Mysql优化器会对SQL进行优化生成执行计划,后续所有的执行流程都是按照这样的执行计划执行,在此阶段就会决策评估索引的选择,mysql在对于索引选择会有关键性的评估依据:成本
说白了,假如有2个索引,优化器会分别对这两个索引使用成本进行评估,这里会涉及到mysql成本评估模型。最终得到成本结果cost,最终对比两者的成本,成本低被选择。
一、查看成本COST
方式一 EXPLAIN FORMAT=JSON
这种方式在SQL执行流程已经介绍过,它包括了最终选择的索引执行计划成本信息。如果想要看更详细的成本决策信息,可以通过OPTIMIZER_TRACE(优化器跟踪)进行跟踪查看。
方式二 OEPTIMIZER_TRACE
在Mysql5.6之后,支持了OEPTIMIZER_TRACE(优化器跟踪)功能,可以在SQL执行后,跟踪记录当前SQL执行优化过程,类似于探针监控PINPOINT。该功能默认关闭状态,可以手动开启,当然在生产区不建议开启,因为会有额外性能损耗。
show variables like '%optimizer_trace%';
开启:
set optimizer_trace="enabled=on",end_markers_in_json=on这里默认limit=1 ,offset=-1 ,表示显示最后一条记录,具体可以根据需求来配置:MySQL: The Optimizer Trace
二、SQL优化跟踪
开启OPTIMIZER_TRACE之后,就可以进行优化器跟踪功能,比如执行完如下sql
select * from project where tenantsid = 286478108025408
查看优化器内容:
select * from information_schema.optimizer_trace limit 1; // 显示最近一条| select * from project where tenantsid = 286478108025408 | { // 原始SQL信息"steps": [{1. 准备阶段"join_preparation": {"select#": 1,"steps": [{// 拓展查询内容,select * 会被转成所有可达字段"expanded_query": "/* select#1 */ select `project`.`tenantsid` AS `tenantsid`,`project`.`project_id` AS `project_id`,`project`.`code` AS `code`,`project`.`name` AS `name`,`project`.`sales_code` AS `sales_code`,`project`.`sales_name` AS `sales_name` from `project` where (`project`.`tenantsid` = 286478108025408)"}]} },{ // 2. 优化阶段"join_optimization": {"select#": 1,"steps": [{// 2.1 条件优化过程 "condition_processing": {"condition": "WHERE", "original_condition": "(`project`.`tenantsid` = 286478108025408)", // 原始的条件"steps": [{"transformation": "equality_propagation", // 开始等价替换步骤 , 比如where a=1 and b=a ==> where a=1 and b=1"resulting_condition": "multiple equal(286478108025408, `project`.`tenantsid`)" // 没有可替换},{"transformation": "constant_propagation", // 常常量条件句转换"resulting_condition": "multiple equal(286478108025408, `project`.`tenantsid`)" // 没有可替换},{"transformation": "trivial_condition_removal", // 无效条件去除 ,比如 where a >10 and a > 5 ==> where a>10"resulting_condition": "multiple equal(286478108025408, `project`.`tenantsid`)" // 没有可替换}] /* steps */} },{"substitute_generated_columns": {} /* substitute_generated_columns */},{// 2.2 多表关联关系信息,如果为多表,则会有多个表信息"table_dependencies": [{"table": "`project`","row_may_be_null": false,"map_bit": 0, // 表的映射编号,从0开始递增"depends_on_map_bits": [ // 依赖的映射表,当使用STRAIGHT_JOIN强行控制连接顺序或者LEFT JOIN/RIGHT JOIN有顺序差别时,会在depends_on_map_bits中展示前置表的map_bit值] }] },{// 2.3 列出所有可用的ref类型的索引"ref_optimizer_key_uses": [{"table": "`project`","field": "tenantsid","equals": "286478108025408","null_rejecting": false},{"table": "`project`","field": "tenantsid","equals": "286478108025408","null_rejecting": false}]},{// 2.4 扫描行数评估(核心),Mysql会将所有可使用到的索引进行评估和成本计算,最终选择最优的成本索引"rows_estimation": [{// 2.4.1 当前表扫描分析 "table": "`project`","range_analysis": {"table_scan": { // 全表扫描计算"rows": 6212, // 预估扫描行数,预估值"cost": 1271.5 // 成本} ,//判断所有可能的索引是否可用"potential_range_indexes": [ {"index": "PRIMARY", // 主键索引"usable": false, // 不可用"cause": "not_applicable" // 原因:不适合使用},{"index": "index_01", // index_01索引"usable": true, // 可以使用(不代表就要用)"key_parts": [ // 使用到的索引列 "tenantsid","code","name","project_id"]},{"index": "index02", // index_02索引"usable": true, // 可以使用(不代表就要用)"key_parts": [ // 使用到的索引列 "tenantsid","name","sales_code","code","project_id"]}] ,"setup_range_conditions": [ //如果有可下推的条件,则带条件考虑范围查询] ,"group_index_range": { // 是否有合适的索引处理分组"chosen": false, // 无"cause": "not_group_by_or_distinct" // 原因:没有grouy或者distinct使用} // 索引扫描成本分析"analyzing_range_alternatives": {"range_scan_alternatives": [{"index": "index_01", // 对index_01索引扫描进行分析"ranges": [ // 扫描条件"286478108025408 <= tenantsid <= 286478108025408" ] ,"index_dives_for_eq_ranges": true, // 是否使用idnex_dives(下面介绍下),精确统计"rowid_ordered": false, // 扫描的结果集是否按照主键PK进行排序"using_mrr": false, // 是否使用到MRR算法(下面也提一下)"index_only": false, // 是否仅仅使用到索引扫面就能满足,即是否索引覆盖了 "rows": 3106, // 预估扫描行数(预估值)"cost": 3728.2, // 计算成本"chosen": false, // 不选择 ,当然这个还不是最终结论,在 best_access_path 阶段,MySQL 会根据最优索引计算最终的成本修正的部分:每个表的大小、碎片率和使用率不同,所以最终的成本也会不同、另外还有根据当前的系统负载来调整成本,所以在做索引分析时,会以best_access_path结论为主"cause": "cost" // 原因:成本相对高},{"index": "index02", // 同上,因为使用索引条件相同,所以与index_01整体就没什么差异"ranges": ["286478108025408 <= tenantsid <= 286478108025408"] ,"index_dives_for_eq_ranges": true,"rowid_ordered": false,"using_mrr": false,"index_only": false,"rows": 3106,"cost": 3728.2,"chosen": false,"cause": "cost"}] ,"analyzing_roworder_intersect": { // 分析是否使用了索引合并(index merge)"usable": false, // 未使用"cause": "too_few_roworder_scans" // 原因:太少有序扫描行} } }}] },// 2.5 执行计划评估和选择(深思熟虑后的结论){"considered_execution_plans": [{"plan_prefix": [ // 前置执行计划] ,"table": "`project`","best_access_path": {// 深思熟虑后的执行计划路径选择"considered_access_paths": [{"access_type": "ref", // 所以类型"index": "index_01", // idnex_01索引"rows": 3106, // 扫描行数(预估值)"cost": 702.2, // 最终执行计划路径成本。从这里可以看出来上面对索引成本评估的数据和这里是有差距,这里就是在索引估算结果基础上进一步修正,评估出访问路径成本"chosen": true // 确定选择使用},{"access_type": "ref", // 同上"index": "index02","rows": 3106,"cost": 702.2,"chosen": false},{"rows_to_scan": 6212, // 全表扫描的成本"access_type": "scan","resulting_rows": 6212,"cost": 1269.4,"chosen": false}] } ,"condition_filtering_pct": 100, //类似于explain的filtered列,是一个估算值"rows_for_plan": 3106, // 扫描行数"cost_for_plan": 702.2, // 最优的路径成本"chosen": true}] },// 附加条件信息,除了原始的条件之外,优化器可能会附件一些条件,在不印象结果的基础上提高效能{"attaching_conditions_to_tables": {"original_condition": "(`project`.`tenantsid` = 286478108025408)", // 原始条件"attached_conditions_computation": [ 使用启发式算法计算已使用的索引,如果已使用的索引的访问类型是ref,则计算用range能否使用组合索引中更多的列,如果可以,则用range的方式替换ref] ,// 附件条件信息"attached_conditions_summary": [{"table": "`project`","attached": null}] } },{"refine_plan": [ //改善执行计划{"table": "`project`"}] }] } },// 3. 执行步骤{"join_execution": {"select#": 1,"steps": [] /* steps */} /* join_execution */}] /* steps */
} 上面针对trace分析结果做了详细的解释,报文比较大,针对优化分析来说,可以按照下面侧重点来关注:
2、rows_estimation步骤-索引成本计算
(1)Mysql成本理解
Mysql在计算成本时候分为IO和CPU两个成本,即最终的成本数据也就是两者之和。
IO成本:从磁盘读取数据页加载到内存的过程。
CPU成本:数据被加载到内存后,读取和检索记录是否满足搜索要求以及结果集排序等操作。
在Mysql5.7版本,并不能准确预测某个查询需要访问的数据中有哪些已经加载到内存中,有哪些还停留在磁盘上。所以MySQL很粗暴的认为不管有没有加载到内存中,使用的成本都是1.0。而在8.0版本中的能更加准确的预测是否加入到缓存了,成本为0.25;
不需要太深入,只要记住:在Mysql5.7版本中:
1、IO成本:读取一个页面花费的成本默认是1.0
2、CPU成本:读取以及检测一条记录是否符合搜索条件的成本默认是0.2
这些数值可以理解为系数,比如从磁盘读取一个数据块过程,需要的成本为1
索引成本计算:
COST = IO成本 + CPU成本
那我们依照上面的trace结论来说明下的,成本计算
(2)索引成本计算
A、全表扫描成本计算
对于InnoDB存储引擎来说,全表扫描的意思就是把聚集索引中的记录都依次与给定的搜索条件进行比较,把符合搜索条件的记录加入到结果集中。 所以需要将聚集引对应的页面加载到内存中,然后再检测记录是否符合搜索条件。
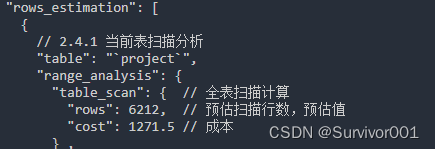
全表扫描计算公式:数据页(IO成本)* 1.0 + 数据行数 * 0.2 (CPU成本)
解释:
1、全表扫描时,数据会以页单位读取到内存中,所以当前表一共多少数据页就需要多少次读取,即为IO成本
2、数据读取到内存后,需要对每个数据进行读取和检索,N笔数据就需要N*0.25的CPU成本。
因此我们就需要得到这两数据:页数、数据行数
这里page数指的是数据占用业务,而不是innodb底层数据页数,所以能用innodb_ruby来查看,我们可以通过:
show table status like 'project'
或者
select data_length,table_rows from information_schema.tables where table_name = 'project'
数据页数 = data_length / 16(页大小kb) / 1024 = 27
数据行数 = 6212(预估值)
IO成本 = 27 * 1.0 + 1(微调值,不用关心) = 28
CPU成本 = 6212 * 0.2 + 1.1(微调值,不用关心) = 1243.5
cost成本 = 28 + 1243.5 = 1271.5 (与上面相同)
B、索引成本计算
index01索引成本计算
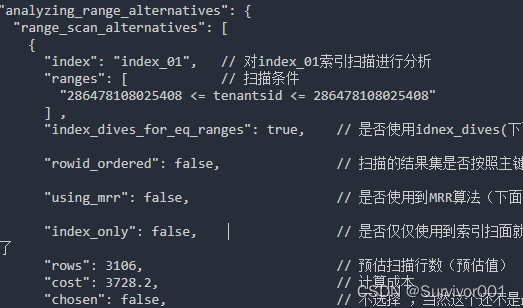
二级索引成本计算 = IO成本+ 数据数据CPU成本 + 回表IO成本 + 回表CPU成本
这个流程前面有说过:SQL优化-深入了解SQL处理流程原理(Server层与存储引擎交互、数据管理结构)-CSDN博客
索引IO成本 = 1 * 1(Mysql认为一个区间数据获取成本就是1次IO,这里区间就是
*** <= tenantsid <=**** , 这个解释也说得通,因为同一个区间页是连续存储的,读取效率快)
索引数据CPU成本 = 3106 * 0.2 = 621.2
回表IO成本 = 3106 * 1.0(因为回表是随机IO读取,所以每1条数据都需要一次IO)= 3106
回表CPU成本 = 3106 * 0.2 = 621.2
总成本:1 + 621.2 + 3106 + 621.2 = 4349.4
因为在MySQL的实际计算中,在和全文扫描比较成本时,使用索引的成本会去除掉读取和检测回表后聚簇索引记录的成本,所以结果是4349.4 - 621.2 = 3728.2
B、连接表成本
对驱动表进行查询后得到的记录条数称之为驱动表的扇出(fanout)。很显然驱动表的扇出值越小,对被驱动表的查询次数也就越少,连接查询的总成本也就越低。
连接查询总成本 = 单次访问驱动表的成本 + 驱动表扇出数 x 单次访问被驱动表的成本
注意:trace成本分析时可以根据索引成本结果来分析索引选择过程,但是索引成本结果并不是最终执行计划结果,最终的执行计划成本best_access_path,会基于索引成本结果进一步修正,比如每个表的大小、碎片率和使用率不同,所以最终的成本也会不同、另外还有根据当前的系统负载来调整成本。所以会看到best_access_path成本和索引成本有差异,最终也是按照best_access_path结果来决定最终的执行计划路径。
结论和优化建议:
OPTIMIZER_TRACE可以对SQL进行优化器跟踪,可以帮助我们了解优化器过程,同时可以通过此信息了解索引决策。在实际开发中可能并不需要这么详细的计算索引使用成本,但是通过对以上知识了解我们可以等到结论和优化建议:
1、索引目的就是快速的定位数据,得出扫描数据,即扫描数据越少索引成本越低,效率越快。因此索引设计时,索引栏位尽量要保证选择性高,即表中当前栏位重复率小的数据,可以通过索引基数(Cardinality,不重复的数据)来识别,这样能保证使用索引时,能过滤掉更多的数据。
2、并不是有了索引就能使用到索引,通过SQL执行流程和成本评估,当扫描行数过大,同时需要回表时,可能最终的成本很高,这时可能会走全表扫描。
3、可以看出来发生回表时,成本会增幅很大,因为需要随机IO,所以几乎每一条扫描数据都需要1成本,所以尽量减少回表次数就很重要。
4、Mysql虽然认为每一个区间IO成本就是1,但是可能存在多单点区间场景,比如in查询,每个in元素都是一个单点区间,即1次IO成本(这里还涉及到一个index_dives,后续再说吧)。所以尽量减少单点区间数量,避免因为成本太高,而走全表扫描。
5、你写的SQL在优化器优化下可能会发生很大的变化,比如关联表顺序、连接字段可能都在优化器作用下进行调整,所以具体分析SQL执行过程要看详细执行计划,而不是SQL本身。