目录
数据集切分
交叉验证
交叉验证实例
混淆矩阵
实例
代码实现
阈值
全局阈值处理
自适应阈值处理
阈值对结果的影响
ROC曲线
数据集切分
数据集切分是指将一个数据集分割成训练集和测试集的过程。常用的方法是随机切分,即将数据集中的样本按照一定比例分配到训练集和测试集中。切分数据集的目的是为了评估模型在未见过的数据上的性能,以便更好地了解模型的泛化能力。
在Python中,可以使用train_test_split函数来进行数据集切分。该函数位于sklearn.model_selection模块中,可以根据指定的比例将数据集切分成训练集和测试集。
from sklearn.model_selection import train_test_split# 假设x为特征数据,y为标签数据
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)# test_size参数指定了测试集的比例,这里设置为0.2,即将20%的数据分配给测试集
# random_state参数用于设置随机种子,保证每次切分的结果一致# 接下来可以使用x_train和y_train进行模型训练,使用x_test和y_test进行模型评估本实验使用sklearn内置数据集Mnist手写数字识别数据进行实验
# 数据集读取
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original')
X, y = mnist["data"], mnist["target"]
X.shape
# (70000, 784)
# 784个像素点 即784个特征值 28*28*1(长*宽*颜色通道[灰度图为1])
y.shape# 划分数据集
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]# 洗牌操作 打乱数据顺序(样本是独立的)
import numpy as npshuffle_index = np.random.permutation(60000)
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
shuffle_index
# array([12628, 37730, 39991, ..., 860, 15795, 56422])
交叉验证
交叉验证是一种常用的模型评估方法,通过将数据集划分为训练集和验证集,来评估模型的性能和泛化能力。交叉验证可以帮助我们更好地了解模型在未知数据上的表现,并选择最佳的模型参数。
常见的交叉验证方法有K折交叉验证和留一交叉验证。
-
K折交叉验证(K-fold Cross Validation):将数据集分成K个子集,其中K-1个子集用于训练模型,剩下的1个子集用于验证模型。这个过程会重复K次,每次选择不同的验证集。最后,将K次验证结果的平均值作为模型的性能指标。
-
留一交叉验证(Leave-One-Out Cross Validation,LOO-CV):将每个样本单独作为验证集,其余样本作为训练集。这个过程会重复N次,其中N是数据集的样本数量。最后,将N次验证结果的平均值作为模型的性能指标。
交叉验证的优点是能够更准确地评估模型的性能,减少因数据集划分不合理而引起的偏差。同时,交叉验证还可以帮助我们选择最佳的模型参数,以提高模型的泛化能力。

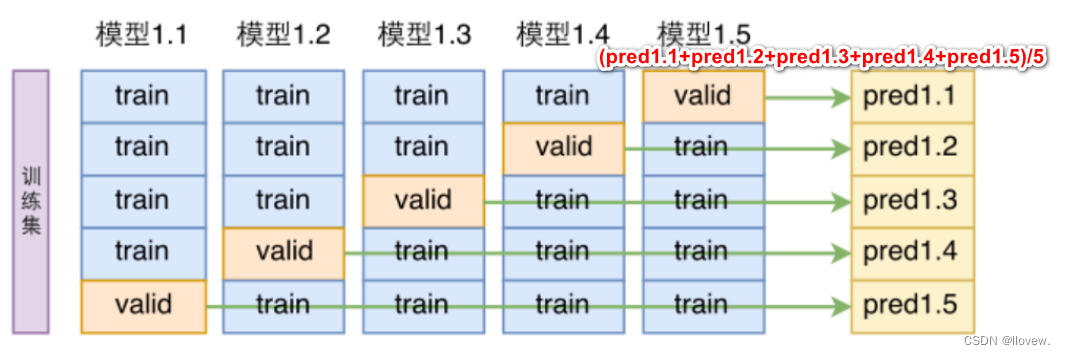
通俗解释交叉验证:一位高三的学生小明在高考前一直在刷题做53模拟试卷,53模拟试卷就表示测试集,最终的高考即代表训练集,由于高考只有一次机会,而小明想验证学习成果的时候只能先通过53模拟试卷的题来进行测试,由于53模拟试卷的题量多为了更好的验证学习成果则需要多次测试,最终测试结果就等于其多次测试的平均值。
交叉验证实例
# 使用StratifiedKFold进行了交叉验证,并在每个折叠中训练了一个克隆的分类器。
# 然后,使用训练好的分类器对测试集进行预测,并计算了预测准确率
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
# 将训练集分成3个折叠,并在每个折叠上进行训练和测试
skflods = StratifiedKFold(n_splits=3,random_state=42)
for train_index,test_index in skflods.split(X_train,y_train_5):clone_clf = clone(sgd_clf)X_train_folds = X_train[train_index]y_train_folds = y_train_5[train_index]X_test_folds = X_train[test_index]y_test_folds = y_train_5[test_index]clone_clf.fit(X_train_folds,y_train_folds)y_pred = clone_clf.predict(X_test_folds)n_correct = sum(y_pred == y_test_folds)print(n_correct/len(y_pred))混淆矩阵
混淆矩阵是用于评估分类模型性能的一种工具,它将实际目标值与机器学习模型预测的目标值进行比较。混淆矩阵是一个N x N的矩阵,其中N是目标类别的数量。
混淆矩阵的元素含义如下:
- True Positive(真正,TP):实际为正例,模型预测为正的样本数。
- True Negative(真负,TN):实际为负例,模型预测为负例的样本数。
- False Positive(假正,FP):实际为负例,模型预测为正例的样本数。
- False Negative(假负,FN):实际为正例,模型预测为负例的样本数。
混淆矩阵可以帮助我们计算出各种分类指标,例如正确率、召回率、精确率和F1值等,从而评估模型的性能和效果。
实例

代码实现
# 判断标签是否等于 5
y_train_5 = (y_train==5)
y_test_5 = (y_test==5)
# 查看前十个
y_train_5[:10]
# array([False, False, False, False, False, False, False, False, False, True])# 使用Scikit-learn库中的SGDClassifier类来训练一个二分类模型
from sklearn.linear_model import SGDClassifier
# 创建一个SGDClassifier对象,并设置参数max_iter=5和random_state=42。max_iter参数表示迭代次数,
# random_state参数用于控制随机数生成器的种子,以确保结果的可重复性
sgd_clf = SGDClassifier(max_iter=5,random_state=42)
# 使用fit()方法来训练模型。fit()方法接受训练数据集X_train和对应的标签y_train_5作为输入。
# 模型将根据这些数据进行学习,以便能够对新的数据进行预测
sgd_clf.fit(X_train,y_train_5)# 使用分类器预测结果
sgd_clf.predict([X[35000]]) #array([ True])
# 查看标签的真实值
y[35000] # 5.0#混淆矩阵 二分类任务
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf,X_train,y_train_5,cv=3)
y_train_pred.shape #(60000,)
X_train.shape #(60000, 784)
from sklearn.metrics import confusion_matrix
# 需要两个参数 标签值、预测值
confusion_matrix(y_train_5,y_train_pred)
"""
array([[53272, 1307],[ 1077, 4344]], dtype=int64)
"""negative class [[ true negatives , false positives ],
positive class [ false negatives , true positives ]]
- true negatives: 53,272个数据被正确的分为非5类别
-
false positives:1307张被错误的分为5类别
-
false negatives:1077张错误的分为非5类别
- true positives: 4344张被正确的分为5类别
一个完美分类器应该只有true positives 和 true negatives, 即主对角线元素不为0,其余元素为0

精度、召回率计算
from sklearn.metrics import precision_score,recall_score
# 精度
precision_score(y_train_5,y_train_pred) # 0.7687135020350381
# 召回率
recall_score(y_train_5,y_train_pred) #0.801328168234643F1 score指标
将Precision 和 Recall结合到一个称为F1 score 的指标,调和平均值给予低值更多权重。 因此,如果召回和精确度都很高,分类器将获得高F1分数。
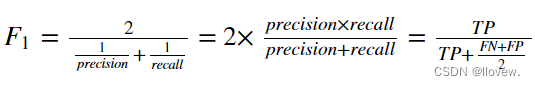
代码实现
from sklearn.metrics import f1_score
f1_score(y_train_5,y_train_pred) #0.7846820809248555阈值
阈值是图像处理中的一个重要概念,它是指将图像转换为二值图像的临界点。在阈值处理中,根据设定的阈值,将图像中的像素值分为两个类别,一类大于阈值,另一类小于阈值。大于阈值的像素被赋予一个固定的值(通常是白色),小于阈值的像素被赋予另一个固定的值(通常是黑色)。这样就可以将图像转换为黑白图像,以突出图像中的目标物体或特定区域。
阈值处理在图像分割、边缘检测、目标检测等领域有广泛的应用。常见的阈值处理方法有全局阈值和自适应阈值。
全局阈值是指将整个图像的像素值与设定的阈值进行比较,根据比较结果将像素分为两类。全局阈值处理适用于图像的整体对比度较好的情况。
自适应阈值是根据图像的局部特性来确定阈值。它将图像分成多个小区域,针对每个小区域计算局部阈值。自适应阈值处理适用于图像的局部对比度不均匀的情况。
全局阈值处理
import cv2# 读取图像
image = cv2.imread('image.jpg', 0)# 设定阈值
threshold_value = 127# 对图像进行全局阈值处理
_, thresholded_image = cv2.threshold(image, threshold_value, 255, cv2.THRESH_BINARY)# 显示结果
cv2.imshow('Thresholded Image', thresholded_image)
cv2.waitKey(0)
cv2.destroyAllWindows()自适应阈值处理
import cv2# 读取图像
image = cv2.imread('image.jpg', 0)# 对图像进行自适应阈值处理
thresholded_image = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2)# 显示结果
cv2.imshow('Thresholded Image', thresholded_image)
cv2.waitKey(0)
cv2.destroyAllWindows()阈值对结果的影响
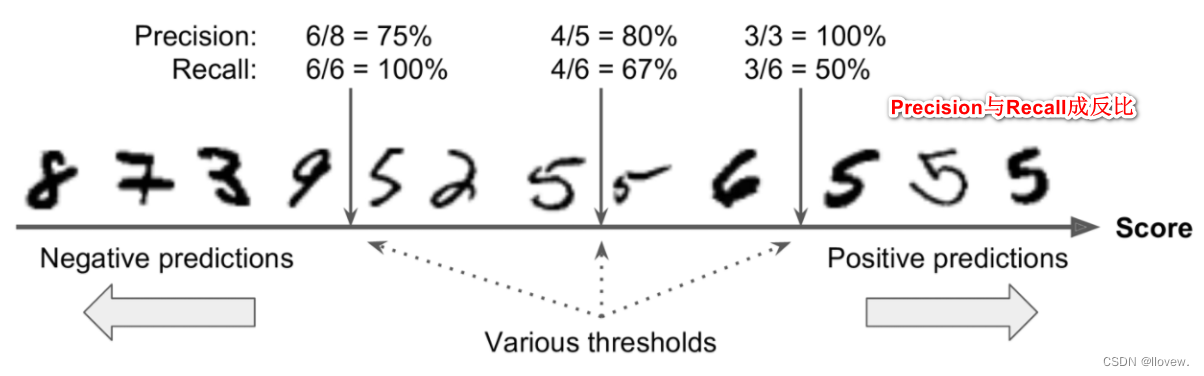
Scikit-Learn不允许直接设置阈值,但它可以得到决策分数,调用其decision_function()方法,而不是调用分类器的predict()方法,该方法返回每个实例的分数,然后使用想要的阈值根据这些分数进行预测。
y_scores = sgd_clf.decision_function([X[35000]])
y_scores # array([43349.73739616])
t = 50000
y_pred = (y_scores > t)
y_pred #array([False])y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,method="decision_function")y_scores[:10]
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
y_train_5.shape #(60000,)
thresholds.shape #(59698,)
precisions[:10]
precisions.shape #(59699,)
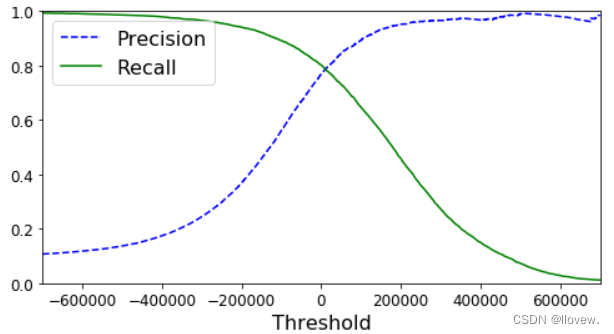
recalls.shape #(59699,)def plot_precision_recall_vs_threshold(precisions,recalls,thresholds):plt.plot(thresholds,precisions[:-1],"b--",label="Precision")plt.plot(thresholds,recalls[:-1],"g-",label="Recall")plt.xlabel("Threshold",fontsize=16)plt.legend(loc="upper left",fontsize=16)plt.ylim([0,1])plt.figure(figsize=(8, 4))
plot_precision_recall_vs_threshold(precisions,recalls,thresholds)
plt.xlim([-700000, 700000])
plt.show()
ROC曲线
ROC曲线(Receiver Operating Characteristic curve)是一种用于评估二分类模型性能的图形工具。它以虚警率(False Positive Rate)为横轴,命中率(True Positive Rate)为纵轴,绘制出的曲线可以反映出模型在不同阈值下的性能表现。
ROC曲线的横轴是虚警率,表示将负例错误地判定为正例的概率。纵轴是命中率,表示将正例正确地判定为正例的概率。ROC曲线上的每个点代表了在不同阈值下模型的性能表现,而曲线上的每个点都对应着一个不同的阈值。
ROC曲线的形状可以帮助我们评估模型的性能。曲线越靠近左上角,说明模型的性能越好,虚警率较低的同时命中率较高。曲线越接近对角线,说明模型的性能越差,虚警率和命中率的比例相对均衡。
通过比较不同模型的ROC曲线,我们可以选择最佳的模型。通常情况下,我们会选择曲线下面积(Area Under Curve,AUC)较大的模型作为最佳模型,因为AUC值表示了模型在所有阈值下的平均性能。
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)def plot_roc_curve(fpr, tpr, label=None):plt.plot(fpr, tpr, linewidth=2, label=label)plt.plot([0, 1], [0, 1], 'k--')plt.axis([0, 1, 0, 1])plt.xlabel('False Positive Rate', fontsize=16)plt.ylabel('True Positive Rate', fontsize=16)plt.figure(figsize=(8, 6))
plot_roc_curve(fpr, tpr)
plt.show()
receiver operating characteristic (ROC) 曲线是二元分类中的常用评估方法
-
它与精确度/召回曲线非常相似,但ROC曲线不是绘制精确度与召回率,而是绘制true positive rate(TPR) 与false positive rate(FPR)
-
要绘制ROC曲线,首先需要使用roc_curve()函数计算各种阈值的TPR和FPR:
TPR = TP / (TP + FN) (Recall)
FPR = FP / (FP + TN)
虚线表示纯随机分类器的ROC曲线; 一个好的分类器尽可能远离该线(朝左上角)。
比较分类器的一种方法是测量曲线下面积(AUC)。完美分类器的ROC AUC等于1,而纯随机分类器的ROC AUC等于0.5。 Scikit-Learn提供了计算ROC AUC的函数
from sklearn.metrics import roc_auc_scoreroc_auc_score(y_train_5, y_scores) #0.9624496555967156



![构建搜索引擎,而非向量数据库(Vector DB) [译]](https://img-blog.csdnimg.cn/img_convert/8321c354d095da7d382a47f13b76d7b9.png)
