JVM常见工具介绍
jinfo(查看配置信息)
查看Java应用程序配置参数或者JVM系统属性,相关命令详情我们可以使用-help或者man命令查看,如下所示:
[root@xxxxxtmp]# jinfo -help
Usage:jinfo [option] <pid>(to connect to running process)jinfo [option] <executable <core>(to connect to a core file)jinfo [option] [server_id@]<remote server IP or hostname>(to connect to remote debug server)where <option> is one of:-flag <name> to print the value of the named VM flag-flag [+|-]<name> to enable or disable the named VM flag-flag <name>=<value> to set the named VM flag to the given value-flags to print VM flags-sysprops to print Java system properties<no option> to print both of the above-h | -help to print this help message
为了演示,笔者在服务器上开启了一个Java应用,我们可以使用jps命令查看其进程id,可以看到笔者服务器中有一个pid为19946的Java进程。
[root@iZ8vb7bhe4b8nhhhpavhwpZ tmp]# jps
20104 Jps
19946 jar查看当前应用所有的配置参数以及系统配置属性命令为jinfo pid如下所示:
[root@xxxxx tmp]# jinfo 19946
Attaching to process ID 19946, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.202-b08
Java System Properties:java.runtime.name = Java(TM) SE Runtime Environment
java.vm.version = 25.202-b08
sun.boot.library.path = /root/jdk8/jre/lib/amd64
java.protocol.handler.pkgs = org.springframework.boot.loader
java.vendor.url = http://java.oracle.com/
java.vm.vendor = Oracle Corporation
path.separator = :
file.encoding.pkg = sun.io
java.vm.name = Java HotSpot(TM) 64-Bit Server VM
sun.os.patch.level = unknown
sun.java.launcher = SUN_STANDARD
user.country = US
user.dir = /tmp......如果我们希望查看当前Java应用是否有配置某些信息,可以使用命令jinfo -flag 配置选项 pid,例如我们想查看当前应用是否有开启gc选项,可以使用下面这段命令
可以看到输出结果为-XX:-PrintGC,因为PrintGC前面是减号,这说明该选项并没有开启。
[root@xxx tmp]# jinfo -flag PrintGC 19946
-XX:-PrintGC如果我们希望将这个选项开启,我们只需在参数前面加个+号即可,例如我们希望开启gc选项,我们只需键入如下命令
[root@xxxxxtmp]# jinfo -flag +PrintGC 19946再次查看可以发现,选项生效了
[root@xxxx tmp]# jinfo -flag PrintGC 19946
-XX:+PrintGC
有些参数是键值对的形式,例如我们想配置dump日志的路径,我们也可以使用jinfo进行配置,命令格式为jinfo -flag 参数=值 Java进程id
jinfo -flag HeapDumpPath=/tmp/dump.log 19946
打印JVM选项信息
jinfo -flags 4854
Attaching to process ID 4854, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.202-b08
Non-default VM flags: -XX:CICompilerCount=2 -XX:HeapDumpPath=null -XX:InitialHeapSize=33554432 -XX:MaxHeapSize=511705088 -XX:MaxNewSize=170524672 -XX:MinHeapDeltaBytes=196608 -XX:NewSize=11141120 -XX:OldSize=22413312 -XX:+PrintGC -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseFastUnorderedTimeStamps
Command line:
查看应用属性,命令格式jinfo -sysprops Java进程id
jinfo -sysprops 2341
jmap(查看堆区信息、对象信息等)
jmap作用:
- 查看使用的GC算法,堆的配置信息以及各个内存区域的内存使用情况
- 显示堆对象的统计信息,包括每一个
Java类、对象数量、内存大小、类名称等 - 打印等会回收的对象的信息
- 生成
dump文件,配合jhat使用
查看堆内存使用情况 jmap -heap Java进程id
[root@iZ8vb7bhe4b8nhhhpavhwpZ tmp]# jmap -heap 25534
Attaching to process ID 25534, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.202-b08using thread-local object allocation.
Mark Sweep Compact GCHeap Configuration:MinHeapFreeRatio = 40MaxHeapFreeRatio = 70MaxHeapSize = 511705088 (488.0MB)NewSize = 11141120 (10.625MB)MaxNewSize = 170524672 (162.625MB)OldSize = 22413312 (21.375MB)NewRatio = 2SurvivorRatio = 8MetaspaceSize = 21807104 (20.796875MB)CompressedClassSpaceSize = 1073741824 (1024.0MB)MaxMetaspaceSize = 17592186044415 MBG1HeapRegionSize = 0 (0.0MB)
查看存活的Java对象,命令格式: jmap -histo:live Java进程id
[root@xxxtmp]# jmap -histo:live 25534num #instances #bytes class name
----------------------------------------------1: 48676 7974952 [C2: 7762 1873312 [I3: 47785 1146840 java.lang.String4: 12737 1120856 java.lang.reflect.Method5: 8773 968912 java.lang.Class6: 25572 818304 java.util.concurrent.ConcurrentHashMap$Node7: 14108 564320 java.util.LinkedHashMap$Entry8: 2712 509536 [B9: 9308 494936 [Ljava.lang.Object;10: 6345 493128 [Ljava.util.HashMap$Node;11: 7001 392056 java.util.LinkedHashMap12: 11255 360160 java.util.HashMap$Node13: 15946 354528 [Ljava.lang.Class;14: 18176 290816 java.lang.Object15: 3447 248184 java.lang.reflect.Field16: 124 192320 [Ljava.util.concurrent.ConcurrentHashMap$Node;
打印正在被回收的类,命令格式:jmap -finalizerinfo Java进程id
[root@xxxtmp]# jmap -finalizerinfo 25534
Attaching to process ID 25534, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.202-b08
Number of objects pending for finalization: 0
将存活的对象的信息存到二进制文件中
jmap -dump:live,format=b,file=/tmp/heap.bin 25534
Dumping heap to /tmp/heap.bin ...
Heap dump file created
此时就可以使用jhat打开该文件,如下所示jhat 文件名,这时候我们就可以通过7000端口查看详情了。
[root@xxxtmp]# jhat heap.bin
Reading from heap.bin...
Dump file created Wed Nov 02 20:21:18 CST 2022
Snapshot read, resolving...
Resolving 346825 objects...
Chasing references, expect 69 dots.....................................................................
Eliminating duplicate references.....................................................................
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.
jstat(常用,监控运行时状态信息)
jstat用于监控虚拟机各种运行状态信息,显示虚拟机进程中装在、内存、垃圾收集、JIT编译等运行数据。
查看类加载信息,命令格式jstat -class Java进程id
[root@iZ8vb7bhe4b8nhhhpavhwpZ tmp]# jstat -class 2341
Loaded Bytes Unloaded Bytes Time8221 14604.3 1 0.9 12.74
[root@iZ8vb7bhe4b8nhhhpavhwpZ tmp]#
查看编译统计信息jstat -compiler Java进程id
[root@xxxtmp]# jstat -compiler 2341
Compiled Failed Invalid Time FailedType FailedMethod4177 0 0 17.68 0
[root@iZ8vb7bhe4b8nhhhpavhwpZ tmp]#
查看gc统计信息
[root@iZ8vb7bhe4b8nhhhpavhwpZ tmp]# jstat -gc 2341S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
1408.0 1408.0 0.0 1020.3 11840.0 7493.1 29268.0 22168.5 42840.0 40613.5 5760.0 5311.9 65 0.401 2 0.213 0.613
[root@iZ8vb7bhe4b8nhhhpavhwpZ tmp]#
每个表头的含义如下
1. S0C :年轻代中第一个survivor(幸存区)的容量 (字节)
2. S1C :年轻代中第二个survivor(幸存区)的容量 (字节)
3. S0U:年轻代中第一个survivor(幸存区)目前已使用空间 (字节)
4. S1U:年轻代中第二个survivor(幸存区)目前已使用空间 (字节)
5. EC:年轻代中Eden(伊甸园)的容量 (字节)
6. EU:年轻代中Eden(伊甸园)目前已使用空间 (字节)
7. OC:Old代的容量 (字节)
8. OU:Old代目前已使用空间 (字节)
9. PC:Perm(持久代)的容量 (字节)
10. PU:Perm(持久代)目前已使用空间 (字节)
11. YGC:从应用程序启动到采样时年轻代中gc次数
12. YGCT:从应用程序启动到采样时年轻代中gc所用时间(s)
13. FGC:从应用程序启动到采样时old代(全gc)gc次数
14. FGCT:从应用程序启动到采样时old代(全gc)gc所用时间(s)
15. GCT:从应用程序启动到采样时gc用的总时间(s)查看gc内存容量和元空间容量
[root@xxxtmp]# jstat -gccapacity 2341NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC10880.0 166528.0 14656.0 1408.0 1408.0 11840.0 21888.0 333184.0 29268.0 29268.0 0.0 1087488.0 42840.0 0.0 1048576.0 5760.0 65 2
查看年轻代统计信息
[root@xxxxtmp]# jstat -gcnew 2341S0C S1C S0U S1U TT MTT DSS EC EU YGC YGCT
1408.0 1408.0 0.0 1020.3 2 15 704.0 11840.0 7652.5 65 0.401
[root@iZ8vb7bhe4b8nhhhpavhwpZ tmp]#
参数详情
1. S0C:年轻代中第一个survivor(幸存区)的容量 (字节)
2. S1C:年轻代中第二个survivor(幸存区)的容量 (字节)
3. S0U:年轻代中第一个survivor(幸存区)目前已使用空间 (字节)
4. S1U:年轻代中第二个survivor(幸存区)目前已使用空间 (字节)
5. TT:持有次数限制
6. MTT:最大持有次数限制
7. EC:年轻代中Eden(伊甸园)的容量 (字节)
8. EU:年轻代中Eden(伊甸园)目前已使用空间 (字节)
9. YGC:从应用程序启动到采样时年轻代中gc次数
10. YGCT:从应用程序启动到采样时年轻代中gc所用时间(s)
了解JVM GC日志
获取日志的两种方式
获取GC日志方式大抵有以下两种:
- 设定JVM参数,具体的命令参数为:
-XX:+PrintGCDetails # 打印GC日志
-XX:+PrintGCTimeStamps # 打印每一次触发GC时发生的时间
- 在服务器上监控:使用
jstat查看,如下所示,命令格式为jstat -gc pid 输出间隔时长 输出次数
[root@xxxxx tmp]# jstat -gc 21608 1000 5S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
1088.0 1088.0 0.0 666.5 8832.0 3102.0 21888.0 11286.8 32512.0 30346.5 4352.0 3842.7 31 0.161 1 0.035 0.195
1088.0 1088.0 0.0 666.5 8832.0 3102.0 21888.0 11286.8 32512.0 30346.5 4352.0 3842.7 31 0.161 1 0.035 0.195
1088.0 1088.0 0.0 666.5 8832.0 3102.0 21888.0 11286.8 32512.0 30346.5 4352.0 3842.7 31 0.161 1 0.035 0.195
1088.0 1088.0 0.0 666.5 8832.0 3102.0 21888.0 11286.8 32512.0 30346.5 4352.0 3842.7 31 0.161 1 0.035 0.195
1088.0 1088.0 0.0 666.5 8832.0 3102.0 21888.0 11286.8 32512.0 30346.5 4352.0 3842.7 31 0.161 1 0.035 0.195
常见配置参数解析
对应的JVM参数和含义笔者都注释解释了,读者可自行阅读
-XX:NewSize=5M # 年轻代空间大小
-XX:MaxNewSize=5M # 年轻代最大空间大小
-XX:InitialHeapSize=10M # 初始化堆空间大小
-XX:MaxHeapSize=10M # 最大堆内存
-XX:SurvivorRatio=8 # eden占比,例如这里设置为8,那么eden和S0、S1区总体比例为8:1:1
-XX:PretenureSizeThreshold=10M # 大于这个值的参数直接在老年代分配。这样做的目的是避免在Eden区和两个Survivor区之间发生大量的内存复制
-XX:+UseParNewGC # 年轻代使用的GC算法
-XX:+UseConcMarkSweepGC # 并行并发CMS垃圾回收器
-XX:+PrintGCDetails # 打印GC日志详情
-XX:+PrintGCTimeStamps # 打印每次触发GC的时间
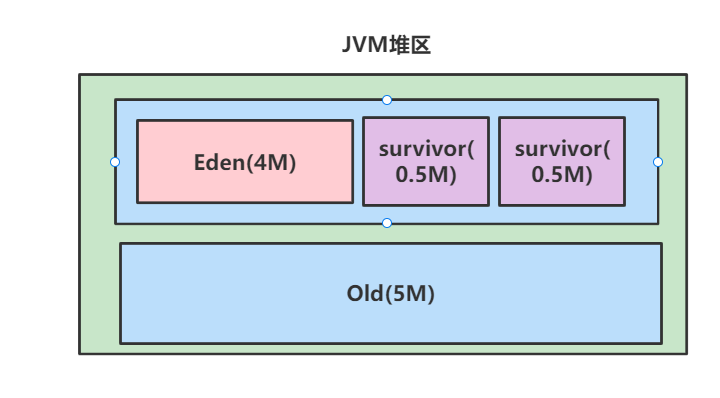
由上面的命令我可以知道堆区初始化内存和最大内存为10M,所以我们堆区的总空间为10M。
而年轻代的内存为5M,年轻代包含Eden区和Survivor区,由参数XX:SurvivorRatio可知Eden区占8/10,所以Eden区为4M,Survivor区总大小为1M,由于Survivor有两个所以每个Survivor区为0.5M。
(实践)基于IDEA调试应用程序了解堆JVM日志
为了演示如何查看GC日志,我们不妨写下这样一段代码,我们在计划将JVM年轻代设置为5M,首先创建3M的垃圾,然后创建2M的对象,触发minor GC。
编码如下所示:
public class gcTest {public static void main(String[] args) {//制造3M的垃圾byte[] bytes = new byte[1024 * 1024];bytes = new byte[1024 * 1024];bytes = new byte[1024 * 1024];//创建2M的新对象触发GCbyte[] byte2 = new byte[2 * 1024 * 1024];}
}然后我在IDEA中的JVM option配日志下面这条命令,每一个参数的命令上面都给出了,不记得的读者可以翻到上文中查阅。
-XX:NewSize=5M -XX:MaxNewSize=5M -XX:InitialHeapSize=10M -XX:MaxHeapSize=10M -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
完成后运行代码,可以在控制台输出下面这样一段内容,我们不妨逐行解释一下详情

首先是第一行,意为0.059s触发年轻代gc,年轻代使用空间从3655K变为512K,而年轻代的总空间为4608K(eden+有对象的s区)。
后面3655K->1671K(9728K)则是堆区总空间大小9728K,使用空间由3655K变为1671K。
后续Times按顺序即用户、系统、时机耗时时间。
0.059: [GC (Allocation Failure) 0.059: [ParNew: 3655K->512K(4608K), 0.0008750 secs] 3655K->1671K(9728K), 0.0009085 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 接下来这段则是年轻代堆区信息使用情况,可以看到eden大小为4096K,使用了78%。from和to(即s区)同理。
Heappar new generation total 4608K, used 3746K [0x00000000ff600000, 0x00000000ffb00000, 0x00000000ffb00000)eden space 4096K, 78% used [0x00000000ff600000, 0x00000000ff9289d0, 0x00000000ffa00000)from space 512K, 100% used [0x00000000ffa80000, 0x00000000ffb00000, 0x00000000ffb00000)to space 512K, 0% used [0x00000000ffa00000, 0x00000000ffa00000, 0x00000000ffa80000)
这一段以为老年代使用情况
concurrent mark-sweep generation total 5120K, used 1159K [0x00000000ffb00000, 0x0000000100000000, 0x0000000100000000)最后两段为元数据和class空间使用情况,不常用到,就不多做解释了。
Metaspace used 3159K, capacity 4496K, committed 4864K, reserved 1056768Kclass space used 343K, capacity 388K, committed 512K, reserved 1048576K
了解JVM几种GC的区别
Minor GC:发生在年轻代的空间回收,包含eden和survivor,也叫做Young GC。Major GC:在老年代堆区进行空间回收。Full GC:清理所有堆区的内存空间的垃圾内存,包括年轻代和老年代。
(实践)修复频繁的 Minor GC 和 Major GC
了解频繁Minor GC的危害和原因
造成Minor GC的原因说白了就是年轻代空间太少,当我们的应用程序需要频繁的创建对象时,就会触发Minor GC。
频繁的Minor GC会导致服务响应时间变长,而原因也很好理解,由上的介绍我们知道频繁的Minor GC会导致大量的年轻代垃圾被回收,并且会将存活的对象拷贝的老年代,而拷贝这个行为是非常消耗系统性能的。
复现问题
我们的程序编写如下所示,在一个for循环里面,创建3M的垃圾后,再创建2M的数组触发GC
public class gcTest {public static void main(String[] args) throws Exception {while (true) {//制造3M的垃圾byte[] bytes = new byte[1024 * 1024];bytes = new byte[1024 * 1024];bytes = new byte[1024 * 1024];//创建2M的新对象触发GCbyte[] byte2 = new byte[2 * 1024 * 1024];Thread.sleep(1000);}}
}
为了演示年轻代的回收行为,我们需要在对这个应用程序的年轻代堆内存改为5M
-XX:NewSize=5M -XX:MaxNewSize=5M -XX:InitialHeapSize=10M -XX:MaxHeapSize=10M -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
输出结果如下,可以看到在1s多就频繁的Minor GC。
修复并解决问题
我们不妨将年轻代和老年代、初始化堆区的空间都扩大,如下所示
-XX:NewSize=10M -XX:MaxNewSize=10M -XX:InitialHeapSize=100M -XX:MaxHeapSize=100M -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
输出结果,可以看到发生GC的时间间隔明显长了。

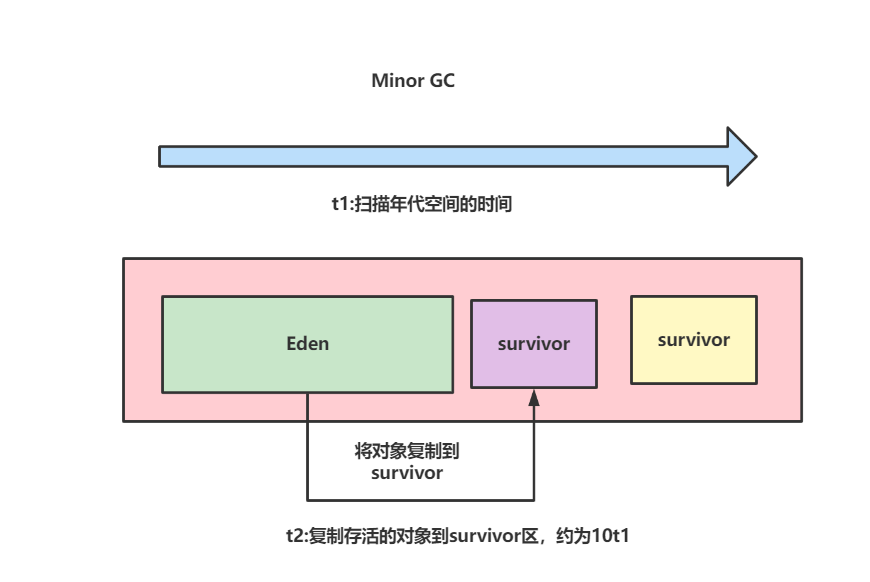
将年轻代空间调大,是否会更加耗时?
答案是不会的,我们将一次GC的时间拆分为t1和t2,t1是扫描年轻代空间是否有垃圾的时间,这个时间的几乎可以忽略不计。而t2则是将eden空间存活的对象复制到survivor区的时间,这个复制操作则是t1时间的10倍。
很明显的,JVM的性能瓶颈是t2(拷贝存活对象到s区),所以增加年轻代空间避免没必要的拷贝是正确的做法。
(实践)频繁的FULL GC
简介
FULL GC的原因即老年区空间满了,需要完完整整走一遍垃圾回收了。注意FULL GC可能会导致整个应用程序阻塞。
(重点)了解CMS GC日志
在进行FULL GC问题实践之前,我们必须了解一下CMS GC的七大阶段:
Initial Mark:首先是初始化标记阶段,这个阶段是STW(stop the world即所有线程停止工作),它会标记出老年代中所有的GC Roots以及被年轻代中存活的对象引用的对象。
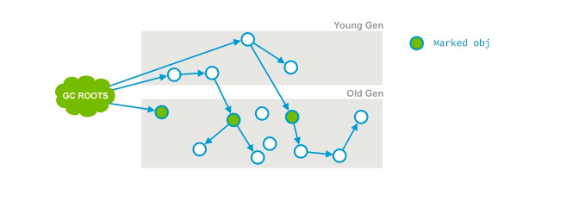
日志范例:

Concurrent Mark:根据上一个阶段得到的GC Roots,遍历找出整个老年代中存活的对象,注意该阶段是和应用程序线程一起执行的。
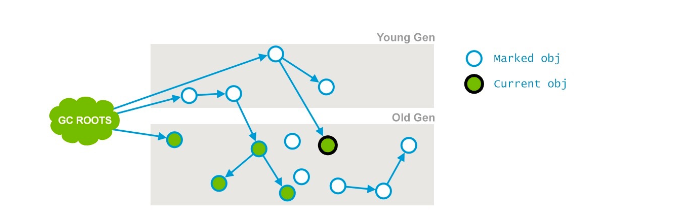
日志范例:

Concurrent Mark:这个阶段也是和应用程序线程并发工作的,它会将上一阶段运行期间引用关系发生变化的对象标记为Dirty Card。
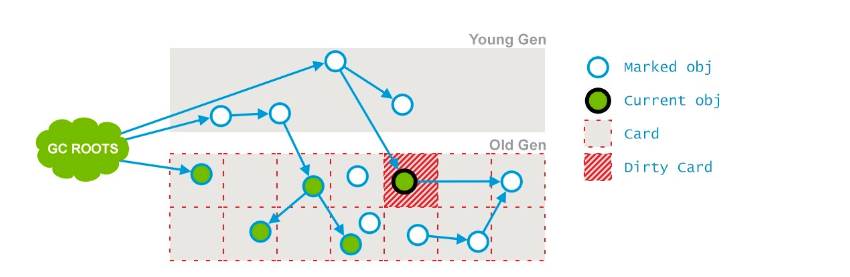
Concurrent Abortable Preclean:该阶段也是和应用程序线程并发执行的,它会尝试着去承担后续STW的Final Remark阶段的工作。
日志范例:

Final Remark:这个阶段是STW的,会标记出老年代中所有存活的对象。
日志范例

- Concurrent Sweep:和应用程序线程同时进行,移除那些不需要的对象,释放空间。
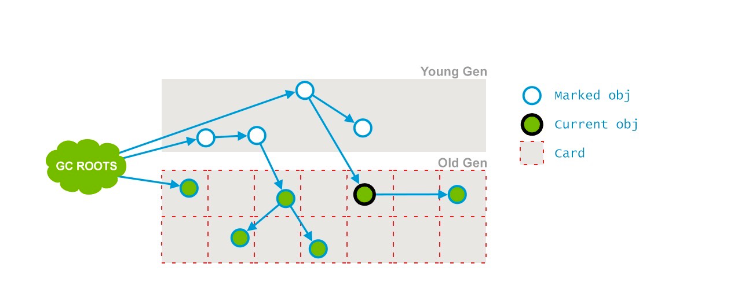
日志范例:

Concurrent Reset:这个阶段并发执行,重新设置CMS算法内部的数据结构,准备下一个CMS生命周期的使用。
日志范例:

问题复现
我们现在模拟一个场景,我们的web应用中有一个定时任务,这个定时任务每隔1s会想另一个定时任务线程池中提交100个任务。
注意spring boot应用要想开启定时任务必须添加@EnableScheduling注解。
代码如下所示:
@Component
public class Task {private static Logger logger = LoggerFactory.getLogger(Task.class);private static final ScheduledThreadPoolExecutor executor =new ScheduledThreadPoolExecutor(50,new ThreadPoolExecutor.DiscardOldestPolicy());private static class Obj {private String name = "name";private int age = 18;private String gender = "man";private LocalDate birthday = LocalDate.MAX;public void func() {//这个方法什么也不做}//返回count个Obj对象private static List<Obj> getObjList(int count) {List<Obj> objList = new ArrayList<>(count);for (int i = 0; i != count; ++i) {objList.add(new Obj());}return objList;}}@Scheduled(cron = "0/1 * * * * ? ") //每1秒执行一次public void execute() {logger.info("1s一次定时任务");//向线程池提交100个任务Obj.getObjList(100).forEach(i -> executor.scheduleWithFixedDelay(i::func, 2, 3, TimeUnit.SECONDS));}
}
完成后我们设置下面这段JVM参数后,将其启动
-Xms20M -Xmx20M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
不久后,控制台出现大量的CMS GC日志:
1288.111: [GC (CMS Initial Mark) [1 CMS-initial-mark: 13695K(13696K)] 19836K(19840K), 0.0058731 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
1288.117: [CMS-concurrent-mark-start]
1288.130: [CMS-concurrent-mark: 0.013/0.013 secs] [Times: user=0.05 sys=0.02, real=0.01 secs]
1288.130: [CMS-concurrent-preclean-start]
1288.133: [Full GC (Allocation Failure) 1288.133: [CMS1288.142: [CMS-concurrent-preclean: 0.012/0.012 secs] [Times: user=0.01 sys=0.00, real=0.01 secs] (concurrent mode failure): 13695K->13695K(13696K), 0.0610050 secs] 19839K->19836K(19840K), [Metaspace: 29026K->29026K(1077248K)], 0.0610521 secs] [Times: user=0.06 sys=0.00, real=0.06 secs]
1288.258: [Full GC (Allocation Failure) 1288.258: [CMS: 13695K->13695K(13696K), 0.0612134 secs] 19839K->19836K(19840K), [Metaspace: 29026K->29026K(1077248K)], 0.0612676 secs] [Times: user=0.06 sys=0.00, real=0.06 secs]
1288.320: [GC (CMS Initial Mark) [1 CMS-initial-mark: 13695K(13696K)] 19836K(19840K), 0.0041303 secs] [Times: user=0.03 sys=0.00, real=0.00 secs]
1288.324: [CMS-concurrent-mark-start]
1288.339: [CMS-concurrent-mark: 0.015/0.015 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
1288.339: [CMS-concurrent-preclean-start]
1288.348: [CMS-concurrent-preclean: 0.009/0.009 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
1288.348: [CMS-concurrent-abortable-preclean-start]
1288.348: [CMS-concurrent-abortable-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
1288.348: [GC (CMS Final Remark) [YG occupancy: 6142 K (6144 K)]1288.348: [Rescan (parallel) , 0.0038030 secs]1288.352: [weak refs processing, 0.0000311 secs]1288.352: [class unloading, 0.0024908 secs]1288.355: [scrub symbol table, 0.0042932 secs]1288.359: [scrub string table, 0.0002748 secs][1 CMS-remark: 13695K(13696K)] 19838K(19840K), 0.0109811 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
1288.360: [CMS-concurrent-sweep-start]
1288.364: [CMS-concurrent-sweep: 0.005/0.005 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
1288.364: [CMS-concurrent-reset-start]
1288.364: [CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
1288.384: [GC (Allocation Failure) 1288.384: [ParNew: 6143K->6143K(6144K), 0.0000365 secs]1288.384: [CMS: 13695K->13695K(13696K), 0.0540105 secs] 19839K->19836K(19840K), [Metaspace: 29026K->29026K(1077248K)], 0.0541242 secs] [Times: user=0.05 sys=0.00, real=0.05 secs]
排查思路
随着时间的推移,我们发现控制台出现了大量FULL GC(如果是生产环境,可能服务的响应速度会非常慢),所以我们首先需要定位这个进程的pid,首先在控制台输入jps找到进程,输出如下结果,可以看到这个pid为7476。
10848 KotlinCompileDaemon
4832 Jps
7476 JstackTestApplication
8856 RemoteMavenServer然后我们使用jstat观察其gc情况,如下所示,可以看到每隔10s,就会增加大量的FULL GC
C:\Users\xxx>jstat -gc 7476 10000 10S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
640.0 640.0 0.0 640.0 5504.0 665.5 13696.0 11176.2 31488.0 28992.6 4352.0 3889.5 39 0.084 15 0.100 0.184
640.0 640.0 0.0 640.0 5504.0 1487.2 13696.0 11176.2 31488.0 28992.6 4352.0 3889.5 39 0.084 25 0.142 0.227
640.0 640.0 0.0 640.0 5504.0 1697.8 13696.0 11176.2 31488.0 28992.6 4352.0 3889.5 39 0.084 35 0.185 0.269
640.0 640.0 0.0 640.0 5504.0 2380.4 13696.0 11176.2 31488.0 28992.6 4352.0 3889.5 39 0.084 41 0.249 0.334
640.0 640.0 0.0 640.0 5504.0 3063.0 13696.0 11176.2 31488.0 28992.6 4352.0 3889.5 39 0.084 44 0.260 0.345
640.0 640.0 0.0 640.0 5504.0 3745.6 13696.0 11176.2 31488.0 28992.6 4352.0 3889.5 39 0.084 46 0.270 0.355
640.0 640.0 0.0 640.0 5504.0 4342.6 13696.0 11176.2 31488.0 28992.6 4352.0 3889.5 39 0.084 50 0.297 0.382
再查看jmap查看堆区使用情况
jmap -heap 7476
Attaching to process ID 26176, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.212-b10using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GCHeap Configuration:MinHeapFreeRatio = 40MaxHeapFreeRatio = 70MaxHeapSize = 20971520 (20.0MB)NewSize = 6946816 (6.625MB)MaxNewSize = 6946816 (6.625MB)OldSize = 14024704 (13.375MB)NewRatio = 2SurvivorRatio = 8MetaspaceSize = 21807104 (20.796875MB)CompressedClassSpaceSize = 1073741824 (1024.0MB)MaxMetaspaceSize = 17592186044415 MBG1HeapRegionSize = 0 (0.0MB)Heap Usage:
New Generation (Eden + 1 Survivor Space):capacity = 6291456 (6.0MB)used = 5088288 (4.852569580078125MB)free = 1203168 (1.147430419921875MB)80.87615966796875% used
Eden Space:capacity = 5636096 (5.375MB)used = 5088288 (4.852569580078125MB)free = 547808 (0.522430419921875MB)90.28036428052326% used
From Space:capacity = 655360 (0.625MB)used = 0 (0.0MB)free = 655360 (0.625MB)0.0% used
To Space:capacity = 655360 (0.625MB)used = 0 (0.0MB)free = 655360 (0.625MB)0.0% used
concurrent mark-sweep generation:capacity = 14024704 (13.375MB)used = 13819664 (13.179458618164062MB)free = 205040 (0.1955413818359375MB)98.53800836010514% used12064 interned Strings occupying 1120288 bytes.
在排除内存泄漏的问题后,我们通过jstack定位进程中导致是什么对象导致老年代堆区被大量占用,如下所示可以看到前20名中的对象都是和定时任务相关,有一个Task$Obj对象非常抢眼,很明显就是因为它的数量过多导致的,此时我们就可以通过定位代码确定如何解决,常见方案无非是: 优化代码、增加空间两种方式,一般来说我们都会采用代码优化的方式去解决。
$ jmap -histo 7476 | head -n 20num #instances #bytes class name
----------------------------------------------1: 50760 3654720 java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask2: 30799 2901552 [C3: 88986 2847552 java.util.concurrent.locks.AbstractQueuedSynchronizer$Node4: 50700 1622400 com.example.jstackTest.Task$Obj5: 50760 1218240 java.util.concurrent.Executors$RunnableAdapter6: 50700 811200 com.example.jstackTest.Task$$Lambda$587/16055533137: 6391 707928 java.lang.Class8: 29256 702144 java.lang.String9: 13577 434464 java.util.concurrent.ConcurrentHashMap$Node10: 6363 341016 [Ljava.lang.Object;11: 1722 312440 [B12: 3414 230424 [I13: 4 210680 [Ljava.util.concurrent.RunnableScheduledFuture;14: 5223 208920 java.util.LinkedHashMap$Entry15: 2297 202136 java.lang.reflect.Method16: 2262 193760 [Ljava.util.HashMap$Node;17: 5668 181376 java.util.HashMap$Node而本次问题也很明显,任务是一个个提交到定时任务线程池中,是由于定时任务队列DelayedWorkQueue不断堆积任务导致内存被打满。所以最终改成将一个批操作一次性提交到定时任务中得以解决
@Scheduled(cron = "0/1 * * * * ? ") //每1秒执行一次public void execute() {logger.info("1s一次定时任务");//向线程池提交100个任务executor.scheduleWithFixedDelay(() -> {Obj.getObjList(100).forEach(i -> i.func());}, 2, 3, TimeUnit.SECONDS);}
补充:导致频繁FULL GC三大原因
我们需要需要具体分析才能得出解决方案,总的来说原因可以分为3个:
- 用户频繁调用
System.gc():这种情况需要修改代码即可,我们不该频繁调用这个方法的。 - 老年区空间过小:视情况适当扩大空间。
- 大对象过多:这种情况视情况决定是扩大老年代空间或者将大对象拆分。
更多JVM调优
从实际案例聊聊Java应用的GC优化
Java中9种常见的CMS GC问题分析与解决
听说 JVM 性能优化很难?今天我小试了一把!
一次线上JVM调优实践,FullGC40次/天到10天一次的优化过程
线上频繁发生Full GC 如何调优?如何快速定位OOM、cpu飙升、线程死锁等问题
参考文献
JVM学习(7)Stop-The-World
JVM调优——之CMS GC日志分析
从实际案例聊聊Java应用的GC优化
Spring Boot定时任务详解(线程池方式)
SpringBoot使用@Scheduled注解实现定时任务
面渣逆袭(Java 虚拟机-JVM面试题八股文)必看👍