1 Knative的自动缩放机制
-
“请求驱动计算”是serverless的核心特性
- 缩容至0:即没有请求时,系统不会分配资源给Kservice;
- 从0开始扩容:由Activator缓存请求,并报告指标数据给Autoscaler;
- 按需扩容:Autoscaler根据Revision中各实例的QP报告的指标数据不断调整Revision中实例数量
-
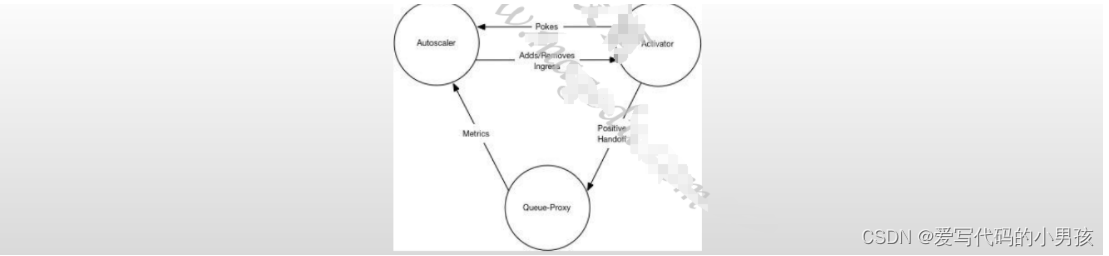
Knative系统中,Autoscaler、Activator和Queue-Proxy三者协同管理应用规模与流量规模的匹配
- Knative附带了开箱即用的AutoScaler,简称KPA;
- 同时,Knative还支持使用Kubernetes HPA进行Deployment缩放
-
Autoscaler在扩缩容功能上实现的基本假设
- 用户不能仅因为服务实例收缩为0而收到错误响应
- 请求不能导致应用过载
- 系统不能造成无谓的资源浪费
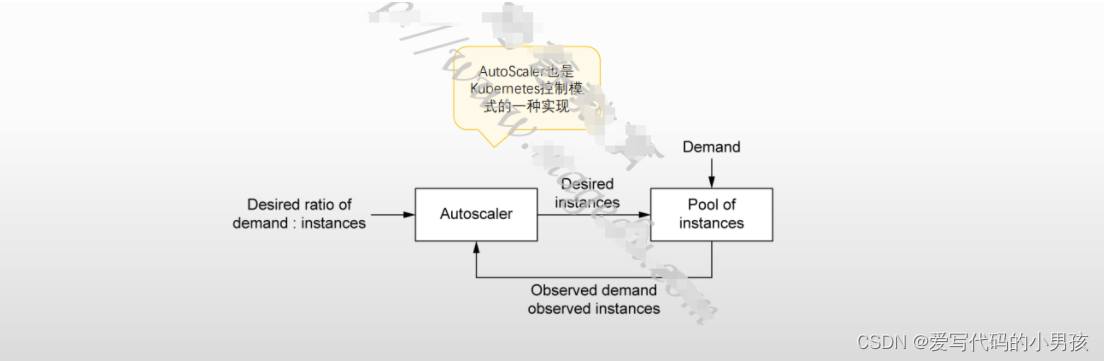
2 请求如何驱动计算
-
Knative的自动扩缩容机制依赖于两个前提
- 为Pod实例配置支持的目标并发数(在给定的时间里可同时处理的请求数)
- 应用实例支持的缩放边界
- 最少实例数,0即表示支持缩容至0实例;
- 最大实例数
-
AutoScaler的基本缩放逻辑
- Autoscaler基于过去一段时间内(stable windows指定)统计的指标(metrics)数据和单个实例的目标并发数(target)来计算目标实例数
- 计算出的目标实例数将发送给相应的Revision的Deployment执行缩放操作
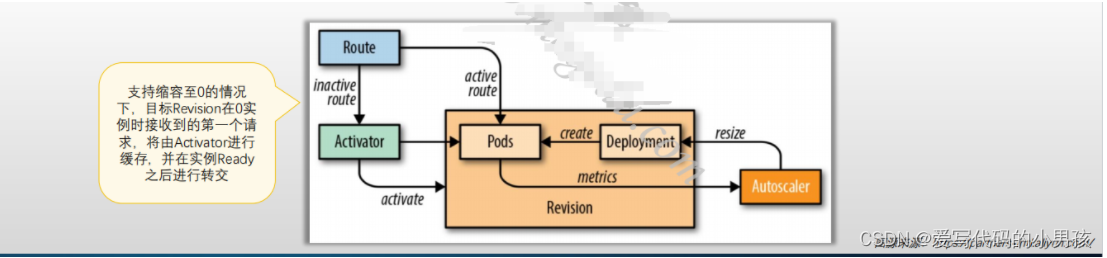
3 Autoscaler执行扩缩容的基本流程
-
目标Revision零实例
- 初次请求由Ingress GW转发给Activator进行缓存,同时报告给数据给Autoscaler,进而控制相应的Deployment来完成Pod实例扩展;
- Pod副本ready后,Activator将缓存的请求转发给相应的Pod对象;
- 随后,存在ready状态的Pod期间,Ingress GW将后续的请求直接转给Pod,而不再转给Activator;
-
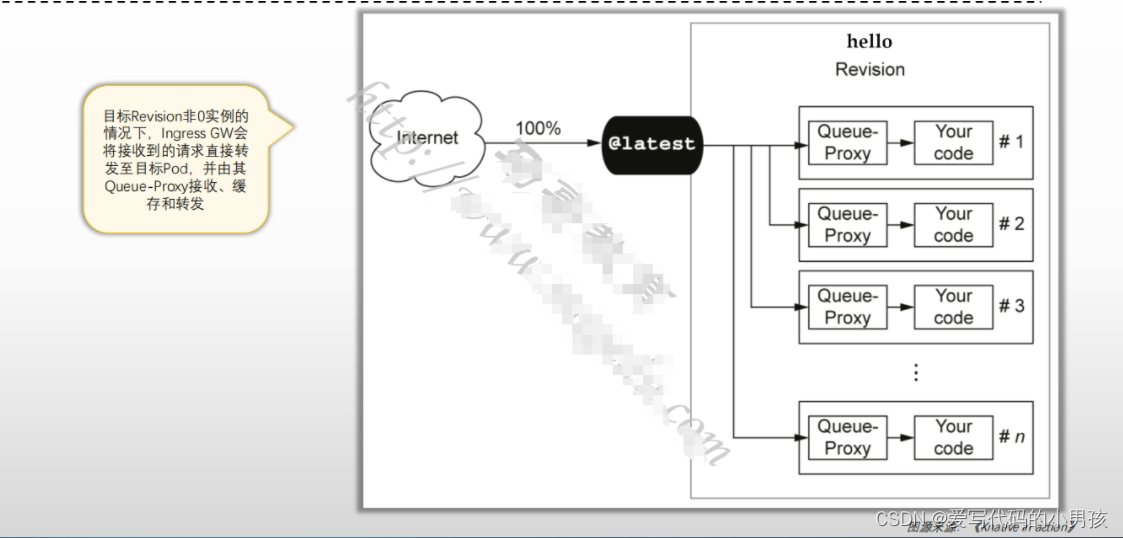
目标Revision存在至少一个Ready状态的Pod
- Autoscaler根据Revision中各Pod的Queue-Proxy容器持续报告指标数据持续计算Pod副本数;
- Deployment根据Autoscaler的计算结果进行实例数量调整
-
Reviision实例数不为0,但请求数持续为0
- Autoscaler在Queue-Proxy持续一段时间报告指标为0后,即将其Pod缩减为0
- 随后,Ingress GW会将收到的请求再次转发给Activator
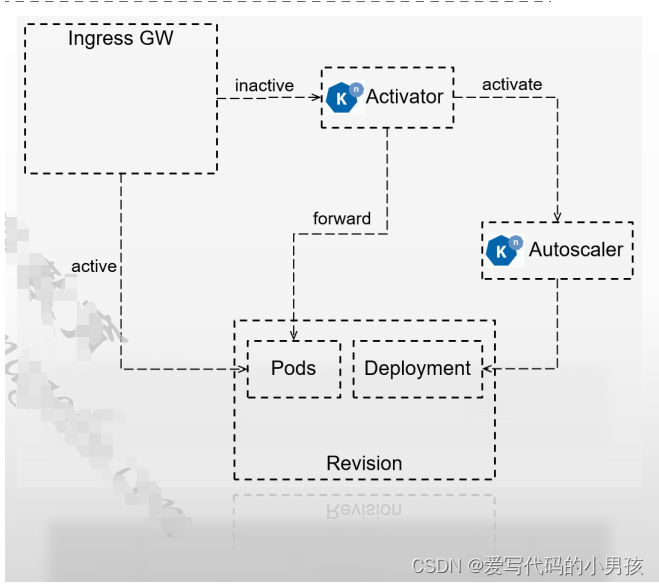
3.1 零实例时收到请求的工作流程
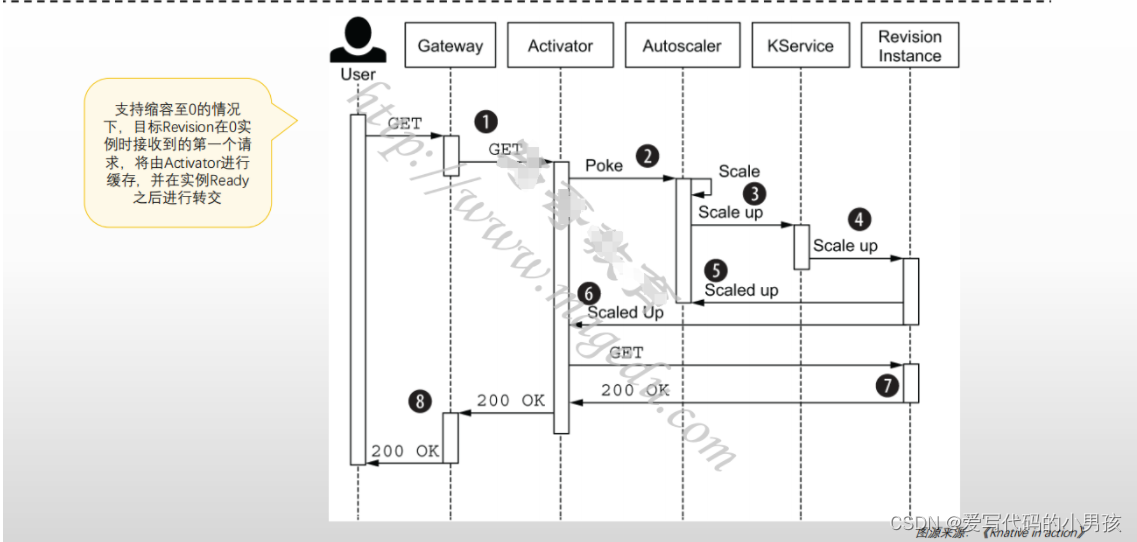
3.2 非零实例时
4 缩放窗口和Panic
-
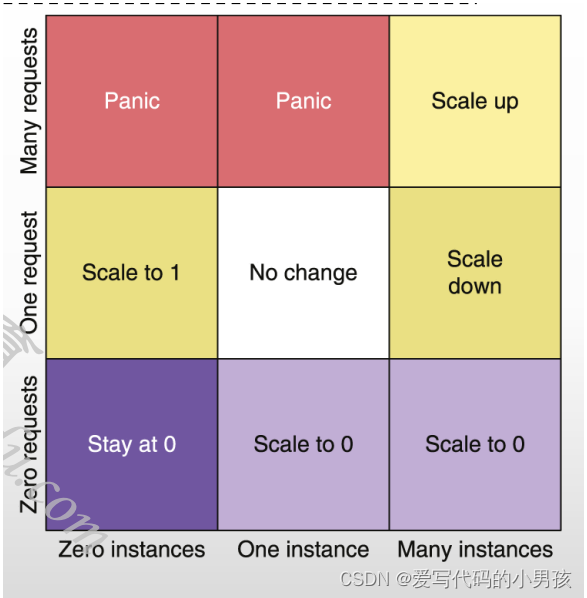
负载变动频繁时,Knative可能会因为响应负载变动而导致频繁创建或销毁Pod实例;
-
为避免服务规模“抖动”,Autoscaler支持两种扩缩容模式:
- Stable:根据窗口稳定期(stable windows,默认60秒)的请求平均数(平均并发数)及每个Pod的目标并发数计算Pod数
- Panic:短期内收到大量请求时,将启用Panic模式
- 十分之一窗口期(6秒)的平均并发数> 2*单实例目标并发数
- 进入panic模式60秒后,系统会重新返回stable模式
-
以下图矩阵为例(假设现有的实例数和平均并发数均为0)
- 横轴(现有实例数量):0个、1个和M个
- 纵轴(到达的请求数): 0个、1个和N个
5 Autoscaler计算Pod数的基本逻辑
- 指标收集周期和决策周期
- Autoscaler每2秒钟计算一次Revision上所需要Pod实例数量
- Autoscaler每2秒钟从Revision的Pod实例(Quueu-Proxy容器)上抓取一次指标数据,并将其(每秒的)平均值存储于单独的bucket中
- 实例较少时,则从每个实例抓取指标
- 实例较多时,则从实例的一个子集上抓取指标,因而计算出的Pod实例数量并非精准数值
- 决策过程
- Autoscaler在Revision中检索就绪状态的Pod实例数量
- 若就绪状态实例为0,将其设定为1,即使用Activator作为实例
- Autoscaler检查累积收集的可用指标
- 若不存在任何可用指标,则将所需要的Pod实例数设置为0
- 若存在累积的指标,则计算出窗口期内的平均并发请求数
- 根据平均并发请求数和每实例的并发目标值计算出所需要的Pod实例数
- 窗口期内每实例的平均并发请求数 = Bucket中的样本值之和 / Bucket数量
- 每实例的目标并发请求数 = 单实例目标并发数 * 目标利用率
- 期望的Pod数 = 窗口期内每实例的并发请求数 / 每实例目标并发请求数
- Panic的触发条件
- 期望的Pod数 / 现有的Pod数 ≥ 2
- 60秒之后返回至Stable
- Autoscaler在Revision中检索就绪状态的Pod实例数量
6 Knative支持的Autoscaler
- Knative支持基于KPA和HPA的自动缩放机制,但二者的功能略有不同;
- Knative Pod Autoscaler
- Knative Serving的核心组件,且默认即为启用状态
- 支持缩容为0
- 不支持基于CPU的自动缩放机制
- Kubernetes Horizontal Pod Autoscaler
- Kubernetes系统上的组件
- 不支持缩容至0
- 支持基于CPU的自动缩放机制
- Knative Pod Autoscaler
6.1 配置要使用的Autoscaler
-
Autoscaler的功能设定方式
- 全局配置:ConfigMap/config-autoscaler
- 每Revision配置:Revision Annotations
-
配置要使用的Autoscaler
-
全局配置:位于knative-serving名称空间下的ConfigMap资源config-autoscaler之中
apiVersion: v1 kind: ConfigMap metadata:name: config-autoscalernamespace: knative-serving data:pod-autoscaler-class: "kpa.autoscaling.knative.dev" # hpa.autoscaling.knative.dev -
特定的Revision:使用注解“autoscaling.knative.dev/class”
apiVersion: serving.knative.dev/v1 kind: Service metadata:name: helloworld-gonamespace: default spec:template:metadata:annotations:autoscaling.knative.dev/class: "kpa.autoscaling.knative.dev"spec:containers:- image: ghcr.io/knative/helloworld-go:latest
-
-
可用的指标
- KPA:concurrency和rps,默认是concurrency
- HPA:cpu、memory和custom
6.2 Autoscaler的全局配置
- 全局配置参数定义在knative-serving名称空间中的configmap/auto-scaler之中
- 相关参数
- container-concurrency-target-default:实例的目标并发数,即最大并发数,默认值为100;
- container-concurrency-target-percentage:实例的目标利用率,默认为“0.7” ;
- enable-scale-to-zero:是否支持缩容至0,默认为true;仅KPA支持;
- max-scale-up-rate:最大扩容速率,默认为1000;
- 当前可最大扩容数 = 最大扩容速率 * Ready状态的Pod数量
- max-scale-down-rate:最大缩容速率,默认为2
- 当前可最大缩容数 = Ready状态的Pod数量 / 最大缩容速率
- panic-window-percentage:Panic窗口期时长相当于Stable窗口期时长的百分比,默认为10,即百分之十;
- panic-threshold-percentage:因Pod数量偏差而触发Panic阈值百分比,默认为200,即2倍;
- scale-to-zero-grace-period:缩容至0的宽限期,即等待最后一个Pod删除的最大时长,默认为30s;
- scale-to-zero-pod-retention-period:决定缩容至0后,允许最后一个Pod处于活动状态的最小时长,默认为0s;
- stable-window:稳定窗口期的时长,默认为60s;
- target-burst-capacity:突发请求容量,默认为200;
- requests-per-second-target-default:每秒并发(RPS)的默认值,默认为200;使用rps指标时生效;
6.3 配置支持缩容至0实例
-
配置支持Revision自动缩放至0实例的参数
- enable-scale-to-zero:不支持Revision级别的配置
- scale-to-zero-grace-period:不支持Revision级别的配置
- scale-to-zero-pod-retention-period:◆Revision级别配置时,使用注解键“autoscaling.knative.dev/scale-to-zero-pod-retention-period”
-
配置示例
apiVersion: serving.knative.dev/v1 kind: Service metadata:name: hellonamespace: default spec:template:metadata:annotations:autoscaling.knative.dev/scale-to-zero-pod-retention-period: "1m5s" ## Reviision级别配置实例缩容为0spec:containers:- image: ikubernetes/helloworld-goports:- containerPort: 8080env:- name: TARGETvalue: "Knative Autoscaling Scale-to-Zero"
6.4 配置实例并发数
-
单实例并发数相关的设定参数
- 软限制:流量突发尖峰期允许超出
- 全局默认配置参数:container-concurrency-target-default
- Revision级的注解:autoscaling.knative.dev/target
- 硬限制:不允许超出,达到上限的请求需进行缓冲
- 全局默认配置参数:container-concurrency:位于config-defaults中
- Revision级的注解:containerConcurrency
- Target目标利用率
- 全局配置参数:container-concurrency-target-percentage
- Revision级的注解:autoscaling.knative.dev/target-utilization-percentage
- 软限制:流量突发尖峰期允许超出
-
配置案例
-
场景:配置ksvc/hello的实例目标并发为10,利用率为0.6. 现在用
hey压测发送20个并发。理论上来说,有4个pod会创建。 -
实例并发数的配置清单
apiVersion: serving.knative.dev/v1 kind: Service metadata:name: hellonamespace: default spec:template:metadata:annotations:autoscaling.knative.dev/target-utilization-percentage: "60" # 实际每个pod接收的并发也就10*0.6autoscaling.knative.dev/target: "10" #最大并发10spec:containers:- image: ikubernetes/helloworld-goports:- containerPort: 8080env:- name: TARGETvalue: "Knative Autoscaling Concurrency" -
用hey工具进行20并发请求
hey -z 60s -c 20 -host "hello.default.icloud2native.com" http://192.168.58.100?sleep=100&prime=10000&bloat=5 -
结论发现确实有4个实例创建,符合预期

-
6.5 配置Revision的扩缩容边界
-
相关的配置参数
- 最小实例数
- Revision级别的Annotation: autoscaling.knative.dev/min-scale:说明:KPA且支持缩容至0时,该参数的默认值为0;其它情况下,默认值为1;
- 最大实例数
- 全局参数:max-scale
- Revision级别的Annotation: autoscaling.knative.dev/max-scale:整数型取值,0表示无限制
- 初始规模:创建Revision,需要立即初始创建的实例数,满足该条件后Revision才能Ready,默认值为1;
- 全局参数:initial-scale和allow-zero-initial-scale
- Revision级别的Annotation:autoscaling.knative.dev/initial-scale:其实际规模依然可以根据流量进行自动调整
- 缩容延迟:时间窗口,在应用缩容决策前,该时间窗口内并发请求必须处于递减状态,取值范围[0s, 1h]
- 全局参数:scale-down-delay
- Revision级别的Annotation:autoscaling.knative.dev/scale-down-delay
- Stable窗口期:取值范围[6s, 1h]
- 全局参数:stable-window
- Revision级别的Annotation: autoscaling.knative.dev/window
- 最小实例数
-
配置案例
-
配置ksvc/hello的实例目标并发为10,利用率为0.6. 现在用
hey压测发送50个并发。理论上来说,有9个pod会创建。但是,我们定义的最大扩容实例为3个,所以,多余的请求会在QP中缓冲 -
扩缩容边界的配置清单
apiVersion: serving.knative.dev/v1 kind: Service metadata:name: hellonamespace: default spec:template:metadata:annotations:autoscaling.knative.dev/target-utilization-percentage: "60"autoscaling.knative.dev/target: "10"autoscaling.knative.dev/max-scale: "3"autoscaling.knative.dev/initial-scale: "1"autoscaling.knative.dev/scale-down-delay: "1m"autoscaling.knative.dev/stable-window: "60s"spec:containers:- image: ikubernetes/helloworld-goports:- containerPort: 8080env:- name: TARGETvalue: "Knative Autoscaling Scale Bounds" -
hey -z 50s -c 50 -host "hello.default.icloud2native.com" http://192.168.58.100?sleep=100&prime=10000&bloat=5 -
可以发现,最多有3个pod创建

-
6.6 使用rps指标
-
相关的配置参数
- 定义使用rps指标
- Revision级别的Annotation:autoscaling.knative.dev/metric:取值为RPS;
- 为rps指标指定目标请求数
- 全局参数:requests-per-second-target-default
- Revision级别的Annotation:autoscaling.knative.dev/target:整数取值,默认值为200
- 定义使用rps指标
-
配置示例
-
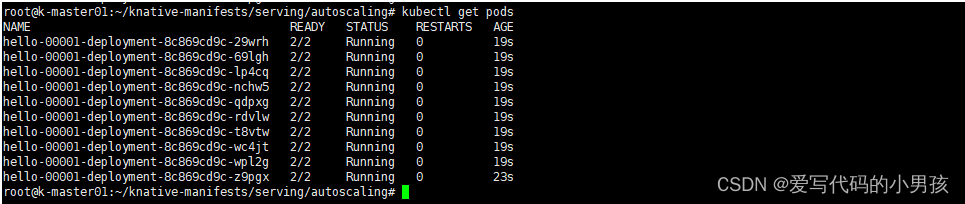
场景:配置ksvc/hello的实例目标并发为100,利用率为0.6. 现在用
hey压测模拟在60秒内以20的并发请求,总共加起来1200个请求。理论上来说,有20个pod会创建。但是,我们定义的最大扩容实例为10个,所以,多余的请求会在QP中缓冲 -
rps的配置清单
apiVersion: serving.knative.dev/v1 kind: Service metadata:name: hellonamespace: default spec:template:metadata:annotations:autoscaling.knative.dev/target-utilization-percentage: "60"autoscaling.knative.dev/metric: "rps"autoscaling.knative.dev/target: "100"autoscaling.knative.dev/max-scale: "10"autoscaling.knative.dev/initial-scale: "1"autoscaling.knative.dev/stable-window: "2m"spec:containers:- image: ikubernetes/helloworld-goports:- containerPort: 8080env:- name: TARGETvalue: "Knative Autoscaling Metrics and Targets" -
使用如下测试命令,模拟在60秒内,以20的并发向hello KService发起请求
hey -z 60s -c 20 -host "hello.default.icloud2native.com" http://192.168.58.100?sleep=100&prime=10000&bloat=5 -
验证:相应Revision上的实例数量会扩展至多个,但最多不超过10个
-