四、推荐系统---模型训练
1、模型训练代码
模型训练代码参照scala文件:Recommonder.scala
1.Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
2.val conf = new SparkConf().setAppName("recommonder").setMaster("local[*]")
3.val sc = new SparkContext(conf)
4.//加载数据,用\t分隔开
5.val data: RDD[Array[String]] = sc.textFile("./traindata").map(_.split("\t")).sample(false,0.1,100L)
6.
7.//得到第一列的值,也就是label
8.val label: RDD[String] = data.map(_(0))
9.
10.//sample这个RDD中保存的是每一条记录的特征名
11.//-1 Item.id,hitop_id53:1;Item.screen,screen6:1;Item.name,ch_name80:1;Item.author,author1:1
12.val sample: RDD[Array[String]] = data.map(_(1)).map(x => {
13.val arr: Array[String] = x.split(";").map(_.split(":")(0))
14.arr
15.})
16.//将所有元素压平,得到的是所有分特征,然后去重,最后索引化,也就是加上下标,最后转成map是为了后面查询用
17.//dict 是所有数据的所有不重复的特征
18.val allFeaturesMap: Map[String, Long] = sample.flatMap(x =>x).distinct().zipWithIndex().collectAsMap()
19.//得到稀疏向量,为每条数据的features,与dict对比,缺少的特征补成0
20.val sam: RDD[SparseVector] = sample.map((sampleFeatures :Array[String])=> {
21.//index中保存的是,未来在构建训练集时,下面填1的索引号集合
22.val currentOneInfoAllFeatureIndexs: Array[Int] = sampleFeatures.map(feature => {
23.//get出来的元素程序认定可能为空,做一个类型匹配
24.val currentFeatureIndex: Long = allFeaturesMap.get(feature).get
25.//非零元素下标,转int符合SparseVector的构造函数
26.currentFeatureIndex.toInt
27.})
28.//SparseVector创建一个向量
29.new SparseVector(allFeaturesMap.size, currentOneInfoAllFeatureIndexs, Array.fill(currentOneInfoAllFeatureIndexs.length)(1.0))
30.})
31.
32.//mllib中的逻辑回归只认1.0和0.0,这里进行一个匹配转换
33.val trainData: RDD[LabeledPoint] = label.map(x => {
34.x match {
35.case "-1" => 0.0
36.case "1" => 1.0
37.}
38.//标签组合向量得到labelPoint
39.}).zip(sam).map(tuple => new LabeledPoint(tuple._1, tuple._2.toDense))
40.
41.//逻辑回归训练,两个参数,迭代次数和步长,生产常用调整参数
42.val model = new LogisticRegressionWithLBFGS()
43..setNumClasses(2)
44..setIntercept(true)
45..run(trainData)
46.
47.//模型结果权重
48.val weights: Array[Double] = model.weights.toArray
49.//将map反转,weights相应下标的权重对应map里面相应下标的特征名
50.val map: Map[Long, String] = allFeaturesMap.map(_.swap)
51.val pw = new PrintWriter("./model");
52.for(i<- 0 until weights.length){
53.//通过map得到每个下标相应的特征名
54.val featureName = map.get(i)match {
55.case Some(feature) => feature
56.case None => ""
57.}
58.//特征名对应相应的权重
59.val str = featureName+"\t" + weights(i)
60.pw.write(str)
61.pw.println()
62.}
63.pw.flush()
64.pw.close()
65.2、将数据导入到Redis
将app基本信息表、app历史下载表、app浏览下载表导入到Redis中,供后期dubbo推荐服务使用。
1.import redis
2.
3.# 将特征值模型文件数据存入redis数据库,将用户历史下载数据存入redis,将app基本描述商品词表存入redis数据库
4.pool = redis.ConnectionPool(host='mynode4', port='6379', db=2)
5.r = redis.Redis(connection_pool=pool)
6.
7.f = open('./ModelFile.txt', "rb")
8.while True:
9. lines = f.readlines(100)
10. if not lines:
11. break
12. for line in lines:
13. kv = line.decode("utf-8").split('\t')
14. r.hset("rcmd_features_score", kv[0], kv[1])
15.
16.f = open('./UserItemsHistory.txt', "rb")
17.while True:
18. lines = f.readlines(100)
19. if not lines:
20. break
21. for line in lines:
22. kv = line.decode("utf-8").split('\t')
23. r.hset('rcmd_user_history', kv[0], kv[1])
24.
25.f = open('./ItemList.txt', "rb")
26.while True:
27. lines = f.readlines(100)
28. if not lines:
29. break
30. for line in lines:
31. kv = line.decode("utf-8").split('\t')
32. # line[:-2] 取line 字符串的开头到倒数第二个的位置 数据,含头不含尾,也就是-2 就是将s 字符串中倒数后两个字符删除,常用在从文本读入数据的时候消除换行符的影响
33. r.hset('rcmd_item_list', kv[0], line[:-2])
34.print('all finished...')
35.f.close()五、推荐流程-dubbo介绍
dubbo介绍参照文档:dubbo.doc
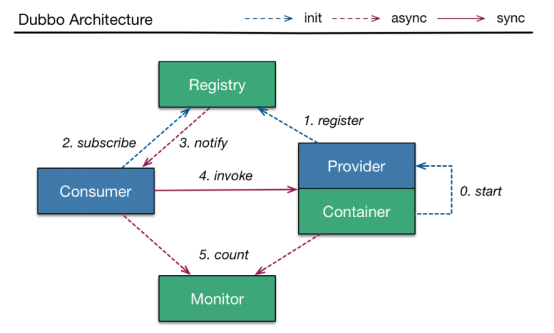
六、推荐系统-dubbo实现推荐服务
利用dubbo实现推荐服务,核心代码如下:
1.public List<String> getRcmdList(String uid) {
2.
3. // 获得数据库连接
4. Jedis jedis = new Jedis("mynode4", 6379);
5. jedis.select(2);
6. // 从用户历史下载表来获取最近下载
7. String downloads = jedis.hget("rcmd_user_history", uid);
8. String[] downloadList = downloads.split(",");
9.
10. // 获取所有appID列表
11. Set<String> appList = jedis.hkeys("rcmd_item_list");
12.
13. // 存储总的特征分值
14. Map<String, Double> scoresMap = new HashMap<String, Double>();
15.
16. // 分别计算所有应用的总权重
17. for (String appId : appList) {
18. if(Arrays.asList(downloadList).contains(appId)) {
19. continue;
20. }
21. // 计算关联权重
22. double relativeFeatureScore = getRelativeFeatureScore(appId, downloadList, jedis);
23. updateScoresMap(scoresMap, appId, relativeFeatureScore);
24. // 计算基本权重
25. double basicFeatureScore = getBasicFeatureScore(appId, jedis);
26. updateScoresMap(scoresMap, appId, basicFeatureScore);
27. }
28.
29. //这里将map.entrySet()转换成list
30. List<Map.Entry<String, Double>> list = new ArrayList<Map.Entry<String, Double>>(scoresMap.entrySet());
31. //然后通过比较器来实现排序
32. Collections.sort(list, new Comparator<Map.Entry<String, Double>>() {
33. //降序排序
34. public int compare(Map.Entry<String, Double> entry1,
35. Map.Entry<String, Double> entry2) {
36. return -entry1.getValue().compareTo(entry2.getValue());
37. }
38. });
39. // 打印分值
40. for (Map.Entry<String, Double> mapping : list) {
41. System.out.println(mapping.getKey() + ":" + mapping.getValue());
42. }
43.
44. // 取前10个appID返回
45. List<String> result = new ArrayList<>();
46. int count = 0;
47. for (Map.Entry<String, Double> mapping : list) {
48. count++;
49. result.add(mapping.getKey());
50. if(count==10){
51. break;
52. }
53. }
54.
55. jedis.close();
56. return result;
57.}