文章目录
- 系统性能监控
- 相关命令
- lscpu
- top
- free
- htop
- dstat
- glances
- iftop
- iptraf
- nethogs
- 监控软件
- Prometheus
- 安装、使用
- 将promethues做成服务
- 监控其他机器
- exporter
- grafana
- 配置、使用
- 密码忘记重置
系统性能监控
相关命令
lscpu
lscpu 是一个 Linux 命令,用于显示关于 CPU(中央处理器)架构和信息的详细信息。它提供了关于 CPU 型号、核心数量、线程数量、缓存大小和其他与 CPU 相关的特性的信息。以下是 lscpu 命令输出的一些常见信息及其解释:
-
Architecture(架构):显示操作系统所运行的 CPU 架构,如 x86、x86_64、ARM 等。
-
CPU(s)(CPU 数量):显示系统中的物理 CPU 数量。
-
Thread(s) per core(每核线程数):显示每个 CPU 核心支持的线程数。如果 CPU 支持超线程技术,该值将大于 1,表示每个物理核心可以同时运行多个线程。
-
Core(s) per socket(每个插槽核心数):显示每个物理 CPU 插槽中的核心数。
-
Socket(s)(插槽数量):显示系统中的物理 CPU 插槽数量。
-
Model name(型号名称):显示 CPU 的型号和描述信息。
-
CPU MHz(CPU 主频):显示 CPU 的主频(运行频率)。
-
CPU max MHz(CPU 最大主频):显示 CPU 的最大主频。
-
CPU min MHz(CPU 最小主频):显示 CPU 的最小主频。
-
L1d cache(一级数据缓存):显示 CPU 的一级数据缓存大小。
-
L1i cache(一级指令缓存):显示 CPU 的一级指令缓存大小。
-
L2 cache(二级缓存):显示 CPU 的二级缓存大小。
-
L3 cache(三级缓存):显示 CPU 的三级缓存大小。
-
Virtualization(虚拟化支持):显示 CPU 是否支持虚拟化技术。
-
Flags(特性标志):显示 CPU 支持的特性标志,如 SSE(流式 SIMD 扩展)、AVX(高级矢量扩展)、AES(高级加密标准)等。
以上是 lscpu 命令输出中常见的一些信息,它们提供了有关系统中 CPU 架构和特性的详细信息。可以使用 lscpu 命令来查看您的系统上 CPU 的相关信息,以了解 CPU 的配置和功能。
top
top 是一个常用的终端命令,用于实时监视和显示系统中运行的进程和系统性能指标。它可以让您查看正在运行的进程的资源使用情况,例如 CPU 占用率、内存占用率、交换空间使用情况等。以下是 top 命令输出的一些常见信息及其解释:
-
第一行:整体系统性能指标
top:显示当前时间和运行时间。up:系统的运行时间。users:当前登录用户数量。load average:过去 1 分钟、5 分钟和 15 分钟的平均负载。
-
第二行:进程统计信息
Tasks:当前运行的进程数量。total:总进程数。running:正在运行的进程数。sleeping:休眠(等待)的进程数。stopped:停止的进程数。zombie:僵尸进程数。
-
第三行:CPU 占用率信息
%Cpu(s):CPU 使用率统计。us:用户空间程序占用 CPU 的百分比。sy:系统空间程序占用 CPU 的百分比。ni:以较低优先级运行的用户空间程序占用 CPU 的百分比。id:空闲 CPU 的百分比。wa:等待 I/O 的 CPU 时间百分比。hi:硬件中断(Hardware IRQ)占用 CPU 的百分比。si:软件中断(Software IRQ)占用 CPU 的百分比。
-
进程列表:显示当前运行的进程列表
PID:进程 ID。USER:进程的所属用户。PR:进程的优先级。NI:进程的优先级修改值。VIRT:进程使用的虚拟内存大小。RES:进程使用的物理内存大小(常驻内存)。SHR:进程使用的共享内存大小。S:进程的状态(R: 运行, S: 睡眠, Z: 僵尸进程等)。%CPU:进程占用 CPU 的百分比。%MEM:进程占用内存的百分比。TIME+:进程累计的 CPU 使用时间。COMMAND:进程的命令行。
top 命令会实时更新并显示系统的运行情况,您可以使用键盘上的不同快捷键来执行特定操作,例如杀死进程、改变排序方式、切换显示模式等。要退出 top命令,可以按下 q 键。通过使用 top 命令,您可以及时监测系统的性能指标和进程活动,以便快速了解系统的状态和资源使用情况。
`load average(系统平均负载)
系统平均负载是指过去的1分钟、5分钟、15分组,处于可运行(可运行或就绪的状态)或不可中断状态(阻塞的状态)的进程的平均数量。这是进程的平均数量,用来判断系统是否繁忙的指标,假如我们的系统是1个cpu核心,这个值超过1就说明系统比较繁忙了,但是不超过5说明还没有达到最忙的时候,0~5以内,说明系统还可以接受,只要超过1就比较忙了。
假如有8个核心,这个值就是8,超过8就比较忙,但是可以承受的总值是5*8=40.
系
交互性命令:
在 top 命令的交互界面中,可以使用多个键盘快捷键执行不同的操作。以下是一些常见的 top 命令的交互性命令:
-
切换排序方式:
M:按内存占用排序。P:按 CPU 占用排序。T:按时间/累计 CPU 排序。
-
进程操作:
k:杀死选中的进程。r:修改选中进程的优先级。
-
显示模式切换:
1:显示全局汇总信息。2:显示每个 CPU 核心的详细信息。3:显示每个任务(进程)的详细信息。
-
刷新频率控制:
s:改变刷新间隔时间。d或D:改变刷新间隔时间为动态调整模式。
-
过滤器和搜索:
o:添加或修改显示字段。/:进入进程搜索模式,可输入关键字搜索进程。=:清除进程搜索过滤器。
-
系统操作:
H:在线程和进程之间切换显示。i:显示内核和 I/O 统计信息。b:显示中断统计信息。
-
退出
top:q:退出top命令。
这只是一些常见的 top 命令的交互性命令示例,实际上 top 命令提供了更多的功能和选项。可以在 top 命令的交互界面中按下 h 键获取更详细的帮助信息,其中包含了所有可用的快捷键和操作说明。
实例
[root@ydh nginx]# top -d 3 -n 1
-d 3:表示刷新间隔为 3 秒。这将使top命令每隔 3 秒更新一次显示内容。-n 1:表示只执行一次top命令后退出。这将使top命令只显示一次系统状态和进程信息,然后立即退出。
top -d 3 -n 1 命令将执行一次 top 命令并在终端显示系统的实时状态和进程信息,刷新间隔为 3 秒,然后在显示一次后立即退出。这样可以获取系统状态的一个快照而不会持续监视和更新。
free
free 是一个常用的 Linux 命令,用于显示系统中的内存使用情况。它提供了物理内存(RAM)和交换空间(Swap)的相关统计信息。以下是 free 命令输出的详细解释:
-
第一行:系统整体内存使用情况
-
total:物理内存总量。 -
used:应用程序已使用的物理内存量。 -
free:可用的物理内存量。 -
shared:被共享使用的物理内存量(多个进程共享的内存)。 -
buffers:被缓存的文件数据的物理内存量(内存–》buffer–》磁盘)(减少IO的次数)。 -
cached:被缓存的文件系统的物理内存量(磁盘–》cached–》内存)(可以将数据先写道cached,提升速度)。 -
total = used + free + shared +buff/cahce
-
available=free + buff/cached里的为使用完的空间:下一次进程可以使用的内存空间
-
-
第二行:内存详细信息
Mem:物理内存统计信息。total:物理内存总量。used:已使用的物理内存量。free:可用的物理内存量。shared:被共享使用的物理内存量。buffers/cache:被缓存的文件数据和文件系统的物理内存量。available:可用的物理内存量,考虑了系统保留的内存和缓存的影响。
-
第三行:交换空间(Swap)信息
Swap:交换空间(Swap)统计信息。total:交换空间总量。used:已使用的交换空间量。free:可用的交换空间量。
free 命令的输出以字节(Bytes)为单位,但通常也以更友好的格式显示,如千字节(Kilobytes)、兆字节(Megabytes)或千兆字节(Gigabytes)。
参数:
-b:以字节(Bytes)为单位显示内存大小。-k:以千字节(Kilobytes)为单位显示内存大小(默认选项)。-m:以兆字节(Megabytes)为单位显示内存大小。-g:以千兆字节(Gigabytes)为单位显示内存大小。-h:以人类可读的格式显示内存大小(自动选择合适的单位)。-s <delay>:指定刷新间隔的时间间隔(以秒为单位)。-c <count>:指定输出的次数后退出。-t:在输出中显示总计行。
可以通过在终端中运行 man free 命令来查看完整的 free 命令的参数列表和详细说明。
注意:
交换分区是从磁盘里划分出来的一块空间临时做内存使用的,当物理内存不足的时候,将不活跃的进程交换到swap分区里(尽量不要使用交换分区,因为速度慢)
实例:
[root@ydh nginx]# cat /proc/sys/vm/swappiness
30
当物理内存只剩下30%的时候空闲的时候,开始使用交换分区
[root@ydh nginx]# echo 0 >/proc/sys/vm/swappiness
[root@ydh nginx]# cat /proc/sys/vm/swappiness
0htop
htop 是一个交互式的系统监视工具,功能类似于经典的 top 命令,但提供了更丰富的功能和更友好的用户界面。以下是对 htop 命令的详细解析:
-
主要显示区域:
- CPU 利用率:显示每个 CPU 核心的使用率和总体 CPU 使用率。
- 内存使用情况:显示物理内存和交换空间的使用情况。
- 任务列表:显示系统上运行的进程和线程的列表,按 CPU 或内存使用排序。
-
导航和交互操作:
- 使用方向键或鼠标滚轮可以滚动浏览任务列表。
- 使用 F1 到 F10 键可以访问不同的功能键菜单,提供了各种系统监视和操作选项。
- 使用键盘上的数字键可以快速切换不同的排序方式(如按 CPU 使用率、内存使用率等)。
- 使用键盘上的快捷键(如 F9)可以对选定的进程执行操作,如终止进程、优先级调整等。
-
颜色编码和标识:
- 不同颜色的文本和背景用于标识不同类型的进程和任务状态,如运行中、睡眠中、僵尸进程等。
- 显示了进程的 CPU 使用率、内存使用量、虚拟内存、线程数量等关键信息。
-
其他功能:
- 支持在任务列表中搜索进程。
- 提供了实时的系统负载图表,显示 CPU 和内存的实时使用情况。
- 可以显示进程树,显示进程之间的父子关系。
- 支持在任务列表中设置进程筛选器,以过滤显示特定的进程。
htop 提供了一个直观且交互式的界面,使您能够更方便地监视系统状态、查看进程信息和执行操作。它对于系统管理员和开发人员来说是一个非常有用的工具,可以帮助他们更好地了解和管理系统。
dstat
dstat 是一个全能的系统资源监视工具,它提供了丰富的统计数据和信息,并以可配置的格式输出。以下是对 dstat 的数据展示解析:
-
CPU 相关数据:
- 用户空间 CPU 使用率(usr):表示用户进程所使用的 CPU 时间的百分比。
- 系统 CPU 使用率(sys):表示内核进程所使用的 CPU 时间的百分比。
- 等待 I/O 的 CPU 使用率(iowait):表示 CPU 等待 I/O 完成的时间的百分比。
- 硬中断的 CPU 使用率(irq):表示处理硬件中断的 CPU 时间的百分比。
- 软中断的 CPU 使用率(soft):表示处理软件中断的 CPU 时间的百分比。
- CPU 空闲率(idle):表示 CPU 空闲时间的百分比。
-
内存相关数据:
- 已使用内存量(used):表示系统当前已使用的内存量。
- 空闲内存量(free):表示系统当前空闲的内存量。
- 缓存使用量(buff):表示系统当前用于文件缓存的内存量。
- 缓冲区使用量(cache):表示系统当前用于缓冲 I/O 操作的内存量。
- 可用内存量(available):表示系统当前可用的内存量。
-
磁盘相关数据:
- 磁盘读取速率(read):表示磁盘读取数据的速率。
- 磁盘写入速率(writ):表示磁盘写入数据的速率。
- 磁盘读取操作数(read_ops):表示磁盘读取操作的数量。
- 磁盘写入操作数(writ_ops):表示磁盘写入操作的数量。
-
网络相关数据:
- 网络传入数据速率(recv):表示网络接收数据的速率。
- 网络传出数据速率(send):表示网络发送数据的速率。
- 网络传入数据包数(recv_pkg):表示网络接收的数据包数量。
- 网络传出数据包数(send_pkg):表示网络发送的数据包数量。
-
进程相关数据:
- 运行进程数(procs):表示系统当前运行的进程数。
- 阻塞进程数(blocked):表示当前阻塞状态的进程数。
- 睡眠进程数(sleeping):表示当前睡眠状态的进程数。
- 线程数(thread):表示当前系统中的线程数。
dstat 的输出可以根据用户需求进行自定义配置,并且支持通过命令行参数选择要显示的数据类型、采样间隔和显示持续时间等。通过监视和分析 dstat 的输出数据,可以获得对系统资源使用情况的全面了解,以便进行性能优化、故障排查和资源规划等操作。
参数:
dstat 是一个功能强大的系统资源监视工具,提供了许多参数和选项,以满足用户对系统性能数据的不同需求。以下是 dstat 常用参数的详细介绍:
-
-c, --cpu:显示 CPU 相关的统计数据。usr:用户空间 CPU 使用率。sys:系统 CPU 使用率。idl:CPU 空闲率。wai:等待 I/O 的 CPU 使用率。hiq:硬中断的 CPU 使用率。siq:软中断的 CPU 使用率。
-
-d, --disk:显示磁盘相关的统计数据。read:磁盘读取速率。writ:磁盘写入速率。read_ops:磁盘读取操作数。writ_ops:磁盘写入操作数。
-
-n, --net:显示网络相关的统计数据。recv:网络传入数据速率。send:网络传出数据速率。recv_pkg:网络传入数据包数。send_pkg:网络传出数据包数。
-
-m, --mem:显示内存相关的统计数据。used:已使用内存量。free:空闲内存量。buff:缓存使用量。cach:缓冲区使用量。free:可用内存量。
-
-p, --proc:显示进程相关的统计数据。run:运行进程数。blk:阻塞进程数。slp:睡眠进程数。thd:线程数。
-
-s, --swap:显示交换空间相关的统计数据。used:已使用交换空间量。free:空闲交换空间量。
-
-g, --page:显示页面交换相关的统计数据。in:页面交换入速率。out:页面交换出速率。
-
-y, --sys:显示系统相关的统计数据。intr:每秒中断数。ctxt:每秒上下文切换数。
-
-l, --load:显示系统负载平均值。 -
-r, --io:显示系统 I/O 相关的统计数据。read:每秒读取字节数。writ:每秒写入字节数。
-
-N, --fs:显示文件系统相关的统计数据。read:文件系统读取速率。writ:文件系统写入速率。used:已使用的文件系统空间。free:可用的文件系统空间。
-
`-S,
–sockets:显示套接字相关的统计数据。 - total:总套接字数。 - udp:UDP 套接字数。 - tcp:TCP 套接字数。 - raw`:RAW 套接字数。
还有其他一些参数和选项可以与上述参数组合使用,以进一步定制 dstat 的输出,例如:
-a:显示所有可用的统计数据。-f:显示文件系统统计数据。-T:显示时间戳。
通过在命令行中使用这些参数和选项,可以根据需要监视和分析系统资源的各个方面。可以通过 man dstat 命令查看完整的参数和选项列表以及其详细说明。
glances
Glances是一个跨平台的系统监视工具,提供了实时的系统状态和性能指标的全面视图。下面是Glances的一些主要特点和功能:
-
实时监视:Glances提供实时的系统监视,可以即时查看CPU、内存、磁盘、网络、传感器等方面的数据。
-
用户友好的界面:Glances采用交互式终端界面,通过命令行展示信息,并以颜色和图表的形式直观地呈现数据。
-
多平台支持:Glances可以在Linux、Windows、MacOS等多个操作系统上运行,并提供相应的可执行文件和软件包。
-
详细的系统信息:Glances显示了关于系统的详细信息,包括操作系统类型、内核版本、主机名等。
-
多项性能指标:Glances提供了广泛的性能指标,包括CPU使用率、内存使用情况、磁盘读写速度、网络流量、进程数量等。
-
进程管理:Glances允许查看和管理运行中的进程,包括CPU和内存占用最高的进程。
-
警报和通知:Glances可以配置警报和通知,以便在达到特定阈值时通知用户。
-
扩展性:Glances支持插件系统,可以通过安装额外的插件来扩展其功能,例如监视数据库、Web服务器等。
总体而言,Glances是一个功能强大且易于使用的系统监视工具,可以为用户提供全面的系统状态和性能数据,并帮助用户监控系统健康、排查问题和优化性能。
[root@ydh ~]# yum install glances -y
进入
[root@ydh ~]# iptraf-ng
按q退出
iftop
iftop是一款开源的命令行工具,用于实时监视网络流量。它提供了一个直观的界面,显示正在进行的网络连接以及每个连接的流量信息。以下是iftop的一些主要特点和功能:
-
实时流量监视:iftop以实时的方式监视网络流量,显示当前网络连接的流量情况,包括传入流量和传出流量。
-
可视化界面:iftop以交互式的方式展示网络连接和流量信息,使用类似于top命令的界面,易于理解和操作。
-
按连接排序:iftop根据流量大小对连接进行排序,使用户可以快速找到产生最多流量的连接。
-
IP和端口信息:iftop显示与每个连接相关的IP地址和端口号,帮助用户识别网络流量的来源和目标。
-
过滤功能:iftop支持根据IP地址、端口号和网络接口等条件进行流量过滤,以便用户关注特定的网络流量。
-
网络带宽图表:iftop提供带宽使用情况的实时图表,使用户可以直观地了解网络的使用情况和趋势。
-
统计信息:iftop提供有关总体流量、平均流量和流量峰值的统计信息,帮助用户评估网络性能和负载。
iftop是一个强大的工具,特别适用于需要实时监视网络流量的情况,如网络故障排除、带宽优化和网络安全监控等。通过iftop,用户可以迅速获取关于网络流量的详细信息,并对网络连接进行分析和管理。
[root@ydh ~]# yum install iftop -y
iptraf
iptraf是一个实时网络流量监视工具,用于在Linux系统上监视网络接口的活动。它提供了一个交互式的界面,显示网络接口的统计信息、连接状态、端口信息等。以下是iptraf的一些主要特点和功能:
-
实时流量监视:iptraf以实时的方式监视网络接口的流量情况,包括传入流量和传出流量。
-
多种统计信息:iptraf提供了各种统计信息,如总流量、每秒流量、传输速率、错误包数量等,以便用户了解网络接口的使用情况。
-
连接状态监视:iptraf可以显示当前活动的连接状态,包括TCP连接和UDP连接,以及连接的源IP地址和目标IP地址。
-
端口监视:iptraf可以监视特定端口的活动情况,包括连接数量、数据传输量等。
-
按协议过滤:iptraf支持按照不同的网络协议进行过滤,如TCP、UDP、ICMP等,以便用户查看特定协议的流量情况。
-
日志功能:iptraf可以将监视的数据记录到日志文件中,方便后续分析和审查。
-
交互式界面:iptraf提供一个交互式的终端界面,允许用户通过按键或菜单选择来查看不同的统计信息和设置选项。
iptraf是一个功能丰富且易于使用的网络流量监视工具,适用于网络管理人员、系统管理员和安全分析师等对网络流量进行实时监视和分析的用户。它可以帮助用户监控网络接口的使用情况、识别潜在的网络问题,并进行网络性能优化和故障排除。
[root@ydh ~]# yum install iptraf -y
nethogs
Nethogs是一款开源的命令行工具,用于实时监视网络接口的流量和进程。它可以显示当前正在使用网络带宽的进程及其相应的流量使用情况。以下是Nethogs的一些主要特点和功能:
-
实时流量监视:Nethogs以实时的方式监视网络接口的流量使用情况,显示当前正在使用带宽的进程及其相应的上传和下载流量。
-
进程识别:Nethogs能够识别每个网络连接对应的进程,并显示相关进程的PID、用户和执行路径。
-
流量分组:Nethogs按照进程进行流量分组,使用户可以快速了解每个进程消耗的带宽情况。
-
用户友好的界面:Nethogs提供一个交互式的终端界面,以表格形式展示进程、带宽和流量信息,易于理解和操作。
-
排序和过滤:Nethogs支持按照进程名称、PID、上传或下载流量进行排序和过滤,以便用户查找特定进程或关注特定类型的流量。
-
统计信息:Nethogs提供有关总体流量、平均流量和流量峰值的统计信息,帮助用户评估网络带宽的使用情况。
Nethogs是一个实用的工具,适用于需要实时监视网络带宽和了解流量消耗情况的场景。通过Nethogs,用户可以迅速发现网络中消耗带宽的进程,并根据需要进行优化和管理。
监控软件
- cacti
- nagios
- zabbix:集合cacti+nagios
- openfalcon
- Prometheus
Prometheus
是什么
Prometheus是一个开源的系统监控和告警工具,它最初由SoundCloud开发并于2012年开源。Prometheus的目标是收集和存储系统和服务的时间序列数据,并提供强大的查询语言和灵活的告警机制,以帮助用户监控其应用程序和基础设施的健康状况。
以下是Prometheus的一些重要特点和概念:
-
多维度数据模型:Prometheus采用多维度数据模型来描述时间序列数据。每个数据样本都由一个指标名称和一组键值对标签组成,用于区分不同的时间序列。这种模型非常适合动态标记的数据,例如系统资源使用情况、应用程序指标等。
-
灵活的查询语言:Prometheus提供了PromQL(Prometheus Query Language)用于查询和聚合时间序列数据。PromQL支持强大的表达式和函数,使用户能够执行复杂的查询和计算。
-
数据采集和存储:Prometheus通过使用自己的数据采集器(exporter)或与其他系统集成,从目标应用程序和基础设施中收集时间序列数据。数据存储在本地时间序列数据库中,并通过基于磁盘的块存储格式进行持久化。
-
动态发现和服务发现:Prometheus支持动态发现目标实例,可以自动发现和监控新的实例。它还与服务发现机制(如Kubernetes的服务发现)集成,以便自动发现和监控动态变化的服务。
-
告警和警报管理:Prometheus具有灵活的告警规则定义和警报通知机制。用户可以定义自定义告警规则,并通过电子邮件、Slack等方式接收警报通知。
-
可视化和仪表板:Prometheus提供了一个内置的基本图形化界面,用于数据可视化和监控仪表板。此外,Prometheus还支持与其他监控工具(如Grafana)进行集成,以创建更复杂和丰富的仪表板。
-
社区支持和生态系统:Prometheus拥有庞大的活跃社区,并且具有丰富的第三方工具和库的生态系统。用户可以通过使用这些工具和库来扩展和增强Prometheus的功能。
Prometheus是一个功能强大的系统监控和告警工具,具有灵活的数据模型、查询语言和告警机制。它被广泛应用于云原生环境、容器化应用程序和微服务架构中,帮助用户实时监控和调优他们的系统和服务的性能。
组成
安装、使用
解压
tar -xf prometheus-2.45.0.linux-amd64.tar.gz
改名
mv prometheus-2.45.0.linux-amd64 prometheus临时修改
PATH=/prom/prometheus:$PATH永久修改
vim /root/.bashrc 启动
nohup prometheus --config.file=/prom/prometheus/prometheus.yml &
查看是否运行
[root@prometheus prom]# ps aux|grep prometheus
root 2015 0.8 4.3 797792 42996 pts/0 Sl 11:53 0:00 prometheus --con
root 2025 0.0 0.0 112824 980 pts/0 S+ 11:54 0:00 grep --color=aut查看Prometheus监听的端口号
[root@prometheus prom]# netstat -anplut|grep prometheus
tcp6 0 0 :::9090 :::* LISTEN 2015/prometheus
tcp6 0 0 ::1:9090 ::1:34724 ESTABLISHED 2015/prometheus
tcp6 0 0 ::1:34724 ::1:9090 ESTABLISHED 2015/prometheus
关闭防火墙
[root@prometheus prom]# service firewalld stop
Redirecting to /bin/systemctl stop firewalld.service
[root@prometheus prom]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
看本机的http
http://192.168.2.22:9090/
将promethues做成服务
/usr/lib/systemd/system/创建prometheus.service文件
vim /usr/lib/systemd/system/prometheus.service
promethes.service文件里的代码
[Unit]
Description=prometheus
[Service]
ExecStart=/prom/prometheus/prometheus --config.file=/prom/prometheus/prometheus.yml
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
~
重新加载 systemd 的配置文件
[root@prometheus system]# systemctl daemon-reload
systemctl启动
[root@prometheus system]# systemctl start prometheus
查看进程是否启动,启动就代表prometheus.service配置成功了
注意:
第一次如果是用nohup启动的,不能用systemctl停止,需要用kill命令
nohup prometheus --config.file=/prom/prometheus/prometheus.yml &
监控其他机器
前提:被监控的机器需要将数据导出,安装好了exporter,同时知道机器的ip和端口号
/prom/prometheus/prometheus.yml文件,修改代码如下,增加被监控机器的信息。
- job_name: "prometheus"static_configs:- targets: ["localhost:9090"]- job_name: "origin"static_configs:- targets: ["192.168.2.24:8090"]- job_name: "LB1"static_configs:- targets: ["192.168.2.23:8090"]![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LHmxOASH-1689353423437)(C:\Users\asus\AppData\Roaming\Typora\typora-user-images\image-20230706155937291.png)]](https://img-blog.csdnimg.cn/8290698c89cf4a5ba38711309cfd63bf.png)
可以看到已经收集到指定机器的数据了
exporter
https://grafana.com/grafana/download下载地址
[root@prometheus grafana]# yum install -y https://dl.grafana.com/enterprise/release/grafana-enterprise-10.0.1-1.x86_64.rpm解压
[root@ydh ~]# tar xf node_exporter-1.6.0.linux-amd64.tar.gz
移位加改名
[root@ydh ~]# mv node_exporter-1.6.0.linux-amd64 /node_exporter
修改环境变量
[root@ydh node_exporter]# PATH=/node_exporter/:$PATH[root@ydh node_exporter]# vim /root/.bashrc #放到该文件下永久修改
运行
[root@ydh node_exporter]# nohup node_exporter --web.listen-address 0.0.0.0:8090 &
查看node是否运行
[root@ydh node_exporter]# ps aux|grep node
root 4955 0.1 0.5 724024 11032 pts/1 Sl 15:43 0:00 node_exporter --web.listen-address 0.0.0.0:8090
root 4985 0.0 0.0 112824 988 pts/1 S+ 15:43 0:00 grep --color=auto nodegrafana
Grafana是一个开源的监控、度量分析和可视化工具,通常与时序数据库(如Prometheus、InfluxDB等)搭配使用。Grafana的主要功能和优点包括:
-
强大的图表和面板可视化。Grafana提供多样化的图表类型,如折线图、柱状图、饼图、热力图等,可以灵活制作出各种监控面板。
-
支持多种数据源。Grafana支持接入Prometheus、Elasticsearch、InfluxDB、MySQL等多种时序数据库作为数据源。
-
自定义监控仪表板。用户可以通过简单的配置就能快速构建自定义的监控仪表盘,方便查看应用或系统的运行状态。
-
丰富的插件系统。Grafana有700多个插件,可以实现警报、访问控制、自动化任务等扩展功能。
-
多用户多权限管理。Grafana可以创建不同的组织和用户,以实现灵活的访问控制。
-
模板变量和钻取功能。模板变量可以实现交互式的监控面板;钻取功能可以快速探查和关联问题。
-
企业级特性。Grafana Enterprise版提供了高级特性,如高可用性、增强的安全控制、数据源权限控制等。
-
开源与免费。Grafana是一个成熟的开源软件,社区活跃,使用免费。也提供企业版的高级功能。
总体来说,Grafana是一个功能强大且易于使用的开源监控 visualize 工具,可以快速搭建出美观实用的监控系统,因此被广泛应用于各类监控场景。
配置、使用
下载
[root@prometheus ~]# yum install -y https://dl.grafana.com/enterprise/release/grafana-enterprise-10.0.1-1.x86_64.rpm
启动
[root@prometheus ~]# service grafana-server start
Starting grafana-server (via systemctl): [ 确定 ]
开机自启
[root@prometheus ~]# systemctl enable grafana-server
查看进程是否启动
[root@prometheus ~]# ps aux|grep grafana
查看端口号
[root@prometheus ~]# netstat -anplut|grep grafana
tcp 0 0 192.168.2.22:35768 34.120.177.193:443 ESTABLISHED 1529/grafana
tcp6 0 0 :::3000 :::* LISTEN 1529/grafana
监听端口号是3000
在浏览器上登录
http://192.168.2.22:3000/
默认的用户名和密码都是:admin
grafana配置数据源
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-COVr41rx-1689353423438)(D:\Snipaste\03【电脑截图软件】snipaste截图软件\Typora\运维\Prometheus\配置源.png)]](https://img-blog.csdnimg.cn/8eee6914aff6445eaad5599cc4bd1439.png)
grafana导入模版
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fKgWXiIQ-1689353423439)(D:\Snipaste\03【电脑截图软件】snipaste截图软件\Typora\运维\Prometheus\配置源.png)]](https://img-blog.csdnimg.cn/393c4dde41924341b96f8eef9e5b0800.png)
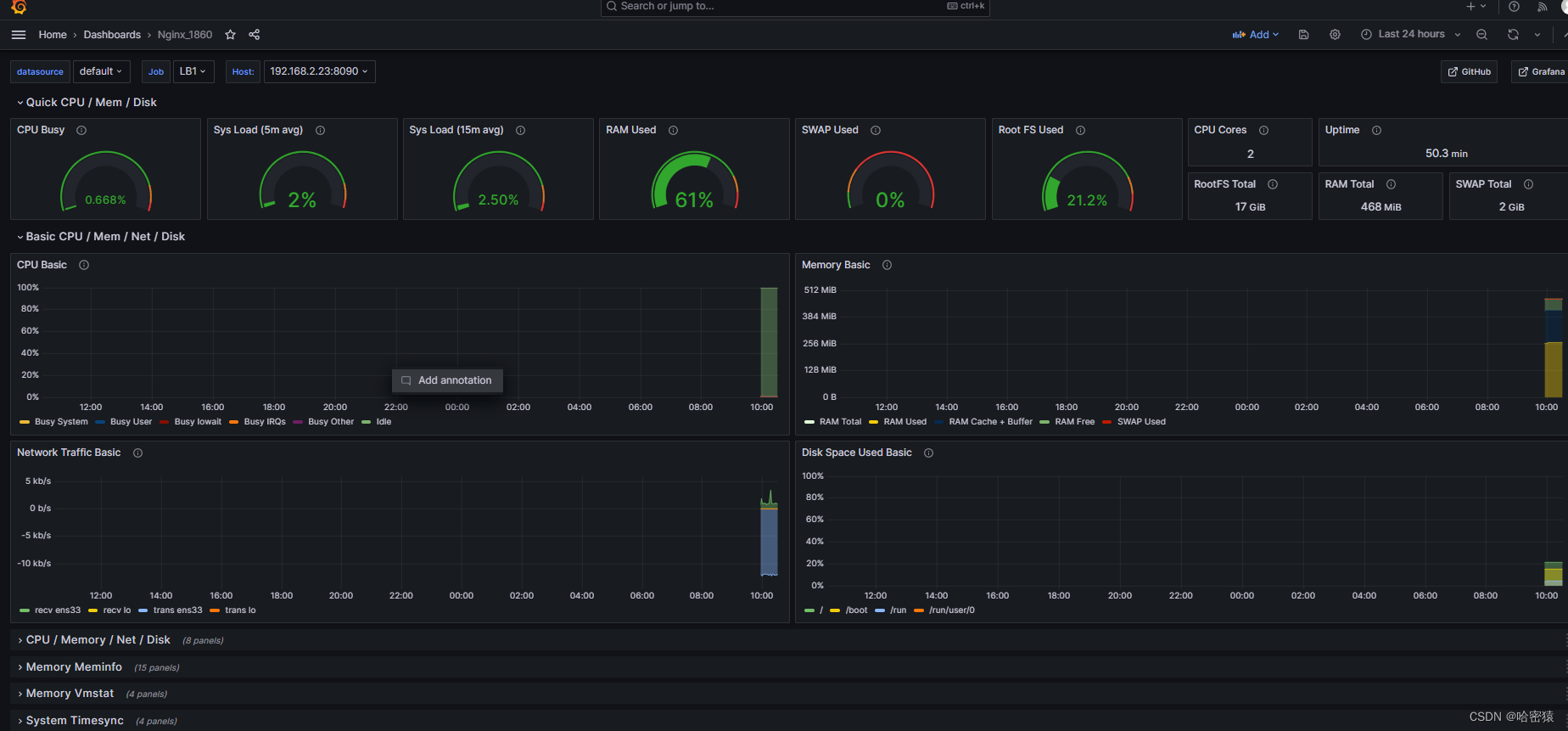
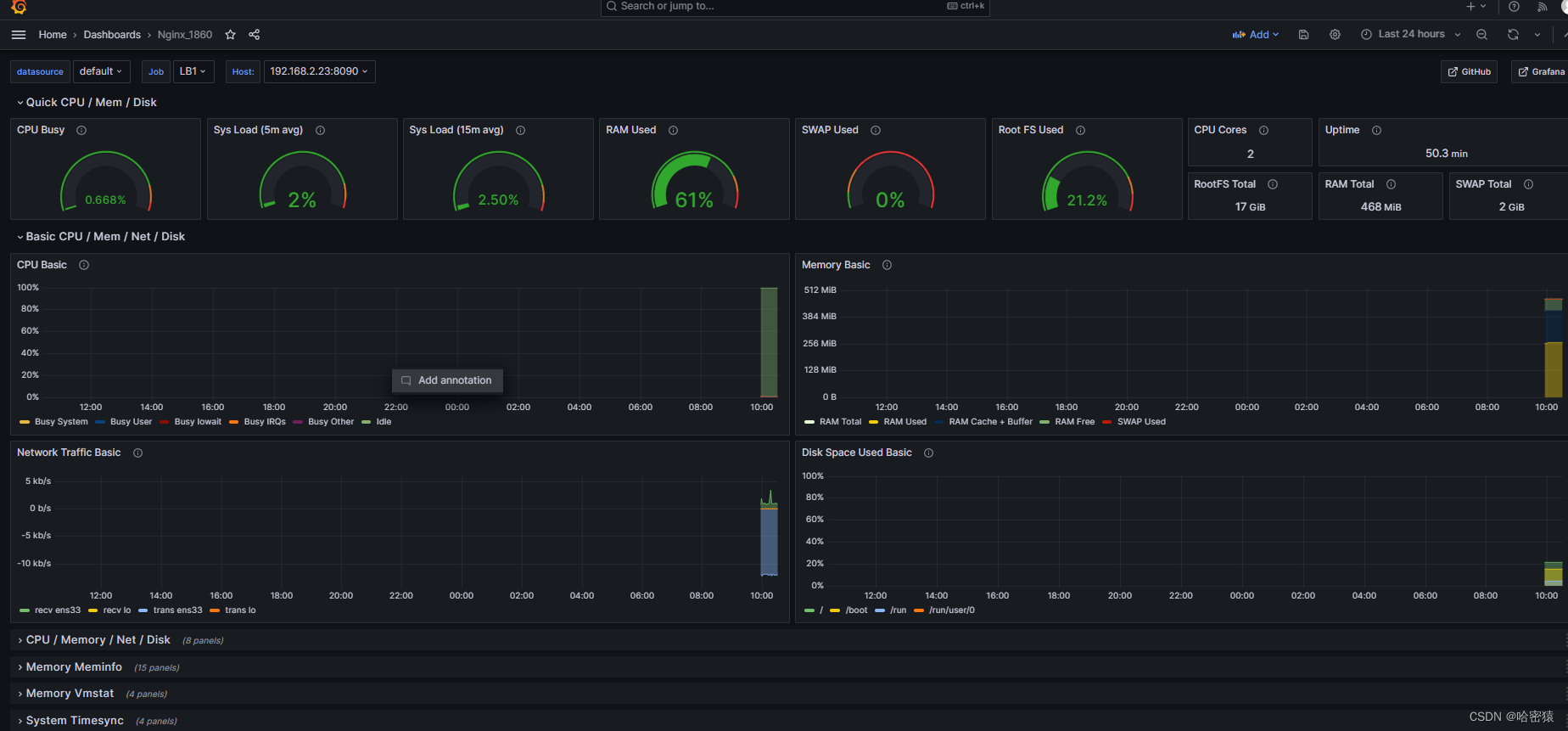
nginx的1860画面
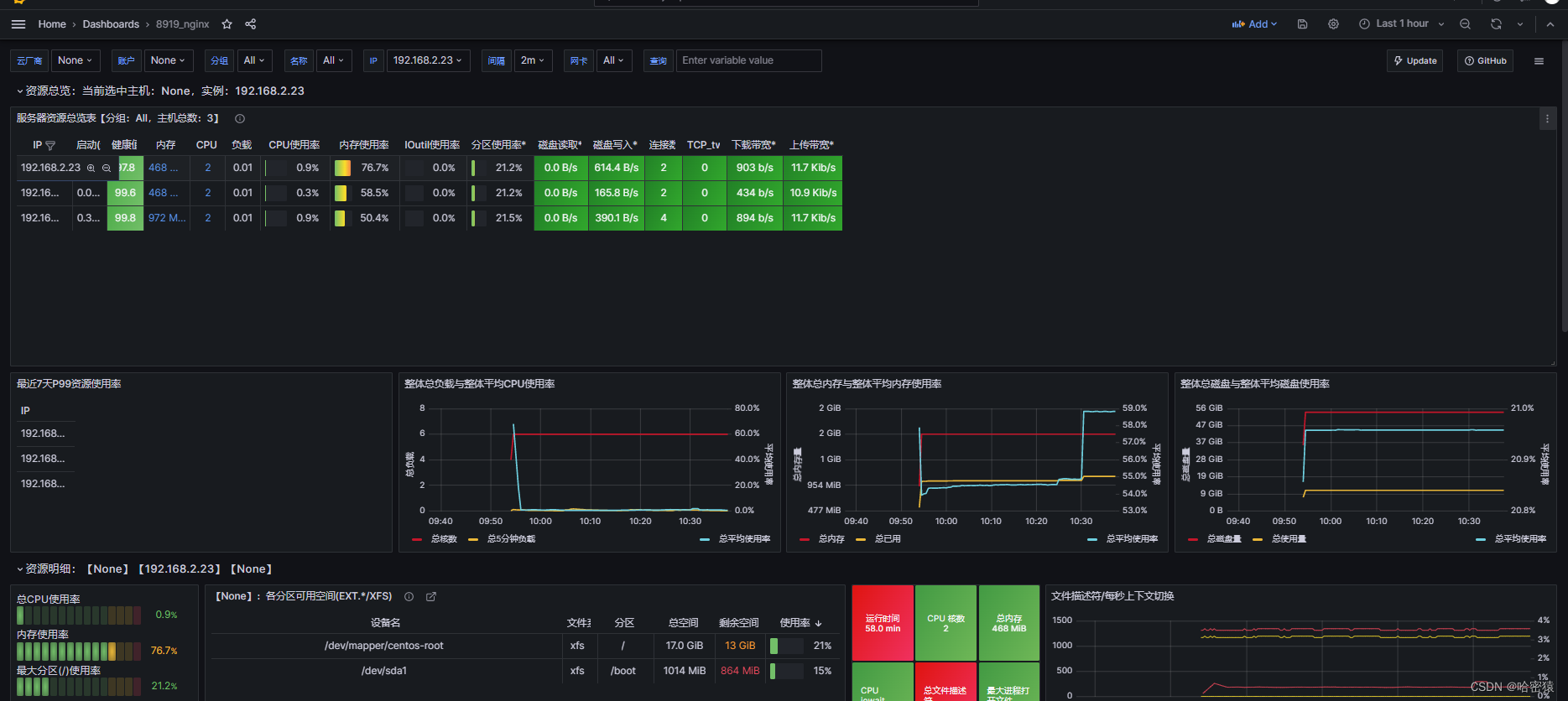
nginx的8919画面
密码忘记重置
grafana-cli admin reset-admin-password '新密码'
systemctl restart grafana-server
grafana-cli admin reset-admin-password 123456