Background
真实世界的图上节点的标签数据是很难拿到的。
因此图转移学习被提出将知识从标记的源图转移出来,以帮助预测域变化的目标图中节点的标签。
尽管图迁移学习算法取得了重大进展,但它们通常假定源图中的所有节点都被标记出来了。
因此文章定义了半监督域自适应框架来进行图上的节点分类。
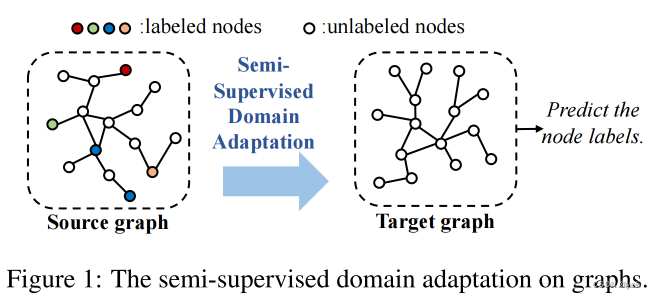
半监督域自适应面临2个挑战:
- 如何克服跨域带来的域转移问题,学习图的域不变信息来进行预测?
- 如何缓解标签稀疏的问题
Contributions
- 为了解决第一个挑战,文章提出在原图编码的时候加入 shift parameter ,并且提出一个对抗迁移模块去学习域不变节点表征
- 为了缓解标签稀疏,提出一个伪标签方法,使用后验评分来监督未标记节点的训练,提高了模型对目标图的鉴别能力。
- 实验效果好
Related Works
domain adaptation:
基于距离的方法:
基于距离的方法显式地计算源域和目标域之间的分布距离,并在嵌入空间中最小化它们。
基于对抗学习的方法:
通常在隐藏嵌入之上训练一个域鉴别器,并试图以隐式的方式融合它进行域对齐
Graph Transfer Learning:
大多数工作在图学习上建立了类似于那些在图像上的方法,而没有考虑图的复杂结构或显式地利用图的拓扑信息。
Semi-supervised Learning on Graphs.
针对节点分类,即图上只有少数节点有标签
Problem definition
源域(少量标签、目标域(没有标签 他们在数据分布上有明显的不同,但是共享相同的标签空间。
文章的目的是学习一个模型,在部分标记的源图的帮助下,准确地预测目标图中的节点类。
Methodology
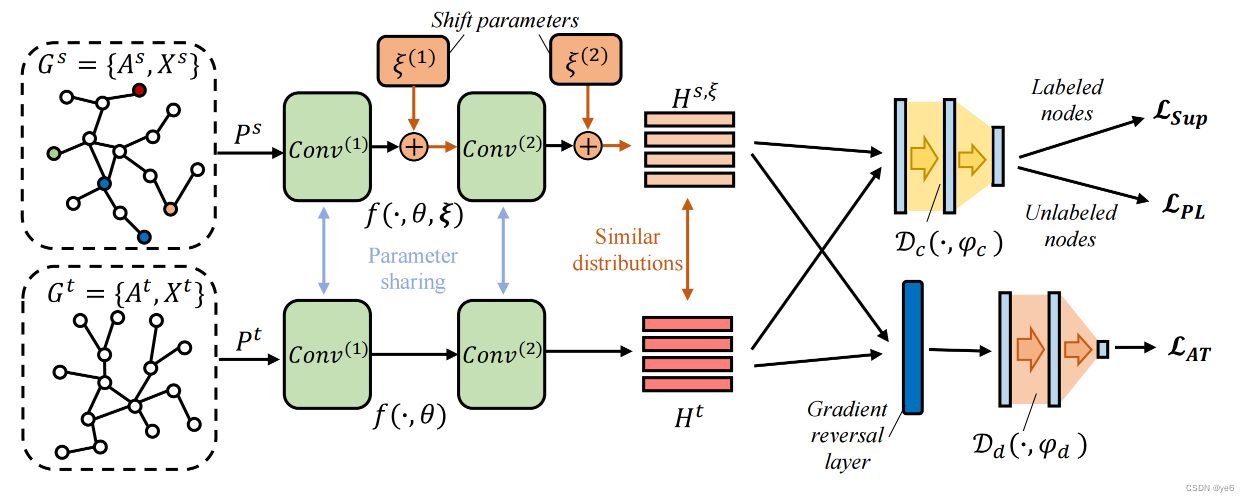
- Node embedding generalization:探索两个图中的高阶结构化信息来学习广义节点表示。
- Adversarial transformation:在源图中引入了自适应分布的位移参数,并对一个域鉴别器以对抗性的方式进行训练。
- Pseudo-labeling with Posterior Scores :解决标签稀疏问题。
Node embedding generalization
- 计算节点之间的 Positive Pointwise Mutual Information (PPMI)来探索高阶无标签图拓扑信息,并且使用图卷积网络去编码节点到泛化的低维空间。 【PPMI是一种用于衡量两个事件之间关联程度的统计量。它通常用于自然语言处理和信息检索领域
- 根据PPMI这个指标获得一个矩阵 P P P, P i , j P_{i,j} Pi,j代表节点i与j之间的相关性。


Adversarial Transformation via Shifting
领域自适应的一般学习目标是训练一个特征编码器来消除分布。
通常,域自适应的一般学习目标是训练一个特征编码器来消除源域与目标域之间的分布差异 ,生成在两个域上分布相似的embedding。
通过在输入空间上添加可训练参数(如扰动)来执行迁移已被证明在将一个分布转移到另一个分布方面是有效的。
文章提出了一个对抗变换模块,其目的是在源图上添加移位参数来修改其分布,并使用对抗学习来训练 graph encoder和shift parameters,以对齐跨域分布。
其中optimization objective定义为:

其 D d D_{d} Dd是一个域鉴别器,用于鉴别输入的节点embedding属于目标域还是源域;
具有shift parameters的编码器则生成难以区分的源节点嵌入,最后产生域不变节点嵌入。
Pseudo-Labeling with Posterior Scores
而在有监督情况下,由于标签比较少,所以容易导致过拟合。
特别是,在没有任何监督的情况下,目标图中分布在边界附近、远离其对应类的簇的质心的节点很容易被误分类。
文章提出了一种新的基于节点后验评分的伪标记策略,以提高对未标记节点的预测精度。
具体步骤:
在每次训练中,更新源域与目标域中原始无标签节点的伪标签;
文章假设节点靠近它们的伪标签聚类的结构质心则更容易被分类成功,文章将这种节点的伪标签视为更高质量的自监督信号,旨在提高这些节点embedding的识别能力。
因此,文章引入一个后验得分来定义ni如何接近其重构邻接矩阵P上的伪标签簇的结构质心:
从属于类X的节点到节点 n j n_{j} nj的互信息(变量间相互依赖性的量度),
文章中认为如果一个节点拥有的伪标签X与其他真实标签为X的节点的互信息值大,那么可以认为该节点的是接近类X的质心的,且 w i w_{i} wi值也会变大。
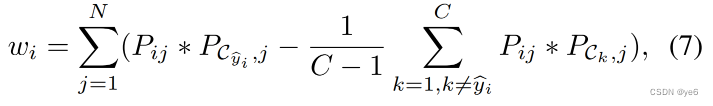
伪标签的损失函数如下所示:

最终的loss function:
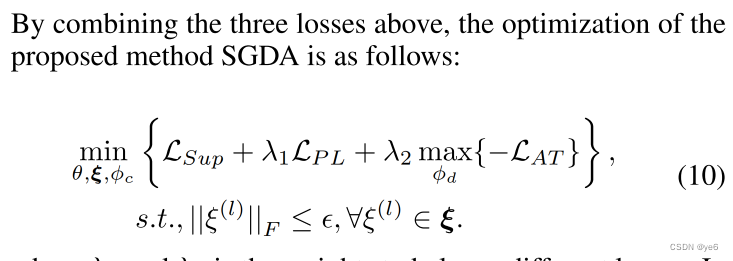
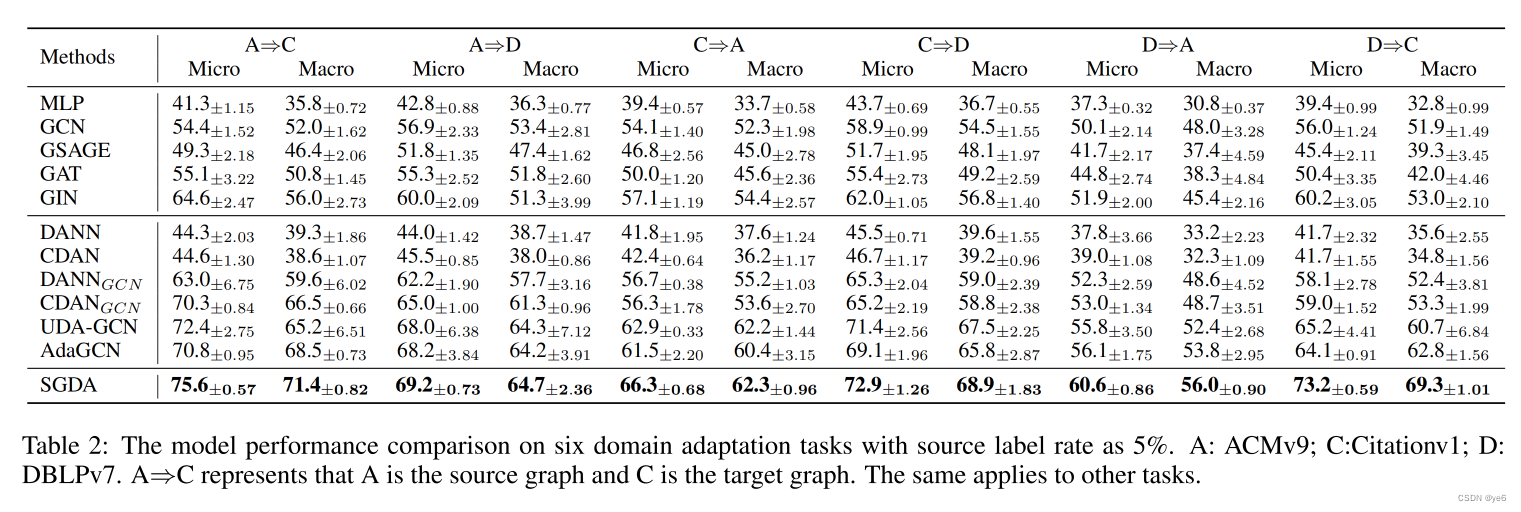
Experiment
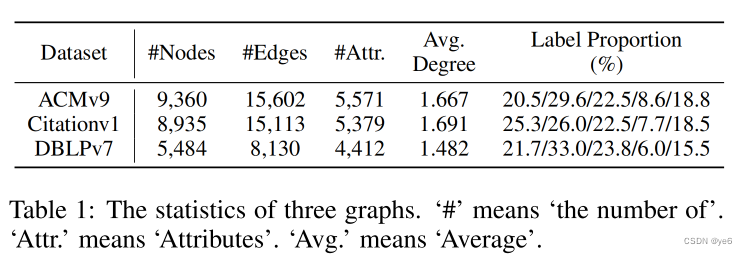
数据集:
conclusion:
- 提出了一个新的图半监督域适应研究问题
- 提出了一种称为SGDA的方法,它使用shift parameters和对抗性学习来实现模型迁移。
- 此外,SGDA还使用带有自适应后验分数的伪标签来缓解标签稀疏的问题
读后感
框架图看了3遍没看懂什么意思,只知道会产生三种loss
感觉伪标签这块解释的有点绕,涉及到很多指标计算或者处理细节;