1、集群环境及问题描述
集群版本:6.8.X
集群节点:5节点(三个节点为主+数据节点,另外两个独立数据节点)。
问题描述:由于IP冲突,修改了一台服务器的IP,然后5台配置改了一下一次重启,能启动,但是连不上,后台各种报错。
2、问题讨论
节点换 IP 原因探讨:宿主机服务器的IP地址和别的服务器IP 冲突,所以要修改一台服务器的 IP地址。
不建议集群节点经常更换 IP,原因如下:
频繁更换 Elasticsearch 集群节点的 IP 地址可能会导致集群稳定性降低,节点发现困难,配置管理复杂化,数据复制和恢复问题,负载均衡配置困扰以及潜在的安全风险。因此,为了保持集群的稳定性和安全性,我们通常不建议频繁更改节点的 IP 地址。
还要考虑一个问题,如果集群规模越大,节点数越多,换 IP 带来的服务不可用时间会越长。
由于这是 6.8.X 版本的集群,每个节点的:discovery.zen.ping.unicast.hosts 都要做修改,就意味着所有集群都必须重启。所以,节点越多,重启后分配恢复时间越长,服务不可用时间越长。尤其线上密集访问性业务要非常慎重。
以上是认知大前提。
3、问题排查
但,上述更换节点 ip 已成为板上钉钉的事实,接下里只能想办法修改 IP、修改各个节点配置后,想办法让集群启动起来。
这里,先敲定排查思路,让问题尽可能的最小化。否则五个节点的日志会看得“眼花缭乱”。
昨晚我敲定的排查思路如下:
从node1、node2、node3三个主+数据节点入手,看为什么不能组建成集群?
也就是说,数据节点先不加入集群,仅node1、node2、node3三个节点,看能否组建成集群、选主成功?
核心点:找到和定位到当前节点不能组建成集群的原因?
核心排查过程记录和梳理如下:
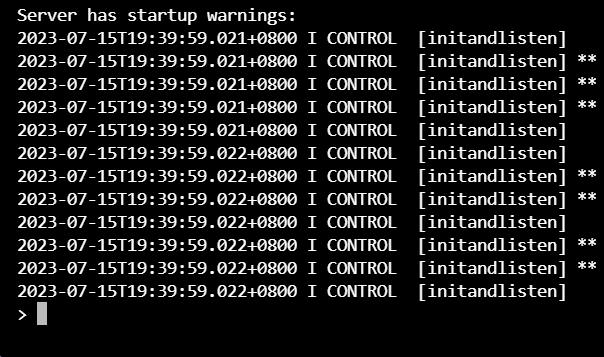
3.1 逐个节点启动,对任何日志猫腻都不放过。
发现了昨天的ip配置错误问题。

[2023-07-15T23:46:02,908][WARN ][o.e.d.z.UnicastZenPing ] [node-1] failed to resolve host [10.14.2·30.41:9300]
java.net.UnknownHostException: 10.14.2¡¤30.
at java.net.Inet6AddressImpl.lookupAllHostAddr(Native Method) ~[?:1.8.0_291]
at java.net.InetAddress$2.lookupAllHostAddr(InetAddress.java:929) ~[?:1.8.0_291]
at java.net.InetAddress.getAddressesFromNameService(InetAddress.java:1324) ~[?:1.8.0_291]
at java.net.InetAddress.getAllByName0(InetAddress.java:1277) ~[?:1.8.0_291]
at java.net.InetAddress.getAllByName(InetAddress.java:1193) ~[?:1.8.0_291]
at java.net.InetAddress.getAllByName(InetAddress.java:1127) ~[?:1.8.0_291]这是修改 IP 地址的误操作,肯定得修改,否则会有大量报错信息。IP地址不对,后面无从谈起。
3.2 在head插件等辅助工具不可用时,借助命令行排查节点是否加入集群。
大前提:只有集群构建成功后,head插件才能使用;只有集群是非红色状态(黄色或者最好绿色状态),kibana 才能正确访问。
而我们的节点是无法构建成功集群的,所以无法使用 kibana、head插件等工具排查问题。但部分命令行的原始方式还是可以用的。
本质是通过如下命令看看节点是否构成了集群。
GET http://IP:端口/_cat/nodes通过 postman 工具排查,如下所示,出现了“master_not_discovered_exception”异常,也就是不能发现主节点。
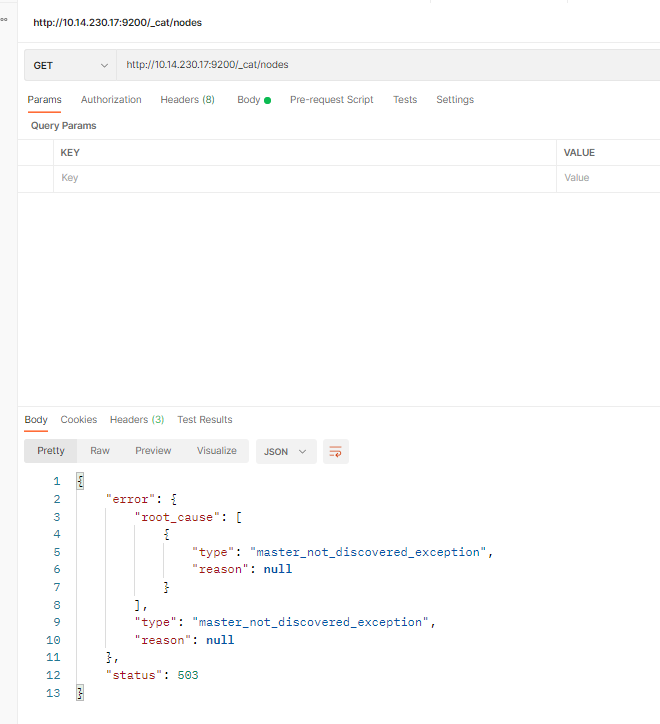
对比看一下正确的情况,下面就是两个节点已构成一个集群,mdi的含义分别是:master节点、data节点、ingest节点类型。
低版本叫节点类型,8.X 版本叫节点角色。
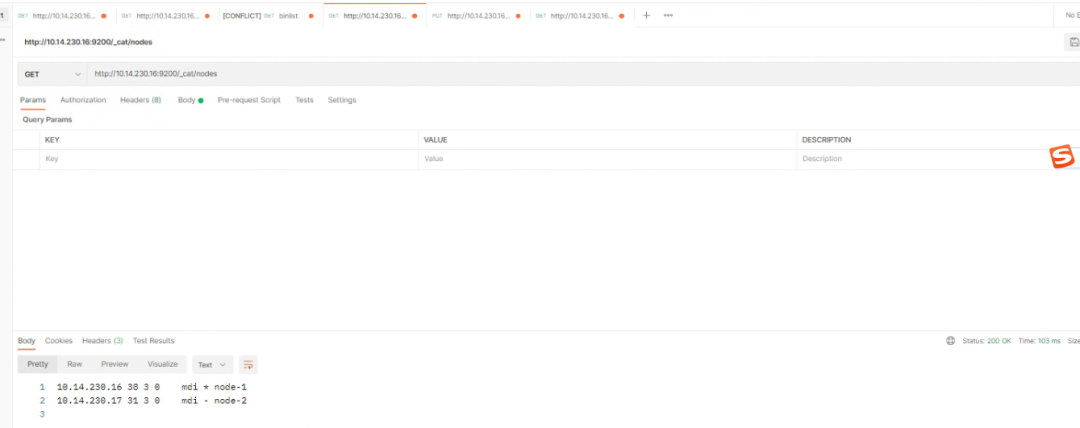
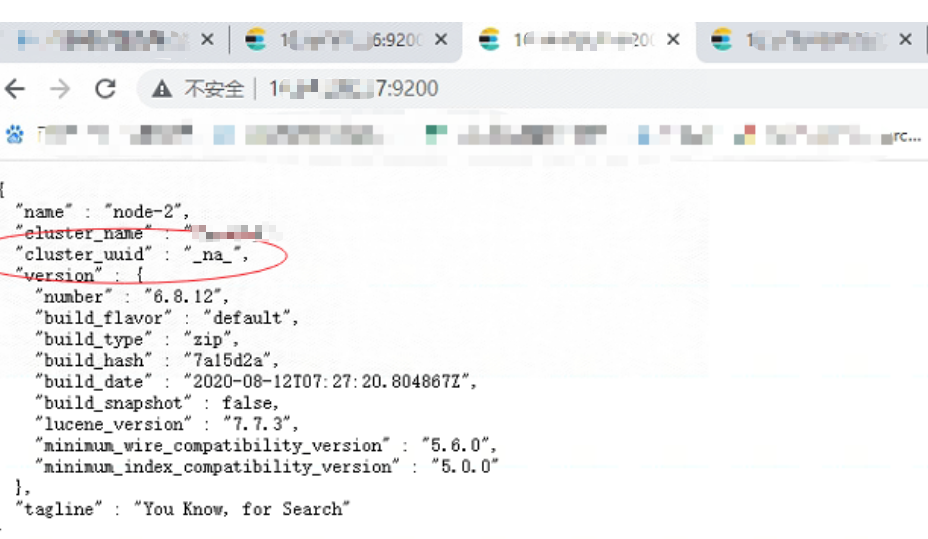
这里还有一个细节,如果集群 uuid 是“_na_” 只代表启动了,但是还未选主成功!
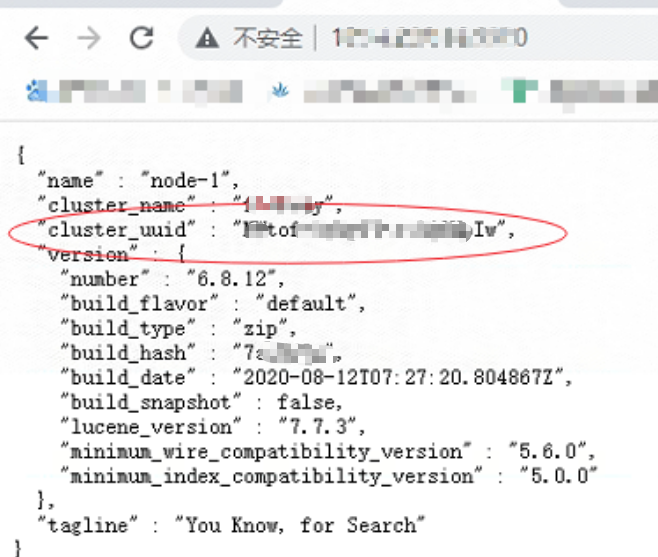
如果选主成功后,大致应该是下面的样子(所有节点的uuid 是一致的,这个非常重要)。
3.3 中间环节的多次异常,差点被带跑偏。
如下日志,我一直以为是网络问题。
排查了防火墙,ping 命令挨个验证都没有问题。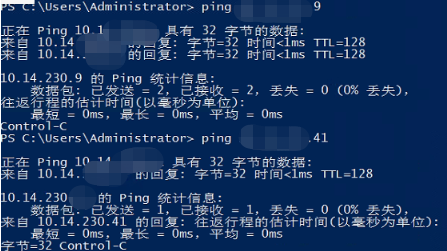
org.elasticsearch.transport.ConnectTransportException: [node-1][10.14.XXX.XX:9300] handshake_timeout[30s]
at org.elasticsearch.transport.TransportHandshaker.lambda$sendHandshake$1(TransportHandshaker.java:77) ~[elasticsearch-6.8.12.jar:6.8.12]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:681) [elasticsearch-6.8.12.jar:6.8.12]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_291]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_291]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_291]
[2023-07-16T00:58:53,697][WARN ][o.e.t.TcpTransport ] [node-2] exception caught on transport layer [Netty4TcpChannel{localAddress=/10.14.XXX.yy:60218, remoteAddress=/10.14.xxx.zz:9300}], closing connection
java.io.IOException: 远程主机强迫关闭了一个现有的连接。
at sun.nio.ch.SocketDispatcher.read0(Native Method) ~[?:?]
at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:43) ~[?:?]
at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223) ~[?:?]
at sun.nio.ch.IOUtil.read(IOUtil.java:197) ~[?:?]
at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:378) ~[?:?]
at io.netty.buffer.PooledHeapByteBuf.setBytes(PooledHeapByteBuf.java:261) ~[netty-buffer-4.1.32.Final.jar:4.1.32.Final]
at io.netty.buffer.AbstractByteBuf.writeBytes(AbstractByteBuf.java:1132) ~[netty-buffer-4.1.32.Final.jar:4.1.32.Final]
at io.netty.channel.socket.nio.NioSocketChannel.doReadBytes(NioSocketChannel.java:347) ~[netty-transport-4.1.32.Final.jar:4.1.32.Final]
at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:148) [netty-transport-4.1.32.Final.jar:4.1.32.Final]
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:656) [netty-transport-4.1.32.Final.jar:4.1.32.Final]
at io.netty.channel.nio.NioEventLoop.processSelectedKeysPlain(NioEventLoop.java:556) [netty-transport-4.1.32.Final.jar:4.1.32.Final]
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:510) [netty-transport-4.1.32.Final.jar:4.1.32.Final]
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:470) [netty-transport-4.1.32.Final.jar:4.1.32.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:909) [netty-common-4.1.32.Final.jar:4.1.32.Final]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_291]后面想其实还是内存不足导致的节点下线!这应该是两个节点一个掉线后,另外一个节点的连锁反应。
期间还发现了各个节点日期不一致问题,通过手动对齐时间方式进行了时间一致性对齐。
还将discovery.zen.ping_timeout 的值由 3s 调整到 100s。
discovery.zen.ping_timeout 是 Elasticsearch 集群设置中的一个参数,它决定了节点在考虑其他节点“不可达”之前应等待 ping 响应的时间。这个设置对于集群节点之间的通信和集群的稳定性非常重要。如果设置 discovery.zen.ping_timeout 为 3 秒(3s),这意味着每个节点在将另一个节点视为离线之前将等待其响应 3 秒。如果网络条件较差,或者Elasticsearch 集群负载很大,可能会导致超时,使得节点错误地认为其他节点已离线。这可能会引起不必要的重新选举和节点重新平衡,从而影响集群性能和稳定性。
3.4 我一直想回避,但这是根源所在。
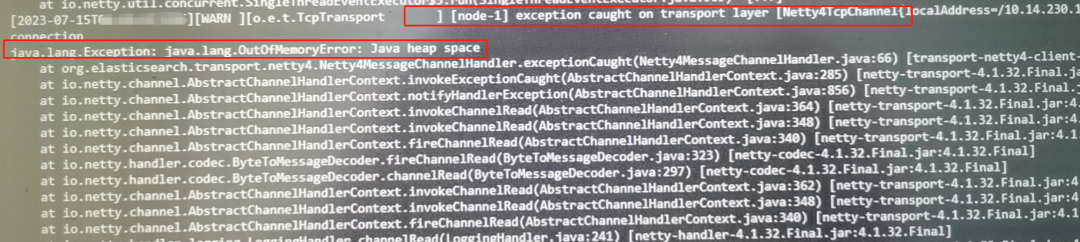
反复排查发现,如下日志就是根源,内存溢出了。
[2023-07-16T00:52:39,878][WARN ][o.e.m.j.JvmGcMonitorService] [node-2] [gc][153] overhead, spent [985ms] collecting in the last [1s]
[2023-07-16T00:52:44,238][INFO ][o.e.m.j.JvmGcMonitorService] [node-2] [gc][154] overhead, spent [1.6s] collecting in the last [4.3s]
[2023-07-16T00:52:44,253][ERROR][o.e.b.ElasticsearchUncaughtExceptionHandler] [node-2] fatal error in thread [elasticsearch[node-2][generic][T#1]], exiting
java.lang.OutOfMemoryError: Java heap space
at org.apache.lucene.util.fst.FST.<init>(FST.java:342) ~[lucene-core-7.7.3.jar:7.7.3 1a0d2a901dfec93676b0fe8be425101ceb754b85 - noble - 2020-04-21 10:31:55]
at org.apache.lucene.util.fst.FST.<init>(FST.java:274) ~[lucene-core-7.7.3.jar:7.7.3 1a0d2a901dfec93676b0fe8be425101ceb754b85 - noble - 2020-04-21 10:31:55]
at org.apache.lucene.codecs.blocktree.FieldReader.<init>(FieldReader.java:91) ~[lucene-core-7.7.3.jar:7.7.3 1a0d2a901dfec93676b0fe8be425101ceb754b85 - noble - 2020-04-21 10:31:55]
at org.apache.lucene.codecs.blocktree.BlockTreeTermsReader.<init>(BlockTreeTermsReader.java:202) ~[lucene-core-7.7.3.jar:7.7.3 1a0d2a901dfec93676b0fe8be425101ceb754b85 - noble - 2020-04-21 10:31:55]
2023-07-16T00:51:59,263][WARN ][o.e.m.j.JvmGcMonitorService] [node-2] [gc][124] overhead, spent [875ms] collecting in the last [1.1s]
[2023-07-16T00:52:00,826][WARN ][o.e.m.j.JvmGcMonitorService] [node-2] [gc][125] overhead, spent [1s] collecting in the last [1.5s]
[2023-07-16T00:52:01,920][WARN ][o.e.m.j.JvmGcMonitorService] [node-2] [gc][126] overhead, spent [938ms] collecting in the last [1s]
[2023-07-16T00:52:03,811][WARN ][o.e.m.j.JvmGcMonitorService] [node-2] [gc][127] overhead, spent [1.1s] collecting in the last [1.8s]
[2023-07-16T00:52:06,639][WARN ][o.e.m.j.JvmGcMonitorService] [node-2] [gc][129] overhead, spent [1s] collecting in the last [1.8s]
[2023-07-16T00:52:08,264][WARN ][o.e.m.j.JvmGcMonitorService] [node-2] [gc][130] overhead, spent [1.2s] collecting in the last [1.6s]
[2023-07-16T00:52:09,468][WARN ][o.e.m.j.JvmGcMonitorService] [node-2] [gc][131] overhead, spent [1s] collecting in the last [1.1s]什么原因导致的呢?堆内存设置的不合理。
可是 jvm.options 明明已经改动了呢,都是官方建议值。
但是,在日志排查的时候我看到了下面的日志。
[node-2] JVM arguments [-Xms1g, -Xmx1g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=75服务启动方式,我把jvm.options 改成了 128GB了,但是还是显示1GB,这就是问题根源。
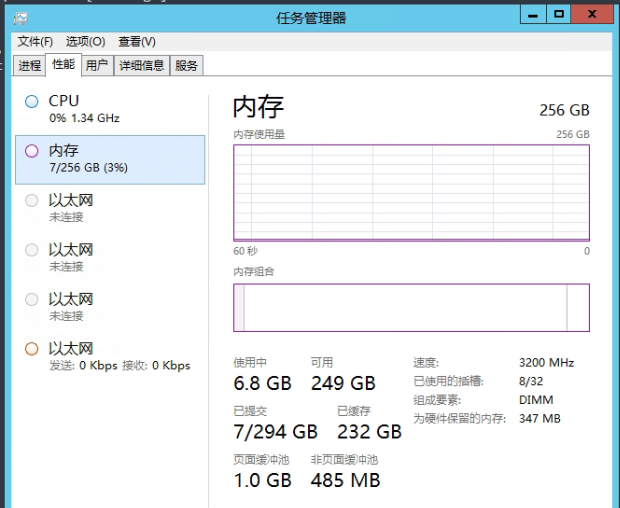
256 GB内存几乎没有怎么用。
后面,改成了elasticsearch.bat 的启动方式后,就搞定了。

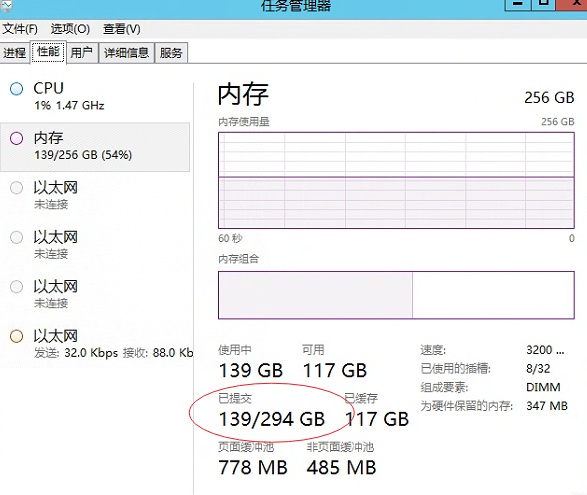
更进一步讲:以windows 服务启动的时候,集群的配置 jvm.options 没有读到导致的上面的内存问题及各种报错!
最终集群启动ok,集群健康状态为绿色。
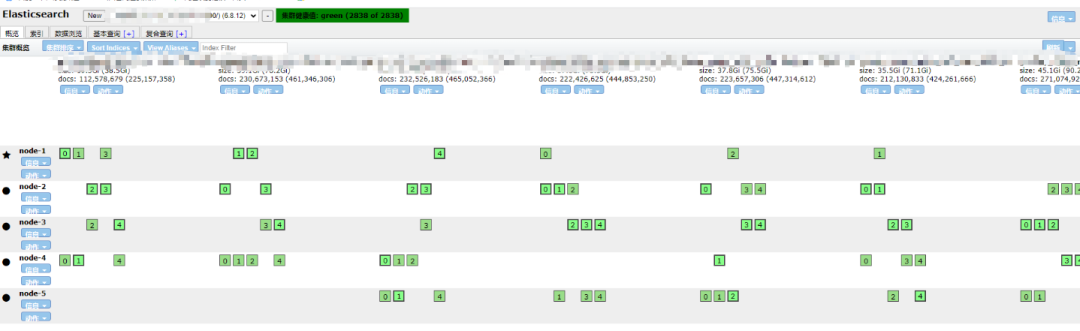
4、小结
类似问题没有更快的策略,只能逐个节点逐个日志进行排查。上述问题累计排查耗时大于 6 个小时以上,只有一点点排查,才能发现问题所在。
欢迎就类似问题留言讨论交流。
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
2023,做点事

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

大模型时代,抢先一步学习进阶干货!