兼而有之。您可以最小化它们,但永远不要完全消除它们。
很明显,一个除了等待灾难之外什么都不做的集群是浪费资源。由于灾难是(或应该是)罕见的,大多数时候我们看到的是一个什么都不做的机器集群。一些组织试图通过拥有比生产集群小得多的 DR(灾难恢复)集群来解决这个问题。但这是一个冒险的决定,因为您无法确定这个最小大小的集群在紧急情况下是否能够支撑。其他组织更愿意通过将一些只读工作负载转移到 DR 集群上运行,使集群在非灾难期间有用,这意味着他们实际上是在运行具有单个分支的中心辐射型体系结构的小型版本。
更严重的问题是,如何在 Apache Kafka 中故障转移到 DR 集群?
首先,不言而喻,无论您选择哪种故障转移方法,您的 SRE 团队都必须定期练习它。今天有效的计划可能会在升级后停止工作,或者新的用例可能会使现有工具过时。每季度一次通常是故障转移实践的最低要求。强大的 SRE 团队练习的频率要高得多。Netflix 著名的 Chaos Monkey 服务是一种随机造成灾难的服务,它是极端的——任何一天都可能成为故障转移练习日。
现在,让我们看一下故障转移涉及的内容。
-
计划外故障转移中的数据丢失和不一致
由于 Kafka 的各种镜像解决方案都是异步的(我们将在下一节中讨论同步解决方案),因此 DR 集群将没有来自主集群的最新消息。您应该始终监控 DR 集群落后的程度,切勿让它落后太远。但是,在繁忙的系统中,您应该期望 DR 集群比主集群落后几百条甚至几千条消息。如果您的 Kafka 集群每秒处理 100 万条消息,并且主集群和 DR 集群之间有 5 毫秒的延迟为 5 毫秒,则在最佳情况下,您的 DR 集群将落后主集群 5,000 条消息。因此,请为计划外故障转移做好准备,以包括一些数据丢失。在计划的故障转移中,您可以停止主集群并等待镜像进程镜像剩余消息,然后再将应用程序故障转移到 DR 集群,从而避免此数据丢失。当发生计划外故障转移并且您丢失了几千条消息时,请注意 Kafka 目前没有事务的概念,这意味着如果多个主题中的某些事件彼此相关(例如,销售和行项目),您可以让一些事件及时到达 DR 站点以进行故障转移,而其他事件则没有。故障转移到 DR 群集后,您的应用程序将需要能够处理没有相应销售的行项目。
-
故障转移后应用程序的起始偏移量
故障转移到另一个集群时最具挑战性的部分是确保应用程序知道从哪里开始使用数据。有几种常见的方法。有些很简单,但可能会导致额外的数据丢失或重复处理;其他人则更复杂,但最大限度地减少了额外的数据丢失和重新处理。让我们来看看其中的几个:
Apache Kafka 使用者有一个配置,用于在他们之前没有提交的偏移量时的行为方式 - 他们要么从分区的开头开始读取,要么从分区的末尾开始读取。如果您使用的是将偏移量提交到 Zookeeper 的旧使用者,并且您没有以某种方式将这些偏移量镜像为 DR 计划的一部分,则需要选择其中一个选项。要么从可用数据的开头开始读取并处理大量重复数据,要么跳到最后并错过未知(希望是少量)事件。如果您的应用程序处理重复项没有问题,或者丢失某些数据没什么大不了的,那么此选项是迄今为止最简单的。简单地跳到有关故障转移的主题的末尾可能仍然是最流行的故障转移方法。
如果您使用的是新的(0.9 及更高版本)Kafka 使用者,则使用者会将其偏移量提交到一个特殊主题:__consumer_offsets。如果将此主题镜像到 DR 集群,则当使用者开始从 DR 集群消费时,他们将能够拾取旧的偏移量,并从上次中断的地方继续。这很简单,但涉及一长串注意事项。
首先,不能保证主集群中的偏移量与辅助集群中的偏移量相匹配。假设您只在主集群中存储数据三天,并在创建主题一周后开始镜像该主题。在这种情况下,主集群中的第一个可用偏移量可能是 57000000(较旧的事件来自前 4 天,并且已被删除),但 DR 集群中的第一个偏移量将为 0。因此,尝试从 DR 群集读取偏移量57000003(因为这是其要读取的下一个事件)的使用者将无法执行此操作。
其次,即使您在首次创建主题时立即开始镜像,并且主主题和 DR 主题都以 0 开头,生产者重试也可能导致偏移量偏离。简而言之,没有现有的 Kafka 镜像解决方案可以保留主集群和 DR 集群之间的偏移量。
第三,即使偏移量被完美地保留下来,由于主集群和 DR 集群之间的滞后,并且由于 Kafka 当前缺少事务,Kafka 使用者提交的偏移量也可能通过此偏移量提前或落后于记录。故障转移的使用者可能会找到没有匹配记录的已提交偏移量。或者,它可能会发现 DR 站点中的最新提交偏移量比主站点中的最新提交偏移量早。请参见图 8-5。
-
自动偏移复位
-
复制偏移量主题
-
-

-
图 8-5. 故障转移会导致提交的偏移量没有匹配的记录
-
-
在这些情况下,如果 DR 站点中最新提交的偏移量早于主站点上提交的偏移量,或者 DR 站点中记录中的偏移量由于重试而领先于主站点,则需要接受一些重复项。您还需要弄清楚如何处理 DR 站点中最新提交的偏移量没有匹配记录的情况 - 您是从主题的开头开始处理,还是跳到最后?
-
外部偏移映射 在讨论镜像偏移主题时,该方法面临的最大挑战之一是主集群和 DR 集群中的偏移量可能会有所不同。考虑到这一点,一些组织选择使用外部数据存储(如 Apache Cassandra)来存储从一个集群到另一个集群的偏移映射。他们构建了自己的 Kafka 镜像工具,以便每当向 DR 集群生成事件时,这两个偏移量都会发送到外部数据存储。或者,它们仅在两个偏移量之间的差值发生变化时才存储这两个偏移量。例如,如果主节点上的偏移量 495 映射到 DR 群集上的偏移量 500,我们将在外部存储中记录 (495,500)。如果差异后来由于重复而发生变化,并且偏移量 596 映射到 600,那么我们将记录新的映射 (596,600)。
无需存储 495 和 596 之间的所有偏移映射;我们只是假设差异保持不变,因此主集群中的偏移量 550 将映射到 DR 中的 555。然后,当发生故障转移时,它们不会将时间戳(总是有点不准确)映射到偏移量,而是将主偏移量映射到 DR 偏移量并使用这些偏移量。他们使用上面列出的两种技术之一来强制使用者开始使用映射中的新偏移量。这仍然存在一个问题,即在记录本身之前到达的偏移提交以及未按时镜像到 DR 的偏移提交,但它涵盖了一些情况。
这个解决方案非常复杂,在我看来几乎不值得付出额外的努力。它可以追溯到索引存在之前,可用于故障转移。这些天来,我选择升级群集并使用基于时间的解决方案,而不是进行映射偏移工作,这仍然无法涵盖所有故障转移情况。
-
-
如您所见,这种方法有其局限性。尽管如此,与其他方法相比,此选项仍允许您故障转移到另一个 DR,减少重复或丢失事件的数量,同时仍然易于实现。
一种选择是将其直接烘焙到您的应用程序中。具有用户可配置的选项来指定应用程序的开始时间。如果配置了此项,则应用可以使用新的 API 按时间提取偏移量,查找到该时间,然后从正确的点开始使用,像往常一样提交偏移量。
如果您提前以这种方式编写所有应用程序,则此选项非常有用。但如果你不这样做呢?编写一个采用时间戳的小工具,使用新的 API 获取此时间戳的偏移量,然后将这些偏移量作为特定的使用者组提交到主题和分区列表中,这相当简单。我们希望在不久的将来将这个工具添加到 Kafka 中,但也可以自己编写一个。在运行此类工具时,应停止使用者组,并在运行后立即启动。
对于使用新版本 Kafka 的用户,建议使用此选项,他们希望在故障转移中具有一定的确定性,并愿意围绕该过程编写一些自定义工具。
-
基于时间的故障转移 如果您使用的是真正新的(0.10.0 及更高版本)Kafka 使用者,则每条消息都包含一个时间戳,指示消息发送到 Kafka 的时间。在真正新的 Kafka 版本(0.10.1.0 及更高版本)中,代理包含一个索引和一个 API,用于按时间戳查找偏移量。因此,如果您故障转移到 DR 集群,并且您知道您的故障始于凌晨 4:05,则可以告诉使用者从凌晨 4:03 开始处理数据。这两分钟会有一些重复,但它可能比其他替代方案更好,而且这种行为更容易向公司中的每个人解释——“我们未能回到凌晨 4 点 03 分”听起来比“我们未能恢复到可能是也可能不是最新承诺的偏移量”要好得多。因此,这通常是一个很好的折衷方案。唯一的问题是:我们如何告诉消费者从凌晨 4:03 开始处理数据?
-
-
故障转移后
假设故障转移成功。DR 集群上一切正常。现在我们需要对主集群做一些事情。也许把它变成一个DR。 人们很容易简单地修改镜像进程以反转其方向,然后简单地开始从新的主服务器镜像到旧的主服务器。但是,这导致了两个重要问题: • 我们怎么知道从哪里开始镜像?对于镜像应用程序本身,我们需要解决所有消费者面临的相同问题。请记住,我们所有的解决方案都存在导致重复或丢失数据的情况,通常两者兼而有之。 • 此外,由于我们上面讨论的原因,您的原始主节点可能会发生 DR 群集没有的事件。如果刚开始镜像新数据,则将保留额外的历史记录,并且两个群集将不一致。
因此,最简单的解决方案是首先抓取原始集群 - 删除所有数据和提交的偏移量,然后开始从新的主集群镜像回现在的新 DR 集群。这为您提供了一个与新主数据库相同的全新石板
-
关于集群发现的几句话
规划备用群集时要考虑的要点之一是,在发生故障转移时,应用程序需要知道如何开始与故障转移群集进行通信。如果在 producer 和 consumer 属性中对主集群代理的主机名进行硬编码,这将具有挑战性。大多数组织保持简单,并创建一个通常指向主代理的 DNS 名称。在紧急情况下,可以将 DNS 名称指向备用集群。发现服务(DNS 或其他)不需要包含所有代理 - Kafka 客户端只需成功访问单个代理即可获取有关集群的元数据并发现其他代理。因此,通常只包括三个经纪人是可以的。无论采用何种发现方法,大多数故障转移方案都需要在故障转移后反弹使用者应用程序,以便它们可以找到开始使用所需的新偏移量。
8.2.5 延伸群集
主备架构用于保护业务免受 Kafka 集群故障的影响,方法是在集群发生故障时移动应用程序与另一个集群进行通信。延伸群集旨在保护 Kafka 群集在整个数据中心发生故障时不会发生故障。他们通过跨多个数据中心安装单个 Kafka 群集来实现此目的。
延伸群集与其他多数据中心方案有根本的不同。首先,它们不是多集群,而只是一个集群。因此,我们不需要镜像过程来保持两个集群同步。像往常一样,使用 Kafka 的正常复制机制来保持集群中的所有代理同步。此设置可以包括同步复制。生产者通常会在消息成功写入 Kafka 后收到来自 Kafka 代理的确认。在 Stretch 集群的情况下,我们可以进行配置,以便在消息成功写入两个数据中心的 Kafka 代理后发送确认。这涉及使用机架定义来确保每个分区在多个数据中心中都有副本,并使用 min.isr 和 acks=all 来确保至少从两个数据中心确认每次写入。
此体系结构的优点在于同步复制 — 某些类型的业务仅要求其 DR 站点始终与主站点 100% 同步。这通常是一项法律要求,适用于整个公司的任何数据存储,包括 Kafka。另一个优点是同时使用数据中心和群集中的所有代理。没有像我们在主动-备用架构中看到的那样的浪费。
此体系结构在它所防范的灾难类型上受到限制。它只能防止数据中心故障,而不能防止任何类型的应用程序或 Kafka 故障。操作的复杂性也是有限的。这种架构需要并非所有公司都能提供的物理基础设施。
如果可以在至少三个数据中心中安装 Kafka(和 Zookeeper),并且它们之间具有高带宽和低延迟,则此体系结构是可行的。如果您的公司在同一条街道上拥有三座建筑物,或者更常见的情况是,在云提供商的一个区域内使用三个可用区,则可以执行此操作。
三个数据中心之所以重要,是因为 Zookeeper 需要群集中的节点数量不等,如果大多数节点可用,则 Zookeeper 将保持可用。如果有两个数据中心和节点数量不等,则一个数据中心将始终包含大多数,这意味着如果此数据中心不可用,则 Zookeeper 不可用,而 Kafka 不可用。使用三个数据中心,可以轻松分配节点,因此没有一个数据中心占多数。因此,如果一个数据中心不可用,则其他两个数据中心中存在大多数节点,并且 Zookeeper 群集将保持可用。因此,Kafka 集群也是如此。
可以使用允许在两个数据中心之间手动故障转移的 Zookeeper 组配置在两个数据中心运行 Zookeeper 和 Kafka。但是,这种设置并不常见。
8.3 Apache Kafka 的 MirrorMaker
Apache Kafka 包含一个简单的工具,用于在两个数据中心之间镜像数据。它被称为 MirrorMaker,其核心是使用者的集合(由于历史原因,在 MirrorMaker 文档中称为流),它们都属于同一个使用者组,并从您选择复制的主题集中读取数据。每个 MirrorMaker 进程都有一个生产者。工作流程非常简单:Mirror-Maker 为每个消费者运行一个线程。每个使用者使用源集群上分配给它的主题和分区中的事件,并使用共享生产者将这些事件发送到目标集群。每 60 秒(默认情况下),消费者会告诉生产者将其拥有的所有事件发送到 Kafka,并等待 Kafka 确认这些事件。然后,使用者联系源 Kafka 集群以提交这些事件的偏移量。这样可以保证不会丢失数据(在将偏移量提交到源之前,Kafka 会确认消息),并且如果 MirrorMaker 进程崩溃,重复的次数不会超过 60 秒。请参见图 8-6。
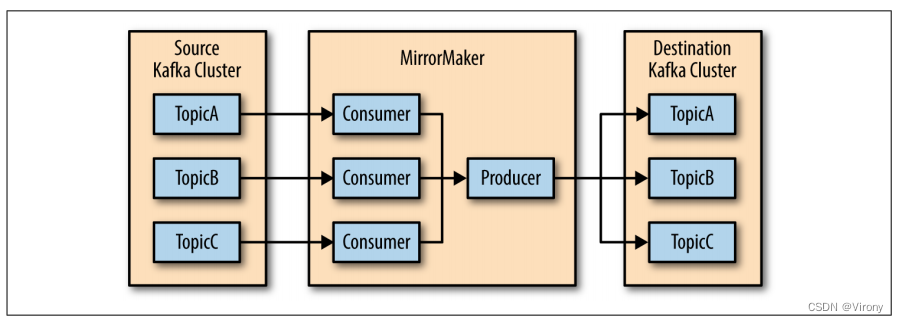
图 8-6. Kafka 中的 MirrorMaker 进程
-
有关 MirrorMaker 的更多信息
MirrorMaker 听起来很简单,但由于我们试图非常高效并非常接近一次交付,因此很难正确实现。在 Apache Kafka 的 0.10.0.0 版本中,MirrorMaker 已经重写了四次。将来也可能发生其他写入。此处的描述和以下各节中的详细信息适用于 MirrorMaker,因为它存在于版本 0.9.0.0 到 版本 0.10.2.0 之间。
8.3.1 如何配置
MirrorMaker 是高度可配置的。首先,它使用一个生产者和多个消费者,因此在配置 MirrorMaker 时,可以使用生产者和消费者的每个配置属性。此外,MirrorMaker 本身有一个相当大的配置选项列表,有时它们之间有复杂的依赖关系。我们将在这里展示一些示例,并重点介绍一些重要的配置选项,但 MirrorMaker 的详尽文档超出了我们的范围。
考虑到这一点,让我们看一个 MirrorMaker 示例:
bin/kafka-mirror-maker --consumer.config etc/kafka/consumer.properties --producer.config etc/kafka/producer.properties --new.consumer --num.streams=2 --whitelist ".*"
让我们一一看一下 MirrorMaker 的基本命令行参数:
-
consumer.config (消费者.config) 这是将从源集群获取数据的所有使用者的配置。它们都共享一个配置文件,这意味着您只能有一个源集群和一个 group.id。因此,所有消费者都将成为同一消费群体的一部分,这正是我们想要的。文件中的必需配置是 bootstrap.servers(用于源集群)和 group.id。但是,您可以为使用者使用所需的任何其他配置。您不想触及的一个配置是 auto.commit.enable=false。MirrorMaker 依赖于它在偏移量安全到达目标 Kafka 集群后提交自己的偏移量的能力。更改此设置可能会导致数据丢失。您确实要更改的一个配置是 auto.offset.reset。这默认为“latest”,这意味着 MirrorMaker 将仅镜像在 MirrorMaker 启动后到达源集群的事件。如果还想镜像现有数据,请将其更改为最早。我们将在第 175 页的“调整 MirrorMaker”一节中讨论其他配置属性。
-
producer.config MirrorMaker 用于写入目标集群的生产者的配置。唯一的强制配置是 bootstrap.servers(对于目标集群)。我们将在第 175 页的“调整 MirrorMaker”一节中讨论其他配置属性。
-
new.consumer MirrorMaker 可以使用 0.8 使用者或新的 0.9 使用者。我们推荐 0.9 使用者,因为它在这一点上更稳定。
-
num.streams 正如我们之前所解释的,每个流都是从源集群读取的另一个使用者。请记住,同一 MirrorMaker 进程中的所有使用者共享相同的生产者。需要多个流才能使生产者饱和。如果在此之后需要额外的吞吐量,则需要另一个 MirrorMaker 进程。
-
白名单 将要镜像的主题名称的正则表达式。所有与正则表达式匹配的主题名称都将被镜像。在此示例中,我们选择复制每个主题,但通常最好使用类似 prod.* 的内容并避免复制测试主题。或者,在主动-主动体系结构中,从 NYC 数据中心复制到 SF 数据中心的 MirrorMaker 将配置白名单=“NYC.*”,并避免复制源自 SF 的主题
8.3.2 在生产环境中部署 MirrorMaker
在前面给出的示例中,我们将 MirrorMaker 作为命令行实用程序运行。通常,在生产环境中运行 MirrorMaker 时,您需要将 MirrorMaker 作为服务运行,在后台使用 nohup 运行,并将其控制台输出重定向到日志文件。从技术上讲,该工具将 -daemon 作为命令行选项,应该为您完成上述所有操作,但实际上,这在最近的版本中并没有按预期工作。
大多数使用 MirrorMaker 的公司都有自己的启动脚本,其中还包括他们使用的配置参数。Ansible、Puppet、Chef 和 Salt 等生产部署系统通常用于自动部署和管理许多配置选项和文件。
一个非常流行的更高级的部署选项是在 Docker 容器中运行 Mirror‐Maker。MirrorMaker 是完全无状态的,不需要任何磁盘存储(所有数据和状态都存储在 Kafka 本身中)。在 Docker 中包装 MirrorMaker 还允许在一台机器上运行多个实例。由于单个 MirrorMaker 实例仅限于单个生产者的吞吐量,因此启动多个 MirrorMaker 实例通常很重要,而 Docker 使它变得更加容易。它还使扩展和缩减变得更加容易 - 在高峰时段需要更多吞吐量时旋转额外的容器,并在流量较少时旋转它们。如果您在云环境中运行 MirrorMaker,您甚至可以根据吞吐量和需求启动额外的服务器来运行容器。
如果可能,请在目标数据中心运行 MirrorMaker。因此,如果您要将数据从纽约市发送到旧金山,MirrorMaker 应该在旧金山运行,并从纽约市使用美国各地的数据。这样做的原因是,远距离网络可能不如数据中心内的网络安全可靠。如果存在网络分区,并且数据中心之间断开连接,则使用者无法连接到群集比无法连接的生产者安全得多。如果消费者无法连接,它将无法读取事件,但事件仍将存储在源 Kafka 集群中,并且可以在那里保留很长时间。没有丢失事件的风险。另一方面,如果事件已经被使用,并且 MirrorMaker 由于网络分区而无法生成它们,则始终存在这些事件被 MirrorMaker 意外丢失的风险。因此,远程消费比远程生产更安全。
什么时候必须本地消费和远程生产?答案是,当数据在数据中心之间传输时需要加密数据,但不需要加密数据中心内的数据。当使用SSL加密连接到Kafka时,消费者会受到显著的性能影响,这比生产者要严重得多。而这种性能打击也影响了 Kafka 代理本身。如果跨数据中心流量需要加密,最好将 Mirror‐Maker 放置在源数据中心,让它在本地使用未加密的数据,然后通过 SSL 加密连接将其生成到远程数据中心。这样一来,生产者就使用 SSL 连接到 Kafka,而不是使用者,这不会对性能产生太大影响。如果在本地使用此功能并远程生成,请确保使用 acks=all 和足够次数的重试来配置 MirrorMaker,使其永远不会丢失事件。此外,将 MirrorMaker 配置为在无法发送事件时退出,这通常比继续并冒着数据丢失的风险更安全。
如果源集群和目标集群之间的延迟非常低很重要,您可能希望在两个不同的服务器上运行至少两个 MirrorMaker 实例,并且让它们都使用相同的使用者组。如果一台服务器因任何原因停止,MirrorMaker 实例可以继续镜像数据。在生产环境中部署 MirrorMaker 时,请务必记住按如下方式对其进行监控:
-
滞后监控 您肯定想知道目标集群是否落后于源集群。滞后是源 Kafka 中的最新消息与目标中的最新消息之间的偏移量之差。请参见图 8-7。
-
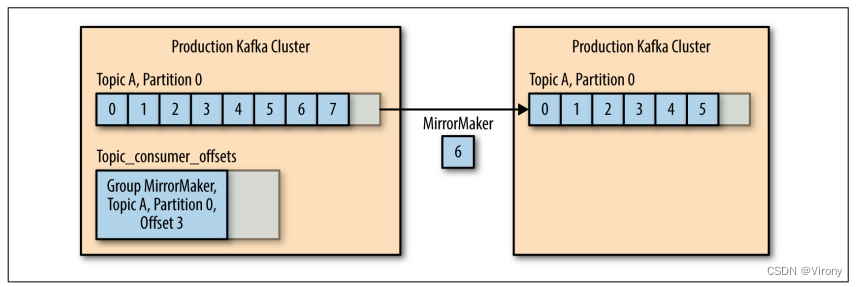
-
图 8-7. 监控偏移量中的滞后差异
在图 8-7 中,源集群中的最后一个偏移量为 7,目标群集中的最后一个偏移量为 5,这意味着存在 2 条消息的滞后。有两种方法可以跟踪这种滞后,但都不是完美的:
请注意,如果 MirrorMaker 跳过或删除消息,则这两种方法都不会检测到问题,因为它们只跟踪最新的偏移量。Confluent 的控制中心监控消息计数和校验和,并弥补这一监控差距。
-
检查 MirrorMaker 向源 Kafka 集群提交的最新偏移量。您可以使用 kafka-consumer-groups 工具检查 MirrorMaker 正在读取的每个分区 — 分区中最后一个事件的偏移量、MirrorMaker 提交的最后一个偏移量以及它们之间的滞后。此指标不是 100% 准确的,因为 MirrorMaker 不会一直提交偏移量。默认情况下,它每分钟提交一次偏移量,因此您会看到延迟增长一分钟,然后突然下降。在图中,实际滞后为 2,但 kafka-consumer-groups 工具将报告滞后 4,因为 MirrorMaker 尚未为最近的消息提交偏移量。LinkedIn的Burrow监控相同的信息,但有一种更复杂的方法来确定滞后是否代表真正的问题,所以你不会收到错误的警报。
-
检查 MirrorMaker 读取的最新偏移量(即使未提交)。MirrorMaker 中嵌入的使用者在 JMX 中发布关键指标。其中之一是使用者最大滞后(在它消耗的所有分区上)。这种滞后也不是 100% 准确的,因为它是根据使用者读取的内容更新的,但没有考虑生产者是否设法将这些消息发送到目标 Kafka 集群,以及它们是否被成功确认。在此示例中,MirrorMaker 使用者将报告延迟 1 条消息而不是 2 条消息,因为它已经读取了消息 6,即使该消息尚未生成到目标。
-
-
指标监控 MirrorMaker 包含一个生产者和一个消费者。两者都有许多可用的指标,我们建议收集和跟踪它们。Kafka 文档列出了所有可用的指标。以下是一些被证明对调整 MirrorMaker 性能有用的指标:
-
消费者 fetch-size-avg、fetch-size-max、fetch-rate、fetch-throttle-time-avg 和 fetch-throttle-time-max。
-
生产者 batch-size-avg、batch-size-max、Requests-in-Progress 和 record-retry-rate。
-
兼两者 IO 比率和 IO 等待比率。
-
-
金丝雀
如果您监控其他所有内容,金丝雀并不是绝对必要的,但我们喜欢将其添加到多层监控中。它提供了一个进程,该进程每分钟向源集群中的特殊主题发送一个事件,并尝试从目标集群读取该事件。如果事件到达所需的时间超过可接受的时间,它还会提醒您。这可能意味着 MirrorMaker 滞后或根本不存在。
8.3.3 调整 MirrorMaker
MirrorMaker 群集的大小取决于所需的吞吐量和可以容忍的延迟。如果不能容忍任何延迟,则必须调整 MirrorMaker 的大小,使其具有足够的容量,以跟上您的最高吞吐量。如果您可以容忍一些延迟,则可以将 MirrorMaker 的大小调整为 75-80% 的 95-99% 利用率。然后,当您处于峰值吞吐量时,预计会出现一些延迟。由于 MirrorMaker 大部分时间都有闲置容量,因此一旦高峰期结束,它就会赶上。
然后,您希望使用不同数量的使用者线程(使用 num.streams 参数配置)测量从 MirrorMaker 获得的吞吐量。我们可以给你一些大致的数字(LinkedIn 在 8 个消费者线程下获得 6MB/s,在 16 个使用者线程下获得 12MB/s),但由于这在很大程度上取决于您的硬件、数据中心或云提供商,因此您需要运行自己的测试。Kafka 附带了 kafka-performance-producer 工具。使用它在源集群上生成负载,然后连接 MirrorMaker 并开始镜像此负载。使用 1、2、4、8、16、24 和 32 个使用者线程测试 MirrorMaker。观察性能逐渐减弱的位置,并将 num.streams 设置在此点下方。如果要使用或生成压缩事件(推荐,因为带宽是跨数据中心镜像的主要瓶颈),则 MirrorMaker 必须解压缩并重新压缩事件。这会占用大量 CPU,因此在增加线程数时请密切关注 CPU 利用率。使用此过程,您将找到使用单个 MirrorMaker 实例可以获得的最大吞吐量。如果这还不够,您将需要尝试其他实例,然后尝试其他服务器。
此外,您可能希望将敏感主题(那些绝对需要低延迟且镜像必须尽可能靠近源的主题)分离到具有自己的使用者组的单独 MirrorMaker 集群。这将防止臃肿的主题或失控的生产者减慢您最敏感的数据管道的速度。
这几乎是您可以对 MirrorMaker 本身进行的所有调整。但是,您仍然可以增加每个使用者线程和每个 MirrorMaker 实例的吞吐量。 如果跨数据中心运行 MirrorMaker,则需要优化 Linux 中的网络配置,如下所示: • 增加 TCP 缓冲区大小(net.core.rmem_default、net.core.rmem_max、net.core.wmem_default、net.core.wmem_max、net.core.optmem_max) • 启用自动窗口缩放(sysctl –w net.ipv4.tcp_window_scaling=1 或将 net.ipv4.tcp_window_scaling=1 添加到 /etc/sysctl.conf) • 减少 TCP 慢启动时间(将 /proc/sys/net/ipv4/tcp_slow_start_after_idle 设置为 0) 请注意,调整 Linux 网络是一个庞大而复杂的主题。要了解有关这些参数和其他参数的更多信息,我们建议阅读网络调优指南,例如 Sandra K. Johnson 等人 (IBM Press) 编写的 Performance Tuning for Linux Servers。
此外,您可能希望调整在 MirrorMaker 中运行的生产者和使用者。首先,您需要确定是生产者还是消费者是瓶颈——生产者是在等待消费者带来更多数据,还是相反?做出决定的一种方法是查看您正在监控的生产者和消费者指标。如果一个进程处于空闲状态,而另一个进程被充分利用,您就知道哪个进程需要调整。另一种方法是执行多个线程转储(使用 jstack),并查看 MirrorMaker 线程是否将大部分时间花在轮询或发送上——轮询时间越长通常意味着使用者是瓶颈,而花在向生产者发送移位点上的时间更多。
如果需要调整生产者,以下配置设置可能很有用:
-
max.in.flight.requests.per.connection 默认情况下,Mi rrorMaker 只允许一个正在进行的请求。这意味着在发送下一条消息之前,生产者发送的每个请求都必须得到目标集群的确认。这可能会限制吞吐量,尤其是在代理确认消息之前存在明显延迟的情况下。MirrorMaker 限制正在进行的请求数的原因是,这是保证 Kafka 在成功确认某些消息需要多次重试时保持消息顺序的唯一方法。如果消息顺序对您的使用案例并不重要,则增加 max.in.flight.requests.per.connection 可以显著提高吞吐量。
-
linger.ms 和 batch.size 如果您的监控显示生产者始终发送部分空批处理(即 batch-size-avg 和 batch-size-max 指标低于配置的 batch.size),您可以通过引入一些延迟来提高吞吐量。增加 latency.ms,生产商将等待几毫秒,让批次装满,然后再发送。如果要发送完整批处理并且有备用内存,则可以增加 batch.size 并发送更大的批处理。 以下使用者配置可以提高吞吐量。
以下使用者配置可以提高使用者的吞吐量:
-
MirrorMaker 中的分区分配策略(即决定为哪个使用者分配哪些分区的算法)默认为 range。范围策略有好处,这就是为什么它是使用者的正常默认值,但它可能导致分区分配给使用者的不均匀。对于 Mirror‐Maker,通常最好将策略更改为轮询,尤其是在镜像大量主题和分区时。您可以通过将 partition.assignment.strategy=org.apache.kafka.clients.consumer.RoundRobinAssignor 添加到使用者属性文件来设置此设置。
-
fetch.max.bytes - 如果您收集的指标显示 fetch-size-avg 和 fetch-size-max 接近 fetch.max.bytes 配置,则使用者将从代理读取允许的数据量。如果您有可用内存,请尝试增加 fetch.max.bytes,以允许使用者在每个请求中读取更多数据。
-
fetch.min.bytes 和 fetch.max.wait - 如果您在使用者指标中看到提取率很高,则消费者向代理发送了太多请求,并且在每个请求中没有收到足够的数据。尝试增加 fetch.min.bytes 和 fetch.max.wait,以便消费者将在每个请求中接收更多数据,并且代理将等待足够的数据可用,然后再响应消费者请求。
8.4 其他跨集群镜像解决方案
我们深入研究了 MirrorMaker,因为这个镜像软件是作为 Apache Kafka 的一部分提供的。但是,MirrorMaker 在实践中使用时也有一些局限性。值得一看的是 MirrorMaker 的一些替代品以及它们解决 MirrorMaker 局限性和复杂性的方法。
8.4.1 优步 uReplicator
Uber 以非常大规模的方式运行 MirrorMaker,随着主题和分区数量的增长以及集群吞吐量的增加,他们开始遇到以下问题:
-
再平衡延迟 MirrorMaker 消费者只是消费者。添加 MirrorMaker 线程、添加 MirrorMaker 实例、跳出 MirrorMaker 实例,甚至添加与白名单中使用的正则表达式匹配的新主题,都会导致消费者重新平衡。正如我们在第 4 章中看到的,重新平衡会停止所有使用者,直到可以为每个使用者分配新的分区。对于非常多的主题和分区,这可能需要一段时间。当像 Uber 那样使用老消费者时尤其如此。在某些情况下,这会导致 5-10 分钟的不活动状态,导致镜像滞后并积累大量要镜像的事件积压,这可能需要很长时间才能恢复。这导致使用者从目标集群读取事件的延迟非常高。
-
添加主题有困难
使用正则表达式作为主题白名单意味着每次有人向源集群添加匹配的主题时,MirrorMaker 都会重新平衡。我们已经看到,再平衡对Uber来说尤其痛苦。为了避免这种情况,他们决定简单地列出他们需要镜像的每个主题,以避免意外的重新平衡。但这意味着他们需要手动添加他们想要镜像到所有 MirrorMaker 实例的白名单中的新主题并退回这些实例,这会导致重新平衡。至少这些重新平衡发生在定期维护中,而不是每次有人添加主题时,但这仍然是大量的维护。这也意味着,如果维护操作不正确,并且不同的实例具有不同的主题列表,MirrorMaker 将启动并无休止地重新平衡,因为消费者将无法就他们订阅的主题达成一致。
鉴于这些问题,Uber 决定编写自己的 MirrorMaker 克隆,称为 uReplicator。他们决定使用 Apache Helix 作为中央(但高度可用)的控制器,用于管理主题列表和分配给每个 uReplicator 实例的分区。管理员使用 REST API 将新主题添加到 Helix 中的列表中,uReplicator 负责将分区分配给不同的使用者。为了实现这一点,Uber 将 MirrorMaker 中使用的 Kafka 消费者替换为他们自己编写的 Kafka 消费者,称为 Helix 消费者。该使用者从 Apache Helix 控制器获取其分区分配,而不是作为使用者之间协议的结果(有关如何在 Kafka 中完成此操作的详细信息,请参阅第 4 章)。因此,Helix 使用者可以避免重新平衡,而是侦听来自 Helix 的已分配分区中的更改。
Uber 写了一篇博文,更详细地描述了架构,并展示了他们所经历的改进。在撰写本文时,除了 Uber 之外,我们还不知道有哪家公司使用 uReplicator。这可能是因为大多数公司没有像 Uber 那样大规模运营,也不会遇到同样的问题,或者可能是因为对 Apache Helix 的依赖引入了一个全新的学习和管理组件,这增加了整个项目的复杂性。
8.4.2 Confluent 的复制器
在 Uber 开发 uReplicator 的同时,Confluent 独立开发了 Replicator。尽管名称相似,但这些项目几乎没有任何共同点——它们是针对两组不同 Mirror-Maker 问题的不同解决方案。Confluent 的 Replicator 旨在解决其企业客户在使用 MirrorMaker 管理其多集群部署时遇到的问题。
-
发散的集群配置 虽然 MirrorMaker 在源和目标之间保持数据同步,但这是它唯一保持同步的事情。主题最终可能会具有不同数量的分区、复制因子和主题级设置。将源集群上的主题保留期从一周增加到三周,而忘记 DR 集群可能会导致故障转移到第二个集群并发现现在丢失了几周的数据时,这可能会导致相当令人讨厌的意外。尝试手动使所有这些设置保持同步很容易出错,如果系统不同步,可能会导致下游应用程序甚至复制本身失败。
-
集群管理挑战 我们已经看到,MirrorMaker 通常部署为多个实例的集群。这意味着另一个集群需要弄清楚如何部署、监视和管理。由于有两个配置文件和大量参数,MirrorMaker 本身的配置管理可能是一个挑战。如果存在两个以上的群集和单向复制,则此值会增加。如果有三个主动-主动群集,则有六个 MirrorMaker 群集需要部署、监视和配置,并且每个群集可能至少有三个实例。有了 5 个主动-主动群集,MirrorMaker 群集的数量增加到 20 个。
为了最大程度地减少繁忙的企业 IT 部门的管理开销,Confluent 决定将 Replicator 实施为 Kafka Connect 框架的源连接器,Kafka Connect 框架是一种从另一个 Kafka 集群而不是从数据库读取数据的源连接器。如果您还记得第 7 章中的 Kafka Connect 架构,您会记得每个连接器将工作划分为可配置数量的任务。在 Replicator 中,每个任务都是一个使用者和生产者对。Connect 框架会根据需要将这些任务分配给不同的 Connect 工作节点,因此您可以在一台服务器上执行多个任务,也可以将这些任务分散到多个服务器。这取代了确定每个实例应运行多少个 MirrorMaker 流以及每台计算机应运行多少个实例的手动工作。Connect 还具有 REST API,用于集中管理连接器和任务的配置。如果我们假设大多数 Kafka 部署出于其他原因都包含 Kafka Connect(将数据库更改事件发送到 Kafka 是一个非常流行的用例),那么通过在 Connect 中运行 Replicator,我们可以减少需要管理的集群数量。另一个重大改进是,Replicator 连接器除了从 Kafka 主题列表中复制数据外,还从 Zookeeper 复制这些主题的配置
8.5 总结
本章的开头介绍了可能需要管理多个 Kafka 集群的原因,然后介绍了几种常见的多集群架构,从简单到非常复杂。我们详细介绍了如何实现 Kafka 的故障转移架构,并比较了当前可用的不同选项。然后,我们继续讨论可用的工具。从 Apache Kafka 的 MirrorMaker 开始,我们详细介绍了在生产环境中使用它的许多细节。最后,我们回顾了两个替代选项,它们解决了您在使用 MirrorMaker 时可能遇到的一些问题。
无论您最终使用哪种架构和工具,请记住,应该像投入生产的其他所有内容一样监控和测试多集群配置和镜像管道。由于 Kafka 中的多集群管理可能比关系数据库更容易,因此一些组织将其视为事后的想法,而忽略了应用适当的设计、规划、测试、部署自动化、监控和维护。通过认真对待多集群管理,最好将其作为整个组织(涉及多个应用程序和数据存储)的整体灾难或地理多样性计划的一部分,您将大大增加成功管理多个 Kafka 集群的机会。
第九章 管理 Kafka
Kafka 提供了多个命令行界面 (CLI) 实用程序,可用于对集群进行管理更改。这些工具是在 Java 类中实现的,并提供了一组脚本来正确调用这些类。这些工具提供了基本功能,但您可能会发现它们缺乏更复杂的操作。本章将介绍作为 Apache Kafka 开源项目的一部分提供的工具。有关在社区开发的高级工具的更多信息,可以在 Apache Kafka 网站上找到。
-
授权管理操作 虽然 Apache Kafka 实现了身份验证和授权来控制主题操作,但尚不支持大多数集群操作。这意味着这些 CLI 工具无需任何身份验证即可使用,这将允许在不进行安全检查或审计的情况下执行主题更改等操作。此功能正在开发中,应尽快添加。
9.1 主题操作
kafka-topics.sh 工具提供对大多数主题操作的轻松访问(配置更改已弃用并移至 kafka-configs.sh 工具)。它允许您创建、修改、删除和列出有关集群中主题的信息。要使用此命令,您需要使用 --zookeeper 参数为集群提供 Zookeeper 连接字符串。在下面的示例中,假定 Zookeeper 连接字符串 zoo1.example.com:2181/kafka-cluster。
-
检查版本 Kafka 的许多命令行工具直接对存储在 Zookeeper 中的元数据进行操作,而不是连接到代理本身。因此,务必确保您使用的工具版本与集群中代理的版本相匹配。最安全的方法是使用已部署的版本在 Kafka 代理本身上运行这些工具。
9.1.1 创建新主题
您需要三个参数才能在集群中创建新主题(必须提供这些参数,即使其中一些参数已经配置了代理级默认值):
-
主题名称 要创建的主题的名称。
-
复制因子 要在群集中维护的主题的副本数。
-
分区 要为主题创建的分区数。
* 指定主题组合还可以在创建期间显式设置主题的副本,或设置主题的配置覆盖。此处将不介绍这些操作。配置覆盖可以在本章后面找到,并且可以使用 --config 命令行参数提供给 kafka-topics.sh。本章后面还将介绍部分重新分配。
主题名称可以包含字母数字字符,以及下划线、破折号和句点。
* 命名主题允许(但不建议)使用以两个下划线开头的主题名称。此形式的主题被视为群集的内部主题(例如,使用者组偏移存储的 __consumer_offsets 主题)。也不建议在单个集群中同时使用句点和下划线,因为当主题名称用于 Kafka 中的指标名称时,句点会更改为下划线(例如,指标中的“topic.1”变为“topic_1”)
按如下方式执行 kafka-topics.sh:
kafka-topics.sh --zookeeper <zookeeper connect> --create --topic <string> --replication-factor <integer> --partitions <integer>
该命令将导致集群创建具有指定名称和分区数的主题。对于每个分区,群集将适当地选择指定数量的副本。这意味着,如果群集设置为机架感知副本分配,则每个分区的副本将位于单独的机架中。如果不需要机架感知分配,请指定 --disable-rack-aware 命令行参数。 例如,创建一个名为“my-topic”的主题,其中包含八个分区,每个分区有两个副本:
# kafka-topics.sh --zookeeper zoo1.example.com:2181/kafka-cluster --create --topic my-topic --replication-factor 2 --partitions 8 Created topic "my-topic".#
* 跳过现有主题的错误在自动化中使用此脚本时,您可能希望使用 --if-not-exists 参数,如果主题已存在,则该参数不会返回错误。
9.1.2 添加分区
有时需要增加主题的分区数。分区是跨群集扩展和复制主题的方式,增加分区计数的最常见原因是进一步分散主题,或降低单个分区的吞吐量。如果使用者需要扩展以在单个组中运行更多副本,则主题也可能会增加,因为分区只能由组中的单个成员使用。
* 调整键控主题从使用者的角度来看,使用键控消息生成的主题可能很难添加分区。这是因为当分区数发生更改时,键到分区的映射将发生变化。因此,建议在创建主题时为将包含键控消息的主题设置分区数,并避免调整主题大小。
* 跳过不存在的主题的错误虽然为 --alter 命令提供了 --if-exists 参数,但不建议使用它。使用此参数将导致在要更改的主题不存在时命令不返回错误。这可以掩盖本应创建的主题不存在的问题。
例如,将名为“my-topic”的主题的分区数增加到 16:
# kafka-topics.sh --zookeeper zoo1.example.com:2181/kafka-cluster --alter --topic my-topic --partitions 16 WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected Adding partitions succeeded!#
* 减少分区计数无法减少主题的分区数。不支持这样做的原因是,从主题中删除分区会导致该主题中的部分数据也被删除,从客户端的角度来看,这将是不一致的。此外,尝试将数据重新分发到剩余的分区将很困难,并导致无序消息。如果需要减少分区数,则需要删除主题并重新创建它。
9.1.3 删除主题
即使是没有消息的主题也会使用群集资源,包括磁盘空间、打开的文件句柄和内存。如果不再需要某个主题,可以将其删除以释放这些资源。要执行此操作,必须已将集群中的代理配置为将 delete.topic.enable 选项设置为 true。如果此选项已设置为 false,则删除主题的请求将被忽略。
* 数据丢失删除主题也会删除其所有消息。这不是一个可逆的操作,因此请确保谨慎执行
例如,删除名为“my-topic”的主题:
# kafka-topics.sh --zookeeper zoo1.example.com:2181/kafka-cluster --delete --topic my-topic Topic my-topic is marked for deletion. Note: This will have no impact if delete.topic.enable is not setto true.#
9.1.4 列出集群中的所有主题
主题工具可以列出集群中的所有主题。该列表的格式为每行一个主题,排名不分先后。 例如,列出群集中的主题:
# kafka-topics.sh --zookeeper zoo1.example.com:2181/kafka-cluster --listmy-topic - marked for deletion other-topic#
9.1.5 描述主题详细信息
还可以获取有关群集中一个或多个主题的详细信息。输出包括分区计数、主题配置覆盖以及每个分区及其副本分配的列表。通过向命令提供 --topic 参数,可以将其限制为单个主题。 例如,描述集群中的所有主题:
# kafka-topics.sh --zookeeper zoo1.example.com:2181/kafka-cluster --describeTopic:other-topic PartitionCount:8 ReplicationFactor:2 Configs:Topic:other-topic Partition: 0 ... Replicas: 1,0 Isr: 1,0Topic:other-topic Partition: 1 ... Replicas: 0,1 Isr: 0,1Topic:other-topic Partition: 2 ... Replicas: 1,0 Isr: 1,0Topic:other-topic Partition: 3 ... Replicas: 0,1 Isr: 0,1Topic:other-topic Partition: 4 ... Replicas: 1,0 Isr: 1,0Topic:other-topic Partition: 5 ... Replicas: 0,1 Isr: 0,1Topic:other-topic Partition: 6 ... Replicas: 1,0 Isr: 1,0Topic:other-topic Partition: 7 ... Replicas: 0,1 Isr: 0,1#
describe 命令还具有几个用于过滤输出的有用选项。这些有助于诊断群集问题。对于其中每个主题,不要指定 --topic 参数(因为目的是在群集中查找与条件匹配的所有主题或分区)。这些选项不适用于 list 命令(详见上一节)。 要查找具有配置覆盖的所有主题,请使用 --topics-with-overrides 参数。这将仅描述具有与集群默认值不同的配置的主题。 有两个筛选器用于查找有问题的分区。--under-replicated-partitions 参数将显示分区的一个或多个副本与主节点不同步的所有分区。--unavailable-partitions 参数显示所有没有领导者的分区。这是一种更严重的情况,这意味着分区当前处于脱机状态,不可用于生产或使用客户端。 例如,显示复制不足的分区:
# kafka-topics.sh --zookeeper zoo1.example.com:2181/kafka-cluster --describe --under-replicated-partitionsTopic: other-topic Partition: 2 Leader: 0 Replicas: 1,0Isr: 0Topic: other-topic Partition: 4 Leader: 0 Replicas: 1,0Isr: 0#
9.2 消费者群体
Kafka 中的消费者组在两个地方进行管理:对于较旧的消费者,信息在 Zookeeper 中维护,而对于新消费者,信息在 Kafka 代理中维护。kafka-consumer-groups.sh 工具可用于列出和描述这两种类型的组。它还可用于删除使用者组和偏移信息,但仅适用于在旧使用者(在 Zookeeper 中维护)下运行的组。使用较旧的使用者组时,您将通过为工具指定 --zookeeper 命令行参数来访问 Kafka 集群。对于新的使用者组,您需要将 --bootstrap-server 参数与要连接到的 Kafka 代理的主机名和端口号一起使用。
9.2.1 列出和描述组
要使用较旧的使用者客户端列出使用者组,请使用 --zookeeper 和 --list 参数执行。对于新使用者,请使用 --bootstrap-server、--list 和 --new-consumer 参数。 例如,列出旧的使用者组:
# kafka-consumer-groups.sh --zookeeper zoo1.example.com:2181/kafka-cluster --listconsole-consumer-79697myconsumer#
例如,列出新的使用者组:
# kafka-consumer-groups.sh --new-consumer --bootstrap-server kafka1.example.com:9092/kafka-cluster --listkafka-python-testmy-new-consumer#
对于列出的任何组,您可以通过将 --list 参数更改为 --describe 并添加 --group 参数来获取更多详细信息。这将列出该组正在使用的所有主题,以及每个主题分区的偏移量。 例如,获取名为“testgroup”的旧使用者组的消费者组详细信息:
# kafka-consumer-groups.sh --zookeeper zoo1.example.com:2181/kafka-cluster --describe --group testgroupGROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG OWNERmyconsumer my-topic 0 1688 1688 0 myconsumer_host1.example.com-1478188622741-7dab5ca7-0myconsumer my-topic 1 1418 1418 0 myconsumer_host1.example.com-1478188622741-7dab5ca7-0myconsumer my-topic 2 1314 1315 1 myconsumer_host1.example.com-1478188622741-7dab5ca7-0myconsumer my-topic 3 2012 2012 0 myconsumer_host1.example.com-1478188622741-7dab5ca7-0myconsumer my-topic 4 1089 1089 0 myconsumer_host1.example.com-1478188622741-7dab5ca7-0myconsumer my-topic 5 1429 1432 3 myconsumer_host1.example.com-1478188622741-7dab5ca7-0myconsumer my-topic 6 1634 1634 0 myconsumer_host1.example.com-1478188622741-7dab5ca7-0myconsumer my-topic 7 2261 2261 0 myconsumer_host1.example.com-1478188622741-7dab5ca7-0#
表 9-1 显示了输出中提供的字段
表 9-1.为名为“testgroup”的旧使用者组提供的字段
| 字段 | 说明 |
|---|---|
| GROUP | 消费者组的名称。 |
| TOPIC | 正在使用的主题的名称。 |
| PARTITION | 正在使用的分区的 ID 号。 |
| CURRENT-OFFSET | 使用者组为此主题分区提交的最后一个偏移量。这是使用者在分区中的位置。 |
| LOG-END-OFFSET | 主题分区的代理的当前高水位线偏移量。这是生成并提交到群集的最后一条消息的偏移量。 |
| LAG | 此主题分区的使用者 Current-Offset 和代理 Log-End-Offset 之间的区别。 |
| OWNER | 当前正在使用此主题分区的使用者组的成员。这是组成员提供的任意 ID,不一定包含使用者的主机名。 |
9.2.2 删除组
只有旧的消费者客户端支持删除消费者组。这会从 Zookeeper 中删除整个组,包括该组正在使用的所有主题的所有存储偏移量。为了执行此操作,应关闭组中的所有使用者。如果不先执行此步骤,则使用者可能会有未定义的行为,因为在使用组时,该组的 Zookeeper 元数据将被删除。 例如,删除名为“testgroup”的使用者组:
# kafka-consumer-groups.sh --zookeeper zoo1.example.com:2181/kafka-cluster --delete --group testgroup Deleted all consumer group information for group testgroup in zookeeper.#
也可以使用相同的命令删除组正在使用的单个主题的偏移量,而无需删除整个组。同样,建议在执行此操作之前停止使用者组,或将其配置为不使用要删除的主题。
例如,从名为“testgroup”的使用者组中删除主题“my-topic”的偏移量:
# kafka-consumer-groups.sh --zookeeper zoo1.example.com:2181/kafka-cluster --delete --group testgroup --topic my-topic Deleted consumer group information for group testgroup topic my-topic in zookeeper.#
9.2.3 偏移量管理
除了使用旧的消费者客户端显示和删除消费组的偏移量外,还可以批量检索偏移量并存储新的偏移量。当存在需要重新读取消息的问题时,这对于重置使用者的偏移量,或者将偏移量推进到使用者遇到问题的消息之后(例如,如果存在使用者无法处理的格式错误的消息),这很有用。
* 管理提交到 Kafka 的偏移量目前没有工具可用于管理将偏移量提交到 Kafka 的使用者客户端的偏移量。此函数仅适用于将偏移量提交到 Zookeeper 的使用者。为了管理提交到 Kafka 的组的偏移量,您必须使用客户端中提供的 API 来提交该组的偏移量。
-
导出偏移量 没有用于导出偏移量的命名脚本,但我们可以使用 kafka-run-class.sh 脚本在适当的环境中执行该工具的底层 Java 类。导出偏移量将生成一个文件,其中包含组的每个主题分区及其偏移量,其格式为导入工具可以读取的已定义格式。创建的文件每行将有一个主题分区,格式如下:
/consumers/GROUPNAME/offsets/topic/TOPICNAME/PARTITIONID-0:OFFSE
例如,将名为“testgroup”的使用者组的偏移量导出到名为 offsets 的文件中:
# kafka-run-class.sh kafka.tools.ExportZkOffsets --zkconnect zoo1.example.com:2181/kafka-cluster --group testgroup --output-file offsets# cat offsets/consumers/testgroup/offsets/my-topic/0:8905/consumers/testgroup/offsets/my-topic/1:8915/consumers/testgroup/offsets/my-topic/2:9845/consumers/testgroup/offsets/my-topic/3:8072/consumers/testgroup/offsets/my-topic/4:8008/consumers/testgroup/offsets/my-topic/5:8319/consumers/testgroup/offsets/my-topic/6:8102/consumers/testgroup/offsets/my-topic/7:12739#
-
导入偏移量 导入偏移工具与导出相反。它获取通过导出上一节中的偏移量生成的文件,并使用它来设置使用者组的当前偏移量。一种常见的做法是导出使用者组的当前偏移量,创建文件的副本(以便保留备份),然后编辑副本以将偏移量替换为所需的值。请注意,对于 import 命令,不使用 --group 选项。这是因为消费者组名称嵌入在要导入的文件中。
* 首先阻止消费者在执行此步骤之前,请务必停止组中的所有使用者。如果在使用者组处于活动状态时写入新偏移量,则它们不会读取这些偏移量。使用者将只覆盖导入的偏移量。
例如,从名为 offset 的文件中导入名为“testgroup”的使用者组的偏移量:
# kafka-run-class.sh kafka.tools.ImportZkOffsets --zkconnect zoo1.example.com:2181/kafka-cluster --input-file offsets#
9.3 动态配置更改
在群集为主题和客户端配额运行时,可以覆盖配置。有意在未来添加更多动态配置,这就是为什么这些更改已放入单独的 CLI 工具 kafka-configs.sh 中的原因。这允许您为特定主题和客户端 ID 设置配置。设置后,这些配置对于群集是永久性的。它们存储在 Zookeeper 中,每个代理在启动时都会读取它们。在工具和文档中,像这样的动态配置称为每个主题或每个客户端的配置,以及覆盖。
与前面的工具一样,您需要使用 --zookeeper 参数为集群提供 Zookeeper 连接字符串。在下面的示例中,假定 Zookeeper 连接字符串 zoo1.example.com:2181/kafka-cluster。
9.3.1 覆盖主题构筑默认值
有许多适用于主题的配置可以针对单个主题进行更改,以适应单个集群中的不同用例。其中大多数配置在代理配置中指定了缺省值,除非设置了覆盖,否则将应用该缺省值。
更改主题配置的命令的格式为:
kafka-configs.sh --zookeeper zoo1.example.com:2181/kafka-cluster --alter --entity-type topics --entity-name <topic name> --add-config <key>=<value>[,<key>=<value>...]
如表9-2所示,主题的有效配置(密钥)如表所示。
表 9-2.主题的有效键
| 配置键 | 说明 |
|---|---|
| cleanup.policy | 如果设置为 compact,则本主题中的消息将被丢弃,以便只有最具有给定键的最近消息将被保留(日志压缩)。 |
| compression.type | 代理在为本主题编写消息批处理时使用的压缩类型到磁盘。当前值为 gzip、snappy 和 lz4。 |
| delete.retention.ms | 已删除的逻辑删除将保留多长时间(以毫秒为单位)。仅有效对于日志压缩主题。 |
| file.delete.delay.ms | 在删除日志段和索引之前等待多长时间(以毫秒为单位)磁盘中的主题。 |
| flush.messages | 在强制将本主题的消息刷新到磁盘之前收到的消息数。 |
| flush.ms | 在强制将本主题的消息刷新到磁盘之前多长时间(以毫秒为单位)。 |
| index.interval.bytes | 日志段的条目之间可以生成多少字节的消息指数。 |
| max.message.bytes | 本主题的单条消息的最大大小(以字节为单位)。 |
| message.format.version | 代理在将消息写入磁盘时将使用的消息格式版本。必须是有效的 API 版本号(例如,“0.10.0”)。 |
| message.timestamp.difference.max.ms | 消息时间戳之间允许的最大差值(以毫秒为单位)以及收到消息时的代理时间戳。仅当 message.timestamp.type 设置为 CreateTime。 |
| message.timestamp.type | 将消息写入磁盘时要使用的时间戳。当前值为CreateTime 用于客户端指定的时间戳,LogAppendTime 用于代理将消息写入分区的时间。 |
| min.cleanable.dirty.ratio | 日志压缩程序尝试压缩本主题分区的频率, 表示为未压缩的日志段数与总数的比率日志段。仅对日志压缩主题有效。 |
| min.insync.replicas | 主题分区必须同步的最小副本数认为可用。 |
| preallocate | 如果设置为 true,则在新分段时应预分配此主题的日志分段被卷起。 |
| retention.bytes | 要为此主题保留的消息量(以字节为单位)。 |
| retention.ms | 此主题的消息应保留多长时间,以毫秒为单位。 |
| segment.bytes | 应写入单个日志段的消息量(以字节为单位)分区。 |
| segment.index.bytes | 单个日志段索引的最大大小(以字节为单位)。 |
| segment.jitter.ms | 随机化并添加到 segment.ms 的最大毫秒数滚动日志段时。 |
| segment.ms | 每个分区的日志段的轮换频率(以毫秒为单位)。 |
| unclean.leader.election.enable | (选举启用)如果设置为 false,则不允许此主题进行不干净的领导人选举。 |
例如,将名为“my-topic”的主题的保留期设置为 1 小时(3,600,000 毫秒):
# kafka-configs.sh --zookeeper zoo1.example.com:2181/kafka-cluster --alter --entity-type topics --entity-name my-topic --add-config retention.ms=3600000 Updated config for topic: "my-topic".#
9.3.2 覆盖客户端配置默认值
对于 Kafka 客户端,唯一可以覆盖的配置是生产者和消费者配额。它们都是允许具有指定客户端 ID 的所有客户端在每个代理的基础上生成或使用的速率(以每秒字节数为单位)。这意味着,如果集群中有 5 个代理,并且为客户端指定了 10 MB/秒的创建者配额,则允许该客户端同时在每个代理上生成 10 MB/秒,总计 50 MB/秒。
* 客户端 ID 与使用者组客户端 ID 不一定与消费者组名称相同。使用者可以设置自己的客户端 ID,并且您可能有许多使用者位于不同的组中,这些使用者指定了相同的客户端 ID。最佳做法是将每个使用者组的客户端 ID 设置为标识该组的唯一值。这允许单个使用者组共享配额,并且可以更轻松地在日志中识别哪个组负责请求。
更改客户端配置的命令的格式为:
kafka-configs.sh --zookeeper zoo1.example.com:2181/kafka-cluster --alter --entity-type clients --entity-name <client ID> --add-config <key>=<value>[,<key>=<value>...]
表 9-3 显示了客户端的配置(密钥) 表 9-3.客户端的配置(密钥)
| 配置键 | 说明 |
|---|---|
| producer_bytes_rate | 允许单个客户端 ID 在一秒钟内向单个代理生成的消息量(以字节为单位)。 |
| consumer_bytes_rate | 允许单个客户端 ID 在一秒钟内从单个代理使用的消息量(以字节为单位)。 |
9.3.3 描述构造覆盖
可以使用命令行工具列出所有配置覆盖。这将允许您检查主题或客户端的特定配置。与其他工具类似,这是使用 --describe 命令完成的。 例如,显示名为“my-topic”的主题的所有配置覆盖:
# kafka-configs.sh --zookeeper zoo1.example.com:2181/kafka-cluster --describe --entity-type topics --entity-name my-topic Configs for topics:my-topic are retention.ms=3600000,segment.ms=3600000#
* 仅主题覆盖配置描述将仅显示覆盖,不包括集群默认配置。目前,无论是通过 Zookeeper 还是 Kafka 协议,都无法动态发现代理本身的配置。这意味着,在使用此工具发现自动化中的主题或客户端设置时,该工具必须单独了解群集默认配置。
9.3.4 删除 Conguation 覆盖
动态配置可以完全删除,这将导致实体恢复为群集默认值。要删除配置覆盖,请使用 --alter 命令和 --delete-config 参数。
例如,删除名为“my-topic”的主题的 retention.ms 配置覆盖:
# kafka-configs.sh --zookeeper zoo1.example.com:2181/kafka-cluster --alter --entity-type topics --entity-name my-topic --delete-config retention.ms Updated config for topic: "my-topic".#
9.4 分区管理
Kafka 工具包含两个用于分区管理的脚本,一个允许重新选择主副本,另一个是用于将分区分配给代理的低级实用程序。总之,这些工具可以帮助在 Kafka 代理集群中正确平衡消息流量。
如第 6 章所述,为了可靠性,分区可以有多个副本。但是,这些副本中只有一个可以作为分区的领导者,并且所有生成和使用操作都发生在该代理上。Kafka 内部将其定义为副本列表中的第一个同步副本,但是当代理停止并重新启动时,它不会自动恢复任何分区的领导权。
-
自动领导者再平衡 有一个用于自动主重新平衡的代理配置,但不建议将其用于生产环境。自动均衡模块会对性能造成重大影响,并且可能会导致大型集群的客户端流量长时间暂停。
促使经纪人恢复领导地位的一种方法是触发首选副本选举。这会告知群集控制器为分区选择理想的领导者。该操作通常不会产生影响,因为客户可以自动跟踪领导层的变化。这可以使用 kafka-preferred-replica-election.sh 实用程序手动订购。
例如,为集群中的所有主题启动首选副本选举,其中一个主题具有八个分区:
# kafka-preferred-replica-election.sh --zookeeper zoo1.example.com:2181/kafka-clusterSuccessfully started preferred replica election for partitionsSet([my-topic,5], [my-topic,0], [my-topic,7], [my-topic,4],[my-topic,6], [my-topic,2], [my-topic,3], [my-topic,1])#
对于具有大量分区的群集,单个首选副本选举可能无法运行。该请求必须写入集群元数据中的 Zookeeper znode,如果请求大于 znode 的大小(默认为 1 MB),则请求将失败。在这种情况下,您需要创建一个文件,其中包含一个 JSON 对象,其中列出了要选择的分区,并将请求分解为多个步骤。JSON 文件的格式为:
9.4.1 首选副本选择
{"partitions": [{"partition": 1,"topic": "foo"},{"partition": 2,"topic": "foobar"}]}
例如,在名为“partitions.json”的文件中使用指定的分区列表启动首选副本选举:
# kafka-preferred-replica-election.sh --zookeeper zoo1.example.com:2181/kafka-cluster --path-to-json-file partitions.jsonSuccessfully started preferred replica election for partitionsSet([my-topic,1], [my-topic,2], [my-topic,3])#
9.4.2 更改分区的副本
有时,可能需要更改分区的副本分配。可能需要这样做的一些示例包括: • 如果某个主题的分区在集群中不平衡,导致代理负载不均衡 • 如果代理脱机且分区复制不足 • 如果添加了新的代理,并且需要接收集群负载的份额
该 kafka-reassign-partitions.sh 可用于执行此操作。此工具必须至少分两步使用。第一步使用代理列表和主题列表来生成一组移动。第二步执行生成的移动。还有一个可选的第三步,它使用生成的列表来验证分区重新分配的进度或完成情况。
若要生成一组分区移动,必须创建一个文件,其中包含列出主题的 JSON 对象。JSON 对象的格式如下(版本号当前始终为 1):
{"topics": [{"topic": "foo"},{"topic": "foo1"}],"version": 1}
例如,生成一组分区移动,以将文件“topics.json”中列出的主题移动到 ID 为 0 和 1 的代理:
# kafka-reassign-partitions.sh --zookeeper zoo1.example.com:2181/kafka-cluster --generate --topics-to-move-json-file topics.json --broker-list 0,1Current partition replica assignment{"version":1,"partitions":[{"topic":"my-topic","partition":5,"replicas":[0,1]},{"topic":"my-topic","partition":10,"replicas":[1,0]},{"topic":"my•topic","partition":1,"replicas":[0,1]},{"topic":"my-topic","partition":4,"replicas":[1,0]},{"topic":"my-topic","partition":7,"replicas":[0,1]},{"topic":"my•topic","partition":6,"replicas":[1,0]},{"topic":"my-topic","partition":3,"replicas":[0,1]},{"topic":"my-topic","partition":15,"replicas":[0,1]},{"topic":"my-topic","partition":0,"replicas":[1,0]},{"topic":"my•topic","partition":11,"replicas":[0,1]},{"topic":"my-topic","partition":8,"replicas":[1,0]},{"topic":"my-topic","partition":12,"replicas":[1,0]},{"topic":"my•topic","partition":2,"replicas":[1,0]},{"topic":"my-topic","partition":13,"replicas":[0,1]},{"topic":"my-topic","partition":14,"replicas":[1,0]},{"topic":"my-topic","partition":9,"replicas":[0,1]}]}Proposed partition reassignment configuration{"version":1,"partitions":[{"topic":"my-topic","partition":5,"replicas":[0,1]},{"topic":"my-topic","partition":10,"replicas":[1,0]},{"topic":"my•topic","partition":1,"replicas":[0,1]},{"topic":"my-topic","partition":4,"replicas":[1,0]},{"topic":"my-topic","partition":7,"replicas":[0,1]},{"topic":"my•topic","partition":6,"replicas":[1,0]},{"topic":"my-topic","partition":15,"replicas":[0,1]},{"topic":"my-topic","partition":0,"replicas":[1,0]},{"topic":"my-topic","partition":3,"replicas":[0,1]},{"topic":"my•topic","partition":11,"replicas":[0,1]},{"topic":"my-topic","partition":8,"replicas":[1,0]},{"topic":"my-topic","partition":12,"replicas":[1,0]},{"topic":"my•topic","partition":13,"replicas":[0,1]},{"topic":"my-topic","partition":2,"replicas":[1,0]},{"topic":"my-topic","partition":14,"replicas":[1,0]},{"topic":"my-topic","partition":9,"replicas":[0,1]}]}#
代理列表在工具命令行上以逗号分隔的代理 ID 列表的形式提供。该工具将在标准输出中输出两个 JSON 对象,用于描述主题的当前分区分配和建议的分区分配。这些 JSON 对象的格式为:{“partitions”: [{“topic”: “my-topic”, “partition”: 0, “replicas”: [1,2] }], “version”:1}。
可以保存第一个 JSON 对象,以防需要还原重新分配。第二个 JSON 对象(显示建议分配的对象)应保存到新文件中。然后,此文件将提供回 kafka-reassign-partitions.sh 工具以进行第二步。
例如,从文件“reassign.json”执行建议的分区重新分配。
# kafka-reassign-partitions.sh --zookeeper zoo1.example.com:2181/kafka-cluster --execute --reassignment-json-file reassign.jsonCurrent partition replica assignment{"version":1,"partitions":[{"topic":"my-topic","partition":5,"replicas":[0,1]},{"topic":"my-topic","partition":10,"replicas":[1,0]},{"topic":"my•topic","partition":1,"replicas":[0,1]},{"topic":"my-topic","partition":4,"replicas":[1,0]},{"topic":"my-topic","partition":7,"replicas":[0,1]},{"topic":"my•topic","partition":6,"replicas":[1,0]},{"topic":"my-topic","partition":3,"replicas":[0,1]},{"topic":"my-topic","partition":15,"replicas":[0,1]},{"topic":"my-topic","partition":0,"replicas":[1,0]},{"topic":"my•topic","partition":11,"replicas":[0,1]},{"topic":"my-topic","partition":8,"replicas":[1,0]},{"topic":"my-topic","partition":12,"replicas":[1,0]},{"topic":"my•topic","partition":2,"replicas":[1,0]},{"topic":"my-topic","partition": 13,"replicas":[0,1]},{"topic":"my-topic","partition":14,"replicas":[1,0]},{"topic":"my-topic","partition":9,"replicas":[0,1]}]}Save this to use as the --reassignment-json-file option duringrollbackSuccessfully started reassignment of partitions {"version":1,"partitions":[{"topic":"my-topic","partition":5,"replicas":[0,1]},{"topic":"my•topic","partition":0,"replicas":[1,0]},{"topic":"my-topic","partition":7,"replicas":[0,1]},{"topic":"my-topic","partition":13,"replicas":[0,1]},{"topic":"my•topic","partition":4,"replicas":[1,0]},{"topic":"my-topic","partition":12,"replicas":[1,0]},{"topic":"my-topic","partition":6,"replicas":[1,0]},{"topic":"my-topic","partition":11,"replicas":[0,1]},{"topic":"my•topic","partition":10,"replicas":[1,0]},{"topic":"my-topic","partition":9,"replicas":[0,1]},{"topic":"my-topic","partition":2,"replicas":[1,0]},{"topic":"my•topic","partition":14,"replicas":[1,0]},{"topic":"my-topic","partition":3,"replicas":[0,1]},{"topic":"my-topic","partition":1,"replicas":[0,1]},{"topic":"my-topic","partition":15,"replicas":[0,1]},{"topic":"my•topic","partition":8,"replicas":[1,0]}]}#
这将开始将指定的分区副本重新分配给新的代理。群集控制器通过将新副本添加到每个分区的副本列表(增加复制因子)来执行此操作。然后,新副本将从当前主节点复制每个分区的所有现有消息。根据磁盘上分区的大小,这可能需要花费大量时间,因为数据会通过网络复制到新的副本。复制完成后,控制器会从副本列表中删除旧副本(将复制因子减小到原始大小)。
* 在重新分配副本时提高网络利用率从单个代理中除去多个分区时,例如,如果要从集群中除去该代理,则最佳做法是在开始重新分配之前关闭并重新启动代理。这会将该特定代理上分区的领导权转移到集群中的其他代理(只要未启用自动领导选举)。这可以显著提高重新分配的性能,并减少对集群的影响,因为复制流量将分发到许多代理。
在重新分配运行时,以及重新分配完成后,可以使用 kafka-reassign-partitions.sh 工具验证重新分配的状态。这将显示当前正在进行的重新分配,已完成的重新分配,以及如果出现错误,则显示哪些重新分配失败。为此,您必须拥有包含执行步骤中使用的 JSON 对象的文件。
例如,从文件“reassign.json”验证正在运行的分区重新分配:
# kafka-reassign-partitions.sh --zookeeper zoo1.example.com:2181/kafka-cluster --verify --reassignment-json-file reassign.jsonStatus of partition reassignment:Reassignment of partition [my-topic,5] completed successfullyReassignment of partition [my-topic,0] completed successfullyReassignment of partition [my-topic,7] completed successfullyReassignment of partition [my-topic,13] completed successfullyReassignment of partition [my-topic,4] completed successfullyReassignment of partition [my-topic,12] completed successfullyReassignment of partition [my-topic,6] completed successfullyReassignment of partition [my-topic,11] completed successfullyReassignment of partition [my-topic,10] completed successfullyReassignment of partition [my-topic,9] completed successfullyReassignment of partition [my-topic,2] completed successfullyReassignment of partition [my-topic,14] completed successfullyReassignment of partition [my-topic,3] completed successfullyReassignment of partition [my-topic,1] completed successfullyReassignment of partition [my-topic,15] completed successfullyReassignment of partition [my-topic,8] completed successfully#
* 批处理重新分配分区重新分配对群集的性能有很大影响,因为它们会导致内存页缓存的一致性发生变化,并使用网络和磁盘 I/O。
9.4.3 更改复制因子
分区重新分配工具有一个未记录的功能,允许您增加或减少分区的复制因子。在使用错误的复制因子创建分区的情况下(例如,在创建主题时没有足够的代理可用),这可能是必需的。这可以通过创建一个 JSON 对象来完成,该对象的格式在分区重新分配的执行步骤中使用,该步骤添加或删除副本以正确设置复制因子。群集将完成重新分配,并将复制因子保持在新大小。
例如,考虑一个名为“my-topic”的主题的当前分配,该主题具有一个分区,复制因子为 1:
{"partitions": [{"topic": "my-topic","partition": 0,"replicas": [1]}],"version": 1}
在分区重新分配的执行步骤中提供以下 JSON 对象将导致复制因子增加到 2:
{"partitions": [{"partition": 0,"replicas": [1,2],"topic": "my-topic"}],"version": 1}
同样,可以通过为 JSON 对象提供较小的副本列表来减少分区的复制因子。
9.4.4 转储日志段
如果您必须去寻找消息的特定内容,可能是因为您最终在主题中得到了消费者无法处理的“毒丸”消息,那么您可以使用一个辅助工具来解码分区的日志段。这将允许您查看单个消息,而无需使用和解码它们。该工具将以逗号分隔的日志段文件列表作为参数,并可以打印出消息摘要信息或详细的消息数据。
例如,解码名为 000000000000052368601.log 的日志段文件,显示消息摘要:
# kafka-run-class.sh kafka.tools.DumpLogSegments --files00000000000052368601.logDumping 00000000000052368601.logStarting offset: 52368601offset: 52368601 position: 0 NoTimestampType: -1 isvalid: truepayloadsize: 661 magic: 0 compresscodec: GZIPCompressionCodec crc:1194341321offset: 52368603 position: 687 NoTimestampType: -1 isvalid: truepayloadsize: 895 magic: 0 compresscodec: GZIPCompressionCodec crc:278946641offset: 52368604 position: 1608 NoTimestampType: -1 isvalid: truepayloadsize: 665 magic: 0 compresscodec: GZIPCompressionCodec crc:3767466431offset: 52368606 position: 2299 NoTimestampType: -1 isvalid: truepayloadsize: 932 magic: 0 compresscodec: GZIPCompressionCodec crc:2444301359...
例如,解码名为 000000000000052368601.log 的日志段文件,显示消息数据:
# kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000052368601.log --print-data-logoffset: 52368601 position: 0 NoTimestampType: -1 isvalid: truepayloadsize: 661 magic: 0 compresscodec: GZIPCompressionCodec crc:1194341321 payload: test message 1offset: 52368603 position: 687 NoTimestampType: -1 isvalid: truepayloadsize: 895 magic: 0 compresscodec: GZIPCompressionCodec crc:278946641 payload: test message 2offset: 52368604 position: 1608 NoTimestampType: -1 isvalid: truepayloadsize: 665 magic: 0 compresscodec: GZIPCompressionCodec crc:3767466431 payload: test message 3offset: 52368606 position: 2299 NoTimestampType: -1 isvalid: truepayloadsize: 932 magic: 0 compresscodec: GZIPCompressionCodec crc:2444301359 payload: test message 4...
也可以使用此工具来验证与日志段一起的索引文件。该索引用于查找日志段中的消息,如果损坏,将导致使用错误。每当代理在不干净的状态下启动(即它没有正常停止)时,都会执行验证,但也可以手动执行。检查索引有两个选项,具体取决于要执行的检查量。选项 --index-sanity-check 将仅检查索引是否处于可用状态,而 --verify-index-only 将检查索引中的不匹配,而不会打印出所有索引条目。
例如,验证名为 000000000000052368601.log 的日志段文件的索引文件是否未损坏:
# kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000052368601.index,00000000000052368601.log --index-sanity-checkDumping 00000000000052368601.index00000000000052368601.index passed sanity check.Dumping 00000000000052368601.logStarting offset: 52368601offset: 52368601 position: 0 NoTimestampType: -1 isvalid: truepayloadsize: 661 magic: 0 compresscodec: GZIPCompressionCodec crc:1194341321offset: 52368603 position: 687 NoTimestampType: -1 isvalid: truepayloadsize: 895 magic: 0 compresscodec: GZIPCompressionCodec crc:278946641offset: 52368604 position: 1608 NoTimestampType: -1 isvalid: truepayloadsize: 665 magic: 0 compresscodec: GZIPCompressionCodec crc:3767466431...
9.4.5 副本验证
分区复制的工作方式类似于常规的 Kafka 使用者客户端:跟随代理从最早的偏移量开始复制,并定期将当前偏移量检查到磁盘。当复制停止并重新启动时,它会从最后一个检查点开始。以前复制的日志段可能会从代理中删除,在这种情况下,跟随者不会填补空白。
要验证主题分区的副本在整个集群中是否相同,您可以使用 kafka-replica-verification.sh 工具进行验证。此工具将从一组给定主题分区的所有副本中获取消息,并检查所有副本上是否存在所有消息。您必须为该工具提供与要验证的主题匹配的正则表达式。如果未提供任何主题,则验证所有主题。您还必须提供要连接到的代理的显式列表。
* 警告:前方的集群影响副本验证工具将对群集产生类似于重新分配分区的影响,因为它必须从最旧的偏移量中读取所有消息才能验证副本。此外,它并行读取分区的所有副本,因此应谨慎使用。
例如,验证代理 1 和 2 上以“my-”开头的主题的副本:
# kafka-replica-verification.sh --broker-list kafka1.example.com:9092,kafka2.example.com:9092 --topic-white-list 'my-.*'2016-11-23 18:42:08,838: verification process is started.2016-11-23 18:42:38,789: max lag is 0 for partition [my-topic,7]at offset 53827844 among 10 partitions2016-11-23 18:43:08,790: max lag is 0 for partition [my-topic,7]at offset 53827878 among 10 partitions
9.5 消费和生产
在使用 Apache Kafka 时,您经常会发现需要手动使用消息或生成一些示例消息,以验证应用程序的情况。提供了两个实用程序来帮助解决这个问题:kafka-console-consumer.sh 和 kafka-console-producer.sh。这些是 Java 客户端库的包装器,允许您与 Kafka 主题进行交互,而无需编写整个应用程序来执行此操作。
* 管道输出到另一个应用程序虽然可以编写环绕控制台使用者或生产者的应用程序(例如,使用消息并将其通过管道传递到另一个应用程序进行处理),但这种类型的应用程序非常脆弱,应避免使用。很难以不丢失消息的方式与控制台使用者进行交互。同样,控制台生产者不允许使用所有功能,正确发送字节也很棘手。最好直接使用 Java 客户端库,或者直接使用 Kafka 协议的其他语言使用第三方客户端库。
9.5.1 控制台使用者
kafka-console-consumer.sh 工具提供了一种使用 Kafka 集群中一个或多个主题中的消息的方法。消息以标准输出打印,由新行分隔。默认情况下,它输出消息中的原始字节,不带格式(使用 DefaultFormatter)。以下段落介绍了所需的选项。
* 检查工具版本使用与 Kafka 集群版本相同的使用者非常重要。较旧的控制台使用者可能会以不正确的方式与 Zookeeper 交互,从而损坏集群。
第一个选项是指定是否使用新的使用者,以及将配置指向 Kafka 集群本身。使用较旧的使用者时,唯一需要的参数是 --zookeeper 选项,后跟集群的连接字符串。从上面的例子来看,这可能是 --zookeeper zoo1.example.com:2181/kafka-cluster。如果您使用的是新使用者,则必须同时指定 --new-consumer 标志和 --broker-list 选项,后跟逗号分隔的代理列表,例如 --broker-list kafka1.example.com:9092,kafka2.example.com:9092。
接下来,您必须指定要使用的主题。为此提供了三个选项:--topic、--whitelist 和 --blacklist。可以提供一个,而且只能提供一个。--topic 选项指定要使用的单个主题。--whitelist 和 --blacklist 选项后面各有一个正则表达式(请记住正确转义正则表达式,以免 shell 命令行更改它)。白名单将消耗与正则表达式匹配的所有主题,而黑名单将消耗除正则表达式匹配的主题之外的所有主题。
例如,使用旧使用者使用名为“my-topic”的单个主题:
# kafka-console-consumer.sh --zookeeper zoo1.example.com:2181/kafka-cluster --topic my-topicsample message 1sample message 2^CProcessed a total of 2 messages#
除了基本的命令行选项之外,还可以将任何正常的使用者配置选项传递给控制台使用者。这可以通过两种方式完成,具体取决于您需要通过多少个选项以及您喜欢如何通过。第一种是通过指定 --consumer.config CONFIGFILE 来提供使用者配置文件,其中 CONFIGFILE 是包含配置选项的文件的完整路径。另一种方法是在命令行上使用一个或多个 --consumer-property KEY=VALUE 形式的参数指定选项,其中 KEY 是配置选项名称,VALUE 是要将其设置为的值。这对于使用者选项(如设置使用者组 ID)非常有用。
* 令人困惑的命令行选项控制台使用者和控制台生产者都有一个 --property 命令行选项,但这不应与 --consumer-property 和 --producer-property 选项混淆。--property 选项仅用于将配置传递给消息格式化程序,而不用于将客户端本身。
对于控制台使用者,还应了解其他一些常用选项:
-
--formatter 类名 指定用于对消息进行解码的消息格式化程序类。默认为 kafka.tools.DefaultFormatter。
-
--从头开始 使用从最早偏移量指定的主题中的消息。否则,消耗量将从最新的偏移量开始。
-
--max-messages NUM 在退出之前,最多使用完 NUM 消息。
-
--partition NUM 仅从 ID 为 NUM 的分区中使用(需要新的使用者)。
-
消息格式化程序选项 除了默认格式化程序外,还有三种消息格式化程序可供使用:
-
kafka.tools.LoggingMessageFormatter 使用记录器输出消息,而不是标准输出。消息在 INFO 级别打印,包括时间戳、键和值。
-
kafka.tools.ChecksumMessageFormatter 仅打印消息校验和。
-
kafka.tools.NoOpMessageFormatter 使用消息,但根本不输出消息。
kafka.tools.DefaultMessageFormatter 还具有几个有用的选项,可以使用 --property 命令行选项传递这些选项:
-
print.timestamp 设置为“true”以显示每条消息的时间戳(如果可用)。
-
print.key(打印键) 设置为“true”以显示除值之外的消息键。
-
key.separator 指定打印时要在消息键和消息值之间使用的分隔符。
-
line.separator 指定要在消息之间使用的分隔符。
-
key.deserializer 提供用于在打印前反序列化消息密钥的类名。
-
value.deserializer (值.解序列化程序) 提供用于在打印之前反序列化消息值的类名。
反序列化程序类必须实现 org.apache.kafka.common.serialization.Deserializer,控制台使用者将对它们调用 toString 方法来显示输出。通常,您可以将这些反序列化程序实现为 Java 类,通过在执行 kafka_console_consumer.sh之前设置 CLASSPATH 环境变量,将其插入到控制台使用者的类路径中。
-
-
使用偏移量主题 有时,查看为集群的使用者组提交的偏移量很有用。您可能希望查看特定组是否正在提交偏移量,或者提交偏移量的频率。这可以通过使用控制台使用者使用名为 __consumer_offsets 的特殊内部主题来完成。所有使用者偏移量都作为消息写入本主题。若要对本主题中的消息进行解码,必须使用格式化程序类 kafka.coordinator.GroupMeta dataManager$OffsetsMessageFormatter。 例如,使用 offset 主题中的一条消息:
# kafka-console-consumer.sh --zookeeper zoo1.example.com:2181/kafka-cluster --topic __consumer_offsets --formatter 'kafka.coordinator.GroupMetadataManager$OffsetsMessage Formatter' --max-messages 1[my-group-name,my-topic,0]::[OffsetMetadata[481690879,NO_METADATA] ,CommitTime 1479708539051,ExpirationTime 1480313339051] Processed a total of 1 messages#
9.5.2 生产者控制台
与控制台使用者类似,kakfa-console-producer.sh 工具可用于将消息写入集群中的 Kafka 主题。默认情况下,每行读取一条消息,使用制表符分隔键和值(如果不存在制表符,则键为 null)。
* 更改行读取行为您可以提供自己的类来读取行,以便执行自定义操作。您创建的类必须扩展 kafka.common.MessageReader,并将负责创建 ProducerRecord。使用 --line-reader 选项在命令行上指定您的类,并确保包含您的类的 JAR 位于类路径中。
控制台生成者要求至少提供两个参数。参数 --broker-list 指定一个或多个代理,作为集群的 hostname:port 条目的逗号分隔列表。另一个必需的参数是 --topic 选项,用于指定要向其生成消息的主题。完成生成后,发送文件结束 (EOF) 字符以关闭客户端。
例如,向名为“my-topic”的主题生成两条消息:
# kafka-console-producer.sh --broker-list kafka1.example.com:9092,kafka2.example.com:9092 --topic my-topicsample message 1sample message 2^D#
就像控制台使用者一样,也可以将任何正常的生产者配置选项传递给控制台生产者。这可以通过两种方式完成,具体取决于您需要通过多少个选项以及您喜欢如何通过。第一种是通过指定 --producer.config CONFIGFILE 来提供生产者配置文件,其中 CONFIGFILE 是包含配置选项的文件的完整路径。另一种方法是在命令行上使用一个或多个 --producer-property KEY=VALUE 形式的参数指定选项,其中 KEY 是配置选项名称,VALUE 是要将其设置为的值。这对于创建者选项(如消息批处理配置,如 linger.ms 或 batch.size)非常有用。
控制台生成者有许多命令行参数可用于调整其行为。一些更有用的选项是:
-
--key-serializer 类名 指定要用于序列化消息键的消息编码器类。默认为 kafka.serializer.DefaultEncoder。
-
--value-serializer 类名 指定要用于序列化消息值的消息编码器类。默认为 kafka.serializer.DefaultEncoder。
-
--compression-codec 字符串 指定生成消息时要使用的压缩类型。这可以是 none、gzip、snappy 或 lz4 之一。默认值为 gzip。
-
--同步 同步生成消息,等待每条消息被确认,然后再发送下一条消息。
* 创建自定义序列化程序自定义序列化程序必须扩展 kafka.serializer.Encoder。这可用于从标准输入中获取字符串,并将其转换为适合主题的编码,例如 Avro 或 Protobuf。
-
行读取器选项 kafka.tools.LineMessageReader 类负责读取标准输入和创建生产者记录,它还有几个有用的选项,可以使用 --property 命令行选项将其传递给控制台生产者:
-
ignore.error
设置为“false”以在 parse.key 设置为 true 且不存在键分隔符时引发异常。默认值为 true。
-
parse.key(解析键)
设置为 false 将始终将键设置为 null。默认值为 true。
-
key.separator
指定读取时要在消息键和消息值之间使用的分隔符。默认为制表符。
生成消息时,LineMessageReader 将拆分 key.separator 的第一个实例上的输入。如果之后没有剩余字符,则消息的值将为空。如果行中没有键分隔符,或者 parse.key 为 false,则键将为 null。
-
9.6 客户端 ACL
提供了一个命令行工具 kafka-acls.sh,用于与 Kafka 客户端的访问控制进行交互。Apache Kafka 网站上提供了有关 ACL 和安全性的其他文档。
9.7 不安全的操作
有些管理任务在技术上是可行的,但除非在最极端的情况下,否则不应尝试。通常,当您诊断问题并且没有选择时,或者您发现了需要临时解决的特定错误。这些任务通常未记录、不受支持,并且会给应用程序带来一定程度的风险。
此处记录了其中几个更常见的任务,以便在紧急情况下,有一个潜在的恢复选项。不建议在正常的群集操作下使用它们,在执行之前应仔细考虑。
* 危险:龙来了本节中的操作涉及直接处理存储在 Zookeeper 中的集群元数据。这可能是一个非常危险的操作,因此您必须非常小心,除非另有说明,否则不要直接修改 Zookeeper 中的信息。
9.7.1 移动群集控制器
每个 Kafka 集群都有一个控制器,该控制器是在其中一个代理中运行的线程。控制器负责监督集群操作,并且不时需要将控制器强行移动到不同的代理。一个这样的例子是,当控制器遇到异常或其他问题时,它使它保持运行但无法正常工作。在这些情况下移动控制器的风险并不高,但这不是一项正常任务,不应定期执行。
当前作为控制器的代理使用名为/controller的集群路径顶层的 Zookeeper 节点注册自身。手动删除此 Zookeeper 节点将导致当前控制器辞职,并且集群将选择新的控制器。
9.7.2 终止分区移动
分区重新分配的正常操作流程为:
-
请求重新分配(已创建 Zookeeper 节点)。
-
集群控制器将分区添加到要添加的新代理中。
-
新代理开始复制每个分区,直到它同步为止。
-
群集控制器从分区副本列表中删除旧代理。
由于所有重新分配在请求时都是并行开始的,因此通常没有理由尝试取消正在进行的重新分配。其中一个例外情况是,代理在重新分配过程中发生故障,无法立即重新启动。这会导致永远无法完成的重新分配,从而无法启动任何其他重新分配(例如,从失败的代理中删除分区并将其分配给其他代理)。在这种情况下,可以使集群忘记现有的重新分配。
-
从 Kafka 集群路径中删除 /admin/reassign_partitions Zookeeper 节点。
-
强制移动控制器(有关详细信息,请参见第 208 页的“移动群集控制器”)。
* 检查复制因子删除正在进行的分区移动时,任何尚未完成的分区都不会执行从副本列表中删除旧代理的步骤。这意味着某些分区的复制因子可能大于预期。代理将不允许对具有具有不一致复制因子的分区(例如增加分区)的主题执行某些管理操作。建议查看仍在进行中的分区,并确保其复制因子在另一个分区重新分配时正确无误。
9.7.3 删除要删除的主题
使用命令行工具删除主题时,Zookeeper 节点会请求创建删除操作。在正常情况下,集群会立即执行此操作。但是,命令行工具无法知道集群中是否启用了主题删除。因此,无论如何,它都会请求删除主题,如果禁用删除,可能会导致意外。可以删除待删除的主题请求以避免这种情况。
通过在 /admin/delete_topic 下创建一个 Zookeeper 节点作为子节点来请求删除主题,该节点以主题名称命名。删除这些 Zookeeper 节点(但不是父 /admin/delete_topic 节点)将删除待处理的请求。
9.7.4 手动删除主题
如果您运行的集群禁用了删除主题,或者您发现自己需要删除正常操作流程之外的某些主题,则可以从集群中手动删除这些主题。但是,这需要完全关闭集群中的所有代理,并且不能在集群中的任何代理运行时执行此操作。
* 首先关闭经纪人在集群在线时修改 Zookeeper 中的集群元数据是一个非常危险的操作,可能会使集群进入不稳定状态。切勿在集群联机时尝试删除或修改 Zookeeper 中的主题元数据。
要从集群中删除主题,请执行以下操作:
-
关闭集群中的所有代理。
-
从 Kafka 集群路径中删除 Zookeeper 路径 /brokers/topics/TOPICNAME。请注意,此节点具有必须首先删除的子节点。
-
从每个代理上的日志目录中删除分区目录。它们将被命名为 TOPICNAME-NUM,其中 NUM 是分区 ID。
-
重新启动所有代理。
9.8 总结
运行 Kafka 集群可能是一项艰巨的任务,需要执行大量配置和维护任务,以保持系统以最佳性能运行。在本章中,我们讨论了许多例行任务,例如管理需要经常处理的主题和客户端配置。我们还介绍了调试问题所需的一些更深奥的任务,例如检查日志段。最后,我们介绍了一些操作,这些操作虽然不安全或常规,但可以用来帮助您摆脱困境。总而言之,这些工具将帮助您管理 Kafka 集群。
当然,如果没有适当的监控,就不可能管理集群。第 10 章将讨论如何监控代理和集群的运行状况和操作,以便您可以确保 Kafka 运行良好(并知道何时运行不正常)。我们还将提供监控您的客户(包括生产者和消费者)的最佳实践。
第十章 监控 Kafka
Apache Kafka 应用程序对其操作进行了大量测量,事实上,如此之多,以至于很容易让人混淆哪些是重要的,哪些是可以搁置的。这些指标的范围从有关总体流量速率的简单指标,到每种请求类型的详细计时指标,再到每个主题和每个分区的指标。它们提供了代理中每个操作的详细视图,但它们也可能使您成为负责管理监控系统的人的祸根。
本节将详细介绍需要始终监控的最关键指标,以及如何应对这些指标。我们还将介绍调试问题时手头的一些更重要的指标。但是,这并不是可用指标的详尽列表,因为该列表经常更改,并且许多指标仅对硬编码 Kafka 开发人员提供信息。
10.1 指标基础知识
在了解 Kafka 代理和客户端提供的特定指标之前,让我们先讨论一下如何监控 Java 应用程序的基础知识,以及一些有关监控和警报的最佳实践。这将为了解如何监视应用程序以及为什么选择本章后面描述的特定指标作为最重要的指标提供基础。
10.1.1 指标在哪里?
Kafka 公开的所有指标都可以通过 Java 管理扩展 (JMX) 接口进行访问。在外部监视系统中使用它们的最简单方法是使用监视系统提供的收集代理并将其附加到 Kafka 进程。这可能是一个单独的进程,在系统上运行并连接到 JMX 接口,例如使用 Nagios XI check_jmx 插件或 jmxtrans。您还可以利用直接在 Kafka 进程中运行的 JMX 代理通过 HTTP 连接(例如 Jolokia 或 MX4J)访问指标。
关于如何设置监视代理的深入讨论超出了本章的范围,并且有太多的选择无法公正地对待所有这些代理。如果您的组织目前没有监视 Java 应用程序的经验,那么将监视视为一项服务可能是值得的。有许多公司在服务包中提供监视代理、指标收集点、存储、图形和警报。它们可以帮助您进一步设置所需的监视代理。
* 查找 JMX 端口为了帮助配置直接连接到 Kafka 代理上的 JMX 的应用程序(例如监视系统),代理在存储在 Zookeeper 中的代理信息中设置配置的 JMX 端口。/brokers/ids/<ID> znode 包含代理的 JSON 格式数据,包括主机名和 jmx_port 密钥。
10.1.2 内部或外部测量
通过 JMX 等接口提供的指标是内部指标:它们由被监视的应用程序创建和提供。对于许多内部测量,例如单个请求阶段的时间,这是最佳选择。除了应用程序本身之外,没有其他东西具有这种详细程度。还有其他指标,例如请求的总时间或特定请求类型的可用性,可以在外部进行测量。这意味着 Kafka 客户端或其他一些第三方应用程序为服务器(在我们的例子中为代理)提供指标。这些通常是可用性(代理是否可访问?)或延迟(请求需要多长时间?)等指标。它们提供了应用程序的外部视图,该视图通常提供更多信息。
外部测量值的一个熟悉示例是监控网站的运行状况。Web 服务器运行正常,并且它报告的所有指标都表明它正在工作。但是,Web 服务器和外部用户之间的网络存在问题,这意味着任何用户都无法访问 Web 服务器。在您的网络外部运行的外部监控会检查网站的可访问性,它会检测到这一点并提醒您注意这种情况。
10.1.3 应用程序运行状况检查
无论您如何从 Kafka 收集指标,您都应该确保通过简单的运行状况检查来监控应用程序进程的整体运行状况。这可以通过两种方式完成: • 报告代理是启动还是关闭(运行状况检查)的外部进程 • 在 Kafka 代理报告的指标缺失时发出警报(有时称为过时指标) 尽管第二种方法有效,但它可能使区分 Kafka 代理的故障和监控系统本身的故障变得困难。
对于 Kafka 代理,这可以简单地连接到外部端口(客户端用于连接到代理的同一端口)以检查它是否响应。对于客户端应用程序,它可能更复杂,从简单检查进程是否正在运行到确定应用程序运行状况的内部方法。
10.1.4 指标覆盖率
特别是当考虑到 Kafka 公开的测量数量时,挑选你所看到的内容是很重要的。当根据这些测量值定义警报时,这一点变得更加重要。屈服于“警报疲劳”太容易了,因为有太多的警报响起,很难知道问题的严重性。也很难正确定义每个指标的阈值并使其保持最新。当警报不堪重负或经常不正确时,我们开始不相信警报正确描述了应用程序的状态。
拥有一些具有高级别覆盖率的警报会更有利。例如,您可能有一个警报,指示存在一个大问题,但您可能必须收集其他数据来确定该问题的确切性质。可以把它想象成汽车上的检查引擎灯。仪表板上有 100 个不同的指示器来显示空气滤清器、机油、排气等的个别问题会令人困惑。相反,一个指标告诉你存在问题,并且有一种方法可以找出更详细的信息,告诉你问题到底是什么。在本章中,我们将确定将提供最高覆盖范围的指标,以保持警报的简单性。
10.2 Kafka Broker 指标
有许多 Kafka 代理指标。其中许多是低级度量,由开发人员在调查特定问题时添加,或者预计以后需要信息进行调试。有一些指标提供了代理中几乎所有功能的信息,但最常见的指标提供了每天运行 Kafka 所需的信息。
* 谁在看守望者?许多组织使用 Kafka 来收集应用程序指标、系统指标和日志,以供中央监控系统使用。这是将应用程序与监控系统分离的绝佳方式,但它给 Kafka 本身带来了一个特定的问题。如果您使用相同的系统来监视 Kafka 本身,您很可能永远不会知道 Kafka 何时中断,因为监视系统的数据流也会中断。
有很多方法可以解决这个问题。一种方法是为 Kafka 使用一个单独的监控系统,该系统不依赖于 Kafka。如果有多个数据中心,另一种方法是确保将数据中心 A 中 Kafka 集群的指标生成到数据中心 B,反之亦然。无论您决定如何处理它,请确保 Kafka 的监视和警报不依赖于 Kafka 的工作。
在本节中,我们将首先讨论作为整体性能度量的未复制分区指标,以及如何应对它。所讨论的其他指标将在高层次上完善经纪人的观点。这绝不是代理指标的详尽列表,而是用于检查代理和集群运行状况的几个“必备”指标。在继续讨论客户端指标之前,我们将讨论日志记录。
10.2.1 复制不足的分区
如果只能从 Kafka 代理监控一个指标,则该指标应该是复制不足的分区数。此度量值在集群中的每个代理上提供,它提供了代理作为主要副本的分区数的计数,在这些分区中,跟随副本未被赶上。通过这种单一的测量,可以深入了解 Kafka 集群的许多问题,从代理故障到资源耗尽。由于该指标可能指示各种各样的问题,因此值得深入研究如何响应零以外的值。本章稍后将介绍用于诊断这些类型问题的许多指标。有关复制不足的分区的更多详细信息,请参见表 10-1。
表 10-1.衡量指标及其相应的复制不足分区
| 指标名称 | 复制不足的分区 |
|---|---|
| JMX MBean kafka.server | type=ReplicaManager,name=UnderReplicatedPartitions |
| 取值范围 | 整数、零或更大 |
集群中的许多代理报告的复制不足分区的稳定(不变)数量通常表示集群中的某个代理处于脱机状态。整个集群中复制不足的分区计数将等于分配给该代理的分区数,并且关闭的代理不会报告衡量指标。在这种情况下,您将需要调查该经纪人发生了什么并解决该情况。这通常是硬件故障,但也可能是导致问题的操作系统或 Java 问题。
* 首选副本选举在尝试进一步诊断问题之前,第一步是确保您最近运行了首选副本选举(请参见第 9 章)。Kafka 代理在释放领导权后(例如,当代理发生故障或关闭时)不会自动收回分区领导权(除非启用了自动领导权重新平衡,但不建议使用此配置)。这意味着主副本在群集中很容易变得不平衡。首选的副本选举安全且易于运行,因此最好先执行此操作,看看问题是否消失。
如果复制不足的分区数在波动,或者如果数量稳定但没有脱机代理,这通常表示集群中存在性能问题。由于这些类型的问题种类繁多,因此更难诊断,但您可以通过几个步骤将其缩小到最可能的原因。第一步是尝试确定问题与单个代理有关还是与整个集群有关。这有时可能是一个很难回答的问题。如果复制不足的分区位于单个代理上,则该代理通常是问题所在。该错误表明其他代理在从该代理复制消息时遇到问题。
如果多个代理的分区复制不足,则可能是集群问题,但它可能仍然是单个代理。在这种情况下,这是因为单个代理在从任何地方复制消息时遇到问题,您必须弄清楚它是哪个代理。一种方法是获取集群的复制不足分区列表,并查看是否存在对所有复制不足的分区通用的特定代理。使用 kafka-topics.sh 工具(在第 9 章中详细讨论),您可以获取复制不足的分区列表以查找公共线程。
例如,列出群集中复制不足的分区:
# kafka-topics.sh --zookeeper zoo1.example.com:2181/kafka-cluster --describe --under-replicatedTopic: topicOne Partition: 5 Leader: 1 Replicas: 1,2 Isr: 1Topic: topicOne Partition: 6 Leader: 3 Replicas: 2,3 Isr: 3Topic: topicTwo Partition: 3 Leader: 4 Replicas: 2,4 Isr: 4Topic: topicTwo Partition: 7 Leader: 5 Replicas: 5,2 Isr: 5Topic: topicSix Partition: 1 Leader: 3 Replicas: 2,3 Isr: 3Topic: topicSix Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1Topic: topicSix Partition: 5 Leader: 6 Replicas: 2,6 Isr: 6Topic: topicSix Partition: 7 Leader: 7 Replicas: 7,2 Isr: 7Topic: topicNine Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1Topic: topicNine Partition: 3 Leader: 3 Replicas: 2,3 Isr: 3Topic: topicNine Partition: 4 Leader: 3 Replicas: 3,2 Isr: 3Topic: topicNine Partition: 7 Leader: 3 Replicas: 2,3 Isr: 3Topic: topicNine Partition: 0 Leader: 3 Replicas: 2,3 Isr: 3Topic: topicNine Partition: 5 Leader: 6 Replicas: 6,2 Isr: 6#
在此示例中,公共代理是 2 号代理。这表明该代理在消息复制方面存在问题,这将导致我们将调查重点放在该代理上。如果没有通用代理,则可能存在集群范围的问题。
-
集群级问题
集群问题通常分为两类: • 负载不平衡 • 资源枯竭 第一个问题,不平衡的分区或领导,是最容易发现的,即使修复它可能是一个复杂的过程。为了诊断此问题,您将需要来自集群中代理的几个指标: • 分区计数 • 主分区计数 • 所有主题字节的速率 • 所有主题消息的速率 检查这些指标。在完全平衡的集群中,集群中所有代理的数字都是均匀的,如表 10-2 所示。
表 10-2.利用率指标
Broker Partitions Leaders Bytes in Bytes out 1 100 50 3.56 MB/秒 9.45 MB/秒 2 101 49 3.66 MB/秒 9.25 MB/秒 3 100 50 3.23 MB/秒 9.82 MB/秒 这表明所有代理都占用了大致相同的流量。假设您已经运行了首选副本选举,则较大的偏差表示集群内的流量不平衡。要解决此问题,您需要将分区从负载较重的代理移动到负载较轻的代理。这是使用第 9 章中描述的 kafka-reassign-partitions.sh 工具完成的。
* 用于平衡群集的帮助程序Kafka 代理本身不提供集群中分区的自动重新分配。这意味着在 Kafka 集群中平衡流量可能是一个令人麻木的过程,需要手动查看一长串指标并尝试提出有效的副本分配。为了帮助解决这个问题,一些组织开发了用于执行此任务的自动化工具。一个例子是 LinkedIn 在 GitHub 上的开源 kafka-tools 存储库中发布的 kafka-assigner 工具。一些 Kafka 支持的企业产品也提供此功能。
另一个常见的集群性能问题是超出了代理处理请求的能力。有许多可能的瓶颈可能会减慢速度:CPU、磁盘 IO 和网络吞吐量是最常见的一些。磁盘利用率不是其中之一,因为在磁盘被填满之前,代理将正常运行,然后该磁盘将突然发生故障。为了诊断容量问题,可以在操作系统级别跟踪许多指标,包括: • CPU 利用率 • 入站网络吞吐量 • 出站网络吞吐量 • 磁盘平均等待时间 • 磁盘利用率百分比
耗尽这些资源中的任何一个通常都会显示为相同的问题:分区复制不足。请务必记住,代理复制过程的运行方式与其他 Kafka 客户端完全相同。如果您的集群在复制方面存在问题,那么您的客户在生成和使用消息方面也会遇到问题。当集群正常运行时,为这些指标制定基线是有意义的,然后设置阈值,在容量耗尽之前很久就指示正在发生的问题。您还需要查看这些指标的趋势,因为集群的流量会随着时间的推移而增加。就 Kafka 代理指标而言,All Topics Bytes In Rate 是显示集群使用情况的良好指南。
-
主机级问题
如果 Kafka 的性能问题不存在于整个集群中,并且可以隔离到一个或两个代理,那么是时候检查该服务器并查看它与集群其余部分的不同之处了。这些类型的问题分为几大类: • 硬件故障 • 与其他进程冲突 • 本地配置差异
* 典型服务器和问题服务器及其操作系统是一台复杂的机器,包含数千个组件,其中任何一个都可能出现问题,并导致完全故障或性能下降。我们不可能在这本书中涵盖所有可能失败的东西——关于这个主题已经写了许多卷,并将继续写。但是我们可以讨论一些最常见的问题。本节将重点介绍运行 Linux 操作系统的典型服务器的问题。
首先,请确保从 IPMI 或硬件提供的接口监视磁盘的硬件状态信息。此外,在操作系统中,您应该运行 SMART(自我监控、分析和报告技术)工具来定期监控和测试磁盘。这将提醒您即将发生的故障。密切关注磁盘控制器也很重要,特别是如果它具有 RAID 功能,无论您是否使用硬件 RAID。许多控制器都有一个板载缓存,仅当控制器运行正常且备用电池单元 (BBU) 工作时才使用。BBU 故障可能导致缓存被禁用,从而降低磁盘性能。
网络是部分故障会导致问题的另一个领域。其中一些问题是硬件问题,例如网络电缆或连接器损坏。有些是配置问题,通常是连接速度或双工设置的更改,无论是在服务器端还是在网络硬件的上游。网络配置问题也可能是操作系统问题,例如网络缓冲区大小过小,或者网络连接过多,占用了太多的整体内存占用量。该领域问题的关键指标之一是在网络接口上检测到的错误数量。如果错误计数增加,则可能存在未解决的问题。
如果没有硬件问题,另一个要查找的常见问题是系统上运行的另一个应用程序正在消耗资源并给 Kafka 代理带来压力。这可能是错误安装的内容,也可能是应该运行的进程(例如监视代理),但存在问题。使用系统上的工具(例如 top)来确定是否有进程使用的 CPU 或内存超过预期。
如果其他选项已用尽,并且您尚未在主机上找到差异的来源,那么配置差异可能已经悄悄出现,无论是代理还是系统本身。考虑到任何一台服务器上运行的应用程序数量以及每个应用程序的配置选项数量,查找差异可能是一项艰巨的任务。这就是为什么使用配置管理系统(如 Chef 或 Puppet)以在操作系统和应用程序(包括 Kafka)之间保持一致的配置至关重要的原因。
10.2.2 经纪人指标
除了复制不足的分区之外,还应监视整个代理级别的其他指标。虽然您可能不愿意为所有这些设置警报阈值,但它们提供了有关代理和集群的宝贵信息。它们应存在于您创建的任何监视仪表板中。
10.2.2.1 主动控制器计数
活动控制器计数指标指示代理当前是否是集群的控制器。指标将为 0 或 1,其中 1 表示代理当前是控制器。在任何时候,都只能有一个代理是控制器,并且一个代理必须始终是集群中的控制器。如果两个代理说他们当前是控制器,这意味着您遇到了一个问题,即本应退出的控制器线程卡住了。这可能会导致无法正确执行管理任务(如分区移动)的问题。要解决此问题,您至少需要重新启动两个代理。但是,当集群中有额外的控制器时,在执行代理的受控关闭时经常会出现问题。有关活动控制器计数的更多详细信息,请参见表 10-3。
表 10-3.Acive 控制器计数指标
| 指标名称 | 活动控制器计数 |
|---|---|
| JMX MBean kafka.controller | type=KafkaController,name=ActiveControllerCount |
| 取值范围 | 零或一 |
如果没有代理声称自己是集群中的控制器,那么集群将无法在状态更改(包括主题或分区创建或代理故障)时正确响应。在这种情况下,您必须进一步调查以找出控制器线程无法正常工作的原因。例如,来自 Zookeeper 群集的网络分区可能会导致这样的问题。一旦解决了该潜在问题,明智的做法是重新启动集群中的所有代理,以便重置控制器线程的状态。
10.2.2.2 请求处理程序空闲比率
Kafka 使用两个线程池来处理所有客户端请求:网络处理程序和请求处理程序。网络处理程序线程负责通过网络向客户端读取和写入数据。这不需要大量处理,这意味着网络处理程序的耗尽问题就不那么重要了。但是,请求处理程序线程负责为客户端请求本身提供服务,其中包括将消息读取或写入磁盘。因此,随着代理负载的增加,对这个线程池有重大影响。有关请求处理程序空闲比率的更多详细信息,请参见表 10-4。
表 10-4.请求处理程序空闲比率
| 指标名称 | 请求处理程序平均空闲百分比 |
|---|---|
| JMX MBean kafka.server | type=KafkaRequestHandlerPool,name=RequestHandlerAvgIdlePercent |
| 值范围 | Float,介于 0 和 1 之间 |
* 智能线程使用虽然看起来您需要数百个请求处理程序线程,但实际上,您不需要配置比代理中的 CPU 更多的线程。Apache Kafka 在使用请求处理程序的方式上非常聪明,确保将需要很长时间才能处理的请求卸载到炼狱中。例如,当引用请求或需要对生产请求进行多次确认时,会使用此功能。
请求处理程序空闲比率指标指示请求处理程序未使用的时间百分比。这个数字越低,代理的负载就越大。经验告诉我们,低于 20% 的空闲比率表示存在潜在问题,低于 10% 通常是主动性能问题。除了群集大小过小之外,此池中线程利用率高的原因还有两个。首先是池中没有足够的线程。通常,应将请求处理程序线程数设置为等于系统中的处理器数(包括超线程处理器)。 请求处理程序线程利用率高的另一个常见原因是线程对每个请求执行不必要的工作。在 Kafka 0.10 之前,请求处理程序线程负责解压缩每个传入消息批次,验证消息并分配偏移量,然后在将消息批次写入磁盘之前使用偏移量重新压缩消息批次。更糟糕的是,压缩方法都位于同步锁后面。从版本 0.10 开始,有一种新的消息格式,允许在消息批处理中进行相对偏移。这意味着较新的生产者将在发送消息批处理之前设置相对偏移量,这允许代理跳过消息批处理的重新压缩。您可以进行的最大性能改进之一是确保所有生产者和使用者客户端都支持 0.10 消息格式,并将代理上的消息格式版本也更改为 0.10。这将大大降低请求处理程序线程的利用率。
10.2.2.3 所有主题字节输入
所有主题字节数(以每秒字节数表示)可用于衡量代理从生产客户端接收的消息流量。这是一个很好的指标,可以随时间推移呈趋势,以帮助您确定何时需要扩展集群或执行其他与增长相关的工作。它还可用于评估集群中的一个代理是否比其他代理接收更多的流量,这表明有必要重新平衡集群中的分区。有关详细信息,请参见表 10-5。
表 10-5.指标中所有主题字节的详细信息
| 指标名称 | 每秒字节数 |
|---|---|
| JMX MBean kafka.server | type=BrokerTopicMetrics,name=BytesInPerSec |
| 取值范围 | 双倍费率,计为整数 |
由于这是讨论的第一个速率指标,因此值得简要讨论这些类型的指标提供的属性。所有费率指标都有 7 个属性,选择要使用的属性取决于您想要的衡量类型。这些属性提供离散的事件计数,以及不同时间段内事件数的平均值。确保适当地使用这些指标,否则你最终会得到一个有缺陷的经纪人视图。
前两个属性不是度量值,但它们将帮助您了解正在查看的指标:
-
事件类型
-
这是所有属性的度量单位。在本例中,它是“字节”。
-
速率单位 对于费率属性,这是费率的时间段。在本例中,它是“SEC-ONDS”。
这两个描述性属性告诉我们,无论速率平均在多长时间段内,它们都表示为每秒字节数的值。提供了四个具有不同粒度的速率属性:
-
一分钟率 前 1 分钟的平均值。
-
五分钟率 前 5 分钟的平均值。
-
十五分钟率 前 15 分钟的平均值。
-
平均利率 自经纪商启动以来的平均值。
OneMinuteRate 将快速波动,并提供更多的测量“时间点”视图。这对于查看流量的短暂峰值很有用。MeanRate 不会有太大变化,并提供整体趋势。尽管 MeanRate 有其用途,但它可能不是您想要收到警报的指标。FiveMinuteRate 和 Fifteen MinuteRate 在两者之间提供了折衷方案。
除了 rate 属性之外,还有一个 Count 属性。这是自代理启动以来指标的不断增加的值。对于此指标,所有主题字节数,Count 表示自进程启动以来向代理生成的总字节数。与支持反度量的指标系统一起使用,这可以为您提供测量的绝对视图,而不是平均率。
10.2.2.4 所有主题字节输出
所有主题的字节输出率,类似于字节数的输入率,是另一个整体增长指标。在本例中,字节输出速率显示使用者读出消息的速率。由于 Kafka 能够轻松处理多个使用者,因此出站字节速率的扩展方式可能与入站字节速率不同。在许多 Kafka 部署中,出站速率很容易达到入站速率的六倍!这就是为什么单独观察和趋势出站字节速率很重要的原因。有关详细信息,请参见表 10-6。
表 10-6.有关所有主题的详细信息 bytes out 指标
| 指标名称 | 每秒输出字节数 |
|---|---|
| JMX MBean kafka.server | type=BrokerTopicMetrics,name=BytesOutPerSec |
| 取值范围 | 双倍费率,计为整数 |
* 包括副本提取器出站字节速率还包括副本流量。这意味着,如果所有主题都配置了复制因子 2,则在没有使用者客户端时,您将看到字节输出速率等于字节输入速率。如果有一个使用者客户端读取集群中的所有消息,则字节输出速率将是字节输入速率的两倍。如果您不知道计算的内容,那么在查看指标时可能会感到困惑。
10.2.2.5 所有主题消息
前面描述的字节速率以字节为单位显示代理流量的绝对值,而消息速率显示每秒生成的单个消息数,无论其大小如何。这可作为增长指标,作为生产者流量的不同衡量标准。它还可以与字节数结合使用,以确定平均消息大小。您可能还会看到代理中的不平衡,就像字节速率一样,这将提醒您需要进行维护工作。有关详细信息,请参见表 10-7。
表 10-7.指标中所有主题消息的详细信息
| 指标名称 | 每秒消息数 |
|---|---|
| JMX MBean kafka.server | type=BrokerTopicMetrics,name=MessagesInPerSec |
| 取值范围 | 双倍费率,计为整数 |
* 为什么没有消息输出?人们经常问为什么 Kafka 代理没有消息输出指标。原因是,当消息被消费时,代理只是将下一批发送给消费者,而不展开它来找出里面有多少消息。因此,代理实际上并不知道发送了多少条消息。唯一可以提供的指标是每秒的提取次数,这是请求速率,而不是消息计数。
10.2.2.6 分区计数
代理的分区计数通常不会有太大变化,因为它是分配给该代理的分区总数。这包括代理拥有的每个副本,无论它是该分区的领导者还是追随者。在启用了自动主题创建的集群中,监控这一点通常更有趣,因为这可能会使主题的创建不受集群运行人员的控制。有关详细信息,请参见表 10-8。
表 10-8.有关分区计数指标的详细信息
| 指标名称 | 分区计数 |
|---|---|
| JMX MBean kafka.server | type=ReplicaManager,name=PartitionCount |
| 取值范围 | 整数、零或更大 |
10.2.2.7 引线计数
leader count 指标显示代理当前是其领导者的分区数。与代理中的大多数其他度量一样,此度量值通常应该在集群中的代理之间是均匀的。定期检查领导者计数更为重要,可能会对此发出警报,因为即使集群中的副本数量在计数和大小上完全平衡,它也会指示集群何时不平衡。这是因为代理可以出于多种原因(例如 Zookeeper 会话过期)删除分区的领导权,并且在恢复后不会自动收回领导权(除非您启用了自动领导重新平衡)。在这些情况下,此指标将显示较少的领导者,或者通常为零,这表明您需要运行首选副本选举来重新平衡集群中的领导者。有关详细信息,请参见表 10-9。
表 10-9.有关领导者计数指标的详细信息
| 指标名称 | Leader 计数 |
|---|---|
| JMX MBean | kafka.server:type=ReplicaManager,name=LeaderCount |
| 取值范围 | 整数、零或更大 |
使用此指标的一个有用方法是将其与分区计数一起使用,以显示代理是其领导者的分区百分比。在使用复制因子 2 的均衡集群中,所有代理都应是其大约 50% 分区的领导者。如果使用的复制因子为 3,则此百分比将降至 33%。
10.2.2.8 脱机分区
除了复制不足的分区计数外,脱机分区计数也是监视的关键指标(请参阅表 10-10)。此度量仅由作为集群控制器的代理提供(所有其他代理将报告 0),并显示集群中当前没有主节点的分区数。没有领导者的分区可能有两个主要原因: • 托管此分区副本的所有代理都已关闭 • 由于消息计数不匹配(禁用不干净的领导者选举),任何同步副本都不能担任领导职务
表 10-10.“脱机分区计数”指标
| 指标名称 | 脱机分区计数 |
|---|---|
| JMX MBean | kafka.controller:type=KafkaController,name=OfflinePartitionsCount |
| 取值范围 | 整数、零或更大 |
在生产 Kafka 集群中,脱机分区可能会影响生产者客户端、丢失消息或导致应用程序背压。这通常是“站点关闭”类型的问题,需要立即解决。
10.2.2.9 请求指标
第 5 章中描述的 Kafka 协议有许多不同的请求。提供了每个请求的执行方式的指标。以下请求提供了指标:
-
Api版本( ApiVersions)
-
受控关机(ControlledShutdown)
-
创建主题(CreateTopics)
-
删除主题(DeleteTopics)
-
描述组(DescribeGroups)
-
获取(Fetch)
-
FetchConsumer(获取消费者)
-
FetchFollower (获取追随者)
-
小组协调员(GroupCoordinator)
-
心跳(Heartbeat)
-
加入组(JoinGroup)
-
领导AndIsr(LeaderAndIsr)
-
离开组(LeaveGroup)
-
列表组(ListGroups)
-
元数据(Metadata)
-
偏移提交(OffsetCommit)
-
偏移量取值(OffsetFetch)
-
补偿(Offsets)
-
生产(Produce)
-
SaslHandshake
10.2.3 主题和分区指标
除了代理上许多可用于描述 Kafka 代理操作的指标外,还有一些特定于主题和分区的指标。在较大的集群中,这些可能很多,并且可能无法作为正常操作将所有这些收集到一个指标系统中。但是,它们对于调试客户端的特定问题非常有用。例如,主题指标可用于识别导致集群流量大幅增加的特定主题。提供这些指标也很重要,以便 Kafka 的用户(生产者和消费者客户端)能够访问它们。无论您是否能够定期收集这些指标,您都应该了解哪些指标是有用的。
10.2.3.1 每个主题的指标
对于所有每个主题的指标,测量值与前面描述的代理指标非常相似。事实上,唯一的区别是提供的主题名称,并且指标将特定于命名主题。鉴于可用的指标数量庞大,具体取决于集群中存在的主题数量,这些指标几乎可以肯定是您不希望为其设置监视和警报的指标。但是,它们对于提供给客户端很有用,以便他们可以评估和调试自己的 Kafka 使用情况。
对于表 10-12 中的所有示例,我们将使用示例主题名称 TOPIC NAME 以及分区 0。在访问所描述的指标时,请确保替换适合您的集群的主题名称和分区号。
表 10-12.每个主题的指标
| 名称 | JMX MBean |
|---|---|
| 速率中的字节数 | kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec,topic=TOPICNAME |
| 字节输出率 | kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec,topic=TOPICNAME |
| 失败的提取率 | kafka.server:type=BrokerTopicMetrics,name=FailedFetchRequestsPerSec,topic=TOPICNAME |
| 失败的产生率 | kafka.server:type=BrokerTopicMetrics,name=FailedProduceRequestsPerSec,topic=TOPICNAME |
| 消息速率 | kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec,topic=TOPICNAME |
| Fetch 请求速率 | kafka.server:type=BrokerTopicMetrics,name=TotalFetchRequestsPerSec,topic=TOPICNAME |
| 生成请求速率 | kafka.server:type=BrokerTopicMetrics,name=TotalProduceRequestsPerSec,topic=TOPICNAME |
10.2.3.2 每个分区的指标
与每个主题的指标相比,每个分区的指标在持续的基础上往往不太有用。此外,它们的数量相当多,因为数百个主题很容易成为数千个分区。然而,它们在某些有限的情况下可能很有用。具体而言,分区大小指标指示当前保留在磁盘上的分区数据量(以字节为单位)(表 10-13)。综合起来,这些将指示为单个主题保留的数据量,这在将 Kafka 的成本分配给单个客户端时很有用。同一主题的两个分区大小之间的差异可能表示消息在生成时使用的密钥上分布不均匀的问题。log-segment count 指标显示分区磁盘上的日志段文件数。这可能与用于资源跟踪的分区大小一起有用。
表 10-13.每个主题的指标
| 名称 | JMX MBean |
|---|---|
| 分区大小 kafka.log | type=Log,name=Size,topic=TOPICNAME,partition=0 |
| 日志段计数 kafka.log | type=Log,name=NumLogSegments,topic=TOPICNAME,partition=0 |
| 日志结束偏移量 | kafka.log:type=Log,name=LogEndOffset,topic=TOPICNAME,partition=0 |
| 日志开始偏移量 | kafka.log:type=Log,name=LogStartOffset,topic=TOPICNAME,partition=0 |
日志结束偏移量和日志开始偏移量指标分别是该分区中消息的最高偏移量和最低偏移量。但是,应该注意的是,这两个数字之间的差异并不一定表示分区中的消息数,因为日志压缩可能会导致“丢失”偏移量,这些偏移量由于具有相同键的新消息而从分区中删除。在某些环境中,跟踪分区的这些偏移量可能很有用。一个这样的用例是提供更精细的时间戳到偏移量的映射,允许消费者客户端轻松地将偏移量回滚到特定时间(尽管这对于 Kafka 0.10.1 中引入的基于时间的索引搜索来说不太重要)。
* 复制不足的分区衡量指标提供了每个分区的衡量指标,用于指示分区是否复制不足。一般来说,这在日常操作中不是很有用,因为有太多的指标需要收集和观察。监视代理范围的复制不足的分区计数,然后使用命令行工具(如第 9 章所述)来确定复制不足的特定分区要容易得多.
10.2.4 JVM监控
除了 Kafka 代理提供的指标之外,您还应该监控所有服务器以及 Java 虚拟机 (JVM) 本身的标准度量套件。这些将用于提醒您注意会降低代理性能的情况,例如增加垃圾回收活动。它们还将深入了解为什么您会看到代理下游指标的变化。
10.2.4.1 垃圾回收
对于 JVM,要监控的关键是垃圾回收 (GC) 的状态。您必须监视此信息的特定 Bean 将因您使用的特定 Java 运行时环境 (JRE) 以及正在使用的特定 GC 设置而异。对于使用 G1 垃圾回收运行的 Oracle Java 1.8 JRE,要使用的 Bean 如表 10-14 所示。
表 10-14.G1 垃圾回收指标
| 名称 | JMX MBean |
|---|---|
| 完整的 GC 循环 | java.lang:type=GarbageCollector,name=G1 老一代 |
| 年轻的 GC 循环 | java.lang:type=GarbageCollector,name=G1 年轻一代 |
请注意,在 GC 的语义中,“Old”和“Full”是一回事。对于每个指标,要关注的两个属性是 CollectionCount 和 CollectionTime。CollectionCount 是自 JVM 启动以来该类型的 GC 周期数(完整或年轻)。CollectionTime 是自 JVM 启动以来在该类型的 GC 周期中花费的时间(以毫秒为单位)。由于这些测量值是计数器,因此度量系统可以使用它们来告诉您 GC 周期的绝对数量和每单位时间在 GC 中花费的时间。它们还可用于提供每个 GC 循环的平均时间量,尽管这在正常操作中不太有用。
其中每个指标还具有 LastGcInfo 属性。这是一个复合值,由五个字段组成,它为您提供有关 Bean 所描述的 GC 类型的最后一个 GC 周期的信息。要查看的重要值是持续时间值,因为它告诉您最后一个 GC 周期花费了多长时间(以毫秒为单位)。复合中的其他值(GcThreadCount、id、startTime 和 endTime)仅供参考,不是很有用。需要注意的是,使用此属性,您将无法查看每个 GC 周期的时间,因为年轻的 GC 周期尤其会频繁发生。
10.2.4.2 Java OS 监控
JVM 可以通过 java.lang:type=OperatingSystem bean 为您提供有关操作系统的一些信息。但是,此信息是有限的,并不代表您需要了解的有关运行代理的系统的所有信息。此处可以收集的两个有用的属性,在操作系统中很难收集,它们是 MaxFileDescriptorCount 和 OpenFileDescriptor Count 属性。MaxFileDescriptorCount 将告诉您允许 JVM 打开的文件描述符 (FD) 的最大数量。OpenFileDescriptor Count 属性告诉您当前打开的 FD 数。每个日志段和网络连接都会打开 FD,它们可以快速加起来。正确关闭网络连接时出现问题可能会导致代理快速耗尽允许的数量。
10.2.5 操作系统监控
JVM 无法为我们提供我们需要了解的有关运行它的系统的所有信息。因此,我们不仅要从代理收集指标,还要从操作系统本身收集指标。大多数监控系统都会提供代理,这些代理将收集比您可能感兴趣的更多的操作系统信息。需要注意的主要方面是 CPU 使用率、内存使用率、磁盘使用率、磁盘 IO 和网络使用率。
对于 CPU 利用率,您至少需要查看系统平均负载。这提供了一个数字,该数字将指示处理器的相对利用率。此外,捕获按类型细分的 CPU 使用率百分比也可能很有用。根据收集方法和您的特定操作系统,您可能会遇到以下部分或全部 CPU 百分比细分(随使用的缩写一起提供):
-
us 在用户空间中花费的时间。
-
sy 在内核空间中花费的时间。
-
ni 在低优先级进程上花费的时间。
-
id 闲置的时间。
-
wa 等待时间(在磁盘上)。
-
hi 处理硬件中断所花费的时间。
-
si 处理软件中断所花费的时间。
-
st 等待虚拟机管理程序的时间
* 什么是系统负载?虽然许多人都知道系统负载是系统上 CPU 使用率的度量,但大多数人误解了它是如何测量的。平均负载是可运行并等待处理器执行的进程数的计数。Linux 还包括处于不可中断休眠状态的线程,例如等待磁盘。负载以三个数字表示,即过去一分钟、5 分钟和 15 分钟的平均值。在单个 CPU 系统中,值为 1 表示系统已 100% 加载,线程始终等待执行。这意味着,在多 CPU 系统上,指示 100% 的平均负载数等于系统中的 CPU 数。例如,如果系统中有 24 个处理器,则 100% 的平均负载为 24。
Kafka 代理使用大量处理来处理请求。因此,在监视 Kafka 时,跟踪 CPU 利用率非常重要。对于代理本身来说,内存的跟踪不太重要,因为 Kafka 通常以相对较小的 JVM 堆大小运行。它将使用堆外部的少量内存进行压缩功能,但大部分系统内存将用于缓存。尽管如此,您仍应跟踪内存利用率,以确保其他应用程序不会侵犯代理。您还需要通过监视总交换内存量和可用交换内存量来确保未使用交换内存。
到目前为止,磁盘是 Kafka 中最重要的子系统。所有消息都持久化到磁盘上,因此 Kafka 的性能很大程度上取决于磁盘的性能。监控磁盘空间和 inode(inode 是 Unix 文件系统的文件和目录元数据对象)的使用情况非常重要,因为您需要确保空间不会不足。对于存储 Kafka 数据的分区尤其如此。还需要监控磁盘 IO 统计信息,因为这将告诉我们磁盘正在被有效使用。至少对于存储 Kafka 数据的磁盘,请监控每秒的读取和写入次数、平均读写队列大小、平均等待时间以及磁盘的利用率百分比。
最后,监视代理上的网络利用率。这只是入站和出站网络流量,通常以每秒比特数报告。请记住,Kafka 代理的每个入站位都将是等于主题复制因子的出站位数,没有使用者。根据使用者的数量,入站网络流量很容易比出站流量大一个数量级。在设置警报阈值时,请记住这一点。
10.2.6 日志
如果不对日志记录只字不提,任何关于监视的讨论都是不完整的。与许多应用程序一样,如果您允许,Kafka 代理将在几分钟内用日志消息填充磁盘。为了从日志记录中获取有用的信息,在正确的级别启用正确的记录器非常重要。只需在 INFO 级别记录所有消息,即可捕获有关代理状态的大量重要信息。但是,将几个记录器与此分开很有用,以便提供一组更干净的日志文件。
有两个记录器写入磁盘上的单独文件。第一个是 kafka.controller,仍处于 INFO 级别。此记录器用于提供专门有关群集控制器的消息。在任何时候,只有一个代理是控制者,因此只有一个代理会写入此记录器。这些信息包括主题创建和修改、代理状态更改以及集群活动,例如首选副本选举和分区移动。另一个要分离的记录器是 kafka.server.ClientQuotaManager,也是在 INFO 级别。此记录器用于显示与生产和消耗配额活动相关的消息。虽然这是有用的信息,但最好不要将其放在主代理日志文件中。
记录有关日志压缩线程状态的信息也很有帮助。没有单个指标来显示这些线程的运行状况,并且单个分区的压缩失败可能会以静默方式完全停止日志压缩线程。在 DEBUG 级别启用 kafka.log.LogCleaner、kafka.log.Cleaner 和 kafka.log.LogCleanerManager 记录器将输出有关这些线程状态的信息。这将包括有关正在压缩的每个分区的信息,包括每个分区中的消息大小和数量。在正常操作下,这不是很多日志记录,这意味着它可以默认启用,而不会让您不知所措。
在调试 Kafka 问题时,打开一些日志记录可能很有用。一个这样的记录器是 kafka.request.logger,它在 DEBUG 或 TRACE 级别打开。这将记录有关发送到代理的每个请求的信息。在 DEBUG 级别,日志包括连接端点、请求计时和摘要信息。在 TRACE 级别,它还将包括主题和分区信息 - 几乎所有请求信息都不包括消息负载本身。无论在哪个级别,此记录器都会生成大量数据,除非需要调试,否则不建议启用它。
10.3 客户端监控
所有应用程序都需要监控。实例化 Kafka 客户端的客户端(无论是生产者还是使用者)都具有特定于客户端的指标,这些指标应被捕获。本节介绍官方的 Java 客户端库,但其他实现应该有自己的测量值。
10.3.1 生产者指标
新的 Kafka 生产者客户端通过在少量 mbean 上作为属性提供指标,极大地压缩了可用的指标。相比之下,以前版本的生产者客户端(不再受支持)使用了更多的 mbean,但在许多指标中具有更多详细信息(提供更多的百分位数测量值和不同的移动平均值)。因此,提供的指标总数覆盖了更广阔的外围应用,但跟踪异常值可能更加困难。
所有生产者指标在 Bean 名称中都具有生产者客户机的客户机 ID。在提供的示例中,这已替换为 CLIENTID。如果 Bean 名称包含代理 ID,则已将其替换为 BROKERID。主题名称已替换为 TOPICNAME。有关示例,请参见表 10-15。
表 10-15.Kafka 生产者指标 MBean
| 名称 | JMX MBean |
|---|---|
| 整体生产者 | kafka.producer:type=producer-metrics,client-id=CLIENTID |
| 每个代理 | kafka.producer:type=producer-node-metrics,client-id=CLIENTID,node-id=node-BROKERID |
| 每个主题 | kafka.producer:type=producer-topic-metrics,client-id=CLIEN TID,topic=主题名称 |
表 10-15 中的每个度量 Bean 都有多个属性可用于描述生产者的状态。最常用的特定属性在第 236 页的“总体生产者指标”中进行了描述。在继续操作之前,请确保您了解生产者工作方式的语义,如第 3 章所述。
-
总体生产者指标
整体生产者指标 Bean 提供了描述从消息批处理大小到内存缓冲区利用率的所有内容的属性。虽然所有这些测量在调试中都有其用武之地,但只有少数需要定期使用,并且只有少数需要监视并发出警报。请注意,虽然我们将讨论几个平均值(以 -avg 结尾)的指标,但每个指标(以 -max 结尾)的最大值也有限。
record-error-rate 是您肯定希望为其设置警报的一个属性。此指标应始终为零,如果大于该值,则生产者将丢弃它试图发送给 Kafka 代理的消息。生产者具有配置的重试次数和这些重试次数之间的回退,一旦用尽,消息(此处称为记录)将被丢弃。还有一个可以跟踪的 record-retry-rate 属性,但它不如错误率重要,因为重试是正常的。
另一个要发出警报的指标是 request-latency-avg。这是发送给代理的生产请求所需的平均时间。您应该能够为正常操作中此数字应是多少建立基线值,并将警报阈值设置为高于该值。请求延迟的增加意味着生成请求的速度越来越慢。这可能是由于网络问题,也可能表明代理存在问题。无论哪种方式,这都是一个性能问题,会导致生产应用程序中出现背压和其他问题。
除了这些关键指标之外,了解您的生产者发送了多少消息流量总是件好事。三个属性将提供三种不同的视图。outgoing-byte-rate 以绝对大小(以每秒字节数为单位)描述消息。record-send-rate 根据每秒生成的消息数来描述流量。最后,request-rate 提供每秒发送到代理的 produce 请求数。单个请求包含一个或多个批处理。单个批处理包含一条或多条消息。当然,每条消息都由一定数量的字节组成。这些指标在应用程序仪表板上都很有用。
* 为什么不是 ProducerRequestMetrics?有一个名为 ProducerRequestMetrics 的生产者指标 bean,它提供了请求延迟的百分位数以及请求速率的几个移动平均值。那么,为什么它不是推荐使用的指标之一呢?问题在于,此指标是为每个生产者线程单独提供的。在出于性能原因使用多个线程的应用程序中,很难协调这些指标。通常,使用单个整体生产者 Bean 提供的属性就足够了。
还有一些指标描述了记录、请求和批处理的大小。request-size-avg 指标提供发送到代理的生成请求的平均大小(以字节为单位)。batch-size-avg 提供单个消息批处理(根据定义,由单个主题分区的消息组成)的平均大小(以字节为单位)。record-size-avg 显示单个记录的平均大小(以字节为单位)。对于单主题生产者,这提供了有关正在生成的消息的有用信息。对于多主题制作者,例如 Mirror Maker,它的信息量较少。除了这三个指标之外,还有一个 records-per-request-avg 指标,用于描述单个生成请求中的平均消息数。
建议的最后一个整体生产者指标属性是 record-queue-time-avg。此度量值是单个消息在应用程序发送后,在实际生成到 Kafka 之前在生产者中等待的平均时间(以毫秒为单位)。在应用程序调用生产者客户端以发送消息(通过调用 send 方法)后,生产者将等待,直到发生以下两种情况之一: • 它有足够的消息来填充基于 max.partition.bytes 配置的批处理 • 自上一批基于 linger.ms 配置发送以来,已经足够长了
这两者中的任何一个都会导致生产者客户端关闭它正在构建的当前批次并将其发送给代理。最简单的理解方法是,对于繁忙的主题,第一个条件将适用,而对于慢速主题,第二个条件将适用。record-queue-time-avg 度量值将指示生成消息所需的时间,因此在调整这两种配置以满足应用程序的延迟要求时非常有用。
-
每个代理和每个主题的指标
除了总体生产者指标之外,还有一些指标 Bean 为连接到每个 Kafka 代理以及正在生成的每个主题提供一组有限的属性。在某些情况下,这些度量值对于调试问题很有用,但它们不是您要持续查看的指标。这些 Bean 上的所有属性都与前面描述的整个生产者 Bean 的属性相同,并且具有与前面描述相同的含义(除了它们适用于特定代理或特定主题)。
每个代理生产者指标提供的最有用的指标是 request-latency-avg 度量。这是因为此指标将基本稳定(给定稳定的消息批处理),并且仍然可能显示与特定代理的连接存在问题。其他属性(如 outgoing-byte-rate 和 request-latency-avg)往往会因每个代理所领导的分区而异。这意味着这些测量值在任何时间点“应该”都会快速改变,具体取决于 Kafka 集群的状态。
主题指标比每个代理指标更有趣一些,但它们只对使用多个主题的生产者有用。它们也只有在制作人没有处理很多主题的情况下才能定期使用。例如,MirrorMaker 可以生成数百或数千个主题。很难查看所有这些指标,并且几乎不可能为它们设置合理的警报阈值。与每个代理指标一样,在调查特定问题时最好使用每个主题的度量。例如,record-send-rate 和 record-error-rate 属性可用于将丢弃的邮件隔离到特定主题(或验证为跨所有主题)。此外,还有一个字节速率指标,用于提供主题的总体消息速率(以字节/秒为单位)。
10.3.2 消费者指标
与新的生产者客户端类似,Kafka 中的新消费者将许多指标合并到几个指标 Bean 上的属性中。这些指标还消除了延迟的百分位数和费率的移动平均值,类似于生产者客户端。在消费者中,由于使用消息的逻辑比将消息发送到 Kafka 代理要复杂一些,因此还需要处理一些指标。请参见表 10-16。 表 10-16.Kafka 使用者指标 MBean
| 名称 | JMX MBean |
|---|---|
| 整体消费者 | kafka.consumer:type=consumer-metrics,client-id=CLIENTID |
| Fetch Manager | kafka.consumer:type=consumer-fetch-manager-metrics,client-id=CLIENTID |
| 每个主题 | kafka.consumer:type=consumer-fetch-manager-metrics,client-id=CLIENTID,topic=主题名称 |
| 每个代理 | kafka.consumer:type=consumer-node-metrics,client-id=CLIENTID,nodeid=node-BROKERID |
| 协调器 | kafka.consumer:type=consumer-coordinator-metrics,client-id=CLIENTID |
10.3.2.1 获取管理器指标
在消费者客户端中,整体消费者指标 Bean 对我们来说用处不大,因为感兴趣的指标位于 fetch 管理器 bean 中。整个使用者 Bean 具有有关较低级别网络操作的指标,但 fetch manager Bean 具有有关字节、请求和记录速率的指标。与创建者客户端不同,使用者提供的指标可用于查看,但对于设置警报没有用处。
对于提取管理器,您可能希望为其设置监控和警报的一个属性是 fetch-latency-avg。与生产者客户端中的等效 request-latency-avg 一样,此指标告诉我们向代理提取请求需要多长时间。针对此指标发出警报的问题在于,延迟由使用者配置 fetch.min.bytes 和 fetch.max.wait.ms 控制。慢速主题将具有不稳定的延迟,因为有时代理会快速响应(当有可用消息时),有时它不会响应 fetch.max.wait.ms(当没有可用消息时)。当使用具有更常规和更丰富的消息流量的主题时,查看此指标可能更有用。
* 等!没有延迟?对所有消费者来说,最好的建议是,你必须监控消费者的滞后。那么,为什么我们不建议监控 fetch manager bean 上的 records-lag-max 属性呢?此衡量指标显示最滞后的分区的当前滞后(代理后面的消息数)。
这样做的问题是双重的:它只显示一个分区的滞后,并且它依赖于消费者的正常运行。如果没有其他选择,请使用此属性表示滞后并为其设置警报。但最佳做法是使用外部滞后监控,如第 243 页的“滞后监控”中所述。
为了了解使用者客户端正在处理多少消息流量,您应该捕获字节消耗率或记录消耗率,或者最好同时捕获两者。这些指标分别以每秒字节数和每秒消息数来描述此客户端实例使用的消息流量。一些用户为这些指标设置了警报的最小阈值,以便在使用者没有做足够的工作时通知他们。但是,执行此操作时应小心。Kafka 旨在将消费者和生产者客户端解耦,允许它们独立运行。消费者能够使用消息的速率通常取决于生产者是否正常工作,因此在消费者身上监控这些指标会对生产者的状态做出假设。这可能会导致使用者客户端出现错误警报。
了解字节、消息和请求之间的关系也很好,fetch 管理器提供了指标来帮助解决这个问题。fetch-rate 度量值告诉我们消费者每秒执行的 Fetch 请求数。fetch-size-avg 指标给出了这些提取请求的平均大小(以字节为单位)。最后,records-per-request-avg 指标为我们提供了每个提取请求中的平均消息数。请注意,使用者没有提供与生产者 record-size-avg 指标等效的指标来让我们知道消息的平均大小是多少。如果这很重要,则需要从其他可用指标中推断它,或者在从使用者客户端库接收消息后在应用程序中捕获它。
10.3.2.2 每个代理和每个主题的指标
与生产者客户端一样,使用者客户端为每个代理连接和正在使用的每个主题提供的指标对于调试使用问题很有用,但可能不是您每天查看的度量值。与 fetch 管理器一样,每个代理指标 Bean 提供的 request-latency-avg 属性的用处有限,具体取决于您正在使用的主题中的消息流量。传入字节速率和请求速率指标将提取管理器提供的已使用消息指标分别细分为每秒每个代理字节数和每秒请求数测量值。这些可用于帮助隔离使用者在与特定代理的连接时遇到的问题。
如果使用多个主题,则使用者客户端提供的每主题指标非常有用。否则,这些指标将与提取管理器的指标相同,并且需要收集。另一方面,如果客户端使用许多主题(例如 Kafka MirrorMaker),则很难查看这些指标。如果您计划收集它们,则要收集的最重要的指标是 bytes-consumed-rate、records-consumed-rate 和 fetch-size-avg。bytes-consumed-rate 显示特定主题的绝对大小(以每秒消耗的字节数为单位),而 records-consumed-rate 在消息数方面显示相同的信息。fetch-size-avg 提供主题的每个提取请求的平均大小(以字节为单位)。
10.3.2.3 使用者协调器指标
如第 4 章所述,消费者客户端通常作为消费者组的一部分一起工作。此组具有协调活动,例如组成员加入和向代理发送检测信号消息以维护组成员身份。使用者协调器是使用者客户端的一部分,负责处理这项工作,它维护自己的指标集。与所有指标一样,提供了许多数字,但只有少数关键数字应定期监控。
由于协调者活动,消费者可能遇到的最大问题是消费者群体同步时消费暂停。这是组中的使用者实例协商哪些分区将被哪些单个客户端实例使用的时候。根据正在使用的分区数,这可能需要一些时间。协调器提供指标属性 sync-time-avg,即同步活动所需的平均时间(以毫秒为单位)。捕获 sync-rate 属性也很有用,该属性是每秒发生的组同步数。对于稳定的消费者组,此数字大多数时候应为零。
使用者需要提交偏移量以检查其使用消息的进度,可以定期自动执行,也可以通过应用程序代码中触发的手动检查点进行检查。这些提交本质上只是生成请求(尽管它们有自己的请求类型),因为偏移提交是向特定主题生成的消息。使用者协调器提供 commit-latency-avg 属性,该属性衡量偏移提交所花费的平均时间。您应该像监视生产者中的请求延迟一样监视此值。应该可以为此指标建立基线预期值,并为高于该值的警报设置合理的阈值。
最后一个可用于收集的协调器指标是 assigned-partitions。这是已分配给使用者客户端(作为使用者组中的单个实例)使用的分区数的计数。这很有帮助,因为与组中其他使用者客户端的此指标相比,可以看到整个使用者组的负载平衡。我们可以使用它来识别可能由使用者协调器用于将分区分发给组成员的算法中的问题引起的不平衡。
10.3.3 配额
Apache Kafka 能够限制客户端请求,以防止一个客户端使整个集群不堪重负。这可针对生产者和使用者客户端进行配置,并以从单个客户端 ID 到单个代理的允许流量(以每秒字节数为单位)表示。有一个代理配置,它为所有客户端设置默认值,以及可以动态设置的每个客户端覆盖。当代理计算出客户端已超出其配额时,它会将响应保留给客户端足够的时间以使客户端保持在配额以下,从而减慢客户端的速度。
Kafka 代理不会在响应中使用错误代码来指示客户端受到限制。这意味着,如果不监视为显示客户端受到限制的时间量而提供的指标,应用程序就不会明显地看到正在发生限制。需要监控的指标如表10-17所示。
表 10-17.要监控的指标
| 客户机 | Bean 名称 |
|---|---|
| 消费者 | bean kafka.consumer:type=consumer-fetch-manager-metrics,client-id=CLIENTID,属性 fetch-throttle-time-avg |
| 生产者 | bean kafka.producer:type=producer-metrics,client-id=CLIENTID,属性 produce-throttle-time-avg |
默认情况下,Kafka 代理上未启用配额,但无论您当前是否使用配额,都可以安全地监控这些指标。监视它们是一种很好的做法,因为它们可能会在将来的某个时候启用,并且从监视它们开始比以后添加指标更容易。
10.4 滞后监控
对于 Kafka 消费者来说,最重要的监控是消费者滞后。以消息数来衡量,这是在特定分区中生成的最后一条消息与使用者处理的最后一条消息之间的差值。虽然这个主题通常会在上一节关于消费者客户端监控中介绍,但这是外部监控远远超过客户端本身可用监控的情况之一。如前所述,使用者客户端中有一个滞后指标,但使用它是有问题的。它只代表一个分区,即滞后最多的分区,因此它不能准确显示使用者落后的程度。此外,它需要消费者的正确操作,因为指标是由消费者在每个提取请求上计算的。如果使用者已损坏或脱机,则指标不准确或不可用。
使用者滞后监控的首选方法是使用一个外部进程,该进程可以监视代理上分区的状态,跟踪最近生成的消息的偏移量,以及使用者的状态,跟踪使用者组为分区提交的最后一个偏移量。这提供了一个客观的视图,无论消费者本身的状态如何,都可以更新。必须对使用者组使用的每个分区执行此检查。对于像 MirrorMaker 这样的大型消费者来说,这可能意味着数以万计的分区。
第 9 章提供了有关使用命令行实用程序获取使用者组信息的信息,包括提交的偏移量和滞后。然而,像这样的监控滞后也存在其自身的问题。首先,您必须了解每个分区的合理滞后量。每小时接收 100 条消息的主题需要与每秒接收 100,000 条消息的主题不同的阈值。然后,您必须能够将所有滞后指标使用到监控系统中,并对其设置警报。如果您有一个使用者组在 1,500 个主题中使用 100,000 个分区,您可能会发现这是一项艰巨的任务。
为了降低这种复杂性,监视使用者组的一种方法是使用 Burrow。这是一个开源应用程序,最初由 LinkedIn 开发,它通过收集集群中所有消费者组的滞后信息并计算每个组的单个状态来提供消费者状态监控,说明消费者组是否正常工作、落后、停滞或完全停止。它通过监视使用者组在处理消息方面的进度来做到这一点,而无需阈值,尽管您也可以将消息滞后作为绝对数字获取。在LinkedIn工程博客上,对Burrow如何工作背后的推理和方法进行了深入讨论。部署 Burrow 可以为集群以及多个集群中的所有使用者提供监控,并且可以轻松地与现有的监控和警报系统集成。
如果没有其他选项,则来自使用者客户端的 records-lag-max 指标将至少提供使用者状态的部分视图。但是,强烈建议您使用像 Burrow 这样的外部监控系统。
10.5 端到端监控
建议确定 Kafka 集群是否正常工作的另一种外部监控类型是端到端监控系统,该系统提供有关 Kafka 集群运行状况的客户端观点。使用者和生产者客户端的指标可以指示 Kafka 集群可能存在问题,但这可能是一个猜测游戏,即延迟增加是由于客户端、网络还是 Kafka 本身的问题。此外,这意味着如果您负责运行 Kafka 集群,而不是客户端,那么您现在还必须监控所有客户端。你真正需要知道的是: • 我可以向 Kafka 集群生成消息吗? • 我可以消费 Kafka 集群的消息吗? 在理想情况下,您将能够单独监控每个主题。但是,在大多数情况下,为了做到这一点,将合成流量注入每个主题是不合理的。但是,我们至少可以为集群中的每个代理提供这些答案,这就是 Kafka Monitor 所做的。该工具由 LinkedIn 的 Kafka 团队开源,它不断从分布在集群中所有代理的主题中生成和使用数据。它测量每个代理上 produce 和 consume 请求的可用性,以及要消耗延迟的总 produce。这种类型的监控对于能够从外部验证 Kafka 集群是否按预期运行非常有价值,因为就像使用者滞后监控一样,Kafka 代理无法报告客户端是否能够正确使用集群。
10.6 总结
监控是正确运行 Apache Kafka 的一个关键方面,这就解释了为什么这么多团队花费大量时间来完善这部分操作。许多组织使用 Kafka 来处理 PB 级数据流。确保数据不会停止,消息不会丢失,是一项关键的业务要求。我们还有责任通过提供用户所需的指标来帮助用户监控他们的应用程序如何使用 Kafka。
在本章中,我们介绍了如何监视 Java 应用程序的基础知识,特别是 Kafka 应用程序。我们回顾了 Kafka 代理中众多可用指标的子集,还涉及 Java 和操作系统监控以及日志记录。然后,我们详细介绍了 Kafka 客户端库中可用的监控,包括配额监控。最后,我们讨论了使用外部监控系统进行消费者滞后监控和端到端集群可用性。虽然肯定不是可用指标的详尽列表,但本章回顾了需要关注的最关键指标。
第十一章 流处理
传统上,Kafka 被视为一个强大的消息总线,能够传递事件流,但没有处理或转换功能。Kafka 可靠的流传输功能使其成为流处理系统的完美数据源。Apache Storm、Apache Spark Streaming、Apache Flink、Apache Samza 和更多流处理系统都是使用 Kafka 构建的,Kafka 通常是唯一可靠的数据源。
行业分析师有时声称,所有这些流处理系统就像已经存在了 20 年的复杂事件处理 (CEP) 系统一样。我们认为流处理之所以更受欢迎,是因为它是在 Kafka 之后创建的,因此可以使用 Kafka 作为事件流的可靠来源进行处理。随着 Apache Kafka 的日益普及,首先是作为简单的消息总线,后来是作为数据集成系统,许多公司都有一个包含许多有趣数据流的系统,存储时间很长并且井井有条,只是等待一些流处理框架出现并处理它们。换句话说,就像在数据库发明之前数据处理要困难得多一样,流处理也因缺乏流处理平台而受到阻碍。
从 0.10.0 版本开始,Kafka 不仅仅是为每个流行的流处理框架提供可靠的数据流源。现在,Kafka 包含一个强大的流处理库,作为其客户端库集合的一部分。这允许开发人员在自己的应用程序中使用、处理和生成事件,而无需依赖外部处理框架。
在本章的开头,我们将解释流处理的含义(因为这个术语经常被误解),然后讨论流处理的一些基本概念以及所有流处理系统通用的设计模式。然后,我们将深入探讨 Apache Kafka 的流处理库——它的目标和架构。我们将举一个小例子来说明如何使用 Kafka Streams 来计算股票价格的移动平均线。然后,我们将讨论其他良好的流处理用例示例,并通过提供一些标准来结束本章,这些标准在选择与 Apache Kafka 一起使用的流处理框架(如果有)时可以使用。本章旨在简要介绍流处理,不会涵盖 Kafka Streams 的所有功能,也不会尝试讨论和比较现有的每个流处理框架——这些主题值得单独阅读,可能是几本。
11.1 什么是流处理?
关于流处理的含义存在很多混淆。许多定义混淆了实现细节、性能要求、数据模型和软件工程的许多其他方面。我看到同样的事情在关系数据库的世界里上演——关系模型的抽象定义永远纠缠在流行数据库引擎的实现细节和特定限制中。
流处理的世界仍在不断发展,仅仅因为特定的流行实现以特定的方式做事或具有特定的限制,并不意味着这些细节是处理数据流的固有部分。
让我们从头开始:什么是数据流(也称为事件流或流数据)?首先,数据流是表示无限数据集的抽象。无边无际意味着无限和不断增长。数据集是无限的,因为随着时间的推移,新的记录不断到来。谷歌、亚马逊和几乎所有其他人都使用这个定义。
请注意,这个简单的模型(事件流)可用于表示我们关心分析的几乎所有业务活动。我们可以查看信用卡交易、股票交易、包裹递送、通过交换机的网络事件、制造设备中的传感器报告的事件、发送的电子邮件、游戏中的移动等。例子的清单是无穷无尽的,因为几乎所有事情都可以看作是一系列事件。
除了事件流模型的无界性质之外,还有其他一些属性:
-
事件流是有序的 对于哪些事件发生在其他事件之前或之后,存在一个固有的概念。这在查看财务事件时最为明显。我先把钱存入我的账户,然后花钱的顺序与我先花钱,然后通过存钱来偿还债务的顺序有很大不同。后者将产生透支费用,而前者则不会。请注意,这是事件流和数据库表之间的区别之一 - 表中的记录始终被视为无序的,并且 SQL 的“order by”子句不是关系模型的一部分;添加它是为了协助报告。
-
不可变的数据记录 事件一旦发生,就永远无法修改。被取消的金融交易不会消失。相反,会将一个附加事件写入流,记录上一个事务的取消。当客户将商品退回商店时,我们不会删除商品之前出售给他的事实,而是将退货记录为附加事件。这是数据流和数据库表之间的另一个区别——我们可以删除或更新表中的记录,但这些都是数据库中发生的附加事务,因此可以记录在记录所有事务的事件流中。如果您熟悉数据库中的二进制日志、WAL或重做日志,您可以看到,如果我们将一条记录插入到表中,然后将其删除,则该表将不再包含该记录,但重做日志将包含两个事务:插入和删除。
-
事件流是可重播的 这是一个理想的属性。虽然很容易想象不可重放的流(通过套接字流式传输的 TCP 数据包通常是不可重放的),但对于大多数业务应用程序来说,能够重放几个月(有时是几年)前发生的事件的原始流至关重要。这是纠正错误、尝试新的分析方法或执行审计所必需的。这就是我们认为 Kafka 使流处理在现代企业中如此成功的原因——它允许捕获和重放事件流。如果没有这种能力,流处理将只不过是数据科学家的实验室玩具。
值得注意的是,无论是事件流的定义,还是我们后面列出的属性,都没有说明事件中包含的数据或每秒事件的数量。数据因系统而异 - 事件可能很小(有时只有几个字节),也可能非常大(具有许多标头的 XML 消息);它们也可以是完全非结构化的键值对、半结构化 JSON 或结构化的 Avro 或 Protobuf 消息。虽然人们通常认为数据流是“大数据”,每秒涉及数百万个事件,但我们将讨论的相同技术同样适用于每秒或每分钟只有几个事件的较小事件流(通常更好)。
现在我们知道了什么是事件流,是时候确保我们了解流处理了。流处理是指对一个或多个事件流的持续处理。流处理是一种编程范式,就像请求-响应和批处理一样。让我们看看不同的编程范式是如何比较的,以便更好地理解流处理如何适应软件架构:
-
请求-响应 这是延迟最低的范例,响应时间从亚毫秒到几毫秒不等,通常期望响应时间高度一致。处理模式通常是阻塞,即应用发送请求并等待处理系统响应。在数据库世界中,这种范式称为联机事务处理 (OLTP)。销售点系统、信用卡处理和时间跟踪系统通常在这种范式中工作。
-
批处理 这是高延迟/高吞吐量选项。处理系统在设定的时间唤醒 - 每天凌晨 2:00,每小时,等等。它读取所有必需的输入(自上次执行以来的所有可用数据、月初的所有数据等),写入所有必需的输出,然后消失,直到下次计划运行时。处理时间从几分钟到几小时不等,用户希望在查看结果时读取过时的数据。在数据库世界中,这些是数据仓库和商业智能系统,每天大批量加载数据一次,生成报告,用户查看相同的报告,直到下一次数据加载发生。这种范式通常具有很高的效率和规模经济,但近年来,企业需要在更短的时间内提供数据,以便使决策更加及时和高效。这给那些为利用规模经济而编写的系统带来了巨大的压力,而不是提供低延迟报告。
-
流处理 这是一个有争议的非阻塞选项。填补了请求-响应世界和批处理世界之间的空白,前者我们等待需要两毫秒才能处理的事件,后者每天处理一次数据,需要八小时才能完成。大多数业务流程不需要在几毫秒内立即响应,但也不能等到第二天。大多数业务流程都是连续发生的,只要业务报表不断更新,并且业务线应用可以持续响应,处理就可以继续进行,而无需任何人在几毫秒内等待特定响应。业务流程,如对可疑的信用交易或网络活动发出警报,根据供需实时调整价格,或跟踪包裹的交付,都是连续但无阻塞处理的自然选择。
需要注意的是,该定义不强制要求任何特定的框架、API 或功能。只要您不断从无限数据集中读取数据,对其执行某些操作并发出输出,您就正在执行流处理。但处理必须是连续和持续的。每天凌晨 2:00 开始,从流中读取 500 条记录,输出结果,然后消失的进程,就流处理而言,这并不完全是削减的。
11.2 流处理概念
流处理与任何类型的数据处理非常相似,即编写接收数据的代码,对数据执行某些操作(一些转换、聚合、扩充等),然后将结果放在某个位置。但是,有一些关键概念是流处理所独有的,当具有数据处理经验的人第一次尝试编写流处理应用程序时,这些概念往往会引起混淆。让我们来看看其中的一些概念。
11.2.1 时间
时间可能是流处理中最重要的概念,但往往是最令人困惑的概念。要了解在讨论分布式系统时时间会变得多么复杂,我们推荐 Justin Sheehy 的优秀论文“没有现在”。在流处理的上下文中,具有通用的时间概念至关重要,因为大多数流应用程序在时间窗口上执行操作。例如,我们的流应用程序可能会计算股票价格的移动 5 分钟平均值。在这种情况下,我们需要知道当我们的某个生产者因网络问题而离线两个小时并返回两个小时的数据时该怎么做——大多数数据将与早已过去的五分钟时间窗口相关,并且已经计算和存储了结果。
流处理系统通常是指以下时间概念:
-
活动时间 这是我们正在跟踪的事件发生和创建记录的时间——进行测量的时间、在商店出售商品的时间、用户查看我们网站上的页面的时间等。在版本 0.10.0 及更高版本中,Kafka 会在创建创建者记录时自动将当前时间添加到创建者记录中。如果这与应用程序的事件时间概念不匹配,例如,在事件发生后的某个时间基于数据库记录创建 Kafka 记录的情况下,则应将事件时间添加为记录本身的字段。事件时间通常是处理流数据时最重要的时间。
-
日志追加时间 这是事件到达 Kafka 代理并存储在那里的时间。在版本 0.10.0 及更高版本中,如果 Kafka 配置为这样做,或者如果记录来自较旧的生产者且不包含时间戳,则 Kafka 代理会自动将此时间添加到他们收到的记录中。这种时间概念通常与流处理不太相关,因为我们通常对事件发生的时间感兴趣。例如,如果我们计算每天生产的设备数量,我们希望计算当天实际生产的设备,即使存在网络问题并且事件仅在第二天到达 Kafka。但是,在未记录真实事件时间的情况下,日志追加时间仍可以一致地使用,因为它在创建记录后不会更改。
-
处理时间 这是流处理应用程序接收事件以执行某些计算的时间。此时间可以是事件发生后的几毫秒、几小时或几天。这种时间概念为同一事件分配不同的时间戳,具体取决于每个流处理应用程序恰好何时读取该事件。它甚至可以在同一应用程序中的两个线程上有所不同!因此,这种时间概念非常不可靠,最好避免。
* 注意时区使用时间时,重要的是要注意时区。整个数据管道应在单个时区上进行标准化;否则,流操作的结果将令人困惑,并且通常毫无意义。如果必须处理具有不同时区的数据流,则需要确保在时间窗口上执行操作之前可以将事件转换为单个时区。这通常意味着将时区存储在记录本身中。
11.2.2 状态
只要只需要单独处理每个事件,流处理就是一个非常简单的活动。例如,如果你需要做的只是从 Kafka 读取一系列在线购物交易,找到超过 10,000 美元的交易并通过电子邮件发送给相关的销售人员,那么你可以使用 Kafka 使用者和 SMTP 库在几行代码中编写它。
当您的操作涉及多个事件时,流处理变得非常有趣:按类型计算事件数量、移动平均线、连接两个流以创建丰富的信息流等。在这些情况下,仅查看每个事件本身是不够的;您需要跟踪更多信息 - 我们这一小时看到了每种类型的事件数量、需要联接的所有事件、总和、平均值等。我们将事件之间存储的信息称为状态。
通常很容易将状态存储在流处理应用的本地变量中,例如用于存储移动计数的简单哈希表。事实上,我们在本书的许多例子中都是这样做的。但是,这不是在流处理中管理状态的可靠方法,因为当流处理应用程序停止时,状态会丢失,从而更改结果。这通常不是预期的结果,因此应注意保留最新状态并在启动应用程序时恢复它。
流处理是指几种类型的状态:
-
本地或内部状态 只能由流处理应用程序的特定实例访问的状态。此状态通常通过在应用程序内运行的嵌入式内存数据库进行维护和管理。本地状态的优点是速度极快。缺点是受可用内存量的限制。因此,stream.processing 中的许多设计模式都侧重于将数据划分为子流的方法,这些子流可以使用有限数量的本地状态进行处理。
-
外部状态
在外部数据存储(通常是 Cassandra 等 NoSQL 系统)中维护的状态。外部状态的优点是其几乎无限的大小,并且可以从应用程序的多个实例甚至不同的应用程序访问它。缺点是附加系统会带来额外的延迟和复杂性。大多数流处理应用都试图避免与外部存储打交道,或者至少通过在本地状态中缓存信息并尽可能少地与外部存储通信来限制延迟开销。这通常会给保持内部和外部状态之间的一致性带来挑战。
11.2.3 流表二象性
我们都熟悉数据库表。表是记录的集合,每个记录都由其主键标识,并包含一组由架构定义的属性。表记录是可变的(即,表允许更新和删除操作)。查询表允许检查数据在特定时间点的状态。例如,通过查询数据库中的CUSTOMERS_CONTACTS表,我们希望找到所有客户的当前联系方式。除非该表专门设计用于包含历史记录,否则我们不会在表中找到他们过去的联系人。
与表不同,流包含更改历史记录。流是一串事件,其中每个事件都会导致更改。表包含世界的当前状态,这是许多更改的结果。从这个描述中可以清楚地看出,流和表是同一枚硬币的两面——世界总是在变化,有时我们对导致这些变化的事件感兴趣,而有时我们对世界的当前状态感兴趣。允许您在两种查看数据的方式之间来回转换的系统比仅支持一种方式的系统更强大。
为了将表转换为流,我们需要捕获修改表的更改。获取所有这些插入、更新和删除事件,并将它们存储在流中。大多数数据库都提供用于捕获这些更改的更改数据捕获 (CDC) 解决方案,并且有许多 Kafka 连接器可以将这些更改通过管道传输到 Kafka 中,以便它们可用于流处理。
为了将流转换为表,我们需要应用流包含的所有更改。这也称为具体化流。我们在内存中、内部状态存储或外部数据库中创建一个表,并开始从头到尾遍历流中的所有事件,并随时更改状态。完成后,我们有一个表,表示特定时间的状态,我们可以使用。
假设我们有一家卖鞋的商店。我们零售活动的流表示可以是事件流: “货物带着红色、蓝色和绿色的鞋子到达” “蓝鞋卖了” “红鞋卖了” “蓝鞋回来了” “绿鞋卖了” 如果我们想知道我们的库存现在包含什么,或者我们到目前为止赚了多少钱,我们需要实现视图。图 11-1 显示我们目前有蓝色和黄色的鞋子和 170 美元的银行存款。如果我们想知道商店有多忙,我们可以查看整个流,看到有五笔交易。我们可能还想调查为什么归还蓝鞋。

图 11-1. 实现库存变化
11.2.4 时间窗口
对流的大多数操作都是窗口操作 - 对时间片进行操作:移动平均线、本周销售最多的产品、系统上的第 99 个百分位负载等。两个流上的联接操作也是窗口化的,我们联接在同一时间段发生的事件。很少有人停下来思考他们想要的运营窗口类型。例如,在计算移动平均线时,我们想知道:
• 窗口大小:我们是否要计算每五分钟窗口内所有事件的平均值?每 15 分钟窗口一次?还是一整天?较大的窗户更平滑,但滞后性更强——如果价格上涨,则比较小的窗户需要更长的时间才能注意到。 • 窗口移动的频率(提前间隔):五分钟平均值可以每分钟、每秒或每次有新事件时更新。当提前间隔等于窗口大小时,这有时称为翻转窗口。当窗口在每条记录上移动时,这有时称为滑动窗口。 • 窗口保持可更新的时间:我们的 5 分钟移动平均线计算了 00:00-00:05 窗口的平均值。现在一个小时后,我们又得到了一些结果,他们的事件时间显示 00:02。我们是否更新 00:00-00:05 期间的结果?还是我们让过去成为过去?理想情况下,我们将能够定义一个特定的时间段,在此期间,事件将被添加到其各自的时间片中。例如,如果事件延迟了多达 4 小时,则应重新计算结果并进行更新。如果事件比这更晚到达,我们可以忽略它们。
窗口可以与时钟时间对齐,即,每分钟移动一次的五分钟窗口将第一个切片为 00:00-00:05,第二个切片为 00:01-00:06。或者,它可以是未对齐的,只要应用程序启动,它就会启动,然后第一个切片可以是 03:17-03:22。滑动窗口永远不会对齐,因为每当有新记录时,它们都会移动。请参见图 11-2,了解这两种类型的窗口之间的区别。

图 11-2. 翻滚窗口与跳跃窗口
11.3 流处理设计模式
每个流处理系统都是不同的,从使用者、处理逻辑和生产者的基本组合,到涉及的集群(如 Spark Streaming 及其机器学习库),以及介于两者之间的许多系统。但是有一些基本的设计模式,这些模式是流处理体系结构常见要求的已知解决方案。我们将回顾其中的一些众所周知的模式,并通过几个示例展示如何使用它们。
11.3.1 单事件处理
流处理的最基本模式是单独处理每个事件。这也称为映射/筛选器模式,因为它通常用于从流中筛选不必要的事件或转换每个事件。(术语“map”基于 map/reduce 模式,在该模式中,map 阶段转换事件,reduce 阶段聚合事件。
在此模式中,流处理应用使用流中的事件,修改每个事件,然后将事件生成到另一个流。例如,一个应用从流中读取日志消息,并将 ERROR 事件写入高优先级流,将其余事件写入低优先级流。另一个示例是从流中读取事件并将其从 JSON 修改为 Avro 的应用程序。此类应用程序需要在应用程序中维护状态,因为每个事件都可以独立处理。这意味着从应用程序故障或负载平衡中恢复非常容易,因为无需恢复状态;只需将事件移交给应用的另一个实例进行处理即可。
这种模式可以通过简单的生产者和使用者轻松处理,如图 11-3 所示。

图 11-3. 单事件处理拓扑
11.3.2 使用本地状态进行处理
大多数流处理应用程序都与聚合信息有关,尤其是时间窗口聚合。这方面的一个例子是找到每天交易的最低和最高股票价格并计算移动平均线。
这些聚合需要维护流的状态。在我们的示例中,为了计算每天的最低价格和平均价格,我们需要存储截至当前时间看到的最小值和最大值,并将流中的每个新值与存储的最小值和最大值进行比较。
所有这些都可以使用本地状态(而不是共享状态)来完成,因为我们示例中的每个操作都是按聚合分组的。也就是说,我们执行每个股票代码的聚合,而不是整个股票市场。我们使用 Kafka 分区程序来确保所有具有相同股票代码的事件都写入同一分区。然后,应用程序的每个实例都将从分配给它的分区中获取所有事件(这是 Kafka 使用者保证)。这意味着应用程序的每个实例都可以维护写入分配给它的分区的股票代码子集的状态。请参见图 11-4。
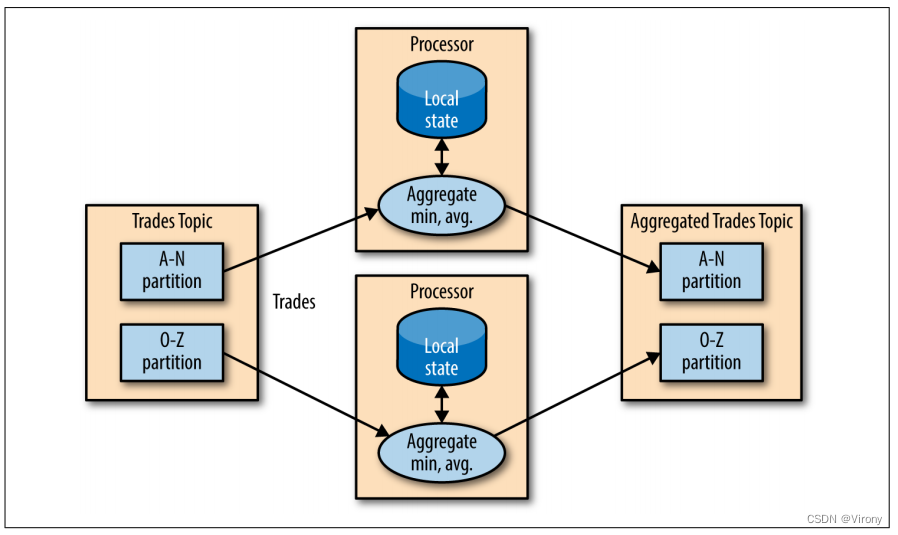
图 11-4. 具有本地状态的事件处理拓扑
当应用程序具有本地状态并且流处理应用程序必须解决以下几个问题时,流处理应用程序会变得更加复杂:
-
内存使用量 本地状态必须适合应用程序实例可用的内存。
-
坚持 我们需要确保当应用程序实例关闭时状态不会丢失,并且当实例再次启动或被其他实例替换时,状态可以恢复。Kafka Streams 很好地处理了这一点——本地状态使用嵌入式 RocksDB 存储在内存中,它还将数据持久化到磁盘,以便在重启后快速恢复。但是,对本地状态的所有更改也会发送到 Kafka 主题。如果流的节点出现故障,本地状态不会丢失,可以通过重新读取 Kafka 主题中的事件轻松重新创建本地状态。例如,如果本地状态包含“IBM = 167.19 的当前最小值”,我们将其存储在 Kafka 中,以便以后我们可以从这些数据重新填充本地缓存。Kafka 对这些主题使用日志压缩,以确保它们不会无休止地增长,并且重新创建状态始终是可行的。
-
平衡 分区有时会重新分配给不同的使用者。发生这种情况时,丢失分区的实例必须存储上次的良好状态,并且接收分区的实例必须知道恢复正确的状态。
流处理框架的不同之处在于它们在多大程度上帮助开发人员管理他们需要的本地状态。如果应用程序需要维护本地状态,请务必检查框架及其保证。我们将在本章末尾提供一个简短的比较指南,但众所周知,软件变化很快,流处理框架也加倍变化。
11.3.3 多阶段处理/重新分区
如果您需要按聚合类型分组,则本地状态非常有用。但是,如果您需要使用所有可用信息的结果,该怎么办?例如,假设我们每天要发布前 10 只股票,即在每天交易中从开盘到收盘收益最大的 10 只股票。显然,我们在每个应用程序实例上本地执行的任何操作都是不够的,因为所有前 10 个库存都可能位于分配给其他实例的分区中。我们需要的是两阶段的方法。首先,我们计算每个股票代码的每日损益。我们可以在每个具有本地状态的实例上执行此操作。然后,我们将结果写入具有单个分区的新主题。此分区将由单个应用程序实例读取,然后可以找到当天排名前 10 位的股票。第二个主题仅包含每个股票代码的每日摘要,显然比包含交易本身的主题要小得多,流量也要少得多,因此可以由应用程序的单个实例处理。有时需要更多的步骤来产生结果。请参见图 11-5。

图 11-5. 包含本地状态和重新分区步骤的拓扑
这种类型的多阶段处理对于编写map-reduce代码的人来说非常熟悉,在这些代码中,您经常不得不求助于多个reduce阶段。如果你曾经编写过map-reduce代码,你会记得每个reduce步骤都需要一个单独的应用程序。与MapReduce不同,大多数流处理框架允许将所有步骤包含在单个应用程序中,框架处理哪个应用程序实例(或工作程序)将运行到达步骤的详细信息。
11.3.4 使用外部查找进行处理:流表联接
有时,流处理需要与流外部的数据集成,即根据存储在数据库中的一组规则验证事务,或者使用有关单击用户的数据来丰富点击流信息。
关于如何对数据扩充执行外部查找的明显想法是这样的:对于流中的每个点击事件,在用户档案数据库中查找用户,并将包含原始点击以及用户年龄和性别的事件写入另一个主题。请参见图 11-6。
图 11-6. 包含外部数据源的流处理
这个明显想法的问题在于,外部查找会给每条记录的处理增加显著的延迟,通常在 5-15 毫秒之间。在许多情况下,这是不可行的。通常,这给外部数据存储带来的额外负载也是不可接受的 — 流处理系统通常每秒可以处理 100K-500K 个事件,但数据库在合理的性能下每秒只能处理 10K 个事件。我们想要一个扩展性更好的解决方案。
为了获得良好的性能和规模,我们需要在流处理应用程序中缓存数据库中的信息。但是,管理此缓存可能具有挑战性 — 我们如何防止缓存中的信息过时?如果我们过于频繁地刷新事件,我们仍然在锤击数据库,缓存没有多大帮助。如果我们等待太久才获得新事件,我们就会使用过时的信息进行流处理。
但是,如果我们可以在事件流中捕获数据库表发生的所有更改,我们就可以让我们的流处理作业侦听此流并根据数据库更改事件更新缓存。将对数据库的更改作为流中的事件捕获称为 CDC,如果使用 Kafka Connect,您将发现多个连接器能够执行 CDC 并将数据库表转换为更改事件流。这允许您保留自己的表的私有副本,并且每当发生数据库更改事件时,您都会收到通知,以便您可以相应地更新自己的副本。请参见图 11-7。

图 11-7. 联接表和事件流的拓扑,无需在流处理中涉及外部数据源
然后,当您收到点击事件时,您可以在本地缓存中查找user_id并扩充事件。而且,由于您使用的是本地缓存,因此可以更好地扩展,并且不会影响使用它的数据库和其他应用程序。
我们将其称为流表联接,因为其中一个流表示对本地缓存表的更改。
11.3.5 流式处理加入
有时,您希望联接两个实际事件流,而不是联接一个带有表的流。是什么让流变得“真实”?如果你回想一下本章开头的讨论,就会发现流是无限的。使用流表示表时,可以忽略流中的大部分历史记录,因为您只关心表中的当前状态。但是,当您加入两个流时,您正在加入整个历史记录,尝试将一个流中的事件与另一个流中具有相同键且发生在相同时间窗口的事件进行匹配。这就是为什么流式联接也称为窗口联接的原因。
例如,假设我们有一个流包含人们在我们网站中输入的搜索查询,另一个流包含点击量,其中包括对搜索结果的点击量。我们希望将搜索查询与他们点击的结果进行匹配,以便我们知道哪个结果在哪个查询中最受欢迎。显然,我们希望根据搜索词匹配结果,但只在特定时间窗口内匹配它们。我们假设在查询输入搜索引擎后几秒钟就点击了结果。因此,我们在每个流上保留一个几秒钟长的小窗口,并匹配每个窗口的结果。请参见图 11-8。
图 11-8. 加入两个事件流;这些联接始终涉及移动时间窗口
这在 Kafka Streams 中的工作方式是,查询和点击这两个流都分区在相同的键上,这些键也是连接键。这样一来,user_id:42 中的所有点击事件最终都会出现在点击主题的第 5 分区中,而 user_id:42 的所有搜索事件都会出现在搜索主题的第 5 分区中。然后,Kafka Streams 确保将两个主题的分区 5 分配给同一任务。因此,此任务将查看 user_id:42 的所有相关事件。它在其嵌入式 RocksDB 缓存中维护这两个主题的 join-window,这就是它执行 join 的方式。
11.3.6 乱序事件
处理在错误时间到达流的事件不仅在流处理中是一个挑战,而且在传统的 ETL 系统中也是一个挑战。在 IoT(物联网)场景中,乱序事件发生得非常频繁,而且是意料之中的(图 11-9)。例如,移动设备在几个小时内失去 WiFi 信号,并在重新连接时发送几个小时的事件。在监控网络设备(故障交换机在维修之前不会发送诊断信号)或制造(工厂的网络连接是出了名的不可靠,尤其是在发展中国家)时也会发生这种情况。

图 11-9. 乱序事件
我们的流应用程序需要能够处理这些场景。这通常意味着应用程序必须执行以下操作: • 识别事件不按顺序排列 - 这要求应用程序检查事件时间并发现它早于当前时间。 • 定义一个时间段,在此期间它将尝试协调乱序事件。也许应该协调三个小时的延迟,并且可以抛弃超过三周的事件。 • 具有协调此事件的带内功能。这是流式处理应用和批处理作业之间的主要区别。如果我们有一个每日批处理作业,并且在作业完成后到达了一些事件,我们通常可以重新运行昨天的作业并更新事件。使用流处理时,无需“重新运行昨天的作业”,即同一连续进程需要在任何给定时刻处理新旧事件。 • 能够更新结果。如果将流处理的结果写入数据库,则放置或更新就足以更新结果。如果直播应用通过电子邮件发送结果,更新可能会更棘手。
一些流处理框架,包括 Google 的 Dataflow 和 Kafka Streams,都内置了对独立于处理时间的事件时间概念的支持,并且能够处理事件时间早于或更新于当前处理时间的事件。这通常是通过在本地状态下维护多个可用于更新的聚合窗口来实现的,并使开发人员能够配置将这些窗口聚合保留多长时间以进行更新。当然,聚合窗口可用于更新的时间越长,维护本地状态所需的内存就越多。
Kafka 的 Streams API 始终将聚合结果写入结果主题。这些通常是压缩的主题,这意味着仅保留每个键的最新值。如果聚合窗口的结果由于后期事件而需要更新,Kafka Streams 将简单地为此聚合窗口写入一个新结果,这将覆盖之前的结果。
11.3.7 加工
最后一个重要模式是处理事件。此模式有两种变体: • 我们有流处理应用程序的改进版本。我们希望在与旧应用程序相同的事件流上运行新版本的应用程序,生成不替换第一个版本的新结果流,比较两个版本之间的结果,并在某个时候移动客户端以使用新结果而不是现有结果。 • 现有的流处理应用程序存在问题。我们修复了这个错误,我们希望重新处理事件流并重新计算我们的结果 第一个用例变得简单,因为 Apache Kafka 将事件流完整地存储在可扩展的数据存储中很长一段时间。这意味着,让两个版本的流处理应用程序编写两个结果流只需要满足以下条件: • 将应用程序的新版本作为新的消费者组进行启动 • 将新版本配置为从输入主题的第一个偏移量开始处理(因此它将获得输入流中所有事件的副本) • 让新应用程序继续处理,并在处理作业的新版本赶上时将客户端应用程序切换到新的结果流
第二个用例更具挑战性,它需要“重置”现有应用,以便在输入流的开头开始处理,重置本地状态(因此我们不会混合来自应用的两个版本的结果),并可能清理以前的输出流。虽然 Kafka Streams 有一个用于重置流处理应用程序状态的工具,但我们的建议是,只要有足够的容量来运行应用程序的两个副本并生成两个结果流,就尝试使用第一种方法。第一种方法要安全得多,它允许在多个版本之间来回切换并比较版本之间的结果,并且不会在清理过程中丢失关键数据或引入错误。
11.4 Kafka Streams 示例
为了演示这些模式在实践中是如何实现的,我们将展示一些使用 Apache Kafka 的 Streams API 的示例。我们之所以使用这个特定的 API,是因为它使用起来相对简单,并且它附带了 Apache Kafka,你已经可以访问它。重要的是要记住,这些模式可以在任何流处理框架和库中实现,这些模式是通用的,但示例是特定的。
Apache Kafka 有两个流 API:一个是低级处理器 API,另一个是高级流 DSL。我们将在示例中使用 Kafka Streams DSL。DSL 允许你通过定义流中事件的转换链来定义流处理应用程序。转换可以像筛选器一样简单,也可以像流到流联接一样复杂。较低级别的 API 允许您创建自己的转换,但正如您将看到的,这很少是必需的。
使用 DSL API 的应用程序始终从使用 StreamBuilder 创建处理拓扑开始,即应用于流中事件的转换的有向图 (DAG)。然后,从拓扑创建 KafkaStreams 执行对象。启动 KafkaStreams 对象将启动多个线程,每个线程将处理拓扑应用于流中的事件。当您关闭 KafkaStreams 对象时,处理将结束。
我们将查看几个使用 Kafka Streams 来实现我们刚才讨论的一些设计模式的示例。将使用一个简单的字数统计示例来演示映射/过滤器模式和简单聚合。然后,我们将转到一个示例,在该示例中,我们计算了股票市场交易的不同统计数据,这将使我们能够演示窗口聚合。最后,我们将使用 ClickStream 扩充作为示例来演示流式联接。
11.4.1 字数
让我们看一下 Kafka Streams 的简短字数统计示例。您可以在 GitHub 上找到完整的示例。
创建流处理应用程序时要做的第一件事是配置 Kafka Streams。Kafka Streams 有大量可能的配置,我们不会在这里讨论,但你可以在文档中找到它们。此外,您还可以通过向 Properties 对象添加任何生产者或使用者配置来配置 Kafka Streams 中嵌入的生产者和使用者:
public class WordCountExample {public static void main(String[] args) throws Exception{Properties props = new Properties();props.put(StreamsConfig.APPLICATION_ID_CONFIG,"wordcount"); (1)props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092"); (2)props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG,Serdes.String().getClass().getName()); (3)props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass().getName());
(1) 每个 Kafka Streams 应用程序都必须有一个应用程序 ID。这用于协调应用程序的实例,也用于命名内部本地存储和与之相关的主题。对于使用同一 Kafka 集群的每个 Kafka Streams 应用程序,此名称必须是唯一的。
(2) Kafka Streams 应用程序始终从 Kafka 主题读取数据并将其输出写入 Kafka 主题。正如我们稍后将讨论的,Kafka Streams 应用程序也使用 Kafka 进行协调。因此,我们最好告诉我们的应用程序在哪里可以找到 Kafka。
(3) 在读取和写入数据时,我们的应用程序需要序列化和反序列化,因此我们提供了默认的 Serde 类。如果需要,我们可以稍后在构建流拓扑时覆盖这些默认值。
现在,我们已经有了配置,让我们构建流拓扑:
KStreamBuilder builder = new KStreamBuilder(); (1)KStream<String, String> source =builder.stream("wordcount-input");final Pattern pattern = Pattern.compile("\\W+");KStream counts = source.flatMapValues(value->Arrays.asList(pattern.split(value.toLowerCase()))) (2) .map((key, value) -> new KeyValue<Object,Object>(value, value)).filter((key, value) -> (!value.equals("the"))) (3).groupByKey() (4).count("CountStore").mapValues(value->Long.toString(value)).toStream(); (5)counts.to("wordcount-output"); (6)
(1) 我们创建一个 KStreamBuilder 对象,并通过指向我们将用作输入的主题来开始定义流。
(2) 我们从源主题中读取的每个事件都是一行单词;我们使用正则表达式将其拆分为一系列单独的单词。然后,我们获取每个单词(当前是事件记录的值)并将其放在事件记录键中,以便可以在分组依据操作中使用。
(3) 我们过滤掉了“the”这个词,只是为了显示过滤是多么容易。
(4) 我们按键分组,因此我们现在为每个唯一单词收集了事件。
(5) 我们计算每个集合中有多少个事件。计数的结果是 Long 数据类型。我们将其转换为字符串,以便人类更容易读取结果。
(6) 只剩下一件事——将结果写回 Kafka。
现在我们已经定义了应用程序将要运行的转换流,我们只需要...运行它:
KafkaStreams streams = new KafkaStreams(builder, props); (1)streams.start(); (2)// usually the stream application would be runningforever,// in this example we just let it run for some time andstop since the input data is finite.Thread.sleep(5000L);streams.close(); (3)}}
(1) 根据我们的拓扑和我们定义的属性定义 KafkaStreams 对象。
(2) 启动 Kafka Streams。
(3) 过了一会儿,停下来。
就是这样!在短短的几行中,我们演示了实现单个事件处理模式是多么容易(我们对事件应用了映射和过滤器)。我们通过添加 groupby 运算符对数据进行重新分区,然后在计算将每个单词作为键的记录数时保持简单的本地状态。然后,当我们计算每个单词出现的次数时,我们保持简单的局部状态。
此时,我们建议运行完整示例。GitHub 存储库中的 README 包含有关如何运行示例的说明。
您会注意到的一件事是,您可以在计算机上运行整个示例,而无需安装除 Apache Kafka 之外的任何东西。这类似于在本地模式下使用 Spark 时可能看到的体验。主要区别在于,如果您的输入主题包含多个分区,则可以运行 WordCount 应用程序的多个实例(只需在几个不同的终端选项卡中运行应用程序),并且您拥有第一个 Kafka Streams 处理集群。WordCount 应用程序的实例相互通信并协调工作。进入 Spark 的最大障碍之一是本地模式非常易于使用,但要运行生产集群,您需要安装 YARN 或 Mesos,然后在所有这些机器上安装 Spark,然后学习如何将应用程序提交到集群。使用 Kafka 的 Streams API,您只需启动应用的多个实例,即可获得一个集群。完全相同的应用在开发计算机上和生产环境中运行。
11.4.2 股票市场统计
下一个示例涉及更多内容——我们将阅读一系列股票市场交易事件,包括股票代码、卖出价和卖出价。在股票市场交易中,卖出价是卖方的要求,而买入价是买方建议支付的价格。卖出价是卖方愿意以该价格出售的股票数量。为了简单起见,我们将完全忽略出价。我们也不会在数据中包含时间戳;相反,我们将依赖于 Kafka 生产者填充的事件时间。
然后,我们将创建包含一些窗口化统计信息的输出流:
• 每五秒窗口的最佳(即最低)要价
• 每五秒窗口的交易数量
• 每五秒窗口的平均要价
所有统计数据将每秒更新一次。
为简单起见,我们假设我们的交易所只有 10 个股票代码在交易。设置和配置与我们在第 265 页的“字数统计”中使用的非常相似:
Properties props = new Properties();props.put(StreamsConfig.APPLICATION_ID_CONFIG, "stockstat");props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,Constants.BROKER);props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG,Serdes.String().getClass().getName());props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG,TradeSerde.class.getName());
主要区别在于使用的 Serde 类。在第 265 页的“字数统计”中,我们同时使用字符串表示键和值,因此使用 Serdes.String() 类作为两者的序列化程序和解序列化程序。在此示例中,键仍为字符串,但值为包含股票代码、卖价和卖出大小的 Trade 对象。为了序列化和反序列化这个对象(以及我们在这个小应用程序中使用的其他一些对象),我们使用 Google 的 Gson 库从我们的 Java 对象生成一个 JSon 序列化器和反序列化器。然后创建了一个小型包装器,从这些包装器创建一个 Serde 对象。以下是我们创建Serde的方式:
static public final class TradeSerde extends WrapperSerde<Trade> {public TradeSerde() {super(new JsonSerializer<Trade>(),new JsonDeserializer<Trade>(Trade.class));}}
没什么好看的,但你需要记住为你想要存储在 Kafka 中的每个对象提供一个 Serde 对象——输入、输出,在某些情况下,还有中间结果。为了简化此操作,我们建议通过 GSon、Avro、Protobufs 或类似项目生成这些 Serdes。
现在,我们已经配置好了一切,是时候构建拓扑了:
KStream<TickerWindow, TradeStats> stats = source.groupByKey() (1).aggregate(TradeStats::new, (2)(k, v, tradestats) -> tradestats.add(v), (3)TimeWindows.of(5000).advanceBy(1000), (4)new TradeStatsSerde(), (5)"trade-stats-store") (6).toStream((key, value) -> new TickerWindow(key.key(), key.window().start())) (7).mapValues((trade) -> trade.computeAvgPrice()); (8)stats.to(new TickerWindowSerde(), new TradeStatsSerde(),"stockstats-output"); (9)
(1) 我们首先从输入主题中读取事件并执行 groupByKey() 操作。尽管有其名称,但此操作不执行任何分组。相反,它确保根据记录键对事件流进行分区。由于我们将数据写入到带有键的主题中,并且在调用 groupByKey() 之前没有修改键,因此数据仍按其键进行分区,因此此方法在本例中不执行任何操作。
(2) 在确保正确的分区后,我们开始窗口化聚合。“聚合”方法将流拆分为重叠的窗口(每秒一个 5 秒的窗口),然后对窗口中的所有事件应用聚合方法。此方法采用的第一个参数是一个新对象,该对象将包含聚合结果,在本例中为 Tradestats。这是我们创建的对象,用于包含每个时间窗口(最低价格、平均价格和交易数量)的所有我们感兴趣的统计数据。
(3) 然后,我们提供一种实际聚合记录的方法,在本例中,Tradestats 对象的 add 方法用于使用新记录更新窗口中的最低价格、交易数量和总价格。
(4) 我们定义窗口 - 在本例中,一个 5 秒 (5,000 毫秒) 的窗口,每秒前进一次。
(5) 然后,我们提供了一个 Serde 对象,用于序列化和反序列化聚合结果(Tradestats 对象)。
(6) 如第 256 页的“流处理设计模式”中所述,窗口聚合需要维护状态和将维护状态的本地存储。聚合方法的最后一个参数是状态存储的名称。这可以是任何唯一的名称。
(7) 聚合的结果是一个表,其中代码和时间窗作为主键,聚合结果作为值。我们将表转换回事件流,并将包含整个时间窗口定义的键替换为我们自己的键,该键仅包含代码和窗口的开始时间。此 toStream 方法将表转换为流,并将键转换为我的 TickerWindow 对象。
(8) 最后一步是更新平均价格——现在聚合结果包括价格和交易数量的总和。我们查看这些记录并使用现有的统计数据来计算平均价格,以便我们可以将其包含在输出流中。
(9) 最后,我们将结果写回 stockstats-output 流。
定义流后,我们使用它来生成一个 KafkaStreams 对象并运行它,就像我们在第 265 页的“字数统计”中所做的那样。
此示例演示如何对流执行窗口聚合,这可能是流处理最常用的用例。需要注意的一点是,维护聚合的本地状态所需的工作很少 - 只需提供 Serde 并命名状态存储即可。然而,此应用程序将扩展到多个实例,并通过将某些分区的处理转移到其中一个幸存的实例来自动从每个实例的故障中恢复。我们将在第 272 页的“Kafka Streams:架构概述”中看到更多关于它是如何完成的。
像往常一样,您可以在 GitHub 上找到完整的示例,包括运行它的说明。
11.4.3 单击 Stream Enrichment
最后一个示例将通过丰富网站上的点击流来演示流式联接。我们将生成一个模拟点击流、一个虚构的配置文件数据库表的更新流,以及一个网络搜索流。然后,我们将加入所有三个流,以获得每个用户活动的 360 度视图。用户搜索了什么?他们因此点击了什么?他们是否在用户资料中更改了他们的“兴趣”?这些类型的联接为分析提供了丰富的数据收集。产品推荐通常基于此类信息——用户搜索自行车、点击“Trek”链接并对旅行感兴趣,因此我们可以宣传从 Trek、头盔和自行车之旅到内布拉斯加州等异国情调地点的自行车。
由于配置应用与前面的示例类似,因此让我们跳过此部分,看一下用于联接多个流的拓扑:
KStream<Integer, PageView> views =builder.stream(Serdes.Integer(),new PageViewSerde(), Constants.PAGE_VIEW_TOPIC); (1)KStream<Integer, Search> searches =builder.stream(Serdes.Integer(), new SearchSerde(),Constants.SEARCH_TOPIC);KTable<Integer, UserProfile> profiles =builder.table(Serdes.Integer(), new ProfileSerde(),Constants.USER_PROFILE_TOPIC, "profile-store"); (2)KStream<Integer, UserActivity> viewsWithProfile = views.leftJoin(profiles, (3)(page, profile) -> new UserActivity(profile.getUserID(),profile.getUserName(), profile.getZipcode(),profile.getInterests(), "", page.getPage())); (4)KStream<Integer, UserActivity> userActivityKStream =viewsWithProfile.leftJoin(searches, (5)(userActivity, search) ->userActivity.updateSearch(search.getSearchTerms()), (6)JoinWindows.of(1000), Serdes.Integer(), new UserActivitySerde(), new SearchSerde()); (7)
(1)首先,我们为要加入的两个流(点击和搜索)创建一个流对象。
(2)我们还为用户配置文件定义了一个 KTable。KTable 是通过更改流更新的本地缓存。
(3) 然后,我们通过将事件流与用户档案表联接,使用用户配置文件信息来丰富点击流。在流表联接中,流中的每个事件都从配置文件表的缓存副本接收信息。我们正在执行左联接,因此将保留没有已知用户的点击。
(4)这是联接方法,它采用两个值,一个来自流,一个来自记录,并返回第三个值。与数据库不同,您可以决定如何将两个值组合成一个结果。在本例中,我们创建了一个活动对象,其中包含用户详细信息和查看的页面。
(5)接下来,我们希望将点击信息与同一用户执行的搜索连接起来。这仍然是一个左联接,但现在我们联接了两个流,而不是流式传输到一个表。
(6)这是联接方法,我们只需将搜索词添加到所有匹配的页面浏览量中即可。
(7)这是有趣的部分 - 流到流联接是具有时间窗口的联接。将每个用户的所有点击和搜索合并没有多大意义,我们希望将每个搜索与搜索相关的点击(即搜索后短时间内发生的点击)合并在一起。因此,我们定义了一个 1 秒的联接窗口。在搜索后一秒内发生的点击被视为相关,并且搜索词将包含在包含点击和用户配置文件的活动记录中。这将允许对搜索及其结果进行全面分析。
定义流后,我们使用它来生成一个 KafkaStreams 对象并运行它,就像我们在第 265 页的“字数统计”中所做的那样。
此示例显示了流处理中可能出现的两种不同的联接模式。一个使用表加入流,以使用表中的信息丰富所有流事件。这类似于在数据仓库上运行查询时将事实数据表与维度联接。第二个示例根据时间窗口联接两个流。此操作是流处理所特有的。
像往常一样,您可以在 GitHub 上找到完整的示例,包括运行它的说明。
11.5 Kafka Streams:架构概述
上一节中的示例演示了如何使用 Kafka Streams API 实现一些众所周知的流处理设计模式。但为了更好地理解 Kafka 的 Streams 库的实际工作和扩展方式,我们需要深入了解并了解 API 背后的一些设计原则。
11.5.1 构建拓扑
每个流应用程序都实现并执行至少一个拓扑。拓扑(在其他流处理框架中也称为 DAG,或有向无环图)是一组操作和转换,每个事件从输入移动到输出。图 11-10 显示了第 265 页“字数统计”中的拓扑。
每个流应用程序都实现并执行至少一个拓扑。拓扑(在其他流处理框架中也称为 DAG,或有向无环图)是一组操作和转换,每个事件从输入移动到输出。图 11-10 显示了第 265 页“字数统计”中的拓扑。
图 11-10. 字数统计流处理示例的拓扑
即使是一个简单的应用程序也具有重要的拓扑结构。拓扑由处理器组成,这些处理器是拓扑图中的节点(在图中用圆圈表示)。大多数处理器都实现了数据的操作,包括筛选、映射、聚合等。还有源处理器和接收器处理器,前者使用来自主题的数据并将其传递,后者从早期处理器获取数据并将其生成到主题。拓扑始终从一个或多个源处理器开始,以一个或多个接收器处理器结束。
11.5.2 缩放拓扑
Kafka Streams 通过允许在应用程序的一个实例中执行多个线程以及支持应用程序的分布式实例之间的负载均衡来扩展。您可以在一台具有多个线程的计算机上或在多台计算机上运行 Streams 应用程序;无论哪种情况,应用程序中的所有活动线程都将平衡数据处理中涉及的工作。
Streams 引擎通过将拓扑拆分为任务来并行执行拓扑。任务数由 Streams 引擎确定,并取决于应用程序处理的主题中的分区数。每个任务负责分区的子集:该任务将订阅这些分区并使用其中的事件。对于它使用的每个事件,任务将按顺序执行应用于此分区的所有处理步骤,然后最终将结果写入接收器。这些任务是 Kafka Streams 中并行性的基本单位,因为每个任务都可以独立于其他任务执行。请参见图 11-11。

图 11-11. 运行相同拓扑的两个任务 - 输入主题中的每个分区一个
应用程序的开发人员可以选择每个应用程序实例将执行的线程数。如果有多个线程可用,则每个线程将执行应用程序创建的任务的子集。如果应用程序的多个实例在多个服务器上运行,则将对每个服务器上的每个线程执行不同的任务。这就是流式处理应用程序的扩展方式:在正在处理的主题中,您的任务数量与分区数量一样多。如果要更快地处理,请添加更多线程。如果服务器上的资源不足,请在另一台服务器上启动应用程序的另一个实例。Kafka 将自动协调工作 - 它将为每个任务分配自己的分区子集,每个任务将独立处理来自这些分区的事件,并在拓扑需要时使用相关聚合维护自己的本地状态。请参见图 11-12。

图 11-12. 流处理任务可以在多个线程和多个服务器上运行
您可能已经注意到,有时处理步骤可能需要来自多个分区的结果,这可能会在任务之间创建依赖关系。例如,如果我们联接两个流,就像我们在第 270 页的“Click Stream 扩充”中的 ClickStream 示例中所做的那样,我们需要来自每个流中分区的数据,然后才能发出结果。Kafka Streams 通过将一个联接所需的所有分区分配给同一任务来处理这种情况,以便该任务可以从所有相关分区使用并独立执行联接。这就是为什么 Kafka Streams 目前要求所有参与联接操作的主题都具有相同数量的分区,并根据联接键进行分区。
任务之间依赖关系的另一个示例是,当我们的应用程序需要重新分区时。例如,在 ClickStream 示例中,我们所有的事件都由用户 ID 键控。但是,如果我们想生成每页的统计数据怎么办?还是每个邮政编码?我们需要按邮政编码对数据进行重新分区,并使用新分区运行数据聚合。如果任务 1 处理来自分区 1 的数据并到达对数据进行重新分区的处理器(groupBy 操作),则它需要 shue,这意味着向它们发送事件 - 将事件发送到其他任务以处理它们。与其他流处理器框架不同,Kafka Streams 通过将事件写入具有新键和分区的新主题来重新分区。然后,另一组任务从新主题中读取事件并继续处理。重新分区步骤将拓扑分解为两个子拓扑,每个子拓扑都有自己的任务。第二组任务依赖于第一组任务,因为它处理第一个子拓扑的结果。但是,第一组和第二组任务仍然可以独立并行运行,因为第一组任务以自己的速率将数据写入主题,而第二组任务从主题中消耗数据并自行处理事件。任务之间没有通信,也没有共享资源,它们不需要在相同的线程或服务器上运行。这是 Kafka 做的更有用的事情之一——减少管道不同部分之间的依赖关系。如图11-13所示。
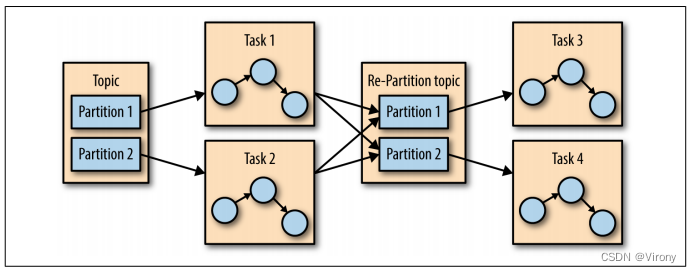
图 11-13. 两组任务处理事件,其中包含用于在它们之间重新分区事件的主题
11.5.3 幸免于难
允许我们扩展应用程序的相同模型也允许我们优雅地处理故障。首先,Kafka 是高可用性的,因此我们持久化到 Kafka 的数据也是高可用性的。因此,如果应用程序失败并需要重新启动,它可以从 Kafka 查找其在流中的最后一个位置,并从失败前提交的最后一个偏移量继续处理。请注意,如果本地状态存储丢失(例如,因为我们需要替换存储它的服务器),streams 应用程序始终可以从它存储在 Kafka 中的更改日志中重新创建它。
Kafka Streams 还利用 Kafka 的使用者协调为任务提供高可用性。如果任务失败,但有线程或流应用程序的其他实例处于活动状态,则该任务将在其中一个可用线程上重新启动。这类似于使用者组通过将分区分配给其余使用者之一来处理组中某个使用者的故障。
11.6 流处理用例
在本章中,我们学习了如何进行流处理 - 从一般概念和模式到 Kafka Streams 中的特定示例。在这一点上,可能值得看看常见的流处理用例。如本章开头所述,流处理(或连续处理)在以下情况下非常有用:您希望以快速顺序处理事件,而不是等待数小时才能处理下一批事件,但您不希望响应在几毫秒内到达。这都是真的,但也非常抽象。我们来看几个可以通过流处理解决的真实场景:
-
顾客服务
假设您刚刚在一家大型连锁酒店预订了一个房间,并且您期望收到电子邮件确认和收据。预订几分钟后,当确认仍未到达时,您致电客户服务以确认您的预订。假设客服台告诉您“我在我们的系统中没有看到订单,但是将数据从预订系统加载到酒店的批处理作业,客服台每天只运行一次,所以请明天回电。您应该会在 2-3 个工作日内看到电子邮件。这听起来不是很好的服务,但我不止一次与一家大型连锁酒店进行过这样的对话。我们真正想要的是连锁酒店中的每个系统都能在预订后几秒钟或几分钟内获得有关新预订的更新,包括客户服务中心、酒店、发送电子邮件确认的系统、网站等。您还希望客户服务中心能够立即提取有关您过去访问过连锁酒店的任何酒店的所有详细信息,并且酒店的接待处知道您是忠实客户,以便他们可以为您提供升级。使用流处理应用程序构建所有这些系统,使他们能够近乎实时地接收和处理更新,从而带来更好的客户体验。有了这样的系统,我会在几分钟内收到一封确认电子邮件,我的信用卡会按时扣款,收据会寄出,服务台可以立即回答我关于预订的问题。
-
物联网 物联网可以意味着很多事情——从用于调节温度和订购洗衣粉补充装的家用设备到制药的实时质量控制。将流处理应用于传感器和设备时,一个非常常见的用例是尝试预测何时需要预防性维护。这类似于应用程序监控,但适用于硬件,在许多行业中很常见,包括制造业、电信(识别有故障的手机信号塔)、有线电视(在用户投诉之前识别有故障的盒顶设备)等等。每个案例都有自己的模式,但目标是相似的:大规模处理来自设备的事件,并识别表明设备需要维护的模式。这些模式可能是交换机丢弃的数据包,在制造过程中拧紧螺丝所需的更大力,或者用户更频繁地重新启动有线电视的盒子。
* 欺诈检测:也称为异常检测,是一个非常广泛的领域,专注于捕获系统中的“作弊者”或不良行为者。欺诈检测应用的示例包括检测信用卡欺诈、股票交易欺诈、视频游戏作弊者和网络安全风险。在所有这些领域,尽早发现欺诈行为有很大的好处,因此,能够快速响应事件的近乎实时的系统(也许在不良交易获得批准之前就停止了该交易)比在事后三天检测欺诈的批处理作业更可取,因为清理要复杂得多。这又是一个在大规模事件流中识别模式的问题。
在网络安全中, 有一种称为信标的方法.当黑客在组织内部植入恶意软件时,它偶尔会到达外部接收命令。可能很难检测到此活动,因为它可以在任何时间和任何频率发生。通常,网络可以很好地抵御外部攻击,但更容易受到组织内部人员的攻击。通过处理大量网络连接事件并将通信模式识别为异常(例如,检测到此主机通常不访问这些特定 IP),可以在造成更多损害之前及早向安全组织发出警报。
11.7 如何选择流处理框架
在选择流处理框架时,重要的是要考虑您计划编写的应用程序类型。不同类型的应用程序需要不同的流处理解决方案:
-
摄取 目标是将数据从一个系统获取到另一个系统,并对数据进行一些修改,以使其符合目标系统。
-
低毫秒级操作 任何需要几乎立即响应的应用程序。一些欺诈检测用例属于此范围。
-
异步微服务 这些微服务代表更大的业务流程执行简单的操作,例如更新商店的库存。这些应用程序可能需要 维护本地状态缓存事件作为提高性能的一种方式。
-
近乎实时的数据分析 这些流式处理应用程序执行复杂的聚合和联接,以便对数据进行切片和切块,并生成有趣的业务相关见解。
您将选择的流处理系统将在很大程度上取决于您要解决的问题。
• 如果你正在尝试解决一个摄取问题,你应该重新考虑你是一个流处理系统,还是一个更简单的摄取系统,如 Kafka Connect。如果您确定需要一个流处理系统,则需要确保它既有良好的连接器选择,又有适合您目标系统的高质量连接器。
• 如果您尝试解决需要低毫秒操作的问题,您还应该重新考虑您的流选择。请求-响应模式通常更适合此任务。如果您确定需要一个流处理系统,那么您需要选择一个支持逐个事件低延迟模型的系统,而不是一个专注于微批处理的系统。
• 如果你正在构建异步微服务,你需要一个流处理系统,该系统可以与你选择的消息总线(希望是 Kafka)很好地集成,具有更改捕获功能,可以轻松地将上游更改传递到微服务本地缓存,并且具有本地存储的良好支持,可以用作微服务数据的缓存或具体化视图。
• 如果您正在构建一个复杂的分析引擎,您还需要一个对本地存储有强大支持的流处理系统,这一次,不是为了维护本地缓存和具体化视图,而是为了支持高级聚合、窗口和联接,否则很难实现。API 应包括对自定义聚合、窗口操作和多种联接类型的支持。
除了特定于用例的注意事项外,还应考虑一些全局注意事项:
-
系统的可操作性 是否易于部署到生产环境?是否易于监控和故障排除?在需要时是否易于扩展和缩减?它是否与您现有的基础架构很好地集成在一起?如果出现错误,需要重新处理数据怎么办?
-
API 的可用性和调试的易用性 我发现,在同一框架的不同版本之间,编写高质量应用程序所需的时间存在数量级差异。开发时间和上市时间非常重要,因此您需要选择一个能够提高效率的系统。
-
让困难的事情变得简单 几乎每个系统都会声称它们可以执行高级窗口聚合并维护本地缓存,但问题是:它们是否让您轻松?他们是否处理有关规模和恢复的粗犷细节,或者他们是否提供泄漏的抽象并让您处理大部分混乱?系统越是公开干净的 API 和抽象,并自行处理粗犷的细节,开发人员的工作效率就越高。
-
社区 您考虑的大多数流处理应用程序都将是开源的,充满活力和活跃的社区是无可替代的。良好的社区意味着您定期获得新的和令人兴奋的功能,质量相对较好(没有人愿意在糟糕的软件上工作),错误得到快速修复,用户问题及时得到答案。这也意味着,如果你遇到一个奇怪的错误并在谷歌上搜索它,你会找到有关它的信息,因为其他人正在使用这个系统并看到同样的问题。
11.8 总结
本章的开头是解释流处理。我们给出了一个正式的定义,并讨论了流处理范式的共同属性。我们还将其与其他编程范式进行了比较。
然后,我们讨论了重要的流处理概念。这些概念通过三个使用 Kafka Streams 编写的示例应用程序进行了演示。
在了解了这些示例应用程序的所有细节之后,我们概述了 Kafka Streams 架构,并解释了它是如何工作的。在本章和本书的最后,我们用几个流处理用例的例子和关于如何比较不同流处理框架的建议来结束。
附录 A 在其他操作系统上安装 Kafka
Apache Kafka 主要是一个 Java 应用程序,因此应该能够在任何能够安装 JRE 的系统上运行。但是,它已针对基于 Linux 的操作系统进行了优化,因此这是它性能最佳的地方。在其他操作系统上运行可能会导致特定于操作系统的错误。因此,在通用桌面操作系统上使用 Kafka 进行开发或测试时,最好考虑在与最终生产环境相匹配的虚拟机中运行。
A.1 在 Windows 上安装
从 Microsoft Windows 10 开始,现在有两种方法可以运行 Kafka。传统方法是使用本机 Java 安装。Windows 10 用户还可以选择使用适用于 Linux 的 Windows 子系统。后一种方法是首选,因为它提供了更简单的设置,更接近典型的生产环境,因此我们将首先对其进行审查。
A.1.1 使用适用于 Linux 的 Windows 子系统
如果运行的是 Windows 10,则可以使用适用于 Linux 的 Windows 子系统 (WSL) 在 Windows 下安装本机 Ubuntu 支持。在发布时,Microsoft 仍然认为 WSL 是一项实验性功能。虽然它的行为类似于虚拟机,但它不需要完整 VM 的资源,并提供与 Windows 操作系统的更丰富的集成。
若要安装 WSL,应按照 Windows 上的 Ubuntu 上的 Bash 页面上的 Microsoft 开发人员网络提供的说明进行操作。完成后,您需要使用 apt-get 安装 JDK:
$ sudo apt-get install openjdk-7-jre-headless[sudo] password for username:Reading package lists... DoneBuilding dependency treeReading state information... Done[...]done.$
安装 JDK 后,您可以按照第 2 章中的说明继续安装 Apache Kafka。
A.1.2 使用原生 Java
对于较旧版本的 Windows,或者如果不想使用 WSL 环境,则可以在适用于 Windows 的 Java 环境中本机运行 Kafka。但是请注意,这可能会引入特定于 Windows 环境的 bug。这些错误可能不会像 Linux 上的类似问题那样在 Apache Kafka 开发社区中引起注意。
在安装 Zookeeper 和 Kafka 之前,必须设置 Java 环境。您应安装最新版本的 Oracle Java 8,该版本可在 Oracle Java SE 下载页面上找到。下载完整的 JDK 包,以便拥有所有可用的 Java 工具,然后按照说明进行安装。
* 小心路径安装 Java 和 Kafka 时,强烈建议您坚持使用不包含空格的安装路径。虽然 Windows 允许在路径中使用空格,但设计为在 Unix 环境中运行的应用程序不是以这种方式设置的,并且指定路径将很困难。安装 Java 时,请确保在设置安装路径时牢记这一点。例如,如果安装 JDK 1.8 update 121,则使用路径 C:Javajdk1.8.0_121 是一个不错的选择。
安装 Java 后,您应该设置环境变量,以便可以使用它。这是在 Windows 的控制面板中完成的,但确切位置将取决于您的操作系统版本。在 Windows 10 中,必须选择“系统和安全”,然后选择“系统”,然后单击“计算机名称、域和工作组设置”部分下的“更改设置”。这将打开“系统属性”窗口,您可以在其中选择“高级”选项卡,最后单击“环境变量...”。按钮。使用此部分添加一个名为 JAVA_HOME 的新用户变量(图 A-1),并将其设置为安装 Java 的路径。然后编辑名为 Path 的系统变量,并添加一个新条目,即 %JAVA_HOME%bin。保存这些设置并退出控制面板。
图 A-1.添加 JAVA_HOME 变量
现在,您可以继续安装 Apache Kafka。安装包括 Zookeeper,因此您不必单独安装它。可以下载 Kafka 的当前版本。在发布时,该版本为 0.10.1.0,在 Scala 版本 2.11.0 下运行。下载的文件将被 GZip 压缩并使用 tar 实用程序打包,因此您需要使用 Windows 应用程序(如 8Zip)来解压缩它。与在 Linux 上安装类似,您必须选择要将 Kafka 提取到的目录。在此示例中,我们假设 Kafka 被提取到 C:kafka_2.11-0.10.1.0 中。
在 Windows 下运行 Zookeeper 和 Kafka 略有不同,因为您必须使用为 Windows 设计的批处理文件,而不是其他平台的 shell 脚本。这些批处理文件也不支持应用程序后台化,因此每个应用程序都需要一个单独的 shell。首先,启动 Zookeeper:
PS C:\> cd kafka_2.11-0.10.2.0PS C:\kafka_2.11-0.10.2.0> bin/windows/zookeeper-server-start.bat C:\kafka_2.11-0.10.2.0\config\zookeeper.properties[2017-04-26 16:41:51,529] INFO Reading configuration from: C:\kafka_2.11-0.10.2.0\config\zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)[...][2017-04-26 16:41:51,595] INFO minSessionTimeout set to -1 (org.apache.zookeeper.server.ZooKeeperServer)[2017-04-26 16:41:51,596] INFO maxSessionTimeout set to -1 (org.apache.zookeeper.server.ZooKeeperServer)[2017-04-26 16:41:51,673] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
一旦 Zookeeper 运行,你可以打开另一个窗口来启动 Kafka:
PS C:\> cd kafka_2.11-0.10.2.0PS C:\kafka_2.11-0.10.2.0> .\bin\windows\kafka-server-start.bat C:\kafka_2.11-0.10.2.0\config\server.properties[2017-04-26 16:45:19,804] INFO KafkaConfig values:[...][2017-04-26 16:45:20,697] INFO Kafka version : 0.10.2.0 (org.apache.kafka.common.utils.AppInfoParser)[2017-04-26 16:45:20,706] INFO Kafka commitId : 576d93a8dc0cf421 (org.apache.kafka.common.utils.AppInfoParser)[2017-04-26 16:45:20,717] INFO [Kafka Server 0], started (kafka.server.KafkaServer)
A.2 在 MacOS 上安装
MacOS 运行在 Darwin 上,Darwin 是一个 Unix 操作系统,部分源自 FreeBSD。这意味着在 Unix 操作系统上运行的许多期望都是正确的,并且安装为 Unix 设计的应用程序(如 Apache Kafka)并不太困难。您可以使用包管理器(如 Homebrew)保持安装简单,也可以手动安装 Java 和 Kafka 以更好地控制版本。
A.2.1 使用 Homebrew
如果您已经安装了 Homebrew for MacOS,您可以使用它一步安装 Kafka。这将确保您首先安装了 Java,然后它将安装 Apache Kafka 0.10.2.0(在撰写本文时)。
如果您尚未安装 Homebrew,请先按照安装页面上的说明进行操作。然后,您可以安装 Kafka 本身。Homebrew 包管理器将确保您首先安装了所有依赖项,包括 Java:
$ brew install kafka==> Installing kafka dependency: zookeeper[...]==> Summary/usr/local/Cellar/kafka/0.10.2.0: 132 files, 37.2MB$
Homebrew 将把 Kafka 安装在 /usr/local/Cellar 下,但文件将链接到其他目录: • 二进制文件和脚本将位于 /usr/local/bin 中 • Kafka 配置将在 /usr/local/etc/kafka 中 • Zookeeper 配置将在 /usr/local/etc/zookeeper 中 • log.dirs 配置(Kafka 数据的位置)将设置为 /usr/local/var/lib/kafka-logs 安装完成后,可以启动 Zookeeper 和 Kafka(本示例在前台启动 Kafka):
$ /usr/local/bin/zkServer startJMX enabled by defaultUsing config: /usr/local/etc/zookeeper/zoo.cfgStarting zookeeper ... STARTED$ kafka-server-start.sh /usr/local/etc/kafka/server.properties[...][2017-02-09 20:48:22,485] INFO [Kafka Server 0], started (kafka.server.KafkaServer)
A.2.2 手动安装
与 Windows 操作系统的手动安装类似,在 MacOS 上安装 Kafka 时,必须先安装 JDK。可以使用相同的 Oracle Java SE 下载页面获取适用于 MacOS 的正确版本。然后,您可以再次下载 Apache Kafka,类似于 Windows。在此示例中,我们假设 Kafka 下载已展开到 /usr/local/kafka_2.11-0.10.2.0 目录中。
启动 Zookeeper 和 Kafka 就像在使用 Linux 时启动它们一样,但您需要确保首先设置JAVA_HOME目录:
$ export JAVA_HOME=`/usr/libexec/java_home`$ echo $JAVA_HOME/Library/Java/JavaVirtualMachines/jdk1.8.0._131.jdk/Contents/Home$ /usr/local/kafka_2.11-0.10.2.0/bin/zookeeper-server-start.sh -daemon /usr/local/kafka_2.11-0.10.2.0/config/zookeeper.properties$ /usr/local/kafka_2.11-0.10.2.0/bin/kafka-server-start.sh /usr/local/etc/kafka/server.properties[2017-04-26 16:45:19,804] INFO KafkaConfig values:[...][2017-04-26 16:45:20,697] INFO Kafka version : 0.10.2.0 (org.apache.kafka.common.utils.AppInfoParser)[2017-04-26 16:45:20,706] INFO Kafka commitId : 576d93a8dc0cf421 (org.apache.kafka.common.utils.AppInfoParser)[2017-04-26 16:45:20,717] INFO [Kafka Server 0], started (kafka.server.KafkaServer)