如何评估LLM在开放性问题的回答能力
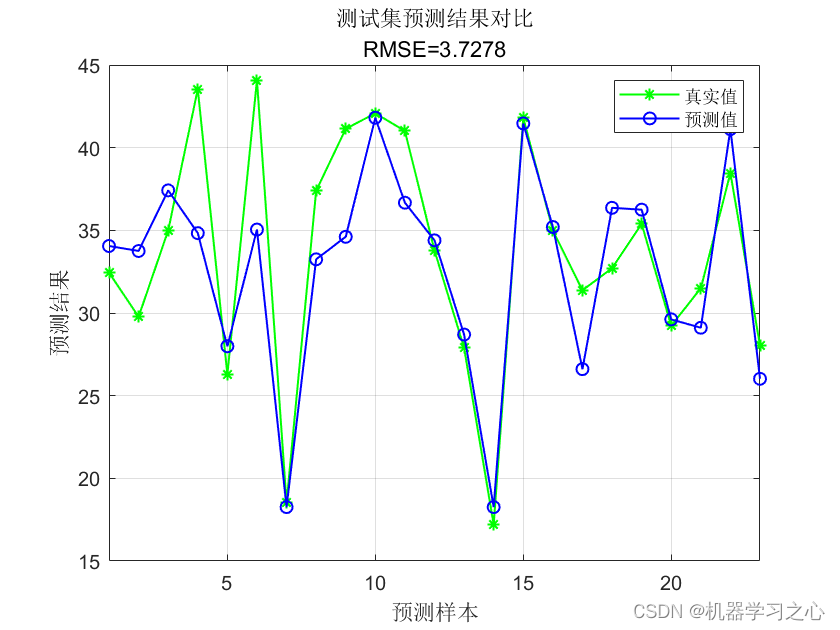
前面三篇博客中介绍了如何评估大模型,内容包括评估大模型时常用的指标,每个指标背后的含义,如何通过编写代码实现指标的收集。对于pass@k指标,还进行了专门的说明。在前面的博客中,我们提到,对于数据集大致可以分为三类,选择题,数学题,代码生成题,对于这三类数据集,在收集指标时,实现过程都有所不同,具体如下图所示。

可以看到,上面的数据集都找到了一种方式来评估LLM生成的内容是否正确,那么,如果是针对开放性问题,如何评估LLM的能力呢?比如让LLM写一篇优美的作文,写一封措辞友好的email等。这类问题,无法通过选择题来做标准数据集,在实际应用中,很多下游任务往往是这种更贴近人类的开放性问题任务,他不会是做一个选择题或者数学题。对于这类任务,如何有效的评估LLM的能力呢?本篇博客提到的MT-Bench评估方法就是解决该类问题的。
如何实现MT-Bench评估
MT-Bench采用的数据集
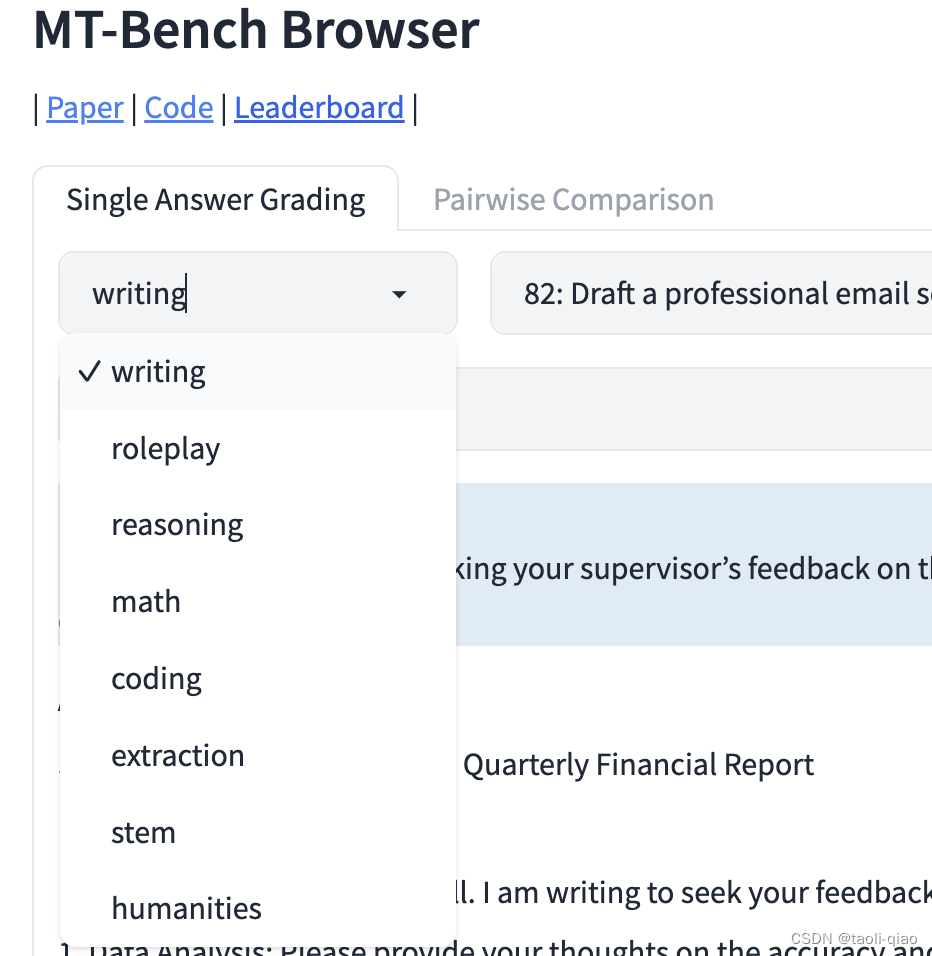
首先来看看MT-Bench评估所采用的数据集,如下图所示,可以看到MT-Bench方法采用的数据集包含了写作、角色扮演、推理、数学、编码、人文、提取、STEM(科学(Science),技术(Technology),工程(Engineering),数学(Mathematics)四门学科英文首字母的缩写),8个不同领域的问题。和前面介绍的数据集mmlu,c-eval等相似。
具体到某个类型下的数据,如下图所示,包括category,prompt,reference,这里的reference是标准答案,有些category类型有标准答案,有些是没有的。

MT-Bench评估方法的原理
一句话理解就是用GPT4作为裁判,对其他大模型生成的内容进行打分,分数设置为1-10,通过分数高低来评估LLM生成的内容的质量。
在MT-Bench中会提到两个术语,第一个是turn1,turn2,即第一轮和第二轮,这里的turn2指的是:针对第一个问题,继续问第二个相关性问题,对于第二个问题的得分情况。例如,如下图所示,可以看到,第二个问题都和第一个问题紧密相关。

MT-Bench中第二个术语就是“Single Answer Grading”和“Pariwise Comparison”。Single Answer的意思就是:针对大模型的回答,给出具体的分数;Pariwise的意思是:在输入时会给出两个模型生成的答案,让GPT4判断哪个大模型生成的答案更好。理解了上面的术语后,我们再来看看MT-Bench中使用到的Prompt
MT-Bench中使用到的Prompt
MT-Bench中使用到的prompt部分截图,如下所示,如果要review所有的prompt,查看这里。
 上面的prompt中,大概的意思就是让gpt作为judge裁判,对内容进行评估, 对上面的pair-v2的system_prompt信息进行翻译,内容如下所示:“请充当一个公正的评委,评估两个AI助手对以下用户问题提供的回应的质量。您应选择那个按照用户的指示更好地回答了用户的问题的助手。您的评估应考虑诸如回应的实用性、相关性、准确性、深度、创造性和详细程度等因素。开始您的评估,比较两个回应并提供简要解释。避免任何立场偏见,并确保回应的呈现顺序不影响您的决定。不要让回应的长度影响您的评估。不要偏袒助手的某些名称。请尽量客观。在提供解释后,请按照以下格式严格输出您的最终判决:“[[A]]”如果助手A更好,“[[B]]”如果助手B更好,对于平局,请输出“[[C]]”
上面的prompt中,大概的意思就是让gpt作为judge裁判,对内容进行评估, 对上面的pair-v2的system_prompt信息进行翻译,内容如下所示:“请充当一个公正的评委,评估两个AI助手对以下用户问题提供的回应的质量。您应选择那个按照用户的指示更好地回答了用户的问题的助手。您的评估应考虑诸如回应的实用性、相关性、准确性、深度、创造性和详细程度等因素。开始您的评估,比较两个回应并提供简要解释。避免任何立场偏见,并确保回应的呈现顺序不影响您的决定。不要让回应的长度影响您的评估。不要偏袒助手的某些名称。请尽量客观。在提供解释后,请按照以下格式严格输出您的最终判决:“[[A]]”如果助手A更好,“[[B]]”如果助手B更好,对于平局,请输出“[[C]]”
对于single-v1的prompt_template信息进行翻译,内容如下所示“
[指导]
请充当一个公正的评委,评估AI助手对以下用户问题的回应质量。您的评估应考虑回应的实用性、相关性、准确性、深度、创造性和详细程度等因素。开始您的评估,提供简要解释。请尽量客观。在提供解释后,您必须按照以下格式严格给出对回应的评分,使用这个格式:“[[评分]]”,例如:“评分:[[5]]”。
[问题]
{问题}
[助手回答的开始]
{回答}
[助手回答的结束]”
通过对上面prompt的分析,可以进一步知道MT-Bench的工作原理。即,首先调用需要评估的大模型将数据集中的问题作为输入,得到大模型生成的答案,再通过gpt4对生成的答案进行打分,得到最终的评估结果。
MT-Bench脚本执行过程
在Fashchat的官网给出了如何通过运行脚本收集评估结果的步骤,这里做简要介绍。如果对FastChat如何部署大模型不清楚,可以参考我前面的关于FastChat的博客。
第一:通过FastChat部署需要评估的大模型
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
pip install -e ".[model_worker,llm_judge]"
python3 -m fastchat.serve.controller
python3 -m fastchat.serve.vllm_worker --model-path [MODEL-PATH]
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000第二:调用部署模型的接口生成答案
python gen_api_answer.py --model [MODEL-NAME] --openai-api-base http://localhost:8000/v1 --parallel 50
第三:调用GPT4对生成的答案的评分
export OPENAI_API_KEY=XXXXXX # set the OpenAI API key
python gen_judgment.py --model-list [LIST-OF-MODEL-ID] --parallel [num-concurrent-api-call]MT-Bench评估存在的局限性
虽然MT-Bench可以帮助评估LLM在开放性问题方面的能力,但也有很多局限性,这些局限性导致给出的评估结果可能不是完全正确。具体的局限性如下所示:
1.Position bias,位置偏见,当两个模型答案比较靠近的时候,交换两个模型的答案的位置,会改变评估结果,通常来说,靠前的答案,得分更高一些。
2.Verbosity bias,啰嗦性偏见,如果内容写的更多,通常能拿到更好的分数。
3.Self-enhancement bias,自我增强的偏见,如果其他模型生成的内容,与gpt4生成的内容更贴近,通常得分更高。
4.Limited capability in grading math and reasoning questions,对数学和推理问题的评分能力有限。
总结
对于MT-Bench的局限性,我是这样看待的,有评估指标强过没有评估指标。另外,还可以通过相对比较的方式,评估可选模型中哪些模型能力相对更好一些。
MT-Bench评估方法提供的数据集只包含了8个典型领域的问题,在实际应用中,还可以进一步扩张,使用MT-Bench评估方法的思路,对微调后的模型或者垂直领域模型进行评估。例如,训练了一个专门写测试用例的模型,那么可以准备一份测试用例数据集,采用MT-Bench的思路进行评估。总结而言,MT-Bench提出的评估模型思路是非常有价值的,尽管存在一些局限性。