数据库和表的操作
- 一、数据库的操作
- 1. 创建数据库
- 2. 字符集和校验规则
- (1)查看系统默认字符集以及校验规则
- (2)查看数据库支持的字符集
- (3)查看数据库支持的字符集校验规则
- (4)校验规则对数据库的影响
- 3. 操纵数据库
- (1)查看数据库
- (2)显示创建的语句
- (3)修改数据库
- 4. 数据库删除
- 5. 备份和恢复
- (1)备份数据库
- (2)还原
- (3)拓展
- 6. 查看连接情况
- 二、表的操作
- 1. 创建表
- 2. 查看表
- 3. 查看表结构
- 4. 修改表
- 5. 删除表
一、数据库的操作
1. 创建数据库
语法:CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification] ...]
create_specification:[DEFAULT] CHARACTER SET charset_name[DEFAULT] COLLATE collation_name
说明:
- 大写的表示关键字,mysql 不区分大小写,所以也可以用小写
- [] 是可选项
- CHARACTER SET: 指定数据库采用的字符集
- COLLATE: 指定数据库字符集的校验规则
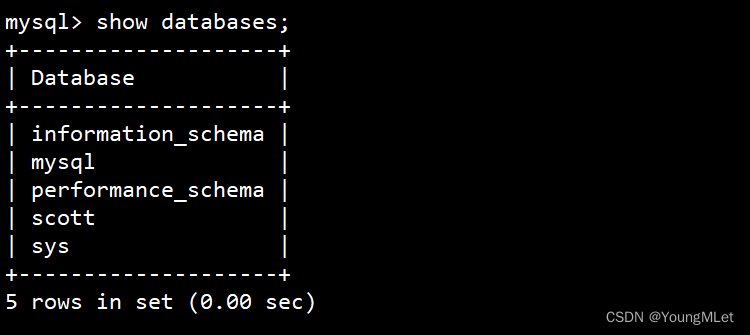
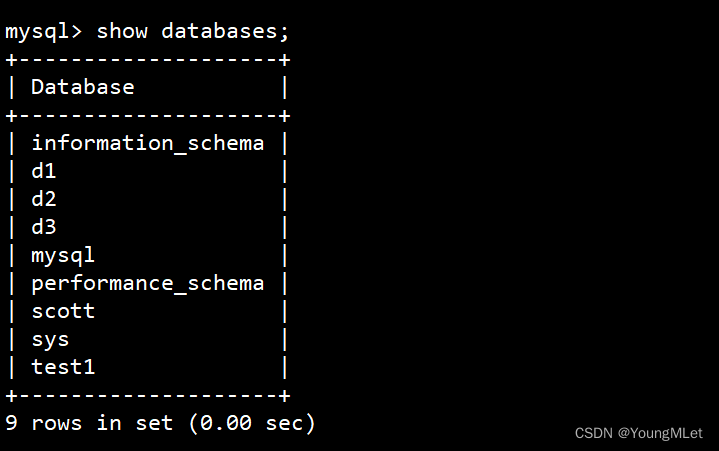
假设现在我们现在需要创建一个名为 d1 的数据库,首先我们先查看一下数据库,查看数据库:show databases;
下面开始创建 d1 数据库:create database d1;
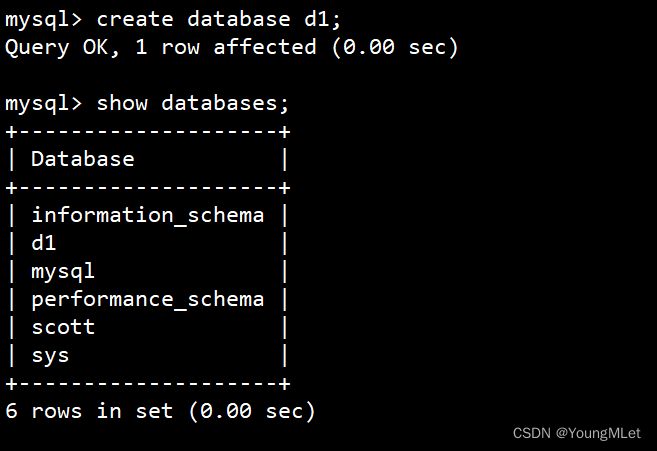
如上,d1 数据库就创建好了。
注意:当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则是:utf8_ general_ ci.
-
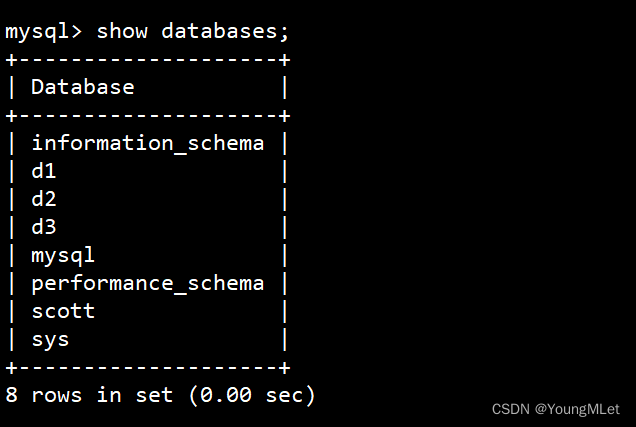
创建一个使用 utf8 字符集的 d2 数据库:
create database d2 charset=utf8; -
创建一个使用 utf8 字符集,并带校对规则的 d3 数据库:
create database d3 charset=utf8 collate utf8_general_ci;
创建好如下:
我们在前面也说过,创建一个数据库其实就是在 Linux 下创建一个目录,这里就不再重复介绍了。
2. 字符集和校验规则
当我们创建数据库的时候,有两个编码集:
- 数据库编码集 - - - 数据库未来存储数据所采用的编码集;
- 数据库校验集 - - - 支持数据库,进行字段比较使用的编码,本质也是一种读取数据库中数据所采用的编码格式;
所以数据库无论对数据做任何操作,都必须保证操作和编码必须是编码一致的。
字符集主要是控制用什么语言。比如 utf8 就可以使用中文。
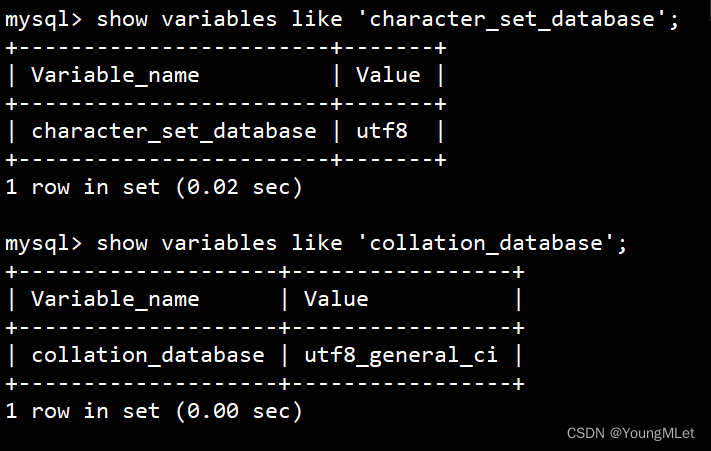
(1)查看系统默认字符集以及校验规则
show variables like 'character_set_database'; # 默认字符集show variables like 'collation_database'; # 检验规则
如下:
(2)查看数据库支持的字符集
show charset;
(3)查看数据库支持的字符集校验规则
show collation;
(4)校验规则对数据库的影响
- 不区分大小写
创建一个数据库,校验规则使用 utf8_ general_ ci (不区分大小写,即在检验的时候不严格匹配,不对大小写字母进行区分)
create database test1 collate utf8_general_ci;
随后我们需要使用这个数据库:use test1
然后我们为这个数据库创建一张表,并插入一些数据,创建表和插入的语法我们先不做介绍,后面再介绍;如下:
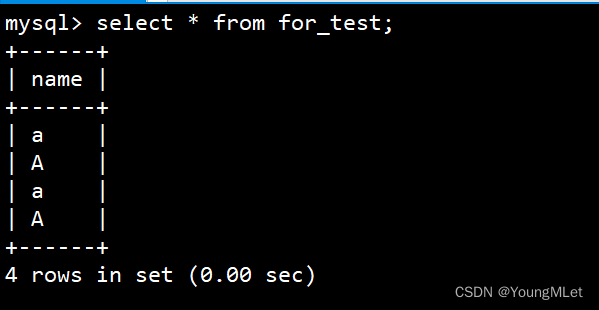
接下来我们对这个表的插入结果进行查看,注意,该表的校验方法是不进行区分大小写进行匹配的;所以我们先查看整个表的情况:select * from for_test;
接下来我们筛选出 a 这个字符:select * from for_test where name='a';
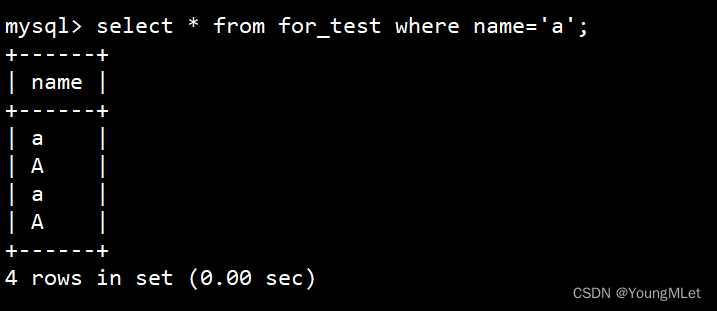
我们可以看到,数据库在匹配 a 这个字符的时候不进行大小写区分,无论大写还是小写都给我们显示出来了。
- 区分大小写
创建一个数据库,校验规则使用 utf8_ bin (区分大小写,校验时按照严格匹配的方式,区分大小写)
我们按照上面的方式进行创建,如下图:
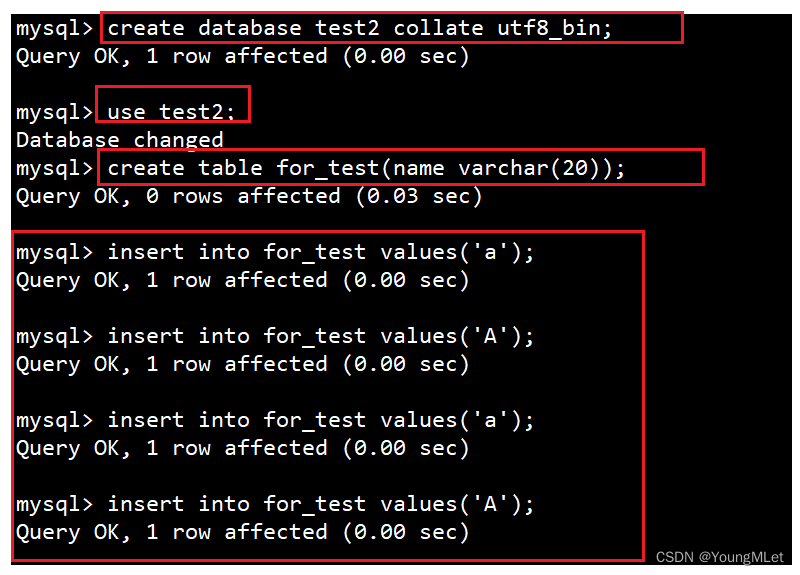
接下来我们查看该表的数据:
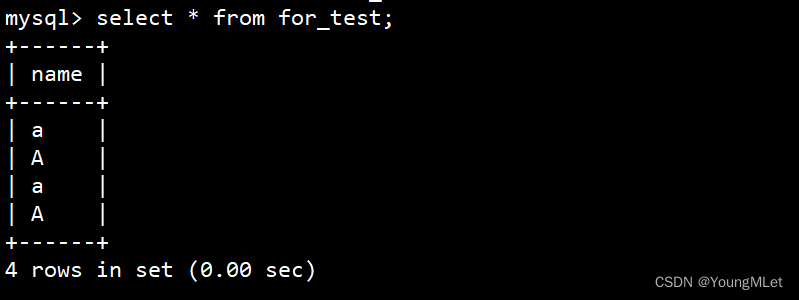
接下来我们筛选出 a 字符:
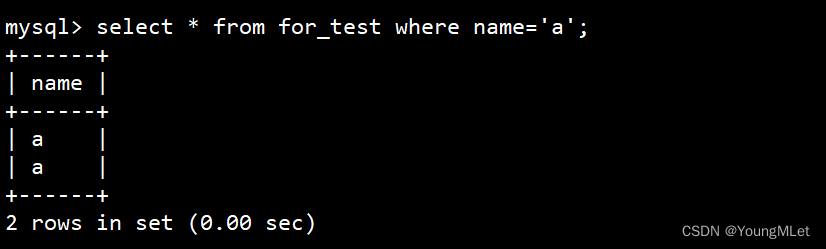
如上图,因为该数据库的检验规则为 utf8_ bin,进行区分大小写的方式进行严格匹配,所以筛选出来的字符 a 就是字符 a.
3. 操纵数据库
(1)查看数据库
show databases;
(2)显示创建的语句
show create database 数据库名;
例如:
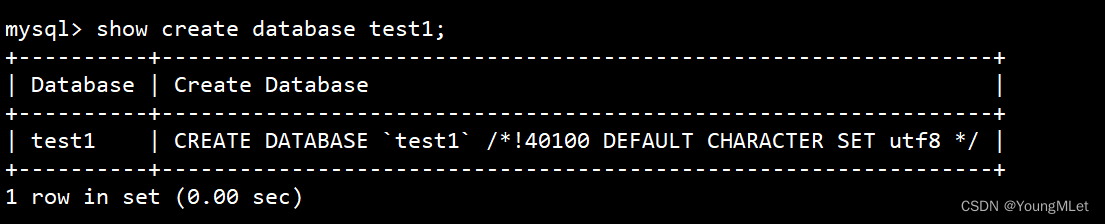
说明:
- MySQL 建议我们关键字使用大写,但是不是必须的;
- 数据库名字的反引号``,是为了防止使用的数据库名刚好是关键字
- / * !40100 default… * / 这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话;
(3)修改数据库
语法:
ALTER DATABASE db_name[alter_spacification [,alter_spacification]...]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name
说明:对数据库的修改主要指的是修改数据库的字符集,校验规则。
假设将我们上面创建的 test1 数据库的字符集改成 gbk:alter database test1 charset=gbk;
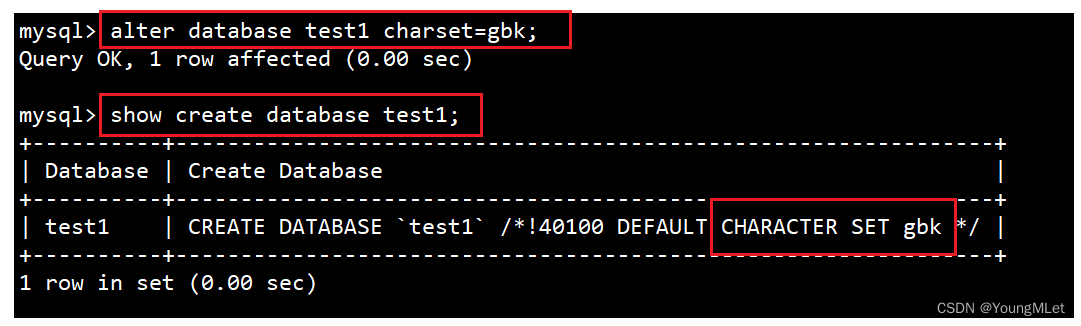
如上图 test1 数据库的字符集就修改成了 gbk.
4. 数据库删除
语法:
DROP DATABASE [IF EXISTS] db_ name;
例如我们删掉我们前面建的 test2 数据库:drop database test2;
如下:
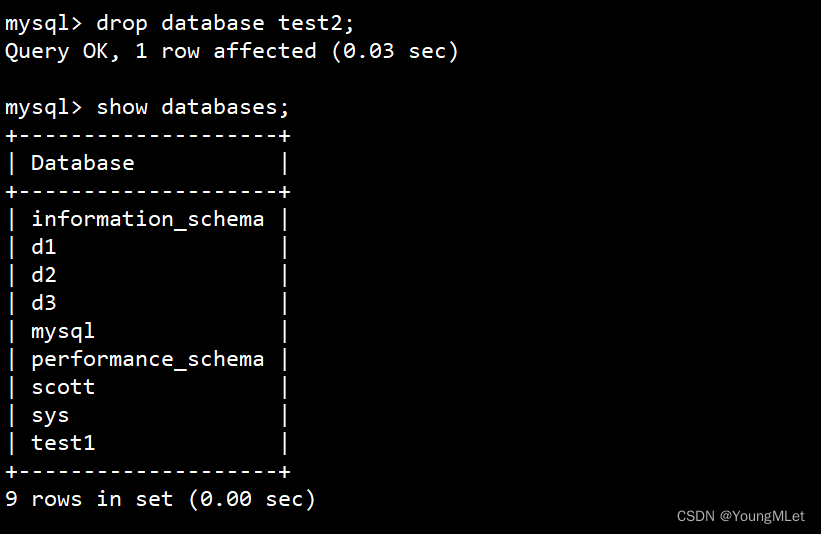
如上图,test2 数据库就被删除了。
执行删除之后的结果:
- 数据库内部看不到对应的数据库
- 对应的数据库文件夹被删除,级联删除,里面的数据表全部被删
5. 备份和恢复
(1)备份数据库
在备份数据库之前我们先需要退出 mysql.
语法:
mysqldump -P3306 -u root -p密码 -B 数据库名 > 数据库备份存储的文件路径
其中密码部分我们可以不在命令行输入,当我们执行这条命令的时候命令行会提示我们输入。
例如我们把 test1 库备份到文件中:mysqldump -P3306 -uroot -p -B test1 > /home/lmy/test1.sql

这时,可以打开看看 test1.sql 文件里的内容,其实把我们整个创建数据库,建表,导入数据的语句都装载这个文件中。
接下来我们进入 mysql 中,把这个数据库删掉:
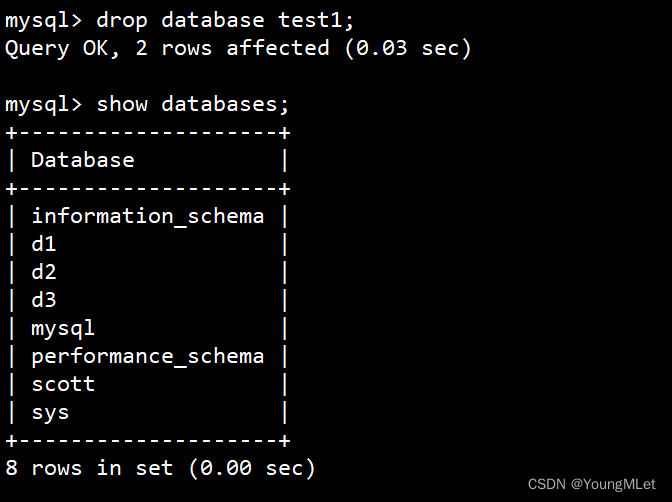
如上图,test1 库就被我们删除了,接下来我们进行还原。
(2)还原
语法:
source 数据库备份的文件路径;
我们在 mysql 中输入指令:source /home/lmy/test1.sql; 即可在 mysql 中恢复 test1 库:
(3)拓展
如果备份的不是整个数据库,而是其中的一张表,怎么做?做法如下:
mysqldump -uroot -p 数据库名 表名1 表名2 > 备份文件路径
如果同时备份多个数据库,如下:
mysqldump -uroot -p -B 数据库名1 数据库名2 ... > 数据库存放路径
如果备份一个数据库时,没有带上 -B 参数, 在恢复数据库时,需要先创建空数据库,然后使用数据库,再使用 source 来还原。
6. 查看连接情况
查看连接情况可以告诉我们当前有哪些用户连接到我们的 MySQL,如果查出某个用户不是我们正常登陆的,很有可能我们的数据库被人入侵了。以后大家发现自己数据库比较慢时,可以用这个指令来查看数据库连接情况。
语法:
show processlist;
例如:

二、表的操作
1. 创建表
语法:
CREATE TABLE table_name (field1 datatype,field2 datatype,field3 datatype) character set 字符集 collate 校验规则 engine 存储引擎;
在创建表之前需要指定数据库,即使用:use 数据库; 为该数据库创建表。
注意,数据库的数据类型我们暂时先不介绍,后续会介绍。
说明:
- field 表示列名
- datatype 表示列的类型
- character set 字符集,如果没有指定字符集,则以所在数据库的字符集为准
- collate 校验规则,如果没有指定校验规则,则以所在数据库的校验规则为准
例如我们创建一个 users 表,里面存储用户的 id、用户名、密码、生日:
create table users(-> id int,-> name varchar(20) comment '用户名',-> password char(20) comment '密码',-> birther date comment '生日'-> ) character set utf8 engine MyISAM;
说明:不同的存储引擎,创建表的文件不一样。users 表存储引擎是 MyISAM ,在数据库目录中有三个不同的文件,我们可以进入该目录查看:cd /var/lib/mysql/d1,分别是:
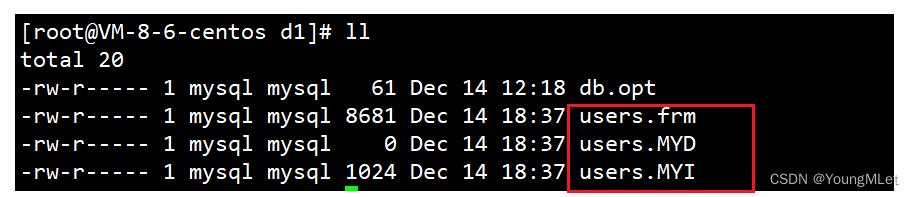
其中,它们分别表示:
- users.frm:表结构
- users.MYD:表数据
- users.MYI:表索引
而 db.opt 则是该数据库对应的字符集和检验规则。
2. 查看表
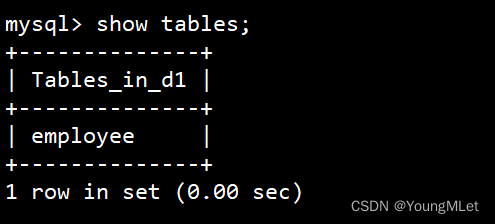
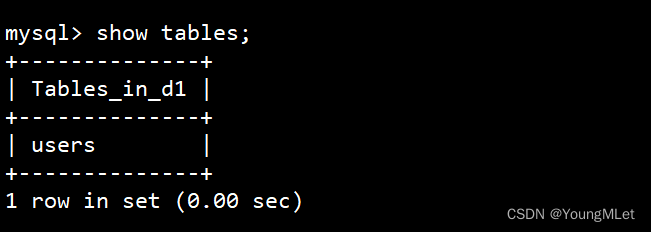
上面我们已经创建好了一张 users 表,此时我们可以查看该数据库有哪些表:show tables;
3. 查看表结构
语法:desc 表明;
例如查看 users 表的结构:
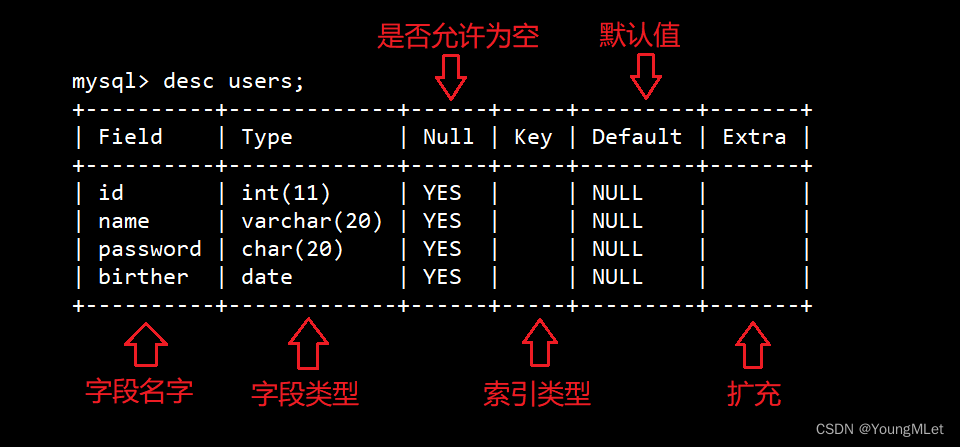
以上就是表的结构中的介绍,我们后面会详细介绍每一列的功能的。
4. 修改表
在项目实际开发中,经常修改某个表的结构,比如字段名字,字段大小,字段类型,表的字符集类型,表的存储引擎等等。我们还有需求,添加字段,删除字段等等;这时我们就需要修改表。
ALTER TABLE tablename ADD (column datatype [DEFAULT expr][,columndatatype]...); # 添加ALTER TABLE tablename MODIfy (column datatype [DEFAULT expr][,columndatatype]...); # 修改ALTER TABLE tablename DROP (column); # 删除
例如:
先在 users 表添加两条记录:
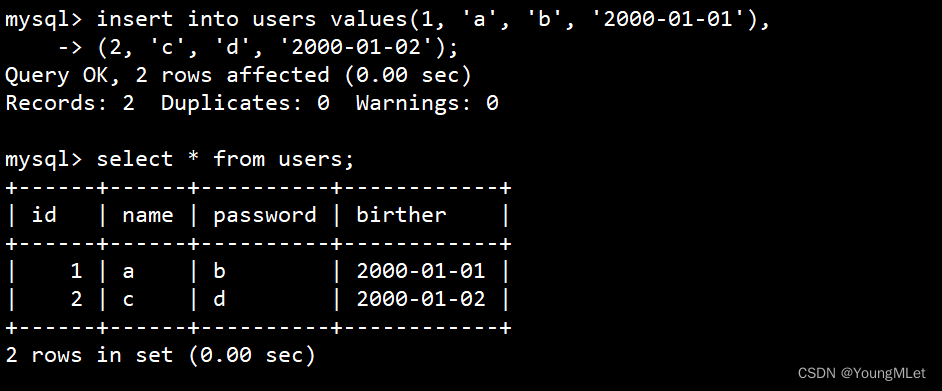
mysql> insert into users values(1, 'a', 'b', '2000-01-01'), -> (2, 'c', 'd', '2000-01-02');
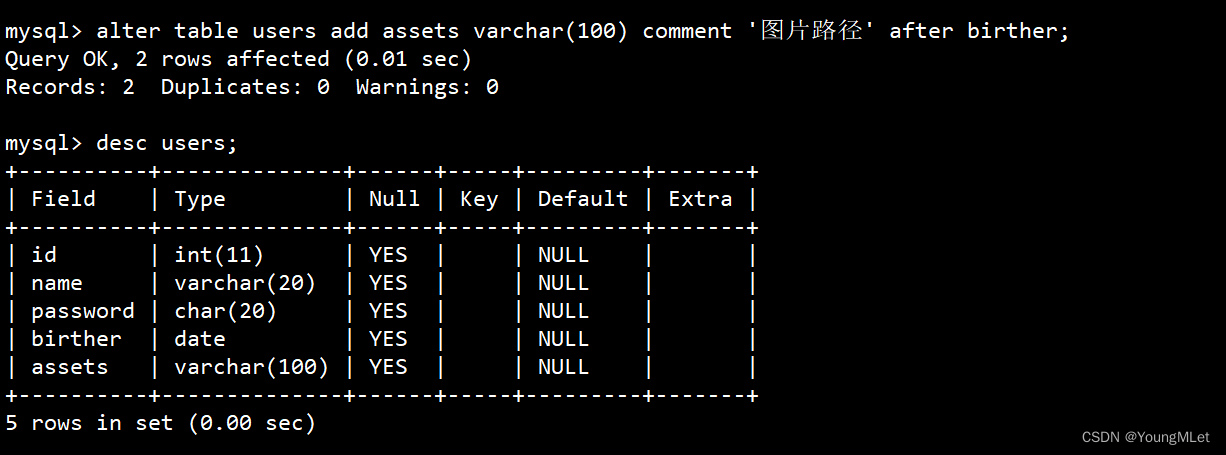
- 在 users 表添加一个字段,用于保存图片路径:
alter table users add assets varchar(100) comment '图片路径' after birther;
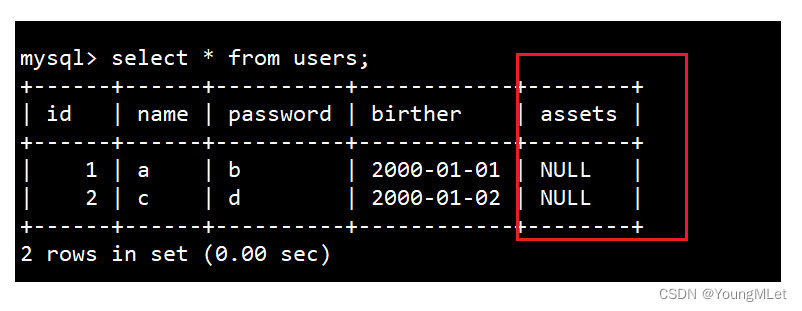
插入新字段后,我们查看原表的数据,对原来表中的数据没有影响:
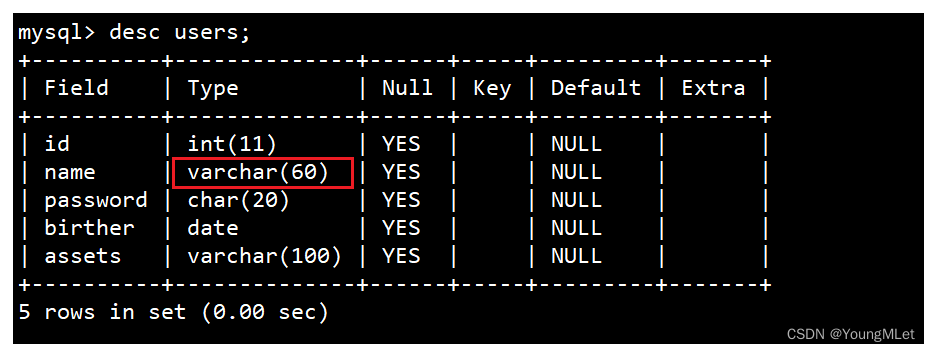
- 修改 name,将其长度改成 60:
alter table users modify name varchar(60);
- 删除 password 列:
alter table users drop password;
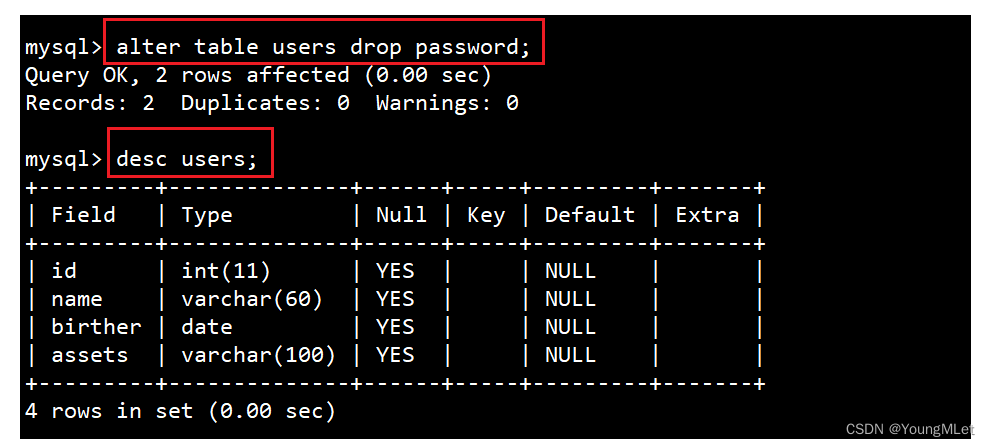
我们再查看表中的数据,发现 password 这一列的数据都不见了:
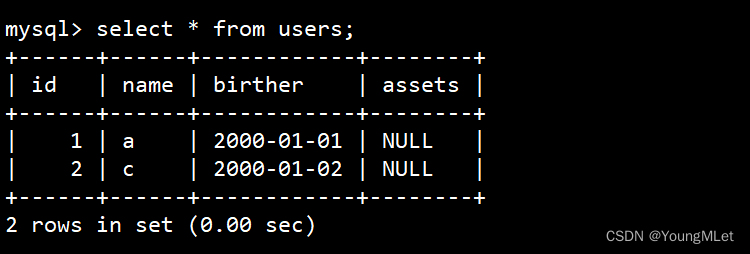
所以删除字段一定要小心,删除字段及其对应的列数据都没了。
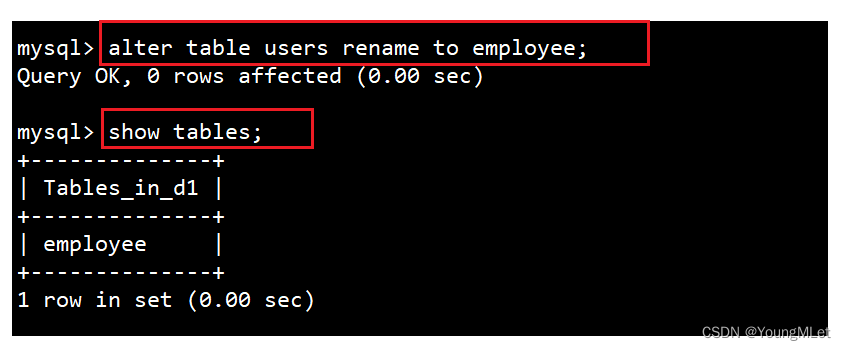
- 修改表名为 employee:
alter table users rename to employee;,其中 to 可以省略
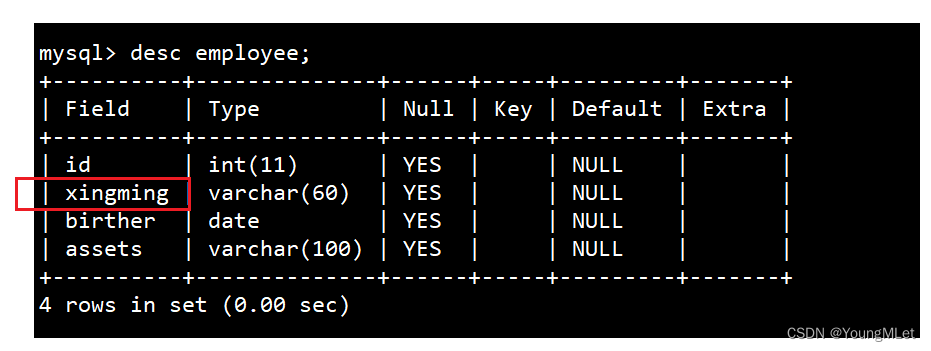
- 将 name 列修改为 xingming:
alter table employee change name xingming varchar(60);,新字段需要完整定义
5. 删除表
语法:DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ...
例如:
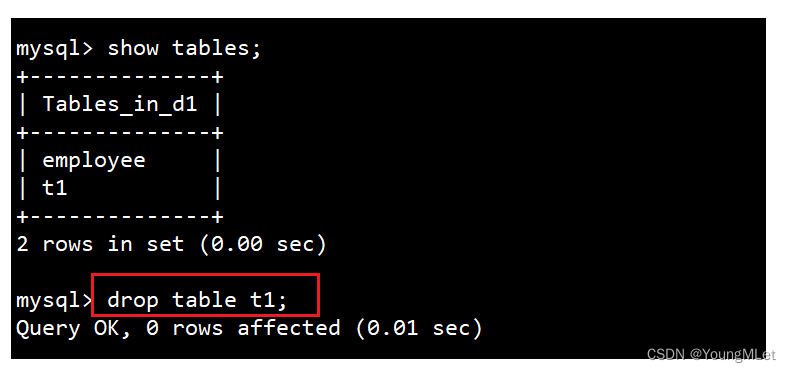
再次查看: