前言:
本论文由同济大学、微软亚洲研究院、西安电子科技大学,于2023年12月11日中了AAAI2024
论文:
《Learning Hierarchical Prompt with Structured Linguistic Knowledge for Vision-Language Models》
地址:
[2312.06323] Learning Hierarchical Prompt with Structured Linguistic Knowledge for Vision-Language Models (arxiv.org)
代码:
GitHub - Vill-Lab/2024-AAAI-HPT: Learning Hierarchical Prompt with Structured Linguistic Knowledge for Vision-Language Models (AAAI 2024)

1、Abstract:
提示学习已经成为适应视觉语言基础模型到下游任务的一种普遍策略。随着大型语言模型(LLMs)的出现,最近的研究已经探索了使用类别相关的描述作为输入以增强提示的有效性。然而,传统的描述远远不足以有效地表示特定类别中实体或属性之间的结构化信息。
为了解决这个问题并优先利用结构化知识,本文提出了一种使用LLM构建每个描述的图来模拟类别中的实体和属性及其相关性的方法。现有的提示调优方法在管理这种结构化知识方面存在不足。
因此,作者提出了一种新颖的方法,称为层次化提示调优(HPT),该方法可以同时建模结构和传统的语言知识。具体而言,作者引入了一种关系引导的注意力模块来捕获实体和属性之间的关联性,以便进行低级提示学习。此外,通过结合高级和全局提示来模拟整体语义,所提出的层次结构可以形成跨级别的联系,并使模型能够处理更复杂和长期的关系。
大量实验表明,作者的HPT显示了强大的效果,并且比现有的最先进方法通用性更好。
2、Introduction:
视觉语言基础模型(VLMs)[1, 13],通过在大规模图像文本对数据集上进行训练,在学习可转移表示方面取得了显著的进步。为了有效地探索这些强大基础模型的潜力,提示调优方法[22, 23]旨在学习一组连续的向量,称为提示向量,并将其纳入输入空间,赋予预训练网络强大的表示能力。然而,当面临歧义类别名称时,模型往往很难做出准确的判断关于相应的视觉概念,导致令人失望的表现。因此,在没有语言知识辅助的情况下,将类别名称作为文本输入似乎是不 optimal 的选择。最近的方法[24, 11]通过使用大型语言模型(LLMs),如GPT-3[2],解决了这个问题。他们以手写模板作为输入,生成类似人类的文本,其中包含丰富的语言知识,补充了少样本视觉识别。
在本文中,作者提出了一种新颖的方法,将结构化知识与自然语言描述相结合。作者主张,这种结构化知识对于提示调优至关重要。具体而言,具有非结构化知识的类别的描述包括定义该类的关键实体和属性。
例如,水仙花类别是由像“叶子”、“开花”、“花”等实体定义的,每个实体都与特定的类别属性相关联。参考知识图谱[13, 14]的相关工作,作者将这些实体、属性和它们之间的关联性表示为一张图进行语义理解。这种基于图的表示方法提供了一种更组织化的方式来呈现信息,从而提高了数据理解。它有助于发现可能不明显的原始描述中的隐性联系。
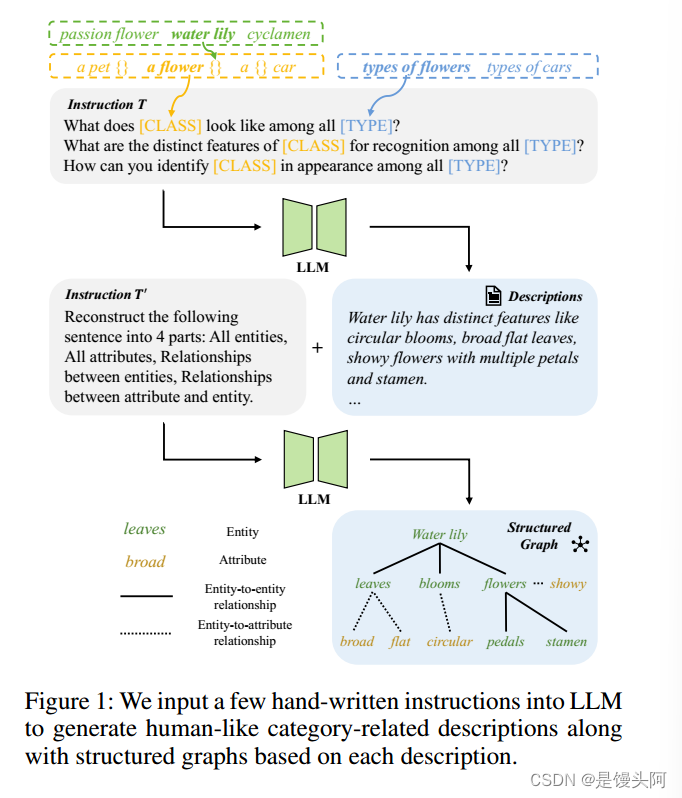
在这项工作中,作者利用现有的大型语言模型从普通的描述中获取结构化信息,如图1所示。对于特定的类别,作者将人工制作的指令输入到LLMs中,旨在生成类似于人类的描述,以及每个描述内的结构化关系,包括实体、属性和它们之间的关系。
然而,现有的提示调优方法无法明确地建模图中所代表的结构化知识。为此,作者提出了一种名为层次化提示调优(HPT)的方法,从LLMs中以层次化的方式整合结构化和传统的语言知识来提高提示的有效性。为了建模复杂的结构化信息,HPT学习具有不同语义级别的层次化提示。具体而言,HPT包含低级提示,代表实体和属性,高级提示包含从描述中派生出的类别相关信息,以及全局级别的提示,包含跨类别的共享知识。
为了捕获LLM生成的实体和属性之间的成对对应关系,作者引入了一种关系引导的注意力模块,其中将可学习的基于注意力的矩阵集成到文本编码器中。此外,为了处理LLM没有完全利用的更复杂和长期的关系,作者采用了跨级别的自注意力来建模不同级别的提示之间的关系。这有效地克服了仅依赖低级 Token 建模的局限性,并允许对类别有更全面的理解。作者的提示是在一个双路径不对称框架下进行训练的[14],其中分别通过将提示图像编码器和文本编码器与另一个模态的冻结编码器对齐来学习。通过用一种新颖的分层提示文本编码器替换普通的提示文本编码器,该编码器仅学习类别无关的提示,可以更好地将文本表示与相应的视觉概念对齐,从而导致出色的识别性能。
作者的工作贡献如下:
1)作者提出使用描述的结构知识辅助学习提示的重要性。因此,作者利用大型语言模型生成具有相应结构关系的类别相关描述;
2)作者提出层次化提示调优(HPT)方法,同时建模结构化和传统语言知识。通过将两种形式的知识相结合,作者可以使用更多的类别相关信息来增强提示的有效性;
3)在三个常用的评估设置上的大量实验表明,作者的方法取得了显著的改进。
3、Related Work
3.1 Large Language Models
大型语言模型(LLMs),如GPT-3[15],OPT[14]和PaLM[13],是在广泛的数据集上进行训练的。最近,ChatGPT[14]由于其生成类似于人类写作的文本和识别跨领域复杂模式的能力而受到了广泛欢迎。利用LLMs的巨大潜力,最近的研究表明它们在解决各种视觉语言任务[13, 15, 16]方面是有效的。此外,其他研究探讨了使用LLMs提示视觉语言模型[14, 15, 16]在图像分类、连续学习、图像描述生成和行为理解方面的效果。在这项研究中,作者旨在利用LLM在图像分类领域的能力。当提示目标类别时,LLM能够生成相关的描述以及相应的结构化关系。
3.2 Visual-Language Models
大型视觉语言模型(VLMs)在推动开放词汇图像分类方面起到了关键作用,CLIP[17]是该领域的开创性工作。显著的方法包括通过使用更多的数据、更大的批量大小和更大的模型来扩展模型,如Align[15]和Basic[16],通过像SLIP[17]、FILIP[18]和Lion[13]这样的模型优化目标函数,并在训练过程中通过像Florence[16]、UniCL[15]、K-LITE[14]和REACT[15]这样的模型集成辅助信息。作者的研究动机是希望通过改进多模态提示来增强CLIP的能力。
3.3 Prompt Learning for V-L Models
提示学习起源于自然语言处理(NLP),旨在增强与大型语言模型的交互[15, 16, 17]。某些努力[13, 14]提出利用LLM中的预训练语言知识来生成提示,从而在不需要额外训练或 Token 的情况下增强V-L模型。为了自动化提示工程并探索最优提示,其他研究[18, 19, 17, 16]使用可学习的文本输入并在训练期间对其进行优化,称为提示调优。随着视觉提示调优(VPT)[15]的出现,最近的方法[12, 16]采用多模态方法对两种模态进行提示以改善视觉和语言表示之间的对齐。与先前的研究不同,作者生成多样化的语言知识并基于它们进行层次化提示调优以生成更健壮的表示。
4、Method
4.1 Overall Pipeline
在本小节中,作者将介绍作者提出的整体方法 Pipeline ,如图2(a)所示。在特定类别的情况下,作者首先用一组手工艺模板作为指令输入到LLMs中,以生成人类般的描述。此外,作者还向生成的描述中添加另一条指令,以捕捉每个描述内的组织良好的结构,包括实体、属性和它们之间的关系。作者将会在第语言数据生成部分提供更详细的阐述。

在给定生成的数据后,作者应用一个双路径不对称网络[22]进行提示调优与视觉语言模型。该网络擅长解决与学习到的提示相关的过拟合问题,尤其是在少样本学习场景中。为了进行类似于Transformer的编码器的提示调优,作者在每个Transformer层输入空间引入可学习的向量作为提示。该框架包括一个新颖的不对称对比损失,它分别使用来自不同模态的冻结编码器作为指导,单独训练提示图像编码器和文本编码器。具体而言,来自不同模态的提示和冻结编码器的表示以不对称的方式对齐,从而生成两个概率 pi 和pt 。然后,它们分别求平均以得出整体预测 po。
相比于对视觉提示进行任何修改,作者将主要关注文本模态的提示调优。与先前的双路径不对称网络不同,其中两个文本编码器处理相同的文本输入,作者的方法采用一种独特的策略,即冻结文本编码器和提示文本编码器输入完全不同。具体而言,非结构化描述被输入到冻结编码器,而关系引导的图以及相应的类别名称被输入到专门设计和微调的层次化提示文本编码器中,该编码器专门用于建模结构化信息。在层次化提示调优部分,作者将详细介绍这个编码器的核心结构,以便更好地理解来自不同语义级别的提示的调优。为了有效地捕获LLM生成的实体和属性之间的成对对应关系,层次化提示文本编码器集成了关系引导的注意力模块,其详细实现将在关系引导注意力模块部分进行阐述。
4.2 Linguistic Data Generation
为了获取语言知识,作者使用最强大的LLM之一ChatGPT[23]生成具有相应结构关系的描述。如图1所示,作者将N_h个问题模板作为语言指令T输入到LLMs中,例如"What does a [CLASS] look like among all a [TYPE]?"或"What are the distinct features of [CLASS] for recognition among all [TYPE]?"等。[CLASS]表示具有修饰符的特定类别名称,如"a pet Abyssinian"。[TYPE]表示与数据集相关的目标类型,如"宠物类型"对于OxfordPets[20]。作者用T生成的描述表示为D={d_{i}}{i=1}^{N{h}},其中每个描述都由问题模板和相应的答案组成。
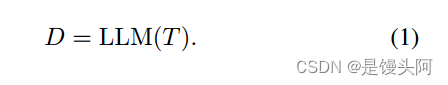
5、Experiments
为了评估作者的方法,作者遵循了之前如Coop Zhou等人(2022年)、CoCoOp Zhou等人(2022年)和MaPLe Khattak等人(2023年)所建立的实验设置。作者首先描述评估协议和数据集,然后讨论实现细节。
5.1 Evaluation Protocols
Base-to-New Generalization
为了评估模型在不同类别上的泛化能力,这个过程涉及将数据集划分为基础(已见)和新的(未见)类别,然后使用少量来自基础类别的样本训练模型。最后,作者在基础(少样本性能)和新(零样本性能)类别上评估模型的性能。此外,作者计算基类和新类上的准确率的调和平均值,以突出泛化权衡。
Cross-Dataset Evaluation
这种评估方法旨在评估模型在跨数据集设置下的零样本能力。为了验证作者方法在跨数据集迁移方面的潜在能力,作者在少量样本的情况下在ImageNet的所有类别上训练作者的模型,并在零样本环境中直接在十个其他未见过的数据集上评估它,这些数据集中包含未知类别。
Domain Generalization
为了评估作者的方法在非目标分布数据集上的鲁棒性,作者将ImageNet视为源域,其其他变体视为目标域。作者在少量样本的情况下在ImageNet上微调作者的模型,并在具有相同类别或子集的四个ImageNet变体上评估它,同时表现出不同的域迁移。
Datasets
对于基到新的泛化和跨数据集评估,作者遵循先前的研究工作Zhou等人(2022年)的评估方法。作者在11个图像识别数据集上评估作者的方法,这些数据集涵盖了各种识别任务。具体来说,该基准包括Deng等人(2009年)的ImageNet和Fei-Fei,Fergus,Perona(2004年)的Caltech101,Parkhi等人(2012年)的OxfordPets,Krause等人(2013年)的StanfordCars,Nilsback和Zisserman(2008年)的Flowers101,Bossard等人(2014年)的Food101,Maji等人(2013年)的FGVCAircraft,Xiao等人(2010年)的SUN397,Soomro等人(2012年)的UCF101,Cimpoi等人(2014年)的DTD,以及Helber等人(2019年)的EuroSAT。对于域泛化,作者使用ImageNet作为源数据集,其四个变体作为目标数据集,包括ImageNetV2 Recht等人(2019年),ImageNet-Sketch Wang等人(2019年),ImageNet-A Hendrycks等人(2021年)和ImageNet-R Hendrycks等人(2021年)。
5.2 Result
作者在三个泛化设置中评估作者的方法,即基到新的泛化,跨数据集评估和域泛化。作者将与零样本CLIP和最近的提示学习工作作为强 Baseline 进行比较,包括CoOp和CoCoOp,以及最新的MaPLe等最先进的方法。在CLIP的情况下,作者使用专门为每个数据集设计的定制化提示。作者还进行了几个消融实验和样本分析,以更好地展示所提出的分层提示调优的有效性。
Base-to-New Generalization
表1展示了在基到新的泛化设置下,HPT在11个识别数据集上的性能。与最先进的提示调优方法MaPLe相比,作者的方法在新型类别的平均准确性方面提高了1.72%,同时保持了在高频见过的类别的较高准确率,甚至超过了MaPLe by 2.04%。
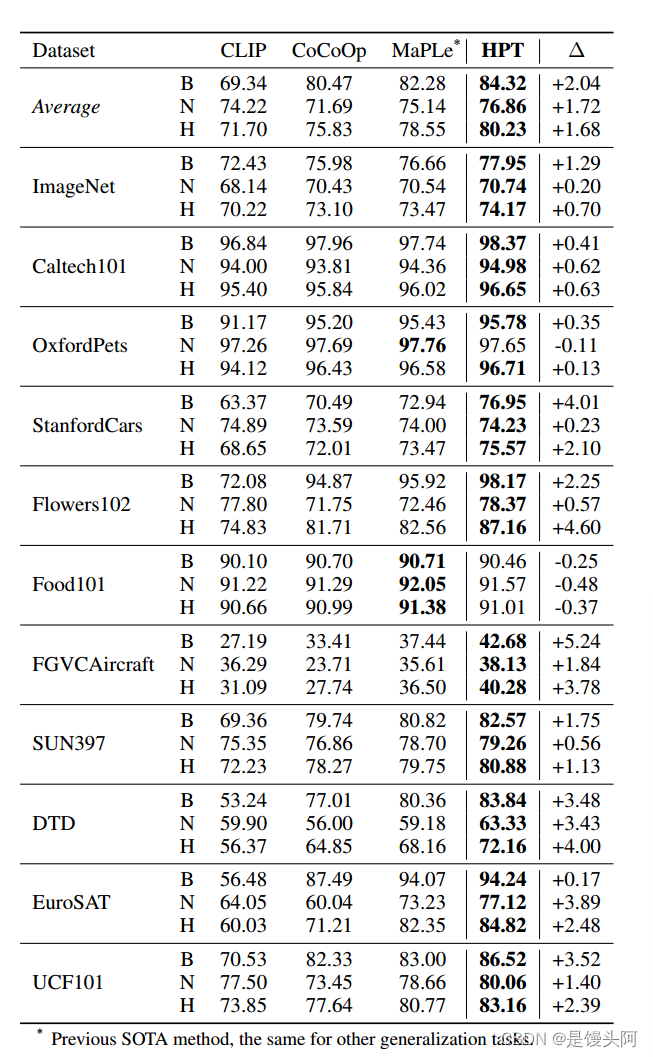
当考虑基和新型类时,HPT在调和平均数方面相对于MaPLe实现了1.68%的绝对平均增益,实现了域内和域外数据的合理权衡。在调和平均数方面的最大改进(相对于先前的SOTA为4.64%)在Flowers102上观察到。通过使用分层提示调优训练的模型,作者可以看到在语言知识更多而不是只有类别名称的情况下,模型有了显著的改进。
Cross-Dataset Evaluation
表2展示了作者的HPT与其他现有方法在跨数据集评估上的性能比较。在ImageNet源数据集上,HPT展示了与竞争对手相当的表现,但在10个数据集中的8个上表现出显著优于其他方法的一般化能力。

总的来说,HPT在竞争性能方面表现出众,实现了与先前的SOTA相比67.74%的平均准确性,提高了1.44%。与其他方法不同,作者不仅将学习到的提示向量直接转移到新任务,还提供了一组丰富的类别相关知识以及一种新的分层学习策略来建模知识,从而实现了优越的跨域性能。
Domain Generalization
作者评估了在ImageNet上训练的HPT直接迁移到各种非域数据集的性能,并观察到HPT相对于所有现有方法都持续改进,如表3所示。

与MaPLe相比,HPT在ImageNet-A上的表现略差,但在其他三个上更好。由于变体数据集与ImageNet共享相同的类别或ImageNet的子集类别,因此可以从源域获取相关的语言知识,从而帮助识别非域数据。
6、Conclusion
在本文中,作者提出利用描述中的结构化关系来帮助学习提示的观点至关重要。因此,作者生成了具有相应结构化关系的类人描述,并提出了层次化提示调优(HPT)方法,该方法同时建模结构化和传统的语言知识,以显著增强提示的有效性。作者的方法在三个泛化任务上都展示了优越的性能。作者希望这项工作能够引起对自然语言中结构化知识在提示调优中的作用的更多关注,使其能够应用于分类之外的多样化任务。
7、Professor Goudan playing with snow photos

背后一凉,我看看增么个事?怎么个事?

虚惊一场