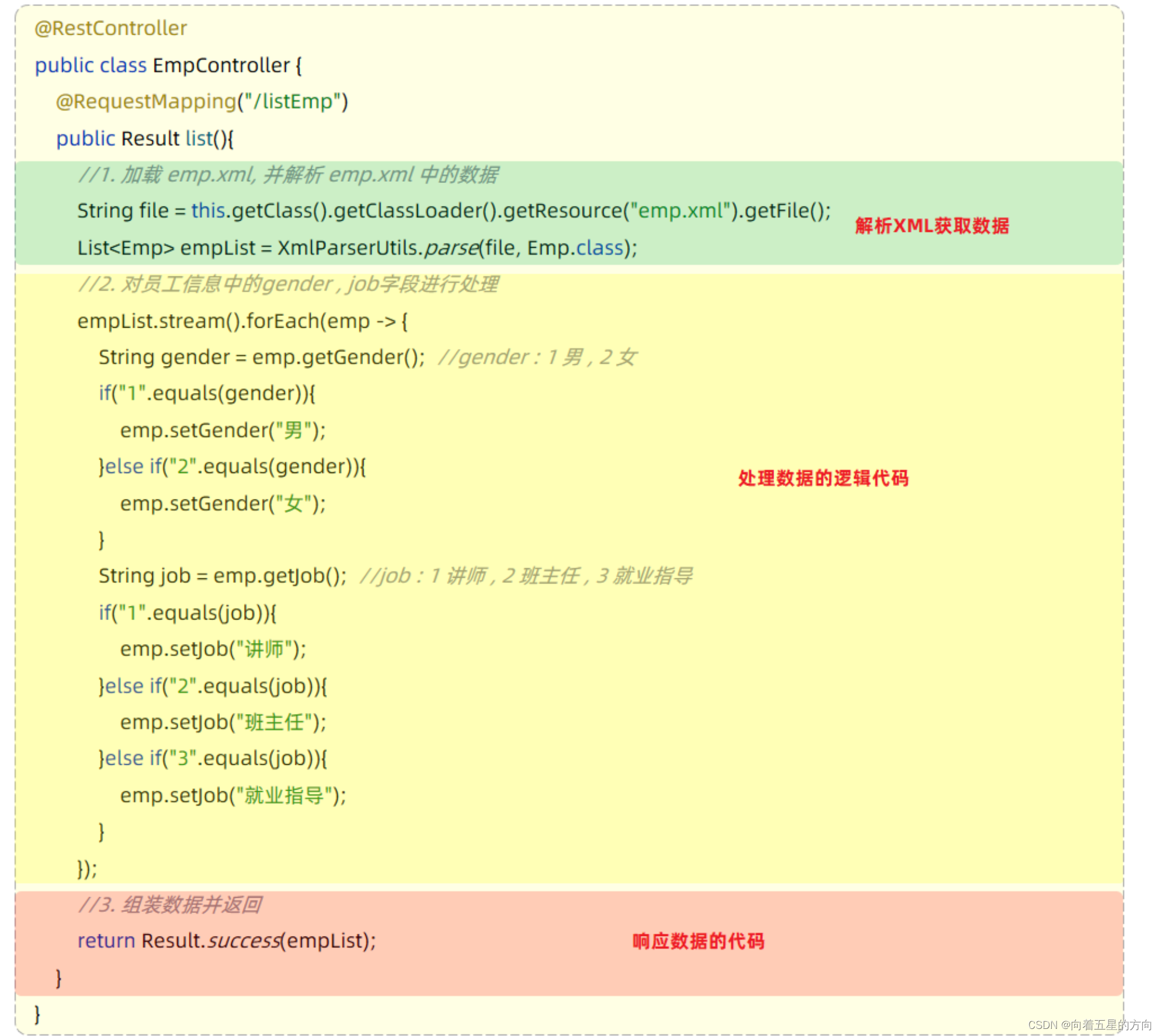
一、本文介绍
本文给大家来的改进机制是RepViT,用其替换我们整个主干网络,其是今年最新推出的主干网络,其主要思想是将轻量级视觉变换器(ViT)的设计原则应用于传统的轻量级卷积神经网络(CNN)。我将其替换整个YOLOv8的Backbone,实现了大幅度涨点。我对修改后的网络(我用的最轻量的版本),在一个包含1000张图片包含大中小的检测目标的数据集上(共有20+类别),进行训练测试,发现所有的目标上均有一定程度的涨点效果,下面我会附上基础版本和修改版本的训练对比图。
推荐指数:⭐⭐⭐⭐⭐
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
训练结果对比图->

目录
一、本文介绍
二、RepViT基本原理
三、RepViT的核心代码
四、手把手教你添加RepViT网络结构
修改一
修改二
修改三
修改四
修改五
修改六
修改七
修改八
五、RepViT的yaml文件
六、成功运行记录
七、本文总结
二、RepViT基本原理

官方论文地址: 官方论文地址点击即可跳转
官方代码地址: 官方代码地址点击即可跳转

RepViT: Revisiting Mobile CNN From ViT Perspective 这篇论文探讨了如何改进轻量级卷积神经网络(CNN)以提高其在移动设备上的性能和效率。作者们发现,虽然轻量级视觉变换器(ViT)因其能够学习全局表示而表现出色,但轻量级CNN和轻量级ViT之间的架构差异尚未得到充分研究。因此,他们通过整合轻量级ViT的高效架构设计,逐步改进标准轻量级CNN(特别是MobileNetV3),从而创造了一系列全新的纯CNN模型,称为RepViT。这些模型在各种视觉任务上表现出色,比现有的轻量级ViT更高效。
其主要的改进机制包括:
-
结构性重组:通过结构性重组(Structural Re-parameterization, SR),引入多分支拓扑结构,以提高训练时的性能。
-
扩展比率调整:调整卷积层中的扩展比率,以减少参数冗余和延迟,同时提高网络宽度以增强模型性能。
-
宏观设计优化:对网络的宏观架构进行优化,包括早期卷积层的设计、更深的下采样层、简化的分类器,以及整体阶段比例的调整。
-
微观设计调整:在微观架构层面进行优化,包括卷积核大小的选择和压缩激励(SE)层的最佳放置。
这些创新机制共同推动了轻量级CNN的性能和效率,使其更适合在移动设备上使用,下面的是官方论文中的结构图,我们对其进行简单的分析。

这张图片是论文中的图3,展示了RepViT架构的总览。RepViT有四个阶段,输入图像的分辨率依次为
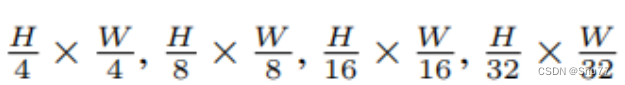
每个阶段的通道维度用 Ci 表示,批处理大小用 B 表示。
- Stem:用于预处理输入图像的模块。
- Stage1-4:每个阶段由多个RepViTBlock组成,以及一个可选的RepViTSEBlock,包含深度可分离卷积(3x3DW),1x1卷积,压缩激励模块(SE)和前馈网络(FFN)。每个阶段通过下采样减少空间维度。
- Pooling:全局平均池化层,用于减少特征图的空间维度。
- FC:全连接层,用于最终的类别预测。
总结:大家可以将RepViT看成是MobileNet系列的改进版本
三、RepViT的核心代码
下面的代码是整个RepViT的核心代码,其中有个版本,对应的GFLOPs也不相同,使用方式看章节四。
import torch.nn as nn
from timm.models.layers import SqueezeExcite
import torch__all__ = ['repvit_m0_6','repvit_m0_9', 'repvit_m1_0', 'repvit_m1_1', 'repvit_m1_5', 'repvit_m2_3']def _make_divisible(v, divisor, min_value=None):"""This function is taken from the original tf repo.It ensures that all layers have a channel number that is divisible by 8It can be seen here:https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py:param v::param divisor::param min_value::return:"""if min_value is None:min_value = divisornew_v = max(min_value, int(v + divisor / 2) // divisor * divisor)# Make sure that round down does not go down by more than 10%.if new_v < 0.9 * v:new_v += divisorreturn new_vclass Conv2d_BN(torch.nn.Sequential):def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,groups=1, bn_weight_init=1, resolution=-10000):super().__init__()self.add_module('c', torch.nn.Conv2d(a, b, ks, stride, pad, dilation, groups, bias=False))self.add_module('bn', torch.nn.BatchNorm2d(b))torch.nn.init.constant_(self.bn.weight, bn_weight_init)torch.nn.init.constant_(self.bn.bias, 0)@torch.no_grad()def fuse_self(self):c, bn = self._modules.values()w = bn.weight / (bn.running_var + bn.eps) ** 0.5w = c.weight * w[:, None, None, None]b = bn.bias - bn.running_mean * bn.weight / \(bn.running_var + bn.eps) ** 0.5m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation,groups=self.c.groups,device=c.weight.device)m.weight.data.copy_(w)m.bias.data.copy_(b)return mclass Residual(torch.nn.Module):def __init__(self, m, drop=0.):super().__init__()self.m = mself.drop = dropdef forward(self, x):if self.training and self.drop > 0:return x + self.m(x) * torch.rand(x.size(0), 1, 1, 1,device=x.device).ge_(self.drop).div(1 - self.drop).detach()else:return x + self.m(x)@torch.no_grad()def fuse_self(self):if isinstance(self.m, Conv2d_BN):m = self.m.fuse_self()assert (m.groups == m.in_channels)identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)identity = torch.nn.functional.pad(identity, [1, 1, 1, 1])m.weight += identity.to(m.weight.device)return melif isinstance(self.m, torch.nn.Conv2d):m = self.massert (m.groups != m.in_channels)identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)identity = torch.nn.functional.pad(identity, [1, 1, 1, 1])m.weight += identity.to(m.weight.device)return melse:return selfclass RepVGGDW(torch.nn.Module):def __init__(self, ed) -> None:super().__init__()self.conv = Conv2d_BN(ed, ed, 3, 1, 1, groups=ed)self.conv1 = torch.nn.Conv2d(ed, ed, 1, 1, 0, groups=ed)self.dim = edself.bn = torch.nn.BatchNorm2d(ed)def forward(self, x):return self.bn((self.conv(x) + self.conv1(x)) + x)@torch.no_grad()def fuse_self(self):conv = self.conv.fuse_self()conv1 = self.conv1conv_w = conv.weightconv_b = conv.biasconv1_w = conv1.weightconv1_b = conv1.biasconv1_w = torch.nn.functional.pad(conv1_w, [1, 1, 1, 1])identity = torch.nn.functional.pad(torch.ones(conv1_w.shape[0], conv1_w.shape[1], 1, 1, device=conv1_w.device),[1, 1, 1, 1])final_conv_w = conv_w + conv1_w + identityfinal_conv_b = conv_b + conv1_bconv.weight.data.copy_(final_conv_w)conv.bias.data.copy_(final_conv_b)bn = self.bnw = bn.weight / (bn.running_var + bn.eps) ** 0.5w = conv.weight * w[:, None, None, None]b = bn.bias + (conv.bias - bn.running_mean) * bn.weight / \(bn.running_var + bn.eps) ** 0.5conv.weight.data.copy_(w)conv.bias.data.copy_(b)return convclass RepViTBlock(nn.Module):def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs):super(RepViTBlock, self).__init__()assert stride in [1, 2]self.identity = stride == 1 and inp == oupassert (hidden_dim == 2 * inp)if stride == 2:self.token_mixer = nn.Sequential(Conv2d_BN(inp, inp, kernel_size, stride, (kernel_size - 1) // 2, groups=inp),SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),Conv2d_BN(inp, oup, ks=1, stride=1, pad=0))self.channel_mixer = Residual(nn.Sequential(# pwConv2d_BN(oup, 2 * oup, 1, 1, 0),nn.GELU() if use_hs else nn.GELU(),# pw-linearConv2d_BN(2 * oup, oup, 1, 1, 0, bn_weight_init=0),))else:assert (self.identity)self.token_mixer = nn.Sequential(RepVGGDW(inp),SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),)self.channel_mixer = Residual(nn.Sequential(# pwConv2d_BN(inp, hidden_dim, 1, 1, 0),nn.GELU() if use_hs else nn.GELU(),# pw-linearConv2d_BN(hidden_dim, oup, 1, 1, 0, bn_weight_init=0),))def forward(self, x):return self.channel_mixer(self.token_mixer(x))class RepViT(nn.Module):def __init__(self, cfgs):super(RepViT, self).__init__()# setting of inverted residual blocksself.cfgs = cfgs# building first layerinput_channel = self.cfgs[0][2]patch_embed = torch.nn.Sequential(Conv2d_BN(3, input_channel // 2, 3, 2, 1), torch.nn.GELU(),Conv2d_BN(input_channel // 2, input_channel, 3, 2, 1))layers = [patch_embed]# building inverted residual blocksblock = RepViTBlockfor k, t, c, use_se, use_hs, s in self.cfgs:output_channel = _make_divisible(c, 8)exp_size = _make_divisible(input_channel * t, 8)layers.append(block(input_channel, exp_size, output_channel, k, s, use_se, use_hs))input_channel = output_channelself.features = nn.ModuleList(layers)self.width_list = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def forward(self, x):# x = self.features(xresults = [None, None, None, None]temp = Nonei = Nonefor index, f in enumerate(self.features):x = f(x)if index == 0:temp = x.size(1)i = 0elif x.size(1) == temp:results[i] = xelse:temp = x.size(1)i = i + 1return resultsdef repvit_m0_6():"""Constructs a MobileNetV3-Large model"""cfgs = [[3, 2, 40, 1, 0, 1],[3, 2, 40, 0, 0, 1],[3, 2, 80, 0, 0, 2],[3, 2, 80, 1, 0, 1],[3, 2, 80, 0, 0, 1],[3, 2, 160, 0, 1, 2],[3, 2, 160, 1, 1, 1],[3, 2, 160, 0, 1, 1],[3, 2, 160, 1, 1, 1],[3, 2, 160, 0, 1, 1],[3, 2, 160, 1, 1, 1],[3, 2, 160, 0, 1, 1],[3, 2, 160, 1, 1, 1],[3, 2, 160, 0, 1, 1],[3, 2, 160, 0, 1, 1],[3, 2, 320, 0, 1, 2],[3, 2, 320, 1, 1, 1],]model = RepViT(cfgs)return modeldef repvit_m0_9():"""Constructs a MobileNetV3-Large model"""cfgs = [# k, t, c, SE, HS, s[3, 2, 48, 1, 0, 1],[3, 2, 48, 0, 0, 1],[3, 2, 48, 0, 0, 1],[3, 2, 96, 0, 0, 2],[3, 2, 96, 1, 0, 1],[3, 2, 96, 0, 0, 1],[3, 2, 96, 0, 0, 1],[3, 2, 192, 0, 1, 2],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 1, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 192, 0, 1, 1],[3, 2, 384, 0, 1, 2],[3, 2, 384, 1, 1, 1],[3, 2, 384, 0, 1, 1]]model = RepViT(cfgs)return modeldef repvit_m1_0():"""Constructs a MobileNetV3-Large model"""cfgs = [# k, t, c, SE, HS, s[3, 2, 56, 1, 0, 1],[3, 2, 56, 0, 0, 1],[3, 2, 56, 0, 0, 1],[3, 2, 112, 0, 0, 2],[3, 2, 112, 1, 0, 1],[3, 2, 112, 0, 0, 1],[3, 2, 112, 0, 0, 1],[3, 2, 224, 0, 1, 2],[3, 2, 224, 1, 1, 1],[3, 2, 224, 0, 1, 1],[3, 2, 224, 1, 1, 1],[3, 2, 224, 0, 1, 1],[3, 2, 224, 1, 1, 1],[3, 2, 224, 0, 1, 1],[3, 2, 224, 1, 1, 1],[3, 2, 224, 0, 1, 1],[3, 2, 224, 1, 1, 1],[3, 2, 224, 0, 1, 1],[3, 2, 224, 1, 1, 1],[3, 2, 224, 0, 1, 1],[3, 2, 224, 1, 1, 1],[3, 2, 224, 0, 1, 1],[3, 2, 224, 0, 1, 1],[3, 2, 448, 0, 1, 2],[3, 2, 448, 1, 1, 1],[3, 2, 448, 0, 1, 1]]model = RepViT(cfgs)return modeldef repvit_m1_1():"""Constructs a MobileNetV3-Large model"""cfgs = [# k, t, c, SE, HS, s[3, 2, 64, 1, 0, 1],[3, 2, 64, 0, 0, 1],[3, 2, 64, 0, 0, 1],[3, 2, 128, 0, 0, 2],[3, 2, 128, 1, 0, 1],[3, 2, 128, 0, 0, 1],[3, 2, 128, 0, 0, 1],[3, 2, 256, 0, 1, 2],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 512, 0, 1, 2],[3, 2, 512, 1, 1, 1],[3, 2, 512, 0, 1, 1]]model = RepViT(cfgs)return modeldef repvit_m1_5():"""Constructs a MobileNetV3-Large model"""cfgs = [# k, t, c, SE, HS, s[3, 2, 64, 1, 0, 1],[3, 2, 64, 0, 0, 1],[3, 2, 64, 1, 0, 1],[3, 2, 64, 0, 0, 1],[3, 2, 64, 0, 0, 1],[3, 2, 128, 0, 0, 2],[3, 2, 128, 1, 0, 1],[3, 2, 128, 0, 0, 1],[3, 2, 128, 1, 0, 1],[3, 2, 128, 0, 0, 1],[3, 2, 128, 0, 0, 1],[3, 2, 256, 0, 1, 2],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 1, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 256, 0, 1, 1],[3, 2, 512, 0, 1, 2],[3, 2, 512, 1, 1, 1],[3, 2, 512, 0, 1, 1],[3, 2, 512, 1, 1, 1],[3, 2, 512, 0, 1, 1]]model = RepViT(cfgs)return modeldef repvit_m2_3():"""Constructs a MobileNetV3-Large model"""cfgs = [# k, t, c, SE, HS, s[3, 2, 80, 1, 0, 1],[3, 2, 80, 0, 0, 1],[3, 2, 80, 1, 0, 1],[3, 2, 80, 0, 0, 1],[3, 2, 80, 1, 0, 1],[3, 2, 80, 0, 0, 1],[3, 2, 80, 0, 0, 1],[3, 2, 160, 0, 0, 2],[3, 2, 160, 1, 0, 1],[3, 2, 160, 0, 0, 1],[3, 2, 160, 1, 0, 1],[3, 2, 160, 0, 0, 1],[3, 2, 160, 1, 0, 1],[3, 2, 160, 0, 0, 1],[3, 2, 160, 0, 0, 1],[3, 2, 320, 0, 1, 2],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 320, 1, 1, 1],[3, 2, 320, 0, 1, 1],# [3, 2, 320, 1, 1, 1],# [3, 2, 320, 0, 1, 1],[3, 2, 320, 0, 1, 1],[3, 2, 640, 0, 1, 2],[3, 2, 640, 1, 1, 1],[3, 2, 640, 0, 1, 1],# [3, 2, 640, 1, 1, 1],# [3, 2, 640, 0, 1, 1]]model = RepViT(cfgs)return model
四、手把手教你添加RepViT网络结构
这个主干的网络结构添加起来算是所有的改进机制里最麻烦的了,因为有一些网略结构可以用yaml文件搭建出来,有一些网络结构其中的一些细节根本没有办法用yaml文件去搭建,用yaml文件去搭建会损失一些细节部分(而且一个网络结构设计很多细节的结构修改方式都不一样,一个一个去修改大家难免会出错),所以这里让网络直接返回整个网络,然后修改部分 yolo代码以后就都以这种形式添加了,以后我提出的网络模型基本上都会通过这种方式修改,我也会进行一些模型细节改进。创新出新的网络结构大家直接拿来用就可以的。下面开始添加教程->
(同时每一个后面都有代码,大家拿来复制粘贴替换即可,但是要看好了不要复制粘贴替换多了)
修改一
我们复制网络结构代码到“ultralytics/nn/modules”目录下创建一个py文件复制粘贴进去 ,我这里起的名字是RepViT。
修改二
找到如下的文件"ultralytics/nn/tasks.py" 在开始的部分导入我们的模型如下图。
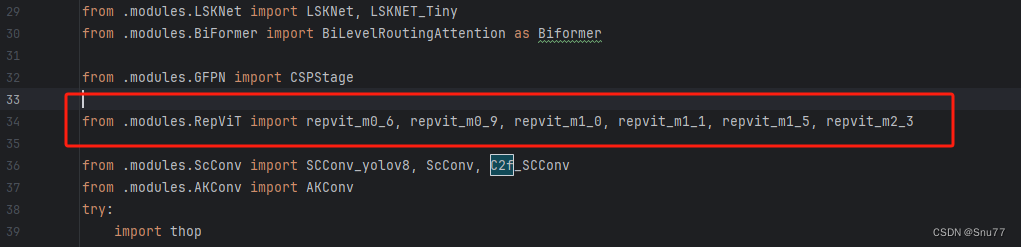
from .modules.RepViT import repvit_m0_6, repvit_m0_9, repvit_m1_0, repvit_m1_1, repvit_m1_5, repvit_m2_3修改三
添加如下两行代码!!!

修改四
找到七百多行大概把具体看图片,按照图片来修改就行,添加红框内的部分,注意没有()只是函数名。

elif m in {repvit_m0_6, repvit_m0_9, repvit_m1_0, repvit_m1_1, repvit_m1_5, repvit_m2_3}:m = m()c2 = m.width_list # 返回通道列表backbone = True修改五
下面的两个红框内都是需要改动的。

if isinstance(c2, list):m_ = mm_.backbone = Trueelse:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typem.np = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type = i + 4 if backbone else i, f, t # attach index, 'from' index, type修改六
如下的也需要修改,全部按照我的来。
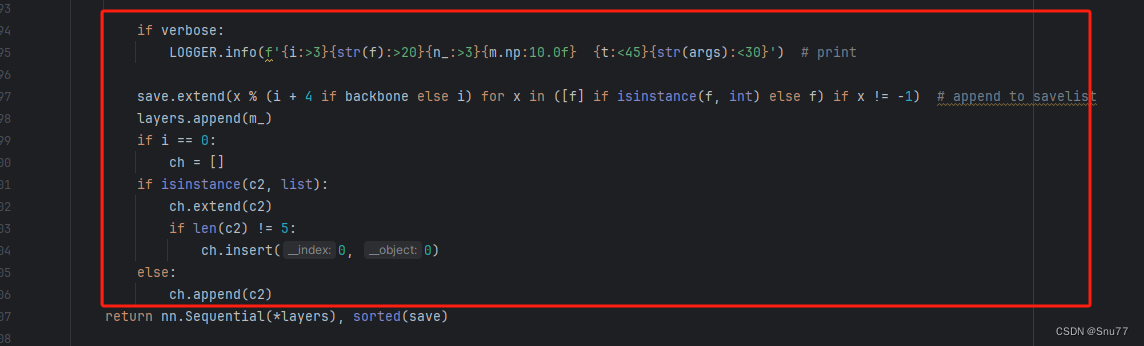
代码如下把原先的代码替换了即可。
if verbose:LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # printsave.extend(x % (i + 4 if backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []if isinstance(c2, list):ch.extend(c2)if len(c2) != 5:ch.insert(0, 0)else:ch.append(c2)修改七
修改七和前面的都不太一样,需要修改前向传播中的一个部分, 已经离开了parse_model方法了。
可以在图片中开代码行数,没有离开task.py文件都是同一个文件。 同时这个部分有好几个前向传播都很相似,大家不要看错了,是70多行左右的!!!,同时我后面提供了代码,大家直接复制粘贴即可,有时间我针对这里会出一个视频。

代码如下->
def _predict_once(self, x, profile=False, visualize=False):"""Perform a forward pass through the network.Args:x (torch.Tensor): The input tensor to the model.profile (bool): Print the computation time of each layer if True, defaults to False.visualize (bool): Save the feature maps of the model if True, defaults to False.Returns:(torch.Tensor): The last output of the model."""y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)if len(x) != 5: # 0 - 5x.insert(0, None)for index, i in enumerate(x):if index in self.save:y.append(i)else:y.append(None)x = x[-1] # 最后一个输出传给下一层else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return x到这里就完成了修改部分,但是这里面细节很多,大家千万要注意不要替换多余的代码,导致报错,也不要拉下任何一部,都会导致运行失败,而且报错很难排查!!!很难排查!!!
修改八
这个Swin Transformer和其他的不太一样会导致计算的GFLOPs计算异常,所以需要额外修改一处, 我们找到如下文件'ultralytics/utils/torch_utils.py'按照如下的图片进行修改。
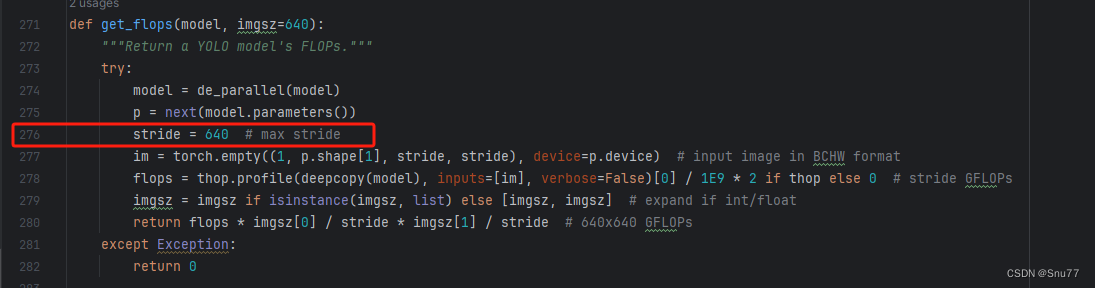
五、RepViT的yaml文件
复制如下yaml文件进行运行!!!
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, repvit_m0_9, []] # 4- [-1, 1, SPPF, [1024, 5]] # 5# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 6- [[-1, 3], 1, Concat, [1]] # 7 cat backbone P4- [-1, 3, C2f, [512]] # 8- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 9- [[-1, 2], 1, Concat, [1]] # 10 cat backbone P3- [-1, 3, C2f, [256]] # 11 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]] # 12- [[-1, 8], 1, Concat, [1]] # 13 cat head P4- [-1, 3, C2f, [512]] # 14 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]] # 15- [[-1, 5], 1, Concat, [1]] # 16 cat head P5- [-1, 3, C2f, [1024]] # 17 (P5/32-large)- [[11, 14, 17], 1, Detect, [nc]] # Detect(P3, P4, P5)
六、成功运行记录
下面是成功运行的截图,已经完成了有1个epochs的训练,图片太大截不全第2个epochs了。 
七、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备