微光图像增强(LLIE)研究如何提高照明并生成正常光图像。现有的大多数方法都是通过全局和统一的方式来改善低光图像,而不考虑不同区域的语义信息。如果没有语义先验,网络可能很容易偏离区域的原始颜色。为了解决这个问题,我们提出了一种新的语义感知知识引导框架(SKF),该框架可以帮助弱光增强模型学习封装在语义分割模型中的丰富多样的先验。我们专注于从三个关键方面整合语义知识:一个语义感知嵌入模块,它在特征表示空间中明智地集成了语义先验,一个语义引导的颜色直方图损失,它保持了各种实例的颜色一致性,以及一个语义导导的对抗性损失,它通过语义先验产生更自然的纹理。我们的SKF作为LLIE任务的通用框架具有吸引力。大量实验表明,配备SKF的模型在多个数据集上显著优于基线,我们的SKF很好地推广到不同的模型和场景。
The code is available at langmanbusi/Semantic-Aware-Low-Light-Image-Enhancement: Semantic-Aware LLIE. CVPR 2023 (github.com)
1. Introduction
在现实世界中,由于不可避免的环境或技术限制,如光照不足和曝光时间有限,低光成像相当普遍。低光图像不仅对人类视觉感知有很差的可见度,而且对于后续的多媒体计算和针对高质量图像设计的视觉任务也不适用。因此,提出了低光图像增强(LLIE)的概念,旨在揭示低光图像中隐藏的细节,避免在后续视觉任务中性能下降的问题。主流的传统LLIE方法包括基于直方图均衡化的方法[2]和基于Retinex模型的方法[18]。
最近,许多基于深度学习的低光图像增强(LLIE)方法被提出,例如端到端的框架[5,7,34,45,46,48]和基于Retinex的框架[29, 41, 43, 44, 49, 53, 54]。由于它们在建模低光和高质量图像之间的映射能力,深度LLIE方法通常比传统方法取得更好的结果。然而,现有方法通常在全局和均匀地改善低光图像,而不考虑不同区域的语义信息,这对于图像增强至关重要。如图1(a)所示,缺乏利用语义先验的网络可能会轻易偏离区域的原始色调[22]。此外,研究表明将语义先验纳入低光增强是至关重要的。例如,Fan等人[8]利用语义地图作为先验,并将其纳入特征表示空间,从而提升图像质量。而不是依赖于优化中间特征,Zheng等人[58]采用新颖的损失函数来保证增强图像的语义一致性。这些方法成功地将语义先验与LLIE任务结合起来,展示了语义约束和引导的优越性。然而,它们的方法未能充分利用语义分割网络可以提供的知识,限制了通过语义先验获得的性能提升。此外,分割和增强之间的交互是针对特定方法设计的,限制了将语义引导纳入LLIE任务的可能性。因此,我们想要探讨两个问题:1.我们如何获取各种可用的语义知识?2.语义知识如何在LLIE任务中对图像质量改善做出贡献?
我们试图回答第一个问题。首先,引入了一个在大规模数据集上预先训练的语义分割网络作为语义知识库。SKB可以提供更丰富、更多样的语义先验,以提高增强网络的能力。其次,根据先前的工作[8,19,58],SKB提供的可用先验主要由中间特征和语义图组成。一旦训练了LLIE模型,SKB就会产生上述语义先验,并指导增强过程。先验不仅可以通过使用亲和矩阵、空间特征变换[40]和注意力机制等技术来细化图像特征,还可以通过将区域信息明确地纳入LLIE任务来指导目标函数的设计[26]。
然后我们试着回答第二个问题。基于上述答案,我们设计了一系列新颖的方法,将语义知识集成到LLIE任务中,形成了一个新颖的语义感知知识引导框架(SKF)。首先,我们使用在PASCAL上下文数据集[35]上预训练的高分辨率网络[38](HRNet)作为前面提到的SKB。为了利用中间特征,我们开发了一个语义感知嵌入(SE)模块。它计算参考特征和目标特征之间的相似性,并采用异构表示之间的跨模态交互。因此,我们将图像特征的语义感知量化为一种注意力形式,并在增强网络中嵌入语义一致性。
其次,一些方法[20,55]提出使用颜色直方图优化图像增强,以保持图像的颜色一致性,而不是简单地全局增强亮度。另一方面,颜色直方图仍然是一种全局统计特征,不能保证局部一致性。因此,我们提出了一种语义引导的颜色直方图(SCH)损失来细化颜色一致性。在这里,我们打算利用从场景语义导出的局部几何信息和从内容导出的全局颜色信息。除了保证增强图像的原始颜色外,它还可以将空间信息添加到颜色直方图中,执行更细致的颜色恢复。
第三,现有的损失函数与人类感知不太一致,无法捕捉图像的内在信号结构,导致不愉快的视觉结果。为了提高视觉质量,EnlightenGAN[16]采用全局和局部图像内容一致性,并随机选择局部补丁。然而,鉴别器不知道哪里的区域可能是“假的”。因此,我们提出了一种语义引导的对抗性(SA)损失。具体来说,通过使用分割图来确定伪区域,提高了鉴别器的能力,可以进一步提高图像质量。
我们工作的主要贡献如下:
•我们提出了一个语义感知知识引导框架(SKF),通过共同保持颜色一致性和提高图像质量来提高现有方法的性能。
•我们提出了三种关键技术来充分利用语义知识库(SKB)提供的语义先验:语义感知嵌入(SE)模块、语义引导的颜色直方图(SCH)丢失和语义引导的对抗性(SA)丢失。
•我们在LOL/LOL-v2数据集和未配对数据集上进行了实验。实验结果表明,我们的SKF大大提高了性能,验证了其在解决LLIE任务方面的有效性。
2. Related Work
2.1. Low-light Image Enhancement
传统方法。低光增强的传统方法包括基于直方图均衡的方法[2]和基于Retinex模型的方法[18]。前者通过扩展动态范围来改善微光图像。后者将低光图像分解为反射图和照明图,并且反射分量被视为增强图像。这种基于模型的方法需要明确的先验来很好地拟合数据,但为各种场景设计合适的先验是困难的[44]。
基于学习的方法。最近基于深度学习的方法显示出有希望的结果[15,29,43,44,53,54,56]。我们可以进一步将现有的设计分为基于Retinex的方法和端到端的方法。基于Retinex的方法使用深度网络来分解和增强图像。Wei等人提出了一种基于Retinex的两阶段方法,称为Retinex-Net[43]。受Retinex Net的启发,张等人提出了两种改进的方法,称为KinD[54]和KinD[53]。最近,Wu等人[44]提出了一种新的基于Retinex的深度展开网络,以进一步整合基于模型和基于学习的方法的优势。
与基于Retinex的方法相比,端到端方法直接学习增强的结果[5-7,27,32,34,37,41,45,46,51,57,59]。Lore等人[30]首次尝试提出了一种名为LowLight Net(LLNet)的深度自动编码器。稍后,提出了各种端到端的方法。提出了基于物理的概念,例如拉普拉斯金字塔[27]、局部参数滤波器[34]、拉格朗日乘法器[57]、德拜尔滤波器[5]、归一化流[41]和小波变换[7],以提高模型的可解释性并产生视觉上令人满意的结果。在[16,17,48]中,引入了对抗性学习来捕捉视觉特性。在[11]中,创造性地将光增强公式化为使用零样本学习的图像特定曲线估计任务。在[20,47,55]中,使用3D查找表和颜色直方图来保持颜色一致性。然而,现有的设计侧重于优化增强过程,而忽略了不同区域的语义信息。相反,我们设计了一个具有三个关键技术的SKF,以探索语义先验的潜力,从而产生视觉上令人愉悦的增强结果
2.2. Semantic-Guided Methods
最近,语义引导方法证明了语义先验的可靠性。这些方法可分为两类:损失级语义引导方法和特征级语义引导方式。
Loss-level semantic-guided methods 为了利用语义先验,一些工作侧重于利用语义感知损失作为原始视觉任务的额外目标函数。在图像去噪[28]、图像超分辨率[1]、微光图像增强[58]中,研究人员直接利用语义分割损失作为额外的约束来指导训练过程。梁等人[26]通过使用语义亮度一致性损失来更好地保持图像的细节。
Feature-level semantic-guided methods. 与损失级语义引导方法相比,特征级语义引导法侧重于从语义分割网络中提取中间特征,并在特征表示空间中引入语义先验与图像特征相结合。在图像恢复[23]、图像去噪[24]、图像超分辨率[40]、微光图像增强[8]、深度估计[10,19]方面也进行了类似的工作。
现有的语义引导方法由于语义先验和原始任务之间的交互不足而受到限制。因此,我们提出了一个语义感知框架来充分利用损失级和特征级的语义信息,包括两个语义引导的损失和一个语义认知嵌入模块。具体而言,与LLIE任务[8,26,58]中的语义引导方法相比,我们的SKF作为一个通用框架具有吸引力。
3. Method
3.1. Motivation and Overview
照明增强是通过调整照明、消除噪声和恢复丢失的细节,使曝光不足的图像看起来更好的过程。语义先验可以为提高增强性能提供丰富的信息。具体来说,语义先验可以帮助将现有的LLIE方法重新表述为区域感知增强框架。特别是新模型将以简单的方式模糊平滑区域上的噪声,比如天空,而要注意细节丰富的区域,比如室内场景。此外,结合语义先验,可以很好地保持增强图像的颜色一致性。缺乏语义先验的网络很容易偏离区域的原始色调[22]。然而,现有的微光增强方法忽略了语义信息的重要性,因此能力有限。
在本文中,我们提出了一种新的SKF,联合优化图像特征,保持区域颜色一致性,提高图像质量。如图2所示,语义先验由SKB提供,并通过三个关键组件集成到LLIE任务中:SE模块、SCH丢失和SA丢失。

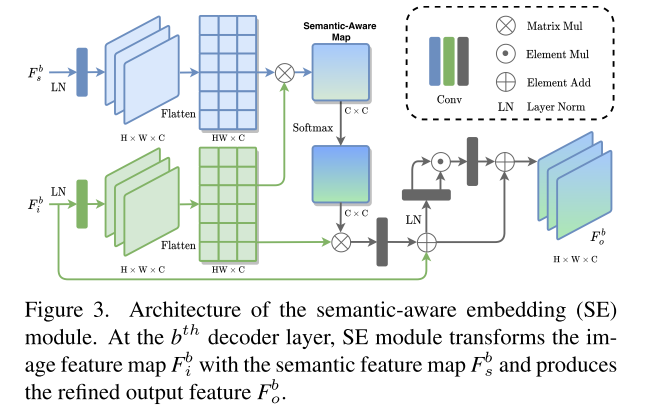
3.2. Semantic-Aware Embedding Module
当借助语义先验来细化图像特征时,另一个挑战应该特别考虑的是两个来源之间的差异。为了缓解这个问题,我们提出了SE模块来细化图像特征图,如图所示。3。SE模块就像分割网和增强网之间的桥梁(见图2),在两个异构任务之间建立连接。
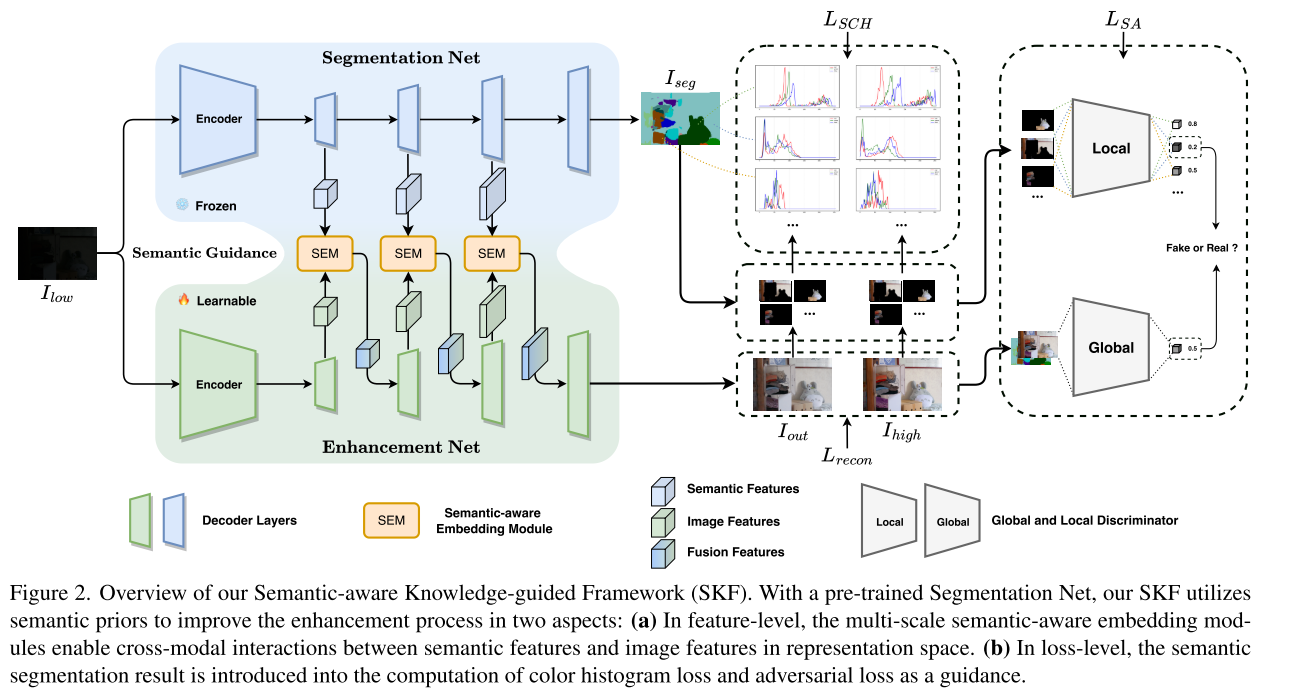
在我们的框架中,由于其卓越的性能,我们选择HRNet[38]作为SKB,并进行了一些特定任务的修改。除了语义图,我们还利用表示头之前的输出特征作为多尺度语义先验。为了进一步说明,图2中显示了三个SE模块。因此,我们采用三个空间分辨率(H/24−b,W/24−b)的三个语义/图像特征(Fb s/Fb i,b=0,1,2),其中H和W是输入图像的高度和宽度。SE模块在Fb s和Fb i之间执行逐像素交互,并给出下面提供了学习过程的细节。

3.3. Semantic-Guided Color Histogram Loss
颜色直方图承载了关键的底层图像统计信息,对于学习颜色表示是有益的。DCC-Net[55]使用具有亲和矩阵的PCE模块来匹配特征级别的颜色直方图和内容,从而保持增强图像的颜色一致性。然而,颜色直方图描述了全局统计信息,消除了各种实例之间颜色特征的差异。因此,我们提出了一种直观的方法来实现局部颜色调整,即语义引导的颜色直方图(SCH)损失,如图所示。2。它专注于调整每个实例的颜色直方图,从而保留更详细的颜色信息。
首先使用语义图将增强结果划分为具有不同实例标签的图像块。每个块都包括一个具有相同标签的实例。因此,生成补丁的过程定义如下:

3.4. Semantic-Guided Adversarial Loss
全局和局部鉴别器用于鼓励在图像修复任务中获得更逼真的结果[14,25]。EnlightenGAN[16]也采用了这一想法,但局部补丁是随机选择的,而不是关注假区域。因此,我们引入语义信息来引导鉴别器关注有趣的区域。为了实现这一点,我们通过第3.3节中提到的分割图Iseg和图像块P′分别进一步细化全局和局部对抗性损失函数。最后,我们提出了语义引导对抗性(SA)损失。
对于局部对抗性损失,我们首先使用精化的补丁组P′作为输出Iout的候选假补丁。然后,我们比较了图像块的判别结果,在P’中,最差的补丁最有可能是“假的”,可以选择它来更新鉴别器和生成器的参数。

4. Experiments
4.1. Experimental Settings
数据集。我们在来自不同场景的几个数据集上评估了所提出的框架,包括LOL[43]、LOL-v2[49]、MEF[31]、LIME[12]、NPE[39]和DICM[21]。LOL数据集[43]是一个真实捕获的数据集,包括485对用于训练的低/正常光图像对和15对用于测试的图像对。LOL-v2数据集[49]是LOL-v2的真实部分,它比LOL更大、更多样,包括689对用于训练的低/正常光对和100对用于测试的光对。MEF(17幅)、LIME(10幅)、NPE(85幅)和DICM(64幅)是真实捕获的数据集,包括未配对的图像。
指标。为了评估使用和不使用SKF的不同LLIE方法的性能,我们使用了全参考和非参考图像质量评估指标。对于LOL/LOL-v2数据集,峰值信噪比(PSNR)、结构相似性(SSIM)[42]、学习感知图像补丁相似性(LPIPS)[52]、自然图像质量评估员。对于没有配对数据的MEF、LIME、NPE和DICM数据集,由于没有基本事实,因此仅使用NIQE。
比较方法。为了验证我们设计的有效性,我们将我们的方法与LLIE的丰富SOTA方法进行了比较,包括LIME[13]、RetinexNet[43]、KinD[54]、DRBN[48]、KinD[5]、Zero DCE[11]、ISSR[8]、EnlightGAN[16]、MIRNet[51]、HWMNet[7]、SNR LLIE Net[46]、LLFlow[41]。为了忠实地证明我们的方法的优越性,我们合理地选择了几种方法作为基线网络。具体来说,既选择了最具代表性的方法,包括RetinexNet、KinD和KinD,也选择了最新的三种方法,包括HWMNet、SNR-LLIE-Net和LLFlow。因此,我们的方法表示为RetinexNetSKF、KinD SKF、DRBN-SKF、KinD-SKF、HWMNetSKF、SNR LLIE Net SKF、LLFlow-S-SKF和LLFlow LSKF(分别为LLFlow的小版本和大版本)。
实施细节。我们在NVIDIA 3090 GPU和NVIDIA A100 GPU上进行了实验,这两个GPU基于相同训练设置的基线网络的发布代码。具体来说,只有Retinex SKF、KinD SKF和KinD-SKF的最后一个子网使用SCH损失和SA损失进行训练,而其他子网使用原始损失函数进行训练。此外,我们不将SA损失应用于LLFlow,因为在训练阶段没有增强的输出。此外,SE模块合理地位于所有基线网络的解码器中
4.2. Quantitative Evaluation
LOL和LOL-v2数据集的定量结果。评价结果如表1所示。我们可以观察到,与每种基线方法相比,我们的SKF实现了一致且显著的性能增益。具体而言,我们的SKF在LOL/LOL-v2数据集上分别提供了1.750 dB/1.611 dB的平均改进,这是通过引入抑制噪声和伪影以及保持颜色一致性的能力来实现的。值得注意的是,我们的LLFlow-L-SKF在LOL/LOL-v2数据集上获得了26.798 dB/28.451 dB的PSNR值,建立了一个新的SOTA。此外,SSIM值也实现了类似的性能。我们的SKF在LOL/LOL-v2数据集上产生了更好的SSIM值,平均值为0.041/0.037,这表明我们的SKF有助于基线方法恢复亮度和对比度,并保留详细的结构信息。此外,我们的SKF提供的LPIPS和NIQE的实质性增益合理地表明,通过从我们的设计中引入语义先验,人类的直觉更加匹配。
MEF、LIME、NPE和DICM数据集的定量结果。MEF、LIME、NPE和DICM数据集的评估结果如表2所示。一般来说,除了DRBN-SKF和HWMNet SKF的三种较差情况外,每种SKF方法在所有六个数据集上都获得了比基线更好的NIQE结果。RetinexNet SKF在MEF数据集上的NIQE为3.632,表现最好,而KinD-SKF在其他五个数据集上表现最好。总体而言,值得注意的是,我们的SKF所有方法和数据集的NIQE平均增益为0.519。更好的NIQE表明,使用我们的SKF的方法可以生成具有更自然纹理的图像,并且在恢复弱光图像时变得更有效。