文章目录
- Abstract
- Introduction
- Contribution
- Generic SOD algorithms
- 提高输入特征的分辨率(Most Important)
- Methods
- 尺度感知训练
- Methods
- 融合上下文信息
- Methods
- 数据增强
- Methods
- 其他策略
- Methods
- 关键的SOD任务
- 小人脸检测
- Methods
- 小型行人检测
- Methods
- 航拍图像中的SOD
- Methods
- Evaluation of SOD
- Dataset
- 评估指标
- Performance on generic SOD
- 小人脸检测性能
- Performance on small pedestrian detection
- Performance on aerial images
- Further discussion
- Challenges and future directions
- Challenges of SOD
- Future directions
- Conclusion
hh
Abstract
小目标检测(SOD)在现实世界的许多应用中都很重要,包括刑事调查、自动驾驶和遥感图像。SOD由于其低分辨率和噪声表示一直是计算机视觉中最具挑战性的任务之一。随着深度学习的发展,人们引入深度学习来提高超SOD的性能。
本文针对SOD的难点,从提高输入特征分辨率、尺度感知训练、融合上下文信息和数据增强四个方面对基于深度学习的SOD研究论文进行了分析。我们还回顾了关于SOD关键任务的文献,包括小人脸检测、小行人检测和航空图像目标检测。此外,我们在四个众所周知的小对象数据集上对关键SOD任务的通用SOD算法和方法进行了全面的性能评估。我们的实验结果表明,通过网络配置来提高输入特征的分辨率可以显著提高wide FACE和Tiny Person的性能。最后,对SOD今后的研究方向进行了展望。
Introduction
小目标检测(SOD)[41]是目标检测领域的一个新兴研究领域。SOD已广泛应用于医学图像分析、海上救援、监控视频人脸识别、无人机场景分析等领域。近年来发表了许多有前途的基于深度学习的SOD工作。小目标可以用两种主要方式定义,一种定义方法是相对尺寸(relative size)[42],即对象的边界框的宽度和高度与图像的宽度和高度之比小于0.1,或者对象的边界框的面积与图像的面积之比小于0.03(Tiny0.01);另一种定义方法是绝对大小,其中COCO[43]数据集表明,如果对象的大小小于32 × 32像素(Tiny是16×16),则对象较小。示例如图1所示。这些定义意味着小物体的视觉特征是有限的。
SOD性能差的主要原因是小对象的分辨率较低,占用的像素比大对象少;在卷积网络中,由于下采样和池化操作导致空间位置信息丢失,使得检测头对小目标的定位更加困难。小对象数据集的大量稀缺性是SOD进步的另一个障碍。
现有的小对象数据集主要集中在特定场景;人脸见[47],行人[48-51],交通场景[52-56];在它们上面训练的网络不适合一般的SOD。为了克服这些挑战,研究人员开发了一系列策略来提高SOD的性能。我们从提高输入特征的分辨率、尺度感知训练、结合上下文信息和数据增强等方面对这些技术进行了总结。
与这些早期的目标检测调查相反,我们关注与SOD相关的困难,研究最近基于深度学习的SOD算法,从而提出一个分类法来说明为提高SOD性能而开发的新策略。除了对三个领域开发的基于深度学习的SOD算法进行深入描述外,我们的研究还对相关实验结果进行了有意义的比较。
Contribution
1)基于深度学习的SOD算法的系统概述。根据SOD面临的挑战,我们分析了基于深度学习的最先进的SOD算法,并从提高输入特征的分辨率、规模感知训练、结合上下文信息和数据增强的角度总结了提高SOD性能的策略。此外,我们提供了一个全面的审查方法的关键SOD任务,包括小人脸检测,小行人识别和航空图像检测。
2)基于SOTA深度学习的SOD算法性能评价。我们不仅在通用大规模数据集上分析了通用SOD方法的性能,而且还评估了最先进的SOD方法在三个关键SOD任务上的性能,包括小人脸检测、小行人检测和航空图像检测。
3)最后,根据SOD的分类方法和性能分析,讨论了未来的研究方向,包括SOD优化的合适指标、弱监督SOD方法、多任务联合优化和开放世界或few-shot SOD。
Generic SOD algorithms
在本节中,我们将广泛回顾通用SOD的方法。为了应对SOD的挑战,现有的SOD方法通常在现有的管道中添加复杂的设计,这些设计擅长于通用目标检测。我们将从四个方面描述这些方法,包括提高输入特征的分辨率、规模感知训练、结合上下文信息和数据增强。
提高输入特征的分辨率(Most Important)
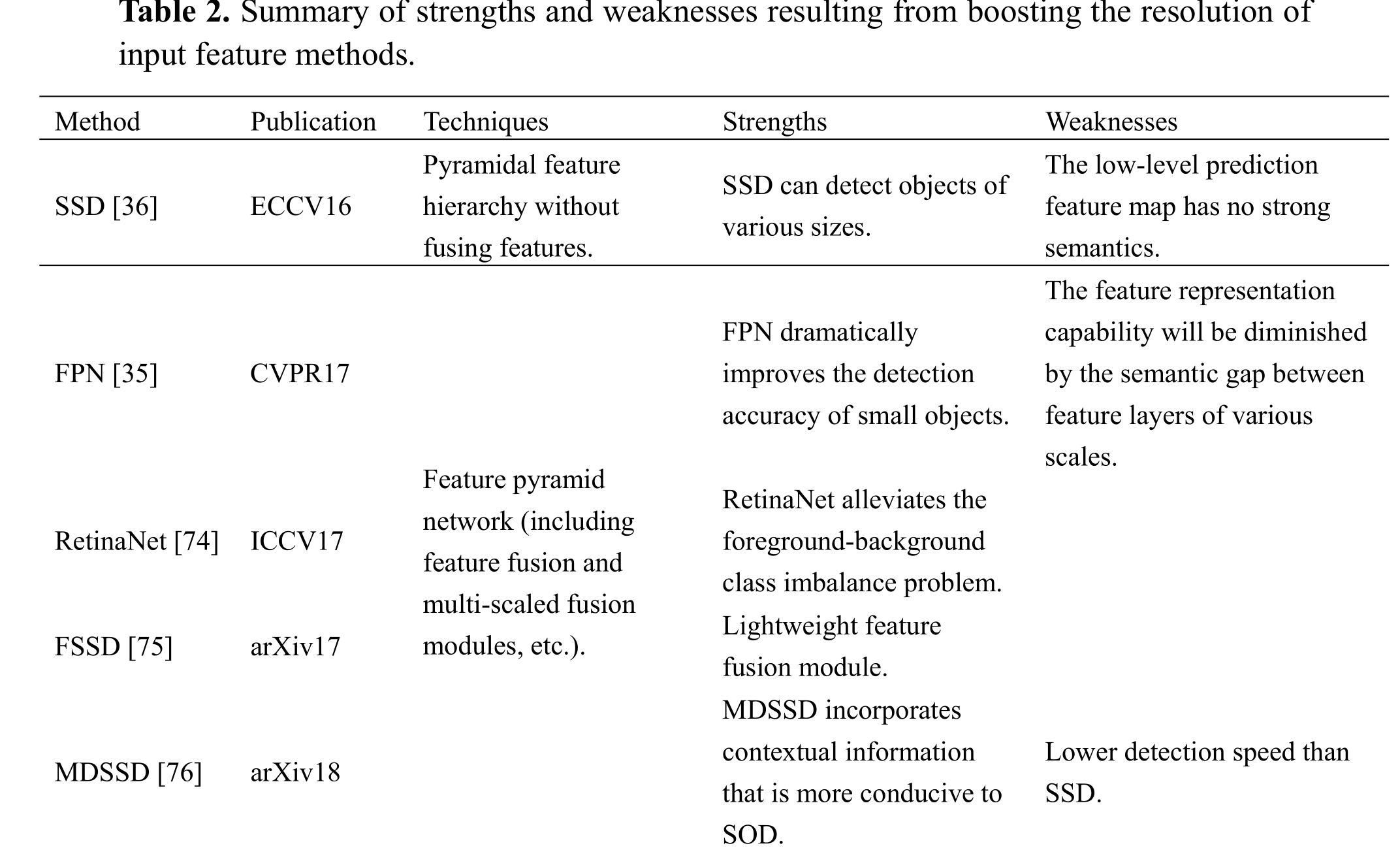
小目标难以精确定位主要是由于CNN的降采样操作导致小目标特征消失,高阶特征图的低空间分辨率严重丢失了小目标的空间位置信息。一个相当合理的解决方案是使用高分辨率特征图或高分辨率图像。然而,采用高质量的图像或增加特征图分辨率将导致更高的计算成本。许多学者通过重用由网络前向传播产生的多尺度特征图来构建特征金字塔,然后使用具有更微小空间细节的低分辨率特征图来检测小目标。此外,一些模型学习了从低分辨率特征到高分辨率特征的映射函数,以达到与大物体相同的检测效果。这两种方法都大大提高了预测特征层的分辨率。图3显示了几个提高输入特征分辨率的典型模型。


SSD[36]是一种多尺度目标检测技术,通过在网络的不同层中放置不同尺度的参考窗口来检测目标。小目标的检测精度没有很大的提高,主要的解释是,低层次的特征图有一个有限的接受域,并且比深度的特征图表示特征的能力要差得多。因此,Lin等人提出了fpn[35]。FPNs的核心思想是利用网络的前向传播,创建4个不同尺度的特征图,通过逐层上采样将高阶特征图与低阶特征图合并,融合不同网络深度的特征,实现特征增强,然后利用每层只需要预测一个尺度的目标的融合特征图进行预测。实验结果表明,FPN显著提高了SOD的检测精度,可以保证6 FPS的检测速度。自FPN被提出以来,已经开发了许多增强的变体,包括PANet [70], BiFPN [71], ASFF [72], NAS-FPN[73]等。尽管基于集成卷积网络的检测模型具有明显更快的检测速度,但基于目标提议的检测技术长期以来具有稍好的检测精度。在调查了这背后的原因后,Lin等人提出了RetinaNet[74]。一级网络最初优于两级网络,Lin等人认为,前景-背景类不平衡是集成卷积网络检测性能较差的主要原因。因此,提出了焦点损失来改善交叉熵损失Focal Loss
MDSSD[76]涉及对具有强大语义信息的高级特征图应用反卷积,然后使用融合模块将其与低级特征图融合,以保留丰富的空间细节和对小对象的高特征表示能力。
在主干的最后一层,小目标特征几乎消失了。自上而下的路径使得FPN几乎不可能融合小对象的特征。此外,随着网络的深入,深度特征图获得了更多的语义信息,但失去了空间信息。这导致锚点和卷积特征之间的偏移,这意味着,经过几次卷积后,锚点在深度特征图上的位置与原始地图上的位置不同。此外,FPN融合不能有效地对深特征和浅特征进行对齐。Gong等[77]提出了一种用于描述FPN中相邻层耦合度的融合因子,该融合因子可以使用数据集统计数据计算或通过内隐学习学习。通过调整FPN中相邻层的融合因子,可以自适应地驱动浅层集中学习微小目标,从而提高对微小目标的检测。高分辨率检测网络(HRDNet)[78]通过多深度骨干网接受多个分辨率输入。
为了减少计算成本,多深度图像金字塔网络(MD-IPN)使用多深度主干来输出多尺度、多层次的特征图,这意味着高分辨率的输入将被馈送到浅层网络中以保留更多的位置信息,而低分辨率的数据将被馈送到深层网络中以提取更多的语义。多尺度FPN对MD-IPN产生的多尺度特征组进行对齐和融合,以减少这些多尺度、多层次特征之间的信息不匹配。Liu等[79]提出了IPG-Net,以缓解连续降采样后小目标特征的消失以及空间信息和语义信息之间的错位;它包括IPG转换和IPG融合模块。
IPG-Net接收图像金字塔作为输入;IPG变换模块从不同分辨率的图像金字塔中提取浅层特征,包含丰富的空间信息和细节信息;IPG融合模块将IPG变换模块提取的浅层特征与主干的深层特征进行融合。RHF-Net[80]采用自顶向下和自底向上的特征融合。它包含了混合融合模块的递归执行,使RHF-Net能够将高级语义特征与低级特征(自顶向下方向)连接起来,并将低级特征映射的丰富空间特征重塑到更深层(自底向上方向),从而改进所有尺度对象的上下文特征。
小物体在特征金字塔的高分辨率特征图上的空间分布非常稀疏,只占高分辨率特征图的一小部分。QueryDet[81]利用查询技术,防止检测头对整个高分辨率特征图进行资源密集型计算,从而加快了基于特征金字塔的目标检测器的推理速度。它包括一个与分类和回归并行的查询头,以预测前一层特征中可能的小对象的位置(查询键)。当前层使用这些位置生成稀疏值特征映射(查询值)。然后,它预测将这一层的查询键传递给下一层。
超分辨率是通过提高输入图像的分辨率来直接丰富小物体信息的另一种有效方法。EFPNs[82]在FPN中添加了一个超分辨率层,因为它使用特征纹理传输模块通过从参考特征中提取区域纹理特征来超分辨率特征。这为EFPN增加了令人信服的细节,并提高了SOD的准确性。为了消除大小物体之间的表征差异,并使小物体获得与大物体相同的检测精度,Li等人[83]使用GAN将小物体的特征表征增强为超分辨表征。但是,由于大目标图像和小目标图像不是来自同一图像,因此超分辨特征可能不具有说服力。
SOD-MTGAN[84]学习了低分辨率图像补丁与高分辨率图像补丁之间的映射,从而降低了计算成本。Noh等人[85]使用高分辨率特征进行直接监督。在超分辨率鉴别器的引导下,将低分辨率特征转移到超分辨率特征发生器中生成高分辨率特征。MARE[86]使用网络获取注意力权重,将其作为每一层特征图的权重,生成最终的注意力特征图;然后进行特征融合,进一步增强对小目标有用的信息。EESRGAN[87]在ESRGAN[89]中加入边缘增强子网(EENs)[88]。EENs对生成器生成的中间超分辨率(ISR)图像进行边缘增强,生成最终的超分辨率图像。鉴别器和检测器一起扮演鉴别器的角色,鉴别器通过使用相对论损失训练生成器[90]。下式(2)和式(3)给出了鉴别器的相对论损失和发生器的对抗损失[91]
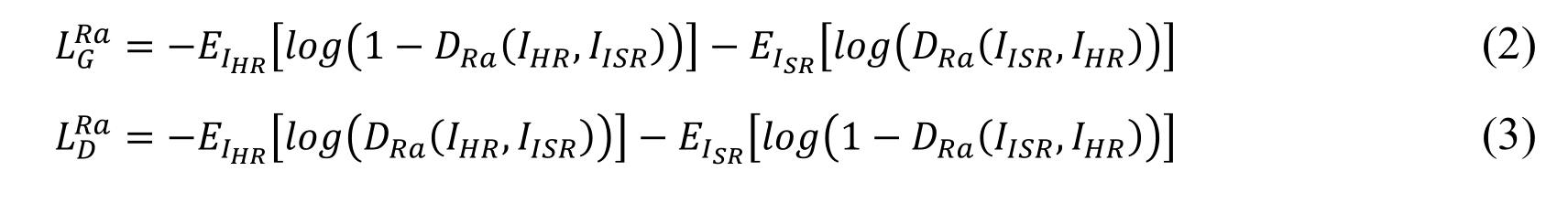
其中𝐷ra表示真实图像(𝐼hr)相对于生成的中间图像(𝐼isr)更真实的概率,其中,Eisr是计算一个mini-batch中所有生成的中间图像的平均值的操作;Eihr是计算一个mini-batch中所有真实图像的平均值的操作。
此外,EESRGAN采用端到端训练将检测器损失反向传播到发生器。因此,发生器接收来自检测器和鉴别器的梯度,以提高超分辨率图像的质量。Cao等人提出了MHN[92],将网络划分为三个不同的分支(branch- 1, branch-m, branch-s),每个分支生成具有各种分辨率的等价高级语义特征图,使其能够更好地匹配各种尺度的对象。
Methods


尺度感知训练
COCO数据集中最大的对象比最小的对象大20倍,cnn的尺度不变性对如此大规模的方差不具有鲁棒性。尺度感知训练策略可以提高检测器对尺度方差的鲁棒性。规模感知训练模型的常见流程如图4所示

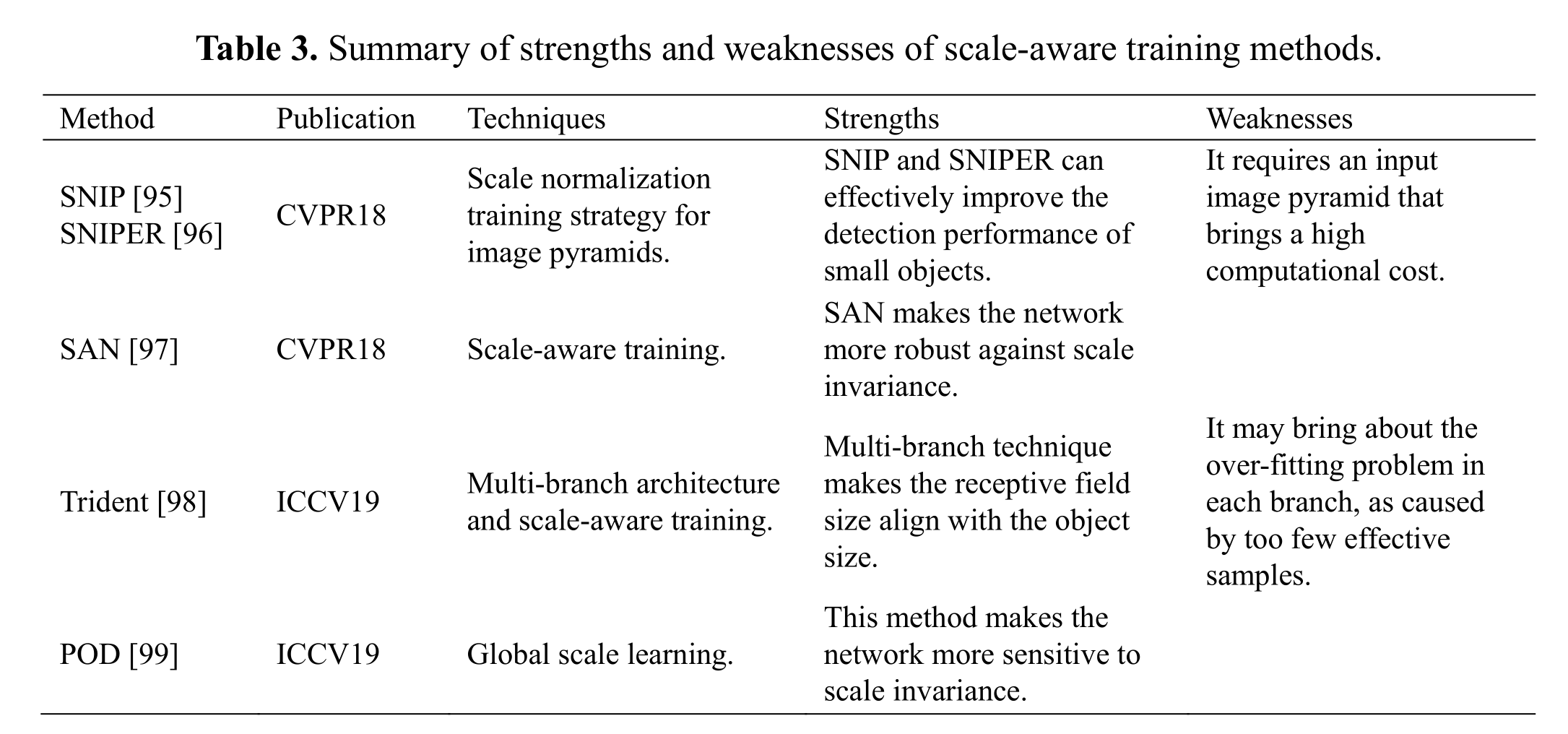
先前提出的方法使用图像金字塔[93,94]来提高各种尺度下目标检测的准确性,这些尺度对内存的要求更大。图像金字塔的尺度归一化(SNIP)[95]是一种使用图像金字塔训练模型的训练策略,只在预定范围内反向传播对象大小的损失。更进一步,SNIPER[96]从金字塔的每一层选择固定分辨率为512 × 512像素的芯片作为训练单元,这与SNIP不同,SNIP分析图像中的每个像素。由于更小的芯片分辨率,它可以训练更大的批量,提高了训练效率和检测精度。Kim等人提出了一种尺度感知网络(SAN)[97],该网络将不同尺度的卷积特征映射到尺度不变的子空间上,使基于cnn的检测方法对尺度变化具有更强的鲁棒性,并构建了一种独特的学习方法,仅考虑通道之间的关系而不考虑空间信息,以实现SAN的高效学习。该方法本质上提高了尺度空间中卷积特征的质量,可以普遍应用于许多基于cnn的检测方法中,在计算时间略有增加的情况下提高检测精度。
Trident[98]是一个多分支平行网络,每个分支采用适当的扩张比例来提供与对象大小一致的感受野大小。此外,采用尺度敏感训练方法增强各分支的尺度感知能力,防止极端尺度的对象在接受域不匹配的分支上训练。各支路的有效范围l由式(4)给出:
Peng等人[99]表明,很难优化的局部和密集的连续尺度是不必要的,并且,通过在层上良好学习的全局尺度的协作,网络可以被授予尺度感知。因此,他们设计了一个全局尺度学习模块来代替普通的卷积模块,学习不同层的合适的全局尺度。
Methods
融合上下文信息
在特定的环境中,视觉目标经常与其他相关对象共存,这提供了丰富的上下文关联。研究人员[100]已经表明,利用上下文作为额外信息可以帮助检测具有模糊特征的小物体。图5显示了合并上下文信息的两个典型模型。

Chen等[42]利用ContextNet和小区域建议生成器对R-CNN模型进行了扩展,改进了SOD。关于区域建议网络(RPN), Chen等人使用了较小的RPN锚大小(16 2、40 2、100 2 vs. 128 2、256 2、512 2)。ContextNet集成上下文信息来计算最终的分类分数。Bell等人[101]提出了ION,利用ROI内外的信息来提高检测性能。在内部部分,ION采用跳跃池的方法提取ROI在不同尺度下的多个层次的特征,增强对小目标的检测能力。在外部部分,ION利用空间递归神经网络提取ROI外部的上下文信息,增强特征信息,提升后续分类和回归性能。DSSD[102]将深层语义信息作为上下文与浅层语义信息融合。CSSD[103]是一个上下文感知框架,通过将反卷积或扩展卷积层集成到SSD中来整合上下文。
在目标检测中,有两种常见的上下文。图像级上下文是指对整个图像中每个像素的上下文信息进行建模,并将其隐式地纳入深度卷积网络中,而实例级上下文是对对象-对象关系进行建模,是对象检测和推理的重要线索。空间记忆网络**(SMN)[104]被提出用于获取实例级上下文。网络检测到一个对象,记住它,然后把它作为先验知识,在下一次迭代中帮助检测先前错过的目标**。Fu等[105]为SOD引入了一种独特的上下文推理方法,该方法对对象的固有语义与空间布局之间的关系进行建模和推断。语义模块从(属于同一类别的提案共享语义共现信息)的角度定义可学习的语义关联函数。公式如式(5)所示:
其中,σi,𝑗表示一个指示函数,并将初始区域特征𝑝映射到潜在表征。
空间布局模块不考虑语义相似度,在内部空间布局中建立基于空间相似度和空间距离的关系,使空间相似度高且出现在集群中的小对象能够相互传递空间布局的上下文信息。FA-SSD[106]是F-SSD和a - ssd的组合,F-SSD使用高级特征映射作为上下文,与低级特征映射连接。A-SSD使用注意机制来最小化后台不必要的浅层特征。SOD通常使用映像级上下文和实例级上下文。
Methods

数据增强
高质量的大规模数据集可以极大地提高深度学习SOD的性能。然而,由于标注成本高,标注数据的数量还远远不够。数据增强是丰富数据集多样性的常用方法,从而在一定程度上提高了模型的通用性和鲁棒性。这也可以帮助缓解由于数据集中不同尺度对象分布不均匀而导致的目标检测精度下降。
目前已经开发了很多数据增强技术,如仿射变换、Mosaic[107]、MixUp[108]和CutMix[109],但这些方法在大中型对象上的性能要优于小型对象。Kisantal等人[110]深入研究了具有小对象的MS在数据集中只占很小的一部分;特别是每幅图像中的小物体数量较少,出现的地点缺乏多样性。Kisantal等人提出对带有小目标的图像进行过采样,以增加训练过程中小目标的数量。Chen等[111]发现随机复制粘贴会导致背景失配和对象尺寸失配。为了解决这个问题,他们采用了自适应数据增强,即使用语义分割网络获得先验路线图,并对路线图增强的对象进行有效位置采样。Ünel等人[112]提出了一种基于平铺的技术,将输入图像故意分割成重叠的平铺,以增加小物体的相对像素面积。
为了解决尺度方差问题,DST[113]接收小物体造成的损失比例作为反馈。如果损失比例小于预定阈值,则在接下来的迭代中对训练图像进行放大和拼接,以补偿缺失的小目标。Zoph等人[114]利用AutoAugment对训练集进行增强策略搜索,找到最优的目标检测数据增强方法。搜索策略中包含RNN控制器和强化学习方法。Chen等人[116]提出了尺度感知的自动数据增强,其中包括一个具有图像和框级增强的尺度感知搜索空间,以及一个称为帕累托尺度平衡的搜索度量。度量是通过记录各种尺度上的累积损耗和精度来实现的。
Methods

其他策略
Samet等人[117]提出了一种新的标记技术,该技术将来自单个特征的预测汇总为一个预测,以减少无锚点检测器的标记噪声。Duan等人提出CenterNet++[118],使用中心关键点和一对角的三元组来表示对象。这些角可以定位任何几何形状的物体。Wang等人[119]评估了Intersection over Union (IoU)对定位小物体变化的敏感性,他们建议用一种新的测量技术取代IoU,该技术将每个方框建模为高斯分布,并使用正态Wasserstein距离(NWD)来确定两个分布之间的相似性。Xu等人[120]提出了接受野距离,直接量化高斯接受野与地面真值之间的相似性,而不是用IoU采样策略分配样本。Lee等人提出的交互式、多类、小对象注释框架C3Det[121]消除了对现实世界中注释需求和费用的担忧。SAHI[122]需要将输入图像划分为重叠的切片,以在输入网络的图像中产生更高百分比的小物体。
Methods

关键的SOD任务
在本节中,我们从小人脸检测、小行人检测和航空图像检测任务方面对SOD进行了系统的综述。我们首先详细描述每个任务的当前方法。然后,对每种方法的优缺点进行了综合总结。
小人脸检测
多尺度建模[123]是在对图像分辨率、物体尺度变化和上下文信息进行深入研究后提出的。该算法以SSD为基础,融合稀疏离散图像金字塔来处理目标的尺度移动。丰富的上下文信息是SOD的必要条件,但由于SOD缺乏语义信息,因此使用底层特征映射;然而,深度特征映射包含丰富的上下文和语义信息。因此,将多层特征融合融合到SOD中,提高了小人脸检测的性能。S^3FD[124]采用了一个尺度均衡的人脸检测网络,以适应不同尺度的人脸检测。此外,利用有效感受野和等比例间隔原则定义锚点的尺度,确保不同尺度的锚点在图像上均匀分布,并确保不同层的锚点与其对应的有效感受野相匹配。然后,采用尺度补偿锚点匹配方法,提高小人脸的召回率。最后,通过预测每个匹配的背景锚点的数量来降低小人脸的假阳性率。[125]使用生成对抗网络生成高分辨率人脸。Face-MagNet[126]采用ConvTranspose (kernel = 8, stride = 4)层,在RPN和分类器内部将小人脸的特征从底层特征层传递到预测层,放大特征映射,从而更好地检测小人脸。
Zhu等[127]指出基于锚点的人脸检测器不能很好地处理小人脸,因为锚点与小人脸不能完美重叠,因此难以调整锚点使其接近地面真实值。因此,Zhu等人提出了期望最大重叠(EMO)分数,提高了锚和面获得高IoU的能力。而且,通过增加小规模锚点的数量,它提高了匹配人脸的可能性。此外,为了获得具有锚点的这些人脸的高IoU,算法在训练过程中随机移动人脸位置。最后,提出了一种锚点匹配补偿策略,提高了硬面检测的准确率。TinaFace[128]涉及对RetinaNet的修改,达到了92.4%的平均精度(AP)。首先,引入DCN[129]作为学习复杂几何变换的主干;然后,利用盗梦空间改进多尺度表示。并且,由于DIoU更适合小物体,因此将边界盒回归的损失从平滑L1变为DIoU[130]。最后,为了解决定位精度与分类分数之间的不匹配问题,引入了IOU感知分支。像OHEM[131]这样的硬例挖掘技术可以识别硬正例和硬负例,并将更多精力集中在训练这些硬例上,以提高检测器的性能。Zhang等人[132]通过将OHEM与硬图像级挖掘相结合来训练人脸检测器,提高了OHEM的有效性;它会根据图像的难度自动改变训练权重。此外,他们还使用了一种检测器,该检测器只能生成带有小锚点的单个高分辨率特征图,以专门学习小面孔,并通过硬图像挖掘策略对其进行训练。小人脸检测方法的优缺点如表7所示。
Methods

小型行人检测
Song等人[133]提出了一种拓扑线定位(topological line localization, TLL)网络,即基于行人躯干的拓扑线检测网络,该网络旨在减少小规模行人边界模糊、外观模糊以及边界框标注方法给小物体带来过多噪声背景的影响。并且,将TLL和ConvLSTM结合到一个单一的时间感知架构中,聚合视频中连续帧的特征,从而提高了小行人检测的性能。此外,采用马尔科夫随机场作为后处理策略来处理人群遮挡。Das等人[134]构建了ISI行人数据集,该数据集包括13129个带注释的视频帧,其中有82.3万个标记的行人。此外,Das等人提供了一种三相检测算法。首先,使用区域分类器识别每帧中的预期区域,该分类器使用改进的Inception网络来降低误差。然后,通过单独使用可能的区域来定位行人的位置,可以显着提高每秒的帧数。最后,采用非最大抑制(NMS)去除同一行人的冗余边界框。
CNNs不仅可以学习低级特征,还具有很强的学习高级语义特征的能力。因此,CSP[135]通过卷积运算将行人检测简化为行人尺度预测和中心任务。检测头对特征提取器生成的特征图进行卷积运算,并将两个并行的1 × 1卷积相加,分别生成质心热图和比例尺尺寸预测图。中心点预测采用交叉熵损失,尺度预测采用L1损失。Yu等人[136]构建了TinyPerson数据集,该数据集主要关注海边、海边和周围的人海上快速救援。TinyPerson中的行人比其他数据集中的行人要小得多,大多数人的像素范围都在20像素以下,而且人的长宽比差异很大。为解决预训练数据集分布与指定任务数据集分布差异较大的问题,本算法提出尺度匹配,使预训练数据集E与任务特定数据集D之间的特征分布一致,如Eq(6)所示,其中定义P(s,d)为数据集D中大小为s的对象的概率密度函数,T为尺度变化函数。
FSAF[37]允许每个实例自由选择优化网络的最佳层,而不是使用传统的金字塔,在每一层放置几个固定大小的锚点。每个实例的最佳特征层是在整个训练阶段根据实例的内容动态选择的,而不仅仅是它的大小;选择函数如式(7)所示:
其中224为ImageNet预训练大小,𝑙o为初始特征层
Methods

航拍图像中的SOD
航空图像中的目标检测在许多现实应用中至关重要,包括城市规划、应急救援[137]、交通检测[138,139]等。由于航空图像通常是从高空向下拍摄的,因此物体的旋转变化很大,并且在任意方向上显示。此外,航空遥感图像中包含高密度场景和许多小物体,这使得SOD成为航空遥感图像的一个复杂问题。创新的检测算法已经出现以解决这些问题。
S²A - Net[140]包含一个特征对齐模块和一个定向检测模块,以保持分类分数和定位精度之间的一致性。SCRDet[141]设计了一种有监督的多维注意力来突出小目标区域,降低背景噪声的影响。定向RCNN[142]和MRDet[143]都提出了一个轻量级的区域提案网络来生成定向提案。[144]提出了一个包含四个部分的新模型。为了从输入的照片中提取特征映射,第一个组件作为主干。由于常规卷积无法适应无人机拍摄的图像的视点变化,因此主干集成了一个具有可变形卷积层的ResNet50网络。第二部分试图使用FPN来利用和改进从ResNet50获得的特征图。RPN是第三个组成部分,它可以用来提取图像中目标的潜在建议。最后一部分是特定目标的任务头。组件采用交错级联结构分配边界框和掩码预测。Yi等人[145]将中心关键点目标检测器扩展到定向目标检测。u型网络[146]是模型的基础。在上采样过程中,采用跳跃连接对特征映射进行组合。四张图组成了架构的输出:热图、偏移图、框参数图和方向图。使用热图和偏移图来推断中心点的位置。在检测到中心点后,回归盒边界感知向量(bbavtors)以捕获定向的边界框。
Han等人[147]认为cnn缺乏旋转不变性,即图像旋转后,其提取的特征也会发生变化。因此提出了ReCNN,使cnn具有旋转不变性。他们将旋转等变网络整合到主干中,以提取旋转等变特征,从而可以精确预测方向。然后,基于RROI Align[148]开发了旋转不变性RoI Align模块,对通道维度和空间维度进行对齐,获得旋转不变性特征。DarkNet-RI[149]以DarkNet53[7]为主干,包含一个旋转不变层,提取旋转不变的多尺度特征,并利用分类方案直接预测目标的位置。之后,利用盒细化模块进行额外的NMS,消除重叠冗余的边界盒。RepPoints[150]开发了自适应点集,可以捕捉混沌环境中方向突变的空中物体的几何结构。Li等人[151]提出了三个定向转换函数,用于将自适应点转换为各种定向对象的定向包围框。他们在后处理中应用MinAeraRect来提供通常旋转的矩形预测,并应用NearestGTCorner和MinAeraRect函数来增强训练过程中的自适应点学习。Xu等人[152]提出Dot Distance (DotD),即两个边界框质心之间的归一化欧氏距离,以解决IoU在检测微小物体时对边界框之间的微小偏移敏感的问题。s2 ANET-SR[153]利用超分辨率增强遥感图像中小目标的特征提取,并结合感知损失和纹理匹配损失与检测损失联合训练s2 ANET-SR。[154]的作者开发了一种跨层注意模块,用于从小对象中提取非局部特征以增强其特征。[155]的作者使用高斯混合模型来生成焦点区域,并使用不完全盒抑制方法来缓解截断盒问题,从而提高了SOD的性能。
Methods

Evaluation of SOD
本节概述当前可用的SOD数据集。利用三个大规模数据集对SOTA SOD方法的性能进行了评价。我们选择了众所周知的图像数据集:MS COCO用于一般SOD评估,WiderFace用于小人脸的SOD任务,TinyPersons用于小行人的SOD任务,DOTA用于航空图像的SOD任务。
Dataset
高质量的数据集对于开发先进的目标检测算法非常重要。COCO在图像中包含更多的小对象和更复杂的背景。COCO还具有更均衡的对象分布。COCO数据集中只有一个类别的图像不到20%,平均每个图像有3.5个类别和7.7个实例对象。不幸的是,对小物体的检测仍然不足,这是由于小对象本身的特性以及为SOD设计的基准较少造成的。为了对数据集进行全面的回顾,我们调查了包含大量小对象的数据集,这些小对象跨越了各种SOD任务,如人脸检测、行人检测、交通标志/灯光检测和航空图像对象检测



评估指标
帧/秒指的是物体检测的速度,表示每秒可以处理的图像数量。数值越高意味着该方法更快,可以应用于实时SOD.
IoU测量预测边界框(bbox pred)和地面真实边界框(bbox GT)区域之间的相似性:
AP是对象检测任务的常用度量,在AP计算中使用以下定义:
1)正样本:包含检测对象的样本,且预测bbox置信度评分大于设定的阈值。
2)负样本:不包含检测对象的样本,且预测bbox置信度评分大于设定的阈值。
3)真阳性(TP):预测正确的阳性样本。
4)真阴性(TN):预测正确的阴性样本。
5)假阳性(FP):预测错误的阳性样本。
6)假阴性(FN):预测错误的阴性样本。

更为严格的COCO评价指标比PASCAL VOC评价指标应用更为广泛。它的IoU阈值通常在0.5到0.95之间,步长为0.05。对于较小的(面积的平方<32 2),中(32 2 < area < 96 2),大(area >96 2)
Performance on generic SOD
表14显示了应用于COCO数据集的通用SOD算法的性能评估结果;注意,AP与mAP具有相同的含义。AP50和AP75分别表示IoU设置为0.5或0.75时的AP, AP s、AP m和AP l分别表示小型、中型和大型物体的平均精度。如图所示,IENet[179]实现了最佳AP(51.2)。一般来说,大型物体的检测性能要比其他大小的物体高得多。HRDNet[78]对于小对象的值为32.1,MRCenterNet[118]对于小对象的值为27.8。这些结果表明,通过多尺度训练提高输入特征的分辨率可以在小目标上获得更好的性能。所有实验均在Linux操作系统上进行,操作系统为NVIDIA GeForce RTX 2080Ti, CUDA 11.7。

小人脸检测性能
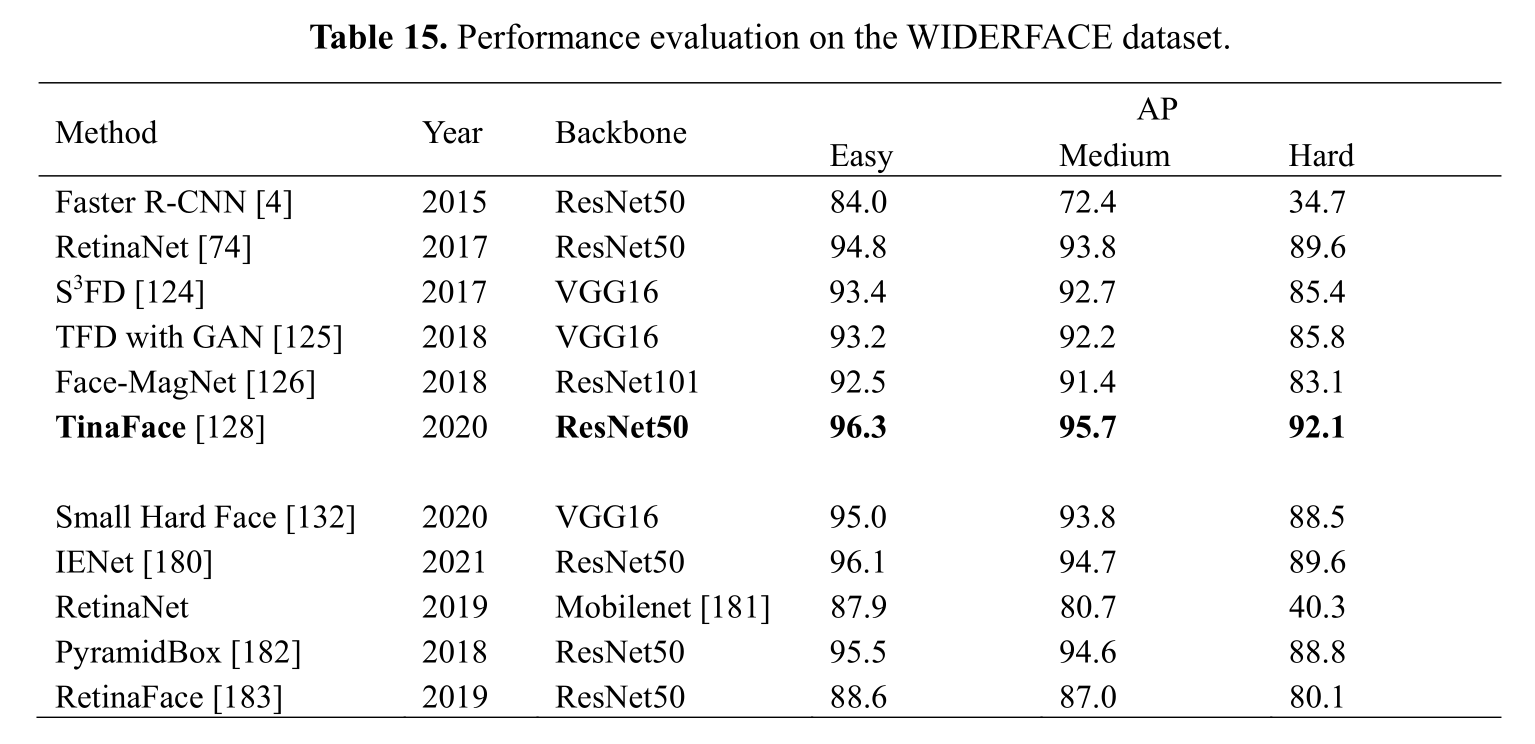
在表15中,我们评估了WIDERFACE上的小人脸检测方法[47]。WIDERFACE根据EdgeBox的检测率定义了“简单”、“中等”和“困难”三个难度等级[180]。如图所示,TinaFace[128]实现了最佳AP;易、中、难测试集的AP值分别为96.3、95.7、92.1。IENet[180]取得了相对较好的结果,易、中、难测试集的AP值分别为96.1、94.7和89.6。Tinface和IENet都提高了预测特征图的分辨率,充分利用了融合的特征图。IENET还充分结合了上下文信息。结果表明,提高预测特征图的分辨率并结合上下文信息可能是增强人脸检测的关键。
Performance on small pedestrian detection

表16显示了TinyPerson[136]数据集上典型的小型行人SOD方法。MR[184]表示缺失率。大小划分用上标MR和AP表示,其中tiny表示大小范围(2,20),small表示大小范围(20,32)。用于评估的IoU阈值由MR和AP的下标表示。在这些算法中,FCOS[39]在所有MR评估中获得了最好的结果。当IoU为0.5时,FPN对小型和微型物体产生了最好的AP,而Grid R-CNN[185]的IoU分别为0.25和0.75。
Performance on aerial images
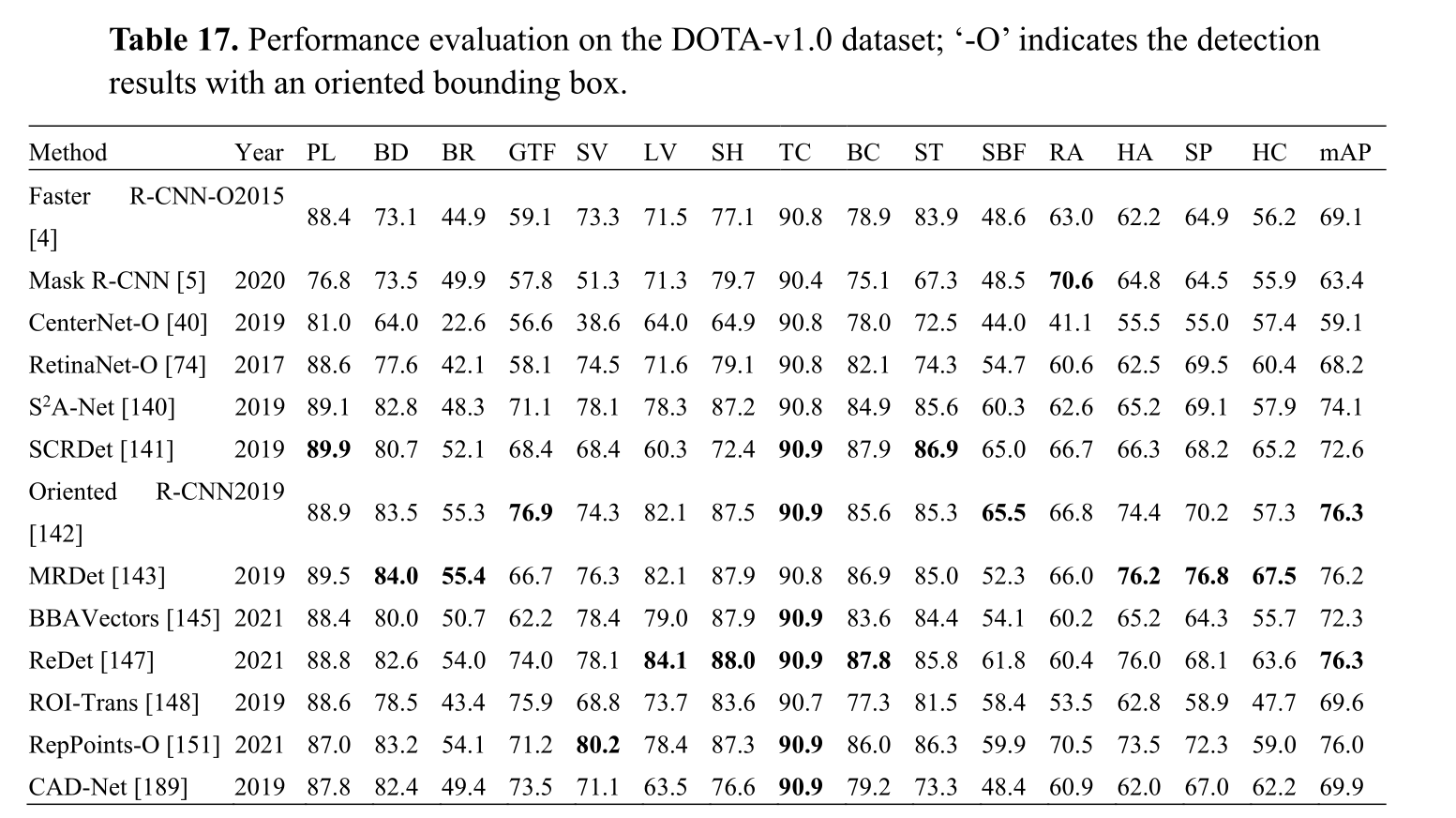
在表17中,我们比较了最先进的航空图像目标检测算法在DOTA-v1.0上的性能[166],该算法由15个类别组成:飞机(PL)、棒球场(BD)、桥梁(BR)、地面跑道(GTF)、小型车辆(SV)、大型车辆(LV)、网球场(TC)、篮球场(BC)、储罐(SC)、足球场(SBF)、环状交叉路口(RA)、港口(HA)、游泳池(SP)和直升机(HC)。redt和Oriented R-CNN的mAP值最好,为76.3。每个类别中最好的AP用粗体标出。
Further discussion
根据实验结果,我们进一步讨论了现有SOD方法的一些局限性:
- SOD的框架一般采用Faster R-CNN、SSD、YOLO等流行模型进行修改;这些架构可能不适合小对象,从而导致性能差。
2)利用超分辨率增强小目标的分辨率可以提高SOD的精度,但检测速度会明显降低,无法满足实时监控等现实场景的需求。
3)Transformer在计算机视觉领域得到了广泛的应用,如DETR[190]在目标检测中的应用。然而,关于Transformer用于SOD的研究并不多。
4) cnn对尺度变化不敏感。有必要设计更适合规模感知的特征提取器。
5) MS COCO可能不是小对象的理想基准,因为小对象占数据集的比例相对较小。
Challenges and future directions
Challenges of SOD
除了目标检测中常见的挑战,如连续目标检测、不平衡问题等。SOD存在典型的挑战,包括带噪声的特征表示、小目标信息丢失、感受野的影响、位置变化敏感性以及小目标数据集的稀缺性。
1)带噪声的特征表示**。CNN实现后,小物体的特征往往受到背景噪声的污染**,使得网络难以捕捉到对定位和分类任务至关重要的判别信息。此外,小目标经常被遮挡和聚类,因此从噪声杂波中区分小目标并精确定位其边界特别困难。
2)小目标信息丢失。在深度神经网络中,由于每个小目标所占用的像素较少,在进行降采样操作后,小目标的特征几乎被消除了。小物体的弱信息消去对SOD是致命的,因为在高度结构化的表示存在下,检测头很难给出准确的预测。
3)感受野的作用。深度神经网络通常选择大的接受野来防止信息丢失。然而,预测低分辨率特征图的接受域可能与小对象的大小不匹配。如果接受野大于小对象,则会导致被检测对象成为背景,骨干网络无法提取特征,导致SOD性能较差。
4)位置变化敏感性。基于IoU的度量中边界框的小位置偏差对小目标的干扰比对大对象的干扰更大,这使得很难找到合适的IoU阈值并提供高质量的正、负样本来训练网络。
5)缺乏小对象数据集。目前还没有足够的大规模通用小目标数据集来匹配标注小目标的成本。MS COCO虽然有相当多的小物体(31.62%),但每张图像的实例太多,导致小物体分布不均匀。
Future directions
根据SOD面临的挑战和性能结果分析,我们讨论了未来SOD研究的几个潜在方向:
1)弱监督、无监督和自监督SOD。现有的基于深度学习的SOD技术使用全监督模型。对于模型训练,需要大量带有边界框注释(完全监督信息)的图像。然而,注释工作既费力又耗时。弱监督对象检测可以使用图像级标签(如图像类别)作为监督信号来训练对象定位模型,而不需要像素级注释,这减少了与注释相关的工作量。无监督显著目标检测[191]和基于对比学习的自监督学习任务[192]是近2年来的研究热点。因此,继续研究基于弱监督学习的SOD算法的发展至关重要。
2) 适合SOD的指标。基于IoU的度量,包括原始IoU及其扩展(DIoU, GIou等),对小物体的位置偏差非常敏感,在基于锚点的检测器中使用时,会显著降低检测性能。[119]的作者使用了一种新的基于Wasserstein距离的SOD指标,它比标准微调基线的AP值高6.7 AP,比最先进的SOTA模型的AP值高6.0 AP。因此,设计一个适合小物体的度量将是进一步研究的关键。
3)多任务联合优化。尽管诸如规模感知训练策略、结合上下文信息、数据增强和增加输入特征分辨率等技术有助于提高SOD性能,但它们仍然远远不够,这些方法的联合使用可能能够进一步提高SOD性能。
4)开放世界或少样本SOD。少弹目标检测[193]已经取得了突出的成果,而少弹场景下的SOD也是亟待解决的问题。开放世界SOD寻求克服SOD难题,同时在模型中实现增量学习,这类问题将是未来一个重要的研究课题。
Conclusion
本文对基于深度学习的SOD算法进行了深入的综述。我们专注于SOD优化方法,旨在解决SOD的挑战,包括规模感知训练,上下文信息整合,数据增强和提高输入特征的分辨率。我们总结了这些方法的优点和局限性。我们还回顾了关键SOD任务的方法,包括微小人脸检测,微小行人检测和航空图像目标检测。此外,还进行了详细的实验来评估通用SOD算法的性能,以及关键SOD任务的方法;我们发现,提高输入特征的分辨率是提高SOD性能的最有效方法。最后,我们提出了SOD的四个潜在发展方向。


![使用教程之【SkyWant.[2304]】路由器操作系统,破解移动【Netkeeper】校园网【小白篇】](https://img-blog.csdnimg.cn/direct/01663f3794ff4cea9462ccd0000b3c0e.png)