ZOrder简介
使用Z-Order索引,可以按任意维度对数据进行排序,以获得更加高效且均衡地范围查询。它即可以作为一级索引,直接影响底层数据组织形式,甚至可以取代二索引(更加节省内存,吞吐量也理更高)。
相比于传统的按SORT KEYs的顺序的自然排序策略,一旦过滤条件与排序键的前缀匹配模型冲突,数据查找空间就会膨胀,进而影响查询性能,而ZOrder由于会考虑每个维度的值,将数据按Z空间排列,因此即使查询时不满足最优条件匹配模型,也不会导致查询空间的过度膨胀。
Z-Order排序可以认为是相对于某个分区来说的,每一个分区的数据文件会按Z-Address的值有序,那些Z-Address值相近的数据会被尽量分配到相同或连续的文件中,如此在查询时进行文件过滤时,可以很容易地基于文件的Metadata信息,决定此文件是否满足匹配条件。
参考文档:
Z-Order Indexing for Multifaceted Queries in Amazon DynamoDB: Part 1
Z-order indexing for multifaceted queries in Amazon DynamoDB: Part 2
Iceberg中的Z-Order实现(基于AWS)
更详细的基本实现原理可以参考上文件中提到的参考文档。
Z-Address排序键
Z-Address是由指定的Z-Order排序字段联合生成的,其数据类型为byte[],且按字典序有序(Lexicographical Order)。
例如有如下的两个排序字段X/Y,且指定了顺序order by Y, X:
X value: 01100001
Y value: 11010110
Z address: 1011011000101001
其中01100001是X值的二进制表示(一个字节),11010110是Y值的二进制表示(一个字节),Z-Address值则是由X/Y的二进制数据按Bit从左到右交叉产生的,即有如下规则:
1011011000101001中的第一个bit来自Y的第一个;第二个0来自X的第一个;第三个1来自Y的第二个,第四个1来自X的第二;…;直到遍历完所有的bits,产生了两个字节的Z-Address值。
上面是两个字段的生成的Z-Address的过程,同理当有N个字段时,则会按字段的定义顺序,依次取每个字段的第一个bit,作为Z-Address的前N-bits,然后取每个字段的第二个bit…
理想情况的搜索:
如下是当X/Y两个字段都为一个字节时,构成的所有可能的Z-Address的取值表,其中绿色的Z字形连接的值,则表示查询条件满足(x >= 2 && x <= 3) and ( y >= 4 && y <=5)的可能真实存在的数据数据所在的空间,例如底层真实存在一行数据(x = 2, y = 5)。
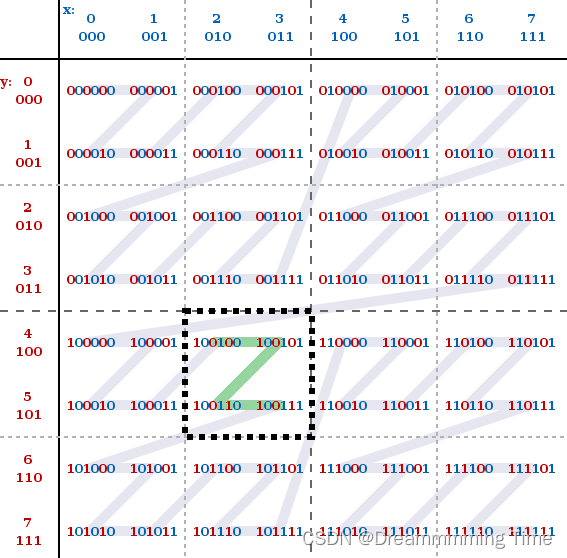
不难看出,X/Y连续的值被分配在了一个方形空间上,或叫搜索空间,这明显区别取传统的按值排序产生的
线性搜索空间。在搜索时,我们只需要关注X/Y的最小值与最大值构成的方形区域即可,即一个2D的空间。
按值排序产生的线性搜索空间:(2, 4) -> (2, 5) -> (3, 4) -> (3, 5)
一般情况的搜索:
上面的图示展示了两个字段产生的最小搜索空间,更一般地,如果一个查询条件通常是会跨越多个搜索空间的,例如下面的图展示了(x >= 1 && x <= 3) and (y >= 3 && y <= 4)产生的所有组合(图中红色+绿色所覆盖的值),而理想情况下我们只需要遍历由最小值和最大值构成的空间即可,即(x=1, y = 3) (x = 3, y = 4)。
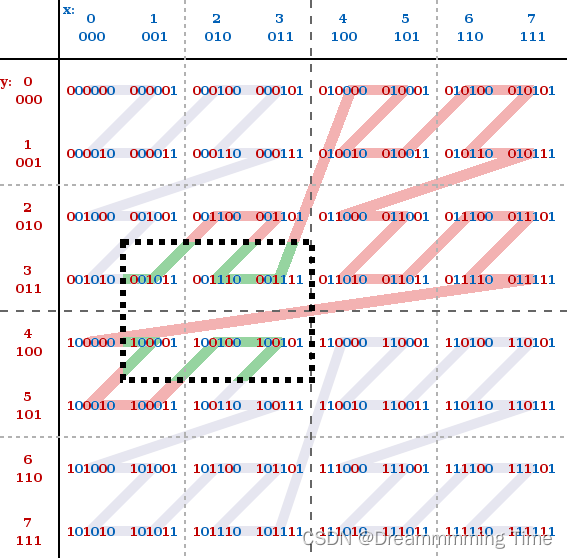
上图中绿色覆盖的二进制数,是我们真正需要遍历的搜索空间,是通过最大值和最小值计算得到的待搜索方形区间,而在实际遍历时,我们需要遍历Z-Address值在[001011, 100101]区间的所有可能的二进制数,则然会出现跳出搜索空间的情况,例如当我们遍历了(x=1, y=3)的Z-Address值时(二进制为001011),下一个要遍历的二进制数为001100(通过001011 + 1得到),但实际上这个Z-Address值并不在我们预期的搜索空间内,同时上图中所有红色线覆盖的数都是不满足条件的取值。
查询优化:
因此了为能够解决搜索空间膨胀的问题,AWS中的实现讲到了,至少需要两个额外的辅助函数,来帮助在搜索时剔除不相关的数据:
- isRelevant函数:判断当前的Z-Address值是不是在搜索空间内;
- nextJumpIn函数:计算下一个可搜索的最小Z-Address的值,例如
nextJumpIn(11, 37, 16)(其中11对应于搜索空间的左上角的值001011,37对应于搜索空间的右下角的值100101,而则16则表示搜索空间的右上角的值001111的下一跳01000)计算得到的下一个匹配的Z-Address值为33, 即指引我们从位置(x=4, y=1)跳转到(x=1, y=4),如此就可以跳过大量的、不相关的取值。
优化的有效性:
前面讲到的查询过程中动态进行空间裁剪的策略,实际上就是一种精确搜索的检索模式,由于需要对每一个可能的Z-Addresss都进行判定,看其是不是在搜索空间内,这明显会付出额外API调用的代价,当搜索空间很大同时空间内的Z-Address值很稠密时,这种查询方式(精确查询)反倒由于API调用过多导致性能下降。
为了在空间裁剪和查询效率的做一个均衡,AWS提出了基于Page面的裁剪,而不是基于最小搜索空间(例如2D空间,就是一个2*2的矩形),避免了过多的API调用。
详细的计算逻辑参见Z-order indexing for multifaceted queries in Amazon DynamoDB: Part 2中的Page jump querying章节。
Iceberg中的实现
Iceberg根据AWS中Z-Order的开源实现,引入了Z-Address的计算和排序逻辑,但并没有进行查询时的空间裁剪优化,因此在查询时依赖于原有的数据文件层级的分区裁剪和非分区键上的Min/Max裁剪能力,而文件内依靠Parquet/Orc本身的过滤能力。
综上,Iceberg中的Z-Order排序,使得文件的组织可以在多维度排序时不再是线性相关,而是同时考量了多个维度上最相近前缀(Z-Address的字节长度是固定的而且有限,不可能表示任意大小的数据,例如字符串类型的数据),将这些数据组织连续排列,因此可以做到每一个维度上的数据在多个文件中,分布地更加均衡且不失聚集性,因此对于非前缀匹配模式的单一维度或多维度过滤,能够避免排序键上的线性排序算法,导致某个维度上的连续数据被分隔到多个不同的数据文件中的问题。
线性排序的示例,ORDER BY A, B, C
1, a, 10
1, c, 20
2, a, 10
2, b, 10
对于一个分区中的数据来说,不难看到在整个分区空间中,字段A是严格有序的,但B,C字段并不是,因此每个维度的上的重复值越多,越靠后的排序字段越容易散落到多个文件中。
Iceberg Z-Order写入的执行流程解析
表模型
private static final Schema SCHEMA =new Schema(optional(1, "c1", Types.IntegerType.get()),optional(2, "c2", Types.StringType.get()),optional(3, "c3", Types.StringType.get()));
构建Rewrite Files任务
RewriteDataFiles.Result result =basicRewrite(table)// 指定C2、C3列为Sort keys,意味着在重写数据文件时交由SparkZOrderStrategy处理.zOrder("c2", "c3").option(// 指定需要重写的文件大小,即超过平均文件大小的数据文件,会被重写SortStrategy.MAX_FILE_SIZE_BYTES,Integer.toString((averageFileSize(table) / 2) + 2))// Divide files in 2.option(RewriteDataFiles.TARGET_FILE_SIZE_BYTES,Integer.toString(averageFileSize(table) / 2))// 指定待重写时的一个文件组包含的最少读取的文件数量,即使文件组的文件问大小小于TARGET_FILE_SIZE_BYTES,也会进行重写// 同时也意味着,一个文件组完成重写任务之后,会至少包含一个数据文件.option(SortStrategy.MIN_INPUT_FILES, "1").execute();
SparkZOrderStrategy
继承自BinPackStrategy,支持运行时设置如下的参数:
targetFileSize =PropertyUtil.propertyAsLong(options,RewriteDataFiles.TARGET_FILE_SIZE_BYTES,PropertyUtil.propertyAsLong(table().properties(),TableProperties.WRITE_TARGET_FILE_SIZE_BYTES,TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT));minFileSize =PropertyUtil.propertyAsLong(options, MIN_FILE_SIZE_BYTES, (long) (targetFileSize * MIN_FILE_SIZE_DEFAULT_RATIO));maxFileSize =PropertyUtil.propertyAsLong(options, MAX_FILE_SIZE_BYTES, (long) (targetFileSize * MAX_FILE_SIZE_DEFAULT_RATIO));maxGroupSize =PropertyUtil.propertyAsLong(options,RewriteDataFiles.MAX_FILE_GROUP_SIZE_BYTES,RewriteDataFiles.MAX_FILE_GROUP_SIZE_BYTES_DEFAULT);minInputFiles = PropertyUtil.propertyAsInt(options, MIN_INPUT_FILES, MIN_INPUT_FILES_DEFAULT);deleteFileThreshold =PropertyUtil.propertyAsInt(options, DELETE_FILE_THRESHOLD, DELETE_FILE_THRESHOLD_DEFAULT);rewriteAll = PropertyUtil.propertyAsBoolean(options, REWRITE_ALL, REWRITE_ALL_DEFAULT);
任务执行
public class RewriteDataFilesSparkActionextends BaseSnapshotUpdateSparkAction<RewriteDataFilesSparkAction> implements RewriteDataFiles {@Overridepublic RewriteDataFiles.Result execute() {if (table.currentSnapshot() == null) {return new BaseRewriteDataFilesResult(ImmutableList.of());}// 获取最新的Snapshot IDlong startingSnapshotId = table.currentSnapshot().snapshotId();// Default to BinPack if no strategy selected// 这里是SparkZOrderStrategyif (this.strategy == null) {this.strategy = binPackStrategy();}// 验证Z-Order的运行时参数的正确性,同时初始化运行时参数,最重要的一个参数如下:// String VAR_LENGTH_CONTRIBUTION_KEY = "var-length-contribution";// 原子类型的字节大小为8字节,即使用64-bits来保存Z-Address的值// int DEFAULT_VAR_LENGTH_CONTRIBUTION = ZOrderByteUtils.PRIMITIVE_BUFFER_SIZE;validateAndInitOptions();// 按分区信息生成文件组,一个文件组即一个独立的重写任务Map<StructLike, List<List<FileScanTask>>> fileGroupsByPartition =planFileGroups(startingSnapshotId);// 构建一个运行时的上下文,方便获取对文件组的ProfilesRewriteExecutionContext ctx = new RewriteExecutionContext(fileGroupsByPartition);if (ctx.totalGroupCount() == 0) {LOG.info("Nothing found to rewrite in {}", table.name());return new BaseRewriteDataFilesResult(Collections.emptyList());}// 生成一组RewriteFileGroup实例Stream<RewriteFileGroup> groupStream = toGroupStream(ctx, fileGroupsByPartition);// CommitManager负责提交Rewrite Files的结果到目标表;startingSnapshotId对应于初始化的Snapshot// new RewriteDataFilesCommitManager(table, startingSnapshotId, useStartingSequenceNumber);RewriteDataFilesCommitManager commitManager = commitManager(startingSnapshotId);if (partialProgressEnabled) {// 支持部分重写成功return doExecuteWithPartialProgress(ctx, groupStream, commitManager);} else {return doExecute(ctx, groupStream, commitManager);}}
}
数据文件分组
按分区打包数据文件
public class RewriteDataFilesSparkActionextends BaseSnapshotUpdateSparkAction<RewriteDataFilesSparkAction> implements RewriteDataFiles {Map<StructLike, List<List<FileScanTask>>> planFileGroups(long startingSnapshotId) {// 搜集所有待重写的数据文件CloseableIterable<FileScanTask> fileScanTasks =table.newScan().useSnapshot(startingSnapshotId).filter(filter).ignoreResiduals().planFiles();try {StructType partitionType = table.spec().partitionType();// 初始化一个支持分区结构体为Key的Map,其Value为一组此分区下的待重写的数据文件// 这里的partitionType是分区键的Schema信息StructLikeMap<List<FileScanTask>> filesByPartition = StructLikeMap.create(partitionType);StructLike emptyStruct = GenericRecord.create(partitionType);fileScanTasks.forEach(task -> {// If a task uses an incompatible partition spec the data inside could contain values// which// belong to multiple partitions in the current spec. Treating all such files as// un-partitioned and// grouping them together helps to minimize new files made.// 如果一个数据文件的分区数据对应的Spec与表的当前分区Spec ID不同,则将这些文件都分类到一个空分区中,保证依然能够对这些文件进行重写StructLike taskPartition =task.file().specId() == table.spec().specId()? task.file().partition(): emptyStruct;List<FileScanTask> files = filesByPartition.get(taskPartition);if (files == null) {files = Lists.newArrayList();}files.add(task);filesByPartition.put(taskPartition, files);});// 这里对分类好的数据文件进行分组,基本逻辑与上面相同StructLikeMap<List<List<FileScanTask>>> fileGroupsByPartition =StructLikeMap.create(partitionType);filesByPartition.forEach((partition, tasks) -> {// strategy拥有父类BinPackStrategy的实现方法,支持对数据文件packing// 根据文件大小:如果指定了运行参数为REWRITE_ALL_DEFAULT=false,则会选择文件大小在[minFileSize,maxFileSize]之间的文件;// 根据Delete Files数量:如果数据文件对应的删除文件数量超过了delete-file-threshold阈值,则被会选择Iterable<FileScanTask> filtered = strategy.selectFilesToRewrite(tasks);// 对当前分区过滤后的数据文件进行分组,默认按如下的参数控制一个分组的数据大小// "max-file-group-size-bytes" = 1024L * 1024L * 1024L * 100L;// 100 GigabytesIterable<List<FileScanTask>> groupedTasks = strategy.planFileGroups(filtered);List<List<FileScanTask>> fileGroups = ImmutableList.copyOf(groupedTasks);if (fileGroups.size() > 0) {fileGroupsByPartition.put(partition, fileGroups);}});return fileGroupsByPartition;} finally {try {fileScanTasks.close();} catch (IOException io) {LOG.error("Cannot properly close file iterable while planning for rewrite", io);}}}
}
按分区生成文件组实例
public class RewriteDataFilesSparkActionextends BaseSnapshotUpdateSparkAction<RewriteDataFilesSparkAction> implements RewriteDataFiles {Stream<RewriteFileGroup> toGroupStream(RewriteExecutionContext ctx,Map<StructLike, List<List<FileScanTask>>> fileGroupsByPartition) {Stream<RewriteFileGroup> rewriteFileGroupStream =fileGroupsByPartition.entrySet().stream().flatMap(e -> {StructLike partition = e.getKey();List<List<FileScanTask>> fileGroups = e.getValue();return fileGroups.stream().map(tasks -> {// 为当前分组生成一个全局唯一的递增IDint globalIndex = ctx.currentGlobalIndex();// 为当前分区分配一个全局唯一的自增IDint partitionIndex = ctx.currentPartitionIndex(partition);FileGroupInfo info =new BaseRewriteDataFilesFileGroupInfo(globalIndex, partitionIndex, partition);// 创建一个RewriteFileGroup实例,保存重写前后的文件分组信息return new RewriteFileGroup(info, tasks);});});return rewriteFileGroupStream.sorted(rewriteGroupComparator());}
}
执行
部分提交拥有更大的容错性,由于分组生成多个任务并行执行,因此可以保证部分任务的失败不会影响其它文件组的重写。
而一次提交,则需要保证所有文件组都重写成功后,才能提交Snapshot。
部分提交
private Result doExecuteWithPartialProgress(RewriteExecutionContext ctx,Stream<RewriteFileGroup> groupStream,RewriteDataFilesCommitManager commitManager) {ExecutorService rewriteService = rewriteService();// Start Commit Service// 根据maxCommits的值,确定一次Commit需要包含多少个文件组// maxCommits默认值为10,意味着当10个文件组的完成时,作为一个Batch进行Commit,// 产生一个新的Snapshot。int groupsPerCommit = IntMath.divide(ctx.totalGroupCount(), maxCommits, RoundingMode.CEILING);RewriteDataFilesCommitManager.CommitService commitService =commitManager.service(groupsPerCommit);// CommitService是一个后台线程,用于搜集完成的重写分组,并以Batch的形式进行提交commitService.start();// Start rewrite tasks// 遍历所有的文件组,并对应生成一个独立的Task交由rewriteService并行执行Tasks.foreach(groupStream).suppressFailureWhenFinished().executeWith(rewriteService).noRetry() // rewrite失败,不重试.onFailure((fileGroup, exception) ->LOG.error("Failure during rewrite group {}", fileGroup.info(), exception))// 定义重写任务的执行逻辑,即rewriteFiles(...).run(fileGroup -> commitService.offer(rewriteFiles(ctx, fileGroup)));// shutdown()会保证所有的并行任务都已经处于完成状态rewriteService.shutdown();// Stop Commit servicecommitService.close();List<RewriteFileGroup> commitResults = commitService.results();if (commitResults.size() == 0) {LOG.error("{} is true but no rewrite commits succeeded. Check the logs to determine why the individual "+ "commits failed. If this is persistent it may help to increase {} which will break the rewrite operation "+ "into smaller commits.",PARTIAL_PROGRESS_ENABLED,PARTIAL_PROGRESS_MAX_COMMITS);}List<FileGroupRewriteResult> rewriteResults =commitResults.stream().map(RewriteFileGroup::asResult).collect(Collectors.toList());return new BaseRewriteDataFilesResult(rewriteResults);}
一次提交
Z-Order排序重写数据
@Overridepublic Set<DataFile> rewriteFiles(List<FileScanTask> filesToRewrite) {// 这个UDF提供了一些工具类方法,可以将指定的ZORDER排序字段的值转换成Bytes,或是生成ZORDER相关的数据SparkZOrderUDF zOrderUDF =new SparkZOrderUDF(zOrderColNames.size(), varLengthContribution, maxOutputSize);String groupID = UUID.randomUUID().toString();boolean requiresRepartition = !filesToRewrite.get(0).spec().equals(table().spec());SortOrder[] ordering;if (requiresRepartition) {// 如果表当前的分区Spec发生了变化,则需要对原数据repartition,以正确分区文件 ordering =SparkDistributionAndOrderingUtil.convert(SortOrderUtil.buildSortOrder(table(), sortOrder()));} else {ordering = SparkDistributionAndOrderingUtil.convert(sortOrder());}// 这里就是基于内置的,ICEZVALUE列,进行ZORDER排序Distribution distribution = Distributions.ordered(ordering);try {tableCache().add(groupID, table());manager().stageTasks(table(), groupID, filesToRewrite);// spark session from parentSparkSession spark = spark();// Reset Shuffle Partitions for our sortlong numOutputFiles =numOutputFiles((long) (inputFileSize(filesToRewrite) * sizeEstimateMultiple()));spark.conf().set(SQLConf.SHUFFLE_PARTITIONS().key(), Math.max(1, numOutputFiles));Dataset<Row> scanDF =spark.read().format("iceberg").option(SparkReadOptions.FILE_SCAN_TASK_SET_ID, groupID).load(groupID);Column[] originalColumns =Arrays.stream(scanDF.schema().names()).map(n -> functions.col(n)).toArray(Column[]::new);List<StructField> zOrderColumns =zOrderColNames.stream().map(scanDF.schema()::apply).collect(Collectors.toList());// 对每一个ZORDER的排序字段,应用zOrderUDF.sortedLexicographically(...)方法,// 产生一个新的列,数据类型为DataTypes.BinaryType,即字节数组,例如对于Integer类型的字段,其列名为"INT_ORDERED_BYTES"。Column zvalueArray =functions.array(zOrderColumns.stream().map(colStruct ->zOrderUDF.sortedLexicographically(functions.col(colStruct.name()), colStruct.dataType())).toArray(Column[]::new));// 追加到scanDF数据集中一个新的列,Z_COLUMN,其值为当前行的Z-COLUMNS字段产生的Z-Address字节数组Dataset<Row> zvalueDF = scanDF.withColumn(Z_COLUMN, zOrderUDF.interleaveBytes(zvalueArray));SQLConf sqlConf = spark.sessionState().conf();// 构建执行计划,zvalueDFLogicalPlan sortPlan = sortPlan(distribution, ordering, zvalueDF.logicalPlan(), sqlConf);Dataset<Row> sortedDf = new Dataset<>(spark, sortPlan, zvalueDF.encoder());// 真正地执行重写任务,同理将数据缓存起来,以groupId为键,方便在重试的时候sortedDf.select(originalColumns).write().format("iceberg").option(SparkWriteOptions.REWRITTEN_FILE_SCAN_TASK_SET_ID, groupID).option(SparkWriteOptions.TARGET_FILE_SIZE_BYTES, writeMaxFileSize()).option(SparkWriteOptions.USE_TABLE_DISTRIBUTION_AND_ORDERING, "false").mode("append").save(groupID);return rewriteCoordinator().fetchNewDataFiles(table(), groupID);} finally {// 收尾工作 tableCache().remove(groupID);manager().removeTasks(table(), groupID);rewriteCoordinator().clearRewrite(table(), groupID);}}