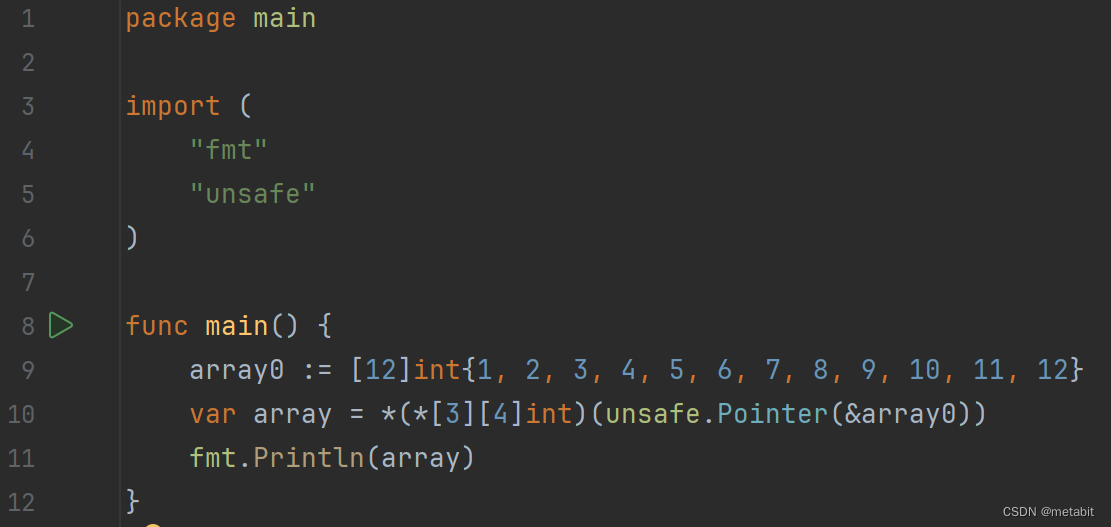
主要业务流程
- 初始请求
- 请求过滤器
- 请求队列
- 响应下载器
- 数据解析器
- 数据清洗器
- 存储器
设计图

-
master + slave:master控制队列,过滤,传递任务;slave负责执行
- 缺点:master和slave端交互数据频繁,slave的数据进出,都给master去调度,对master端相当于成倍数据,并发比较大
-
升级策略2:分离响应异步下载与异步处理,避免一方阻塞另一方
- 如果解析,和清洗也会处理很长时间,并发量就会下降,也可以在中间加入队列,解耦任务
- 如果没有耗时操作,也没必要新加一个队列来做
- 具体在哪些环节之间加入队列,取决你分析业务需求,在哪些环节会出现耗时操作
- 对于一个任务来说,是共享一个进程的,这个队列可以直接用Queue(内存队列),共享一个进程中数据,
- 如果解析,和清洗也会处理很长时间,并发量就会下降,也可以在中间加入队列,解耦任务
-
升级策略3:日志监控捕获错误,并实时通报。ELK
- 先对日志进行埋点,针对Error错误日志进行报告
-
还有一种,master 只负责过滤重复请求;slave自己负责维护自己的队列,只需要 slave 执行任务前询问 master是否有重复值即可
- 减轻了master的负担,但是slave自己维护自己队列,彼此独立
系统架构组件
-
队列组件
- 队列类型
- FIFO
- 内存队列 - 一般实现单机版的队列
- Python内置队列
- Asyncio中的队列
- 持久化队列:分布式,断点续爬
- Redis队列
- 消息队列:Kafka,Rabbitmq
- 队列类型
-
过滤器组件
- 指纹过滤器(redis等): 千万级数据去重
- simhash过滤器,相似文本去重
- 布隆过滤器(redis),亿级数据去重(存在极小概率误判),,占的空间比较小,性能高
-
下载器组件
- urllib/requests
- aiohttp
- tomada.httpclient
-
异步组件
- asyncio
- celery + eventlet/gevent
- selenium + chrome-headless Pool(多个浏览器实例)
- appium + android-app Pool (多台设备)
-
数据解析提取组件
- 语法规则
- 正则
- Xpath
- 解析提取工具
- re
- lxml
- lxml + bs4
- lxml + pyquery
- 语法规则
-
数据清洗组件
- 自定义清洗规则
-
数据存储组件
- 存储介质
- file:csv/json
- DB:mysql/mongondb
- 存储工具
- csv、json
- sqlalchemy/mongoengine
- 存储介质
-
程序监控组件
- ELK
- elasticsearch:日志数据存储
- logstash: 日志收集工具
- kibana: 日志可视化
- ELK
-
可视化控制组件
- web界面
- GUI界面
异步改造并发代码
同步请求
- 下载器中,开始使用的是 requests 同步发请求,没有异步
- 下载器(同步请求)
import requests
from spiderSystem.response import Responseclass RequestsDownloader(object):"""根据request发起请求,构建response对象"""def fetch(self, request):if request.method.upper() == "GET":resp = requests.get(request.with_query_url, headers=request.headers)elif request.method.upper() == "POST":resp = requests.post(request.with_query_url, headers=request.headers, body=request.body)else:raise Exception('only support GET or POST Method')return Response(request, status_code=resp.status_code, url=resp.url, headers=resp.headers, body=resp.content)- 请求的 Slave 客户端
from .request_manager import RequestManager
from .request_manager.utils.redis_tools import get_redis_queue_cls
from .downloader import RequestsDownloaderfrom .request import RequestFIFO_QUEUE = get_redis_queue_cls('fifo')class Slave(object):def __init__(self, spiders, project_name, request_manager_config):self.filter_queue = FIFO_QUEUE("filter_queue", host="localhost")self.request_manager = RequestManager(**request_manager_config) self.downloader = RequestsDownloader() # 用 requests 同步请求的下载器self.spiders = spidersself.project_name = project_namedef handle_request(self):# 1. 获取一个请求request = self.request_manager.get_request(self.project_name)# 2. 发起请求response = self.downloader.fetch(request) # 每次都同步去请求 !!!# 3. 获取爬虫对象spider = self.spiders[request.name]()# 4. 处理 responsefor result in spider.parse(response):if result is None:raise Exception('不允许返回None')elif isinstance(result, Request):self.filter_queue.put(result)else:# 意味着是一个数据new_result = spider.data_clean(result)spider.data_save(new_result)def run(self):while True:self.handle_request() 异步请求改造
- 通过 tornado 的异步请求
- 下载器(异步)
from tornado.httpclient import HTTPClient, HTTPRequest, AsyncHTTPClientfrom spiderSystem.response import Response# tornado 也有同步请求方式 (可以忽略)
class TornadoDownloader(object):def __init__(self):self.httpclient = HTTPClient()def fetch(self, request):print("tornado 同步客户端发的请求")tornado_request = HTTPRequest(request.with_query_url, method=request.method.upper(), headers=request.headers)tornado_response = self.httpclient.fetch(tornado_request)return Response(request=request, status_code=tornado_response.code, url=tornado_response.effective_url,body=tornado_response.buffer.read())"""同步的请求,不能复用,需要用完后关闭"""def __del__(self):self.httpclient.close()# tornado 也有异步请求方式
class AsyncTornadoDownloader(object):def __init__(self):self.async_http_client = AsyncHTTPClient()async def fetch(self, request): # 开启协程print("tornado 异步客户端发的请求")tornado_request = HTTPRequest(request.with_query_url, method=request.method.upper(), headers=request.headers)tornado_response = await self.async_http_client.fetch(tornado_request) # 等待return Response(request=request, status_code=tornado_response.code, url=tornado_response.effective_url,headers=request.headers,body=tornado_response.buffer.read())- Slave 调用方
import asyncio
import tornado.ioloopfrom .request_manager import RequestManager
from .request_manager.utils.redis_tools import get_redis_queue_cls
from .downloader import RequestsDownloader, TornadoDownloader, AsyncTornadoDownloaderfrom .request import RequestFIFO_QUEUE = get_redis_queue_cls('fifo')class Slave(object):def __init__(self, spiders, project_name, request_manager_config):self.filter_queue = FIFO_QUEUE("filter_queue", host="localhost")self.request_manager = RequestManager(**request_manager_config) self.downloader = AsyncTornadoDownloader() # 异步下载器self.spiders = spidersself.project_name = project_nameasync def handle_request(self):# request = self.request_manager.get_request(self.project_name) 阻塞改异步io_loop = tornado.ioloop.IOLoop.current()# 1. 获取一个请求future = io_loop.run_in_executor(None, self.request_manager.get_request,self.project_name) # 不支持协程的函数,可以自己获取事件循环,去定义执行,让其支持协程request = await future# 2. 发起请求response = await self.downloader.fetch(request)# 3. 获取爬虫对象spider = self.spiders[request.name]()# 4. 处理 responsefor result in spider.parse(response):if result is None:raise Exception('不允许返回None')elif isinstance(result, Request):# self.filter_queue.put(result) 可能阻塞,改异步await io_loop.run_in_executor(None, self.filter_queue.put,result) else:# 意味着是一个数据new_result = spider.data_clean(result)spider.data_save(new_result)async def run(self):while True:# 不能写成 await self.handle_request(),否则,也是相当于同步请求了await asyncio.wait([self.handle_request(),self.handle_request(),])- 启动方式
if __name__ == '__main__':spiders = {BaiduSpider.name: BaiduSpider}# 同步请求,用 requests 发请求# Slave(spiders, project_name=PROJECT_NAME, request_manager_config=REQUEST_MANAGER_CONFIG).run()# 要用异步方式去请求slave = Slave(spiders, project_name=PROJECT_NAME, request_manager_config=REQUEST_MANAGER_CONFIG)io_loop = tornado.ioloop.IOLoop.current()io_loop.run_sync(slave.run)tornado库 io_loop.run_sync 用于将阻塞函数转换为同步函数并在 IOLoop 上执行,它会阻塞当前协程。 io_loop.run_in_executor 用于在指定的线程池中异步执行耗时的、阻塞的操作,不会阻塞当前协程,并允许 IOLoop 继续处理其他事件。
asyncio库 实现类似于 run_sync 的效果:您可以使用 loop.run_until_complete 方法来运行一个协程并等待其完成。这个方法会阻塞当前线程,直到协程执行完毕 实现类似于 run_in_executor 的效果:您可以使用 loop.run_in_executor 方法将耗时的、阻塞的操作转移到一个线程池中执行,以避免阻塞事件循环。
async 异步协程改造重点!!!
- 下载器中,用到的所有异步的地方,必须是协程 async 定义
- await 后面跟着的,一定是支持协程的方法,要不是一个 协程对象,future 或者 task 对象,比如 self.async_http_client.fetch ,如果不支持协程,会报错
- 连带着的,所有调用 async 的方法,也必须是协程函数
- 对于不支持协程的函数,可以自己获取事件循环,去定义执行,让其支持协程;如果一个函数是一个协程函数后,如果这个协程函数中,有任意可以阻塞的,或耗时操作,都应该改成异步的 await ,不然可能会阻塞整个线程
# self.request_manager.get_request 本身不支持异步,或者改造成异步,嵌套要改的太深,可以用 io_loop.run_in_executor 来替代io_loop = tornado.ioloop.IOLoop.current()# 1. 获取一个请求future = io_loop.run_in_executor(None, self.request_manager.get_request,self.project_name) request = await future
- 在最开始调用的地方,比如 run ,启动的方式,必须是 用 asyncio.wait 或用其他方式启动(asyncio.gather 或 asyncio.as_completed)
# 开启2个协程,去执行。asyncio.wait 能让其变成一个异步关系
async def run(self):while True:# 不能写成 await self.handle_request(),否则,也是相当于同步请求了await asyncio.wait([self.handle_request(),self.handle_request(),])Master 进程用多线程改造
- master 的启动方法,这两个可以用两个线程去做,不然以前的写法是同步的执行方式
def run(self):# self.run_start_requests()# self.run_filter_queue()# 两个线程去做threading.Thread(target=self.run_start_requests).start()threading.Thread(target=self.run_filter_queue).start()自己封装的SpiderSystem模块安装成内置环境中
- 在模块目录添加 setup.py 脚本
├── setup.py
├── spiderSystem
├── README.md- 执行 pip3 setup.py install 即可
- 查看包信息 pip3 show spiderSystem
from setuptools import setup, find_packagessetup(name="spiderSystem",version="0.1",description="spiderSystem module",author='raoju',url="url",license="license",packages=find_packages(exclude=[]), # 当前所有模块都安装install_requires=["tornado >= 5.1","pycurl",]).markdown-body pre,.markdown-body pre>code.hljs{color:#333;background:#f8f8f8}.hljs-comment,.hljs-quote{color:#998;font-style:italic}.hljs-keyword,.hljs-selector-tag,.hljs-subst{color:#333;font-weight:700}.hljs-literal,.hljs-number,.hljs-tag .hljs-attr,.hljs-template-variable,.hljs-variable{color:teal}.hljs-doctag,.hljs-string{color:#d14}.hljs-section,.hljs-selector-id,.hljs-title{color:#900;font-weight:700}.hljs-subst{font-weight:400}.hljs-class .hljs-title,.hljs-type{color:#458;font-weight:700}.hljs-attribute,.hljs-name,.hljs-tag{color:navy;font-weight:400}.hljs-link,.hljs-regexp{color:#009926}.hljs-bullet,.hljs-symbol{color:#990073}.hljs-built_in,.hljs-builtin-name{color:#0086b3}.hljs-meta{color:#999;font-weight:700}.hljs-deletion{background:#fdd}.hljs-addition{background:#dfd}.hljs-emphasis{font-style:italic}.hljs-strong{font-weight:700}
主要业务流程
- 初始请求
- 请求过滤器
- 请求队列
- 响应下载器
- 数据解析器
- 数据清洗器
- 存储器
设计图

-
master + slave:master控制队列,过滤,传递任务;slave负责执行
- 缺点:master和slave端交互数据频繁,slave的数据进出,都给master去调度,对master端相当于成倍数据,并发比较大
-
升级策略2:分离响应异步下载与异步处理,避免一方阻塞另一方
- 如果解析,和清洗也会处理很长时间,并发量就会下降,也可以在中间加入队列,解耦任务
- 如果没有耗时操作,也没必要新加一个队列来做
- 具体在哪些环节之间加入队列,取决你分析业务需求,在哪些环节会出现耗时操作
- 对于一个任务来说,是共享一个进程的,这个队列可以直接用Queue(内存队列),共享一个进程中数据,
- 如果解析,和清洗也会处理很长时间,并发量就会下降,也可以在中间加入队列,解耦任务
-
升级策略3:日志监控捕获错误,并实时通报。ELK
- 先对日志进行埋点,针对Error错误日志进行报告
-
还有一种,master 只负责过滤重复请求;slave自己负责维护自己的队列,只需要 slave 执行任务前询问 master是否有重复值即可
- 减轻了master的负担,但是slave自己维护自己队列,彼此独立
系统架构组件
-
队列组件
- 队列类型
- FIFO
- 内存队列 - 一般实现单机版的队列
- Python内置队列
- Asyncio中的队列
- 持久化队列:分布式,断点续爬
- Redis队列
- 消息队列:Kafka,Rabbitmq
- 队列类型
-
过滤器组件
- 指纹过滤器(redis等): 千万级数据去重
- simhash过滤器,相似文本去重
- 布隆过滤器(redis),亿级数据去重(存在极小概率误判),,占的空间比较小,性能高
-
下载器组件
- urllib/requests
- aiohttp
- tomada.httpclient
-
异步组件
- asyncio
- celery + eventlet/gevent
- selenium + chrome-headless Pool(多个浏览器实例)
- appium + android-app Pool (多台设备)
-
数据解析提取组件
- 语法规则
- 正则
- Xpath
- 解析提取工具
- re
- lxml
- lxml + bs4
- lxml + pyquery
- 语法规则
-
数据清洗组件
- 自定义清洗规则
-
数据存储组件
- 存储介质
- file:csv/json
- DB:mysql/mongondb
- 存储工具
- csv、json
- sqlalchemy/mongoengine
- 存储介质
-
程序监控组件
- ELK
- elasticsearch:日志数据存储
- logstash: 日志收集工具
- kibana: 日志可视化
- ELK
-
可视化控制组件
- web界面
- GUI界面
异步改造并发代码
同步请求
- 下载器中,开始使用的是 requests 同步发请求,没有异步
- 下载器(同步请求)
import requests
from spiderSystem.response import Responseclass RequestsDownloader(object):"""根据request发起请求,构建response对象"""def fetch(self, request):if request.method.upper() == "GET":resp = requests.get(request.with_query_url, headers=request.headers)elif request.method.upper() == "POST":resp = requests.post(request.with_query_url, headers=request.headers, body=request.body)else:raise Exception('only support GET or POST Method')return Response(request, status_code=resp.status_code, url=resp.url, headers=resp.headers, body=resp.content)- 请求的 Slave 客户端
from .request_manager import RequestManager
from .request_manager.utils.redis_tools import get_redis_queue_cls
from .downloader import RequestsDownloaderfrom .request import RequestFIFO_QUEUE = get_redis_queue_cls('fifo')class Slave(object):def __init__(self, spiders, project_name, request_manager_config):self.filter_queue = FIFO_QUEUE("filter_queue", host="localhost")self.request_manager = RequestManager(**request_manager_config) self.downloader = RequestsDownloader() # 用 requests 同步请求的下载器self.spiders = spidersself.project_name = project_namedef handle_request(self):# 1. 获取一个请求request = self.request_manager.get_request(self.project_name)# 2. 发起请求response = self.downloader.fetch(request) # 每次都同步去请求 !!!# 3. 获取爬虫对象spider = self.spiders[request.name]()# 4. 处理 responsefor result in spider.parse(response):if result is None:raise Exception('不允许返回None')elif isinstance(result, Request):self.filter_queue.put(result)else:# 意味着是一个数据new_result = spider.data_clean(result)spider.data_save(new_result)def run(self):while True:self.handle_request() 异步请求改造
- 通过 tornado 的异步请求
- 下载器(异步)
from tornado.httpclient import HTTPClient, HTTPRequest, AsyncHTTPClientfrom spiderSystem.response import Response# tornado 也有同步请求方式 (可以忽略)
class TornadoDownloader(object):def __init__(self):self.httpclient = HTTPClient()def fetch(self, request):print("tornado 同步客户端发的请求")tornado_request = HTTPRequest(request.with_query_url, method=request.method.upper(), headers=request.headers)tornado_response = self.httpclient.fetch(tornado_request)return Response(request=request, status_code=tornado_response.code, url=tornado_response.effective_url,body=tornado_response.buffer.read())"""同步的请求,不能复用,需要用完后关闭"""def __del__(self):self.httpclient.close()# tornado 也有异步请求方式
class AsyncTornadoDownloader(object):def __init__(self):self.async_http_client = AsyncHTTPClient()async def fetch(self, request): # 开启协程print("tornado 异步客户端发的请求")tornado_request = HTTPRequest(request.with_query_url, method=request.method.upper(), headers=request.headers)tornado_response = await self.async_http_client.fetch(tornado_request) # 等待return Response(request=request, status_code=tornado_response.code, url=tornado_response.effective_url,headers=request.headers,body=tornado_response.buffer.read())- Slave 调用方
import asyncio
import tornado.ioloopfrom .request_manager import RequestManager
from .request_manager.utils.redis_tools import get_redis_queue_cls
from .downloader import RequestsDownloader, TornadoDownloader, AsyncTornadoDownloaderfrom .request import RequestFIFO_QUEUE = get_redis_queue_cls('fifo')class Slave(object):def __init__(self, spiders, project_name, request_manager_config):self.filter_queue = FIFO_QUEUE("filter_queue", host="localhost")self.request_manager = RequestManager(**request_manager_config) self.downloader = AsyncTornadoDownloader() # 异步下载器self.spiders = spidersself.project_name = project_nameasync def handle_request(self):# request = self.request_manager.get_request(self.project_name) 阻塞改异步io_loop = tornado.ioloop.IOLoop.current()# 1. 获取一个请求future = io_loop.run_in_executor(None, self.request_manager.get_request,self.project_name) # 不支持协程的函数,可以自己获取事件循环,去定义执行,让其支持协程request = await future# 2. 发起请求response = await self.downloader.fetch(request)# 3. 获取爬虫对象spider = self.spiders[request.name]()# 4. 处理 responsefor result in spider.parse(response):if result is None:raise Exception('不允许返回None')elif isinstance(result, Request):# self.filter_queue.put(result) 可能阻塞,改异步await io_loop.run_in_executor(None, self.filter_queue.put,result) else:# 意味着是一个数据new_result = spider.data_clean(result)spider.data_save(new_result)async def run(self):while True:# 不能写成 await self.handle_request(),否则,也是相当于同步请求了await asyncio.wait([self.handle_request(),self.handle_request(),])- 启动方式
if __name__ == '__main__':spiders = {BaiduSpider.name: BaiduSpider}# 同步请求,用 requests 发请求# Slave(spiders, project_name=PROJECT_NAME, request_manager_config=REQUEST_MANAGER_CONFIG).run()# 要用异步方式去请求slave = Slave(spiders, project_name=PROJECT_NAME, request_manager_config=REQUEST_MANAGER_CONFIG)io_loop = tornado.ioloop.IOLoop.current()io_loop.run_sync(slave.run)tornado库 io_loop.run_sync 用于将阻塞函数转换为同步函数并在 IOLoop 上执行,它会阻塞当前协程。 io_loop.run_in_executor 用于在指定的线程池中异步执行耗时的、阻塞的操作,不会阻塞当前协程,并允许 IOLoop 继续处理其他事件。
asyncio库 实现类似于 run_sync 的效果:您可以使用 loop.run_until_complete 方法来运行一个协程并等待其完成。这个方法会阻塞当前线程,直到协程执行完毕 实现类似于 run_in_executor 的效果:您可以使用 loop.run_in_executor 方法将耗时的、阻塞的操作转移到一个线程池中执行,以避免阻塞事件循环。
async 异步协程改造重点!!!
- 下载器中,用到的所有异步的地方,必须是协程 async 定义
- await 后面跟着的,一定是支持协程的方法,要不是一个 协程对象,future 或者 task 对象,比如 self.async_http_client.fetch ,如果不支持协程,会报错
- 连带着的,所有调用 async 的方法,也必须是协程函数
- 对于不支持协程的函数,可以自己获取事件循环,去定义执行,让其支持协程;如果一个函数是一个协程函数后,如果这个协程函数中,有任意可以阻塞的,或耗时操作,都应该改成异步的 await ,不然可能会阻塞整个线程
# self.request_manager.get_request 本身不支持异步,或者改造成异步,嵌套要改的太深,可以用 io_loop.run_in_executor 来替代io_loop = tornado.ioloop.IOLoop.current()# 1. 获取一个请求future = io_loop.run_in_executor(None, self.request_manager.get_request,self.project_name) request = await future
- 在最开始调用的地方,比如 run ,启动的方式,必须是 用 asyncio.wait 或用其他方式启动(asyncio.gather 或 asyncio.as_completed)
# 开启2个协程,去执行。asyncio.wait 能让其变成一个异步关系
async def run(self):while True:# 不能写成 await self.handle_request(),否则,也是相当于同步请求了await asyncio.wait([self.handle_request(),self.handle_request(),])Master 进程用多线程改造
- master 的启动方法,这两个可以用两个线程去做,不然以前的写法是同步的执行方式
def run(self):# self.run_start_requests()# self.run_filter_queue()# 两个线程去做threading.Thread(target=self.run_start_requests).start()threading.Thread(target=self.run_filter_queue).start()自己封装的SpiderSystem模块安装成内置环境中
- 在模块目录添加 setup.py 脚本
├── setup.py
├── spiderSystem
├── README.md- 执行 pip3 setup.py install 即可
- 查看包信息 pip3 show spiderSystem
from setuptools import setup, find_packagessetup(name="spiderSystem",version="0.1",description="spiderSystem module",author='raoju',url="url",license="license",packages=find_packages(exclude=[]), # 当前所有模块都安装install_requires=["tornado >= 5.1","pycurl",])如果你对Python感兴趣,想要学习python,这里给大家分享一份Python全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!
😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓
Python全套学习资料

1️⃣零基础入门
① 学习路线
对于从来没有接触过Python的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~

③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

2️⃣国内外Python书籍、文档
① 文档和书籍资料

3️⃣Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!

②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!

③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!

4️⃣Python面试题
我们学会了Python之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


上述所有资料 ⚡️ ,朋友们如果有需要的,可以扫描下方👇👇👇二维码免费领取🆓