select 查询
字段别名用 as (可以为中文) 例如 select ''
distinct 关键字 去重复值 例如select distinct deptno from test
where 条件过滤
and or 和 not运算符 and同时成立 or有一个成立就可以了 优先级and>or>not不符合(!)
in 匹配多个值 select 1 where 1 in (3,2)
Between: SELECT * FROM Websites
WHERE alexa BETWEEN 1 AND 20; >=1 <=20
like搜索匹配的字符串: select * from test where name like '王%' 查询到 王111111 %匹配任意长度的字符串 —表示单一的字符 select * from test where name like '_王' 查询到1王而不会查询到11王
order by排序 默认是升序 从低到高 可以加关键字 desc降序 例如select name,salary from test order by salary desc;
单行注释-- 多行注释 /* */
null 空值 select 1 where '' is null ->no 我们一般来说把不知道的值设置为null
not in的坑 not in表示不在集合中 not in 不能对空值进行判断
update更新一个或多个字段 update 表名 set 字段名 where 条件
例如 update test set name=1 where name='zs'
update中使用子查询 select * from test where deptno in (select deptno from depart where managerno=2 or managerno=3)
Delete删除记录 truncate table == delete from table 效率不同 truncate比delete高很多,把这个分配空间直接删除
Delete中使用子查询 从员工表中删除所有在二楼办公的员工
delete from test where deptno in (select deptno from test where loc like '二楼')
传统的多表连接方式
select name,dname,departments.deptno from employees,departments where employess.deptno=departments.deptno
一般来说,我们可以使用别名
select name,dname,d.deptno from employees e,departments d where e.deptno=d.deptno
inner join内连接 select name,dname,e.deptno from employees e inner join departments d on e.deptno=d.deptno 就是把这个俩个表连接在一起,好查询
self join 自连接 就是表自己连接自己 奥秘就是一个表使用不同的别名进行连接,别名好像是表的实体化一样,化成多个表进行连接
select t1.name,t2.empno,t1.empno from test t1 join test t2 on t1.name=t2.name and t1.empno<>t2.empno 这样就能找到 员工名字相同但是员工号不同的记录
outer join 外连接

select * from A inner join B on A.id = B.id
select * from A inner join B on A.id = B.id
select * from A inner join B on A.id = B.id
cross join 交叉连接
select * from a cross join b
select * from a full join b on a.id = b.id
union集合联合
select empno,deptno from employees union select managerno,deptno from departments
加到一张表中,重复的只加一次
select empno,deptno from employees union all select managerno,deptno from departments
重复的也会加
select empno,deptno from employees intersect select managerno,deptno from departments
俩张表中交互的内容
常用的分组函数
max()最大 min()最小 avg() 平均 sum()汇总 count(*)记录数
group by 分组
select deptno 部门,avg(salary) as 平均工资 from employees group by deptno 按部门分类 这里有一个注意点当跟order by 结合起用 顺序不能出问题现有group by 然后有order by
having过滤分组 在groupby后面的专门用来修饰group by
子查询 就是用一条数据实现多条数据的查询 查询入职时间比李四早的员工 select name from test where date<(select date from test where name='李四')
IN运算符中的子查询 查询所有在二楼办公的员工的姓名 select empno,name from employess where deptno in (select deptno from departments where depart loc='二楼')
子查询和连接 select empno,name from employess join departments on employees.deptno=departments.deptno where loc='二楼' 效果也是一样的
all关键字 查询比所有1号部门所有员工工资高的员工
select name from employees where salary > all (select salary from employees where deptno=1);
ANY关键字
查询比2号部门任一员工工资低的员工
select name from test where salary < any (select salary from test where deptno=2)
其次in都可以修改为any
相关子查询 就是在子查询中使用外部查询的值
查询出比自己部门平均工资高的员工
select name,deptno,salary from test t where salary>(select avg(salary) from test where deptno=e.deptno)
变蓝色的就是外部查询 括号里面,绿色的就是子查询
EXISTS运算符
EXISTS 运算符用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。
有时用来替代in 执行效率不同 如果子查询返回来的记录比较多,使用exists 如果主记录比较多,那就使用in
SELECT column_name(s) FROM table_name WHERE EXISTS (SELECT column_name FROM table_name WHERE condition);
select子句中的子查询
select name,salary,deptno,(select avg(salary) from test where deptno=e.deptno) 部门平均工资
from test t
from子句中的子查询
select * from (
select name,salary,deptno,(select avg(salary) from test where deptno=e.deptno) 部门平均工资
from test t
)t2 order by salary
PARTITION BY 分区函数 这个函数跟group by有相似之处,但是功能要比group by厉害很多
写法:over(partition by cno order by degree )
SELECT *
FROM (select sno,cno,degree,
rank()over(partition by cno order by degree desc) mm
from score)
where mm = 1;


case where 表达式
select empno,deptno,
-> case deptno
->when 1 then '开发部'
->when 2 then '测试部'
-> when 3 then '销售部'
-> else '其他部门' end deptname
-> from employees

cte共用表达式

with 表名(自己定)as
(
select * from test where id in (select name from test2)
) //结果集
select * from 表明
view视图
在 SQL 中,视图(View)是一个虚拟表,它由一个查询定义而成,并且可以像真实的表一样进行查询操作。视图并不实际存储数据,而是根据定义时指定的查询结果动态生成。
视图可以简化复杂的查询操作,并提供了一种安全机制,可以隐藏底层数据结构和敏感信息。通过创建视图,用户可以以一种更简单、更易理解的方式访问数据库中的数据。
创建视图
CREATE VIEW high_salary_employees AS
SELECT name, position, salary
FROM employees
WHERE salary >= 5000;
SELECT * FROM high_salary_employees;
查看视图
SHOW COLUMNS FROM high_salary_employees;
修改视图
ALTER VIEW high_salary_employees AS
SELECT name, position, salary
FROM employees
WHERE salary >= 6000;
更新视图数据
UPDATE employees
SET salary = 5500
WHERE employee_id = 123;
删除视图
DROP VIEW high_salary_employees;
注释注入
就是原本是select * from test where name='zs' and password='123';
一个完整的句子,但是前台如果输入zs';# 那么就会变成
select * from test where name='zs';#' and password='123';它会把查询到的所有句子返回
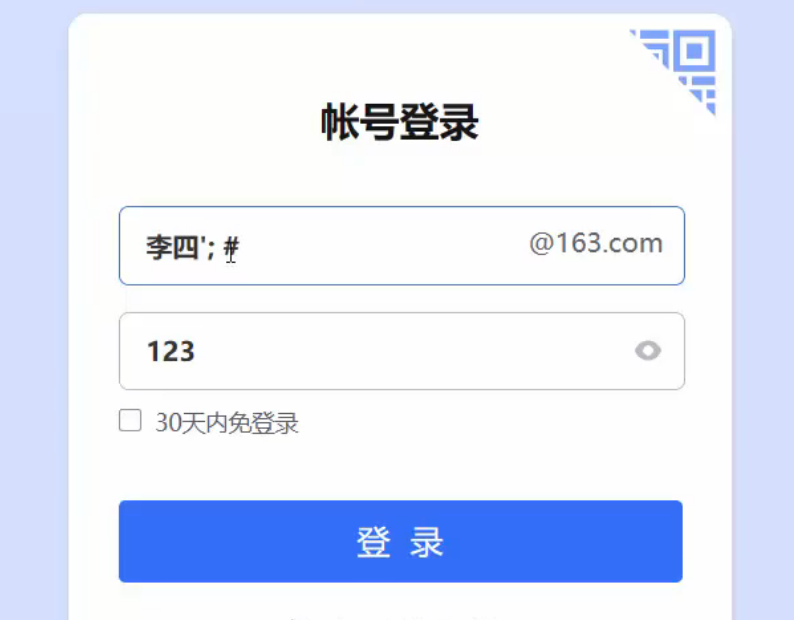
也可以select * from test where name='zs' and password=123 or 1=1;