一、本文介绍
本文给大家带来的教程是利用YOLOv5训练自己的数据集,以及有关YOLOv5的网络结构讲解/数据集获取/环境搭建/训练/推理/验证/导出/部署相关的教程,同时通过示例的方式让大家来了解具体的操作流程,过程中还分享给大家一些好用的资源,我还对其中的参数进行了详细的讲解,通过本文大家可以成功训练自己的数据集,在开始之前给大家推荐一下我的YOLOv5专栏,本专栏包含上百种YOLOv5的改进机制,以及如何撰写论文的教程,手把手教大家如何改进YOLOv5非常适合科研小白。
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新
目录
一、本文介绍
二、模型获取
三、数据集获取
四、环境搭建
五、训练教程
六、推理教程
七、验证教程
八、导出教程
二、模型获取
我们可以从官方的Github开源的地址进行下载即可。
官方代码下载地址:官方代码下载地址点击即可跳转
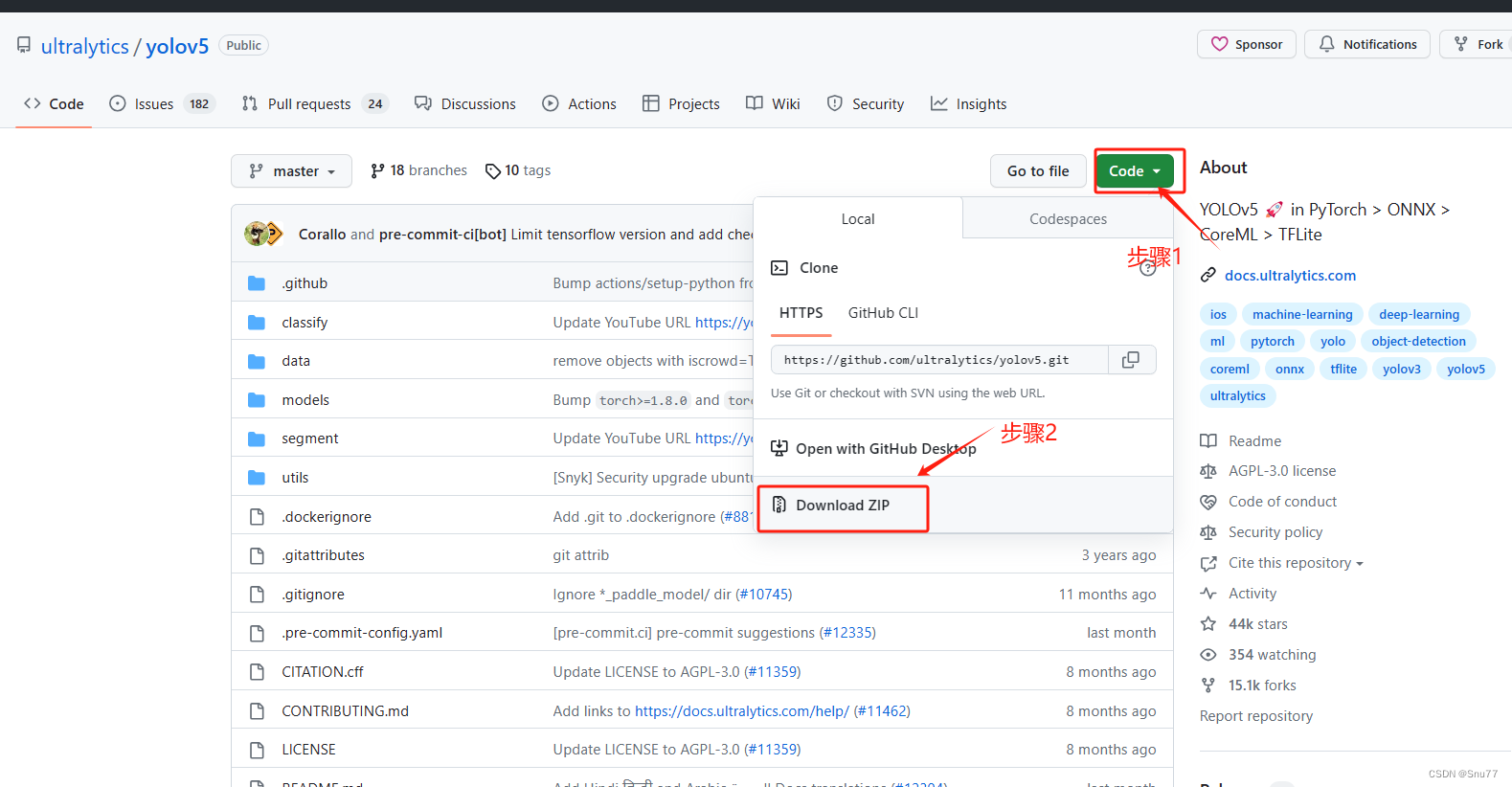 下载完之后,用我们自己熟悉的IDEA打开即可,YOLOv5不像YOLOv8可以通过pip下载,如果通过Git下载,大家也不能够统一,所以推荐大家就去官方下载最方便了,毕竟就是一个压缩包的事情。
下载完之后,用我们自己熟悉的IDEA打开即可,YOLOv5不像YOLOv8可以通过pip下载,如果通过Git下载,大家也不能够统一,所以推荐大家就去官方下载最方便了,毕竟就是一个压缩包的事情。
三、数据集获取
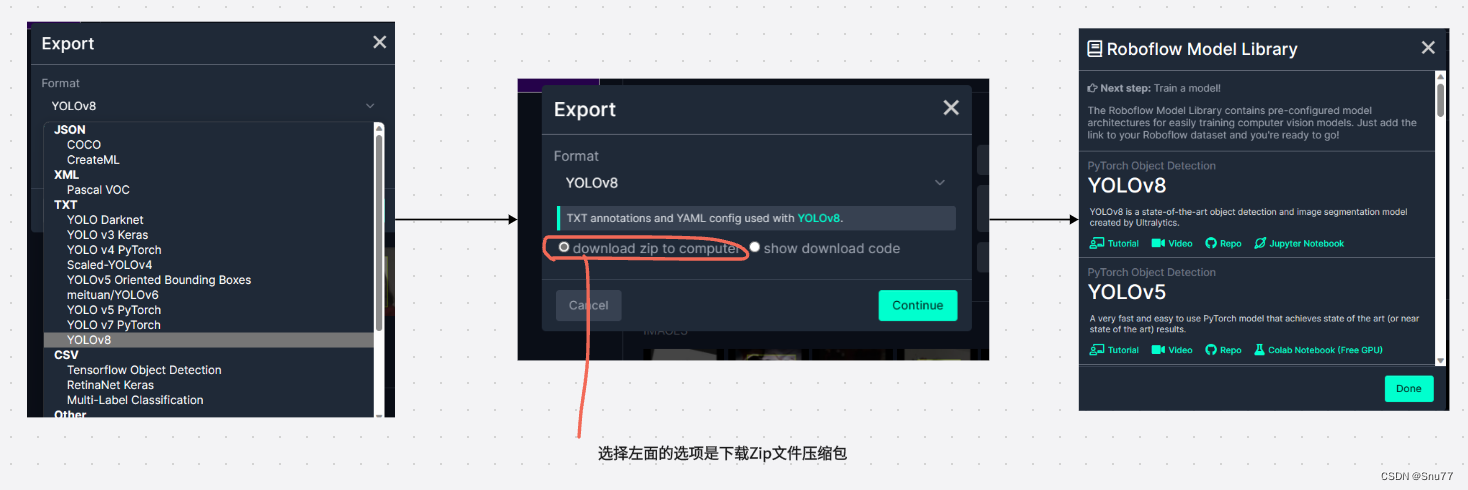
在开始训练之前,我们必须准备一份数据集,网上有很多都是给大家转换脚本,我这里给大家推荐一个免费的数据集网站,里面包含200000+的数据集包括各种VOC、COCO数据集,而且可以一键导出我们想要的数据集格式,下载过后的数据集,我们拿过来直接就可以使用无需做任何的修改了。
数据集教程:超详细教程YoloV5官方推荐免费数据集网站Roboflow一键导出Voc、COCO、Yolo、Csv等格式
四、环境搭建
大家如果没有搭建环境可以看我的另一篇博客,里面讲述了如何搭建pytorch环境(内容十分详细我每次重新更换系统都要看一遍)。
Win11上Pytorch的安装并在Pycharm上调用PyTorch最新超详细过程并附详细的系统变量添加过程,可解决pycharm中pip不好使的问题
在我们配置好环境之后,在之后模型获取完成之后,我们可以进行配置的安装我们可以在命令行下输入如下命令进行环境的配置。
pip install -r requirements.txt输入如上命令之后我们就可以看到命令行在安装模型所需的库了。
五、训练教程
YOLO采用的是文件训练的形式,每一个功能都定义了一个文件,我们通过目录下的'train.py'进行训练即可,这里主要讲解一下其中的参数含义,以及必备的设置。
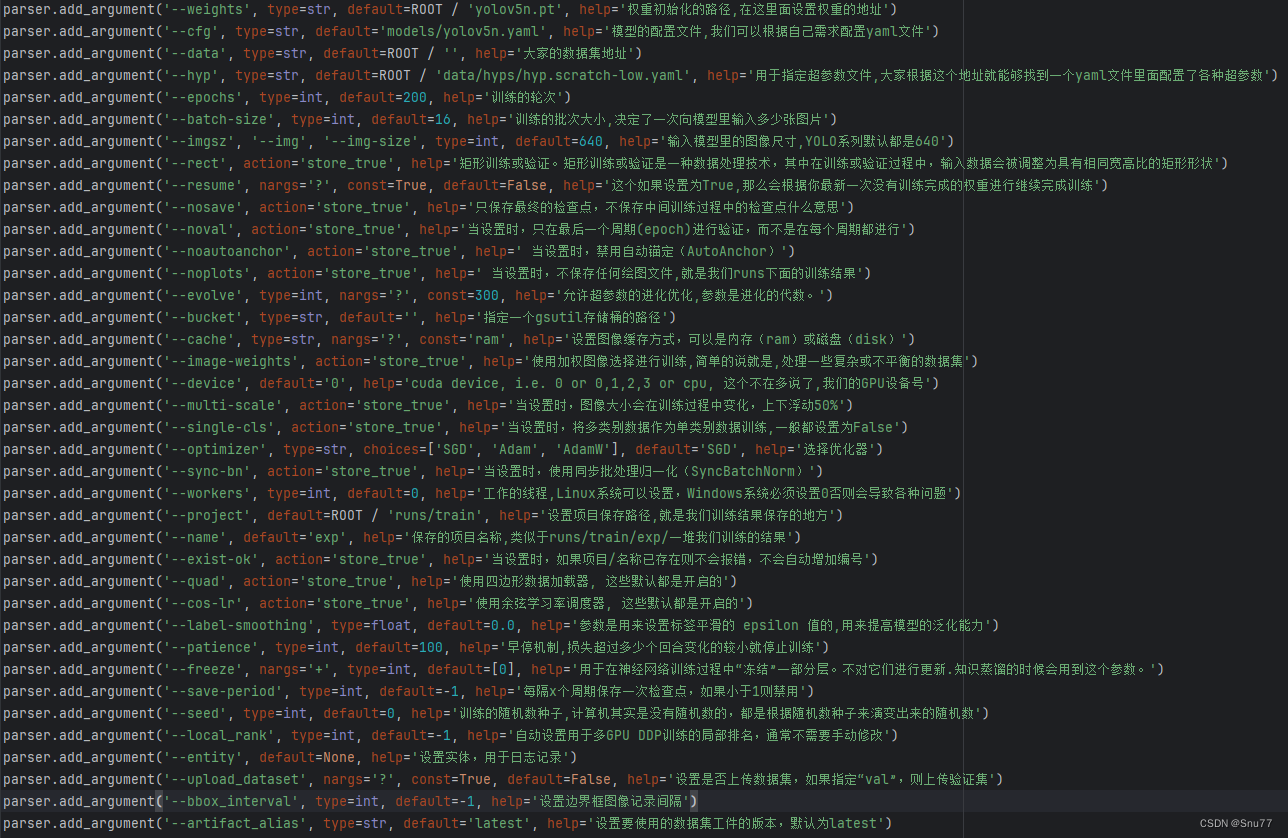
def parse_opt(known=False):parser = argparse.ArgumentParser()parser.add_argument('--weights', type=str, default=ROOT / 'yolov5n.pt', help='权重初始化的路径,在这里面设置权重的地址')parser.add_argument('--cfg', type=str, default='models/yolov5n.yaml', help='模型的配置文件,我们可以根据自己需求配置yaml文件')parser.add_argument('--data', type=str, default=ROOT / '', help='大家的数据集地址')parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='用于指定超参数文件,大家根据这个地址就能够找到一个yaml文件里面配置了各种超参数')parser.add_argument('--epochs', type=int, default=200, help='训练的轮次')parser.add_argument('--batch-size', type=int, default=16, help='训练的批次大小,决定了一次向模型里输入多少张图片')parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='输入模型里的图像尺寸,YOLO系列默认都是640')parser.add_argument('--rect', action='store_true', help='矩形训练或验证。矩形训练或验证是一种数据处理技术,其中在训练或验证过程中,输入数据会被调整为具有相同宽高比的矩形形状')parser.add_argument('--resume', nargs='?', const=True, default=False, help='这个如果设置为True,那么会根据你最新一次没有训练完成的权重进行继续完成训练')parser.add_argument('--nosave', action='store_true', help='只保存最终的检查点,不保存中间训练过程中的检查点什么意思')parser.add_argument('--noval', action='store_true', help='当设置时,只在最后一个周期(epoch)进行验证,而不是在每个周期都进行')parser.add_argument('--noautoanchor', action='store_true', help=' 当设置时,禁用自动锚定(AutoAnchor)')parser.add_argument('--noplots', action='store_true', help=' 当设置时,不保存任何绘图文件,就是我们runs下面的训练结果')parser.add_argument('--evolve', type=int, nargs='?', const=300, help='允许超参数的进化优化,参数是进化的代数。')parser.add_argument('--bucket', type=str, default='', help='指定一个gsutil存储桶的路径')parser.add_argument('--cache', type=str, nargs='?', const='ram', help='设置图像缓存方式,可以是内存(ram)或磁盘(disk)')parser.add_argument('--image-weights', action='store_true', help='使用加权图像选择进行训练,简单的说就是,处理一些复杂或不平衡的数据集')parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu, 这个不在多说了,我们的GPU设备号')parser.add_argument('--multi-scale', action='store_true', help='当设置时,图像大小会在训练过程中变化,上下浮动50%')parser.add_argument('--single-cls', action='store_true', help='当设置时,将多类别数据作为单类别数据训练,一般都设置为False')parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='选择优化器')parser.add_argument('--sync-bn', action='store_true', help='当设置时,使用同步批处理归一化(SyncBatchNorm)')parser.add_argument('--workers', type=int, default=0, help='工作的线程,Linux系统可以设置,Windows系统必须设置0否则会导致各种问题')parser.add_argument('--project', default=ROOT / 'runs/train', help='设置项目保存路径,就是我们训练结果保存的地方')parser.add_argument('--name', default='exp', help='保存的项目名称,类似于runs/train/exp/一堆我们训练的结果')parser.add_argument('--exist-ok', action='store_true', help='当设置时,如果项目/名称已存在则不会报错,不会自动增加编号')parser.add_argument('--quad', action='store_true', help='使用四边形数据加载器, 这些默认都是开启的')parser.add_argument('--cos-lr', action='store_true', help='使用余弦学习率调度器, 这些默认都是开启的')parser.add_argument('--label-smoothing', type=float, default=0.0, help='参数是用来设置标签平滑的 epsilon 值的,用来提高模型的泛化能力')parser.add_argument('--patience', type=int, default=100, help='早停机制,损失超过多少个回合变化的较小就停止训练')parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='用于在神经网络训练过程中“冻结”(freeze)一部分层。冻结的意思是在训练过程中保持这些层的权重不变,不对它们进行更新.知识蒸馏的时候会用到这个参数。')parser.add_argument('--save-period', type=int, default=-1, help='每隔x个周期保存一次检查点,如果小于1则禁用')parser.add_argument('--seed', type=int, default=0, help='训练的随机数种子,计算机其实是没有随机数的,都是根据随机数种子来演变出来的随机数')parser.add_argument('--local_rank', type=int, default=-1, help='自动设置用于多GPU DDP训练的局部排名,通常不需要手动修改')# Logger argumentsparser.add_argument('--entity', default=None, help='设置实体,用于日志记录')parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='设置是否上传数据集,如果指定“val”,则上传验证集')parser.add_argument('--bbox_interval', type=int, default=-1, help='设置边界框图像记录间隔')parser.add_argument('--artifact_alias', type=str, default='latest', help='设置要使用的数据集工件的版本,默认为latest')return parser.parse_known_args()[0] if known else parser.parse_args()在上面的所有参数里,我们只需要填写前三个就可以开始训练了(仅需配置好前三个),填好地址即可,其中pt权重文件,如果没有会自动联网下载,大家也可以在我门前面给的官方上主动下载到本地,填好参数之后,我们运行train.py文件就可以开始训练 。
六、推理教程
推理就是,利用我们训练好的权重文件,或者是官方提供的权重文件进行加载预测的过程,功能集成在'detect.py'文件里面,我下面对其中参数含义进行讲解然后进行一个简单的视频推理示例。
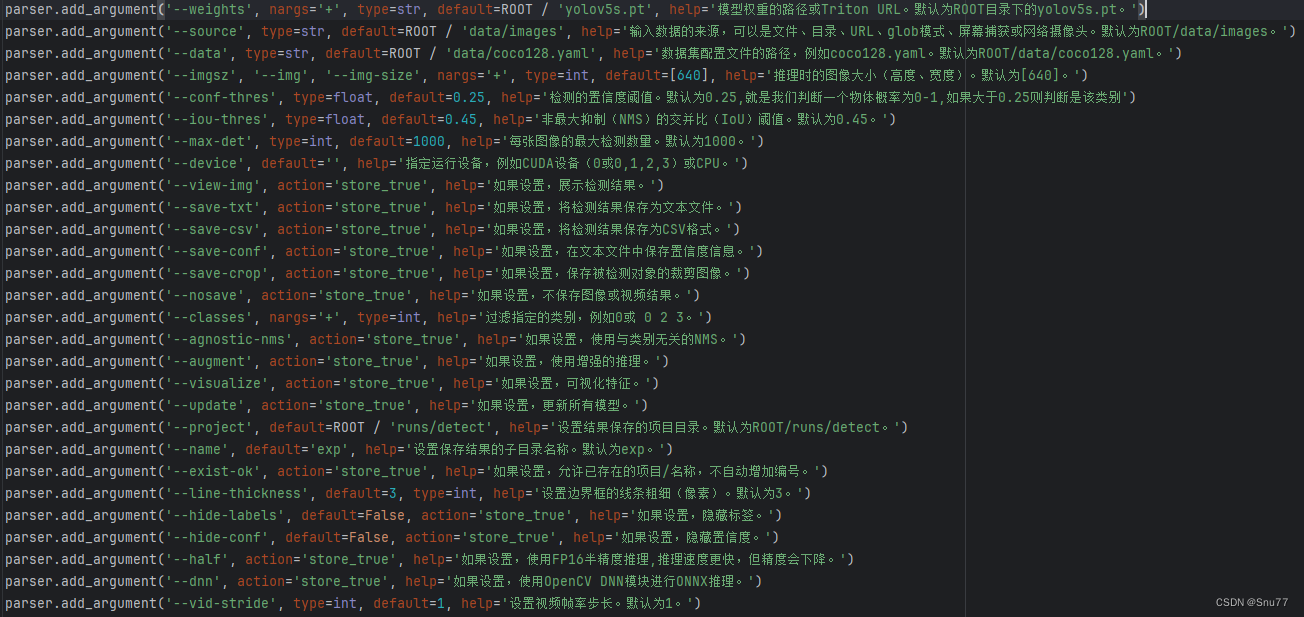
大家可以用下面的代码替换你的代码参数解析部分。
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='模型权重的路径或Triton URL。默认为ROOT目录下的yolov5s.pt。')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='输入数据的来源,可以是文件、目录、URL、glob模式、屏幕捕获或网络摄像头。默认为ROOT/data/images。')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='数据集配置文件的路径,例如coco128.yaml。默认为ROOT/data/coco128.yaml。')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='推理时的图像大小(高度、宽度)。默认为[640]。')
parser.add_argument('--conf-thres', type=float, default=0.25, help='检测的置信度阈值。默认为0.25,就是我们判断一个物体概率为0-1,如果大于0.25则判断是该类别')
parser.add_argument('--iou-thres', type=float, default=0.45, help='非最大抑制(NMS)的交并比(IoU)阈值。默认为0.45。')
parser.add_argument('--max-det', type=int, default=1000, help='每张图像的最大检测数量。默认为1000。')
parser.add_argument('--device', default='', help='指定运行设备,例如CUDA设备(0或0,1,2,3)或CPU。')
parser.add_argument('--view-img', action='store_true', help='如果设置,展示检测结果。')
parser.add_argument('--save-txt', action='store_true', help='如果设置,将检测结果保存为文本文件。')
parser.add_argument('--save-csv', action='store_true', help='如果设置,将检测结果保存为CSV格式。')
parser.add_argument('--save-conf', action='store_true', help='如果设置,在文本文件中保存置信度信息。')
parser.add_argument('--save-crop', action='store_true', help='如果设置,保存被检测对象的裁剪图像。')
parser.add_argument('--nosave', action='store_true', help='如果设置,不保存图像或视频结果。')
parser.add_argument('--classes', nargs='+', type=int, help='过滤指定的类别,例如0或 0 2 3。')
parser.add_argument('--agnostic-nms', action='store_true', help='如果设置,使用与类别无关的NMS。')
parser.add_argument('--augment', action='store_true', help='如果设置,使用增强的推理。')
parser.add_argument('--visualize', action='store_true', help='如果设置,可视化特征。')
parser.add_argument('--update', action='store_true', help='如果设置,更新所有模型。')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='设置结果保存的项目目录。默认为ROOT/runs/detect。')
parser.add_argument('--name', default='exp', help='设置保存结果的子目录名称。默认为exp。')
parser.add_argument('--exist-ok', action='store_true', help='如果设置,允许已存在的项目/名称,不自动增加编号。')
parser.add_argument('--line-thickness', default=3, type=int, help='设置边界框的线条粗细(像素)。默认为3。')
parser.add_argument('--hide-labels', default=False, action='store_true', help='如果设置,隐藏标签。')
parser.add_argument('--hide-conf', default=False, action='store_true', help='如果设置,隐藏置信度。')
parser.add_argument('--half', action='store_true', help='如果设置,使用FP16半精度推理,推理速度更快,但精度会下降。')
parser.add_argument('--dnn', action='store_true', help='如果设置,使用OpenCV DNN模块进行ONNX推理。')
parser.add_argument('--vid-stride', type=int, default=1, help='设置视频帧率步长。默认为1。')
下面我来进行一个简单的示例,
找到推理文件'detect.py',然后配置前两个参数即可,然后运行文件。

下面的是推理的过程,视频个本质就是帧处理,它会一帧一帧的处理。
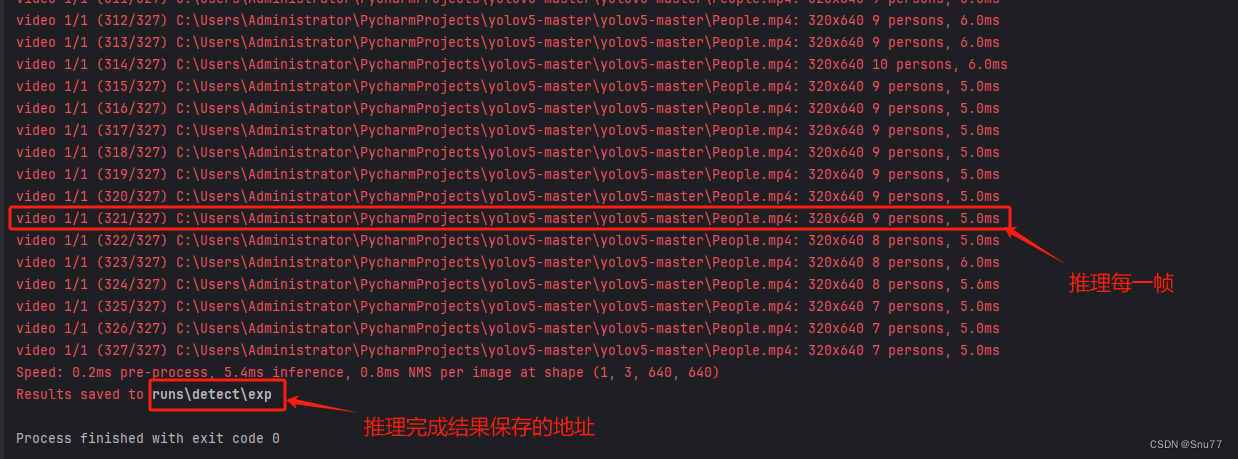
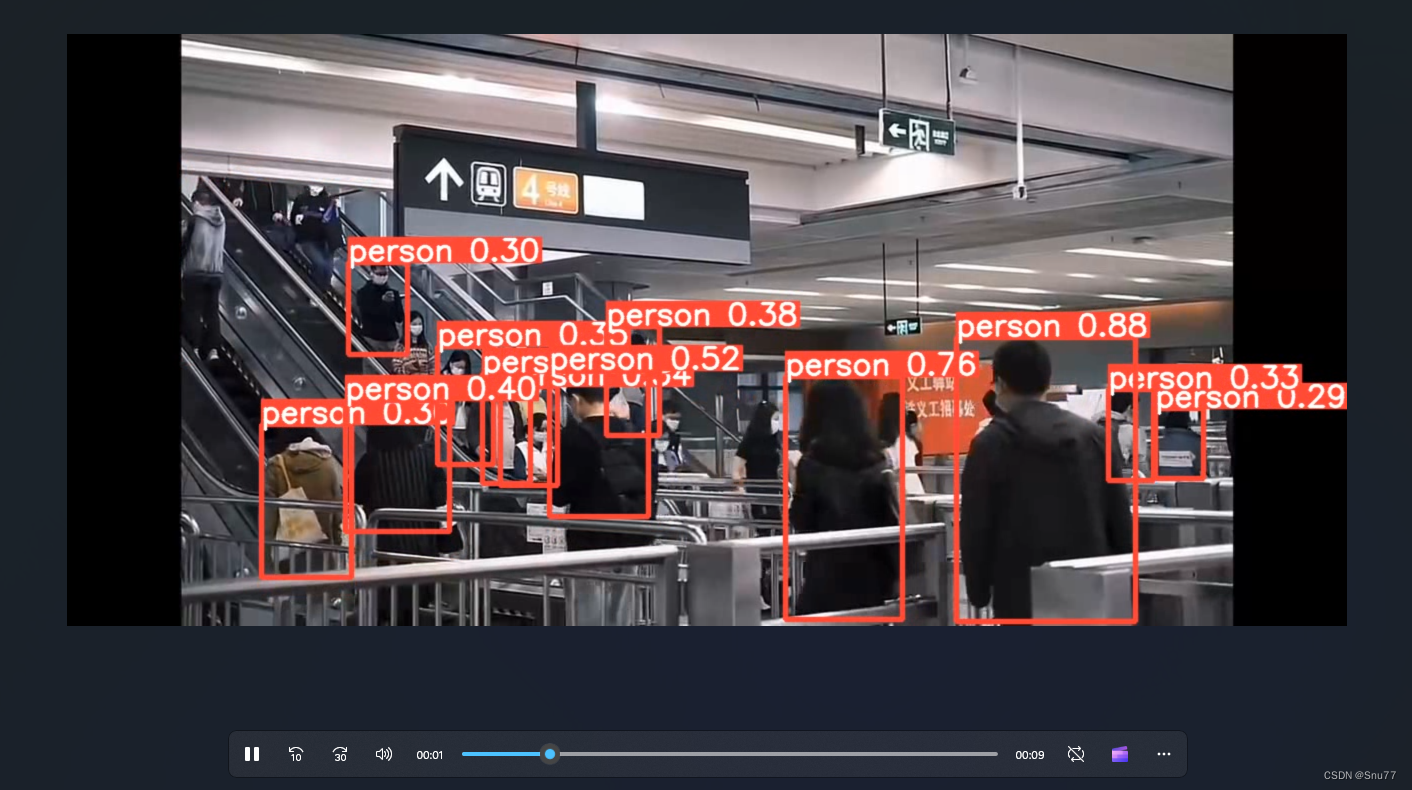
People
七、验证教程
推理的文件是'val.py'文件,其中的参数解释如下。
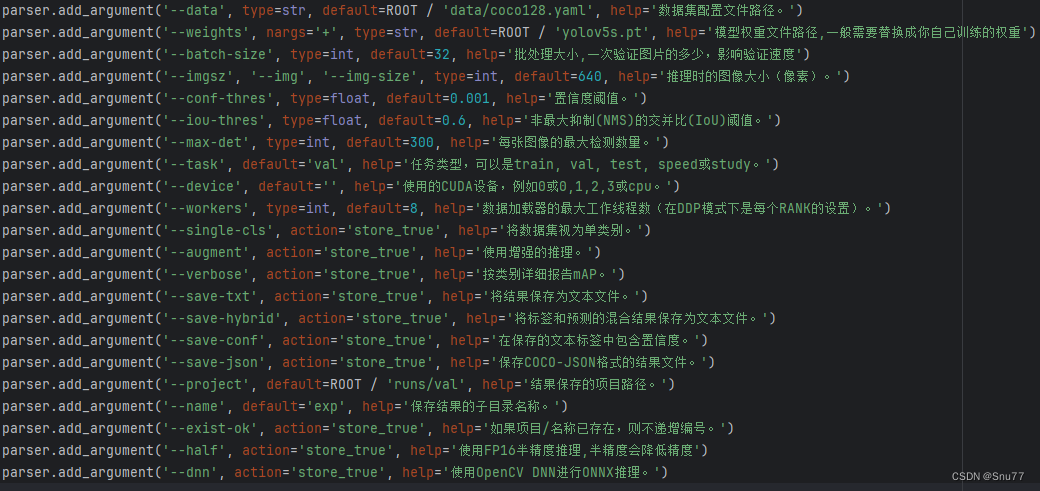
下面的是上面的代码块形式,大家可以复制粘贴。
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='数据集配置文件路径。')
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='模型权重文件路径,一般需要替换成你自己训练的权重')
parser.add_argument('--batch-size', type=int, default=32, help='批处理大小,一次验证图片的多少,影响验证速度')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='推理时的图像大小(像素)。')
parser.add_argument('--conf-thres', type=float, default=0.001, help='置信度阈值。')
parser.add_argument('--iou-thres', type=float, default=0.6, help='非最大抑制(NMS)的交并比(IoU)阈值。')
parser.add_argument('--max-det', type=int, default=300, help='每张图像的最大检测数量。')
parser.add_argument('--task', default='val', help='任务类型,可以是train, val, test, speed或study。')
parser.add_argument('--device', default='', help='使用的CUDA设备,例如0或0,1,2,3或cpu。')
parser.add_argument('--workers', type=int, default=8, help='数据加载器的最大工作线程数(在DDP模式下是每个RANK的设置)。')
parser.add_argument('--single-cls', action='store_true', help='将数据集视为单类别。')
parser.add_argument('--augment', action='store_true', help='使用增强的推理。')
parser.add_argument('--verbose', action='store_true', help='按类别详细报告mAP。')
parser.add_argument('--save-txt', action='store_true', help='将结果保存为文本文件。')
parser.add_argument('--save-hybrid', action='store_true', help='将标签和预测的混合结果保存为文本文件。')
parser.add_argument('--save-conf', action='store_true', help='在保存的文本标签中包含置信度。')
parser.add_argument('--save-json', action='store_true', help='保存COCO-JSON格式的结果文件。')
parser.add_argument('--project', default=ROOT / 'runs/val', help='结果保存的项目路径。')
parser.add_argument('--name', default='exp', help='保存结果的子目录名称。')
parser.add_argument('--exist-ok', action='store_true', help='如果项目/名称已存在,则不递增编号。')
parser.add_argument('--half', action='store_true', help='使用FP16半精度推理,半精度会降低精度')
parser.add_argument('--dnn', action='store_true', help='使用OpenCV DNN进行ONNX推理。')
八、导出教程
导出是为了将我们训练结果进行其它平台的部署,因为python的执行效率是很低的,所以为了加速推理速度,可以将模型进行导出,然后进行其它语言的部署,从而提高检测FPS。
其中的导出文件是'export.py'文件,利用这个文件我们就能将我们训练好的模型进行导出。
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='数据集配置文件的路径。')
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='模型权重文件的路径。')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='图像的高度和宽度。')
parser.add_argument('--batch-size', type=int, default=1, help='批处理大小。')
parser.add_argument('--device', default='cpu', help='使用的CUDA设备,例如0或0,1,2,3或cpu。')
parser.add_argument('--half', action='store_true', help='FP16半精度导出。')
parser.add_argument('--inplace', action='store_true', help='设置YOLOv5 Detect()的inplace参数为True。')
parser.add_argument('--keras', action='store_true', help='使用Keras(TensorFlow)。')
parser.add_argument('--optimize', action='store_true', help='TorchScript: 为移动端优化模型。')
parser.add_argument('--int8', action='store_true', help='CoreML/TF/OpenVINO的INT8量化。')
parser.add_argument('--dynamic', action='store_true', help='ONNX/TF/TensorRT: 动态轴。')
parser.add_argument('--simplify', action='store_true', help='ONNX: 简化模型。')
parser.add_argument('--opset', type=int, default=17, help='ONNX: opset版本。')
parser.add_argument('--verbose', action='store_true', help='TensorRT: 详细日志。')
parser.add_argument('--workspace', type=int, default=4, help='TensorRT: 工作空间大小(GB)。')
parser.add_argument('--nms', action='store_true', help='TensorFlow: 在模型中添加NMS。')
parser.add_argument('--agnostic-nms', action='store_true', help='TensorFlow: 添加与类别无关的NMS到模型。')
parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: 每个类别保留的topk。')
parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: 所有类别保留的topk。')
parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: 交并比(IoU)阈值。')
parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: 置信度阈值。')
parser.add_argument('--include',nargs='+',default=['torchscript'],help='支持的导出格式列表。可选项包括:torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle。')