1 已知可能影响对话效果的参数(位于configs/model_config.py文件):
# 文本分句长度
SENTENCE_SIZE = 100# 匹配后单段上下文长度
CHUNK_SIZE = 250
# 传入LLM的历史记录长度
LLM_HISTORY_LEN = 3
# 知识库检索时返回的匹配内容条数
VECTOR_SEARCH_TOP_K = 5
# 知识检索内容相关度 Score, 数值范围约为0-1100,如果为0,则不生效,经测试设置为小于500时,匹配结果更精准
VECTOR_SEARCH_SCORE_THRESHOLD = 0
其中可能对读取知识库影响较大的变量有CHUNK_SIZE(单段参考上下文的长度),VECTOR_SEARCH_TOP_K(知识库参考文段数量),和VECTOR_SEARCH_SCORE_THRESHOLD(知识库匹配内容需要达到的最小相关度)。本实验将通过向不同参数配置下的模型进行提问并对不同模型对各个问题的回答进行排名。最后,我们实验Friedman检验和Nemenyi后续检验分析不同模型的回答排名是否具有显著差别。
2 设计提问问题
模型的知识库使用书籍《深度学习入门:基于Python的理论与实现》作为知识库。对模型的提问涵盖一下类型:
知识型(K - knowledge):关于深度学习的一般知识,不一定需要依靠知识库内容回答,但是知识库提高的参考答案
内容型(C - context):关于书中具体内容的提问,必须依靠知识库才能回答
问题同时还可以分为以下两类:
普遍型(G - general):关于笼统的概念性知识问题,或者要求总结书中部分内容
细节型(S - specific):关于深度学习知识或书中内容技术细节进行提问
每一个问题都利用下面两个分类进行描述,例如KG代表知识普遍型问题,如“什么是深度学习”,CS代表内容细节型问题,如“书中手写数字识别示例使用了什么数据集作为训练数据集”。我们对每一分类设计5个问题,一共对模型提问20个问题。
设计问题
KG:
1 什么是深度学习
2 什么是神经网络
3 什么是卷积神经网络
4 简单介绍神经网络反向传播法
5 什么是神经网络的过拟合,如何避免过拟合
CG:
1 本书主要介绍了哪几种神经网络
2 书中介绍了哪几种更新神经网络参数的方法
3 书中介绍了哪几种常用的激活函数
4 书中介绍了哪几种设置神经网络权重初始值方法
5 书中介绍了哪几种抑制过拟合的方法
KS:
1 为什么神经网络权重初始值不能全部设为0
2 为什么计算权重梯度一般使用反向传播而不是数值微分
3 为什么只有非线性激活函数可以加深网络层数
4 卷积神经网络的卷积层和池化层分别有什么作用
5 为什么训练数据集和测试数据集要分开
CS:
1 书中建议解决分类问题的神经网络输出层使用什么激活函数
2 书中手写数字识别的示例程序使用什么数据集作为训练数据集
3 为什么书中手写数字识别的示例程序要对输入数据集进行批处理
4 书中讲到了batch normalization有哪些优点
5 书中讲到了哪些容易出现过拟合的条件
对于每一类问题,我们按照以下标准进行排名:
K问题:
1 答案正确性:模型的回答是否存在知识型错误
2 引用相关度:模型引用的原文内容是否和答案相关
C问题:
1 内容全面性:模型是否正确复述了书中全部的相关内容
2 原文契合度:模型是否编造和书中没有提到的内容(无论编造的部分是否正确)
3 引用相关度:模型引用的原文内容是否和答案相关
3 实验步骤
1 修改模型配置文件中的相关参数,启动langchain-ChatGLM的webui.py程序打开在线提问界面
2 在提问界面中,选择传入《深度学习入门:基于Python的理论与实现》pdf文件作为知识库。
3 将上面设计的20个问题依次传入模型,并保持模型的完整回答和原文引用保存
4 在不同参数配置下重复1-3步骤
实验组:
1 VECTOR_SEARCH_SCORE_THRESHOLD对对话效果影响
序号 CHUNK_SIZE VECTOR_SEARCH_TOP_K VECTOR_SEARCH_SCORE_THRESHOLD
1 250 5 0
2 250 10 0
3 500 5 0
4 250 5 500
回答得分

数据分析:
在使用Friedman检验和Nemenyi后置检验后(具体分析见excel文件模型对话打分)。四个模型在回答全部类型问题上的能力没有显著差别(p-value = 0.8368)




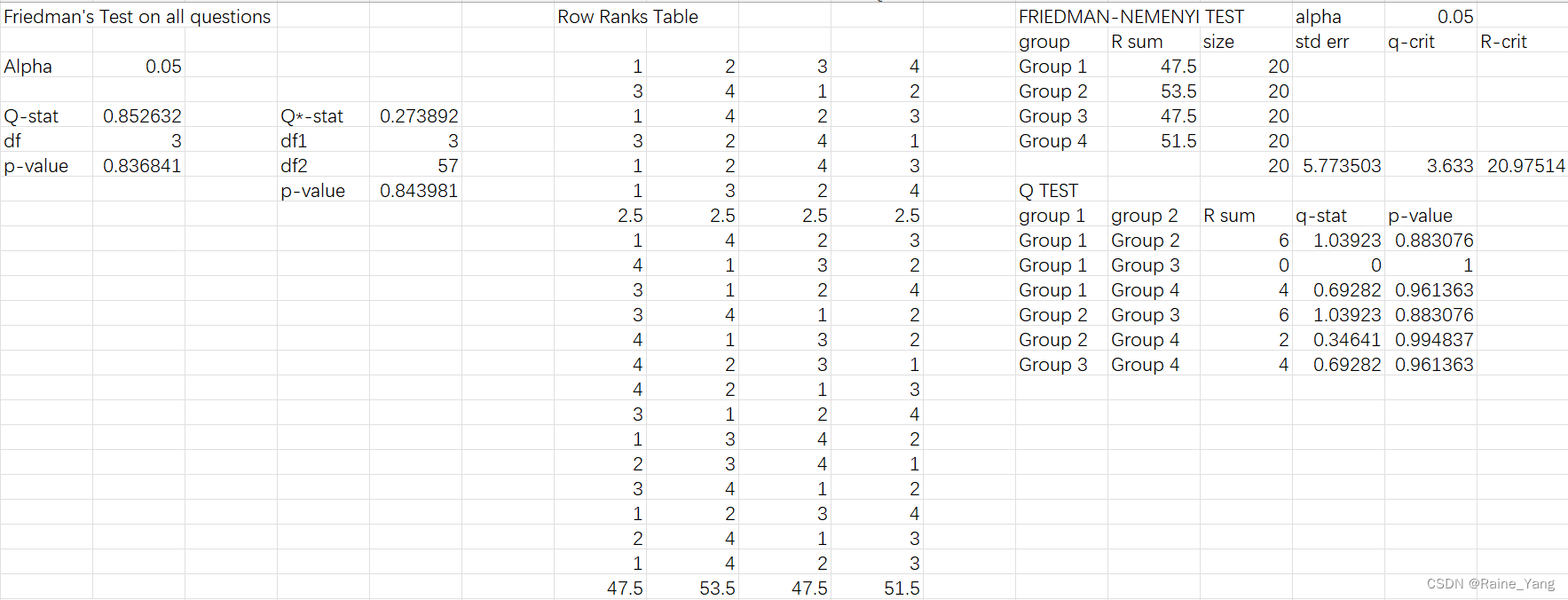
对于四个分类问题的回答(知识型,内容型,普遍型,细节型),四个模型答案依然没有显著差别。值得注意的是对于内容型问题,四个模型见差距较大,并且模型1和模型2,模型和模型3有较大的组间差距。但是这些差距在统计上不具有显著性(整体p-value=0.233, 模型1和模型2 Q test p-value=0.350,模型2和模型3 Q test p-value=0.350).
实验结论和参数调优建议:
langchain-ChatGLM模型结合本地知识库回答答案会受到CHUNK_SIZE, VECTOR_SEARCH_TOP_K,VECTOR_SEARCH_SCORE_THRESHOLD参数影响。但是这些参数变化对模型回答的总体准确性不具有显著影响。
另外值得注意的是,在第2,3组实验中,较高的CHUNK_SIZE和VECTOR_SEARCH_TOP_K使得模型回复内容明显较长,使得模型对服务器显存消耗明显增大。(在1,4组实验中显存一般会在15个问题左右时爆满,而在2,3组中只需要1到2个问题)。在实际应用中,这两个参数应该适当选取较低值,或者直接使用默认的初始值250和5
本实验可能存在以下漏洞:
1 在选择知识库数据时只使用了《深度学习入门:基于Python的理论与实现》这一本书进行测试。没有对大规模知识库进行测试,也没有测试在同一知识库传入不同题材文本是否会对模型进行干扰
2 LLM的回答完全由我个人打分排序,根据我本人对相关知识点和书中对应内容回忆以评分,具有一定主观性。另外由于无法进行双盲实验,我对不同模型的预期可能会对打分产生误差。
3 LLM回答会对历史对话进行参考。由于如果每一次问答都重启模型过于耗时耗力,本实验中只有在模型显存爆满时才会终止本轮对话,这使得模型的历史问题可能对模型回答有影响。
住:完整对话内容过长(差不多有10万字),没法在文章里展示出来