112 路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
示例: 给定如下二叉树,以及目标和 sum = 22,
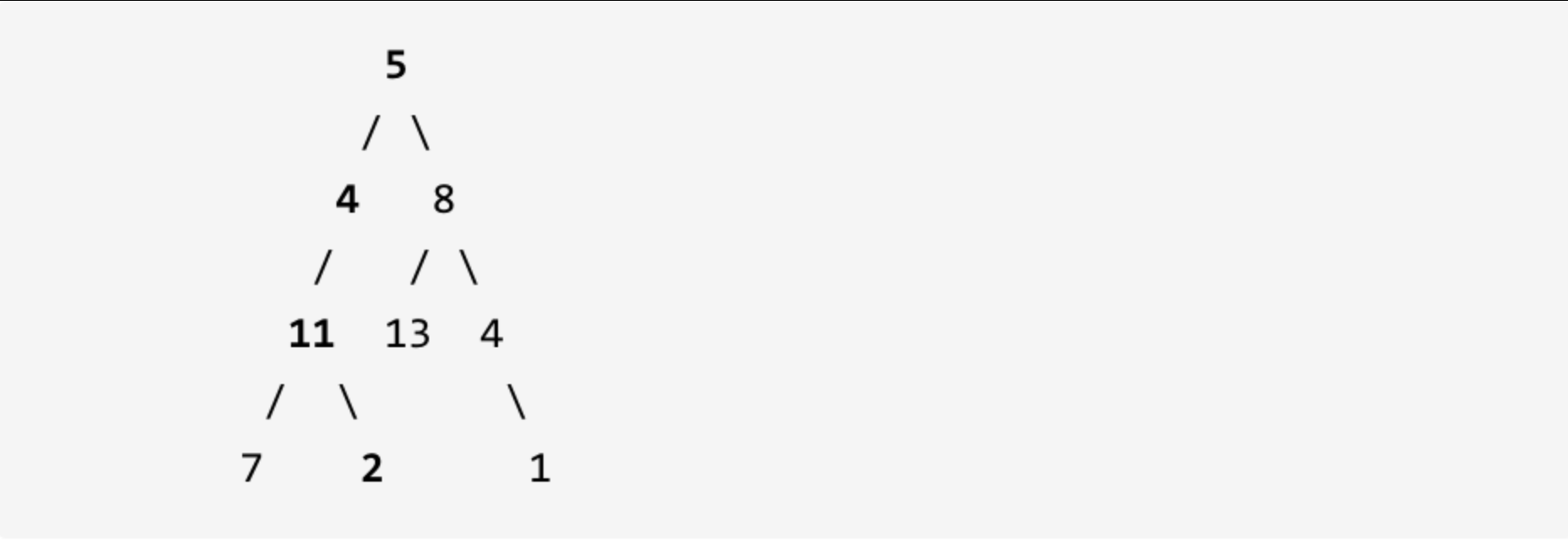
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
思路
参考:https://www.programmercarl.com/0112.%E8%B7%AF%E5%BE%84%E6%80%BB%E5%92%8C.html#%E6%80%9D%E8%B7%AF
递归函数什么时候要有返回值,什么时候没有返回值,特别是有的时候递归函数返回类型为bool类型。
那么接下来我通过详细讲解如下两道题,来回答这个问题:
112.路径总和
113.路径总和ii
这道题我们要遍历从根节点到叶子节点的路径看看总和是不是目标和。
递归
可以使用深度优先遍历的方式(本题前中后序都可以,无所谓,因为中节点也没有处理逻辑)来遍历二叉树
- 确定递归函数的参数和返回类型
参数:需要二叉树的节点,还需要一个计数器,这个计数器用来计算二叉树的一条边之和是否正好是目标和,计数器为int型。
再来看返回值,递归函数什么时候需要返回值?什么时候不需要返回值?这里总结如下三点:
- 如果需要搜索整棵二叉树且不用处理递归返回值,递归函数就不要返回值。(这种情况就是本文下半部分介绍的113.路径总和ii)
- 如果需要搜索整棵二叉树且需要处理递归返回值,递归函数就需要返回值。 (这种情况我们在236. 二叉树的最近公共祖先 中介绍)
- 如果要搜索其中一条符合条件的路径,那么递归一定需要返回值,因为遇到符合条件的路径了就要及时返回。(本题的情况)
而本题我们要找一条符合条件的路径,所以递归函数需要返回值,及时返回,那么返回类型是什么呢?
如图所示:
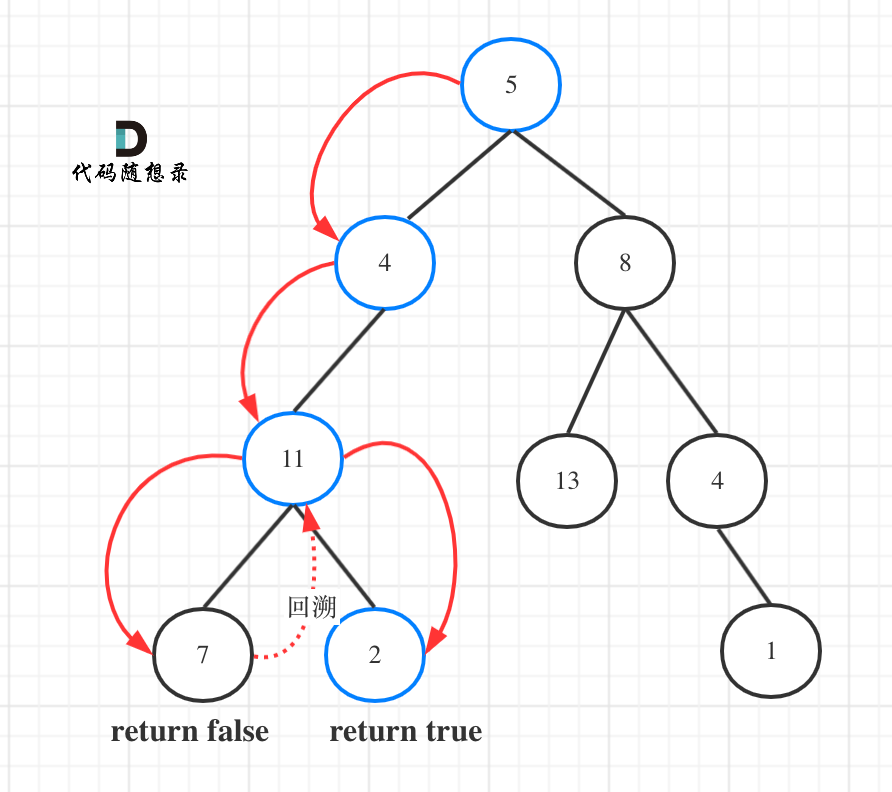
图中可以看出,遍历的路线,并不要遍历整棵树(只需要有符合题意得时候 立刻返回就行),所以递归函数需要返回值,可以用bool类型表示。
所以代码如下:
# 我的问题就是遍历到一条路径底部时候 如何转到另一条路径 —— > 回溯def travelsal(self, node, count): # 递归第一步 参数为当前节点 另外采用一个计数器 遍历路径时候减去当前遍历节点的值
在python中 函数头不明确指明返回值类型 但自己要知道 返回值什么 为什么需要返回值
- 确定终止条件
首先计数器如何统计这一条路径的和呢?
不要去累加然后判断是否等于目标和,那么代码比较麻烦,可以用递减,让计数器count初始为目标和,然后每次减去遍历路径节点上的数值。(逆向思维)
如果最后count == 0,同时到了叶子节点的话,说明找到了目标和。
如果遍历到了叶子节点,count不为0,就是没找到。
递归终止条件代码如下:
if not node.left and not node.right and count == 0:return True # 到达叶子节点 且count为0 说明当前路径刚好符合目标
if not node.left and not node.right:return False # 到达叶子节点 但是count不为0 因为路径有很多条 到达路径时候必然是叶子节点
- 确定单层递归的逻辑
因为终止条件是判断叶子节点,所以递归的过程中就不要让空节点进入递归了。
递归函数是有返回值的,如果递归函数返回true,说明找到了合适的路径,应该立刻返回。
代码如下:
if node.left:count -= node.left.valif self.travelsal(node.left, count): # 递归处理节点return Truecount += node.left.val # 回溯
# 右
if node.right:count -= node.right.valif self.travelsal(node.right, count):return Truecount += node.right.val # 回溯
完整代码:
class TreeNode(object):def __init__(self, val=0, left=None, right=None):self.val = valself.left = leftself.right = rightclass Solution(object):def hasPathSum(self, root, targetSum):""":type root: TreeNode:type targetSum: int:rtype: bool"""if not root:return False# self.travelsal(root, targetSum)return self.travelsal(root, targetSum - root.val) # 减去根节点的 再遍历之后的# 我的问题就是遍历到一条路径底部时候 如何转到另一条路径 —— > 回溯def travelsal(self, node, count): # 递归第一步 参数为当前节点 另外采用一个计数器 遍历路径时候减去当前遍历节点的值if not node.left and not node.right and count == 0:return True # 到达叶子节点 且count为0 说明当前路径刚好符合目标if not node.left and not node.right:return False # 到达叶子节点 但是count不为0 因为路径有很多条 到达路径时候必然是叶子节点# 左# if node.left:# count -= node.left.val# self.travelsal(node.left, count)# count += node.left.val # 回溯 # 上面错误if node.left:count -= node.left.valif self.travelsal(node.left, count): # 递归处理节点return Truecount += node.left.val # 回溯 # 右if node.right:count -= node.right.valif self.travelsal(node.right, count):return Truecount += node.right.val # 回溯return False # 注意最后还要返回False 因为没有符合以上True的情况
迭代法
如果使用栈模拟递归的话,那么如果做回溯呢?
此时栈里一个元素不仅要记录该节点指针,还要记录从头结点到该节点的路径数值总和。
# 法二 迭代法
class Solution(object):def hasPathSum(self, root, targetSum):if not root:return False # 树为空 直接返回False# 采用前序遍历 中左右 stack = [(root, root.val)] # 栈里面存储的是节点及节点值while stack:node, path_sum = stack.pop()# 如果该节点是叶子节点了,同时该节点的路径数值等于sum,那么就返回trueif not node.left and not node.right and path_sum == targetSum:return True# # 左节点,压进去一个节点的时候,将该节点的路径数值也记录下来if node.left:stack.append((node.left, path_sum + node.left.val))# 右节点if node.right:stack.append((node.right, path_sum + node.right.val))return False
113 路径总和2
给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。(本题与上一题得区别是要找到所有的路径)
说明: 叶子节点是指没有子节点的节点。
示例: 给定如下二叉树,以及目标和 sum = 22,
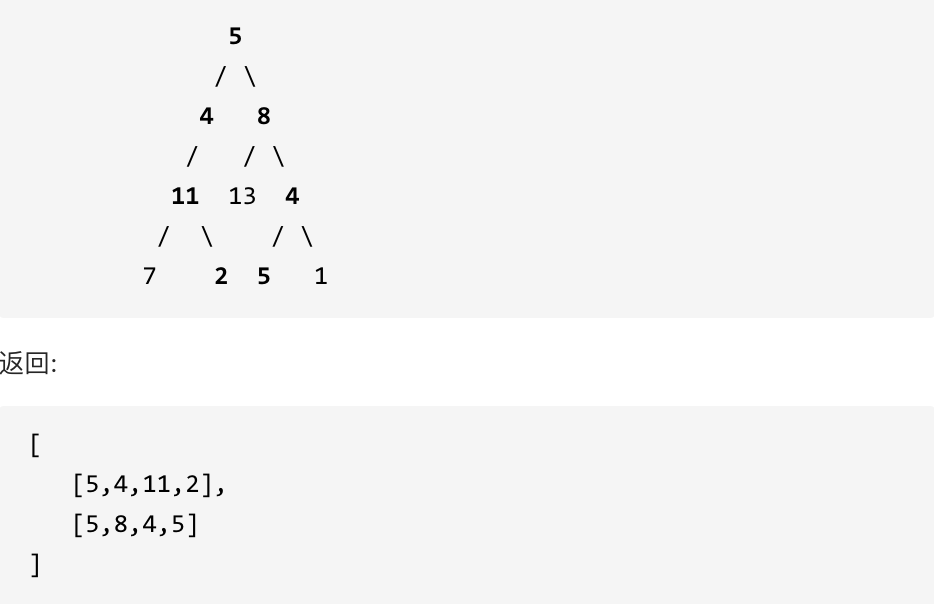
思路
113.路径总和ii要遍历整个树,找到所有路径,所以递归函数不要返回值!
如图:
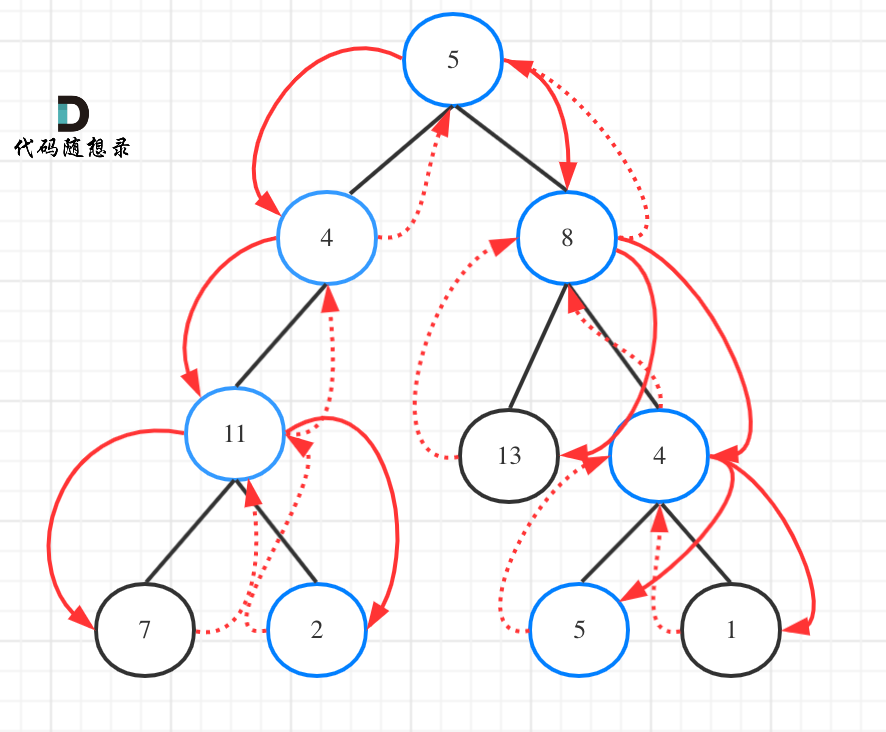
代码:
class TreeNode(object):def __init__(self, val=0, left=None, right=None):self.val = valself.left = leftself.right = right# 本题与112题不同的是 本题要找出所有路径 所以除了count计数之外 还需要一个列表来存储路径结果
class Solution(object):def __init__(self):self.result = [] # 总的结果self.path = [] # 单条路径结果def pathSum(self, root, targetSum):""":type root: TreeNode:type targetSum: int:rtype: List[List[int]]"""# 先清空 result 和 path# self.result.clear()# self.path.clear()del self.result[:] # 注意若是 del self.result则是删除整个对象 而加了[:]是删除其中的元素del self.path[:]if not root:return self.resultself.path.append(root.val) # 把根节点放入pathself.travelsal(root, targetSum - root.val)return self.resultdef travelsal(self, node, count): # 用node表示更一般化 容易理解if not node.left and not node.right and count == 0:self.result.append(self.path[:]) # 收获结果 符合题目的单条路径加到总结果中 注意是 self.path[:]return if not node.left and not node.right:returnif node.left: # 左节点不为空 空节点不遍历self.path.append(node.left.val)count -= node.left.valself.travelsal(node.left, count) # 递归节点count += node.left.val # 回溯self.path.pop() # 回溯 pop不需要传入参数if node.right: # 右节点不为空 空节点不遍历self.path.append(node.right.val)count -= node.right.valself.travelsal(node.right, count) # 递归节点count += node.right.val # 回溯self.path.pop() # 回溯return # 不需要返回值 直接一个return就行
self.result.append(self.path) 与 self.result.append(self.path[:]) 的区别:
- result.append(self.path) 将 self.path 添加到 result 列表中,但实际上它是对 self.path 的引用。这意味着如果后续更改了 self.path 的值,result 列表中的相应元素也会受到影响,因为它们引用相同的对象。这是因为 self.path 是一个可变对象(例如,列表、字典),并且在列表中仅存储了对该对象的引用。
self.path = [1, 2, 3]
result = []
result.append(self.path)self.path.append(4)
print(result) # 输出 [1, 2, 3, 4]- result.append(self.path[:]) 创造了 self.path 的一个副本,并将该副本添加到 result 列表中。这意味着即使后续更改了 self.path 的值,result 列表中的元素仍然保持不变,因为它们引用的是一个独立的副本。
self.path = [1, 2, 3]
result = []
result.append(self.path[:])self.path.append(4)
print(result) # 输出 [1, 2, 3]总结
本篇通过leetcode上112. 路径总和 和 113. 路径总和ii 详细的讲解了 递归函数什么时候需要返回值,什么不需要返回值。
这两道题目是掌握这一知识点非常好的题目,大家看完本篇文章再去做题,就会感受到搜索整棵树和搜索某一路径的差别。
对于112. 路径总和,我依然给出了递归法和迭代法,这种题目其实用迭代法会复杂一些,能掌握递归方式就够了
参考:https://www.programmercarl.com/0112.%E8%B7%AF%E5%BE%84%E6%80%BB%E5%92%8C.html