摘要:本文整理自 Apache Flink 中文社区发起人、阿里巴巴开源大数据平台负责人王峰(莫问),在 Flink Forward Asia 2023 主会场的分享。Flink 从 2014 年诞生之后,已经发展了将近 10 年,尤其是最近这些年得到了飞速发展。在全球范围内,Flink 已经成为了实时流计算的事实标准。但是 Flink 不会止步于此。Flink 社区在用户的推动下,不断地在技术创新和技术演进中,向着未来的更多场景发展,本次分享将为大家汇报 Flink 在 2023 年的核心技术成果和技术发展的趋势。
Tips:点击「阅读原文」在线观看 FFA 2023 会后资料~
Apache Flink 全球社区持续活跃
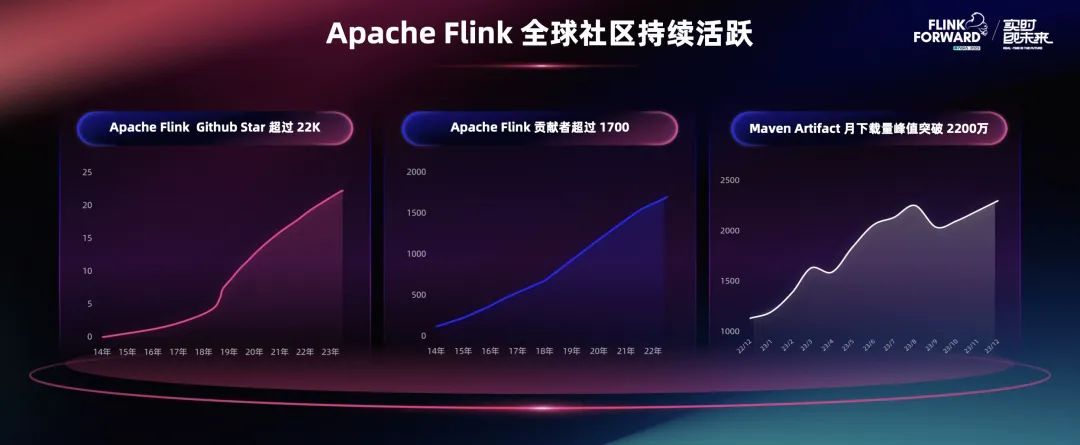
Flink 在最近十年,持续保持着稳定快速的发展。全球开发贡献者已经超过了 1700 名,贡献者来自世界各地,不仅有中国,也有欧洲、美洲等地区,大家共同推动 Flink 社区发展。同时,Flink 下载量也创下新高。今年,月下载量突破了 2200 万次,更多的使用者、企业下载 Flink,应用于学习、测试和生产,进行实时数据处理。
Apache Flink 斩获
SIGMOD 2023 系统大奖

今年年中,Flink 团队也获得了SIGMOD 2023 系统大奖。SIGMOD 是整个数据处理领域中的顶级会议,也是最有权威性的会议之一。SIGMOD 每年都会评选出一项在全球工业界得到广泛使用和验证的创新性系统技术,授予其系统大奖。今年 SIGMOD 将大奖授予了Apache Flink,以表彰 Flink 在全球范围内实时流处理领域的领先地位和广泛应用。这再一次验证了 Flink 不仅在中国,也在全球范围内得到了认可,成为事实上的流计算标准。
上图获奖名单中,可以看到一条特殊的风景线,几乎 50%都是来自于华人。华人开发者突出的贡献,推动了社区的发展。
Apache Flink 中文社区五周年

中国开发者愿意加入社区、推动 Flink 的发展。可以说 Flink 是一款由华人工程师主导的全球性开源大数据项目。Apache Flink 中文社区是于 2018 年成立的本土化社区。社区创建初衷旨在推进 Flink 在中国的社区发展和技术普及。国内各大公司都参与了建设,包括腾讯、快手、字节、美团等,推动了 Flink 中文社区的快速发展。Flink Forward Asia(以下简称 FFA)也是中文社区的重要产物,从 2018 年开始,阿里云承办 Flink Forward 大会,并保持每年一次 FFA 峰会。通过丰富的社区活动和众多的内容贡献,我们积累了非常多的 Flink 学习材料,供开发者学习和使用。
Apache Flink Major Releases in 2023
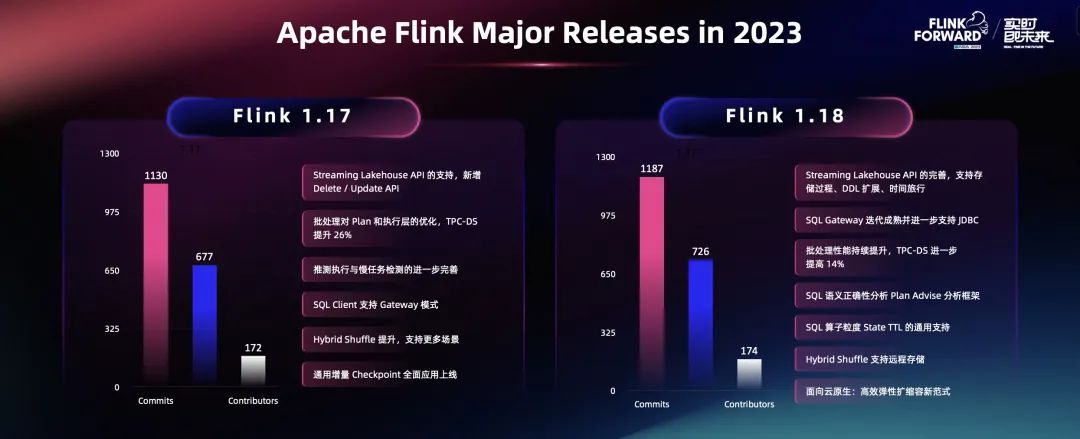
Flink 作为开源大数据领域的常青树,这些年一直保持快速发展。除了踊跃的社区贡献者和持久化运营支撑之外,最核心的推动力,是它的技术本质。Flink 社区在技术核心领域不断演进,每年都能推出各种新特性、新创新,给用户带来新的业务价值,使得用户愿意使用、贡献、推动它的发展。
下面我汇报一下 Flink 在 2023 年团队所取得的核心技术进展:
Flink 社区依然保持了一年两个大版本的发布,上半年 Flink 1.17 和下半年 Flink 1.18 两个大版本。在这两个版本中,社区依然产生了很多新的贡献者。在核心的流处理领域内,Flink 开发团队精益求精,根据用户诉求和业务场景进行打磨、完善。在流批一体的计算领域,我们持续完善了 Flink 在批处理模式下的性能问题和功能完善性问题,使 Flink 能够成为一款真正在有限数据集和无限数据集都能够统一处理的优秀计算引擎。
此外,在场景上,我们也持续创新。Flink 希望能够处理更多的数据,让更多的数据能够流动起来。所以我们让 Flink 跟 Lakehouse 架构产生合作协同的效果。Lakehouse 架构已经成为了现在数据分析领域的新架构趋势,越来越多的用户将传统的基于 Hive 的数仓体系转移到 Lakehouse 架构上。我们希望基于 Flink 实时计算能力可以加速 Lakehouse 数据流动和数据分析效果。
在部署架构上,我们在 Flink 社区也做了非常多的工作,推动 Flink 在云上更好的运行。Cloud Native 现在不仅是大数据,也是包括 AI、数据库、各种计算系统的新底座,越来越多的项目、软件都必须要能够很好的运行在云上,去给用户更好的体验。
Streaming SQL 精益求精、持续完善

我挑选了 Flink 社区在 2023 年这两个大版本中非常有价值的技术特性,给大家做一个解读。首先,在最核心的 Streaming 计算领域,我们做了哪些重要升级?
Streaming SQL 是用户最关注的,也是用户用得最多的,给用户最直接的体感。Flink SQL 功能强大。使用 Flink SQL 可以实时分析各种流式数据。今年我们对 Flink SQL 做了非常多的改进。可以看到有数百个 issue 在围绕着 Flink SQL,有 40 多名新的贡献者在贡献 Flink SQL,比如说今年新推出了一个新特性,叫 Plan Advice,帮助用户智能检查 Streaming SQL,发现潜在的语义上的风险等,第一时间给用户进行提示,告诉用户 SQL 可能写得不够好,存在一定风险和潜在的未知情况,并且给出可行建议。避免在运行时出现不确定性因素和不稳定情况,这些都是非常实用的功能。
此外 SQL 的用户还有很多需求,希望能够 SQL 更加灵活,是像 DataStream 一样,Flink 早期都是用 Java 等语言来写,DataStream 数据有很多灵活的功能,我们也希望把它推进到 SQL 中,让 SQL 的用户也能够在简化开发的同时,享受到这些系统灵活性。比如像 Watermark 更加灵活的管理,基于算子级别的 STATE TTL 配置等。同时,我们在 SQL 的基础框架 Calcite 进行了大幅升级,让整个 SQL 的 Plan 优化能力更强,效果更好。
通用增量 Checkpoint 全面应用上线

我们在 Stream 核心架构上做了比较大的升级工作。Flink 的最大特点是面向状态的计算。它自带状态存储和状态访问能力、状态管理 Checkpoint 快照管理等,这些都是 Flink 非常核心的部分,用户在这块儿也有很强诉求。Flink 定期会做全局一致性快照,快照的频率越快越好,代价越小越好,这样可以让系统在出现容错的时候,尽量少的数据回放。比如说做到秒级的 Checkpoint 是非常好的效果。因此,我们努力将它落地,通用增量 Checkpoint 能力在 Flink1.17 和 1.18 落地,并且达到了完全生产可用的状态。国内非常多的公司开始在大规模生产使用这项新的技术。这些技术也是基于 log 的能力,进行 log 打点的方式进行推广,框架因为是必要基于 log 打点 Checkpoint 能力,工作是比较轻量的,所以它可以快速地实现 Checkpoint。同时架构将 Checkpoint 和状态数据的物化进行解耦。这样天然就打散了各个 Task 数据 IO 的时间点频率。这样整个系统就没有瞬间的波动,系统会变得更加平滑。因此,实现了整个 Checkpoint 又快又平滑的效果。
Flink Batch – 日益成熟,生产可用

在 Batch 方面,我们也做非常多的工作,Flink 作为一款流批一体引擎,我们希望它具备更加全面的计算能力,给用户带来一站式的数据计算和数据开发体验。总体来说, Batch 完善更多一点,因为 Batch 相关工作,Flink 启动得较晚一些,不像 Streaming 已经非常完善了,但是我们经过今年的努力,把用户的需求进行了落地。无论从功能上,还是从系统稳定性上,还是从用户易用性角度,我们把这些事情都已经做在了 Flink 生态的版本中,现在 Flink 已经具备了真正达到业界主流 Batch 引擎的能力。
今天,可以看到很多公司来分享 Flink 能力如何在生产中发挥的效果。此外,我们一直对 Batch 引擎做了很多的性能优化,不仅基于核心的流引擎的这种优势,去优化 Batch 场景下的执行效率。同时,我们也将传统 Batch 上的一些优化的手段都在 Flink 里进行了实现。
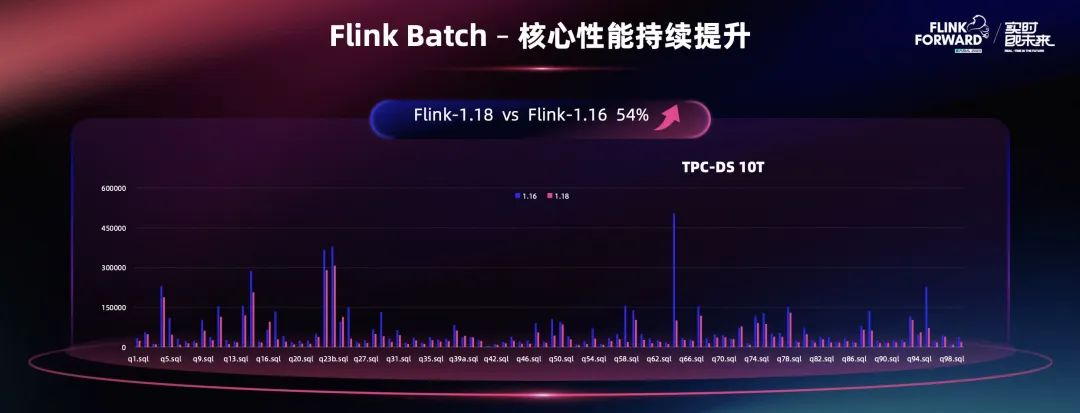
总体来说,Flink Batch 在功能、性能方面都非常完善了。通过 Batch 模式下,在 TPC-DS 10T 的 Benchmark 的测试项目中可以看到,Flink 1.18 相比 Flink 1.16 拿到了 50%以上的性能优化结果。每年持续性能优化下,让 Flink 不仅在流计算领域达到业界的最强水平,在 Batch 领域也可以达到一流的执行能力。Flink 正逐渐成为功能最全面、综合性能最好的计算引擎。
高效弹性扩缩容新范式
进一步走向云原生
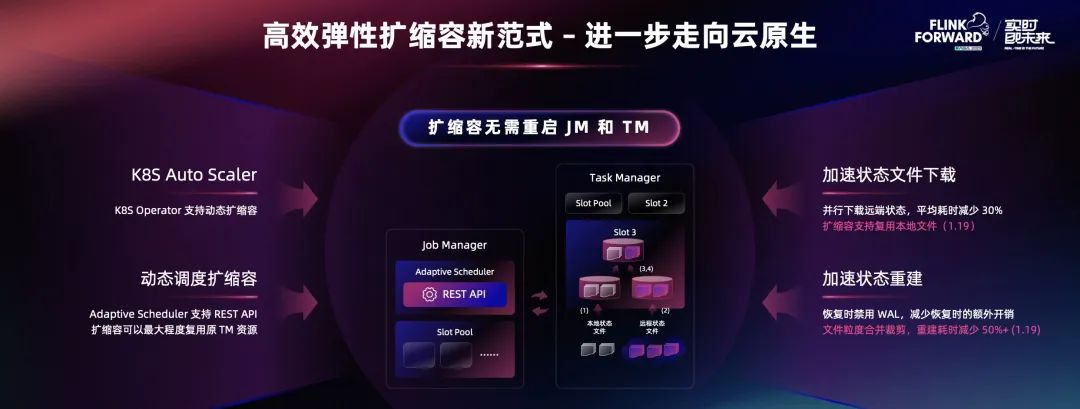
除了 Flink 核心引擎技术进展之外,我们在云原生分布式部署架构上也做了非常多的完善。随着越来越多的计算负载迁移到云上,大家特别在意云上运行体验。云上最大的特点是弹性特别好,云计算提供了无限的资源,用户可以根据自己业务负载,动态选择用多少资源满足业务需求。Flink 也在今年做了很多工作去适应新的运行架构。
比如,我们通过开放 API,支持用户可以在线实时进行扩缩容,Schedule 任务更改并发度,Flink 调度器可以不重启整个 Job,而只是在内部去调整它的并发度,对用户的体感是非常友好。State Backend 在过程中,进行了全程配合。状态数据可以更快的恢复、下载、复用,保证端到端的过程非常迅速和轻量。此外,我们知道自动扩缩容过程不可能完全靠人工来去操作触发,因为业务的变化,并没有特别强的规律,而且频率具有不确定性,因此,我们希望它自动完成。我们推出了基于 K8S Operator 的 AutoScale 技术去动态、实时地监控整个任务负载。任务延迟性根据这些实时指标自动的、动态地调整并发度。结合引擎能力可以实现全程无人值守的弹性扩缩,以此更好的利用云的特性,来服务业务。
Flink 在加速融入 Lakehouse 新架构

Flink 在新业务场景下,我们也做了非常多的尝试。其中,最大的一个创新,是让 Flink 和 Lakehouse 有更好的融合、集成。Lakehouse 是新一代的数据分析架构,Flink 是一款最好的实时计算引擎。基于两者的结合, Flink 能够发挥价值,让整个 Lakehouse 数据运行流动得更快。我们在今年两个大的版本中也加入了很多新的 API 对 Lakehouse 进行支持。通过这些新的 API,可以更好的去利用 Flink 管理 Lakehouse,更好的对接了 Lakehouse 中的湖存储格式,更好的去读写 Lakehouse 的数据。同时,Flink 也增加了对 JDBC Driver 的能力支持。开发者使用传统 BI 工具都可以跟 Flink 进行无缝衔接,利用 Flink 更好的分析 Lakehouse 数据。
大数据业务从离线向实时加速升级

近些年来,Flink 每年都会做出很多技术创新和技术架构的升级,去满足用户的需求。Flink 一直在遵循着一个新的趋势:大数据的业务场景正在因离线向实时加速升级而转换。在大的浪潮下,Flink 的每一项工作都能够得到验证,不断满足用户价值。我们可以看到越来越多的行业,如互联网、金融、制造业、交通等都开始这样的演进,各种各样的数据分析场景都开始从离线向实时进行升级,更进一步地发挥出数据价值。
Flink Forward Asia 2023
本届 Flink Forward Asia 更多精彩内容,可点击「阅读原文」或扫描图片二维码观看全部议题的视频回放及 FFA 2023 峰会资料!

关注 Apache Flink 公众号,回复 FFA 2023 即可获取 FFA 2023 会后资料查看地址
▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,在线观看 FFA 2023 会后资料~
点击「阅读原文」,在线观看 FFA 2023 会后资料~