1、Nosql
1.1 数据存储的发展
1.1.1 只使用Mysql
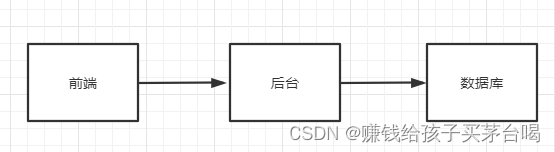
以前的网站访问量不大,单个数据库是完全够用的。
但是随着互联网的发展,就出现了很多的问题:
-
数据量太大,服务器放不下
-
访问量太大,服务器也承受不了
1.1.2 缓存+Mysql(多台服务器)+读写分离
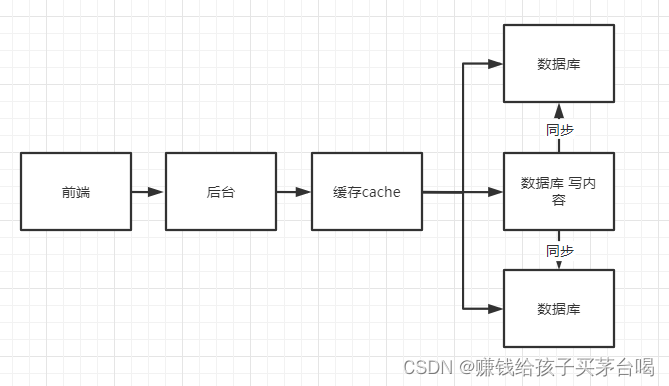
相同的数据不断的查询数据库比较浪费性能,这时候就会加上缓存,用来减轻服务器的压力提高效率(但同步也是一个问题)
1.1.3 分库分表+数据库集群
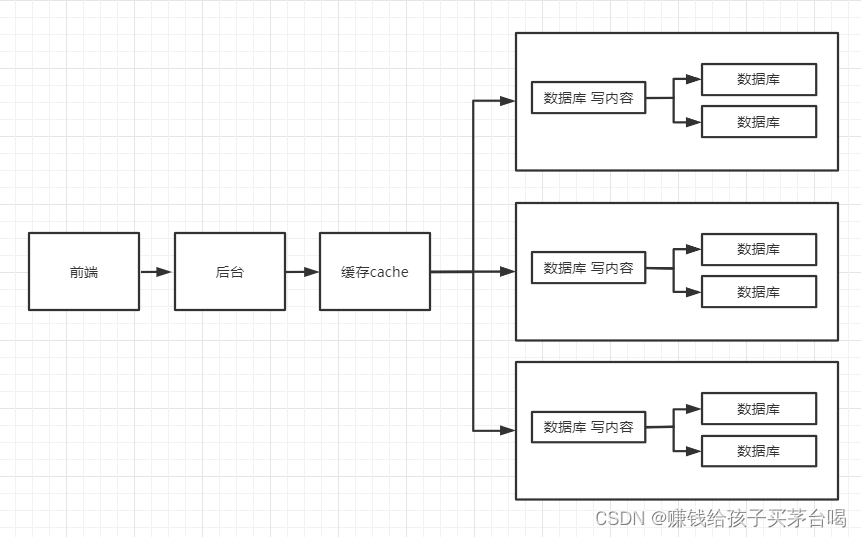
由于用户量的增加,读数据由缓存来减轻压力所以数据的压力从读数据到了写数据
-
数据量多变化快
-
数据量大(博客,小说等)
用户产生的数据库增长量太快,这个用Nosql可以很好的处理这些问题
1.2 什么是Nosql
Nosql = Not Only Sql
泛指非关系型数据库
-
关系型数据库:表格、行、列
-
非关系型数据库:没有固定的存储格式,什么类型的数据都可以存储
1.3 Nosql特点
-
数据之间没有关系,方便拓展
-
大数据量的性能高
-
数据类型多样性(不需要事先设计数据库,随存随取)
-
没有固定的查询语言
-
键值对存储、列存储、文档存储、图形数据库
-
CAP定理和BASE
1.5 Nosql分类
-
键值(Key-Value)存储数据库
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果数据库管理员(DBA)只对部分值进行查询或更新的时候,Key/value就显得效率低下了。举例如:Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB。
-
列存储数据库
这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。如:Cassandra, HBase, Riak.
-
文档型数据库
文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可以看作是键值数据库的升级版,允许之间嵌套键值,在处理网页等复杂数据时,文档型数据库比传统键值数据库的查询效率更高。如:CouchDB, MongoDb(json形式). 国内也有文档型数据库SequoiaDB,已经开源。
-
图形(Graph)数据库
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。如:Neo4J, InfoGrid, Infinite Graph。
1.6 不同分类的特点
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。 |
2、Redis简介
2.1 概述
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
2.2 作用
-
内存存储、持久化
-
效率高,用于高速缓存
-
发布订阅系统(简单的消息队列)
-
地图信息分析
-
计时器、计数器(浏览量)
2.3 特性
-
多样的数据类型
-
持久化
-
集群
-
事务
2.4 基本知识
-
基本命令
select 2 # 选择3号数据库redis有16个数据库,默认使用的是第0个,可以使用select进行切换 DBSIZE # 查看DB大小 keys * # 查看数据库所有的key flushdb # 清空当前数据库数据库 FLUSHALL # 清空所有数据的的数据 exists name # 判断name是否存在,0不存在 1存在 move name 1 # 移动name到1号数据库 del name # 删除name expire name 10 # 设置name 10s后过期 ttl name # 查看剩余的过期时间 type name # 查看name的类型
-
Redis是单线程的
redis是基于内存操作的,CPU不是Redis的性能瓶颈,Redis的瓶颈是根据机器的内存和网络带宽的,不需要用到多线程,就直接用单线程。
-
为什么单线程还这么快
redis是把所有的数据放在内存中,所以用单线程操作效率最高,多线程会进行上下文切换,这个是需要耗时的,对于内存系统来说,没有上下文切换效率是就是最高的。
2.5 window下的安装
-
解压压缩包
-
安装服务
-
进入解压的路径
-
输入 redis-server.exe --service-install redis.windows.conf --service-name redis --loglevel verbose
-
出现安装成功即可,去服务查看

-
启动服务:redis-server.exe --service-start --service-name redis (后续启动Redis只需要这个命令就可以了)
-
停止服务:redis-server.exe --service-stop --service-name redis
-
卸载服务:redis-server.exe --service-uninstall--service-name redis
-
3、五大基本数据类型
3.1 String
SET name kk # 设置name为ab
GET name # 获取name
APPEND name "cd" # 追加内容
STRLEN name # 获取长度
SET count 0 # 设置count:0
INCR count # 自增
DECR count # 自减
INCRBY count 10 # 步长+10
DECRBY count 5 # 步长-5
GETRANGE name 0 3 # 获取0-3的内容,包括0和3
GETRANGE name 0 -1 # 获取所有字符串
SETRANGE name 1 ss # 从1的位置替换字符串 abcd -> assd
SETEX sex 10 "male" # 10s过期
SETNX name kk # 判断是否存在,不存在创建,存在则失败
MSET k1 v1 k2 v2 k3 v3 # 批量设置
MGET k1 k2 k3 # 批量获取
MSETNX k1 v1 k4 v4 # 不存在则创建k1,k4(原子性的操作,同时成功或者同时失败)
SET user:1 {name:kk,age:18} # 设置一个user,使用json保存数据
MSET user:2:name kk user:2:age 18 # redis中可以直接使用这种方式设置对象
MGET user:2:name user:2:age # 获取 user:{id}:{field}
GETSET name kk # 如果不存在值则返回 nil,并设置值
GETSET name ww # 如果存在值则获取原来的值并设置新的值3.2 List
LPUSH list data1 # 将值插入列表头部
LRANGE list 0 -1 # 获取数据
RPUSH list data4 # 插入尾部
LPOP list # 左边移除
RPOP list # 右边移除
LINDEX list 1 # 通过下标获取数据
LLEN list # 获取长度
LREM list 1 data1 # 移除指定数量的指定数据
LREM list 2 data2 # 移除指定数量的指定数据
LTRIM list 0 2 # 截取指定的长度(闭区间) ltrim start stop,原先的list只剩下截取的内容
RPOPLPUSH list list2 # 移除list最后一个元素并且将这个元素加入到新列表list2中
LSET list 0 data1 # 将指定位置值替换
LINSERT list BEFORE data3333 data # 往data3333前面插入data
LINSERT list AFTER data3333 dataAfter# 往data3333前面插入dataAfter-
本质上是一个链表
-
如果key不存在创建新链表
-
存在新增内容
-
可以做栈(lpush,lpop)、队列(lpush,lpop)
3.3 Set
set的值不能重复,无序
SADD myset data1 # 插入
SMEMBERS myset # 查询
SISMEMBER myset data1 # 查看是否有data1这个值
SREM myset data1 # 移除元素
SRANDMEMBER myset 1 # 随机抽选指定个数的元素
SPOP myset # 随机删除一个元素
SMOVE myset myset2 data3 # 移动一个值到另外一个set
SDIFF myset myset2 # 差集 myset2有myset没有的数据
SINTER myset myset2 # 交集 myset和myset2都有的数据
SUNION myset myset2 # 并集 myset和myset2的数据合并的结果3.4 Hash
其实就是一个Map集合,和String类型没有太大区别,就是一个集合里面存多个key-value
HSET myhash key1 value1 # 插入数据,再次赋值是修改
HGET myhash key1 # 取值
HMSET myhash key2 value2 key3 value3 # 设置多个字段
HMGET myhash key1 key2 key3 # 获取多个字段
HGETALL myhash # 获取所有key-value
HDEL myhash key1 # 删除指定的key-value
HLEN myhash # 获取长度
HEXISTS myhash key1 # 判断指定字段是否存在
HKEYS myhash # 只获取key
HVALS myhash # 只获取value
HINCRBY myhash key4 -2 # 指定增量
HSETNX myhash key4 value4 # 如果不存在则可以设置,存在不能设置更适合对象的存储,比如个人信息等
3.5 sorted set/zset(有序集合)
在set的基础上,增加了一个值 k s v
ZADD salary 1000 xaiomin # 添加一个值
ZADD salary 3000 xiaohong 2000 xiaolv # 添加多个值
ZRANGE salary 0 -1 # 查看
ZRANGEBYSCORE salary -inf +inf # 升序 负无穷 - 正无穷
ZRANGEBYSCORE salary -inf 2000 WITHSCORES # 自定义范围,并且附带对应的score值
ZREVRANGE salary 0 -1 WITHSCORES # 降序查询
ZCOUNT salary 1000 2000 # 查询 1000-2000有多少个数据
ZREM salary xiaolv # 删除成绩表、工资表、排行榜等需要排序的
通过maven使用jedis
3、Jedis
Redis官方推荐的JAVA连接开发工具
3.1 依赖
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.75</version>
</dependency>3.2 使用
@Test
void redisTest01() {// 创建Jedis连接对象Jedis jedis = new Jedis("127.0.0.1", 6379);// 直接调用相关语法即可System.out.println(jedis.ping());System.out.println(jedis.get("k1"));jedis.set("k1", "V1");// 关闭连接jedis.close();
}3.3 事务
@Test
void redisTest02() {Jedis jedis = new Jedis("127.0.0.1", 6379);// 获取一个Redis事务对象Transaction multi = jedis.multi();try {// 往事务中插入语句multi.set("k2", "v2");multi.set("k3", "v3");// 执行事务multi.exec();} catch (Exception e) {e.printStackTrace();// 回滚事务multi.discard();}jedis.close();
}通过springboot使用Redis
导入依赖redis
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>将resourse下的application.property 改成 application.yml
配置yml
spring:redis:
# 本地端口host: 127.0.0.1
# redis的端口port: 6379
# Redis有16个数据库,可以选择要用哪个database: 1测试类RedisTemplate对象
@Resourceprivate RedisTemplate<String,Object> template;尝试拿值
package com.example.demo;import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;import javax.annotation.Resource;@SpringBootTest
class DemoApplicationTests {//redisTemplate是外部依赖导入的,不是在我们本身的代码里,所以//idea去我们的代码里找不到,会爆红//这里必须指明名字@Resource(name = "redisTemplate")//这里不能用@Autowiredprivate RedisTemplate<String,Object> template;@Testvoid contextLoads() {ValueOperations<String, Object> valueoption = template.opsForValue();valueoption.set("s2","abc");System.out.println(valueoption.get("s2"));}}
这样的话是拿不到正确的值的
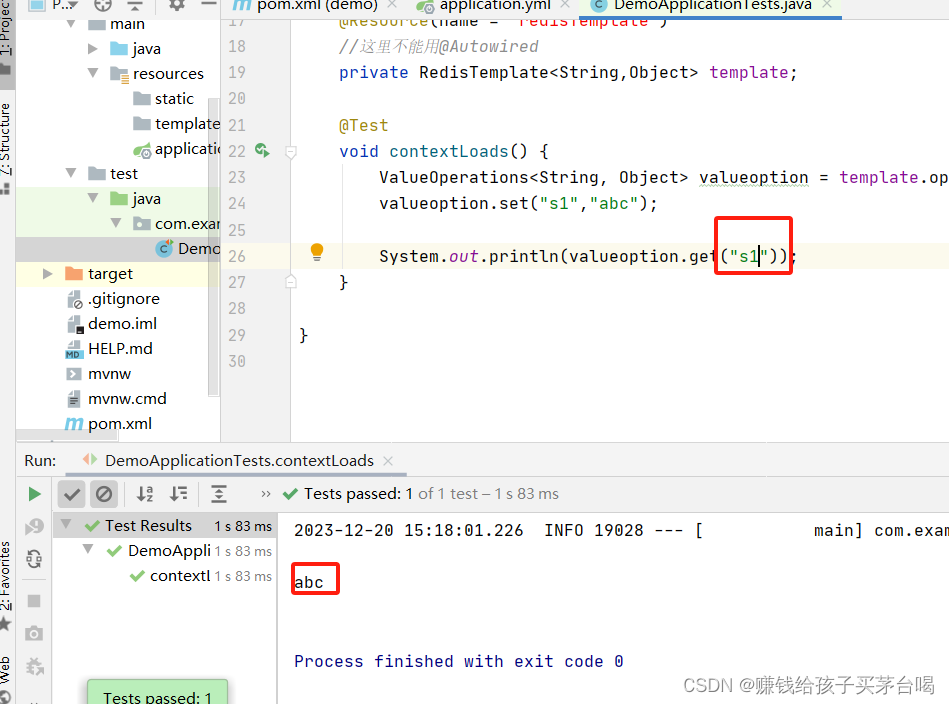
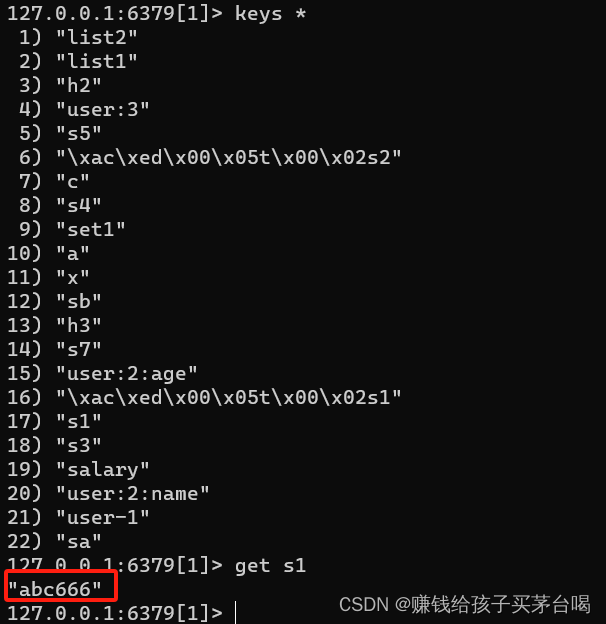
键在存和取的时候会有一些差异,无法正常取到,我们存入的s1起始是在16行的位置
自定义template
为了保证存储和拿取一致,可以自定义template(这个类对键进行了序列化之类的操作)
@Configuration
public class RedisConfig {// 定义了一个RedisTemplate@Bean@SuppressWarnings("all")public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {// RedisTemplate 为了自己方便一般直接使用<String,Object>RedisTemplate<String, Object> template = new RedisTemplate();template.setConnectionFactory(redisConnectionFactory);// 序列化配置Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<Object>(Object.class);ObjectMapper om = new ObjectMapper();// 设置可见度om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);// 启动默认的类型om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);// 序列化类,对象映射设置jackson2JsonRedisSerializer.setObjectMapper(om);// String的序列化StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();// key采用String的序列化方式template.setKeySerializer(stringRedisSerializer);// hash的key采用String的序列化template.setHashKeySerializer(stringRedisSerializer);// value采用jackson的序列化template.setValueSerializer(jackson2JsonRedisSerializer);// hash的value采用jackson的序列化template.setHashValueSerializer(jackson2JsonRedisSerializer);return template;}
}封装工具类
/*** spring redis 工具类** @author ruoyi**/
@SuppressWarnings(value = {"unchecked", "rawtypes"})
@Component
public class RedisUtil {@Autowiredpublic RedisTemplate redisTemplate;/*** 缓存基本的对象,Integer、String、实体类等** @param key 缓存的键值* @param value 缓存的值*/public <T> void setCacheObject(final String key, final T value) {redisTemplate.opsForValue().set(key, value);}/*** 缓存基本的对象,Integer、String、实体类等** @param key 缓存的键值* @param value 缓存的值* @param timeout 时间* @param timeUnit 时间颗粒度*/public <T> void setCacheObject(final String key, final T value, final Integer timeout, final TimeUnit timeUnit) {redisTemplate.opsForValue().set(key, value, timeout, timeUnit);}/*** 设置有效时间** @param key Redis键* @param timeout 超时时间* @return true=设置成功;false=设置失败*/public boolean expire(final String key, final long timeout) {return expire(key, timeout, TimeUnit.SECONDS);}/*** 设置有效时间** @param key Redis键* @param timeout 超时时间* @param unit 时间单位* @return true=设置成功;false=设置失败*/public boolean expire(final String key, final long timeout, final TimeUnit unit) {return redisTemplate.expire(key, timeout, unit);}/*** 获得缓存的基本对象。** @param key 缓存键值* @return 缓存键值对应的数据*/public <T> T getCacheObject(final String key) {ValueOperations<String, T> operation = redisTemplate.opsForValue();return operation.get(key);}/*** 删除单个对象** @param key*/public boolean deleteObject(final String key) {return redisTemplate.delete(key);}/*** 删除集合对象** @param collection 多个对象* @return*/public long deleteObject(final Collection collection) {return redisTemplate.delete(collection);}/*** 缓存List数据** @param key 缓存的键值* @param dataList 待缓存的List数据* @return 缓存的对象*/public <T> long setCacheList(final String key, final List<T> dataList) {Long count = redisTemplate.opsForList().rightPushAll(key, dataList);return count == null ? 0 : count;}/*** 获得缓存的list对象** @param key 缓存的键值* @return 缓存键值对应的数据*/public <T> List<T> getCacheList(final String key) {return redisTemplate.opsForList().range(key, 0, -1);}/*** 缓存Set** @param key 缓存键值* @param dataSet 缓存的数据* @return 缓存数据的对象*/public <T> BoundSetOperations<String, T> setCacheSet(final String key, final Set<T> dataSet) {BoundSetOperations<String, T> setOperation = redisTemplate.boundSetOps(key);Iterator<T> it = dataSet.iterator();while (it.hasNext()) {setOperation.add(it.next());}return setOperation;}/*** 获得缓存的set** @param key* @return*/public <T> Set<T> getCacheSet(final String key) {return redisTemplate.opsForSet().members(key);}/*** 缓存Map** @param key* @param dataMap*/public <T> void setCacheMap(final String key, final Map<String, T> dataMap) {if (dataMap != null) {redisTemplate.opsForHash().putAll(key, dataMap);}}/*** 获得缓存的Map** @param key* @return*/public <T> Map<String, T> getCacheMap(final String key) {return redisTemplate.opsForHash().entries(key);}/*** 往Hash中存入数据** @param key Redis键* @param hKey Hash键* @param value 值*/public <T> void setCacheMapValue(final String key, final String hKey, final T value) {redisTemplate.opsForHash().put(key, hKey, value);}/*** 获取Hash中的数据** @param key Redis键* @param hKey Hash键* @return Hash中的对象*/public <T> T getCacheMapValue(final String key, final String hKey) {HashOperations<String, String, T> opsForHash = redisTemplate.opsForHash();return opsForHash.get(key, hKey);}/*** 删除Hash中的数据** @param key* @param hKey*/public void delCacheMapValue(final String key, final String hKey) {HashOperations hashOperations = redisTemplate.opsForHash();hashOperations.delete(key, hKey);}/*** 获取多个Hash中的数据** @param key Redis键* @param hKeys Hash键集合* @return Hash对象集合*/public <T> List<T> getMultiCacheMapValue(final String key, final Collection<Object> hKeys) {return redisTemplate.opsForHash().multiGet(key, hKeys);}/*** 获得缓存的基本对象列表** @param pattern 字符串前缀* @return 对象列表*/public Collection<String> keys(final String pattern) {return redisTemplate.keys(pattern);}
}