栈与队列
- 栈与队列理论基础
- 用栈实现队列
- 思路
- 代码
- 用队列实现栈
- 思路
- 代码
- 删除字符串中的所有相邻重复项
- 思路
- 代码
- 有效的括号
- 思路
- 代码
- 逆波兰表达式求值
- 思路
- 代码
- 滑动窗口最大值
- 思路
- 代码
- 未完待续
- 前 K 个高频元素
- 思路
- 代码
- 拓展
- 总结
- 栈在系统中的应用
- 括号匹配问题
- 字符串去重问题
- 逆波兰表达式问题
- 滑动窗口最大值问题
- 求前 K 个高频元素
栈与队列理论基础
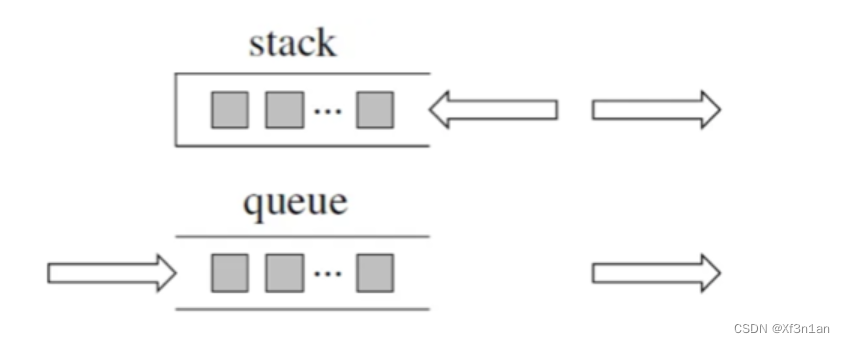
队列是先进先出,栈是先进后出。
这里再列出四个关于栈的问题,大家可以思考一下。
- C++中stack 是容器么?
- 我们使用的stack是属于哪个版本的STL?
- 我们使用的STL中stack是如何实现的?
- stack 提供迭代器来遍历stack空间么?
首先要知道 栈和队列是STL(C++标准库)里面的两个数据结构。
C++标准库是有多个版本的,要知道我们使用的STL是哪个版本,才能知道对应的栈和队列的实现原理。
那么来介绍一下,三个最为普遍的STL版本:
- HP STL 其他版本的C++ STL,一般是以HP STL为蓝本实现出来的,HP STL是C++ STL的第一个实现版本,而且开放源代码。
- P.J.Plauger STL 由P.J.Plauger参照HP STL实现出来的,被Visual C++编译器所采用,不是开源的。
- SGI STL 由Silicon Graphics Computer Systems公司参照HP STL实现,被Linux的C++编译器GCC所采用,SGI STL是开源软件,源码可读性甚高。
接下来介绍的栈和队列也是SGI STL里面的数据结构, 知道了使用版本,才知道对应的底层实现。
先说一说栈,栈先进后出,如图所示:
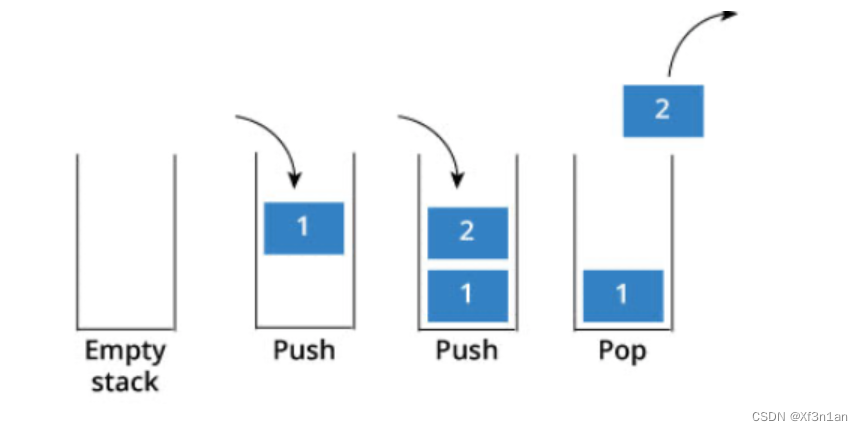
栈提供push 和 pop 等等接口,所有元素必须符合先进后出规则,所以栈不提供走访功能,也不提供迭代器(iterator)。 不像是set 或者map 提供迭代器iterator来遍历所有元素。
栈是以底层容器完成其所有的工作,对外提供统一的接口,底层容器是可插拔的(也就是说我们可以控制使用哪种容器来实现栈的功能)。
所以STL中栈往往不被归类为容器,而被归类为container adapter(容器适配器)。
那么问题来了,STL 中栈是用什么容器实现的?
从下图中可以看出,栈的内部结构,栈的底层实现可以是vector,deque,list 都是可以的, 主要就是数组和链表的底层实现。
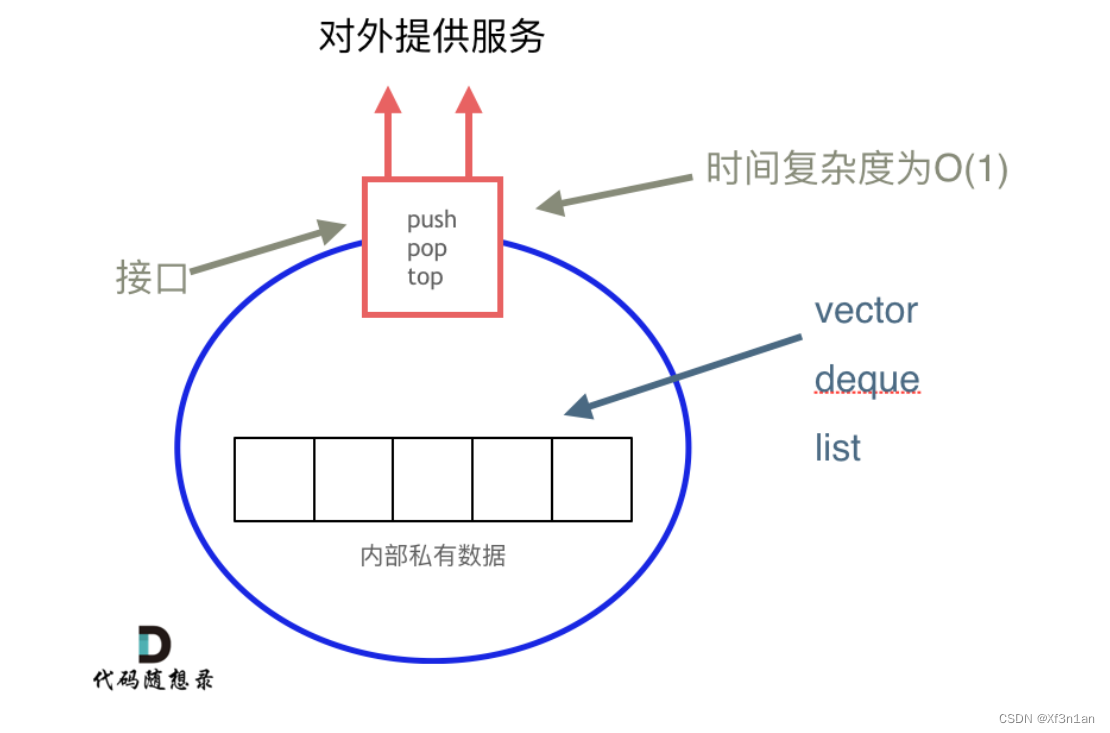
我们常用的SGI STL,如果没有指定底层实现的话,默认是以deque为缺省情况下栈的底层结构。
deque是一个双向队列,只要封住一端,只开通另一端就可以实现栈的逻辑了。
SGI STL中 队列底层实现缺省情况下一样使用deque实现的。
我们也可以指定vector为栈的底层实现,初始化语句如下:
std::stack<int, std::vector<int> > third; // 使用vector为底层容器的栈
刚刚讲过栈的特性,对应的队列的情况是一样的。
队列中先进先出的数据结构,同样不允许有遍历行为,不提供迭代器, SGI STL中队列一样是以deque为缺省情况下的底部结构。
也可以指定list 为起底层实现,初始化queue的语句如下:
std::queue<int, std::list<int>> third; // 定义以list为底层容器的队列
所以STL 队列也不被归类为容器,而被归类为container adapter( 容器适配器)。
用栈实现队列
力扣题目链接
思路
栈是先进后出的数据结构,队列则是先进先出。
那么这道题,我们需要两个栈才能模拟一个队列。
为什么这么说?
栈插入元素后,元素是逆序排列的,但是我把元素取出来后再插入一个栈,不就是负负得正了吗。
我先准备一个输入栈In,每次做push操作的时候都向这个栈里插入元素。
当需要pop元素的时候,将输入栈中的元素全部取出然后插入到输出栈Out中。此时,输出栈Out的栈顶元素就是我们需要的第一个元素。
代码
void push(int x) {stIn.push(x);}int pop() {if(!stOut.empty()){int x = stOut.top();stOut.pop();return x;}else{while(!stIn.empty()){int x = stIn.top();stIn.pop();stOut.push(x);}int x = stOut.top();stOut.pop();return x;}}int peek() {int a = pop();stOut.push(a);return a;}bool empty() {if(stIn.empty()&&stOut.empty()){return true;}else{return false;}}
用队列实现栈
力扣题目链接
思路
队列是先进先出的数据结构,栈是先进后出。如果像上一道题一样做法,那么无论如何也不可能实现先进后出。
但是,模拟的时候我发现,如果我每次弹出队列中除了最后一个元素的所有元素,那么此时最后一个元素就是模拟栈弹出的第一个元素。
我只需要将队列弹出元素存入另一个队列中,当弹出最后一个元素的时候再将他们放入队列中即可。
que2其实完全就是一个备份的作用,把que1最后面的元素以外的元素都备份到que2,然后弹出最后面的元素,再把其他元素从que2导回que1。
代码
void push(int x) {d1.push_back(x);}int pop() {int n = d1.size();n--;while(n--){int x = d1.front();d1.pop_front();d2.push_back(x);}int result = d1.front();d1.pop_front();while(!d2.empty()){int x = d2.front();d2.pop_front();d1.push_back(x);}return result;}int top() {int x = pop();d1.push_back(x);return x;}bool empty() {if(d1.empty()){return true;}else{return false;}}
删除字符串中的所有相邻重复项
力扣题目链接
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
在 S 上反复执行重复项删除操作,直到无法继续删除。
在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
示例:
输入:“abbaca”
输出:“ca”
解释:例如,在 “abbaca” 中,我们可以删除 “bb” 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 “aaca”,其中又只有 “aa” 可以执行重复项删除操作,所以最后的字符串为 “ca”。
思路
我们在删除相邻重复项的时候,其实就是要知道当前遍历的这个元素,我们在前一位是不是遍历过一样数值的元素,那么如何记录前面遍历过的元素呢?
所以就是用栈来存放,那么栈的目的,就是存放遍历过的元素,当遍历当前的这个元素的时候,去栈里看一下我们是不是遍历过相同数值的相邻元素。
代码
class Solution {
public:string removeDuplicates(string s) {stack<char> st;for(int i = 0 ; i < s.size(); i++){char ch;// 只有当栈非空时才检查栈顶元素if(!st.empty() && s[i] == st.top()){st.pop();}else{st.push(s[i]);}}string result = "";while(!st.empty()){char c = st.top();result += c;st.pop();}reverse(result.begin(),result.end());return result;}
};
有效的括号
力扣题目链接
给定一个只包括 ‘(’,‘)’,‘{’,‘}’,‘[’,‘]’ 的字符串,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
注意空字符串可被认为是有效字符串。
思路
该题是很经典的栈问题,用来括号匹配。
我的代码可能看起来比较乱。
我的思路是,首先判断栈是否为空,如果为空,我们需要将遍历到的字符放入栈中。此时,有四种情况,前三种是三个不同的左括号,最后一个情况是任意一个右括号。如果出现了栈是空的,并且当前遍历的括号是右括号,已经说明不匹配了。
接下来就是栈不为空的情况。那么有两种,一是遍历的括号和栈中的括号一样,那么就抵消了。
二是,如果是左括号,那么还是把对应的右括号压入栈中。如果是右括号,那就是不匹配的情况。
最后检查一下栈是否为空即可判断出括号是否完全匹配。
代码
class Solution {
public:bool isValid(string s) {stack<char> st;for(int i = 0 ; i < s.size(); ++i){if(st.empty()){if(s[i]=='('){st.push(')');}else if(s[i]=='[') st.push(']');else if(s[i]=='{') st.push('}');else{return false;}}else{if(s[i]== st.top()){st.pop();}else{if(s[i]=='(') st.push(')');else if(s[i]=='[') st.push(']');else if(s[i]=='{') st.push('}');else{return false;}}}}if(st.empty()){return true;}else{return false;}}
};
逆波兰表达式求值
力扣题目链接
根据 逆波兰表示法,求表达式的值。
有效的运算符包括 + , - , * , / 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
说明:
整数除法只保留整数部分。 给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
思路
这道题的做法没什么好说的,很经典的栈问题。如果遍历到的是数字,就压入栈中,如果是运算符,那么从栈中取出两个元素进行相应的运算,之后把结果压入栈中。
唯一需要注意的地方是:在逆波兰表达式中,先弹出的是第二个操作数,后弹出的是第一个操作数。
代码
class Solution {
public:int evalRPN(vector<string>& tokens) {stack<int> st;for(int i = 0 ; i < tokens.size();++i){if(tokens[i]== "+"){int x = st.top();st.pop();int y = st.top();st.pop();int sum = x+y;st.push(sum);}else if(tokens[i]== "-"){int x = st.top();st.pop();int y = st.top();st.pop();int sum = y-x;st.push(sum);}else if(tokens[i]== "*"){int x = st.top();st.pop();int y = st.top();st.pop();int sum = x * y;st.push(sum);}else if(tokens[i]== "/"){int x = st.top();st.pop();int y = st.top();st.pop();int sum = y / x;st.push(sum);}else{int a = stoi(tokens[i]);st.push(a);}}int result = st.top();st.pop();return result;}
};
滑动窗口最大值
力扣题目链接
给定一个数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回滑动窗口中的最大值。
思路
代码
未完待续
前 K 个高频元素
力扣题目链接
给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
思路
这道题目主要涉及到如下三块内容:
1.要统计元素出现频率
2.对频率排序
3.找出前K个高频元素
那么针对 对频率进行排序 我们可以使用一种容器适配器 叫做优先级队列。
优先级队列其实就是一个披着队列外衣的 堆,因为优先级队列的接口是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来像一个队列。
而且优先级队列内部元素是自动依照元素的权值排列。那么它是如何有序排列的呢?
缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。
什么是堆呢?
堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
所以大家经常说的大顶堆(堆头是最大元素),小顶堆(堆头是最小元素),如果懒得自己实现的话,就直接用priority_queue(优先级队列)就可以了,底层实现都是一样的,从小到大排就是小顶堆,从大到小排就是大顶堆。
本题我们就要使用优先级队列来对部分频率进行排序。
此时要思考一下,是使用小顶堆呢,还是大顶堆?
有的同学一想,题目要求前 K 个高频元素,那么果断用大顶堆啊。
那么问题来了,定义一个大小为k的大顶堆,在每次移动更新大顶堆的时候,每次弹出都把最大的元素弹出去了,那么怎么保留下来前K个高频元素呢。
而且使用大顶堆就要把所有元素都进行排序,那能不能只排序k个元素呢?
所以我们要用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。
代码
class Solution {
public://小顶堆排序规则class mycompare{public:bool operator()(const pair<int,int>&lhs,const pair<int,int>&rhs){return lhs.second > rhs.second;}};vector<int> topKFrequent(vector<int>& nums, int k) {//统计元素出现频率unordered_map<int ,int > map; for(int i : nums){map[i]++;}//对频率进行排序priority_queue<pair<int,int>,vector<pair<int,int>>,mycompare> pri_que;for(auto it = map.begin();it!=map.end();it++){pri_que.push(*it);if(pri_que.size() > k){pri_que.pop();}}//找出前k个频率大的元素vector<int>result(k);for(int i = 0 ; i < k ;++i){result[i] = pri_que.top().first;pri_que.pop();}return result;}
};
拓展
大家对这个比较运算在建堆时是如何应用的,为什么左大于右就会建立小顶堆,反而建立大顶堆比较困惑。
确实 例如我们在写快排的cmp函数的时候,return left>right 就是从大到小,return left<right 就是从小到大。
优先级队列的定义正好反过来了,可能和优先级队列的源码实现有关(我没有仔细研究),我估计是底层实现上优先队列队首指向后面,队尾指向最前面的缘故!
关于优先级队列的定义
priority_queue<pair<int,int>, vector<pair<int,int>>, mycompare> pri_que;pair<int,int>:这里的 pair 用于存储两个信息:map中的元素(int 类型)及其出现频率(也是 int 类型)。
vector<pair<int,int>>:这是 priority_queue 的底层容器。它指定了 priority_queue 内部应该使用 vector 来存储元素,这些元素是 pair<int, int> 类型的。
mycompare:这是一个比较类,用于定义堆中元素的排序规则。在小顶堆中,顶部元素是最小的元素。
总结
栈在系统中的应用
如果还记得编译原理的话,编译器在词法分析的过程中处理括号、花括号等这个符号的逻辑,就是使用了栈这种数据结构。
再举个例子,linux系统中,cd这个进入目录的命令我们应该再熟悉不过了。
cd a/b/c/…/…/
这个命令最后进入a目录,系统是如何知道进入了a目录呢 ,这就是栈的应用。这在leetcode上也是一道题目,编号:71. 简化路径,大家有空可以做一下。
递归的实现是栈:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
所以栈在计算机领域中应用是非常广泛的。
括号匹配问题
括号匹配是使用栈解决的经典问题。
建议要写代码之前要分析好有哪几种不匹配的情况,如果不动手之前分析好,写出的代码也会有很多问题。
先来分析一下 这里有三种不匹配的情况,
第一种情况,字符串里左方向的括号多余了,所以不匹配。
第二种情况,括号没有多余,但是括号的类型没有匹配上。
第三种情况,字符串里右方向的括号多余了,所以不匹配。
这里还有一些技巧,在匹配左括号的时候,右括号先入栈,就只需要比较当前元素和栈顶相不相等就可以了,比左括号先入栈代码实现要简单的多了!
字符串去重问题
思路就是可以把字符串顺序放到一个栈中,然后如果相同的话 栈就弹出,这样最后栈里剩下的元素都是相邻不相同的元素了。
逆波兰表达式问题
本题中每一个子表达式要得出一个结果,然后拿这个结果再进行运算,那么这岂不就是一个相邻字符串消除的过程。
滑动窗口最大值问题
在栈与队列:滑动窗口里求最大值引出一个重要数据结构 (opens new window)中讲解了一种数据结构:单调队列。
这道题目还是比较绕的,如果第一次遇到这种题目,需要反复琢磨琢磨
主要思想是队列没有必要维护窗口里的所有元素,只需要维护有可能成为窗口里最大值的元素就可以了,同时保证队列里的元素数值是由大到小的。
那么这个维护元素单调递减的队列就叫做单调队列,即单调递减或单调递增的队列。C++中没有直接支持单调队列,需要我们自己来一个单调队列
而且不要以为实现的单调队列就是 对窗口里面的数进行排序,如果排序的话,那和优先级队列又有什么区别了呢。
设计单调队列的时候,pop,和push操作要保持如下规则:
pop(value):如果窗口移除的元素value等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作
push(value):如果push的元素value大于入口元素的数值,那么就将队列出口的元素弹出,直到push元素的数值小于等于队列入口元素的数值为止
保持如上规则,每次窗口移动的时候,只要问que.front()就可以返回当前窗口的最大值。
一些同学还会对单调队列都有一些困惑,首先要明确的是,题解中单调队列里的pop和push接口,仅适用于本题。
单调队列不是一成不变的,而是不同场景不同写法,总之要保证队列里单调递减或递增的原则,所以叫做单调队列。
不要以为本地中的单调队列实现就是固定的写法。
我们用deque作为单调队列的底层数据结构,C++中deque是stack和queue默认的底层实现容器(这个我们之前已经讲过),deque是可以两边扩展的,而且deque里元素并不是严格的连续分布的。
求前 K 个高频元素
通过求前 K 个高频元素,引出另一种队列就是优先级队列。
什么是优先级队列呢?
其实就是一个披着队列外衣的堆,因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列。
而且优先级队列内部元素是自动依照元素的权值排列。那么它是如何有序排列的呢?
缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。
什么是堆呢?
堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
所以大家经常说的大顶堆(堆头是最大元素),小顶堆(堆头是最小元素),如果懒得自己实现的话,就直接用priority_queue(优先级队列)就可以了,底层实现都是一样的,从小到大排就是小顶堆,从大到小排就是大顶堆。
本题就要使用优先级队列来对部分频率进行排序。 注意这里是对部分数据进行排序而不需要对所有数据排序!
所以排序的过程的时间复杂度是 O ( log k ) O(\log k) O(logk),整个算法的时间复杂度是 O ( n log k ) O(n\log k) O(nlogk)。