目录
一.什么是泛型编程?
编辑
编辑
二.函数模板
函数模板的实例化
当不同类型形参传参时的处理
使用多个模板参数
三.模板参数的匹配原则
四.类模板
1.定义对象时要显式实例化
2.类模板不支持声明与定义分离
3.非类型模板参数
4.模板的特化
函数模板特化
类模板特化
类模板特化应用示例
模板的优缺点:
一.什么是泛型编程?
当我们写一个交换两个数的函数:
void swap(int& x, int& y)
{int temp = x;x = y;y = temp;
}我们知道,这个函数只能交换两个整形变量的值,在C++中虽然实现了函数重载,但是如果我们想要实现交换两个浮点数的值,仍要重新写一个函数,但是函数的内容几乎和交换整形的内容几乎一样,这就显得代码有些重复,同时又增加了程序员的工作量且不方便维护代码。
那能否告诉编译器一个模子,让编译器根据不同的类型利用该模子来生成代码呢?
模板分为:函数模板与类模板
二.函数模板
概念:
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定 类型版本。
函数模板格式:
template<typename T1, typename T2,......,typename Tn>
返回值类型 函数名(参数列表){}注:typename是用来定义模板参数关键字,也可以使用class(切记:不能使用struct代替class)
例子:
#include<iostream>
using namespace std;template<typename T>
void Swap(T& x, T& y)
{int temp = x;x = y;y = temp;
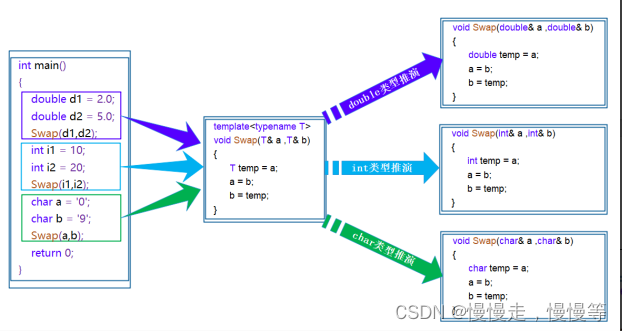
}int main()
{int a = 1, b = 2;double e = 1.1, f = 2.2;Swap(a, b);Swap(e, f);cout << a << " " << b << endl;cout << e << " " << f << endl;return 0;
}注:main()函数里的两个Swap函数,调用的不是同一个函数,也不是模板,而是编译器用模板生成的实例化Swap函数,在上述代码中,模板会生成int和double两种实例化函数。
函数模板的实例化
1. 隐式实例化:让编译器根据实参推演模板参数的实际类型
template<class T>
T Add(const T& left, const T& right)
{return left + right;
}
int main()
{int a1 = 10, a2 = 20;double d1 = 10.0, d2 = 20.0;Add(a1, a2);Add(d1, d2);return 0;
}2. 显式实例化:在函数名后的<>中指定模板参数的实际类型
int main()
{int a = 10;double b = 20.0;// 显式实例化Add<int>(a, b);return 0;
}当不同类型形参传参时的处理
int main()
{int a=1,b=2;double c=1.1,d=2.2;/*Add(a,c);该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有一个T,编译器无法确定此处到底该将T确定为int 或者 double类型而报错注意:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,编译器就需要背黑锅*/// 此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化Add(a,(int)c);//用户自己来强制转化Add<int>(a,c);//使用显式实例化return 0;
}方式一:在编译器推演前就将c强转成int
方式二:明确告诉编译器类型是int,经此编译器直接将c作为int处理
使用多个模板参数
T1 Add(const T1 a, const T1 b)
{return a + b;}int main()
{int a = 1, b2;double c = 1.1, d = 2.2;Add(a, c); //多个模板参数,编译器推演为Add<int,double>(a,c)return 0;
}三.模板参数的匹配原则
// 专门处理int的加法函数
int Add(int left, int right)
{return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{return left + right;
}
void Test()
{Add(1, 2); // 与非模板函数匹配,编译器不需要特化Add<int>(1, 2); // 调用编译器特化的Add版本
}// 专门处理int的加法函数
int Add(int left, int right)
{return left + right;
}// 通用加法函数
template<class T1, class T2>
T1 Add(T1 left, T2 right)
{return left + right;
}void Test()
{Add(1, 2); // 与非函数模板类型完全匹配,不需要函数模板实例化Add(1, 2.0); // 模板函数可以生成更加匹配的版本,编译器根据实参生成更加匹配的Add函
数
}四.类模板
定义格式:
template<class T1, class T2, ..., class Tn>
class 类模板名
{// 类内成员定义
};例子:
template<class T>
class Stack
{
public:Stack():_data(nullptr),_size(0),_capacity(0){}~Stack(){cout << "~Stack()" << endl;delete[]_data;_data = nullptr;_size = _capacity = 0;}void push(T x){//入栈}private:T* _data;int _size;int _capacity;};1.定义对象时要显式实例化
int main()
{Stack<int> s;s.push(1);Stack<double> x;x.push(1.1);return 0;
}我们知道使用模板定义时,需要通过参数确定类型进行显示实例化,显而易见的时,类模板无法向函数模板一样通过传参来确定类型。因此必须要在定义对象时,显示实例化类型。
类模板显式实例化的类型不同,他们就是不同的类。如上面的s与x就属于不同的类定义出的两个对象。所以不能又s=x这样的操作,除非你在s类中对=进行运算符重载。
类模板名字不是真正的类,而实例化的结果才是真正的类
// Vector类名,Vector<int>才是类型
Vector<int> s1;
Vector<double> s2;2.类模板不支持声明与定义分离
template<class T>
class Stack
{
public:Stack();~Stack();void push(const T& ch);private:T* _data;int _size;int _capacity;
};template<class T>
Stack<T>::Stack()
{//构造函数初始化
}template<class T>
Stack<T>::~Stack()
{//析构
}template<class T>
void Stack<T>::push(const T& ch)
{//入栈
}
类模板的成员函数不支持声明与定义分离。因为类模板和函数模板都不是真正的定义,真正的定义是在实例化之后由编译器完成。如果声明与定义分离,编译器会由于没有推演出参数,使定义部分并不会编译,而main函数里由于有声明会编译,最后导致在汇编时,找不到函数的定义报错。
解决放法:
1.在模板定义的位置显式实例化
template
class Stack<int>;//显式实例化2.声明与定义不分离,全部放在一个.hpp文件(相当于.h+.cpp。一般里面大概率会有模板)或.h文件里。
3.非类型模板参数
类型形参即:出现在模板参数列表中,跟在 class 或者 typename 之类的参数类型名称 。非类型形参,就是用一个常量作为类 ( 函数 ) 模板的一个参数,在类 ( 函数 ) 模板中可将该参数当成常量来使用 。
如:当你想在一个类中定义一个静态数组的成员变量,在C语言中只能使用宏定义的方式确定数组的大小,但是这样数组的大小是固定的。
C++中可以在模板使用非类型模板参数,在类里生成一个可以指定大小的成员变量。
template<class T,size_t n>
class arr
{
private:T a[n];
};int main()
{arr<int,10> a1;arr<int,20> a2;return 0;
}注:非类型模板参数,只支持 整形,常量。浮点型,变量,类对象都不行。
4.模板的特化
概念:
通常情况下, 使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结 果 ,需要特殊处理,比如:实现了一个专门用来进行小于比较的函数模板
举例:
// 函数模板 -- 参数匹配
template<class T>
bool Less(T left, T right)
{return left < right;
}
int main()
{cout << Less(1, 2) << endl; // 可以比较,结果正确Date d1(2022, 7, 7);Date d2(2022, 7, 8);cout << Less(d1, d2) << endl; // 可以比较,结果正确Date* p1 = &d1;Date* p2 = &d2;cout << Less(p1, p2) << endl; // 可以比较,结果错误return 0;
}函数模板特化
1. 必须要先有一个基础的函数模板2. 关键字 template 后面接一对空的尖括号 <>3. 函数名后跟一对尖括号,尖括号中指定需要特化的类型4. 函数形参表 : 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
// 函数模板 -- 参数匹配
template<class T>
bool Less(T left, T right)
{return left < right;
}
// 对Less函数模板进行特化
template<>
bool Less<Date*>(Date* left, Date* right)
{return *left < *right;
}
int main()
{cout << Less(1, 2) << endl;Date d1(2022, 7, 7);Date d2(2022, 7, 8);cout << Less(d1, d2) << endl;Date* p1 = &d1;Date* p2 = &d2;cout << Less(p1, p2) << endl; // 调用特化之后的版本,而不走模板生成了return 0;
}bool Less(Date* left, Date* right)
{return *left < *right;
}类模板特化
类模板特化与函数模板特化一样:必须存在模板.(即在原模板的基础上进行特化)
类模板特化分为:全特化,偏特化
全特化:
全特化即是将模板参数列表中所有的参数都确定化
template<class T1, class T2>
class Data
{
public:Data() {cout<<"Data<T1, T2>" <<endl;}
private:T1 _d1;T2 _d2;
};template<>
class Data<int, char> //特化为int char
{
public:Data() {cout<<"Data<int, char>" <<endl;}
private:int _d1;char _d2;
};void TestVector()
{Data<int, int> d1;Data<int, char> d2;
}偏特化:
偏特化:任何针对模版参数进一步进行条件限制设计的特化版本。比如对于以下模板类:
template<class T1, class T2>
class Data
{
public:Data() {cout<<"Data<T1, T2>" <<endl;}
private:T1 _d1;T2 _d2;
};偏特化有以下两种表现方式:
// 将第二个参数特化为int
template <class T1>
class Data<T1, int>
{
public:Data() {cout<<"Data<T1, int>" <<endl;}
private:T1 _d1;int _d2;
};//两个参数偏特化为指针类型
template <typename T1, typename T2>
class Data <T1*, T2*>
{
public:Data() {cout<<"Data<T1*, T2*>" <<endl;}private:T1 _d1;T2 _d2;
};//两个参数偏特化为指针类型
template <typename T1, typename T2>
class Data <T1*, T2*>
{
public:Data():_d1(d1),_d2(d2){cout<<"Data<T1*, T2*>" <<endl;}private:const T1 & _d1;const T2 & _d2; };void test2 ()
{Data<double , int> d1; // 调用特化的int版本Data<int , double> d2; // 调用基础的模板 Data<int *, int*> d3; // 调用特化的指针版本Data<int&, int&> d4(1, 2); // 调用特化的指针版本
}注:当模板,模板的特护全都存在是,那个类型最匹配,就用那个。
类模板特化应用示例
专门用来按照小于比较的类模板Less:
#include<vector>
#include <algorithm>
template<class T>
struct Less
{bool operator()(const T& x, const T& y) const{return x < y;}
};int main()
{Date d1(2022, 7, 7);Date d2(2022, 7, 6);Date d3(2022, 7, 8);vector<Date> v1;v1.push_back(d1);v1.push_back(d2);v1.push_back(d3);// 可以直接排序,结果是日期升序sort(v1.begin(), v1.end(), Less<Date>());vector<Date*> v2;v2.push_back(&d1);v2.push_back(&d2);v2.push_back(&d3);// 可以直接排序,结果错误日期还不是升序,而v2中放的地址是升序// 此处需要在排序过程中,让sort比较v2中存放地址指向的日期对象// 但是走Less模板,sort在排序时实际比较的是v2中指针的地址,因此无法达到预期sort(v2.begin(), v2.end(), Less<Date*>());return 0;
}// 对Less类模板按照指针方式特化
template<>
struct Less<Date*>
{bool operator()(Date* x, Date* y) const{return *x < *y;}
};特化之后,在运行上述代码,就可以得到正确的结果