文章目录
- 一、命名规约
- 二、代码格式
- 三、集合篇
- 1. 栈、队列、双端队列
- 2. List的升序倒序
- 3. Map的升序降序
- 4. 二维数组排序
- 5. 集合之间的转换
- 6. Map键值对遍历
- 7. 重写equal与hashCode
- 8. ArrayList的subList
- 9. keySet()/values()/entrySet()
- 10. Collections.emptyList()
- 11. Collections.singletonList(str)
- 12. Collection接口的addAll()
- 13. foreach与iterator()
- 14. 使用Set去重
- 四、并发篇
- 1. 创建线程池
- 2. ThreadLocal的使用
- 五、时间篇
- 1. LocalDateTime的使用
- 2. String、Date、LocalDateTime转换
- 六、控制块
- 1. switch
- 2. 三目运算
- 3. 循环体
- 4. try-catch-finally-return
- 七、其他
- 1. 正则表达式
- 2. BeanUtil的copy
- 3. Integer的比较
- 4. 浮点数的比较
- 5. Object的clone方法
一、命名规约
A) 各类命名方法
类名:UserController、UserService、UserMapper
模型名:User、UserDTO、UserVO
对象名:userController
常量名:USER_NAMEB) Service/DAO 层方法命名规约
1) 获取单个对象的方法用 get 做前缀。
2) 获取多个对象的方法用 list 做前缀,复数结尾,如:listObjects。
3) 获取统计值的方法用 count 做前缀。
4) 插入的方法用 save/insert 做前缀。
5) 删除的方法用 remove/delete 做前缀。
6) 修改的方法用 update 做前缀。注意:POJO 类中布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列化错误。
二、代码格式
1. if/for/while/switch/do 等保留字与括号之间都必须加空格
2. 任何二目、三目运算符的左右两边都需要加一个空格,包括赋值运算符=、逻辑运算符&&、加减乘除符号等。
3. 注释的双斜线与注释内容之间有且仅有一个空格。
4. 在进行类型强制转换时,右括号与强制转换值之间不需要任何空格隔开。
5. 方法参数在定义和传入时,多个参数逗号后边必须加空格。三、集合篇
1. 栈、队列、双端队列
Stack<Integer> stack = new Stack<>(); // 栈stack.push(1); // 压入stack.pop(); // 弹出stack.peek(); // 获取但不弹出Queue<Integer> queue = new ArrayDeque<>(); //队列queue.offer(1); //压入queue.poll(); // 弹出queue.peek(); // 获取但不弹出Deque<Integer> deque = new ArrayDeque<>(); // 双端队列deque.offerFirst(1); // 压入队头deque.offerLast(2); // 压入对尾deque.pollFirst(); // 弹出队头deque.pollLast(); // 弹出队尾deque.peekFirst(); // 获取队头但不弹出deque.peekLast(); // 获取队尾但不弹出
2. List的升序倒序
List<Integer> list = Arrays.asList(10,1,6,4,8,7,9,3,2,5);System.out.println("原始数据:");list.forEach(n ->{System.out.print(n+", ");});System.out.println("");System.out.println("升序排列:");Collections.sort(list); // 升序排列list.forEach(n ->{System.out.print(n+", ");});// 降序的话:需要先升序再倒序,才能有降序的结果System.out.println("");System.out.println("降序排列:");Collections.reverse(list); // 倒序排列list.forEach(n ->{System.out.print(n+", ");});
3. Map的升序降序
Map<Integer, String> map = new HashMap<>();map.put(100, "I'am a");map.put(99, "I'am c");map.put(2, "I'am d");map.put(33, "I'am b");// 按照value进行倒排,如果要根据key进行排序的话使用Map.Entry.comparingByKey()map.entrySet().stream().sorted(Collections.reverseOrder(Map.Entry.comparingByValue())).forEach(System.out::println);// 根据value进行正序排序,根据key进行排序的话使用comparingByKey()map.entrySet().stream().sorted(Map.Entry.comparingByValue()).forEach(System.out::println);// 如果要将排序的结果返回的话,我们可以使用下面的方法(注意:要使用LinkedHashMap进行保存,linkedHashMap可以保存插入顺序)Map<Integer, String> resultMap1 = map.entrySet().stream().sorted(Map.Entry.comparingByValue()).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (s, s2) -> s,LinkedHashMap::new));// 下面的这种写法同上面的写法,只不过是将简写展开了,这样更易于理解Map<Integer, String> resultMap = map.entrySet().stream().sorted(Map.Entry.comparingByValue()).collect(Collectors.toMap(new Function<Map.Entry<Integer, String>, Integer>() {@Overridepublic Integer apply(Map.Entry<Integer, String> integerStringEntry) {return integerStringEntry.getKey();}}, new Function<Map.Entry<Integer, String>, String>() {@Overridepublic String apply(Map.Entry<Integer, String> integerStringEntry) {return integerStringEntry.getValue();}}, new BinaryOperator<String>() {@Overridepublic String apply(String s, String s2) {return s;}}, new Supplier<Map<Integer, String>>() {@Overridepublic Map<Integer, String> get() {return new LinkedHashMap<>();}}));// 同样如果需要将排序的将结果作为Map进行返回我们还可以使用下面的方法,但是不推荐这种方式(effectivejava 178页中说:foreach操作应该只用于报告stream计算的结果,而不是执行计算)Map<Integer, String> result2 = new LinkedHashMap<>();map.entrySet().stream().sorted(Map.Entry.comparingByValue()).forEach(new Consumer<Map.Entry<Integer, String>>() {@Overridepublic void accept(Map.Entry<Integer, String> integerStringEntry) {result2.put(integerStringEntry.getKey(), integerStringEntry.getValue());}});
4. 二维数组排序
Arrays.sort(intervals, new Comparator<int[]>() {public int compare(int[] interval1, int[] interval2) {return interval1[0] - interval2[0];}});
5. 集合之间的转换
// Object转基本元素
List<String> tableNames=list.stream().map(User::getMessage).collect(Collectors.toList());// Object转Map
Map<String, Account> map = accounts.stream().collect(Collectors.toMap(Account::getUsername, Function.identity(), (key1, key2) -> key2));// Object转Map
/** * 1. 避免key重复* 在使用 java.util.stream.Collectors 类的 toMap()方法转为 Map 集合时,一定要使* 用含有参数类型为 BinaryOperator,参数名为 mergeFunction 的方法,否则当出现相同 key* 值时会抛出 IllegalStateException 异常。* 说明:参数 mergeFunction 的作用是当出现 key 重复时,自定义对 value 的处理策略* 2. 避免值为null* 在使用 java.util.stream.Collectors 类的 toMap()方法转为 Map 集合时,一定要注* 意当 value 为 null 时会抛 NPE 异常。
**/
Map<Long, String> getIdNameMap = accounts.stream().collect(Collectors.toMap(Account::getId, Account::getUsernamee, (v1, v2) -> v2));// String转Long
List<Long>=stringList.stream().map(Long::valueOf).collect(Collectors.toList());// Long转String
List<String>=longList.stream().map(String::valueOf).collect(Collectors.toList());// Integer转Long
List<Long> listLong = JSONArray.parseArray(listInt.toString(),Long.class);// Long 转Integer
List<Integer> integerList = JSONArray.parseArray(LongList.toString(), Integer.class);
// 或者
List<Integer> integerList = longList.stream().map(x -> Integer.valueOf(String.valueOf(x))).collect(Collectors.toList());// JSONArray转List
JSONArray jsonArray = updateApplicationSchemaDTO.getJSONArray("configTrophyDTOList");
configTrophyDTOList = jsonArray.toJavaList(ConfigTrophyDTO.class);// List转数组
// 使用集合转数组的方法,必须使用集合的 toArray(T[] array)
String[] array = list.toArray(new String[0]);// 数组转List
/**
1. 使用工具类 Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方法,
它的 add/remove/clear 方法会抛出 UnsupportedOperationException 异常。
2. asList 的返回对象是一个 Arrays 内部类,并没有实现集合的修改方法。Arrays.asList 体现的是适配器模式,只是转换接口,后台的数据仍是数组。
**/
List list = Arrays.asList(strArray);
6. Map键值对遍历
不推荐使用ketSet()获取键集合,再遍历value,这样的性能较低。keySet 其实是遍历了 2 次,一次是转为 Iterator 对象,另一次是从 hashMap 中取出 key 所对应的value。而 entrySet 只是遍历了一次就把 key 和 value 都放到了 entry 中,效率更高。如果是 JDK8,使用
Map.forEach 方法。
System.out.println("====4、通过entrySet()获得key-value值——使用迭代器遍历====");
Set set1 = hashMap.entrySet();
Iterator iterator1 = set1.iterator();
while(iterator1.hasNext()){Object itset = iterator1.next();Map.Entry entry = (Map.Entry) itset;System.out.println(entry.getKey()+"-"+entry.getValue());
}
7. 重写equal与hashCode
package jianlejun.study;public class Student {private String name;// 姓名private String sex;// 性别private String age;// 年龄private float weight;// 体重private String addr;// 地址// 重写hashcode方法@Overridepublic int hashCode() {int result = name.hashCode();result = 17 * result + sex.hashCode();result = 17 * result + age.hashCode();return result;}// 重写equals方法@Overridepublic boolean equals(Object obj) {if(!(obj instanceof Student)) {// instanceof 已经处理了obj = null的情况return false;}Student stuObj = (Student) obj;// 地址相等if (this == stuObj) {return true;}// 如果两个对象姓名、年龄、性别相等,我们认为两个对象相等if (stuObj.name.equals(this.name) && stuObj.sex.equals(this.sex) && stuObj.age.equals(this.age)) {return true;} else {return false;}}
}
8. ArrayList的subList
- ArrayList 的 subList 结果不可强转成 ArrayList,否则会抛出 ClassCastException 异
常:java.util.RandomAccessSubList cannot be cast to java.util.ArrayList。因为subList 返回的是 ArrayList 的内部类 SubList。此外subList()返回原来list的从[fromIndex, toIndex)之间这一部分的视图,之所以说是视图,是因为实际上,返回的list是靠原来的list支持的。 - 在 subList 场景中,高度注意对父集合元素的增加或删除,均会导致子列表的遍历、
增加、删除产生 ConcurrentModificationException 异常。
// 左闭右开
List<String> list = arrayList.subList(1,3);// 如果想防止原list被改变可以这样操作
List<Integer> sub = new ArrayList<Integer>(test.subList(1, 3));
9. keySet()/values()/entrySet()
使用 Map 的方法 keySet()/values()/entrySet()返回集合对象时,不可以对其进行添
加元素操作,否则会抛出 UnsupportedOperationException 异常。
10. Collections.emptyList()
- Collections.emptyList()返回一个空的List(list != null,size == 0),这是因为new ArrayList()创建时有初始大小,占用内存,emptyList()不用创建一个新的对象,可以减少内存开销;但是所以返回的List不能进行
增加和删除元素操作。
private static List<String> getList(String str) {if (StringUtils.isBlank(str)) {// 使用时不会报空指针return Collections.emptyList(); }List<String> list = new ArrayList<String>();list.add(str);return list;}
11. Collections.singletonList(str)
- 在实际的开发中,如果有特殊要求只需要List存放一个的元素,就可以使用Collections.singletonList作为数据结构来存放数据啦。
List<String> myList = Collections.singletonList(str);
12. Collection接口的addAll()
- 在使用 Collection 接口任何实现类的 addAll()方法时,都要对输入的集合参数进行
NPE 判断。
//1. addAll()测试//1.1 初始化多种情形的集合List<String> addList = null;List<String> addList1 = new ArrayList<String>();List<String> addList2 = new ArrayList<String>(Arrays.asList("epsilon", "zeta", "eta"));List<String> addList3 = new ArrayList<String>(Arrays.asList(null, "epsilon", "zeta", "eta"));//1.2 测试list.addAll(addList);//addList为null,报空指针list.addAll(addList1);//addList1为[],不报错list.addAll(addList2);//addList2无null,不报错list.addAll(addList3);//addList3有null,不报错
13. foreach与iterator()
不要在 foreach 循环里进行元素的 remove/add 操作。remove 元素请使用 Iterator
方式
// 正例:
List<String> list = new ArrayList<>();
list.add("1");
list.add("2");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {String item = iterator.next();if (删除元素的条件) {iterator.remove();}
}
// 反例:
for (String item : list) {if ("1".equals(item)) {list.remove(item);}
}
14. 使用Set去重
利用 Set 元素唯一的特性,可以快速对一个集合进行去重操作,避免使用 List 的
contains()进行遍历去重或者判断包含操作。
// Set集合去重,保持原来顺序public static void ridRepeat2(List<String> list) {System.out.println("list = [" + list + "]");List<String> listNew = new ArrayList<String>();Set set = new HashSet();for (String str : list) {if (set.add(str)) {listNew.add(str);}}System.out.println("listNew = [" + listNew + "]");}// Set去重 由于Set(HashSet)的无序性,不会保持原来顺序public static void ridRepeat3(List<String> list) {System.out.println("list = [" + list + "]");Set set = new HashSet();List<String> listNew = new ArrayList<String>();set.addAll(list);listNew.addAll(set);System.out.println("listNew = [" + listNew + "]");}// Set通过HashSet去重(将ridRepeat3方法缩减为一行) 无序public static void ridRepeat4(List<String> list) {System.out.println("list = [" + list + "]");List<String> listNew = new ArrayList<String>(new HashSet(list));System.out.println("listNew = [" + listNew + "]");}// Set通过TreeSet去重 会按字典顺序重排序public static void ridRepeat5(List<String> list) {System.out.println("list = [" + list + "]");List<String> listNew = new ArrayList<String>(new TreeSet<String>(list));System.out.println("listNew = [" + listNew + "]");}// Set通过LinkedHashSet去重 保持原来顺序public static void ridRepeat6(List<String> list) {System.out.println("list = [" + list + "]");List<String> listNew = new ArrayList<String>(new LinkedHashSet<String>(list));System.out.println("listNew = [" + listNew + "]");}
四、并发篇
1. 创建线程池
ThreadPoolExecutor 参数介绍
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {}
参数 1:corePoolSize
核心线程数,线程池中始终存活的线程数。
参数 2:maximumPoolSize
最大线程数,线程池中允许的最大线程数,当线程池的任务队列满了之后可以创建的最大线程数。
参数 3:keepAliveTime
最大线程数可以存活的时间,当线程中没有任务执行时,最大线程就会销毁一部分,最终保持核心线程数量的线程。
参数 4:unit:
单位是和参数 3 存活时间配合使用的,合在一起用于设定线程的存活时间 ,参数 keepAliveTime 的时间单位有以下 7 种可选:
TimeUnit.DAYS:天
TimeUnit.HOURS:小时
TimeUnit.MINUTES:分
TimeUnit.SECONDS:秒
TimeUnit.MILLISECONDS:毫秒
TimeUnit.MICROSECONDS:微妙
TimeUnit.NANOSECONDS:纳秒
参数 5:workQueue
一个阻塞队列,用来存储线程池等待执行的任务,均为线程安全,它包含以下 7 种类型:较常用的是 LinkedBlockingQueue 和 Synchronous,线程池的排队策略与 BlockingQueue 有关。
ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
SynchronousQueue:一个不存储元素的阻塞队列,即直接提交给线程不保持它们。
PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
DelayQueue:一个使用优先级队列实现的无界阻塞队列,只有在延迟期满时才能从中提取元素。
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。与SynchronousQueue类似,还含有非阻塞方法。
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
参数 6:threadFactory
线程工厂,主要用来创建线程,默认为正常优先级、非守护线程。
参数 7:handler
拒绝策略,拒绝处理任务时的策略,系统提供了 4 种可选:默认策略为 AbortPolicy。
AbortPolicy:拒绝并抛出异常。
CallerRunsPolicy:使用当前调用的线程来执行此任务。
DiscardOldestPolicy:抛弃队列头部(最旧)的一个任务,并执行当前任务。
DiscardPolicy:忽略并抛弃当前任务。
ThreadPoolExecutor执行流程
ThreadPoolExecutor 关键节点的执行流程如下:
- 当线程数小于核心线程数时,创建线程。
- 当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
- 当线程数大于等于核心线程数,且任务队列已满:若线程数小于最大线程数,创建线程;若线程数等于最大线程数,抛出异常,拒绝任务。
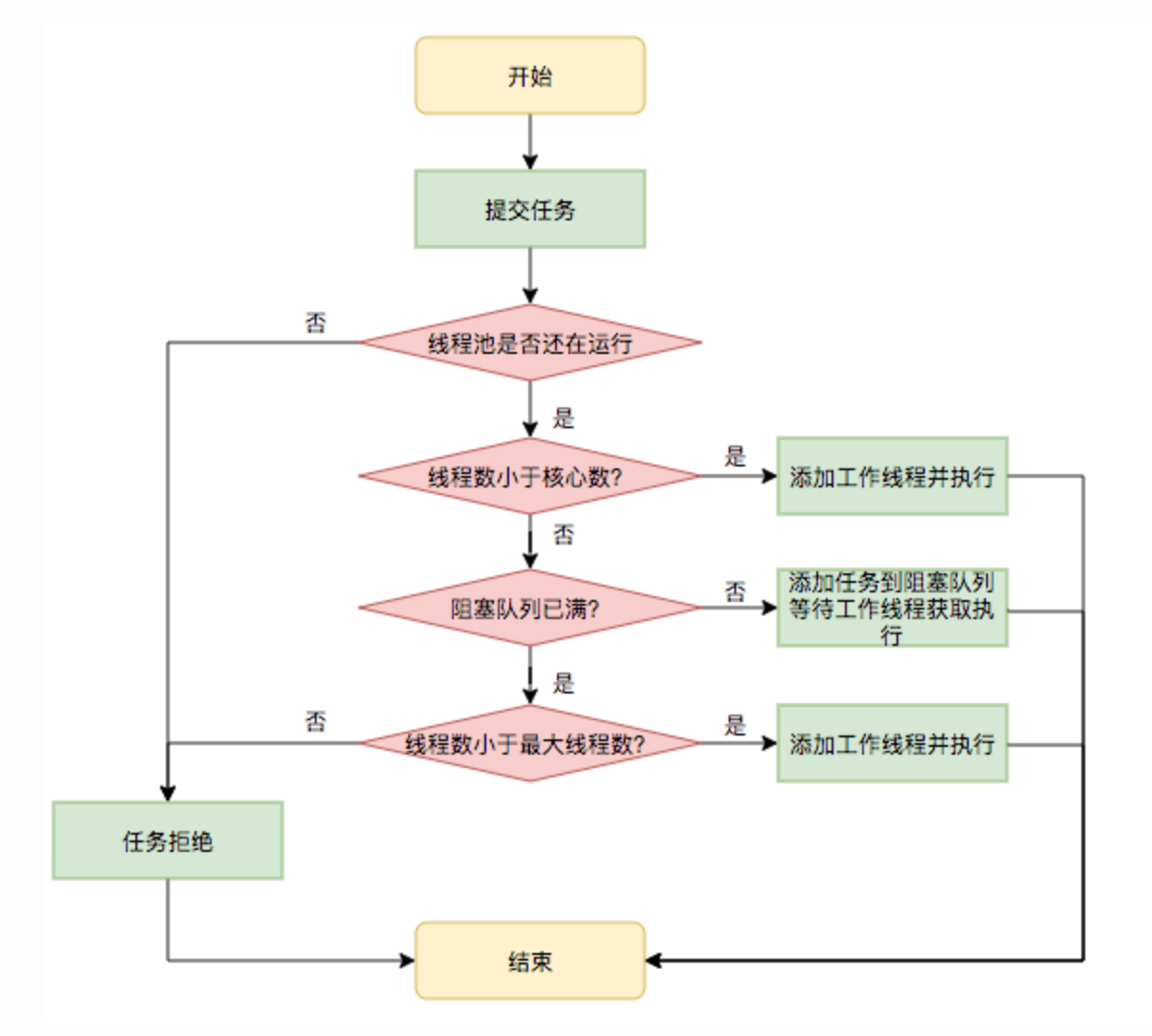
ThreadPoolExecutor自定义拒绝策略
public static void main(String[] args) {// 任务的具体方法Runnable runnable = new Runnable() {@Overridepublic void run() {System.out.println("当前任务被执行,执行时间:" + new Date() +" 执行线程:" + Thread.currentThread().getName());try {// 等待 1sTimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}}};// 创建线程,线程的任务队列的长度为 1ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 1,100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1),new RejectedExecutionHandler() {@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {// 执行自定义拒绝策略的相关操作System.out.println("我是自定义拒绝策略~");}});// 添加并执行 4 个任务threadPool.execute(runnable);threadPool.execute(runnable);threadPool.execute(runnable);threadPool.execute(runnable);
}
2. ThreadLocal的使用
/**
ThreadLocal的api很简单,就4个* get——获取threadlocal局部变量* set——设置threadlocal局部变量* initialvalue——设置局部变量的初始值* remove——删除该局部变量
**/
public class SequenceNumber { // ThreadLocal 对象使用 static 修饰,ThreadLocal 无法解决共享对象的更新问题。private static ThreadLocal<Integer> seqNum = new ThreadLocal<Integer>(){ public Integer initialValue(){ return 0; } }; public int getNextNum() { seqNum.set(seqNum.get() + 1); return seqNum.get(); } public static void main(String[] args) { SequenceNumber sn = new SequenceNumber(); TestClient t1 = new TestClient(sn); TestClient t2 = new TestClient(sn); TestClient t3 = new TestClient(sn); t1.start(); t2.start(); t3.start(); t1.print(); t2.print(); t3.print(); }
}private static class TestClient extends Thread { private SequenceNumber sn; public TestClient(SequenceNumber sn ) { this.sn = sn; } public void run() { for(int i=0; i< 3; i++) { System.out.println( Thread.currentThread().getName() + " --> " + sn.getNextNum()); } } public void print() { for(int i=0; i< 3; i++) { System.out.println( Thread.currentThread().getName() + " --> " + sn.getNextNum()); } }
}
Thread-2 --> 1
Thread-2 --> 2
Thread-2 --> 3
Thread-0 --> 1
Thread-0 --> 2
Thread-0 --> 3
Thread-1 --> 1
Thread-1 --> 2
Thread-1 --> 3
main --> 1
main --> 2
main --> 3
main --> 4
main --> 5
main --> 6
main --> 7
main --> 8
main --> 9
结论:可以发现,static的ThreadLocal变量是一个与线程相关的静态变量,即一个线程内,static变量是被各个实例共同引用的,但是不同线程内,static变量是隔开的。
五、时间篇
1. LocalDateTime的使用
// 获取当前时间
LocalDateTime now = LocalDateTime.now();// 获取指定时间
LocalDateTime localDateTime = LocalDateTime.of(2021, 6, 16, 16, 37, 20, 814 * 1000 * 1000);
LocalDateTime ldt = LocalDateTime.now().withYear(2021).withMonth(6).withDayOfMonth(16).withHour(10).withMinute(10).withSecond(59).withNano(999 * 1000 * 1000);// 获取指定时区时间
LocalDateTime datetime = LocalDateTime.now(ZoneId.of("Asia/Shanghai"));
LocalDateTime datetime2 = LocalDateTime.now(ZoneId.of("+8"));// 获取年月日信息
LocalDateTime now = LocalDateTime.now();
int year = now.getYear();
int month = now.getMonthValue();
int dayOfYear = now.getDayOfYear();
int dayOfMonth = now.getDayOfMonth();
int hour = now.getHour();
int minute = now.getMinute();
int second = now.getSecond();
int nano = now.getNano();// 日期计算
LocalDateTime now = LocalDateTime.now();
LocalDateTime tomorrow = now.plusDays(1L);
tomorrow = tomorrow.plusHours(2L);
tomorrow = tomorrow.plusMinutes(10L);LocalDateTime yesterday = now.minus(Duration.ofDays(1));
yesterday = yesterday.plusHours(2L);
yesterday = yesterday.plusMinutes(10L);// 时间格式化,DateTimeFormatter是线程安全的类。
DateTimeFormatter df = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
String format = LocalDateTime.now().format(df);
2. String、Date、LocalDateTime转换
// LocalDateTime转Date
public static Date localDateTime2Date(LocalDateTime localDateTime) {return Date.from(localDateTime.atZone(ZoneId.systemDefault()).toInstant());
}// LocalDateTime转String
private static final DateTimeFormatter DATE_TIME_FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
public static String localDateTime2String(LocalDateTime localDateTime) {return localDateTime.format(DATE_TIME_FORMATTER);
}// String 转 LocalDateTime,DateTimeFormatter是线程安全的类,可以将此类放到常量中。
private static final DateTimeFormatter DATE_TIME_FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
public static LocalDateTime string2LocalDateTime(String str) {return LocalDateTime.parse(str, DATE_TIME_FORMATTER);
}// String 转 Date,SimpleDateFormat是非线程安全的类,在多线程操作时会报错。
public static Date string2Date(String str) throws ParseException {SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");return simpleDateFormat.parse(str);
}// Date 转 LocalDateTime
public static LocalDateTime date2LocalDateTime(Date date) {return date.toInstant().atZone(ZoneId.systemDefault()).toLocalDateTime();
}// Date 转 String
public static String date2String(Date date) {SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");return formatter.format(date);
}
六、控制块
1. switch
public class SwitchString {public static void main(String[] args) {method("sth");}public static void method(String param) {// 1. 当 switch 括号内的变量类型为 String 并且为外部参数时,必须先进行 null判断。if(StringUtils.isEmpty(param)){return;}switch(param){case"sth": System.out.printin("it's sth"); break;case"sb": System.out.println("it's sb"); break;// 2. 在一个 switch 块内,都必须包含一个 default语句并且放在最后default: System.out.println("default"); break;}}
}
2. 三目运算
三目运算符 condition? 表达式 1 : 表达式 2 中,高度注意表达式 1 和 2 在类型对齐 时,可能抛出因自动拆箱导致的 NPE 异常。
// 反例
Integer a = 1;
Integer b = 2;
Integer c = null;
Boolean flag = false;
// a*b 的结果是 int 类型,那么 c 会强制拆箱成 int 类型,抛出 NPE 异常
Integer result=(flag? a*b : c);
3. 循环体
1. 循环体中的语句要考量性能,以下操作尽量移至循环体外处理,如定义对象、变量、 获取数据库连接,进行不必要的 try-catch 操作(这个 try-catch 是否可以移至循环体外)
4. try-catch-finally-return
- return的执行优先级高于finally的执行优先级,但是return语句执行完毕之后并不会马上结束函数,而是将结果保存到栈帧中的局部变量表中,然后继续执行finally块中的语句;
- 如果finally块中包含return语句,则不会对try块中要返回的值进行保护,而是直接跳到finally语句中执行,并最后在finally语句中返回,返回值是在finally块中改变之后的值
// return 1
public static int test1() {int x = 1;try {return x;} finally {x = 2;}
}// return 2
public static int test2() {int x = 1;try {return x;} finally {x = 2;return x;}
}
七、其他
1. 正则表达式
在使用正则表达式时,利用好其预编译功能,可以有效加快正则匹配速度。
// 反例
public void addSyncConfigToCache(String configName, ESSyncConfig config) {Pattern pattern = Pattern.compile(".*:(.*)://.*/(.*)\\?.*$");Matcher matcher = pattern.matcher(dataSource.getUrl());
}// 正例
private static final Pattern pattern = Pattern.compile(regexRule);
public void addSyncConfigToCache(String configName, ESSyncConfig config) {Matcher matcher = pattern.matcher(dataSource.getUrl());
}
2. BeanUtil的copy
Apache BeanUtils 性能较差,可以使用其他方案比如 Spring BeanUtils, Cglib BeanCopier,注意
均是浅拷贝。
Person source = Person("Alice", 25);
Person destination = new Person();
BeanUtils.copyProperties(destination, source);
3. Integer的比较
所有整型包装类对象之间值的比较,全部使用 equals 方法比较
Integer a = 123;
Integer b = 321;
a.equal(b); // false
4. 浮点数的比较
基本数据类型使用Math.abs(),包装类使用BigDecimal;
// 基本数据类型
float a = 1.0f - 0.9f;
float b = 0.9f - 0.8f;
float diff = 1e-6f;
if (Math.abs(a - b) < diff) {System.out.println("true");
}// 包装类
//禁止使用构造方法 BigDecimal(double)的方式把 double 值转化为 BigDecimal 对象。
BigDecimal a = new BigDecimal("1.0".toString());
BigDecimal b = BigDecimal.value(0.9f);
BigDecimal c = new BigDecimal("0.8".toString());
if (a.equals(b)) {System.out.println("false");
}
5. Object的clone方法
对象 clone 方法默认是浅拷贝,若想实现深拷贝需覆写 clone 方法实现域对象的深度遍历式拷贝。
public class Person implements Cloneable {private String name;private Integer age;private String sex;public Person() {super();}public Person(String name, Integer age, String sex) {super();this.name = name;this.age = age;this.sex = sex;}public void setName(String name) {this.name = name;}public void setAge(Integer age) {this.age = age;}public void setSex(String sex) {this.sex = sex;}@Overridepublic String toString() {return "Person [name=" + name + ", age=" + age + ", sex=" + sex + "]";}public Person clone() throws CloneNotSupportedException {return (Person) super.clone();}public static void main(String[] args) {Person person = new Person("Jachen", 23, "boy");System.out.println("person:" + person);try {Person person2 = person.clone();System.out.println("person2:" + person2);System.out.println("person.equals(person2):"+ person2.equals(person));person2.setName("Anna");person2.setSex("girl");person2.setAge(22);System.out.println(person2.getClass() == person.getClass());} catch (CloneNotSupportedException e) {e.printStackTrace();}}
}