2.1 实验目的
加深对计算机流水线基本概念的理解;
理解MIPS结构如何用5段流水线来实现,理解各段的功能和基本操作;
加深对结构冲突/数据冲突/控制冲突的理解;
进一步理解解决数据冲突的方法,掌握如何应用定向技术来减少数据冲突引起的停顿,并加深对指令调度技术和延迟分支技术的理解;
2.2 实验平台
实验平台采用指令级和流水线操作级模拟器MIPSsim。
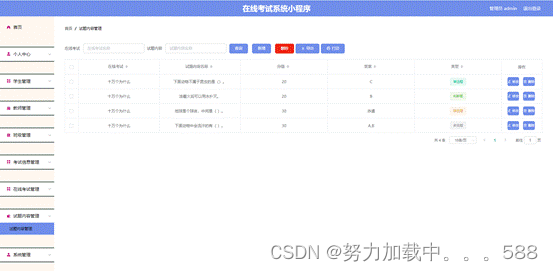
2.3 实验内容
阅读理解课件第3章的“3.4节 流水线的相关与冲突”(97屏-127屏)。
1)启动MIPSsim,选择“配置->流水方式”选项,使模拟器工作在流水方式下。
2)观察分析结构冲突对CPU性能的影响:
加载样例程序structure_hz.s,执行该程序(用连续执行方式)。分析结构冲突的原因,记录结构冲突引起的停顿时钟周期数。(注:模拟器中浮点加法执行段时间默认6个周期)
把浮点加法器的个数改为6个(配置->常规配置->浮点加法器个数 改为6),再重复上一步的工作。总结解决结构冲突的方法。

结构冲突:在流水线处理机中,某种指令组合因为资源冲突而不能正常执行。
导致此结构冲突的原因:资源份数不够。
在该流水线中,只有一个加法器,导致下一条指令在第三周期执行加法操作时,加法器被第一条加法指令占用,此时只能等待第一条指令加法操作执行完毕让出加法器。

可见结构冲突引起的停顿时钟周期数为35。
而当我们将浮点加法器的个数改为6个时,再次执行程序。
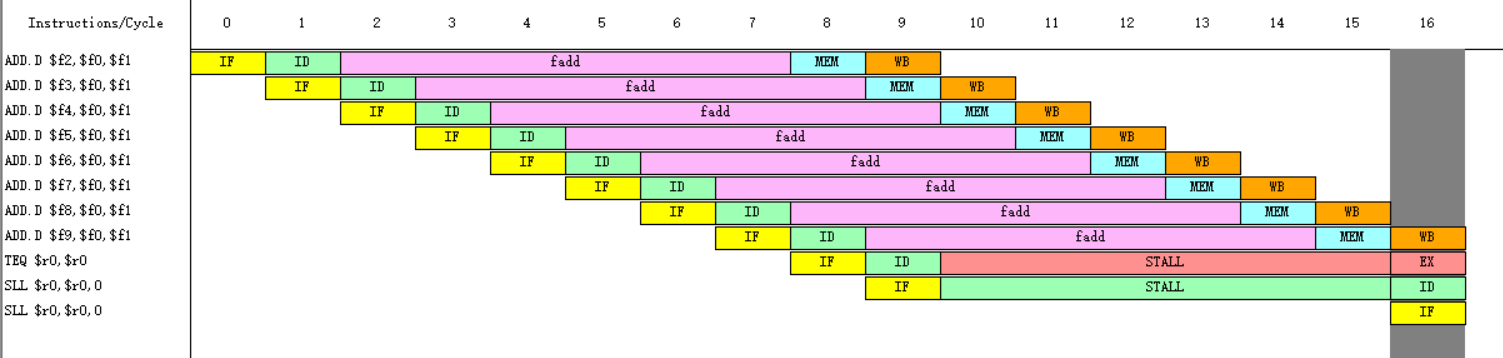

可见结构冲突引起的停顿时钟周期数为0,成功解决了结构冲突问题。
3)观察数据冲突并用定向技术来减少停顿:
数据冲突:当相关的指令彼此靠得足够近时,它们在流水线中的重叠执行或者重新排序会改变指令读/写操作数的顺序,使之不同于它们串行执行时的顺序,则发生了数据冲突。
(a)
全部复位,加载data_hz.s,关闭定向功能(“配置->定向”无对勾),单步执行该程序,查看时钟周期图,记录分析在什么时刻发生了RAW(写后读)冲突(只需运行到第一条分支指令BGTZ $r4, loop执行完)。记录数据冲突引起的停顿时钟周期数(可在统计窗口查看到)。
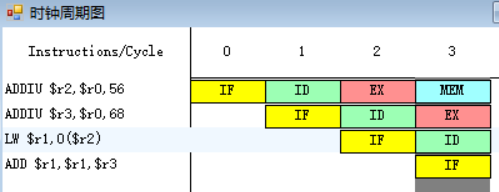
1.

![]()

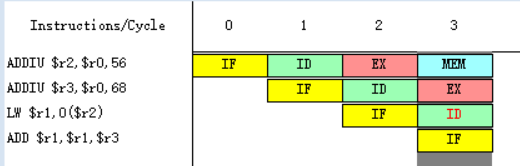
因为指令LW在第三个周期需要读取r2寄存器中的数据,而第一条指令ADDIU在第四周期才会进行到写回周期WB,在第四周期前半将相加后的结果写入r2之中,所以LW指令需要等到第四周期才能执行指令译码/读寄存器周期ID,在第四周期后半读r2寄存器中的数据。
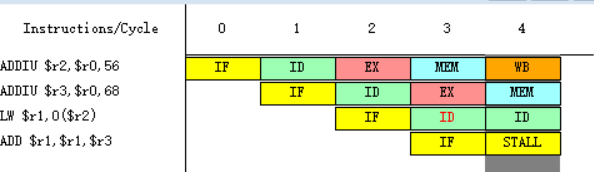
2-3.


![]()
因为指令ADD在第五个周期需要读r1寄存器中的数据,而指令LW在第七周期才会进行到写回周期WB,在第七周期前半将值写入r1之中,所以ADD指令需要等到第七周期才能执行指令译码/读寄存器周期ID,在第七周期后半读r1寄存器中的数据。
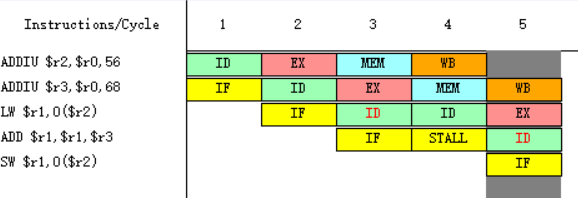
4-5.

![]()

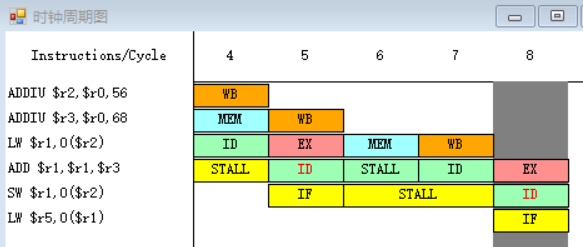
因为指令SW在第八个周期需要读r1寄存器中的数据,而指令ADD在第十周期才会进行到写回周期WB,在第十周期前半将值写入r1之中,所以SW指令需要等到第十周期才能执行指令译码/读寄存器周期ID,在第十周期后半读r1寄存器中的数据。
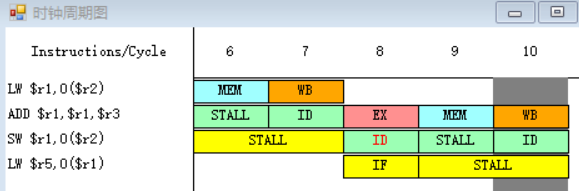
6-7.



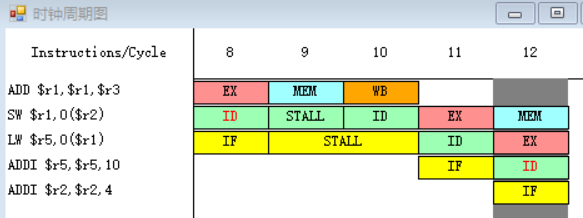
因为指令ADDI在第十二个周期需要读r5寄存器中的数据,而指令LW在第十四周期才会进行到写回周期WB,在第十四周期前半将值写入r5之中,所以ADDI指令需要等到第十四周期才能执行指令译码/读寄存器周期ID,在第十四周期后半读r5寄存器中的数据。
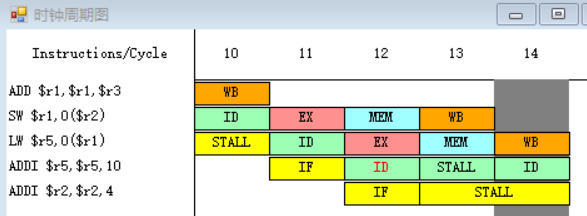
8-9.




因为指令SUB在第十六个周期需要读r3、r2寄存器中的数据,而指令ADDI在第十八周期才会进行到写回周期WB,在第十八周期前半将值写入r2之中,所以SUB指令需要等到第十八周期才能执行指令译码/读寄存器周期ID,在第十八周期后半读r2寄存器中的数据。
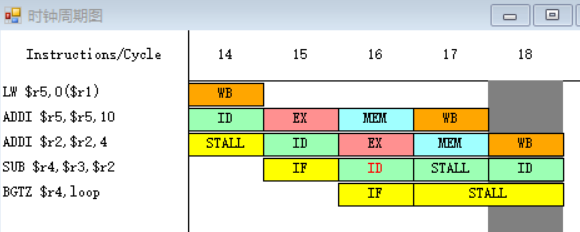
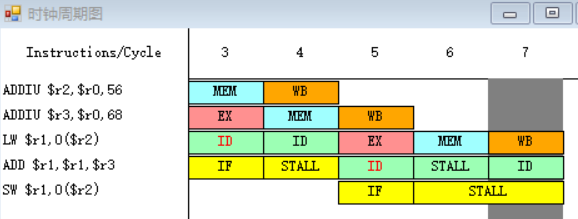
10-11.


![]()
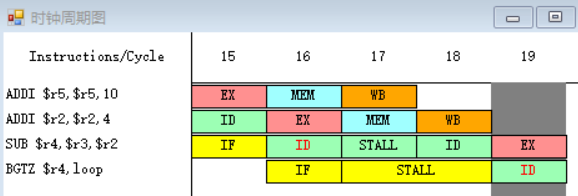
因为指令BGTZ在第十九个周期需要读r4寄存器中的数据,而指令SUB在第二十一周期才会进行到写回周期WB,在第二十一周期前半将值写入r4之中,所以BGTZ指令需要等到第二十一周期才能执行指令译码/读寄存器周期ID,在第二十一周期后半读r4寄存器中的数据。
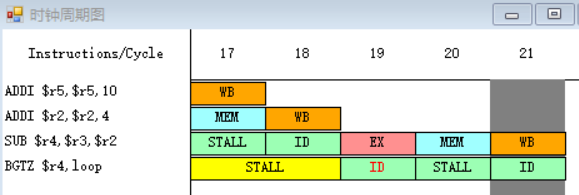
12.
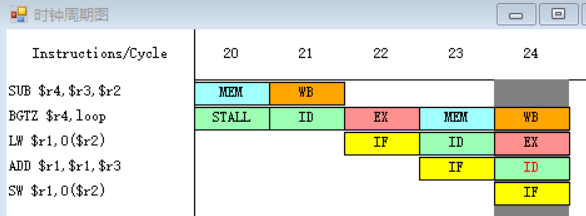
同2-3.
总结
可以看到,RAW停顿在第0-24周期之间一共发生了12次。

(b)
打开定向功能,单步执行,查看时钟周期图,分析定向功能使用后减少了多少数据停顿,分析每一处定向为何要如此实现,并分析在什么时刻还有RAW停顿未消除,原因是什么(只需运行到第一条分支指令BGTZ $r4, loop执行完)。
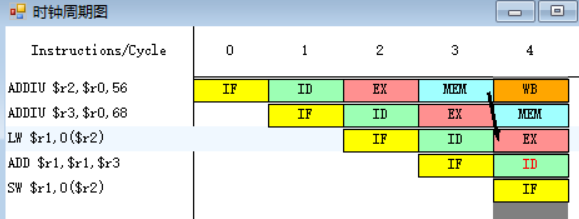
原1.

![]()

指令LW在第三个周期需要读取r2寄存器中的数据,而第一条指令ADDIU在第三周期MEM段执行完之后,MEM段和WB段之间的流水寄存器中保存的数值将会被送至LW指令的ALU的入口处,减少了停顿的发生。
原2-3.(1.-load停顿)


![]()
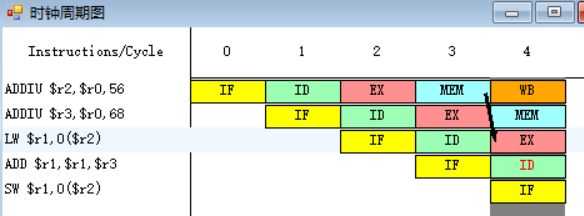
因为指令ADD在第四个周期需要读r1、r3寄存器中的数据,而指令LW在第五周期访存周期MEM才会得到r1中的结果,所以ADD指令需要等到第五周期才能执行指令译码周期ID。
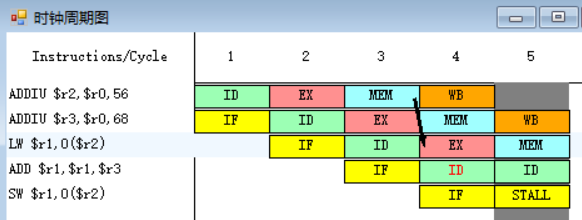
可以看到,指令LW在第五周期MEM段执行完之后,MEM段和WB段之间的流水寄存器中保存的数值将会被送至ADD指令的ALU的入口处,减少了停顿的发生。

原4-5.
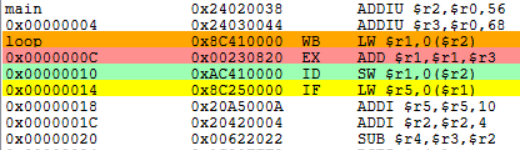
![]()

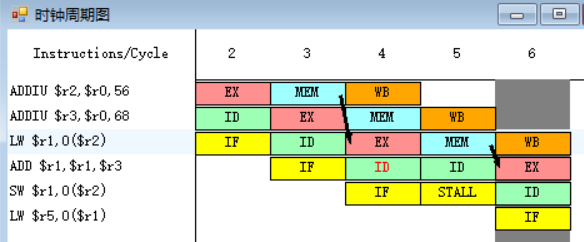
指令SW需要将寄存器r1中的数值存入存储器中,指令ADD在第七周期MEM段执行完之后,MEM段和WB段之间的流水寄存器中保存的数值将会被直接送至SW指令的MEM段的入口处,减少了停顿的发生。
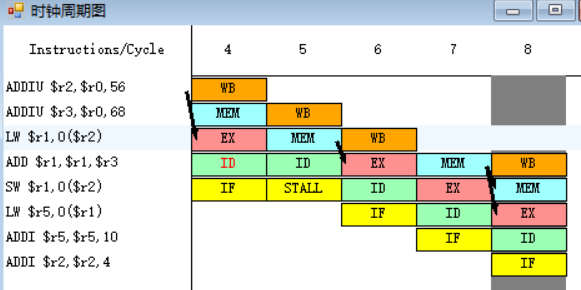

另外,LW指令需要从寄存器r1中取出数值,指令ADD在第七周期MEM段执行完之后,MEM段和WB段之间的流水寄存器中保存的数值也会被直接送至LW指令的EX段的入口处,减少了停顿的发生。
原6-7.(2.-load停顿)



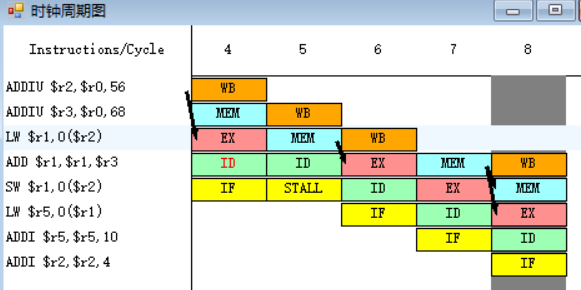
指令ADDI需要取出r5中的值,指令LW在第九周期MEM段执行完之后,MEM段和WB段之间的流水寄存器中保存的数值将会被直接送至ADDI指令的EX段的入口处,所以ADDI指令需要等待一个周期。
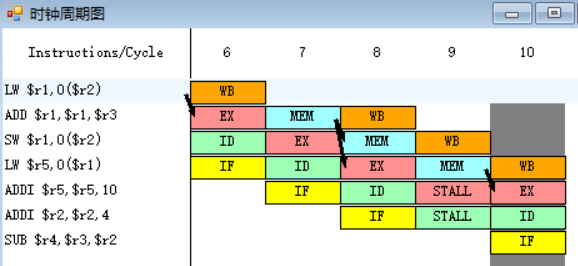
原8-9.



指令SUB需要取出r3、r2中的值,指令ADDI在第十一周期EX段执行完之后,EX段和MEM段之间的流水寄存器中保存的数值将会被直接送至SUB指令的EX段的入口处,减少了停顿的发生。
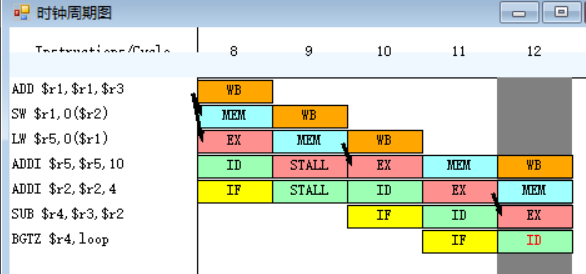
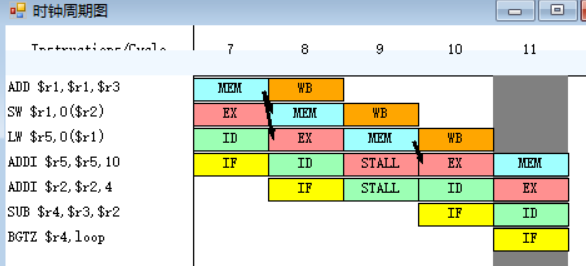
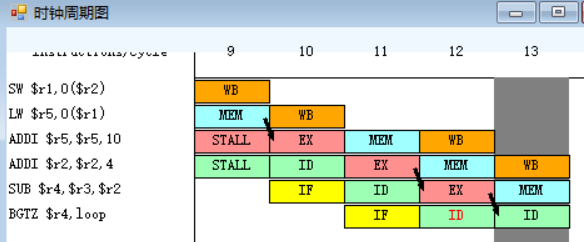
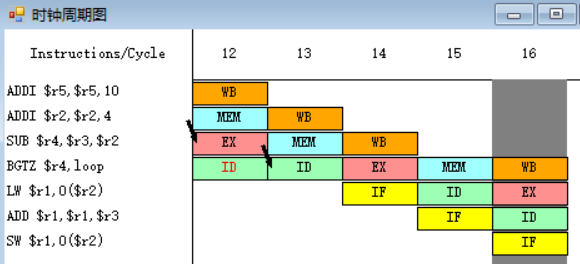
原10-11.(3.)


![]()
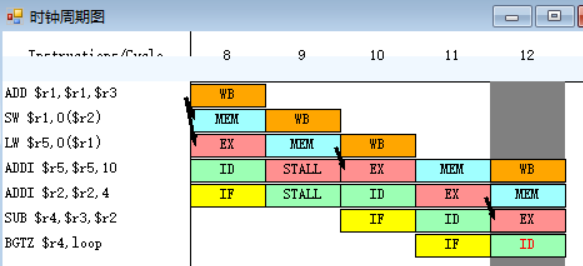
指令BGTZ需要取出r4中的值,并将其与0作比较,指令SUB在EX段执行完之后,EX段和MEM段之间的流水寄存器中保存的数值将会被直接送至BGTZ指令的ID段的入口处,所以BGTZ指令需要等待一个周期。
总结
可以看到,定向功能减少了9次数据停顿,一共发生了三次RAW停顿,其中有两次为load停顿。
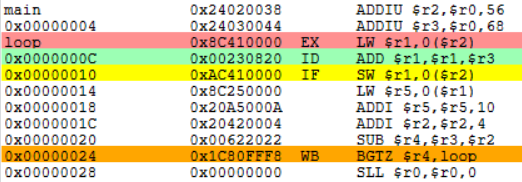

- 用指令调度技术解决流水线中的数据冲突:
全部复位,在MIPSsim中载入schedule.s样例程序。
(a)
打开定向功能,执行该程序(用连续执行方式),分析哪几个地方还有数据冲突(停顿),记录程序执行的总时钟周期数。

连续执行之后可以看到,一共发生了三次RAW停顿。
1.



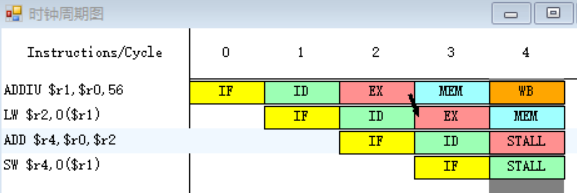
指令ADD需要取出r0、r2中的值,指令LW在第四周期MEM段执行完之后,MEM段和WB段之间的流水寄存器中保存的数值将会被直接送至ADD指令的EX段的入口处,所以ADD指令需要等待一个周期。
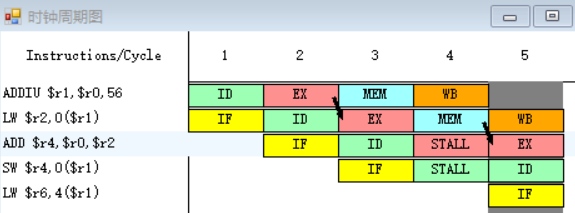
2.



指令ADD需要取出r6、r1中的值,指令LW在第八周期MEM段执行完之后,MEM段和WB段之间的流水寄存器中保存的数值将会被直接送至ADD指令的EX段的入口处,所以ADD指令需要等待一个周期。
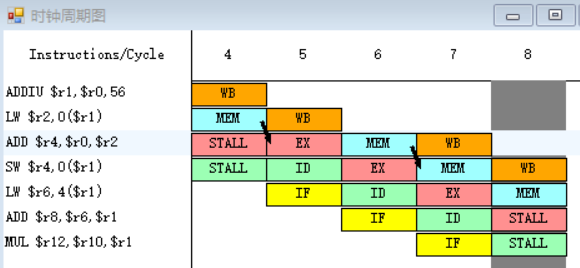
3.



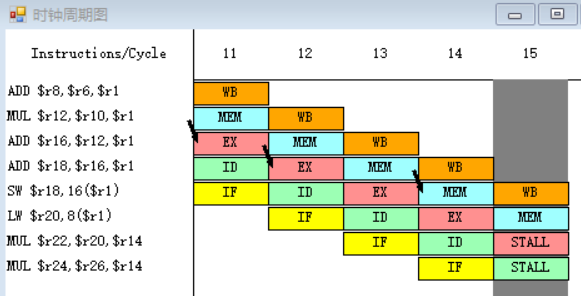
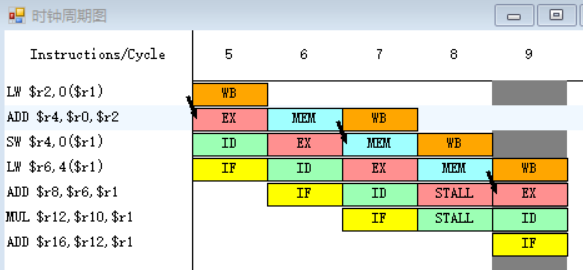
指令MUL需要取出r20、r14中的值,指令LW在第十五周期MEM段执行完之后,MEM段和WB段之间的流水寄存器中保存的数值将会被直接送至MUL指令的EX段的入口处,所以MUL指令需要等待一个周期。
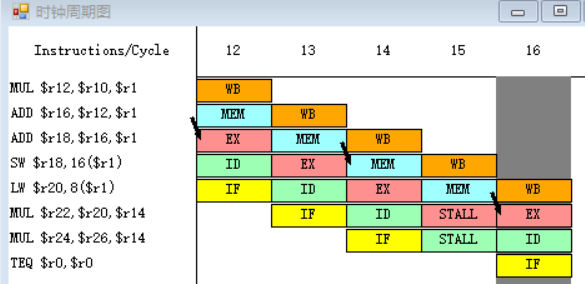
总结
程序执行的总时钟周期数为20。
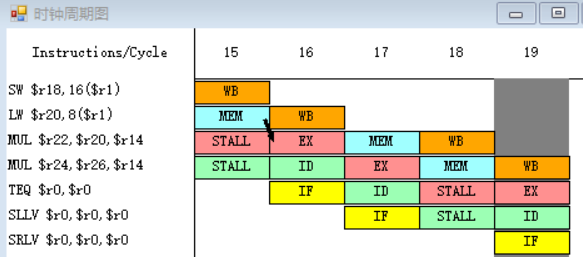

(b)
自己采用调度技术对schedule.s程序进行指令调度(自己修改源程序),完全消除数据冲突。将调度(修改)后的程序重新命名为afer-schedule.s。
afer-schedule.s:
.text
main:
ADDIU $r1,$r0,A
LW $r2,0($r1)
SW $r4,0($r1)
ADD $r4,$r0,$r2
LW $r6,4($r1)
MUL $r12,$r10,$r1
ADD $r8,$r6,$r1
ADD $r16,$r12,$r1
ADD $r18,$r16,$r1
SW $r18,16($r1)
LW $r20,8($r1)
MUL $r24,$r26,$r14
MUL $r22,$r20,$r14
TEQ $r0,$r0
.data
A:
.word 4,6,8
(c)
CPU复位,载入afer-schedule.s,执行该程序,记录程序执行的总时钟周期数。
指令调度前:


指令调度后:
连续执行,可见已完全消除数据冲突,时钟周期数为17,相比指令调度前执行周期总数少了3。

总结
指令调度可以通过在编译时让编译器重新组织指令顺序来消除冲突。仅改变了指令执行的顺序,使得本来需要等待的指令后执行,在不影响整体程序的执行结果的同时让无需等待的指令先执行,使得后执行的指令无需等待,达到了减少数据冲突的目的,使指令的平均执行周期减少了,性能因此而提高了。
5) 用延迟分支技术(延迟槽)减少分支指令对性能的影响:
(a)
全部复位,在MIPSsim中载入branch.s样例程序,关闭延迟槽功能,执行该程序(用连续执行方式),记录发生分支延迟的时刻,记录该程序执行的总时钟周期数。



连续执行之后可以看到,一共有两条分支指令,其中分支成功1条,分支失败一条。共发生两个周期的控制冲突。执行周期总数为38。
1.
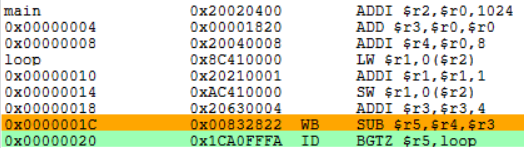
![]()

一旦流水线的译码段ID检测到分支指令(第17周期),就暂停其后的所有指令的执行,直到确定是否成功并计算出新的PC值,然后按照新的PC值取指(第18周期)。
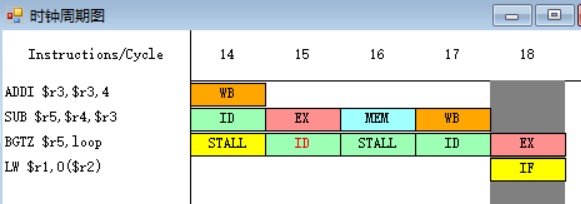
2.

![]()

一旦流水线的译码段ID检测到分支指令(第32周期),就暂停其后的所有指令的执行,直到确定是否成功并计算出新的PC值,然后按照新的PC值取指(第33周期)。

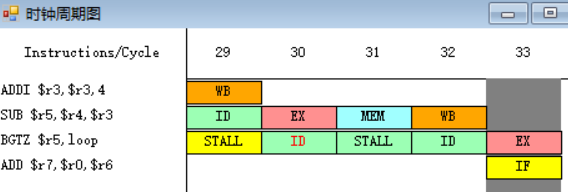
(b)
对branch.s程序进行指令调度(自己修改源程序,使用从前调度法),将调度后的程序重新命名为delayed-branch.s。(注:模拟器中延迟槽默认为1个)。

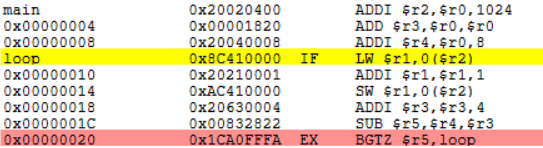
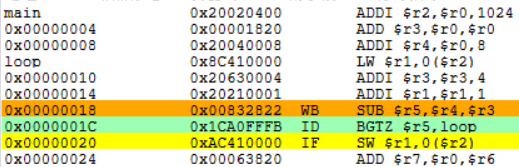
delayed-branch.s:
.text
main:
ADDI $r2,$r0,1024
ADD $r3,$r0,$r0
ADDI $r4,$r0,8
loop:
LW $r1,0($r2)
ADDI $r3,$r3,4
ADDI $r1,$r1,1
SUB $r5,$r4,$r3
BGTZ $r5,loop
SW $r1,0($r2)
ADD $r7,$r0,$r6
TEQ $r0,$r0
(c)
全部复位后,载入delayed-branch.s,打开延迟槽功能,执行该程序,观察其时钟周期图,记录程序执行的总时钟周期数。
原1.
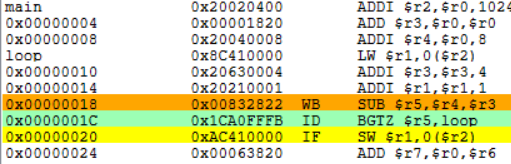
![]()
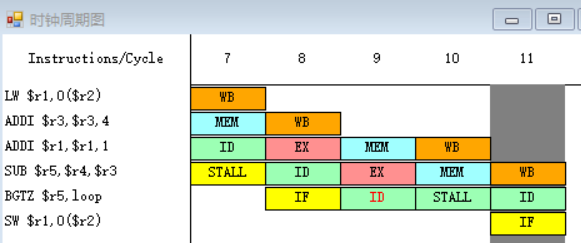
在延迟槽中放入SW $r1,0($r2)指令,从逻辑上“延长”分支指令的执行时间,把延迟分支看成是由原来的分支指令和延迟槽中的指令构成,不管分支是否成功,都要按顺序执行延迟槽中的指令(SW $r1,0($r2))。
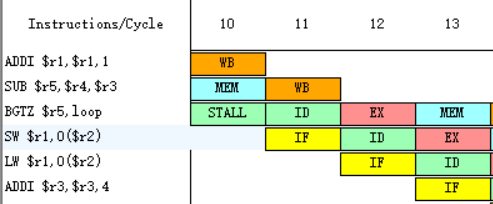
原2.
![]()
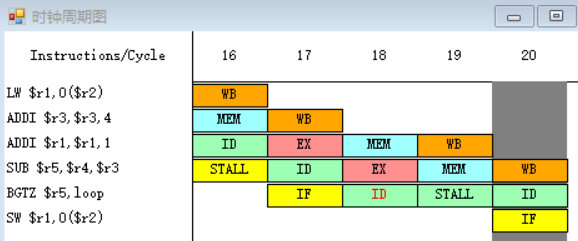
在延迟槽中放入SW $r1,0($r2)指令,从逻辑上“延长”分支指令的执行时间,把延迟分支看成是由原来的分支指令和延迟槽中的指令构成,不管分支是否成功,都要按顺序执行延迟槽中的指令(SW $r1,0($r2))。

不采用延迟槽:



采用延迟槽:


可以看到采用延迟槽时,执行周期总数为26,比不采用延迟槽少12。控制停顿数为0,比不采用延迟槽少2。
总结
延迟槽技术从逻辑上“延长”分支指令的执行时间,把延迟分支看成是由原来的分支指令和延迟槽中的指令构成,不管分支是否成功,都要按顺序执行延迟槽中的指令。可以将分支指令后应执行的指令或者与分支无关的指令放入延迟槽中,使其在原本暂停指令执行的时间执行,使指令的平均执行周期减少了,性能因此而提高了。