一:Scrapy介绍
1.Scrapy是什么?
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架(异步爬虫框架)
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片
Scrapy使用了Twisted异步网络框架,可以加快我们的下载速度
- 异步和非阻塞的区别
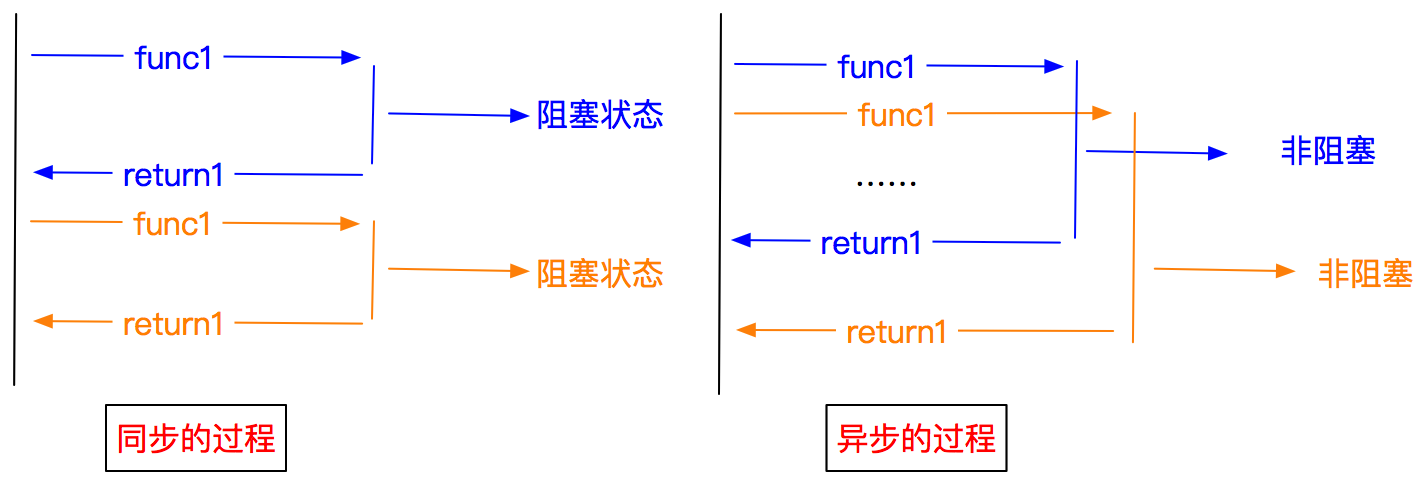
异步:调用在发出之后,这个调用就直接返回,不管有无结果
非阻塞:关注的是程序在等待调用结果时的状态,指在不能立刻得到结果之前,该调用不会阻塞当前线程
2.Scrapy的优势
爬虫必备的技术
- 能够使我们的爬虫程序更加稳定 效率更高(多线程)
- 配置和可扩展性非常强(很灵活)
downloader下载器(基于多线程的) 发送请求 获取响应的
3.Scrapy参考学习
scrapy官方学习网址:https://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
最新的:https://docs.scrapy.org/en/latest/
4.Scrapy的安装
pip install scrapy==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
二:Scrapy工作流程
一种爬虫方式:

另一种爬虫方式:
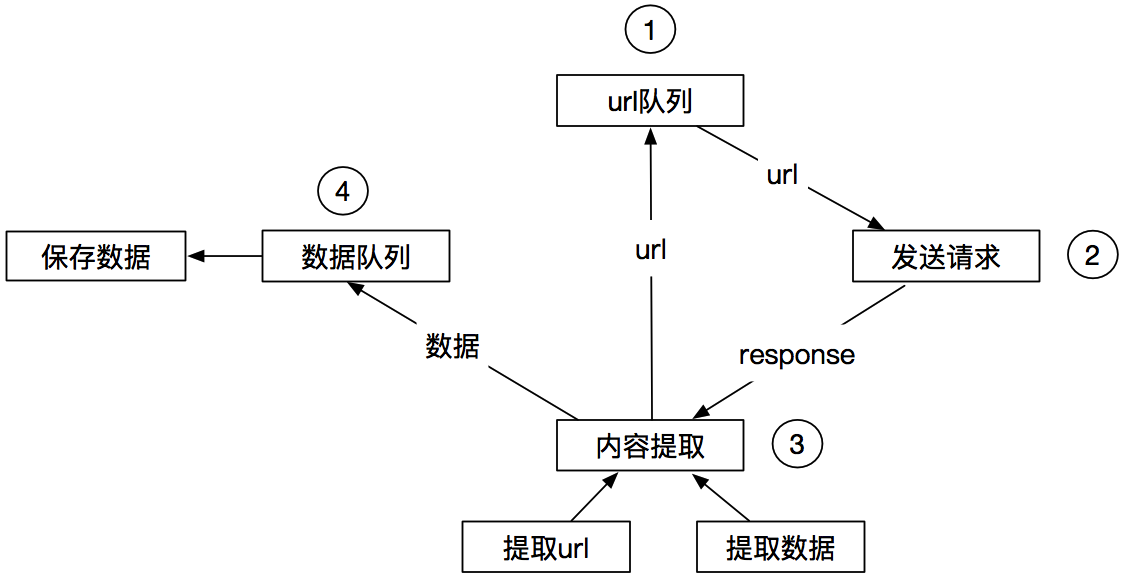
工作流程:

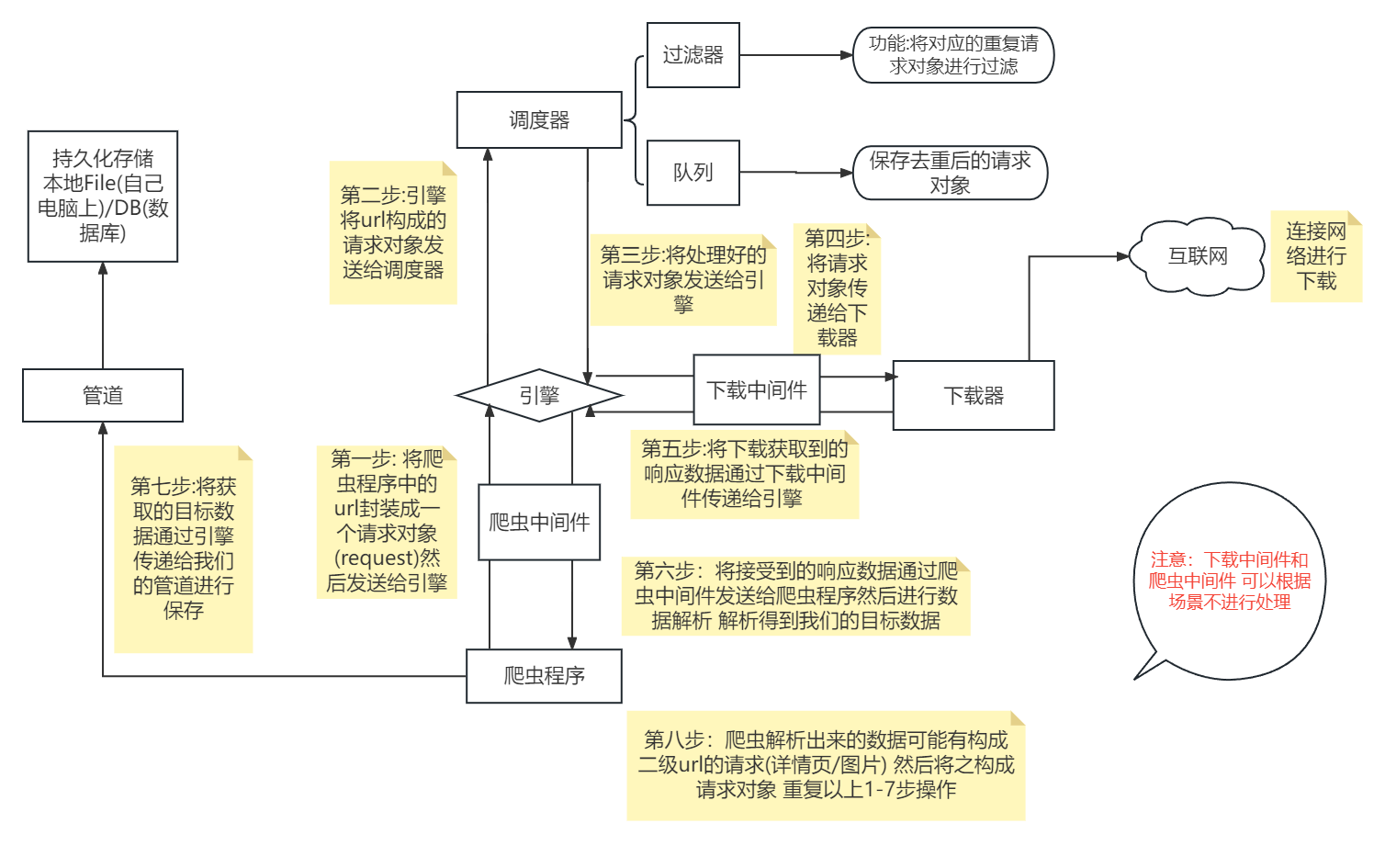
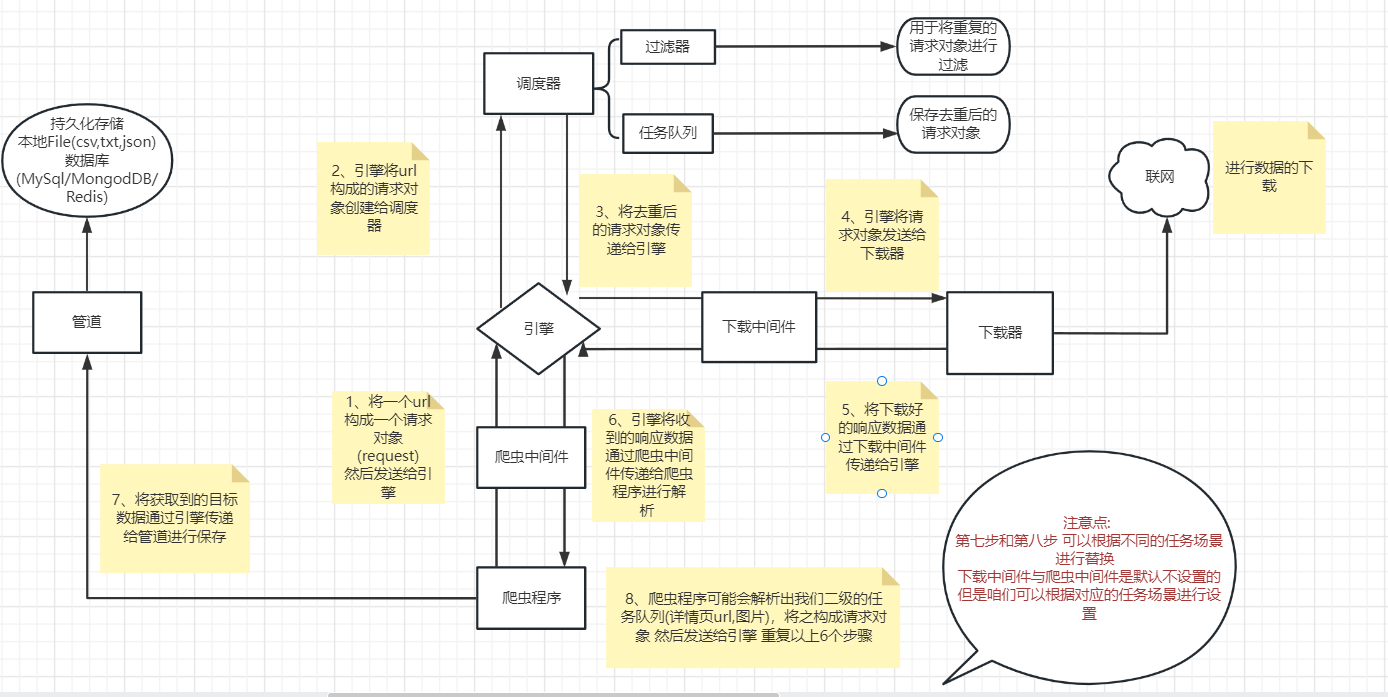
1.各个组件的功能介绍:
Scrapy engine(引擎) | 总指挥:负责数据和信号的在不同模块间的传递 | scrapy已经实现 |
|---|---|---|
Scheduler(调度器) | 一个队列,存放引擎发过来的request请求 | scrapy已经实现 |
Downloader(下载器) | 下载把引擎发过来的requests请求,并返回给引擎 | scrapy已经实现 |
Spider(爬虫) | 处理引擎发来的response,提取数据,提取url,并交给引擎 | 需要手写 |
Item Pipline(管道) | 处理引擎传过来的数据,比如存储 | 需要手写 |
Downloader Middlewares(下载中间件) | 可以自定义的下载扩展,比如设置代理 | 一般不用手写 |
Spider Middlewares(中间件) | 可以自定义requests请求和进行response过滤 | 一般不用手写 |
1 引擎(engine) scrapy已经实现
scrapy的核心, 所有模块的衔接, 数据流程梳理2 调度器(scheduler) scrapy已经实现
本质上这东西可以看成是一个队列,里面存放着一堆我们即将要发送的请求,可以看成是一个url的容器
它决定了下一步要去爬取哪一个url,通常我们在这里可以对url进行去重操作。3 下载器(downloader) scrapy已经实现
它的本质就是用来发动请求的一个模块,小白们完全可以把它理解成是一个requests.get()的功能,
只不过这货返回的是一个response对象.4 爬虫(spider) 需要手写
这是我们要写的第一个部分的内容, 负责解析下载器返回的response对象,从中提取到我们需要的数据5 管道(Item pipeline)
这是我们要写的第二个部分的内容, 主要负责数据的存储和各种持久化操作6 下载中间件(downloader Middlewares) 一般不用手写
可以自定义的下载扩展 比如设置代理 处理引擎与下载器之间的请求与响应(用的比较多)7 爬虫中间件(Spider Middlewares) 一般不用手写
可以自定义requests请求和进行response过滤(处理爬虫程序的响应和输出结果以及新的请求)
三:Scrapy入门与总结
1.Scrapy入门
前提:路径切换 cd copy path 复制绝对路径 1. 创建scrapy项目
scrapy startproject mySpider
scrapy startproject(固定的)
mySpider(不固定的 需要创建的项目的名字)2. 进入项目里面:cd mySpider3. 创建爬虫程序
scrapy genspider example example.comscrapy genspider:固定的
example:爬虫程序的名字(不固定的)
example.com:可以允许爬取的范围(不固定的) 是根据你的目标url来指定的 其实很重要 后面是可以修改的目标url:https://www.baidu.com/scrapy genspider bd baidu.com4. 执行爬虫程序
scrapy crawl bd
scrapy crawl:固定的
db:执行的爬虫程序的名字可以通过start.py文件执行爬虫项目:
from scrapy import cmdline
cmdline.execute("scrapy crawl bd".split())2.Scrapy文件说明
baidu.py爬虫文件 # 爬虫程序的名字name = 'bd'# 可以爬取的范围# 有可能我们在实际进行爬取的时候 第一页可能是xxx.com 第三页可能就变成了xxx.cn # 或者xxx.yy 那么可能就会爬取不到数据# 所以我们需要对allowed_domains进行一个列表的添加allowed_domains = ['baidu.com']# 起始url地址 会根据我们的allowed_domains对网页前缀进行一定的补全 # 但有时候补全的url不对 所以我们也要去对他进行修改start_urls = ['https://www.baidu.com/']# 专门用于解析数据的def parse(self, response): items.py 数据封装的
middlewares.py 中间件(爬虫中间件和下载中间件)
pipelines.py 管道(保存数据的)settings.py Scrapy的配置项# 1 自动生成的配置,无需关注,不用修改
BOT_NAME = 'mySpider'
SPIDER_MODULES = ['mySpider.spiders']
NEWSPIDER_MODULE = 'mySpider.spiders'# 2 取消日志
LOG_LEVEL = 'WARNING'# 3 设置UA,但不常用,一般都是在MiddleWare中添加
USER_AGENT = 'mySpider (+http://www.yourdomain.com)'# 4 遵循robots.txt中的爬虫规则,很多人喜欢False,当然我也喜欢....
ROBOTSTXT_OBEY = True# 5 对网站并发请求总数,默认16
CONCURRENT_REQUESTS = 32# 6 相同网站两个请求之间的间隔时间,默认是0s。相当于time.sleep()
DOWNLOAD_DELAY = 3# 7 禁用cookie,默认是True,启用
COOKIES_ENABLED = False# 8 默认的请求头设置
DEFAULT_REQUEST_HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en',
}# 9 配置启用爬虫中间件,Key是class,Value是优先级
SPIDER_MIDDLEWARES = {'mySpider.middlewares.MyspiderSpiderMiddleware': 543,
}# 10 配置启用Downloader MiddleWares下载中间件
DOWNLOADER_MIDDLEWARES = {'mySpider.middlewares.MyspiderDownloaderMiddleware': 543,
}# 11 开启管道 配置启用Pipeline用来持久化数据
ITEM_PIPELINES = {'mySpider.pipelines.MyspiderPipeline': 300,
}
settings配置项更多参考: https://www.cnblogs.com/seven0007/p/scrapy_setting.html
3.Scrapy总结
scrapy其实就是把我们平时写的爬虫进行了四分五裂式的改造. 对每个功能进行了单独的封装, 并且, 各个模块之间互相的不做依赖. 一切都由引擎进行调配. 这种思想希望你能知道–解耦. 让模块与模块之间的关联性更加的松散. 这样我们如果希望替换某一模块的时候会非常的容易. 对其他模块也不会产生任何的影响