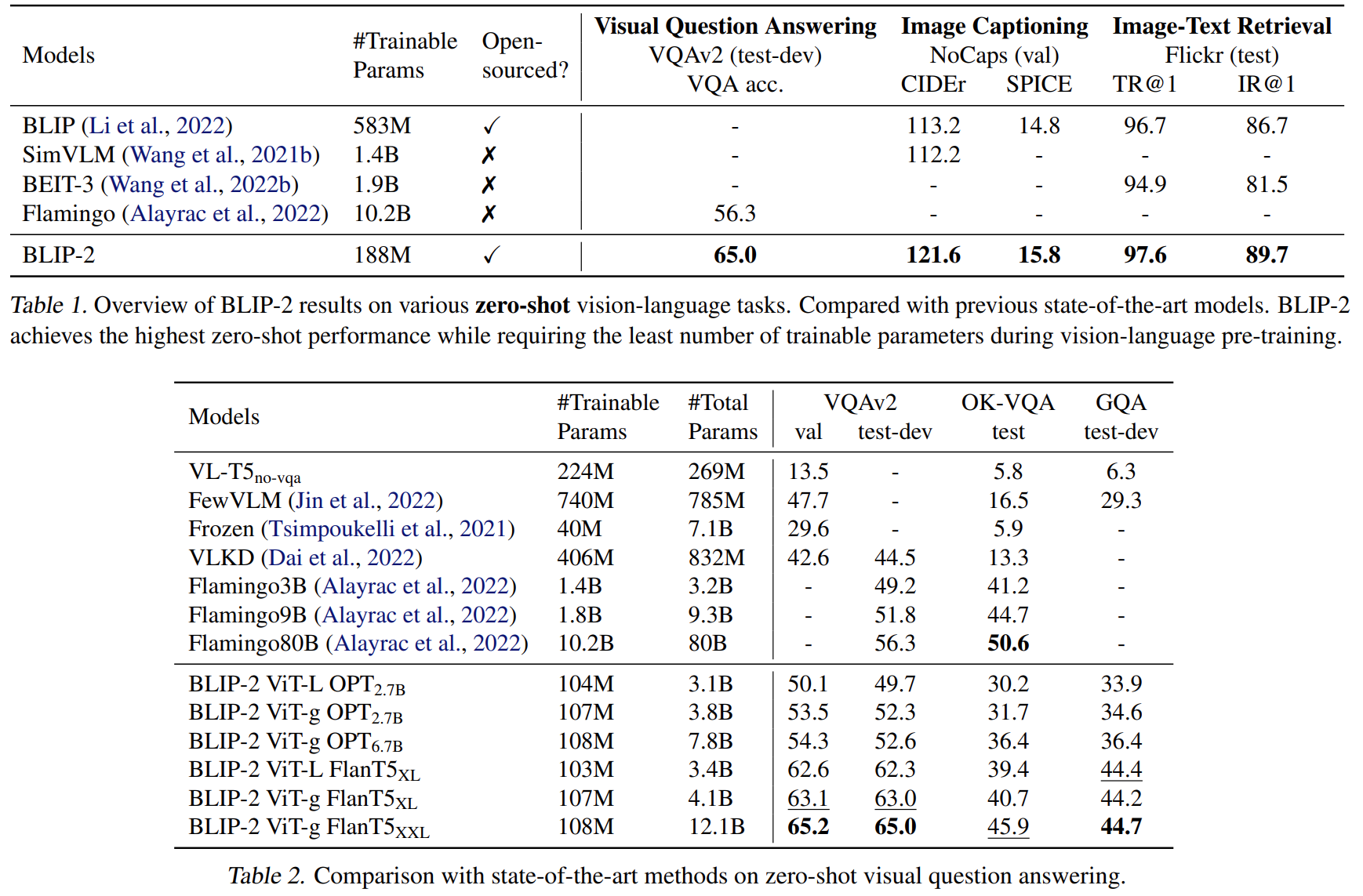
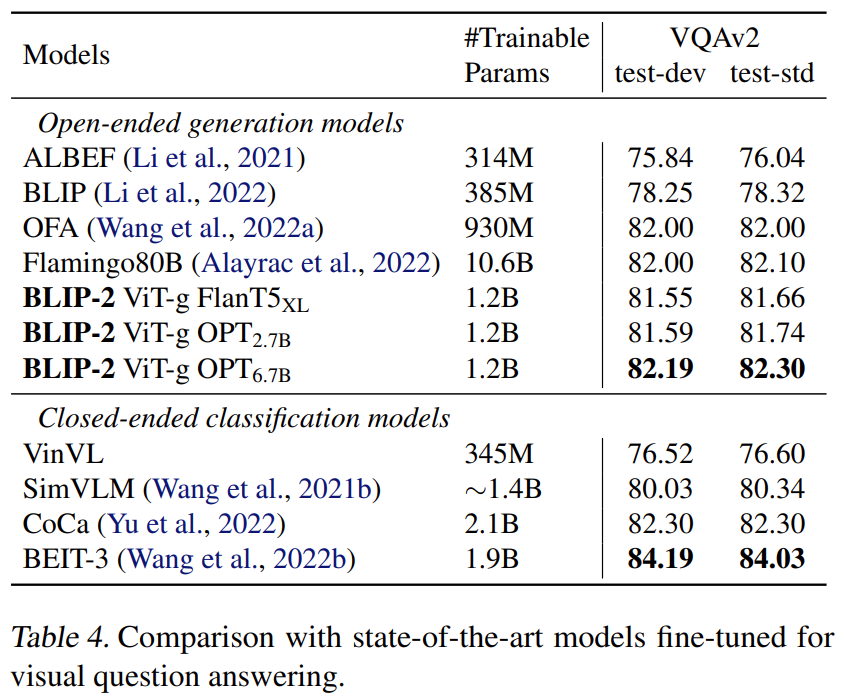
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
1 模型
在预训练视觉模型和预训练大语言模型中间架起了一座桥梁。两阶段训练,视觉文本表示和视觉到语言生成学习。

Q-Former由两个转换器子模块组成,它们共享相同的自注意层:(1)与冻结图像编码器交互用于视觉特征提取的图像转换器,(2)既可以用作文本编码器又可以用作文本解码器的文本转换器
可以通过相同的自关注层与文本进行交互。根据预训练任务的不同,应用不同的自我注意掩码来控制查询-文本交互。用BERTbase的预训练权重初始化Q Former,而交叉注意力层是随机初始化的。Q-Former总共包含188M个参数。
1.1 Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
共同优化三个共享相同输入格式和模型参数的预训练目标。每个对象在查询和文本之间使用不同的注意力掩蔽策略来控制它们的交互。
Image-Text Contrastive Learning (ITC)
学习对齐图像表示和文本表示,使得它们的相互信息最大化。它通过对比正对与负对的图像文本相似性来实现这一点。
视觉输出查询表示Z,有很多向量,文本用[CLS] token输出t,一个向量。计算Z的每个向量和t的相似性,选最高的作为图片文本相似性。为了避免信息泄露,我们使用了一个unimodal self-attention mask,,其中查询和文本不允许相互看到。
Image-grounded Text Generation (ITG) loss
模型不允许冻结的图片编码器和文本tokens直接交互提取信息,所以产生文本的信息必须通过查询提取,然后通过自注意机制传递给文本tokens。怎么做到这一点?通过多模态因果自注意力掩码(multimodal causal self-attention mask)控制查询文本的交互。用[DEC]替代原来的[CLS]用来标志第一个文本token。
Image-Text Matching (ITM)
文本图片对齐。它是一个二值分类任务,是,还是不是。用了一个双向自注意力掩码(bi-directional self-attention mask),所有查询和文本都可以相互关注。
1.2 Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
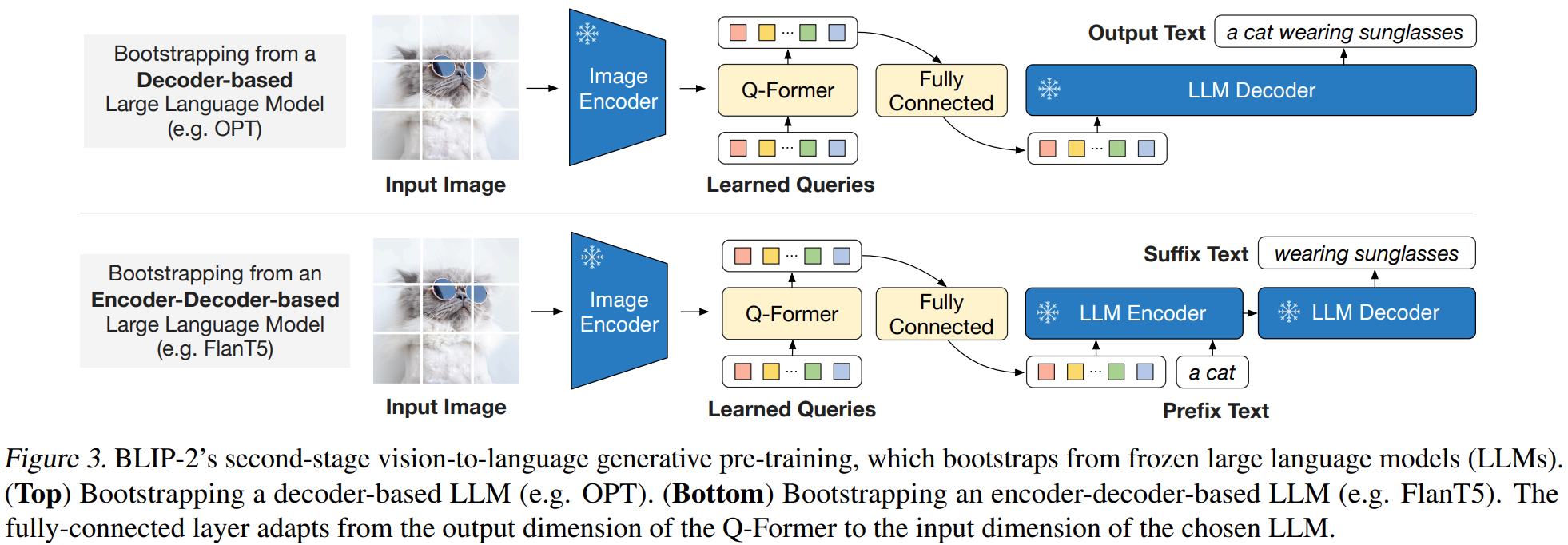
这部分加上了冻结的LLM模型,生成文本。上面几部分已经训练好一个提取语言信息视觉表示(extract language-informative visual representation)的模型,也就是,上面训练好的Q-Former已经可以从视觉编码器中提取和文本相关的视觉信息了。直接在上面的模型的基础上,加一个FC层,将Q-Former输出向量的维度和LLM输入的维度一样。将经过FC层后的维度预置到文本向量作为软视觉提示(soft visual prompts)。
介入两种LLM,decoder-based LLMs 和 encoder-decoder-based LLMs。
对于decoder-based LLMs,用language modeling loss预训练
对于encoder-decoder-based LLMs,用prefix language modeling loss预训练。前缀文本与视觉表示连接,作为LLM编码器的输入。后缀文本用作LLM解码器的生成目标。
实验:
Pre-trained image encoder and LLM:
ViT-L/14 from CLIP,ViT-g/14 from EVA-CLIP;
unsupervised-trained OPT model family for decoder-based LLMs,the instruction-trained FlanT5 model family for encoder-decoder-based LLMs。