如果您刚开始并且第一次设置 Kafka 和 ClickHouse 需要帮助怎么办?这篇文章也许会提供下帮助。
我们将通过一个端到端示例,使用 Kafka 引擎将数据从 Kafka 主题加载到 ClickHouse 表中。我们还将展示如何重置偏移量和重新加载数据,以及如何更改表架构。最后,我们将演示如何将数据从 ClickHouse 写回 Kafka 主题。
先决条件
下面的练习假设你已经安装并运行了 Kafka 和 ClickHouse。为了方便起见,我们使用了 Kubernetes。Kafka 版本是 Confluent 5.4.0,使用带有三个 Kafka 代理的 Kafka helm chart 安装。ClickHouse版本为20.4.2,使用ClickHouse Kubernetes Operator安装在单个节点上。
这些练习应该适用于任何类型的安装,但您需要相应地更改主机名。如果 Kafka 代理较少,则可能还需要更改复制因子。
Kafka-ClickHouse 集成概述
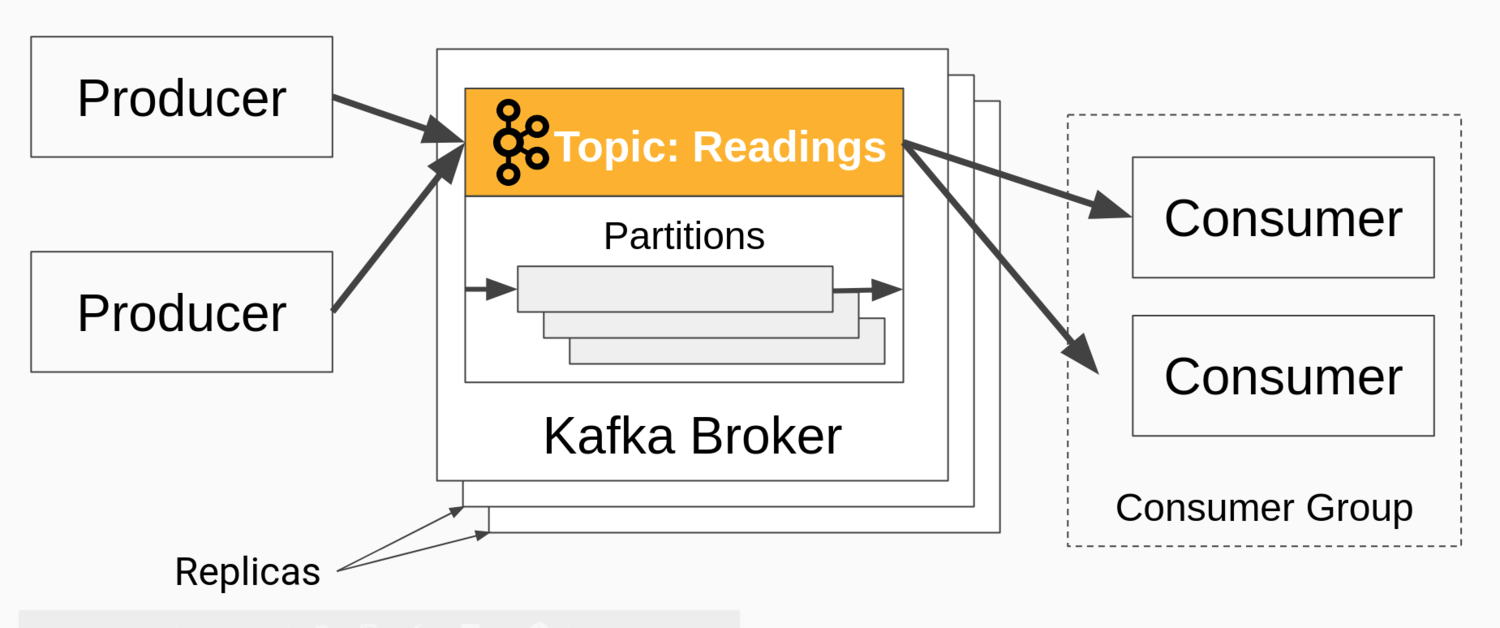
Kafka 是一种极具可扩展性的消息总线。它的核心是由运行在不同主机上的代理管理的分布式日志。以下是应用程序模型的简短说明。
生产者将消息写入主题,主题是一组消息。使用者从主题中读取消息,该主题分布在分区上。消费者被安排在消费者组中,这允许应用程序从 Kafka 并行读取消息,而不会丢失或重复。
下图说明了上述主要部分。
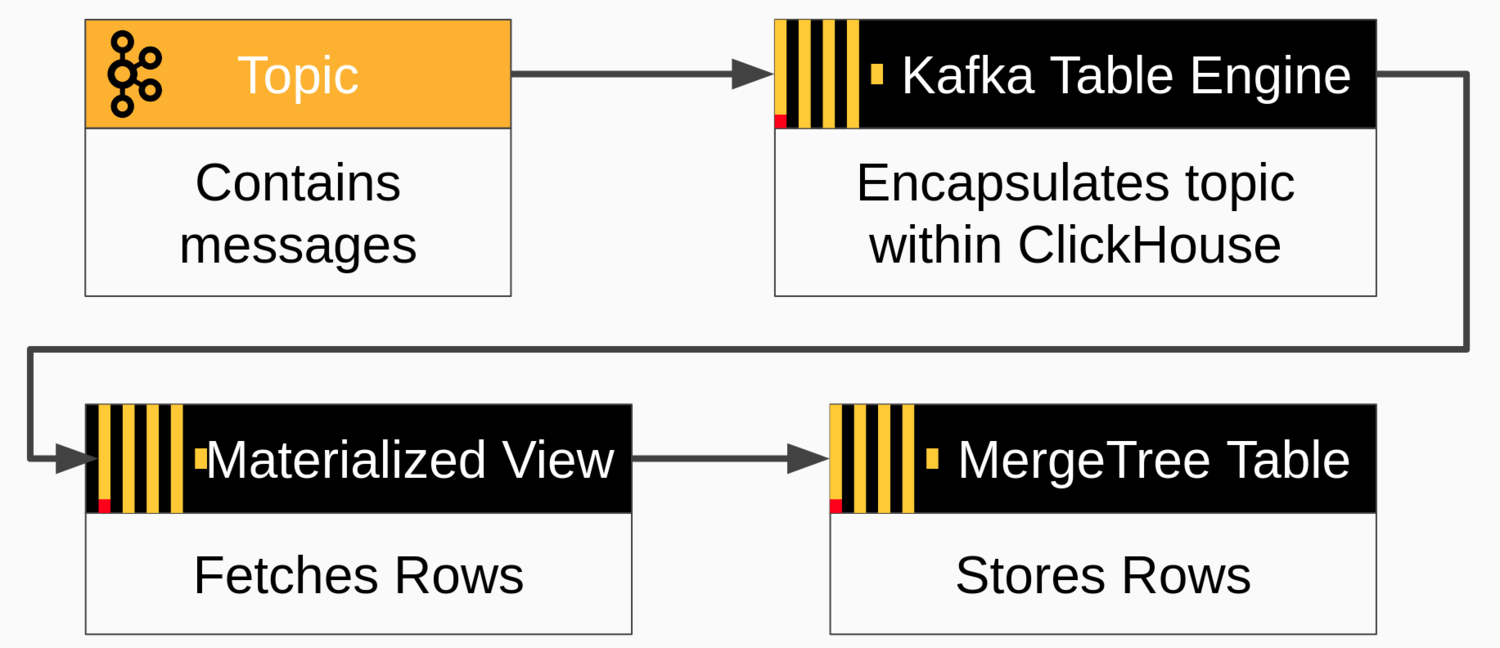
ClickHouse 可以使用 Kafka 表引擎和物化视图直接从 Kafka 主题读取消息,该视图获取消息并将其推送到 ClickHouse 目标表。目标表通常使用 MergeTree 引擎或 ReplicatedMergeTree 等变体来实现。消息流如下图所示。
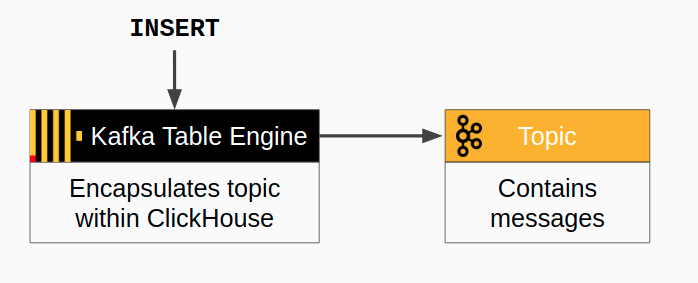
也可以从 ClickHouse 写回 Kafka。消息流更简单 - 只需插入到 Kafka 表中即可。下面是流程图。
在 Kafka 上创建主题
现在让我们在 Kafka 上设置一个主题,我们可以使用它来加载消息。登录到 Kafka 服务器,然后使用以下示例中的命令创建主题。在此示例中,“kafka”是服务器的 DNS 名称。如果您有其他 DNS 名称,请改用该名称。您还可以调整分区数以及复制因子。
kafka-topics \
--bootstrap-server kafka:9092 \
--topic readings \
--create --partitions 6 \
--replication-factor 2检查主题是否已成功创建。
kafka-topics --bootstrap-server kafka:9092 --describe readingsTopic: readings PartitionCount: 6 ReplicationFactor: 2 Configs:Topic: readings Partition: 0 Leader: 0 Replicas: 0,2 Isr: 0,2Topic: readings Partition: 1 Leader: 2 Replicas: 2,1 Isr: 2,1Topic: readings Partition: 2 Leader: 1 Replicas: 1,0 Isr: 1,0Topic: readings Partition: 3 Leader: 0 Replicas: 0,1 Isr: 0,1Topic: readings Partition: 4 Leader: 2 Replicas: 2,0 Isr: 2,0Topic: readings Partition: 5 Leader: 1 Replicas: 1,2 Isr: 1,2现在 Kafak 准备工作已完成。让我们转向ClickHouse。
ClickHouse Kafka 引擎设置
要将数据从 Kafka 主题读取到 ClickHouse 表,我们需要做三件事:
-
一个目标 MergeTree 表,用于为引入的数据提供主目录
-
一个 Kafka 引擎表,使主题看起来像一个 ClickHouse 表
-
用于自动将数据从 Kafka 移动到目标表的具体化视图
首先,我们将定义目标 MergeTree 表。登录到 ClickHouse 执行以下 SQL
CREATE TABLE readings (readings_id Int32 Codec(DoubleDelta, LZ4),time DateTime Codec(DoubleDelta, LZ4),date ALIAS toDate(time),temperature Decimal(5,2) Codec(T64, LZ4)
) Engine = MergeTree
PARTITION BY toYYYYMM(time)
ORDER BY (readings_id, time);接下来,我们需要使用 Kafka 引擎创建一个表来连接主题并读取数据。引擎将使用主题“readings”和消费者组名称“readings consumer_group1”从主机 kafka 的代理读取数据。输入格式为 CSV。
请注意,我们省略了“date”列。它是目标表中的别名,将从“time”列自动填充。
CREATE TABLE readings_queue (readings_id Int32,time DateTime,temperature Decimal(5,2)
)
ENGINE = Kafka
SETTINGS kafka_broker_list = 'kafka-headless.kafka:9092',kafka_topic_list = 'readings',kafka_group_name = 'readings_consumer_group1',kafka_format = 'CSV',kafka_max_block_size = 1048576;前面的设置处理最简单的情况:单个代理、单个主题且没有专用配置。
最后,我们创建一个物化视图,用于在 Kafka 和合并树表之间传输数据。
CREATE MATERIALIZED VIEW readings_queue_mv TO readings AS
SELECT readings_id, time, temperature
FROM readings_queue;这就是 Kafka 到 ClickHouse 的集成。让我们来测试一下。
加载数据
现在是时候使用 kafka-console-producer 命令加载一些输入数据了。以下示例使用 CSV 格式添加三条记录。
kafka-console-producer --broker-list kafka:9092 --topic readings <<END
1,"2020-05-16 23:55:44",14.2
2,"2020-05-16 23:55:45",20.1
3,"2020-05-16 23:55:51",12.9
ENDSELECT *
FROM readings┌─readings_id─┬────────────────time─┬─temperature─┐
│ 1 │ 2020-05-16 23:55:44 │ 14.20 │
│ 2 │ 2020-05-16 23:55:45 │ 20.10 │
│ 3 │ 2020-05-16 23:55:51 │ 12.90 │
└─────────────┴─────────────────────┴─────────────┘Kafka 和 ClickHouse 现已连接。
从 Kafka 重读消息
前面的示例从 Kafka 主题中的起始位置开始,并在消息到达时读取消息。这是正常方式,但有时再次阅读消息很有用。例如,您可能希望在修复架构中的 bug 或重新加载备份后重新读取消息。幸运的是,这很容易做到。我们只是重置使用者组中的偏移量。
假设我们丢失了 readings 表中的所有消息,并希望从 Kafka 重新加载它们。首先,让我们使用 TRUNCATE 命令“丢失”消息。
TRUNCATE TABLE readings;在重置分区上的偏移量之前,我们需要关闭消息消费。为此,请在 ClickHouse 中分离 readings_queue 表,如下所示。
DETACH TABLE readings_queue接下来,使用以下 Kafka 命令重置用于 readings_queue 表的使用者组中的分区偏移量 (kafka 节点执行)。
kafka-consumer-groups --bootstrap-server kafka:9092 \--topic readings --group readings_consumer_group1 \--reset-offsets --to-earliest --execute现在重新连接readings_queue表。
ATTACH TABLE readings_queue等待几秒钟,丢失的记录将被恢复。您可以运行 SELECT 来确认它们已恢复。
添加虚拟列
使用显示原始 Kafka 消息坐标的信息标记行通常很有用。为此,Kafka 表引擎自动定义了虚拟列。下面介绍如何更改 readings 表以显示源主题、分区和偏移量。
首先,让我们通过分离 Kafka 表来禁用消息使用。消息可能会堆积在主题上,但我们不会丢失它们。
DETACH TABLE readings_queue接下来,我们通过连续执行以下 SQL 命令来更改目标表和物化视图。请注意,我们只是删除并重新创建具体化视图,而更改目标表,从而保留现有数据。
ALTER TABLE readingsADD COLUMN _topic String,ADD COLUMN _offset UInt64,ADD COLUMN _partition UInt64DROP TABLE readings_queue_mvCREATE MATERIALIZED VIEW readings_queue_mv TO readings ASSELECT readings_id, time, temperature, _topic, _offset, _partitionFROM readings_queue;最后,我们通过重新附加 readings_queue 表来再次启用消息使用。
ATTACH TABLE readings_queue您可以通过截断表并重新加载消息来确认新架构,就像我们在上一节中所做的那样。如果查询数据,它将如下所示。
SELECTreadings_id AS id, time, temperature AS temp,_topic, _offset, _partition
FROM readings┌─id─┬────────────────time─┬──temp─┬─_topic───┬─_offset─┬─_partition─┐
│ 1 │ 2020-05-16 23:55:44 │ 14.20 │ readings │ 0 │ 5 │
│ 2 │ 2020-05-16 23:55:45 │ 20.10 │ readings │ 1 │ 5 │
│ 3 │ 2020-05-16 23:55:51 │ 12.90 │ readings │ 2 │ 5 │
└────┴─────────────────────┴───────┴──────────┴─────────┴────────────┘顺便说一句,上述过程与在消息格式更改时升级架构的方式相同。此外,物化视图提供了一种非常通用的方法,可以使 Kafka 消息适应目标表行。您甚至可以定义多个具体化视图,以将消息流拆分到不同的目标表中。
从 ClickHouse 写入 Kafka
在本教程的最后,我们将展示如何将消息从 ClickHouse 写回 Kafka。这是一个相对较新的功能,在当前的 Altinity 稳定版本 19.16.18.85 中可用。
让我们首先在 Kafka 中创建一个新主题来包含消息。我们称其为“readings_high”
kafka-topics \
--bootstrap-server kafka:9092 \
--topic readings_high \
--create --partitions 6 \
--replication-factor 2接下来,我们需要使用 Kafka 表引擎定义一个指向新主题的表。事实证明,此表可以读取和写入消息,但在此示例中,我们将仅使用它进行写入。
CREATE TABLE readings_high_queue (readings_id Int32,time DateTime,temperature Decimal(5,2)
)
ENGINE = Kafka
SETTINGS kafka_broker_list = 'kafka:9092',kafka_topic_list = 'readings_high',kafka_group_name = 'readings_high_consumer_group1',kafka_format = 'CSV',kafka_max_block_size = 1048576;最后,让我们添加一个实例化视图,将温度大于 20.0 的所有行传输到 readings_high_queue 表。此示例说明了 ClickHouse 物化视图的另一个用例,即在特定条件下生成事件。
CREATE MATERIALIZED VIEW readings_high_queue_mv TO readings_high_queue AS
SELECT readings_id, time, temperature FROM readings
WHERE toFloat32(temperature) >= 20.0在单独的终端窗口中启动消费者,以从 Kafka 上的 readings_high 主题打印消息,如下所示。这将允许您在 ClickHouse 将行写入 Kafka 时查看行。
kafka-console-consumer --bootstrap-server kafka:9092 --topic readings_high最后,加载一些数据,这些数据将演示如何写回 Kafka。让我们在原始主题中添加一个新批量。在另一个窗口中运行以下命令。
kafka-console-producer --broker-list kafka:9092 --topic readings <<END
4,"2020-05-16 23:55:52",9.7
5,"2020-05-16 23:55:56",25.3
6,"2020-05-16 23:55:58",14.1
END几秒钟后,您将在运行 kafka-console-consumer 命令的窗口中看到第二行弹出。它应如下所示:
5,"2020-05-16 23:55:56",25.3故障处理
如果您在使用任何示例时遇到问题,请查看 ClickHouse 日志。如果尚未启用跟踪日志记录,请启用跟踪日志记录。您可以看到如下消息,这些消息表示 Kafka 表引擎中的活动。
2020.05.17 07:24:20.609147 [ 64 ] {} <Debug> StorageKafka (readings_queue): Started streaming to 1 attached views所有错误将保存在在clickhouse-server.err.log中。
结论
正如这篇博客文章所展示的,Kafka 表引擎提供了一种简单而强大的方法来集成 Kafka 主题和 ClickHouse 表。显然,管理集成还有很多工作要做,尤其是在生产系统中。我们希望本文能帮助您入门,并使您能够自己探索其他可能性。



![[自动化运维工具]ansible简单介绍和常用模块](https://img-blog.csdnimg.cn/direct/a6256d5bae7e47b390d03ed6d3eb3ca3.png)


