文章目录
- 前言
- 0、论文摘要
- 一、Introduction
- 1.1目标问题
- 1.2相关的尝试
- 1.3本文贡献
- 二.相关工作
- 强化学习方法
- 两阶段重新排名方法
- 具有序列级损失的多任务学习
- 三.本文方法
- 3.1 相似度函数
- 3.2 校准损失
- 3.3正则化损失
- 3.4 候选解码方法
- 四 实验效果
- 4.1数据集
- 4.2 对比模型
- 4.3实施细节
- 4.4评估指标
- 4.5 实验结果
- 校准序列似然的好处
- 校准模型的缩放属性
- 最终结果
- 五 总结
前言

CALIBRATING SEQUENCE LIKELIHOOD IMPROVES CONDITIONAL LANGUAGE GENERATION(2209)
0、论文摘要
条件语言模型主要通过最大似然估计(MLE)进行训练,为稀疏观察的目标序列提供概率质量。虽然 MLE 训练的模型为给定上下文的合理序列分配了高概率,但模型概率通常不会按质量准确地对生成的序列进行排序。这已在波束搜索解码中凭经验观察到,因为大波束尺寸会导致输出质量下降,而解码策略则受益于长度归一化和重复阻止等启发式方法。
在这项工作中,我们引入了序列似然校准(SLiC),其中对模型生成序列的似然进行校准,以更好地与模型潜在空间中的参考序列对齐。使用 SLiC,解码启发式变得不必要,并且无论采用何种解码方法,解码候选的质量都会显着提高。
此外,SLiC 没有显示出模型规模带来的回报递减的迹象,并且提供了在有限的训练和推理预算下提高质量的替代方法。
借助 SLiC,我们在抽象摘要、问题生成、抽象问答和数据到文本生成等广泛的生成任务上超越或匹配了 SOTA 结果,即使是中等大小的模型也是如此。
一、Introduction
1.1目标问题
条件语言生成旨在根据输入上下文生成自然语言文本,包括许多有用且困难的任务,例如抽象摘要(Mani,2001;Nenkova 和 McKeown,2011)、生成式问答(Bajaj 等人,2016)、问题生成(Zhou et al., 2017)和数据到文本(Wiseman et al., 2017; Gardent et al., 2017)任务。预训练大型 Transformer 编码器-解码器模型并在下游任务上对其进行微调是解决这些任务的常见范例(Raffel 等人,2020;Lewis 等人,2019;Tay 等人,2022;Zhang 等人, 2019a)。
条件语言生成任务是通过学习给定上下文序列 x 的目标序列 y 的概率来建模的。由于直接对所有可能生成的文本序列上的序列概率 P (y|x) 进行建模很困难,因此规范的解决方案是自回归分解概率并在所有标记预测步骤中共享参数,即 Pθ(y|x) = ∏l t =0 Pθ(yt|y0…yt−1, x),其中 l 是序列长度。这些模型通常使用最大似然估计 (MLE) 对观察到的目标序列进行训练。学习目标因此变为 L = ΣN i −log(Pθ(yi|xi)) = ΣN i Σl t=0 −log(Pθ(yt i |y0 i …yt−1 i , xi)),其中 N 是训练实例的数量。它也被称为下一个令牌预测损失,因为它在数学上是等效的。
在 MLE 训练的理想设置中,每个上下文都会观察到大量目标序列,并且输出序列的相对频率可以校准分配的模型概率。然而,实际上大多数语言生成训练数据集只有一个目标序列鉴于上下文。虽然随后的 MLE 训练模型学习为合理的序列分配相对较高的概率,但它们缺乏比较这些序列的直接监督,并且仅依赖于模型的泛化能力。我们将这种现象称为模型的序列似然未校准。先前的工作(Liu 和 Liu,2021;Liu 等人,2022)表明,MLE 训练模型的序列概率与其质量之间的相关性可能较低。刘等人。 (2022)将此类似地归因于确定性(单点)目标分布问题。暴露偏差(Ranzato et al., 2016)进一步加剧了问题,因为当模型的解码序列偏离暴露的训练数据分布时,序列似然估计的噪声更大。
在训练和解码过程中,人们提出了许多有效的启发式方法来解决未校准序列似然的问题。标签平滑(Szegedy et al., 2016)可防止网络对观察到的目标过于自信。这在语言生成中尤其必要,因为黄金目标仅代表多种可能性中的一种。据观察,解码候选数量的增加超过某一点会导致波束搜索解码(Yang 等人,2018;Koehn 和 Knowles,2017)和采样(Adiwardana 等人,2020)的质量变差。解码候选的最佳数量通常是通过在验证集上解码模型并测量其性能来凭经验确定的。使用长度归一化对于波束搜索解码(Wu et al., 2016)和采样(Adiwardana et al., 2020)也至关重要,因为模型往往会低估较长句子的序列可能性。当模型高估重复序列的概率时,重复是另一种常见的故障模式(Holtzman 等人,2019)。 Trigram 阻断(Paulus 等人,2018)和核采样(Holtzman 等人,2020)已被用来中断重复序列。这些技术很普遍,并且通常是现代 Transformer 库中的默认技术(Wolf 等人,2020;Lewis 等人,2019;Raffel 等人,2020;Zhang 等人,2019a)。
由于 MLE 训练中缺乏观察到的目标序列是根本问题,因此已经提出了涉及使用多个候选序列进行学习的解决方案来直接解决该问题。它们可以大致分为三类:(1)具有序列级奖励的强化学习(Paulus et al., 2018;Ziegler et al., 2019;Stiennon et al., 2020); (2) 生成候选者并对其重新排名的两阶段系统(Liu 和 Liu,2021;Ravaut 等人,2022b;Liu 等人,2022); (3)具有序列级损失的多任务学习(Edunov et al., 2018;Liu et al., 2022)。请参阅相关著作(第 4 节)以获得更全面的讨论。
1.2相关的尝试
1.3本文贡献
在本文中,我们建议首先在其自己的训练数据集上从微调模型中解码候选者,然后继续使用新目标训练模型。新目标旨在根据候选序列与模型潜在空间中目标序列的相似性来对齐候选序列的可能性。我们将此过程称为序列似然校准 (SLiC)。
我们的方法与 Liu 等人的具有序列级损失的多任务学习相关。 (2022)。
然而,我们提出了一种简单而有效的方法,可以消除解码启发式方法,并且不会冒直接优化用于报告文本生成质量的相同指标的风险。
与强化学习不同,它是一次性离线过程,避免了昂贵的在线解码过程。
此外,与两阶段重新排名系统相比,它不需要单独的重新排名模型,从而增加额外的复杂性和计算量。如图 1 所示,我们的校准阶段自然地扩展了当前预训练和微调的范式,并且我们表明,在不同模型大小上,校准模型比仅微调模型有很大的改进。
总之,我们的贡献如下:
提出了序列似然校准 (SLiC) 阶段,该阶段能够持续提高模型质量,超越或匹配抽象摘要、生成问答、问题生成和数据到文本生成任务的最先进结果。
• 提出了模型解码和模型潜在空间中测量的目标之间的新颖校准相似性度量,而不是诉诸外部度量或人类反馈。
• 证明SLiC 无需流行的解码启发式方法,例如校准模型的波束尺寸优化、长度归一化和重复预防。
• 证明即使模型参数数量增加,SLiC 对模型性能也具有持续的显着优势。在相同的推理预算下,较小的校准模型可能通过解码更多候选者而胜过较大的模型。
二.相关工作
强化学习方法
保卢斯等人。 (2018)在RL微调阶段直接优化评价指标ROUGE。一个问题是 ROUGE 指标不强制流畅性。作者发现摘要并不总是可读,并提出使用混合训练目标效果更好。齐格勒等人。 (2019);斯蒂农等人。 (2020)收集人类对微调模型解码的判断,以训练根据人类偏好对候选者进行排名的奖励模型。然后使用 PPO 针对奖励模型对监督策略进行微调。作者发现,与直接优化 ROUGE 相比,优化奖励模型会产生更好的质量摘要。
两阶段重新排名方法
SimCLS(Liu and Liu,2021)提出将文本生成公式化为对比学习辅助的无参考质量估计问题。第一阶段通过不同的波束搜索对候选者进行解码,并在第二阶段使用基于 RoBERTa 的模型对它们进行排名。 SummaReRanker(Ravaut 等人,2022a)观察到,与在相同数据上训练两个模型相比,在微调数据的两个不重叠的一半上训练生成和重新排序模型时,性能有所提高。李等人。 (2021) 训练一个用于神经机器翻译的判别性重排序器,该重排序器可以预测观察到的 BLEU 分数在 n 最佳列表中的分布。 BRIO(Liu et al., 2022)包括一个使用序列到序列生成模型的两阶段重新排序系统。结果表明,序列到序列重排序器在提供排序分数方面比仅编码器模型具有更好的性能。
具有序列级损失的多任务学习
埃杜诺夫等人。 (2018)调查了一系列用于结构化预测的经典目标函数,并将其应用于序列到序列模型。他们的实验表明,将序列级目标与标记级目标相结合可以提高翻译和摘要数据集的性能。 Sun 和 Li(2021)将对比学习目标与负对数似然相结合,以降低模型生成“银”摘要的可能性,同时增加“金”参考的可能性。 BRIO(Liu et al., 2022)证明,与两阶段重排序系统相比,通过对比重排序和标记级生成对候选序列进行多任务学习具有更好的性能。排名顺序是通过使用外部指标(ROUGE、BERTScore)与目标的相似性来确定的。经过 ROUGE 训练进行排名的模型在 BERTScore 上的测量结果也表现良好,反之亦然。卢卡西克等人。 (2020) 将标签平滑从分类任务扩展到用于序列到序列学习的语义标签平滑。他们的技术增加了序列级损失,平滑了在语义上和 n-gram 级别上与目标序列相似的格式良好的相关序列。
三.本文方法
我们通过引入第三个校准阶段 SLiC 来扩展预训练和微调的常见范例。如算法 1 所示,我们首先在微调数据集 {x, ̄ y}n 上从微调模型 Pθft (y|x) 解码 m 个候选 {ˆ y}m,然后通过继续校准微调模型对我们提出的损失进行训练: L(θ) = Σ b Lcal(θ, s; x, ̄ y, {ˆ y}m) + λLreg(θ, θft; x, ̄ y) ,其中 Lcal 和 Lreg 是校准和正则化损失。 s = s(ˆ y, ̄ y; x) 衡量候选者 ˆ y 和目标 ̄ y 之间的相似度(以上下文 x 为条件)。我们在下面的部分中讨论 s、Lcal、Lreg 的选择和解码策略 ˆ y ∼ Pθ(y|x)。
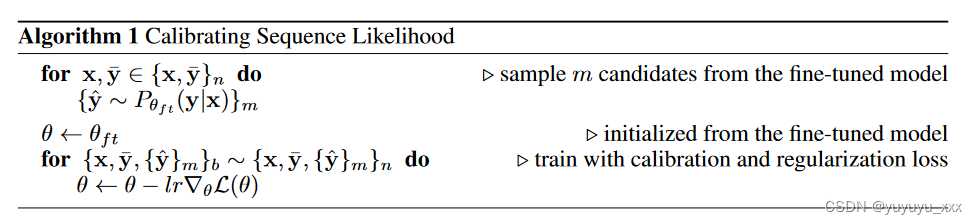
3.1 相似度函数
对于给定的输出序列 y,我们将解码器输出隐藏状态 eL×D = emb(y, x) 作为其表示,其中 L 是标记数,D 是隐藏状态维度。在候选 ^ y 的表示 ^ e 和目标 ̄ y 的表示 ̄ e 之间,我们计算它们在 n 个标记跨度上的余弦相似度,并使用基于 F 测量的函数 Fn 在序列上聚合它们。 Fn、Pn、Rn 的表示法与 BERTScore 中的相同(Zhang et al., 2019b)。
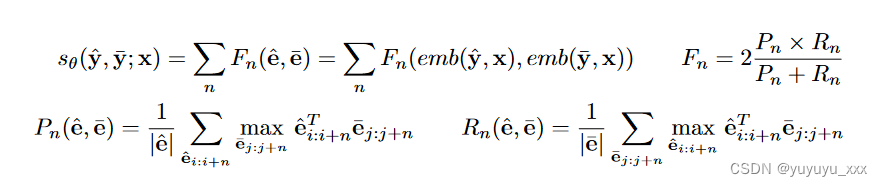
与 BERTScore 相比,我们使用模型的解码器输出表示而不是 BERT 编码器表示,并且还考虑在 n = 1,2,4,8 个标记而不是 1 的范围内进行匹配。与使用外部指标(例如 ROUGE、BERTScore)相比,这个评分函数有几个优点:(1)它增加的计算成本非常少,不需要额外的模型或图外计算; (2)它与我们评估发电系统所用的指标不同,并降低了直接优化这些不完美指标的风险(Paulus et al., 2018;Stiennon et al., 2020); (3) 它以上下文 s(ˆ y, ̄ y; x) 为条件,而不是 s(ˆ y, ̄ y) 形式的度量。
3.2 校准损失
校准损失 Lcal(θ, s; x, ̄ y, {ˆ y}m) 旨在根据模型与目标序列 s(ˆ y, ̄ y;x)。给定上下文 x、目标 ̄ y 和一组候选 {ˆ y}m,我们考虑以下 4 种损失类型。排名损失优化从 {ˆ y}m 均匀采样的正负候选对 ˆ y+, ˆ y− 的排序顺序,其中 s(ˆ y+, ̄ y; x) > s(ˆ y−, ̄ y; x)。保证金损失最大化正负候选对的序列概率差距。列表式排名损失优化候选列表的排名顺序,其中 i, j 是 ˆ yi, ˆ yj 在按 s(ˆ y, ̄ y; x) 排序的集合 {ˆ y}m 中的位置。它是 BRIO 中使用的对比损失(Liu et al., 2022)。预期奖励损失(或预期最小风险)最大化候选列表的预期相似性(Edunov et al., 2018)。
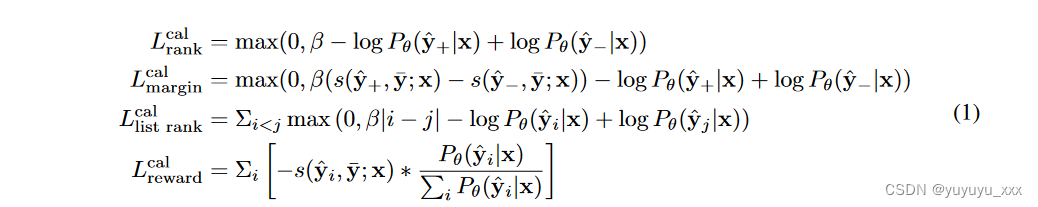
所有损失的 β 值都是根据第 3.3 节中每种损失类型的经验选择的。
3.3正则化损失
我们考虑两种替代类型的正则化损失 Lreg,以防止模型显着偏离其微调 MLE 目标:交叉熵是(Liu 等人,2022)中使用的标准微调 MLE 目标。 KL 散度直接最小化观察到的目标序列上每个标记处的校准模型和微调模型之间的概率分布距离。正则化损失都是令牌级别的。
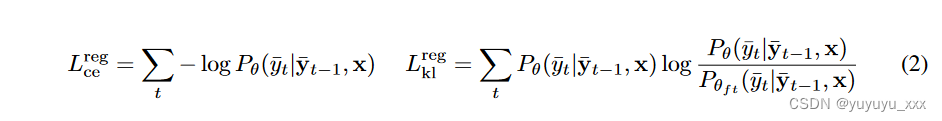
3.4 候选解码方法
我们考虑以下 SLiC 解码方法:
Beam Search 是标准的最佳优先算法,用于解决序列到序列模型中棘手的最大似然优化问题(Tillmann 和 Ney,2003 年;Li 等人,2016 年;Wiseman 等人,2016 年)。 ,2017;陈等人,2018)。
多样化波束搜索(DBS;Vijayakumar 等人,2016)通过将波束搜索预算划分为组并强制波束组之间的相异性来生成不同输出的列表。它在质量和多样性之间取得了平衡,通常是两阶段重排序系统的最佳策略(Liu and Liu,2021;Ravaut et al.,2022b;Liu et al.,2022)。
Nucleus Sampling(Holtzman et al., 2020)仅在解码的每个步骤中对累积概率 p 内的高概率令牌进行采样。它产生多样化的候选者,同时防止抽样质量非常低的候选者。
四 实验效果
4.1数据集
对于抽象摘要任务,我们选择 CNN/DailyMail (Hermann et al., 2015; See et al., 2017)、XSUM (Narayan et al., 2018)、RedditTIFU-long (Kim et al., 2019) 和 SAMSum ( Gliwa 等人,2019),因为它们在领域、风格、抽象性和摘要长度方面具有多样性。对于问答相关任务,我们选择给定上下文的生成式问答 MSMARCO NLG (Bajaj et al., 2016) 及其问题生成 SQuAD QG 的逆向问题 (Zhou et al., 2017; Du et al., 2017)。对于数据到文本的任务,我们选择给定结构化数据 WebNLG-en (Gardent et al., 2017) 和常见概念推理 CommonGen (Lin et al., 2020) 的文本生成。数据集的更多详细信息及其统计数据可以在附录 A 中找到。
4.2 对比模型
4.3实施细节
我们遵循 PEGASUS 预训练(Zhang et al., 2019a),并将 Transformer 模型大小扩展到 PEGASUSSMALL (50M)、PEGASUSBASE (200M)、PEGASUSLARGE (500M) 和 PEGASUS2B (2B)。1 与原始论文不同,我们使用句子96k 词汇量,具有字节回退(Kudo,2018),所有模型的预训练批量大小为 4096。型号尺寸请参见附录 B。在所有实验中,我们使用学习率 lr = 10−4,使用 512 的批量大小进行微调,使用 64 的批量大小来校准模型。除非另有说明,我们使用波束搜索来生成校准候选并评估校准模型。在我们的消融研究(第 3.3 小节)、效益分析(第 3.4 小节)和扩展实验(第 3.5 小节)中,我们使用预训练了 500,000 个步骤的模型,并在 4 个数据集(CNN/DailyMail、XSUM、RedditTIFU-long 和 SAMSum)上进行实验。对于消融研究和效益分析,我们使用 PEGASUSLARGE。我们报告每个数据集验证分割的 ROUGE 1/2/L (Lin, 2004)2 及其总体得分 Rm,定义为跨数据集平均的 ROUGE 1/2/L 的几何平均值,Rm = 1 4 Σ d 3 √R1R2RL。对于最终结果(第 3.6 小节),我们将 PEGASUS2B 模型预训练为 250 万步,在所有 8 个数据集上对其进行微调,使用相同的配方进行校准并报告测试分组的数字(除非另有说明)。我们对每个数据集使用相应的标准评估脚本。3
4.4评估指标
4.5 实验结果
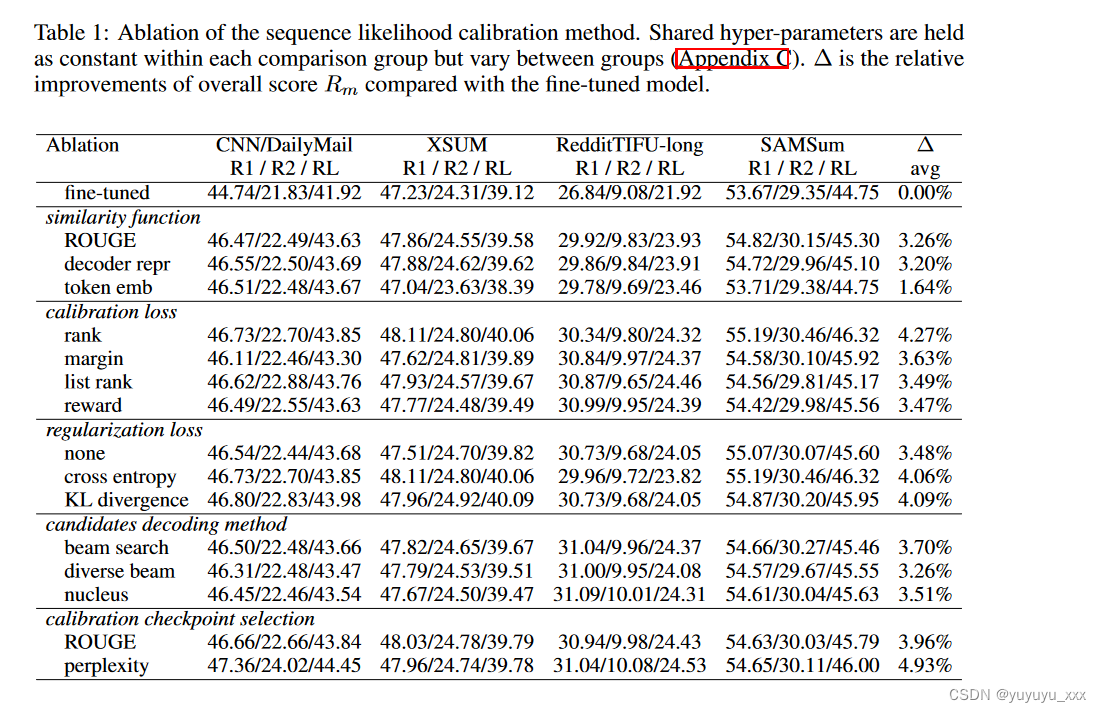
相似性函数 我们使用模型在解码器输出表示 sθ(ˆ y, ̄ y; x) 处的潜在状态(第 2.1 小节)来比较我们提出的相似性函数,以直接优化评估指标 ROUGE。即使评估指标是 ROUGE 分数,它们在所有数据集上的表现也相似。我们还通过用标记嵌入替换解码器表示 emb(y, x) 来测试相似性函数的变体。这种变体的性能较低,这表明上下文化和依赖于输入的表示的好处。
校准损失 具有所有损失类型的校准模型比仅微调模型有显着改进。排名损失表现最好,其次是利润、列表排名,然后是奖励。奖励最大化的优点是无需扫描超参数 β(公式 1),而排名和边际损失则具有较小的训练内存占用。显示最佳增益的排名损失表明候选的相对排序比它们与目标的相似度的绝对值更重要。
正则化损失 交叉熵和 KL 散度正则化的表现类似。如果移除正则化,大约还会保留 85% 的校准增益。
校准候选解码方法 我们根据验证集为校准候选解码方法选择超参数。最佳解码方法取决于数据集,但方法之间的差异很小,最差方法的增益仅为最佳方法的 90%。集束搜索产生最高的平均质量。这与两阶段重排序系统(Liu and Liu, 2021; Ravaut et al., 2022b; Liu et al., 2022)中的发现相反,两阶段重排序系统更喜欢更多样化的解码策略。
微调模型的检查点选择 我们比较了 ROUGE 选择的检查点和 perplexity 选择的检查点。实验表明,从困惑度选择的检查点开始校准可以产生相同或更好的性能,并且在 CNN/DailyMail 数据集上差距最大。
**TL;DR:**我们推荐一个简单的方法:通过验证集困惑度选择微调模型的检查点;使用波束搜索解码候选;使用排名损失和 KL 散度正则化来校准模型。
校准序列似然的好处
校准模型的质量随着解码候选数量的增加而单调提高,4 无论校准解码和评估解码方法如何,如图 2 所示。另一方面,当解码候选数增加时,仅微调模型的质量会下降。解码次数超过最佳值。一旦模型使用任一解码方法进行校准,它在评估时都会表现良好。使用波束搜索进行解码可得到更高的分数,最多可验证 20 次解码。当校准解码和评估解码方法一致时,最终质量略好于不匹配的设置。 CNN/DailyMail、XSUM 和 SAMSum 数据集与波束搜索配合使用效果最佳,但 RedditTIFU-long 与核采样配合使用效果更好,并且使用大量候选者对其进行解码可能会获得更好的结果。
校准模型不需要长度标准化。如表 2 所示,长度归一化(通常在波束搜索中实现为 α)对于在解码时偏向于较长序列的仅微调模型至关重要。相反,长度归一化对校准模型的影响最小。
校准模型的重复次数要少得多。重复率 (rep%) 衡量模型失败的常见模式。它被定义为包含任何类型的连续重复单词 n-gram 的示例的百分比。虽然长度归一化有助于仅微调模型的总体质量,但它会导致更高重复的副作用。校准模型,无论是否进行长度归一化,重复率都要低得多。当我们与黄金参考中的重复率(重复可能自然发生)进行比较时,没有长度归一化的校准模型具有相似或更低的重复率。
校准模型的缩放属性
随着模型规模的扩大,缩放特性对于预测技术的未来相关性非常重要(Kaplan 等人,2020a)。在图 3 中,我们使用波束搜索比较了不同模型大小和解码候选数量下的生成质量与推理计算。附录 F 描述了估计推理计算 FLOP 的方法。
正如前面第 3.4 节中提到的,仅微调模型具有最佳解码波束尺寸,而校准模型的性能随着解码波束尺寸的增大而单调增加。即使在贪婪解码的情况下(波束大小为 1),校准模型的性能也超过了仅微调模型,对于某些数据集(CNN/DailyMail 和 RedditTIFUlong)来说,性能大幅提高。它们的间隙随着光束尺寸的增加而变大。校准带来的质量改进幅度在模型大小从 50M 到 2B 的范围内持续存在。随着模型规模的扩大,没有明显的回报递减迹象。推理计算可用于解码,而不是用于较大的模型。经过训练的校准模型可以通过解码更多候选者来提高其性能,通常在开始时更有效,尽管回报会减少超过 10 个候选者。在某些情况下(SAMSum,尤其是 CNN/DailyMail),解码更多候选者的较小模型可以在质量和效率上击败较大模型。 TL;DR:随着模型尺寸的扩大,校准优势仍然存在。在相同的推理计算预算下,较小的校准模型可以胜过较大的模型。
最终结果
我们使用第 3.3 小节中确定的简单配方在 8 种语言生成任务上校准微调的 PEGASUS2B 模型,并使用波束搜索来评估它们,而不需要解码启发式(第 3.4 小节)。我们针对 SLiC 优化的唯一超参数是学习率 lr(附录 H)。我们对仅微调模型使用光束尺寸 5,对校准模型使用光束尺寸 10。如表 3 所示,校准模型在数据集和任务中显示出比仅微调模型的一致改进。总体而言,我们的校准模型在所有数据集上都超过或匹配 SOTA 模型。在 XSUM、SAMSum、WebNLG-en 和 CommonGen 上,我们校准的 2B 模型比 SOTA 模型小十到一百倍。
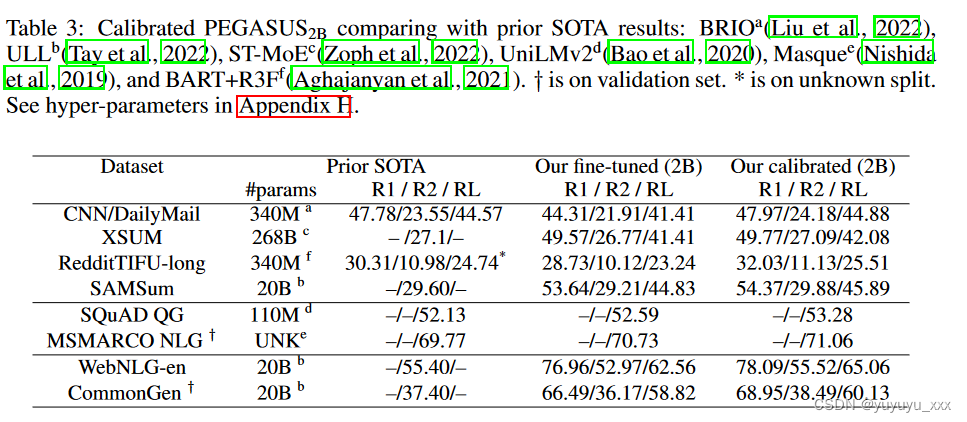
TL;DR:PEGASUS2B 使用简单的 SLiC 配方在各种语言生成任务上实现了 SOTA 结果,同时消除了解码启发式方法。
五 总结
我们建议在条件语言生成的预训练和微调阶段之后添加序列似然校准(SLiC)的第三阶段。校准过程从微调模型中解码候选序列,并继续训练,根据它们与模型潜在空间中目标序列的相似性来对齐它们的序列似然。 SLiC 的一个简单而有效的方法是通过困惑度选择微调模型的检查点,通过波束搜索解码候选,通过秩损失和 KL 散度正则化进行校准。我们能够消除校准模型的所有解码启发式方法。随着模型规模的扩大,校准的好处仍然存在。在相同的推理计算预算下,较小的校准模型可能优于较大的模型。通过校准 PEGASUS2B 模型,我们在 8 个数据集上超越或匹配了最先进的结果,涵盖抽象摘要、生成问答、问题生成和数据到文本任务。