文章目录
-
- 监控相关 API
-
- 查看健康状况
- 查看所有节点
- 查看所有节点详细信息
- 查看主节点
- 查看所有索引
- 查看所有分片
- 索引管理
-
- 创建索引
- 查看索引
- 查看索引字段类型
- 修改索引字段
- 删除索引
- 别名
-
- 给索引添加别名
- 查询某个索引下的别名
- 给索引更换别名
- 给索引解绑别名
- 一个别名绑定多个索引
- 查询`index_name_alias`别名指向哪些索引,哪些别名指向索引`index_name`
- 索引模板
-
- 索引模板的用途
- 查看模板
- 创建模板
- 删除模板
- 文档管理
-
- 创建文档
- 查询文档
- 修改文档
- 删除文档
- 文档查询
-
- 全文查询
-
- `match_all`查询
- `match`查询
- `multi_match`查询
- `match_phrase`查询
- `match_phrase_prefix`查询
- `match`查询相关总结
- 词项查询
-
- `term`查询
- `terms`查询
- `range`查询
- `exists` 查询
- `wildcard`查询
- `fuzzy`查询
- `ids`查询
- `count`查询
- 复合查询
-
- `bool`查询
- 分页查询
-
- `from + size`浅分页
- `scroll`深分页
- `search_after`深分页
- 批量操作
-
- `multi get`查询
- `bulk`批量操作
- 其他查询
- 复杂条件修改/删除
-
- `_update_by_query`条件修改
- `_delete_by_query`条件删除
- 排序
-
- 字段的值排序
- 多字段排序
- 多值字段的排序
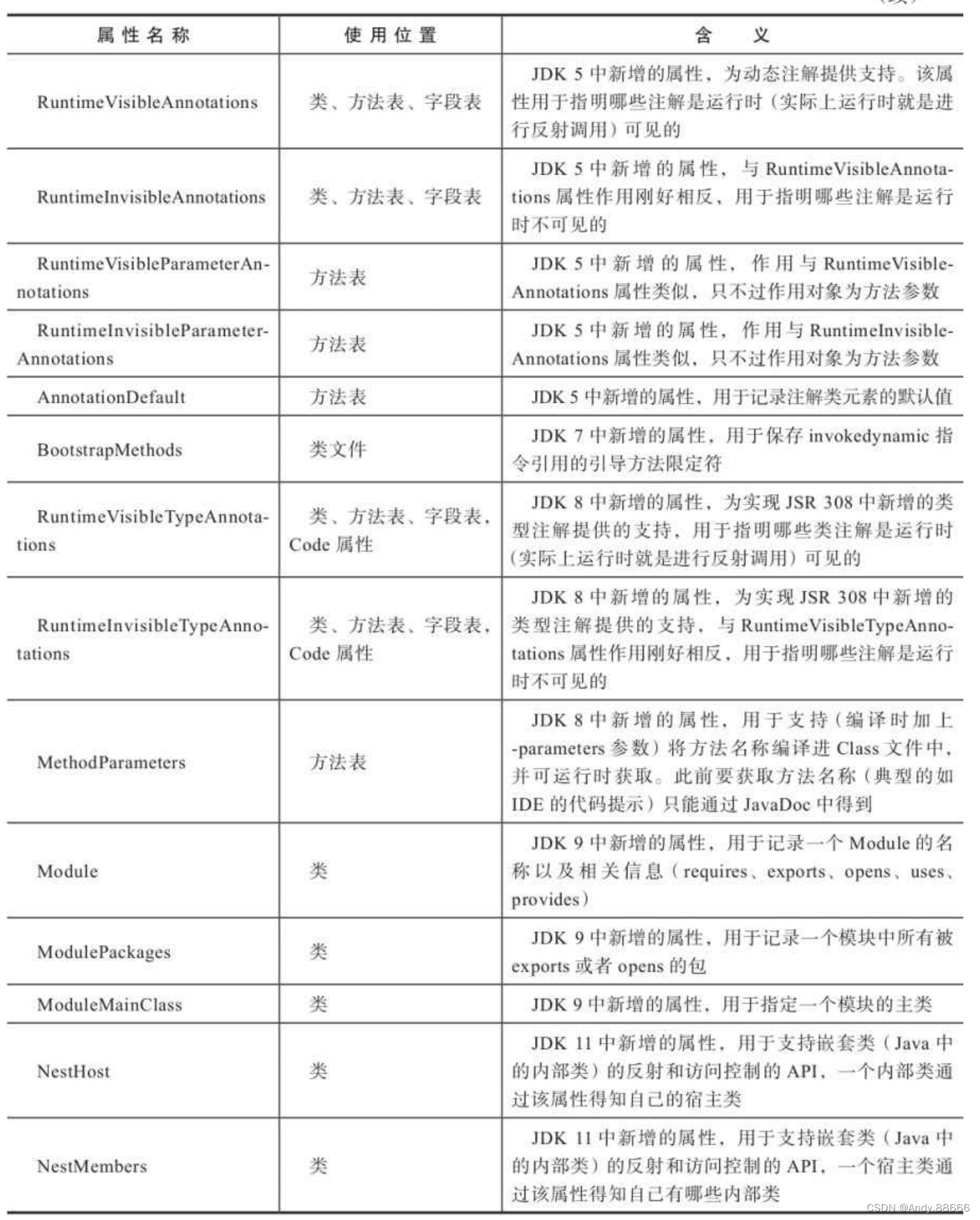
监控相关 API
Elasticsearch 中集群相关的健康、统计等相关的信息都是围绕着 _cat API 进行的。
# 监控相关 API
# 查看健康状况
GET /_cat/health?v# 查看所有节点
GET /_cat/nodes?v# 查看所有节点详细信息
GET /_nodes/process# 查看主节点
GET /_cat/master?v# 查看所有索引
GET /_cat/indices?v# 查看所有分片
GET /_cat/shards?v查看健康状况
# 查看健康状况
GET /_cat/health?v# 输出结果
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1677899229 03:07:09 bigdata yellow 1 1 1364 1364 0 0 939 0 - 59.2%# 名词解释
epoch 时间戳,单位秒
timestamp 时间戳,时分秒
cluster 集群名称
status 集群状态 green代表健康;yellow代表分配了所有主分片 但至少缺少一个副本 此时集群数据仍旧完整;red代表部分主分片不可用 可能已经丢失数据
node.total 在线的节点总数量
node.data 在线的数据节点的数量
shards active_shards 存活的分片数量
pri active_primary_shards 存活的主分片数量 正常情况下 shards的数量是pri的两倍
relo relocating_shards 迁移中的分片数量 正常情况为 0
init initializing_shards 初始化中的分片数量 正常情况为 0
unassign unassigned_shards 未分配的分片 正常情况为 0
pending_tasks 准备中的任务 任务迁移分片等 正常情况为 0
max_task_wait_time 任务最长等待时间
active_shards_percent 正常分片百分比 正常情况为 100%查看所有节点
# 查看所有节点
GET /_cat/nodes?v# 输出结果
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
172.16.0.1 52 98 11 3.95 3.80 3.74 mdi * host-172.16.0.1# 名词解释
ip node节点的IP
heap.percent 堆内存占用百分比
ram.percent 内存占用百分比
cpu CPU占用百分比
load_1m 1分钟的系统负载
load_5m 5分钟的系统负载
load_15m 15分钟的系统负载
node.role node节点的角色
master 是否是master节点
name 节点名称查看所有节点详细信息
# 查看所有节点详细信息
GET /_nodes/process# 输出结果
{"_nodes" : {"total" : 1,"successful" : 1,"failed" : 0},"cluster_name" : "bigdata","nodes" : {"fTnAAEckRgmCPB8m630_aw" : {"name" : "host-172.16.0.1","transport_address" : "172.16.0.1:9601","host" : "172.16.0.1","ip" : "172.16.0.1","version" : "7.2.1","build_flavor" : "default","build_type" : "rpm","build_hash" : "fe6cb20","roles" : ["master","data","ingest"],"attributes" : {"ml.machine_memory" : "134630465536","xpack.installed" : "true","ml.max_open_jobs" : "20"},"process" : {"refresh_interval_in_millis" : 1000,"id" : 374127,"mlockall" : true}}}
}# 名词解释查看主节点
# 查看主节点
GET /_cat/master?v# 输出结果
id host ip node
fTnAAEckRgmCPB8m630_aw 172.16.0.1 172.16.0.1 host-172.16.0.1# 名词解释
id 节点ID
host 主机名称
ip 主机IP
node 节点名称查看所有索引
# 查看所有索引
GET /_cat/indices?v# 输出结果
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open test_300025 IhhJA7YLSW2hWTnmnFvKrQ 2 1 2 0 30.1kb 30.1kb
yellow open test_600086 nNjwWGPtQVmxb5seAb9R_A 6 1 4999 0 1.5mb 1.5mb
yellow open test_23001 aqYCvNM0Qhe44MzSsdS94Q 6 1 15354429 3164548 7gb 7gb# 名词解释
health 索引的健康状态
status 索引的开启状态
index 索引名字
uuid 索引的uuid
pri 索引的主分片数量
rep 索引的副本分片数量
docs.count 索引下的文档总数
docs.deleted 索引下删除状态的文档数
store.size 主分片+副本分片的大小
pri.store.size 主分片的大小查看所有分片
# 查看所有分片
GET /_cat/shards?v# 输出结果
index shard prirep state docs store ip node
test_001 4 p STARTED 835 336.9kb 172.16.0.1 host-172.16.0.1
test_001 4 r UNASSIGNED
test_001 3 p STARTED 869 352.1kb 172.16.0.1 host-172.16.0.1
test_001 3 r UNASSIGNED
test_001 2 p STARTED 863 352.3kb 172.16.0.1 host-172.16.0.1
test_001 2 r UNASSIGNED
test_001 5 p STARTED 842 338.4kb 172.16.0.1 host-172.16.0.1
test_001 5 r UNASSIGNED
test_001 1 p STARTED 774 323.3kb 172.16.0.1 host-172.16.0.1
test_001 1 r UNASSIGNED
test_001 0 p STARTED 816 331.8kb 172.16.0.1 host-172.16.0.1
test_001 0 r UNASSIGNED # 名词解释
index 索引名称
shard 分片序号
prirep 分片类型,p表示是主分片,r表示是副本分片
state 分片状态
docs 该分片存放的文档数量
store 该分片占用的存储空间大小
ip 该分片所在的服务器ip
node 该分片所在的节点名称索引管理
创建索引
# 创建索引
PUT /index_name
{"settings": {"number_of_shards": 2,"number_of_replicas": 1},"mappings": {"properties": {"id": {"type": "integer"},"name": {"type": "keyword"},"age": {"type": "long"},"desc": {"type": "text"},"birthday": {"type": "date"}}}
}# 输出结果
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "index_name"
}# 名词解释
settings索引的配置(可用于配置分片数和副本数)、以及mappings字段映射查看索引
# 查看索引
GET /index_name# 输出结果
{"index_name" : {"aliases" : { },"mappings" : {"properties" : {"age" : {"type" : "long"},"birthday" : {"type" : "date"},"desc" : {"type" : "text"},"id" : {"type" : "integer"},"name" : {"type" : "keyword"},"title" : {"type" : "text"}}},"settings" : {"index" : {"creation_date" : "1677902431250","number_of_shards" : "2","number_of_replicas" : "1","uuid" : "bUWxBreMQ8KnL2ivXm7htQ","version" : {"created" : "7020199"},"provided_name" : "index_name"}}}
}查看索引字段类型
# 查看索引字段类型
GET /index_name/_mapping# 输出结果
{"index_name" : {"mappings" : {"properties" : {"age" : {"type" : "long"},"birthday" : {"type" : "date"},"desc" : {"type" : "text"},"id" : {"type" : "integer"},"name" : {"type" : "keyword"},"title" : {"type" : "text"}}}}
}# 修改索引配置
PUT /index_name/_settings
{"number_of_replicas": 2
}# 输出结果
{"acknowledged" : true
}修改索引字段
注:只能新增字段,不能删除字段
# 修改索引字段
POST /index_name/_mapping
{"properties": {"title": {"type": "text"}}
}# 输出结果
{"acknowledged" : true
}删除索引
# 删除索引
DELETE /index_name# 输出结果
{"acknowledged" : true
}别名
给索引添加别名
# 给索引index_name添加别名index_name_alias,文档查询的时候可以使用别名作为索引进行查询
POST /_aliases
{"actions": [{"add": {"index": "index_name","alias": "index_name_alias"}}]
}# 输出结果
{"acknowledged" : true
}查询某个索引下的别名
# 查询某个索引下的别名
GET /index_name/_alias# 输出结果
{"index_name" : {"aliases" : {"index_name_alias" : { }}}
}给索引更换别名
# 给索引更换别名
POST /_aliases
{"actions": [{"remove": {"index": "index_name","alias": "index_name_alias"}},{"add": {"index": "index_name","alias": "index_name_alias1"}}]
}# 输出结果
{"acknowledged" : true
}给索引解绑别名
# 给索引解绑别名
POST /_aliases
{"actions": [{"remove": {"index": "index_name","alias": "index_name_alias1"}}]
}# 输出结果
{"acknowledged" : true
}一个别名绑定多个索引
# 一个别名绑定多个索引(如果一个别名绑定多个索引,通过别名进行文档查询的时候会报错)
POST /_aliases
{"actions": [{"add": {"index": "index_name","alias": "index_name_alias"}},{"add": {"index": "index_name1","alias": "index_name_alias"}}]
}# 输出结果
{"acknowledged" : true
}查询index_name_alias别名指向哪些索引,哪些别名指向索引index_name
# 查询index_name_alias别名指向哪些索引
GET /_alias/index_name_alias# 哪些别名指向索引index_name
GET /index_name_alias/_alias# 上面两个语句输出结果都如下
{"index_name1" : {"aliases" : {"index_name_alias" : { }}},"index_name" : {"aliases" : {"index_name_alias" : { }}}
}索引模板
索引模板:把已经创建好的某个索引的参数设置(settings)和字段映射(mapping)保存下来作为模板,在创建新索引时,指定要使用的模板名,就可以直接重用已经定义好的模板中的设置和映射
索引模板的用途
- 索引模板一般用在时间序列相关的索引中
- 索引模板一般与索引别名一起使用
查看模板
# 查看所有模板
GET _template
# 查看所有模板名称
GET _cat/templates?v&h=name
# 查看与通配符相匹配的模板
GET _template/temp*
# 查看多个模板
GET _template/temp1,temp2
# 查看指定模板
GET _template/test_template# 判断模板是否存在
HEAD _template/test_template
结果说明:
a) 如果存在,响应结果是: 200 - OK
b) 如果不存在,响应结果是: 404 - Not Found创建模板
PUT _template/test_template
{# 可以通过"logging_status_*"和"logging_index_*"和"logging_usercenter_*"来适配,比如:创建索引的时候可以使用PUT /logging_status_20230720直接创建索引,logging_status_20230720的参数设置和字段映射和模板一样"index_patterns": ["logging_status_*","logging_index_*","logging_usercenter_*"],# 模板的权重,多个模板的时候优先匹配用,值越大,权重越高"order": 0,# 参数设置"settings": {"number_of_shards": 1},# 索引别名"aliases": {"alias_1": {}},# 字段映射"mappings": {"properties": {"id": {"type": "integer"},"name": {"type": "keyword"},"price": {"type": "integer"}}}
}创建模板之后,创建索引的时候可以使用PUT /logging_status_20230720直接创建索引,logging_status_20230720的参数设置和字段映射和模板一样
删除模板
# 删除指定索引模板
DELETE _template/test_template文档管理
区别:put文档必须要指定文档_id;post可指定,可不指定,不指定则会随机生成一个_id
情况1:如果没有提前设定索引中字段类型而直接添加文档,es会对字段数据给自动数据类型,新字段会永久补充进去mapping。
情况2:如果添加的数据字段数量大于提前设定索引中字段数量,可成功,按情况1处理。
情况3:如果添加的数据字段数量小于提前设定索引中字段数量,可成功。
创建文档
put指定id(有则修改,无则创建)
PUT /index_name/_doc/1
{"id": 1001,"name": "张三","age": 12,"desc": "我的自我描述","birthday": "2020-02-02"
}# 输出结果
{"_index" : "index_name","_type" : "_doc","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 3,"successful" : 1,"failed" : 0},"_seq_no" : 4,"_primary_term" : 1
}# 第二次执行输出结果
{"_index" : "index_name","_type" : "_doc","_id" : "1","_version" : 2,"result" : "updated","_shards" : {"total" : 3,"successful" : 1,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1
}post指定id(有则修改,无则创建)
POST /index_name/_doc/3
{"id": 1002,"name": "张三","age": 12,"desc": "我的自我描述","birthday": "2020-02-02"
}# 输出结果
{"_index" : "index_name","_type" : "_doc","_id" : "3","_version" : 4,"result" : "created","_shards" : {"total" : 3,"successful" : 1,"failed" : 0},"_seq_no" : 9,"_primary_term" : 1
}# 第二次执行输出结果
{"_index" : "index_name","_type" : "_doc","_id" : "3","_version" : 2,"result" : "updated","_shards" : {"total" : 3,"successful" : 1,"failed" : 0},"_seq_no" : 7,"_primary_term" : 1
}post不指定id,自动生成文档id(每次执行都是创建新的文档)
POST /index_name/_doc
{"id":1003,"name":"张三","age":12,"desc":"我的自我描述","birthday":"2020-02-02"
}# 输出结果
{"_index" : "index_name","_type" : "_doc","_id" : "WWTbrIYBhncLYm9cw3Li","_version" : 1,"result" : "created","_shards" : {"total" : 3,"successful" : 1,"failed" : 0},"_seq_no" : 10,"_primary_term" : 1
}# 第二次执行输出结果
{"_index" : "index_name","_type" : "_doc","_id" : "NmTcrIYBhncLYm9cVnii","_version" : 1,"result" : "created","_shards" : {"total" : 3,"successful" : 1,"failed" : 0},"_seq_no" : 11,"_primary_term" : 1
}PUT和POST请求的区别:
-
POST理解为新增或更新,PUT理解为更新。因此,在PUT中需要指定id。而POST的话,不指定id(ES会自动生成文档id),指定id(有则修改,无则创建)
-
PUT会将新的json值完全替换掉旧的;而POST方式不指定
_update参数新的json值完全替换掉旧的,带_update参数可以更新相同字段的值,其他数据不会改变,新提交的字段若不存在则增加。 -
PUT和DELETE操作是幂等的。所谓幂等是指不管进行多少次操作,结果都一样。比如用PUT修改一篇文章,然后在做同样的操作,每次操作后的结果并没有什么不同,DELETE也是一样。POST操作不是幂等的,比如常见的POST重复加载问题:当我们多次发出同样的POST请求后,其结果是创建了若干的资源。
查询文档
查询所有文档
# 查询所有文档
GET /index_name/_search# 输出结果
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 2,"successful" : 2,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "index_name","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"id" : 1001,"name" : "张三","age" : 12,"desc" : "我的自我描述","birthday" : "2020-02-02"}}]}
}查询指定id文档
# 查询指定id文档
GET /index_name/_doc/1# 通过别名查询文档
GET /index_name_alias/_doc/1# 上面两个语句输出结果都如下
{"_index" : "index_name","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 4,"_primary_term" : 1,"found" : true,"_source" : {"id" : 1001,"name" : "张三","age" : 12,"desc" : "我的自我描述","birthday" : "2020-02-02"}
}修改文档
全修改:PUT和POST都可以,全部字段均会被修改更新,未修改的字段会置为空
# 全修改:PUT和POST都可以,全部字段均会被修改更新,未修改的字段会置为空
POST /index_name/_doc/1
{"id": 1005,"name": "李四","age": 13,"desc": "我的自我描述4"
}# 输出结果
{"_index" : "index_name","_type" : "_doc","_id" : "1","_version" : 3,"result" : "updated","_shards" : {"total" : 3,"successful" : 1,"failed" : 0},"_seq_no" : 12,"_primary_term" : 1
}部分修改:POST,只修改部分字段数据
# 部分修改:POST,只修改部分字段数据
POST /index_name/_update/3
{"doc": {"name": "赵六"}
}# 输出结果
{"_index" : "index_name","_type" : "_doc","_id" : "3","_version" : 7,"result" : "updated","_shards" : {"total" : 3,"successful" : 1,"failed" : 0},"_seq_no" : 15,"_primary_term" : 1
}# 第二次执行输出结果
{"_index" : "index_name","_type" : "_doc","_id" : "3","_version" : 7,"result" : "noop","_shards" : {"total" : 0,"successful" : 0,"failed" : 0}
}删除文档
根据id删除指定文档
# 根据id删除指定文档
DELETE /index_name/_doc/1# 输出结果
{"_index" : "index_name","_type" : "_doc","_id" : "1","_version" : 3,"result" : "deleted","_shards" : {"total" : 3,"successful" : 1,"failed" : 0},"_seq_no" : 2,"_primary_term" : 1
}# 第二次执行输出结果
{"_index" : "index_name","_type" : "_doc","_id" : "1","_version" : 4,"result" : "not_found","_shards" : {"total" : 3,"successful" : 1,"failed" : 0},"_seq_no" : 3,"_primary_term" : 1
}根据查询条件删除部分文档
# 根据查询条件删除部分文档
POST /index_name/_delete_by_query
{"query": {"bool": {"filter": [{"range": {"birthday": {"gte": "2020-06-01"}}}]}}
}# 输出结果
{"took" : 6,"timed_out" : false,"total" : 2,"deleted" : 2,"batches" : 1,"version_conflicts" : 0,"noops" : 0,"retries" : {"bulk" : 0,"search" : 0},"throttled_millis" : 0,"requests_per_second" : -1.0,"throttled_until_millis" : 0,"failures" : [ ]
}# 第二次执行输出结果
{"took" : 4,"timed_out" : false,"total" : 0,"deleted" : 0,"batches" : 0,"version_conflicts" : 0,"noops" : 0,"retries" : {"bulk" : 0,"search" : 0},"throttled_millis" : 0,"requests_per_second" : -1.0,"throttled_until_millis" : 0,"failures" : [ ]
}删除索引中所有的文档
注:危险操作
# 删除索引中所有的文档
POST /index_name/_delete_by_query
{"query": {"match_all": {}}
}# 输出结果
{"took" : 7,"timed_out" : false,"total" : 4,"deleted" : 4,"batches" : 1,"version_conflicts" : 0,"noops" : 0,"retries" : {"bulk" : 0,"search" : 0},"throttled_millis" : 0,"requests_per_second" : -1.0,"throttled_until_millis" : 0,"failures" : [ ]
}文档查询
Elasticsearch 查询分类大致分为全文查询、词项查询、复合查询、嵌套查询、地理位置查询、特殊查询。
全文查询
匹配查询match
match和term的区别是,match查询的时候,elasticsearch会根据你给定的字段提供合适的分析器,而term查询不会有分析器分析的过程,match查询相当于模糊匹配,只包含其中一部分关键词就行
同时还要注意match系列匹配时,datatype要设置为text,否则不会开启分词
match_all查询
查询匹配所有的文档
# 查询匹配所有的文档
GET /index_name/_search
{"query": {"match_all": {}}
}# 输出结果
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 2,"successful" : 2,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 5,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "index_name","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"id" : 1001,"name" : "张三","age" : 12,"desc" : "我的自我描述","birthday" : "2020-02-02"}},{"_index" : "index_name","_type" : "_doc","_id" : "KWcyrYYBhncLYm9cWbGB","_score" : 1.0,"_source" : {"id" : 1002,"name" : "李四","age" : 13,"desc" : "我的自我描2述","birthday" : "2023-02-03"}},{"_index" : "index_name","_type" : "_doc","_id" : "G2cyrYYBhncLYm9cmrSc","_score" : 1.0,"_source" : {"id" : 1003,"name" : "王五","age" : 14,"desc" : "我的自我述3","birthday" : "2023-02-03"}},{"_index" : "index_name","_type" : "_doc","_id" : "2mc5rYYBhncLYm9cifcv","_score" : 1.0,"_source" : {"id" : 1003,"name" : "王五","age" : 14,"desc" : "超人","birthday" : "2023-02-04"}},{"_index" : "index_name","_type" : "_doc","_id" : "Rmc5rYYBhncLYm9c_fxA","_score" : 1.0,"_source" : {"id" : 1005,"name" : "王五","age" : 14,"desc" : "超人的平凡人生","birthday" : "2023-02-04"}}]}
}match查询
支持全文检索和精确查询,取决于字段是否支持全文检索,字段类型为text支持全文检索
当一个字段需要用于全文搜索(会被分词), 比如产品名称、产品描述信息,就应该使用text类型
当一个字段需要按照精确值进行过滤、排序、聚合等操作时,就应该使用keyword类型
全文检索
# 全文检索,desc字段类型是text,支持全文检索,全文检索会将查询的字符串先进行分词,会将desc字段值包含[我,的,我的]的文档都查询出来
GET /index_name/_search
{"query": {"match": {"desc": "我的"}}
}# 输出结果
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 2,"successful" : 2,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 0.8084657,"hits" : [{"_index" : "index_name","_type" : "_doc","_id" : "1","_score" : 0.8084657,"_source" : {"id" : 1001,"name" : "张三","age" : 12,"desc" : "我的自我描述","birthday" : "2020-02-02"}},{"_index" : "index_name","_type" : "_doc","_id" : "G2cyrYYBhncLYm9cmrSc","_score" : 0.8084657,"_source" : {"id" : 1003,"name" : "王五","age" : 14,"desc" : "我的自我述3","birthday" : "2023-02-03"}},{"_index" : "index_name","_type" : "_doc","_id" : "KWcyrYYBhncLYm9cWbGB","_score" : 0.7622653,"_source" : {"id" : 1002,"name" : "李四","age" : 13,"desc" : "我的自我描2述","birthday" : "2023-02-03"}},{"_index" : "index_name","_type" : "_doc","_id" : "Rmc5rYYBhncLYm9c_fxA","_score" : 0.2876821,"_source" : {"id" : 1005,"name" : "王五","age" : 14,"desc" : "超人的平凡人生","birthday" : "2023-02-04"}}]}
}精确查询
# 精确查询,name字段类型是keyword,name字段值必须完全匹配[李四]才能查询出来,查询[李]或者[四]都没有没有结果返回的,因为keyword类型字段不会进行分词
GET /index_name/_search
{"query": {"match": {"name": "李四"}}
}# 输出结果
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 2,"successful" : 2,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.2039728,"hits" : [{"_index" : "index_name","_type" : "_doc","_id" : "KWcyrYYBhncLYm9cWbGB","_score" : 1.2039728,"_source" : {"id" : 1002,"name" : "李四","age" : 13,"desc" : "我的自我描2述","birthday" : "2023-02-03"}}]}
}精确度匹配
match 查询支持 minimum_should_match 最小匹配参数, 可以指定必须匹配的词项数用来表示一个文档是否相关。我们可以将其设置为某个具体数字(指需要匹配倒排索引的词的数量),更常用的做法是将其设置为一个百分数,因为我们无法控制用户搜索时输入的单词数量
# 精确度匹配
GET /index_name/_search
{"query": {"match": {"desc": {"query": "超 人","minimum_should_match": "2"}}}
}# 输出结果
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 2,"successful" : 2,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 3.2245533,"hits" : [{"_index" : "index_name","_type" : "_doc","_id" : "2mc5rYYBhncLYm9cifcv","_score" : 3.2245533,"_source" : {"id" : 1003,"name" : "王五","age" : 14,"desc" : "超人","birthday" : "2023-02-04"}},{"_index" : "index_name","_type" : "_doc","_id" : "Rmc5rYYBhncLYm9c_fxA","_score" : 0.68324494,"_source" : {"id" : 1005,"name" : "王五","age" : 14,"desc" : "超人的平凡人生","birthday" : "2023-02-04"}}]}
}只会返回匹配上超和人两个词的文档返回,如果minimum_should_match是1,则只要匹配上其中一个词,文档就会返回
正向匹配度-使用百分比
比如"minimum_should_match":75%,可以配置一个百分比,至少optional clauses(可选子句)至少满足75%,这里是向下取整的。
比如有5个clause,5*75%=3.75,向下取整为3,也就是至少需要match 3个clause。
注意:由于是向下取整,所以尤其针对短的query,我们把"minimum_should_match"设为大于100% 还是可以得到结果(如下,130*3=3.90,向下取整为3)
# 正向匹配度-使用百分比
GET /index_name/_search
{"query": {"match": {"desc": {"query": "超 人 的","minimum_should_match": "130%"}}}
}# 输出结果
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 2,"successful" : 2,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.97092706,"hits" : [{"_index" : "index_name","_type" : "_doc","_id" : "Rmc5rYYBhncLYm9c_fxA","_score" : 0.97092706,"_source" : {"id" : 1005,"name" : "王五","age" : 14,"desc" : "超人的平凡人生","birthday" : "2023-02-04"}}]}
}multi_match查询
多字段查询,比如查询name和desc字段包含单词的的文档
# 多字段查询
GET /index_name/_search
{"query": {"multi_match": {"query": "的","fields": ["name","desc"]}}
}# 输出结果
{"took" : 25,"timed_out" : false,"_shards" : {"total" : 2,"successful" : 2,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 0.33698124,"hits" : [{"_index" : "index_name","_type" : "_doc","_id" : "1","_score" : 0.33698124,"_source" : {"id" : 1001,"name" : "张三","age" : 12,"desc" : "我的自我描述","birthday" : "2020-02-02"}},{"_index" : "index_name","_type" : "_doc","_id" : "G2cyrYYBhncLYm9cmrSc","_score" : 0.33698124,"_source" : {"id" : 1003,"name" : "王五","age" : 14,"desc" : "我的自我述3","birthday" : "2023-02-03"}},{"_index" : "index_name","_type" : "_doc","_id" : "KWcyrYYBhncLYm9cWbGB","_score" : 0.31387398,"_source" : {"id" : 1002,"name" : "李四","age" : 13,"desc" : "我的自我描2述","birthday" : "2023-02-03"}},{"_index" : "index_name","_type" : "_doc","_id" : "Rmc5rYYBhncLYm9c_fxA","_score" : 0.2876821,"_source" : {"id" : 1005,"name" : "王五","age" : 14,"desc" : "超人的平凡人生","birthday" : "2023-02-04"}}]}
}match_phrase查询
match_phrase查询首先会把 query 内容分词,分词器可以自定义,同时文档还要满足以下两个条件才会被搜索到:
- 分词后所有词项都要出现在该字段中(相当于 and 操作)。
- 字段中的词项顺序要一致。
例如,有以下 3 个文档,使用 match_phrase查询what a wonderful life,只有第二个文档会被匹配:
# 新增文档
PUT /test_idx/1
{"desc": "what a wonderful life"
}PUT /test_idx/2
{"desc": "what a life"
}PUT /test_idx/3
{"desc": "life is what"
}# 短语查询
GET /test_idx/_search
{"query": {"match_phrase": {"desc": "a life"}}
}# 输出结果
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 2,"successful" : 2,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.62927824,"hits" : [{"_index" : "test_idx","_type" : "_doc","_id" : "2","_score" : 0.62927824,"_source" : {"desc" : "what a life"}}]}
}match_phrase_prefix查询
match_phrase_prefix 和 match_phrase 类似,只不过 match_phrase_prefix 支持最后一个 term 的前缀匹配。
# 新增文档
PUT /test_idx/_doc/4
{"desc": "lifeabc is what"
}PUT /test_idx/_doc/5
{"desc": "asdflifeabc is what"
}# 前缀查询
GET test_idx/_search
{"query": {"match_phrase_prefix": {"desc": "life"}}
}# 输出结果
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 2,"successful" : 2,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 0.36826366,"hits" : [{"_index" : "test_idx","_type" : "_doc","_id" : "2","_score" : 0.36826366,"_source" : {"desc" : "what a life"}},{"_index" : "test_idx","_type" : "_doc","_id" : "3","_score" : 0.36826366,"_source" : {"desc" : "life is what"}},{"_index" : "test_idx","_type" : "_doc","_id" : "1","_score" : 0.32590747,"_source" : {"desc" : "what a wonderful life"}},{"_index" : "test_idx","_type" : "_doc","_id" : "4","_score" : 0.2876821,"_source" : {"desc" : "lifeabc is what"}}]}
}match查询相关总结
1、match:返回所有匹配的分词。
2、match_all:查询全部。
3、match_phrase:短语查询,在match的基础上进一步查询词组,可以指定slop分词间隔。
4、match_phrase_prefix:前缀查询,根据短语中最后一个词组做前缀匹配,可以应用于搜索提示,但注意和max_expanions搭配使用。
5、multi_match:多字段查询,使用相当的灵活,可以完成match_phrase和match_phrase_prefix的工作。
词项查询
term查询
精确值查询
查询price字段等于6000的文档
# 新增三个文档
PUT /ad/_doc/1
{"name":"phone 8","price": 6000,"color":"white","ad":"this is a white phone","label":["white","nice"]
}PUT /ad/_doc/2
{"name":"xiaomi 8","price": 4000,"color":"red","ad":"this is a red phone","label":["white","xiaomi"]
}PUT /ad/_doc/3
{"name":"huawei p30","price": 5000,"color":"white","ad":"this is a white phone","label":["white","huawei"]
}# 查询price字段等于6000的文档
GET /ad/_search
{"query": {"term": {"price": {"value": "6000"}}}
}# 输出结果
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "ad","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "phone 8","price" : 6000,"color" : "white","ad" : "this is a white phone","label" : ["white","nice"]}}]}
}查询name字段等于phone 8的文档
# 查询name字段等于phone 8的文档
GET /ad/_search
{"query": {"term": {"name": {"value": "phone 8"}}}
}# 输出结果
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]}
}避免 term 查询对 text 字段使用查询。
默认情况下,Elasticsearch 针对 text 字段的值进行解析分词,这会使查找 text 字段值的精确匹配变得困难。
要搜索 text 字段值,需改用 match 查询。
为什么没有查到phone 8的这个文档呢,这里需要介绍一下term的查询原理
term查询会去倒排索引中寻找确切的term,它并不会走分词器,只会去匹配倒排索引 ,而name字段的type类型是text,会进行分词,将phone 8 分为phone和8,我们使用term查询phone 8时倒排索引中没有phone 8,所以没有查询到匹配的文档
term查询与match查询的区别
term查询时,不会分词,直接匹配倒排索引match查询时会进行分词,查询phone 8时,会先分词成phone和8,然后去匹配倒排索引,所以结果会将phone 8和xiaomi 8两个文档都查出来
还有一点需要注意,因为term查询不会走分词器,但是会去匹配倒排索引,所以查询的结构就跟分词器如何分词有关系,比如新增一个/ad的文档,name字段赋值为Oppo,这时使用term查询Oppo不会查询出文档,这时因为es默认是用的standard分词器,它在分词后会将单词转成小写输出,所以使用Oppo查不出文档,使用小写oppo可以查出来
# 新增文档
PUT /ad/_doc/4
{"name":"Oppo","price": 3999,"color":"white","ad":"this is a white phone","label":["white","Oppo"]
}# 使用Oppo查询不出文档,改成oppo可以查出新添加的文档
GET /ad/_search
{"query": {"term": {"name": {"value": "Oppo" }}}
}这里说的并不是想让你了解standard分词器,而是要get到所有像term这类的查询结果跟选择的分词器有关系,了解选择的分词器分词方式有助于我们编写查询语句
terms查询
terms查询与term查询一样,但它允许你指定多值进行匹配,如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件
# 新增文档
PUT /ad/_doc/5
{"name":"Vivo","price": 2999,"color":"blue","ad":"this is a blue phone","label":["blue","Vivo"]
}# 查询ad字段包含red或者blue值的文档
GET /ad/_search
{"query": {"terms": {"ad": ["red","blue"]}}
}# 输出结果
{"took" : 29,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "ad","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"name" : "xiaomi 8","price" : 4000,"color" : "red","ad" : "this is a red phone","label" : ["white","xiaomi"]}},{"_index" : "ad","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"name" : "Vivo","price" : 2999,"color" : "blue","ad" : "this is a blue phone","label" : ["blue","Vivo"]}}]}
}range查询
范围查询,查询大于等于12,且小于等于13的文档
# 范围查询
GET /index_name/_search
{"query": {"range": {"age": {"gte": 12,"lte": 13}}}
}# 输出结果
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 2,"successful" : 2,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "index_name","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"id" : 1001,"name" : "张三","age" : 12,"desc" : "我的自我描述","birthday" : "2020-02-02"}},{"_index" : "index_name","_type" : "_doc","_id" : "KWcyrYYBhncLYm9cWbGB","_score" : 1.0,"_source" : {"id" : 1002,"name" : "李四","age" : 13,"desc" : "我的自我描2述","birthday" : "2023-02-03"}}]}
}范围查询操作符:gt (大于),gte(大于等于),lt(小于),lte(小于等于);
exists 查询
用于查询哪些指定字段中有值 (exists)的文档
查询name字段有值的文档
# 查询name字段有值的文档
GET /ad/_search
{"query": {"bool": {"filter": {"exists": {"field": "name"}}}}
}# 输出结果
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 5,"relation" : "eq"},"max_score" : 0.0,"hits" : [{"_index" : "ad","_type" : "_doc","_id" : "1","_score" : 0.0,"_source" : {"name" : "phone 8","price" : 6000,"color" : "white","ad" : "this is a white phone","label" : ["white","nice"]}},{"_index" : "ad","_type" : "_doc","_id" : "2","_score" : 0.0,"_source" : {"name" : "xiaomi 8","price" : 4000,"color" : "red","ad" : "this is a red phone","label" : ["white","xiaomi"]}},{"_index" : "ad","_type" : "_doc","_id" : "3","_score" : 0.0,"_source" : {"name" : "huawei p30","price" : 5000,"color" : "white","ad" : "this is a white phone","label" : ["white","huawei"]}},{"_index" : "ad","_type" : "_doc","_id" : "4","_score" : 0.0,"_source" : {"name" : "Oppo","price" : 3999,"color" : "white","ad" : "this is a white phone","label" : ["white","Oppo"]}},{"_index" : "ad","_type" : "_doc","_id" : "5","_score" : 0.0,"_source" : {"name" : "Vivo","price" : 2999,"color" : "blue","ad" : "this is a blue phone","label" : ["blue","Vivo"]}}]}
}查询name字段无值的文档
# 新增文档
PUT /ad/_doc/6
{"name":"","price": 2999,"color":"black","ad":"this is a black phone","label":["black","unknown"]
}PUT /ad/_doc/7
{"price": 999,"color":"black","ad":"this is a black phone","label":["black","unknown"]
}PUT /ad/_doc/8
{"name": null,"price": 666,"color":"orange","ad":"this is a orange phone","label":["orange","unknown"]
}# 查询出没有name字段或者name字段的值为null的文档
GET /ad/_search
{"query": {"bool": {"must_not": {"exists": {"field": "name"}}}}
}# 输出结果
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 0.0,"hits" : [{"_index" : "ad","_type" : "_doc","_id" : "7","_score" : 0.0,"_source" : {"price" : 999,"color" : "black","ad" : "this is a black phone","label" : ["black","unknown"]}},{"_index" : "ad","_type" : "_doc","_id" : "8","_score" : 0.0,"_source" : {"name" : null,"price" : 666,"color" : "orange","ad" : "this is a orange phone","label" : ["orange","unknown"]}}]}
}# 查询name字段值为空字符,没有name字段或者name字段值为null的文档
GET /ad/_search
{"query": {"bool": {"must_not": [{"wildcard": {"name": {"value": "*"}}}]}}
}# 输出结果
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 0.0,"hits" : [{"_index" : "ad","_type" : "_doc","_id" : "6","_score" : 0.0,"_source" : {"name" : "","price" : 2999,"color" : "black","ad" : "this is a black phone","label" : ["black","unknown"]}},{"_index" : "ad","_type" : "_doc","_id" : "7","_score" : 0.0,"_source" : {"price" : 999,"color" : "black","ad" : "this is a black phone","label" : ["black","unknown"]}},{"_index" : "ad","_type" : "_doc","_id" : "8","_score" : 0.0,"_source" : {"name" : null,"price" : 666,"color" : "orange","ad" : "this is a orange phone","label" : ["orange","unknown"]}}]}
}# 查询name字段值不为空字符串的文档
GET /ad/_search
{"query": {"wildcard": {"name": {"value": "*"}}}
}# 输出结果
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 5,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "ad","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "phone 8","price" : 6000,"color" : "white","ad" : "this is a white phone","label" : ["white","nice"]}},{"_index" : "ad","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"name" : "xiaomi 8","price" : 4000,"color" : "red","ad" : "this is a red phone","label" : ["white","xiaomi"]}},{"_index" : "ad","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"name" : "huawei p30","price" : 5000,"color" : "white","ad" : "this is a white phone","label" : ["white","huawei"]}},{"_index" : "ad","_type" : "_doc","_id" : "4","_score" : 1.0,"_source" : {"name" : "Oppo","price" : 3999,"color" : "white","ad" : "this is a white phone","label" : ["white","Oppo"]}},{"_index" : "ad","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"name" : "Vivo","price" : 2999,"color" : "blue","ad" : "this is a blue phone","label" : ["blue","Vivo"]}}]}
}wildcard查询
wildcard query 中文译为通配符查询,支持通配符的模糊查询,支持单字符通配符和多字符通配符,? 用来匹配一个任意字符,* 用来匹配零个或者多个字符。
以 H?tland 为例,Hatland、Hbtland 等都可以匹配,但是不能匹配 Htland,? 只能代表一位。H*tland 可以匹配 Htland、Habctland 等,* 可以代表 0 至多个字符。和 prefix 查询一样,wildcard 查询的查询性能也不是很高,需要消耗较多的 CPU 资源。
为了防止极其缓慢通配符查询,*或?通配符项不应该放在通配符的开始
# 通配符查询
GET /index_name/_search
{"query": {"wildcard": {"color": "r?d"}}
}fuzzy查询
模糊查询,fuzzy 查询会计算与关键词的拼写相似程度
编辑距离又称 Levenshtein 距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。fuzzy 查询就是通过计算词项与文档的编辑距离来得到结果的,但是使用 fuzzy 查询需要消耗的资源比较大,查询效率不高,适用于需要模糊查询的场景。举例如下,用户在输入查询关键词时不小心把 “javascript” 拼成 “javascritp”,在存在拼写错误的情况下使用模糊查询仍然可以搜索到含有 “javascript” 的文档
# fuzzy查询
GET /ad/_search
{"query": {"fuzzy": {"color":{"value": "res","fuzziness": 2,"prefix_length": 1}}}
}# 输出结果
{"took" : 23,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.3862942,"hits" : [{"_index" : "ad","_type" : "_doc","_id" : "2","_score" : 1.3862942,"_source" : {"name" : "xiaomi 8","price" : 4000,"color" : "red","ad" : "this is a red phone","label" : ["white","xiaomi"]}}]}
}参数设置:
fuzziness:最大编辑距离,默认为AUTO
prefix_length:不会“模糊化”的初始字符数。这有助于减少必须检查的术语数量,默认为0
max_expansions:fuzzy查询将扩展到的最大术语数。默认为50,设置小,有助于优化查询
transpositions:是否支持模糊转置(ab→ ba),默认是false
ids查询
ids query 用于查询具有指定 id 的文档。
GET /index_name/_search
{"query": {"ids": {"values": ["1","2","KWcyrYYBhncLYm9cWbGB"]}}
}# 输出结果
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 2,"successful" : 2,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "index_name","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"id" : 1001,"name" : "张三","age" : 12,"desc" : "我的自我描述","birthday" : "2020-02-02"}},{"_index" : "index_name","_type" : "_doc","_id" : "KWcyrYYBhncLYm9cWbGB","_score" : 1.0,"_source" : {"id" : 1002,"name" : "李四","age" : 13,"desc" : "我的自我描2述","birthday" : "2023-02-03"}}]}
}count查询
count 查询是在 ES 中统计文档数量的一种查询方式。它可以计算指定索引或查询条件内的文档数量。查询方式很简单,只需要把之前_search后缀改成_count即可
# 查询index_name索引所有的文档数量
GET /index_name/_count
{"query": {"match_all": {}}
}复合查询
bool查询
bool 查询可以把任意多个简单查询组合在一起,使用 must、should、must_not、filter 选项来表示简单查询之间的逻辑,每个选项都可以出现 0 次到多次,它们的含义如下:
- must 文档必须匹配 must 选项下的查询条件,相当于逻辑运算的 AND,且参与文档相关度的评分。
- should 文档可以匹配 should 选项下的查询条件也可以不匹配,相当于逻辑运算的 OR,且参与文档相关度的评分。
- must_not 与 must 相反,匹配该选项下的查询条件的文档不会被返回;需要注意的是,must_not 语句不会影响评分,它的作用只是将不相关的文档排除。
- filter 和 must 一样,匹配 filter 选项下的查询条件的文档才会被返回,但是 filter 不评分,只起到过滤功能,与 must_not 相反。
假设要查询 title 中包含关键词 java,并且 price 不能高于 70,description 可以包含也可以不包含虚拟机的书籍,构造 bool 查询语句如下:
# 复合查询
GET /index_name/_search
{"query": {"bool": {"filter": {"term": {"status": 1}},"must_not": {"range": {"price": {"gte": 70}}},"must": {"match": {"title": "java"}},"should": [{"match": {"description": "虚拟机"}}],"minimum_should_match": 1}}
}常见组合查询
1、bool-must-filter结合
查询商户ID为3582,订单号为360102199003072618,按时间范围过滤,按下单时间倒序,每次查询100条
GET /index_name/_search
{"query": {"bool": {"must": [{"term": {"merchant_id": "3582"}},{"term": {"order_num": "360102199003072618"}}],"filter": [{"range": {"order_time": {"from": "2019-11-01T17:00:00+08:00","to": "2019-11-01T20:00:00+08:00"}}}]}},"size": 100,"sort": [{"order_time": "desc"}]
}2、bool-must-should-match
查询venderId值为1234,taskId为1234,字段itemCodes和templateCodes的值至少有一个match匹配到结果,才返回对应数据集。
即must下两个terms同时满足,should下两个match至少满足一条
GET /index_name/_search
{"bool": {"must": [{"terms": {"venderId": ["1234"]}},{"terms": {"taskId": ["1234"]}},{"should": [{"match": {"itemCodes": {"query": "12,124"}}},{"match": {"templateCodes": {"query": "t123,t124,t125"}}}]}]}
}3、bool-must-wildcard-range
根据促销ID和促销名称查询某个时间段的促销,并时间排序
GET /index_name/_search
{"from": 0,"size": 10,"query": {"bool": {"must": [{"term": {"promt_id": {"value": 200352052277}}},{"wildcard": {"promt_name": {"wildcard": "*业务部*"}}},{"range": {"promt_end_time": {"from": "2022-10-01 00:00:00"}}},{"range": {"promt_begin_time": {"to": "2022-10-31 23:59:59"}}}]}},"sort": [{"created_time": {"order": "desc","unmapped_type": "keyword"}}]
}分页查询
from + size浅分页
"浅"分页可以理解为简单意义上的分页。
es是通过协调节点从每个shard中都获取from+size条数据返回给协调节点后,由协调节点汇总排序,然后查找[from , from+size] 之间的数据,并返回給前端。
from:未指定,默认值是 0,注意不是1,代表当前页返回数据的起始偏移量。size:未指定,默认值是 10,代表当前页返回数据的条数。
需要注意的是,from + size 不能超过10000,也就是说在前10000条之内,可以随意翻页,10000条之后就不行了。
实际上,通过设置 index.max_result_window 可以修改这个限制,但是不建议这么做,因为这种方式翻页越深效率越低。
# from+size查询
GET /ad/_search
{"query": {"match_all": {}},"from": 0,"size": 2
}# 输出结果
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 11,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "ad","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "phone 8","price" : 6000,"color" : "white","ad" : "this is a white phone","label" : ["white","nice"]}},{"_index" : "ad","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"name" : "xiaomi 8","price" : 4000,"color" : "red","ad" : "this is a red phone","label" : ["white","xiaomi"]}}]}
}其中,from定义了目标数据的偏移值,size定义当前返回的数目。默认from为0,size为10,即所有的查询默认仅仅返回前10条数据。
在这里有必要了解一下from/size的原理:
因为es是基于分片的,假设有5个分片,from=100,size=10。则会根据排序规则从5个分片中各取回110条数据数据,然后汇总成550条数据排序后的前10条数据。
测试发现,越往后的分页,执行的效率越低。总体上会随着from的增加,消耗时间也会增加。而且数据量越大,就越明显!
scroll深分页
es客户端实时分页一般使用from-size。如果有100条数据,按size=10共分10页,那么当用户查询第n页的时候,实际上es是把前n页的数据全部找出来,再去除前n-1页最后得到需要的数据返回,查最后一页就相当于全扫描。且es一般查询只支持最多查询出前1w条数据。所以离线大批量数据的处理业务或迁移不适合使用from-size方式查询。
为了解决上面的问题,elasticsearch提出了一个scroll滚动的方式。
scroll 类似于sql中的cursor,使用scroll,每次只能获取一页的内容,然后会返回一个scroll_id。根据返回的这个scroll_id可以不断地获取下一页的内容,所以scroll并不适用于有跳页的情景。
# 游标查询
POST /ad/_search?scroll=1m
{"query": {"match_all": {}},"from": 0,"size": 1
}# 输出结果
{"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAcLKwWZlRuQUFFY2tSZ21DUEI4bTYzMF9hdw==","took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 11,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "ad","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "phone 8","price" : 6000,"color" : "white","ad" : "this is a white phone","label" : ["white","nice"]}}]}
}- scroll=1m表示设置scroll_id保留1分钟可用。
- 使用scroll必须要将from设置为0。
- size决定后面每次调用_search搜索返回的数量
然后我们可以通过数据返回的_scroll_id读取下一页内容,每次请求将会读取下1条数据,直到数据读取完毕或者scroll_id保留时间截止:
# 通过_scroll_id读取下一页内容
POST /_search/scroll
{"scroll": "1m","scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAcLKwWZlRuQUFFY2tSZ21DUEI4bTYzMF9hdw=="
}# 输出结果
{"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAcLKwWZlRuQUFFY2tSZ21DUEI4bTYzMF9hdw==","took" : 1,"timed_out" : false,"terminated_early" : true,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 11,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "ad","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"name" : "xiaomi 8","price" : 4000,"color" : "red","ad" : "this is a red phone","label" : ["white","xiaomi"]}}]}
}注意:请求的接口不再使用索引名了,而是 _search/scroll,其中GET和POST方法都可以使用。
scroll删除
根据官方文档的说法,scroll的搜索上下文会在scroll的保留时间截止后自动清除,但是我们知道scroll是非常消耗资源的,所以一个建议就是当不需要了scroll数据的时候,尽可能快的把scroll_id显式删除掉。
清除指定的scroll_id:
DELETE _search/scroll/DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAcLKwWZlRuQUFFY2tSZ21DUEI4bTYzMF9hdw==清除所有的scroll:
DELETE _search/scroll/_allsearch_after深分页
scroll 的方式,官方的建议不用于实时的请求(一般用于数据导出),因为每一个 scroll_id 不仅会占用大量的资源,而且会生成历史快照,对于数据的变更不会反映到快照上。
search_after 分页的方式是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。但是需要注意,因为每一页的数据依赖于上一页最后一条数据,所以无法跳页请求。
为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,其实使用业务层的 id 也可以。
GET /ad/_search
{"query": {"match_all": {}},"from": 0,"size": 2,"sort": [{"_id": {"order": "desc"}}]
}# 输出结果
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 11,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "ad","_type" : "_doc","_id" : "9","_score" : null,"_source" : {"name" : null,"price" : 666,"color" : "orange","ad" : "this is a orange phone","label" : ["orange","unknown"]},"sort" : ["9"]},{"_index" : "ad","_type" : "_doc","_id" : "8","_score" : null,"_source" : {"name" : null,"price" : 666,"color" : "orange","ad" : "this is a orange phone","label" : ["orange","unknown"]},"sort" : ["8"]}]}
}- 使用search_after必须要设置from=0。
- 这里使用_id作为唯一值排序。
- 我们在返回的最后一条数据里拿到sort属性的值传入到search_after。
使用sort返回的值搜索下一页:
GET /ad/_search
{"query": {"match_all": {}},"from": 0,"size": 2,"search_after": ["8"],"sort": [{"_id": {"order": "desc"}}]
}# 输出结果
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 11,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "ad","_type" : "_doc","_id" : "7","_score" : null,"_source" : {"price" : 999,"color" : "black","ad" : "this is a black phone","label" : ["black","unknown"]},"sort" : ["7"]},{"_index" : "ad","_type" : "_doc","_id" : "6","_score" : null,"_source" : {"name" : "","price" : 2999,"color" : "black","ad" : "this is a black phone","label" : ["black","unknown"]},"sort" : ["6"]}]}
}批量操作
multi get查询
允许基于索引,类型(可选)和id(以及可能的路由)获取多个文档,如果某个文档获取失败则会返回错误信息在响应中
不同索引的mget查询
# 不同索引的mget查询
GET /_mget
{"docs": [{"_index": "ad","_id": "1"},{"_index": "ad","_id": "2"},{"_index": "index_name","_id": "1"},{"_index": "index_name","_id": "4"}]
}# 输出结果
{"docs" : [{"_index" : "ad","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"name" : "phone 8","price" : 6000,"color" : "white","ad" : "this is a white phone","label" : ["white","nice"]}},{"_index" : "ad","_type" : "_doc","_id" : "2","_version" : 1,"_seq_no" : 1,"_primary_term" : 1,"found" : true,"_source" : {"name" : "xiaomi 8","price" : 4000,"color" : "red","ad" : "this is a red phone","label" : ["white","xiaomi"]}},{"_index" : "index_name","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 20,"_primary_term" : 1,"found" : true,"_source" : {"id" : 1001,"name" : "张三","age" : 12,"desc" : "我的自我描述","birthday" : "2020-02-02"}},{"_index" : "index_name","_type" : "_doc","_id" : "4","found" : false}]
}相同索引的mget查询
# 相同索引的mget查询
#index和type相同的话可以简化成如下
GET /ad/_mget
{"docs": [{"_id": "1"},{"_id": "2"},{"_id": "3"}]
}# 输出结果
{"docs" : [{"_index" : "ad","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"name" : "phone 8","price" : 6000,"color" : "white","ad" : "this is a white phone","label" : ["white","nice"]}},{"_index" : "ad","_type" : "_doc","_id" : "2","_version" : 1,"_seq_no" : 1,"_primary_term" : 1,"found" : true,"_source" : {"name" : "xiaomi 8","price" : 4000,"color" : "red","ad" : "this is a red phone","label" : ["white","xiaomi"]}},{"_index" : "ad","_type" : "_doc","_id" : "3","_version" : 1,"_seq_no" : 2,"_primary_term" : 1,"found" : true,"_source" : {"name" : "huawei p30","price" : 5000,"color" : "white","ad" : "this is a white phone","label" : ["white","huawei"]}}]
}bulk批量操作
bulk是es提供的一种批量增删改的操作API。
bulk对JSON串的有着严格的要求。每个JSON串不能换行,只能放在同一行,同时,相邻的JSON串之间必须要有换行(Linux下是\n;Window下是\r\n)。bulk的每个操作必须要一对JSON串(delete语法除外)。
bulk请求体如下
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\naction必须是以下几种:
| 行为 | 解释 |
|---|---|
| create | 如果文档不存在就创建,但如果文档存在就返回错误 |
| index | 如果文档不存在就创建,如果文档存在就更新 |
| update | 更新一个文档,如果文档不存在就返回错误 |
| delete | 删除一个文档,如果要删除的文档id不存在,就返回错误 |
其实可以看得出来index是比较常用的。bulk请求不是原子操作,它们不能实现事务。每个请求操作时分开的,所以每个请求的成功与否不干扰其它操作
返回:
# bulk批量的混合操作,一般不推荐这种使用,项目中也用的极少。
PUT /_bulk
{ "create" : { "_index" : "ad", "_id" : "6" }}
{ "doc" : {"name" : "bulk"}}
{ "index" : { "_index" : "ad", "_id" : "6" }}
{ "doc" : {"name" : "bulk"}}
{ "delete":{ "_index" : "ad", "_id" : "1"}}
{ "update":{ "_index" : "ad", "_id" : "3"}}
{ "doc" : {"name" : "huawei p20"}}# 输出结果
{"took" : 77,# 如果任意一个文档出错,这里返回true,"errors" : true,# items数组,它罗列了每一个请求的结果,结果的顺序与我们请求的顺序相同"items" : [{# create这个文档已经存在,所以异常 "create" : {"_index" : "ad","_type" : "_doc","_id" : "6","status" : 409,"error" : {"type" : "version_conflict_engine_exception","reason" : "[6]: version conflict, document already exists (current version [1])","index_uuid" : "90zLKRHyT02kyN148mQpqg","shard" : "0","index" : "ad"}}},# index这个文档已经存在,会覆盖{"index" : {"_index" : "ad","_type" : "_doc","_id" : "6","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 11,"_primary_term" : 3,"status" : 200}},{"delete" : {"_index" : "ad","_type" : "_doc","_id" : "1","_version" : 2,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 12,"_primary_term" : 3,"status" : 200}},{"update" : {"_index" : "ad","_type" : "_doc","_id" : "3","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 13,"_primary_term" : 3,"status" : 200}}]
}测试数据准备
# 测试数据准备
PUT example
PUT example/_mapping
{"properties": {"id": {"type": "long"},"name": {"type": "text"},"counter": {"type": "integer"},"tags": {"type": "text"}}
}批量插入
# 批量插入
POST /example/_bulk
{"index": {"_id": 1}}
{"id":1, "name":"admin", "counter":10, "tags":["red", "black"]}
{"index": {"_id": 2}}
{"id":2, "name":"张三", "counter":20, "tags":["green", "purple"]}
{"index": {"_id": 3}}
{"id":3, "name":"李四", "counter":30, "tags":["red", "blue"]}
{"index": {"_id": 4}}
{"id":4, "name":"tom", "counter":40, "tags":["orange"]}# 输出结果
{"took" : 7,"errors" : false,"items" : [{"index" : {"_index" : "example","_type" : "_doc","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1,"status" : 201}},{"index" : {"_index" : "example","_type" : "_doc","_id" : "2","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1,"status" : 201}},{"index" : {"_index" : "example","_type" : "_doc","_id" : "3","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 2,"_primary_term" : 1,"status" : 201}},{"index" : {"_index" : "example","_type" : "_doc","_id" : "4","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 3,"_primary_term" : 1,"status" : 201}}]
}批量修改
# 批量修改
POST /example/_bulk
{"update": {"_id": 1}}
{"doc": {"id":1, "name": "admin-02", "counter":11}}
{"update": {"_id": 2}}
{"script":{"lang":"painless","source":"ctx._source.counter += params.num","params": {"num":2}}}
{"update":{"_id": 3}}
{"doc": {"name": "test3333name", "counter": 999}}
{"update":{"_id": 4}}
{"doc": {"name": "test444name", "counter": 888}, "doc_as_upsert" : true}# 输出结果
{"took" : 149,"errors" : false,"items" : [{"update" : {"_index" : "example","_type" : "_doc","_id" : "1","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 4,"_primary_term" : 1,"status" : 200}},{"update" : {"_index" : "example","_type" : "_doc","_id" : "2","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 5,"_primary_term" : 1,"status" : 200}},{"update" : {"_index" : "example","_type" : "_doc","_id" : "3","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 6,"_primary_term" : 1,"status" : 200}},{"update" : {"_index" : "example","_type" : "_doc","_id" : "4","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 7,"_primary_term" : 1,"status" : 200}}]
}批量删除
# 批量删除
POST /example/_bulk
{"delete": {"_id": 1}}
{"delete": {"_id": 2}}
{"delete": {"_id": 3}}
{"delete": {"_id": 4}}# 输出结果
{"took" : 7,"errors" : false,"items" : [{"delete" : {"_index" : "example","_type" : "_doc","_id" : "1","_version" : 3,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 8,"_primary_term" : 1,"status" : 200}},{"delete" : {"_index" : "example","_type" : "_doc","_id" : "2","_version" : 3,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 9,"_primary_term" : 1,"status" : 200}},{"delete" : {"_index" : "example","_type" : "_doc","_id" : "3","_version" : 3,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 10,"_primary_term" : 1,"status" : 200}},{"delete" : {"_index" : "example","_type" : "_doc","_id" : "4","_version" : 3,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 11,"_primary_term" : 1,"status" : 200}}]
}其他查询
查询两个字段相等的文档,比如文档_id与USER_ID字段值相等的文档
GET /index_name/_search
{"from": 0,"size": 1,"query": {"bool": {"must": [{"match_all": {}}],"filter": {"script": {"script": {"source": "doc['_id'] == doc['USER_ID']","lang": "painless"}}},"must_not": [],"should": []}}
}复杂条件修改/删除
_update_by_query条件修改
将desc中含有我的数据,desc修改为张3新的自我介绍
# 复杂条件更新
POST /index_name/_update_by_query
{"script": {"source": "ctx._source['desc']='张3新的自我介绍'"},"query": {"bool": {"must": [{"term": {"desc": "我"}}]}}
}# 输出结果
{"took" : 38,"timed_out" : false,"total" : 3,"updated" : 3,"deleted" : 0,"batches" : 1,"version_conflicts" : 0,"noops" : 0,"retries" : {"bulk" : 0,"search" : 0},"throttled_millis" : 0,"requests_per_second" : -1.0,"throttled_until_millis" : 0,"failures" : [ ]
}_delete_by_query条件删除
将desc中含有3的数据删除
# 复杂条件删除
POST /index_name/_delete_by_query
{"query": {"bool": {"must": [{"term": {"desc": "3"}}]}}
}# 输出结果
{"took" : 19,"timed_out" : false,"total" : 3,"deleted" : 3,"batches" : 1,"version_conflicts" : 0,"noops" : 0,"retries" : {"bulk" : 0,"search" : 0},"throttled_millis" : 0,"requests_per_second" : -1.0,"throttled_until_millis" : 0,"failures" : [ ]
}排序
在 Elasticsearch 中,默认排序是按照相关性的评分(_score)进行降序排序,也可以按照字段的值排序、多级排序、多值字段排序、基于 geo(地理位置)排序以及自定义脚本排序。
字段的值排序
在 Elasticsearch 中按照字段的值排序,可以利用 sort 参数实现。
GET /books/_search
{"sort": {"price": {"order": "desc"}}
}# 输出结果
{"took": 132,"timed_out": false,"_shards": {"total": 10,"successful": 10,"skipped": 0,"failed": 0},"hits": {"total": 749244,"max_score": null,"hits": [{"_index": "books","_type": "book","_id": "8456479","_score": null,"_source": {"id": 8456479,"price": 1580.00,...},"sort": [1580.00]},...]}
}从如上返回结果,可以看出,max_score 和 _score 字段都返回 null,返回字段多出 sort 字段,包含排序字段的分值。计算 _score 的花销巨大,如果不根据相关性排序,记录 _score 是没有意义的。如果无论如何都要计算 _score,可以将 track_scores 参数设置为 true。
多字段排序
如果我们想要结合使用 price、date 和 _score 进行查询,并且匹配的结果首先按照价格排序,然后按照日期排序,最后按照相关性排序,具体示例如下:
GET /books/_search
{"query": {"bool": {"must": {"match": {"content": "java"}},"filter": {"term": {"user_id": 4868438}}}},"sort": [{"price": {"order": "desc"}},{"date": {"order": "desc"}},{"_score": {"order": "desc"}}]
}排序条件的顺序是很重要的。结果首先按第一个条件排序,仅当结果集的第一个 sort 值完全相同时才会按照第二个条件进行排序,以此类推。
多级排序并不一定包含 _score。你可以根据一些不同的字段进行排序,如地理距离或是脚本计算的特定值。
多值字段的排序
一种情形是字段有多个值的排序,需要记住这些值并没有固有的顺序;一个多值的字段仅仅是多个值的包装,这时应该选择哪个进行排序呢?比如:集合类型例如 List<Date> dates
对于数字或日期,你可以将多值字段减为单值,这可以通过使用 min、max、avg 或是 sum 排序模式。例如你可以按照每个 date 字段中的最早日期进行排序,通过以下方法:
GET /books/_search
{"sort": {"dates": {"order": "asc","mode": "min"}}
}如果你也想学习:黑客&网络安全
在这里领取:

这个是我花了几天几夜自整理的最新最全网安学习资料包免费共享给你们,其中包含以下东西:
1.学习路线&职业规划


2.全套体系课&入门到精通

3.黑客电子书&面试资料