aigc图像相关
- 一、Diffusion webui 在autodl上部署一些问题
- 二、lora和kohyass
- (1)角色模型
- (2)风格模型
- (3)dreambooth
- (4)模型合并
- (5)Lora加Adetail
- 其他
- 三、sd api
- 四、ai视频模型
- 五、换脸
- 六、voice2face
- 七、clash代理
- 八、3090、cuda和tensorflow 1.x
- 八、 Nvidia显卡驱动、CUDA、cuDNN、Anaconda及Tensorflow-GPU版本
- 九、显卡信息命令/CPU内存/硬盘
- 1.显卡
- 2、CPU内存
- 3、硬盘
- 4、查看进程
- 5、释放显存
- 十、文生视频
- 十一、数字人
- 十二、 flask socket
- 十三、图像超分辨率模型( video Super Resolution)
- 十四、GUI
- 十五、调试
- 十六、ftp
- 1、安装启动状态
- 2、配置
- 3、创建用户 与 目录的分配
- 4、windows远程连接
- 5、PASV模式
- 6、报错
- 十七、TTS
- Bert-VITS2训练
- 常用Linux命令
- 1、 conda复制环境
- 2、压缩
- 3、ffmpeg
- 4、conda换源
- 5、conda相关命令
- 6、shell启动python虚拟环境
- 7、终端目录说明界面(terminal)
- 8、修改huggingface 目录
- Python 常用操作
- 1.清空文件夹
- 2.格式化字符串f() python中 r'', b'', u'', f'' 的含义
- 3、python设置临时环境变量
- 4、vars将类转成字典
- 5、交互窗口,jupy
- 6、数据保存json
- 7、任意路径导包
- 8、Python 全局异常处理 sys.excepthook (路由和进程捕获不了)
- 9、将Python控制台输出保存到文件的方法
- 10、python info日志
- 11、 traceback 异常信息 到控制台
- 12、多队列线程
- 13、python执行脚本当前相对目录
- 附: python代码常用函数
- python模型库
- 1、accelerate
- 2、os.system和subprocess(多进程模型训练1)
- 3、多进程spawn、fork、forkserver (多进程模型训练2)
- 4、python multiprocessing 如何在主进程中捕获子进程抛出的异常
- 5、requests和request
- 6、gradio UI库
一、Diffusion webui 在autodl上部署一些问题
1、虚拟环境中的pip要更新和换源
python -m pip install --upgrade pip
pip install pip -U
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
python -m pip install --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
用设置代理export http_proxy=http:xxxxxxxxxxx,加速git和wget
查看当前pip源pip config list
使用pip命令从requirements.txt升级python包
pip install --upgrade -r requirements.txt
更多查看https://www.codenong.com/24764549/
1.临时换源:
#清华源
pip install markdown -i https://pypi.tuna.tsinghua.edu.cn/simple
# 阿里源
pip install markdown -i https://mirrors.aliyun.com/pypi/simple/
# 腾讯源
pip install markdown -i http://mirrors.cloud.tencent.com/pypi/simple
# 豆瓣源
pip install markdown -i http://pypi.douban.com/simple/2.永久换源:
# 清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 阿里源
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 腾讯源
pip config set global.index-url http://mirrors.cloud.tencent.com/pypi/simple
# 豆瓣源
pip config set global.index-url http://pypi.douban.com/simple/
# 换回默认源
pip config unset global.index-url3、常用源
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/Ubuntu apt更新可用软件包列表
$ sudo apt update
更新已安装的包
$ sudo apt upgrade
通常安装完ubuntu之后, 可以先使用upgrade 更新一下当前系统中可以升级的的软件包
$ sudo apt update
$ sudo apt upgrade
1.安装软件
$ sudo apt install 软件名
2.卸载软件
$ sudo apt remove 软件名
2、pytorch内存不足,安装pytorch被killed,根本原因就是虚拟机分配的内存不足以安装torch,1.9/1.9 GB 29.9 MB/s eta 0:00:01Killed。
du命令用来查看目录或文件所占用磁盘空间的大小。常用选项组合为:du -sh
conda删除虚拟环境conda env remove --name your_env_name
切换有卡模式
修改conda虚拟环境存贮位置
conda info
vim .condarc
envs_dirs:- /root/autodl-tmp/conda/envs- /usr/local/anaconda3/envs- /home/zth/.conda/envs
pkgs_dirs:- /root/autodl-tmp/conda/pkgs- /usr/local/anaconda3/pkgs- /home/zth/.conda/pkgs3、conda shell问题,
重新进入虚拟环境: source activate
退出虚拟环境:source deactivate或conda deactivate(直接 source activate 环境名)
修改路径:conda info vim .condarc
删除虚拟环境:conda env remove --name your_env_name
复制虚拟环境:conda create -n newname --clone oldname
conda activate和source activate 的命令区别
4、git submodule update失败
rm -r sd_scripts/ 删除失败的文件夹
5、lanch.py --share等参数
python launch.py --share --xformers --enable-insecure-extension-access --port 6006
6、下载慢,更换加速网址
7、复制cp -r /root/stable-diffusion-webui/. /root/autodl-tmp/stable-diffusion-webui
假设复制源目录 为 dir1 ,目标目录为dir2。怎样才能将dir1下所有文件复制到dir2下了
如果dir2目录不存在,则可以直接使用
cp -r dir1 dir2
即可。
如果dir2目录已存在,则需要使用
cp -r dir1/. dir2
8、–xformers参数报错(安装xformers导致包冲突)
/root/miniconda3/lib/python3.10/site-packages/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension: libtorch_cuda_cu.so: cannot open shared object file: No such file or directory
9、Something went wrong Expecting value: line 1 column 1 (char 0)
运行
!python launch.py --share --autolaunch --deepdanbooru --xformers --no-gradio-queue --port 6006
二、lora和kohyass
报错:
1、ValueError: persistent_workers option needs num_workers > 0
Enable buckets 没开,适应不同尺寸图片
2、Caption Extension(开启才能读取标签,不然和没打标签一样)
.txt
查看日志:tensorboard --logdir ./tensorboard --port 8080
主要在数据集和基底模型一致
1、LORA模型可以分类两类,角色模型和风格模型。
参考:https://zhuanlan.zhihu.com/p/629303934
https://www.bilibili.com/read/cv22022392
https://zhuanlan.zhihu.com/p/612107375
(1)角色模型
人物背景要干净,选取头像部分,SDsam截取人物,用sd裁剪图片大小。
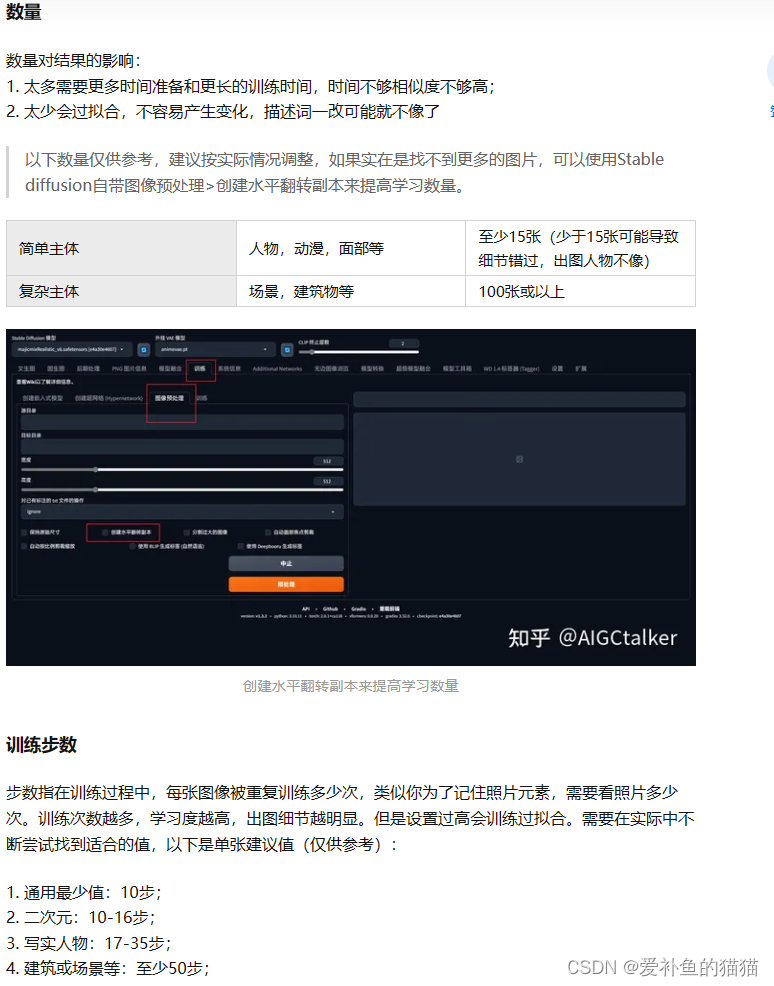
注意:数据准备的质量决定了你最终模型的效果,如果你喂给模型的图是低质量的图,那么模型给你生成的图也是低质量的图,所以尽量保证图片清晰,分辨率较高,无遮挡。如果是角色训练集控制在20-50张图左右,太多会导致过拟合,如果是角色尽可能收集到头像,正视图,侧视图,背面等多角度的无背景素材。先我各种搜集训练对象的图片,去掉糊的,并且一概抠图改为白色背景,
一定要挑光线好的,无遮挡的图,一定要抠图,无关东西一定要去掉,不然影响真的很大
可以用一张图来分别做大头照,半身照,全身照来凑数,但出来的图也会很大程度上感觉似曾相识。
一.图片要求
至少15张图片,每张图片的训练步数不少于100
照片人像要求多角度,特别是脸部特写(尽量高分辨率),多角度,多表情,不同灯光效果,不同姿势等
图片构图尽量简单,避免复杂的其他因素干扰
可以单张脸部特写+单张服装按比例组成的一组照片(这里比例是3:1)
减少重复或高度相似的图片,避免造成过拟合
(1)素材:
对要用于训练的图片素材:例如在角色训练素材中,需要清晰的、多角度的、正脸的、侧脸的、最好是背景干净的、各种表情的、摆头的。就是需要各种角度(不要有俯视的,尽量都是平视图避免比例失调)、景别、姿势、光照。脸部不要有被遮挡的图片。这样增加训练集的多样性,提高模型的泛化性。
如果是角色训练集控制在20-50张图左右,太多会导致过拟合,如果是训练其他风格,有说法是图片越多效果就越好,相应的训练时长也会增加,建议在50~80张。
影响训练出的LoRa模型的好坏,训练集是最最最重要的~!
如果是角色训练,也建议将需要训练的人物及相关的特征装饰都抠出来,背景尽量简单或直接是纯色背景,建议白底或黑底,但不要是透明底。
素材可以少,但是质量一定要高。
角色背景最好是白底网站上面可以选择换背景颜色
搜集好训练用的图像后,需要进行大小的规范处理,需要是64的倍数。一般都处理为512512,也可以是768768,不建议超过1024,尺寸越大则越吃显存。
推荐网站可以进行批量的图像尺寸处理:https://www.birme.net/
(2)裁剪:把所有图片批量进行统一分辨率裁切,分辨率需要是64的倍数,至于说分辨率,其实512就可以了,可以调大一些,如果你显存够大,我用3090发现基本上拉到1024分辨率后就没有收益了,而低于512明显效果不好。理论上图片分辨率高一些好,此外图片质量解析力也应该高。并不一定必须要512*512,但是上下长宽像素必须要是64的倍数。
(3)打标签
BLIP处理的提示词是如果想要保留的特征,就添加这个特征标签。例如需要强调人物特征,会导致训练出的模型并不很像,所以需要加上突出人物特征的标签:
常用特征标签:
Face
Nose
Lips
Hairstyle
Eyes
Ears
Forehead
breast
face,nose,lips,hairstyle,eyes,ears,forehead,people
(4)训练次数
(训练步数 × 素材总数 × 训练循环数Epoch) / 并行数量Bath size ≤ 训练总步数
LoRA训练总步数在1500至6000步,checkpoint训练总步数:至少30000步
训练完成后,模型文件会保存到设置的输出目录。比如 epoch 训练循环数设置了 5,就会得到 5 个训练好的 LoRA 模型。
LoRa的训练需要至少1500步,而每张图片至少需要训练100步。
如果我们有15张或者15张以上张图片,文件夹就需要写上100_Hunzi。
如果训练的图片不够15张,比如10张,就需要改为150_Hunzi,以此类推。
这部分很重要,一定要算清楚。
当然,这也正是LoRa强大的地方,用这么少的图片即可完成训练。
训练时长,总的来说,不宜也不需训练过长时间。尽可能把训练时长控制在半小时到一小时内,时间过长容易导致过拟合,通过调整等参数控制训练时长。即便是batch size值为1,也是如此,这就意味着你的训练总步数其实是不需要过多。(当然,时长也跟显卡的功力也有一定关系,但时长不至于偏差得几倍去。)
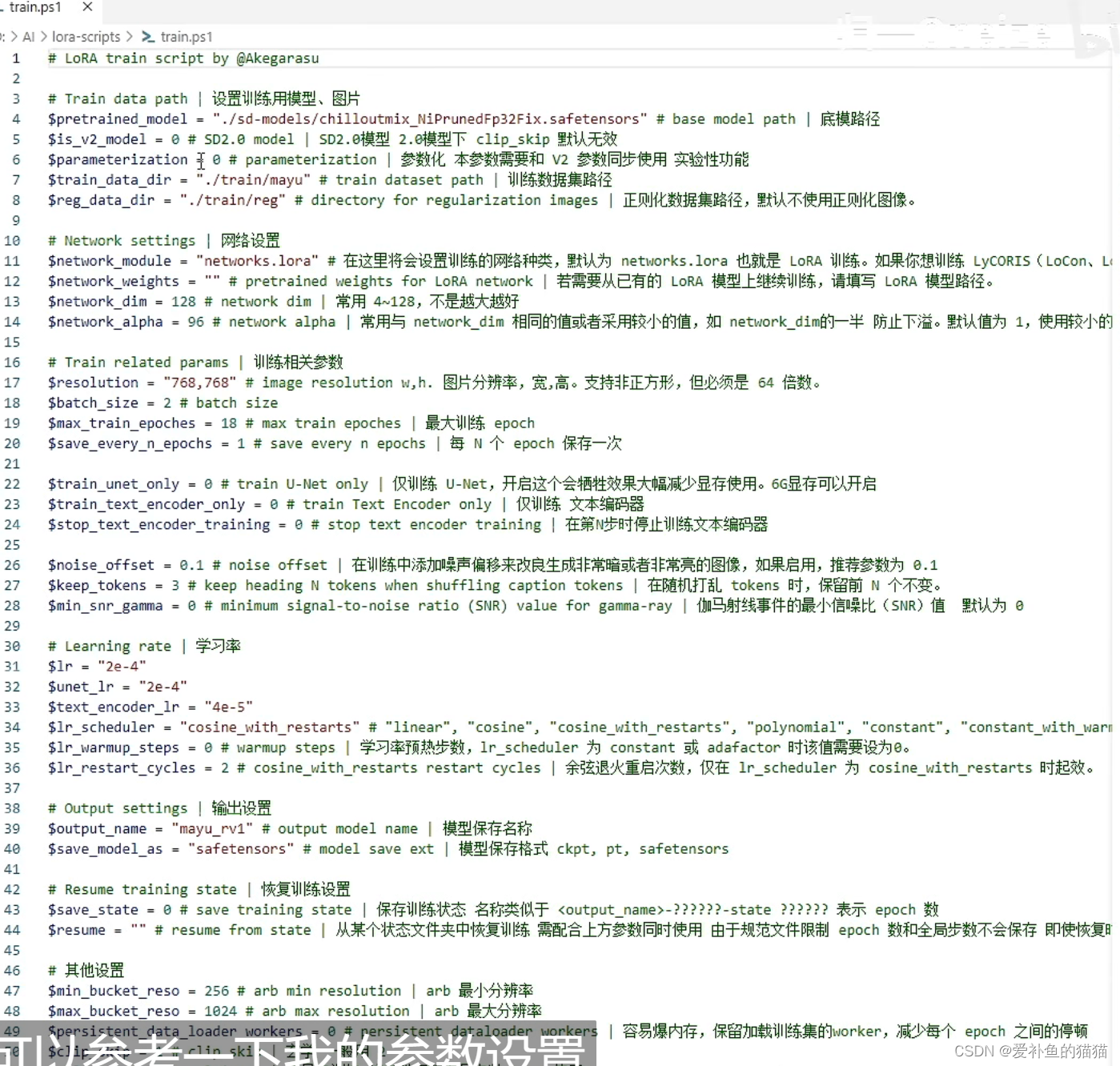
(4)参数设置:
参考:
https://zhuanlan.zhihu.com/p/643550056
https://zhuanlan.zhihu.com/p/618758020
https://zhuanlan.zhihu.com/p/619348969
https://www.bilibili.com/video/BV1UF411Q7cP/?spm_id_from=333.337.search-card.all.click&vd_source=38e7fc10713eca999c22c7ff25f6e6d2
https://www.bilibili.com/video/BV1Ba4y1M7LD/?spm_id_from=333.337.search-card.all.click&vd_source=38e7fc10713eca999c22c7ff25f6e6d2
https://www.bilibili.com/video/BV1GV4y1z7Fn/?spm_id_from=333.337.search-card.all.click&vd_source=38e7fc10713eca999c22c7ff25f6e6d2
https://www.bilibili.com/video/BV1GP411U7fK/?spm_id_from=333.788.recommend_more_video.13&vd_source=38e7fc10713eca999c22c7ff25f6e6d2
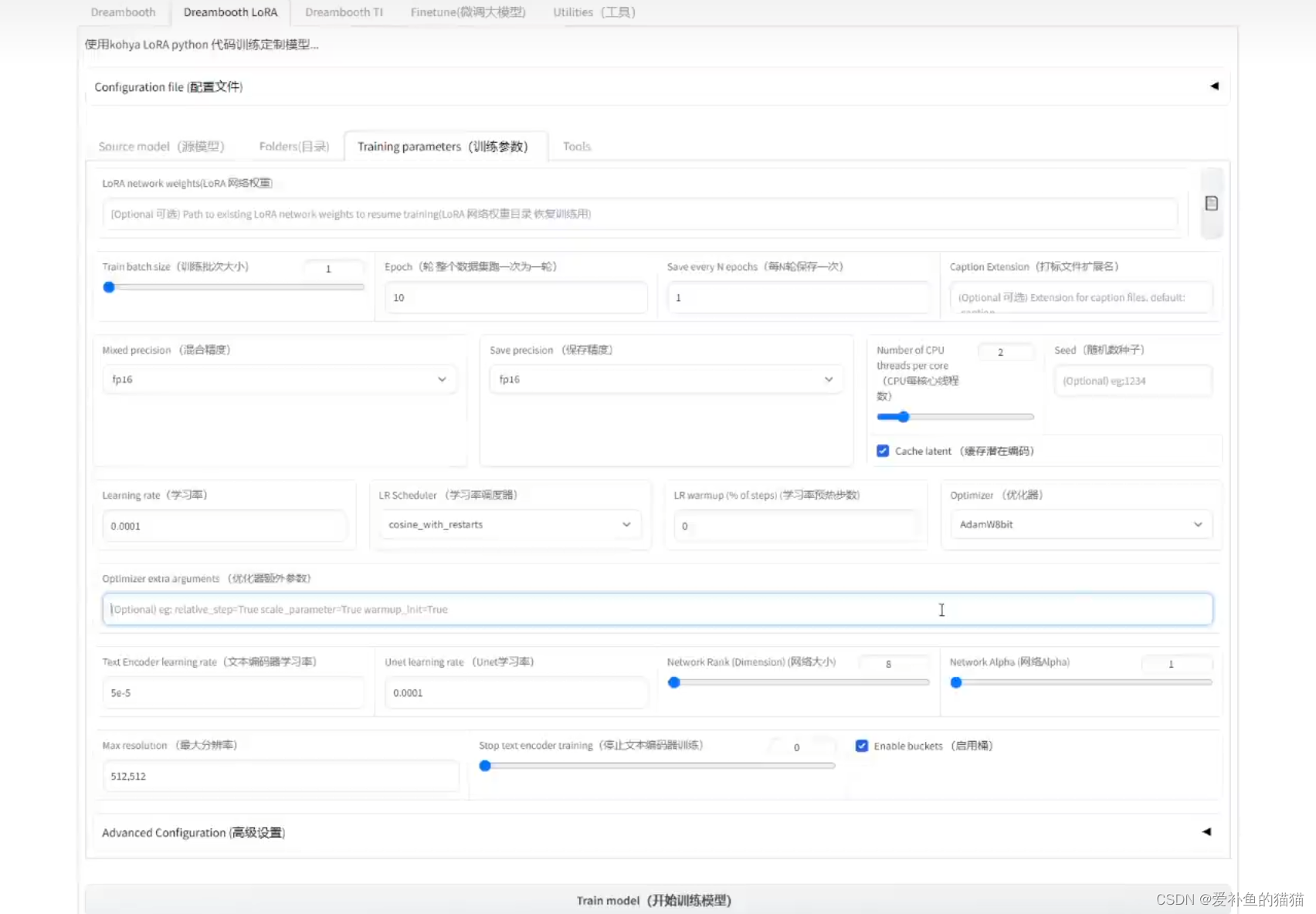
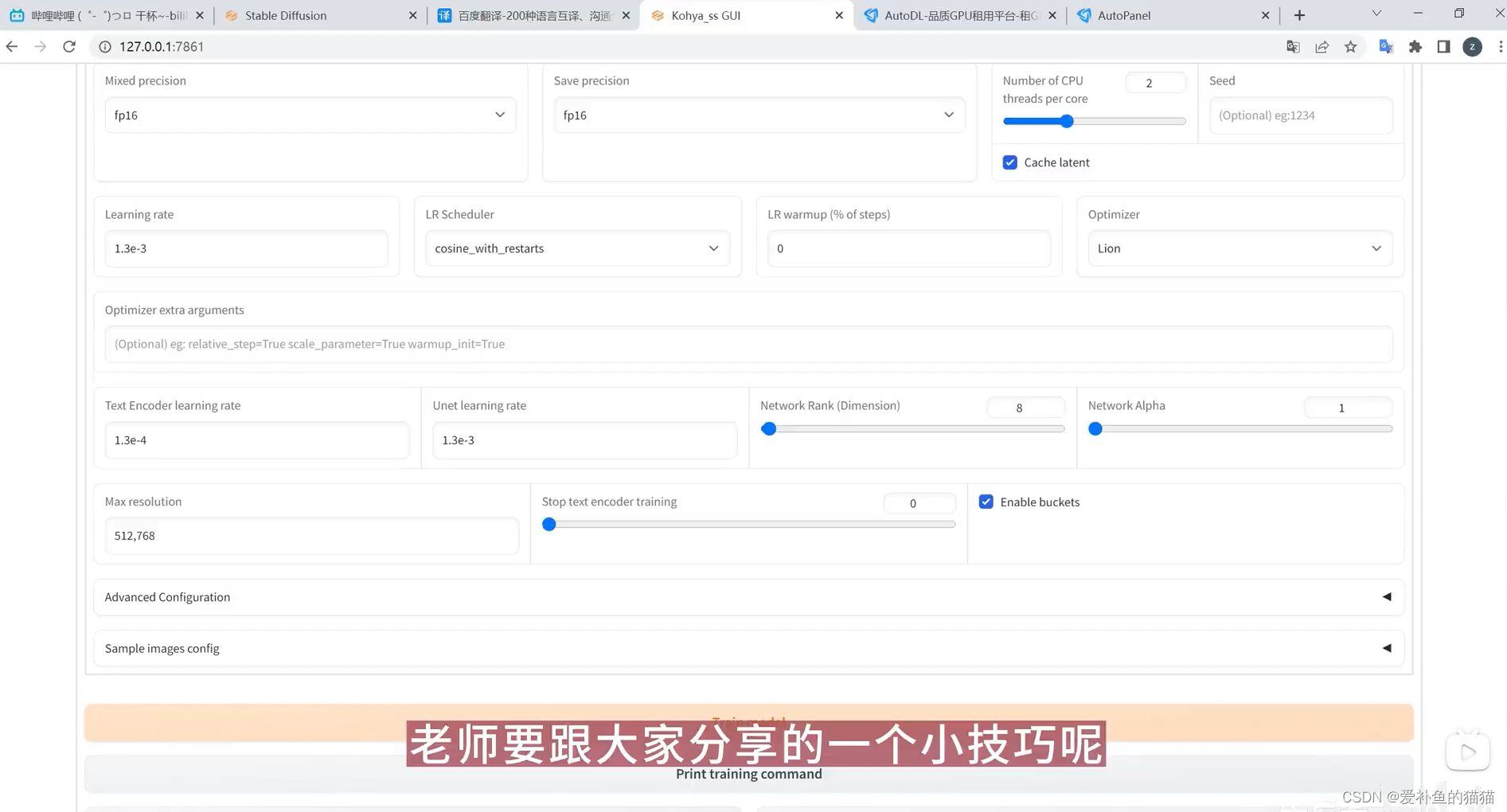
clip_skip:用于控制clip_skip参数,这是一个训练层数的定义。一般情况下,真实模型的clip_skip都使用1,而动漫都使用2,当你选择是的时候这个值被更改为1。而否则改为2。(Clip用1似乎效果不佳,真是玄学,还是用回2吧,不管是真人还是二次元。)
batch_size:较大的batch_size可以加快训练速度,但可能导致内存或显存不足的问题;较小的batch_size可以增加模型的泛化能力,但可能增加训练过程中的抖动和噪声。已经给出了一个参考参数,12g显存,在512分辨率下,可以最多处理6张图像。
epoch:epoch的数量越多,模型的训练效果越好,但过多的epoch可能会导致模型过拟合训练数据,泛化能力下降。
DIM:DIM是特征的数量,也就是输入数据的维度。在机器学习中,每个样本由多个特征组成,而这些特征就对应了输入数据的维度。这个值严重影响lora的质量,太低模型不像,太高容易过拟合。经过多方调试,128被认为是一个最为推荐的数值。它也直接影响输出的模型大小。 dim值和alpha值设定,训练人物一般都设32,64也是可以;训练风格可以用到128。network_dim表示我们训练出来的Lora模型大小,一般不要大于128,因为没收益,小一些的dim可以抗过拟合。
resolution:请设置分辨率,大多数模型的分辨率都是正方形,因此只用提供一个数据。注意,你提供的数据需要为64的倍数设置图片分辨率为 512,640(和你训练的图片分辨率一致)。根据训练集的图片文件的像素来设定即可。resolution没动,因为我的训练图片就是512x512,所以没动。你如果自己的图片分辨率统一都比较大,比如都是1024x1024,你就改一下变成1024,1024。
shuffle_captions :打乱文本数据的操作是对于每个caption随机选择一个其他的caption,然后将它们交换位置,这样就完成了一次打乱操作。打乱操作可以多次进行,从而更大程度地增加数据的随机性”常常用于SD模型。在训练真人模型的时候与二次元模型不同,它的构成是caption + tag的形式。
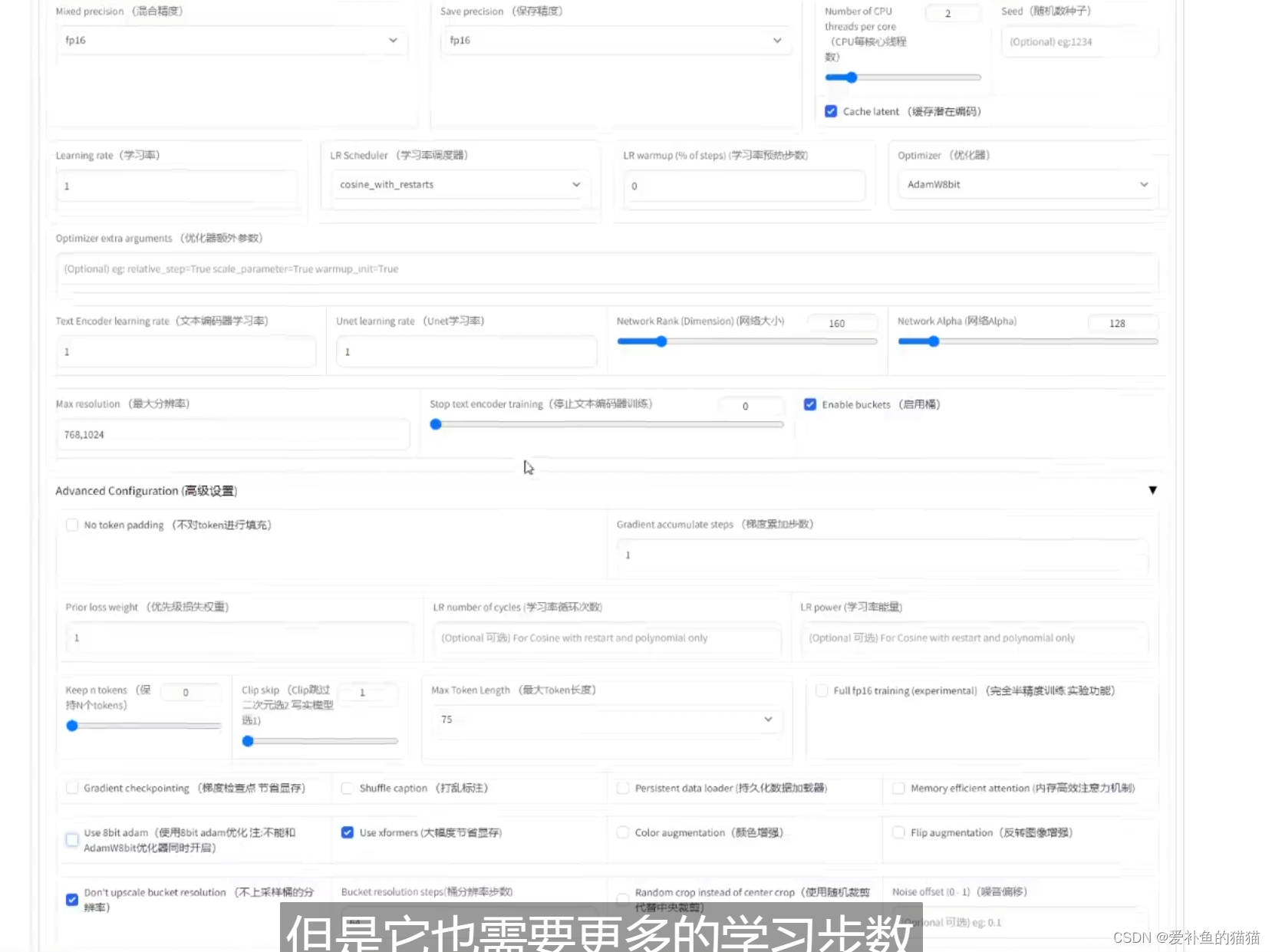
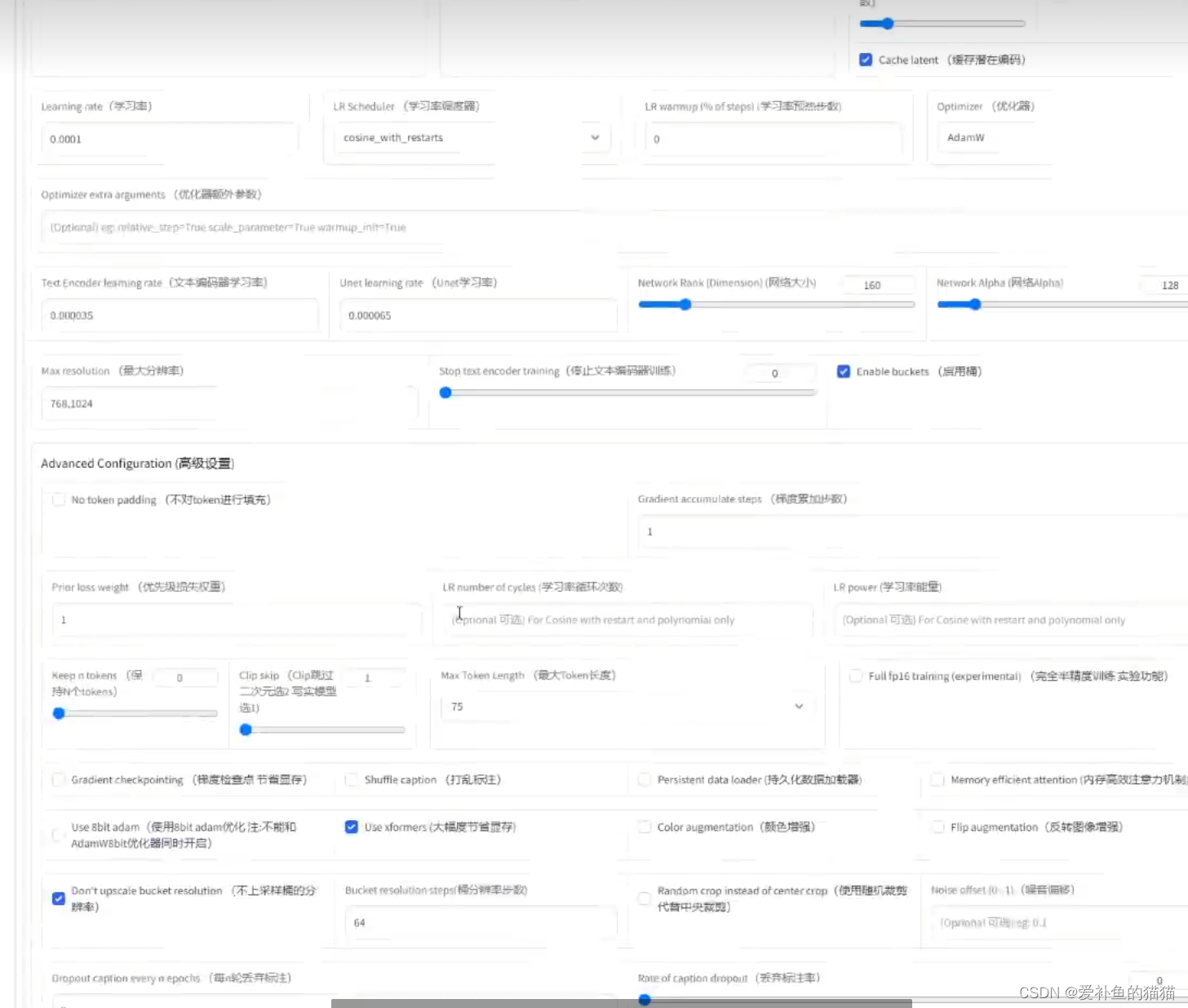
(5)具体设置:
clip_skip:人物选1,(Clip用1似乎效果不佳,真是玄学,还是用回2吧,不管是真人还是二次元。)
network_dimension:128(1024X1024)
该参数不是越高越好。维度提升时有助于学会更多细节,但模型收敛速度变慢,需要的训练时间更长,也更容易过拟合。高分辨率训练集通常需要更高的维度。
训练人物通常设置network_dimension = 32,也可设置16或64,画风可以考虑128。通常训练人物不超过2000 steps 即可完成训练。
alpha :alpha 被推荐设置为 network_dimension 的一半,一些封装的训练脚本也默认这么设置。当alpha设置为一半dim时,scale为0.5,可以放缩网络的权重。削弱上面网络维度的值。Alpha的值为0时相当于Alpha为128,即没有任何削弱。Alpha为1时,相当于削弱到128分之1。
scheduler:cosine_with_restarts
noise_offset:有助于生成特别暗或特别亮的图像,通常设置为 0.1
max_data_loader_n_workers:指定数据加载的进程数。默认是"8或者CPU并发执行线程数 - 1,取小者",
enable_bucket:如果你的训练集有不同分辨率图像则开启,会略微多消耗显存。
max_train_epoches :最大循环训练的次数,通常在5-10,一般设置为6,防止过拟合,如果使用了镜像翻转,导致相同的图片实际训练了两次,可以改为三次
Sample every n epochs: 每 N 轮采样一次,一般设置为 1
Sample prompt: 采样提示词,设置之后,LoRA 训练的同时会每隔设定的步数或轮次,生成一副图片,以此来直观观察 LoRA 训练的进展
prior_loss_weight
使用正则化时使用,该权重控制先验知识强度,默认为1。使用100张以上训练集有人推荐是5%-10%,不要设置更低了,那等于没有正则化,使用正则化权重1时模型收敛会非常困难。我在设置为1时多次炸炉,推荐训练画风时使用正则化。
Min SNR gamma:优化损失函数增强训练过程的稳定性,建议值为5,
min_snr_gamma=0 # minimum signal-to-noise ratio (SNR) value for gamma-ray | 伽马射线事件的最小信噪比(SNR)值 默认为 0
学习率(Learning rate)0.0001
Text Encoder学习率 5e–5
Unet学习率 0.0001
Network : 128和128
模型像素:512x512以上尽量大
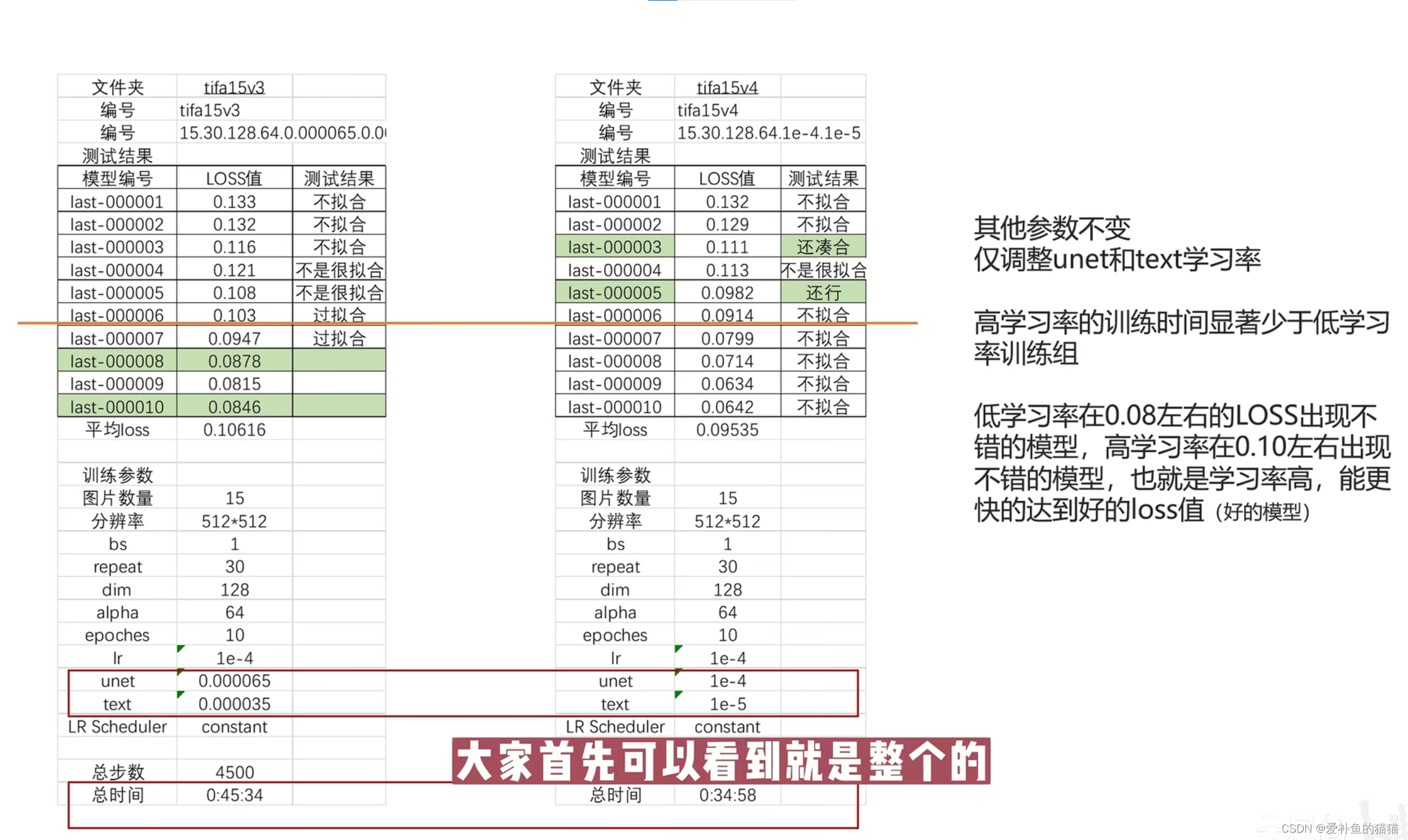
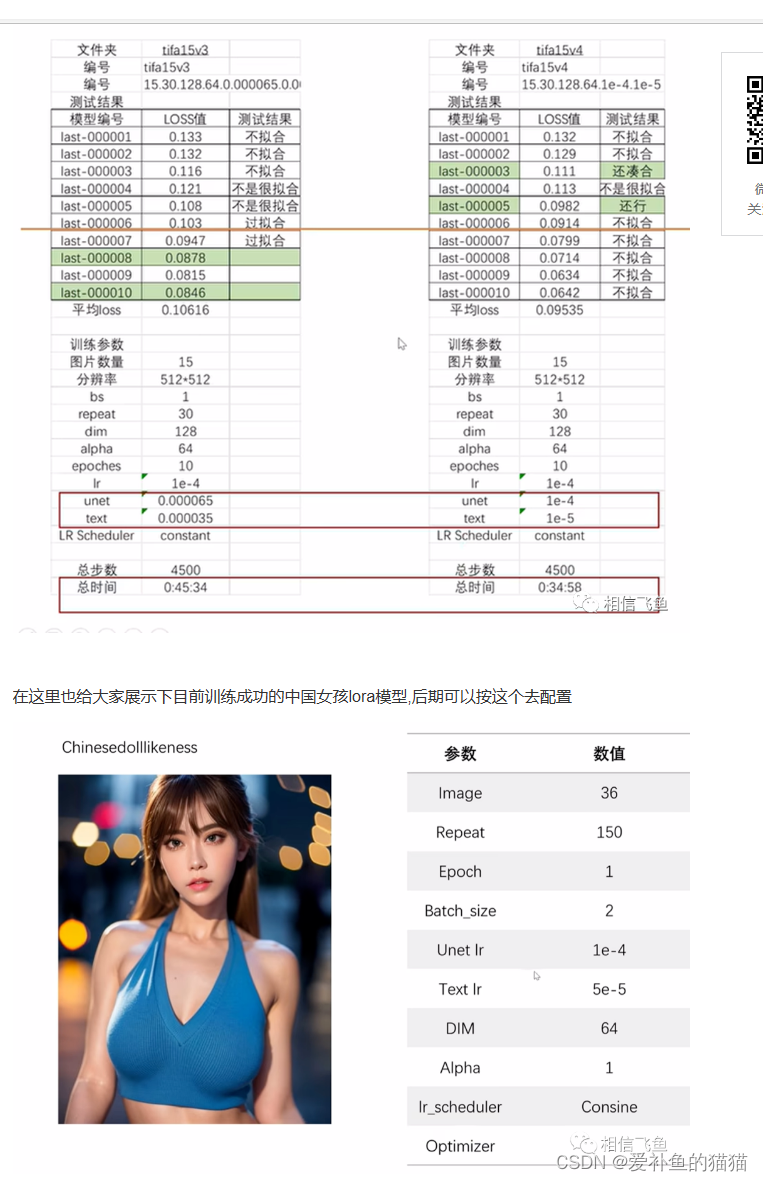
(3)epoch先用10,看一下loss,说是人物loss到0.08左右,二次元0.05左右就可以。从上面有个图也能看出,loss不是越低越好。
(4)unet学习率1e-4。如果loss下不去,就提高学习率;如果loss太低或者没有得到一个特别像的模型,可能是设置高了,再降低些试试。
(5)dim,直接上128就完事。还有个alpha参数,建议是128的一半,不要超过dim。
(6)loss通常0.08左右是最优的,不过也比较玄学,还是用xyz图表测一下。
学习率与优化器
推荐优化器 lion
搭配的学习率:
lr=“7e-5”
unet_lr=“7e-5”
text_encoder_lr=“8e-6”
一般来说按这个设置就没啥问题,当然UP青龙圣者也提到过一个先用DA优化器跑一个最佳学习率再取三分之一是Lion的学习率的说法,但是我觉得这个太费事儿了,一般取这个数效果就挺好……
lora的dim与alpha
Lora分层
(6)注意:
不像:学习率、repect
Text 、Unet学习率设定后,learning rate不生效
Text Encoder学习率 :为unet十分之一,多一位小数,或1/2
Unet学习率:
loss:0.08左右
一般Loss值为0.08~0.1则模型训练的比较好,Loss值为0.08则最佳。
dim
学习率:用adapt寻找
优化器:
1)打标签:(没有的删掉)、不变的不打标签,变部分打标签、错误重复缺失、添加正则里面额外tag比如汉服,这里删除提示词,比如想要什么特征就删掉什么提示词,比如要保留船的特征,那就删掉船的提示词,删掉就是让AI去学习记住这个特征,背景的提示词一定不要删。
于自定义tag和人脸
其实机器是可以识别人脸的,不需要添加 eyes, nose, mouth 。 最多机器会给你有关发型或发色的tag,你是否要删除这些tag,取决于你对人物的需求。如果你需要人物不改变发型或发色,就要去掉这些标注,让机器把这个发型或发色当作人脸的一部分。如果认为以后需要更换发型等,就不要删除tag,甚至如果机器没有给你标注,你还应该自己标注出来。自定义tag我认为是一种补救措施,如果因为什么原因无法调用lora中的元素了,才需要使用自定义tag。
关于自定义tag与1girl。这个问题我在前面帖子里面说过了。你输入1girl,机器优先找lora里面的1girl,如果有,就按照lora里描述的1girl来绘制1girl,如果没有,就到底模(Chillout之类的)里面找1girl来绘制。如果你要做一个人物的lora,第一个tag是1girl,就意味着你使用它生图时候输入1girl就可以了。如果你去掉了1girl,用了一个人物名称代替(比如mywaife),那么你生图的时候第一个prompt就要输入 mywaife。https://g.nga.cn/read.php?&tid=35850123
2)token:触发词
Keep n tokens(保持N个tokens),这个参数是用来设置触发词数量的。在前面提示词打标的时候,你为你的LoRA模型设置了几个触发词,这里就填写几,常见的有1~3。
3)学习率
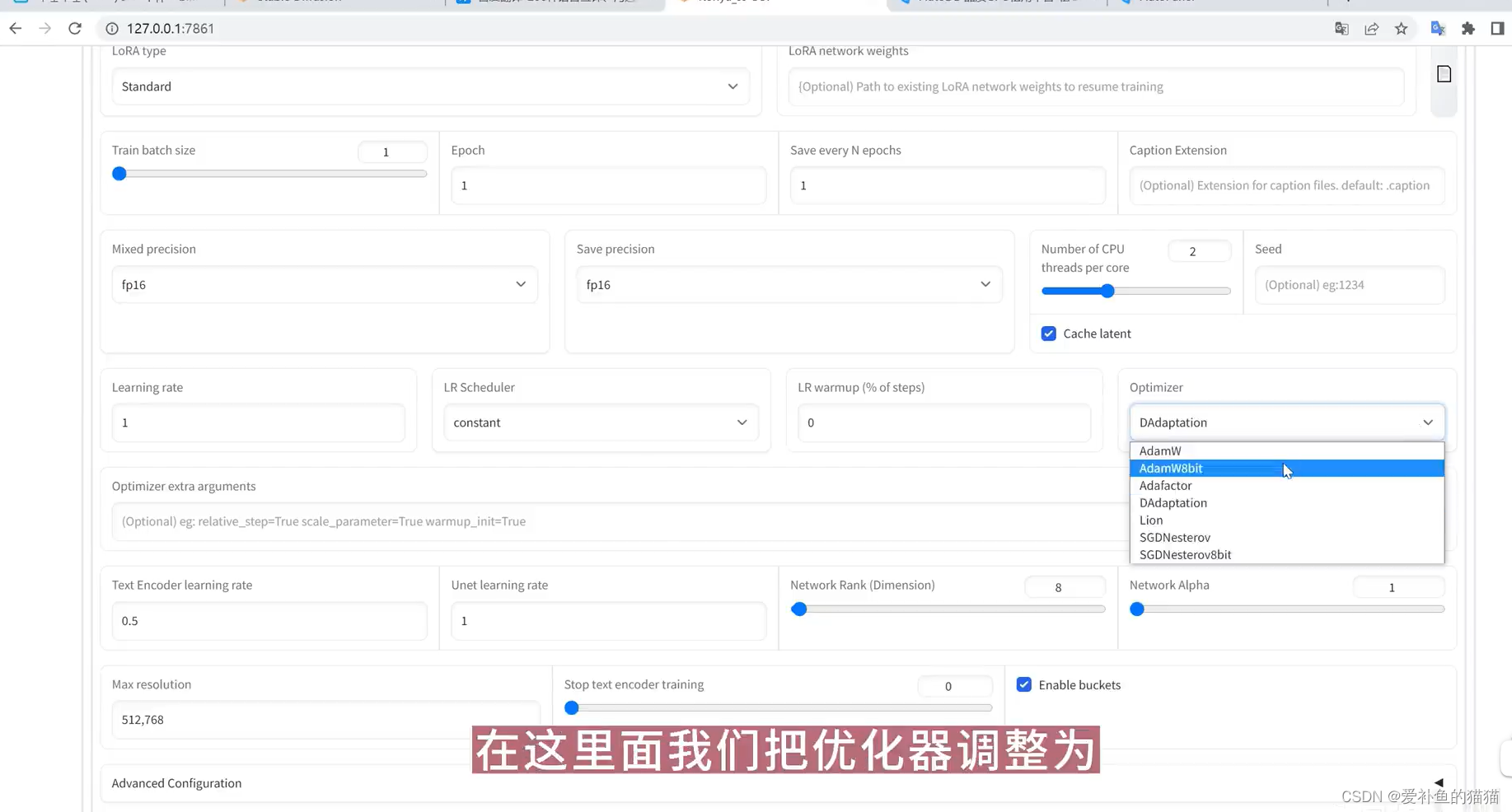
use 8bit adapt和DAdaptation 不能同时开启
自动调整学习率,不要勾选8bit adam,其他照常,Learning rate直接填写1,epoch可以高一些比如说8或者10。Optimizer选择Adafactor(据GUI作者说这个效果最好,我测试下来text略微过拟合)。直接点击训练。如果使用dadaptation,那就让lr=unetlr=1,textlr=0.5(测试下来会有拟合不太够的情况,可能需要调整epoch).
DAdaptation 时,应当将学习率设置在1附近,text_encoder_lr 可以设置成1,或者小一点,0.5之类。使用DAdaptation 时,推荐将学习率调整策略调整为 constant 。
D-Adaptation 优化器自动调整学习率。 学习率选项指定的值不是学习率本身,而是D-Adaptation决定的学习率的应用率,所以通常指定1.0。 如果您希望 Text Encoder 的学习率是 U-Net 的一半,请指定 --text_encoder_lr=0.5 --unet_lr=1.0。
Text Encoder learning rate(文本编码器学习率),一般为Unet learning rate的十分之一或者一半,比如设置为5e-5(1e-4的一半则为5e-5,十分之一则为1e-5)。
使用DAdaptation时,需要把unet学习率设成1,text的学习率设成0.5,让它自动去跑,过一会就能获得一个最优学习率。接下来用AdamW8bit跑,或者Lion学习率调整为最优的1/3跑。
lr_warmup_steps: 热身步数,仅在学习率调度策略为“constant_with_warmup”时需要设置,用来控制模型在训练前逐渐增加学习率的步数。一般不动
lr_restart_cycles: 余弦退火重启次数,仅在学习率调度策略为"cosine_with_restarts"时需要设置,用来控制余弦退火的重启次数。一般不动
学习率
预热比例(warm up ratio)吗?
这是为了在训练开始时避免模型权重更新过于剧烈而采用的策略。学习率预热比例越高,就会有更多的迭代次数用于学习率的逐渐增加,以帮助模型更好地收敛。通常,学习率预热比例设置为训练迭代总数的一小部分,比如1/10或1/20。如果你的总步数为1000,在接下来的设置里请改为50-100。 作者:冬归初雪 https://www.bilibili.com/read/cv22022392 出处:bilibili
lr_warmup_steps=0 # warmup steps | 学习率预热步数,lr_scheduler 为 constant 或 adafactor 时该值需要设为0。
lr_restart_cycles=1 # cosine_with_restarts restart cycles | 余弦退火重启次数,仅在 lr_scheduler 为 cosine_with_restarts 时起效。
lr_warmup_steps:升温步数,仅在学习率调度策略为“constant_with_warmup”时设置,用来控制模型在训练前逐渐增加学习率的步数,一般不动。
lr_restart_cycles:退火重启次数,仅在学习率调度策略为“cosine_with_restarts”时设置,用来控制余弦退火的重启次数,一般不动。
② 采样参数设置
Sample every n epochs:每 N 轮采样一次,一般设置为 1。
Sample every n steps:比如设置为 100,则代表每训练 100 步采样一次。
Sample prompt:采样提示词,设置之后,LoRA 训练的同时会每隔设定的步数或轮次,生成一副图片,以此来直观观察 LoRA 训练的进展。
4)dim
Network Rank(Dimension)维度,代表模型的大小。数值越大模型越精细,常用4~128,如果设置为128,则最终LoRA模型大小为144M。一般现在主流的LoRA模型都是144M,所以根据模型大小便可知道Dimension设置的数值。设置的小,则生成的模型小。
Network Alpha,一般设置为比Network Rank(Dimension)小或者相同,常用的便是Network Rank设置为128,Network Alpha设置为64。
Dim影响学习的深度,也直接决定了文件的大小。dim越大,则学习的深度越深,高的dim更适合学习画风。
Alpha:根据大佬经验,推荐取dim的一半。更低的alpha总体上表现为一种对学习的抑制,比如alpha取1的话一般来说需要更高的学习率。
alpha的大小可以根据数据集和模型的复杂度来确定,通常情况下,alpha越大,模型的正则化程度就越高,复杂度越小,泛化能力越强。反之,alpha越小,模型的正则化程度就越低,复杂度越高,泛化能力越弱。”经过实验调试,这个值为0.25-0.5 dim最佳。
5)loss:0.08左右
一般Loss值为0.08~0.1则模型训练的比较好,Loss值为0.08则最佳。
写错的地方:
1、 DAdaptation 时,应当将学习率设置在1附近,text_encoder_lr 可以设置成1,或者小一点,0.5之类。使用DAdaptation 时,推荐将学习率调整策略调整为 constant 。(constant 设错)
2、cosine_with_restarts设置成constant_with_warmup

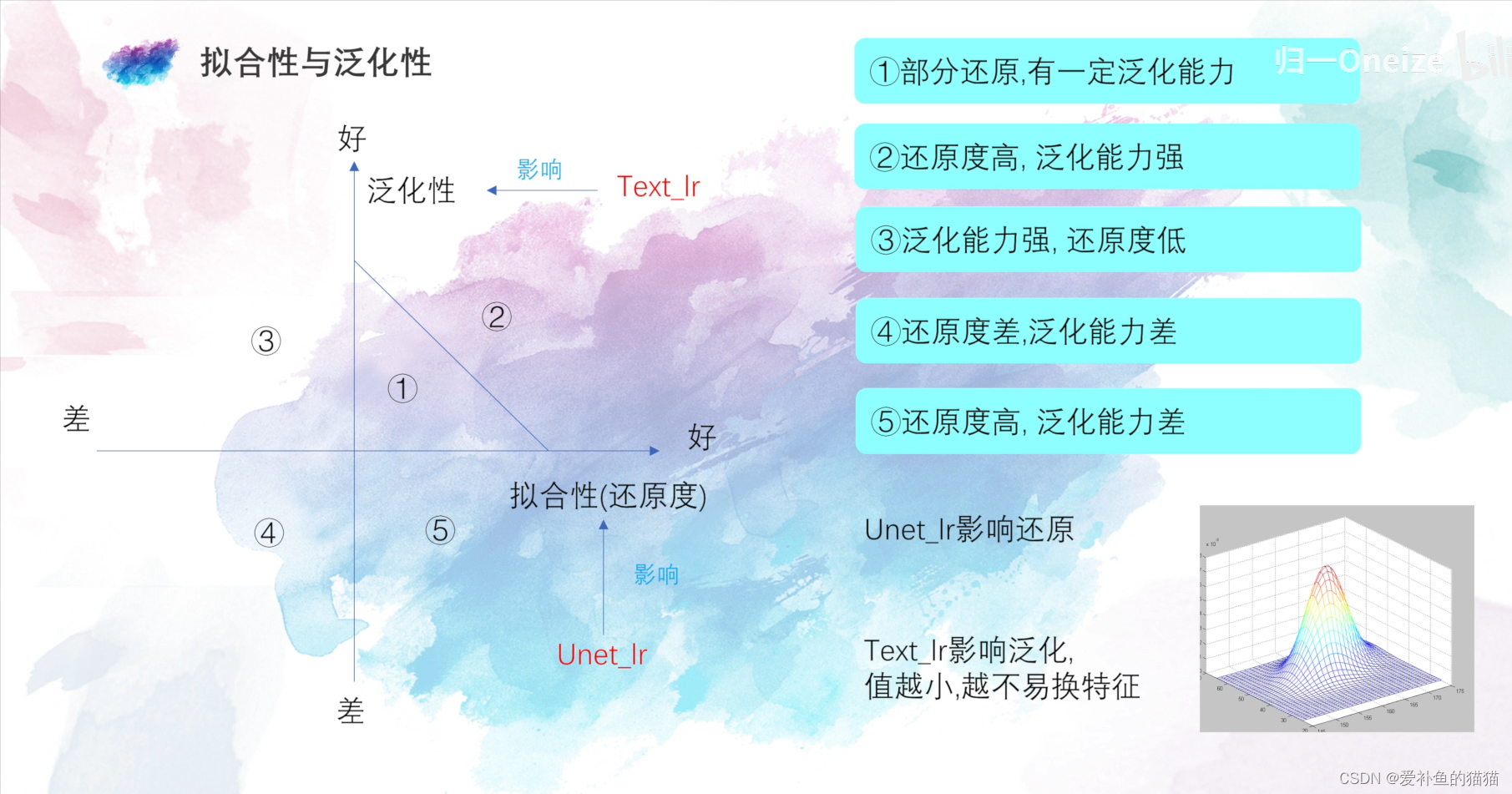
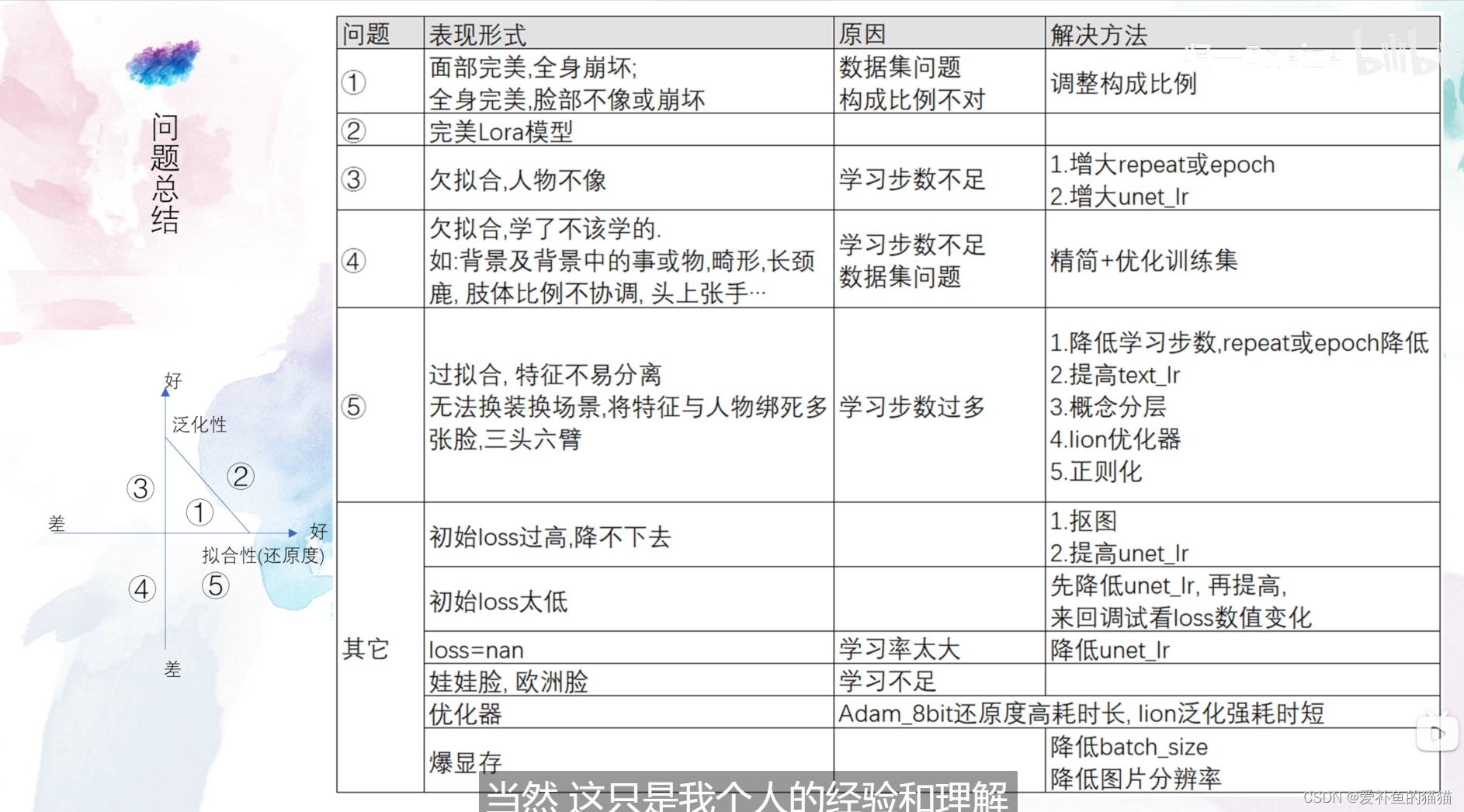
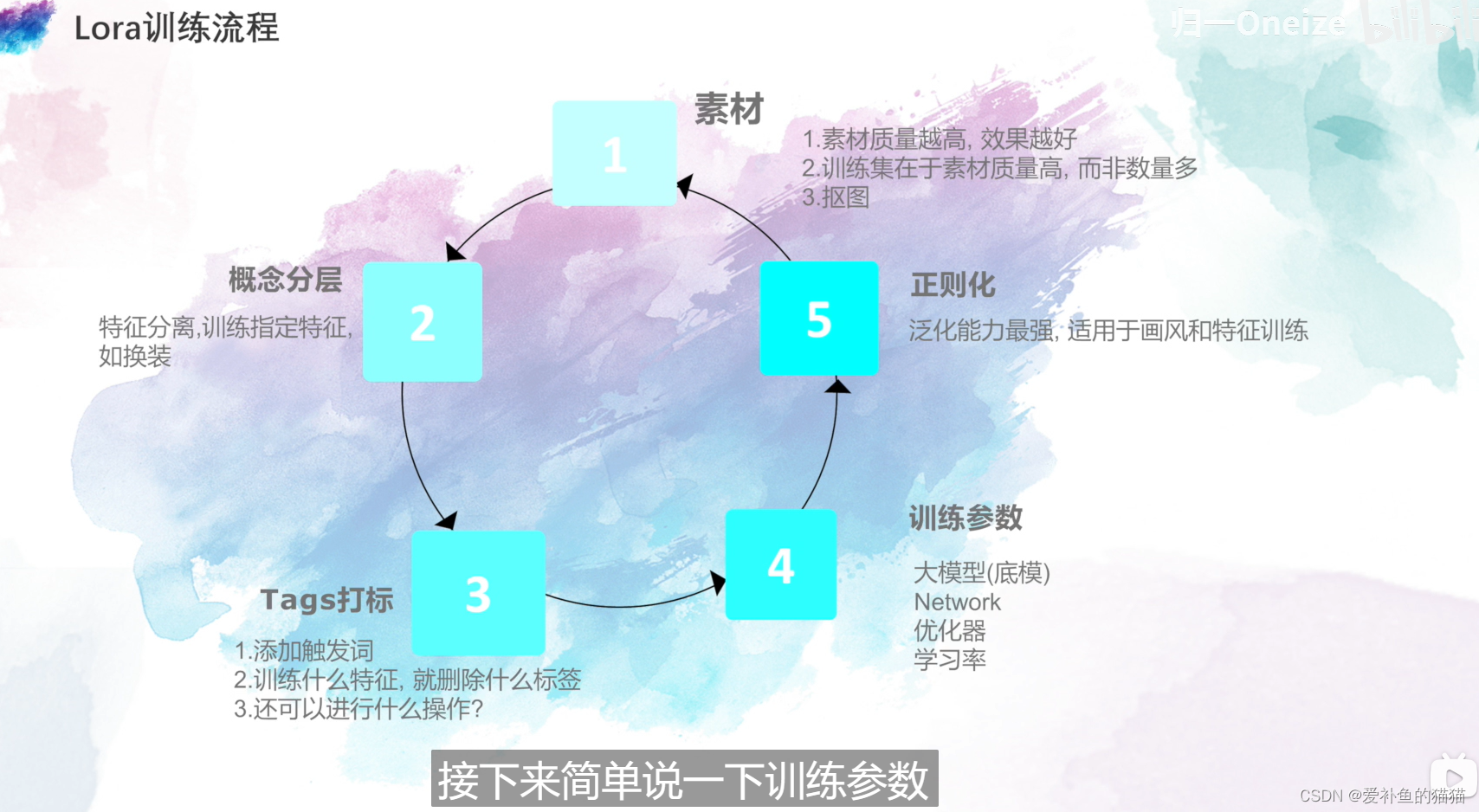


(2)风格模型
参考:
https://zhuanlan.zhihu.com/p/643550056
https://www.bilibili.com/video/BV1Lc411H7kz/?spm_id_from=333.788&vd_source=38e7fc10713eca999c22c7ff25f6e6d2
https://www.bilibili.com/video/BV1jh4y1Z77c/?spm_id_from=333.788.recommend_more_video.0&vd_source=38e7fc10713eca999c22c7ff25f6e6d2
1.打标
打标优化
预处理生成 tags 打标文件后,就需要对文件中的标签再进行优化,一般有两种优化方法:
方法一:保留全部标签
就是对这些标签不做删标处理, 直接用于训练。一般在训练画风,或想省事快速训练人物模型时使用。
优点:不用处理 tags 省时省力,过拟合的出现情况低。
缺点:风格变化大,需要输入大量 tag 来调用、训练时需要把 epoch 训练轮次调高,导致训练时间变长。
方法二:删除部分特征标签
比如训练某个特定角色,要保留蓝眼睛作为其自带特征,那么就要将 blue eyes 标签删除,以防止将基础模型中的 blue eyes 引导到训练的 LoRA 上。简单来说删除标签即将特征与 LoRA 做绑定,保留的话画面可调范围就大。
一般需要删掉的标签:如人物特征 long hair,blue eyes 这类。
不需要删掉的标签:如人物动作 stand,run 这类,人物表情 smile,open mouth 这类,背景 simple background,white background 这类,画幅位置等 full body,upper body,close up 这类。
优点:调用方便,更精准还原特征。
缺点:容易导致过拟合,泛化性降低。
画风:训练集打标签,正则集不要打标签(数量多,重复次数少,不用打标,不用预处理)

训练难易度
不同风格的模型训练难易度不相同,原则就是画面越复杂训练越难,排序就是场景>真人lora>动漫二次元
参考:https://zhuanlan.zhihu.com/p/643550056

3.lora分层
分层训练和分层生成
https://www.bilibili.com/video/BV1jh4y1Z77c/?spm_id_from=333.788.recommend_more_video.0&vd_source=38e7fc10713eca999c22c7ff25f6e6d2
https://www.bilibili.com/video/BV1Cg4y1V7uA/?spm_id_from=333.788.recommend_more_video.0&vd_source=38e7fc10713eca999c22c7ff25f6e6d2
https://www.bilibili.com/video/BV1gV4y1r7e7/?spm_id_from=333.337.search-card.all.click&vd_source=38e7fc10713eca999c22c7ff25f6e6d2
https://www.bilibili.com/video/BV1Cg4y1V7uA/?spm_id_from=333.788&vd_source=38e7fc10713eca999c22c7ff25f6e6d2
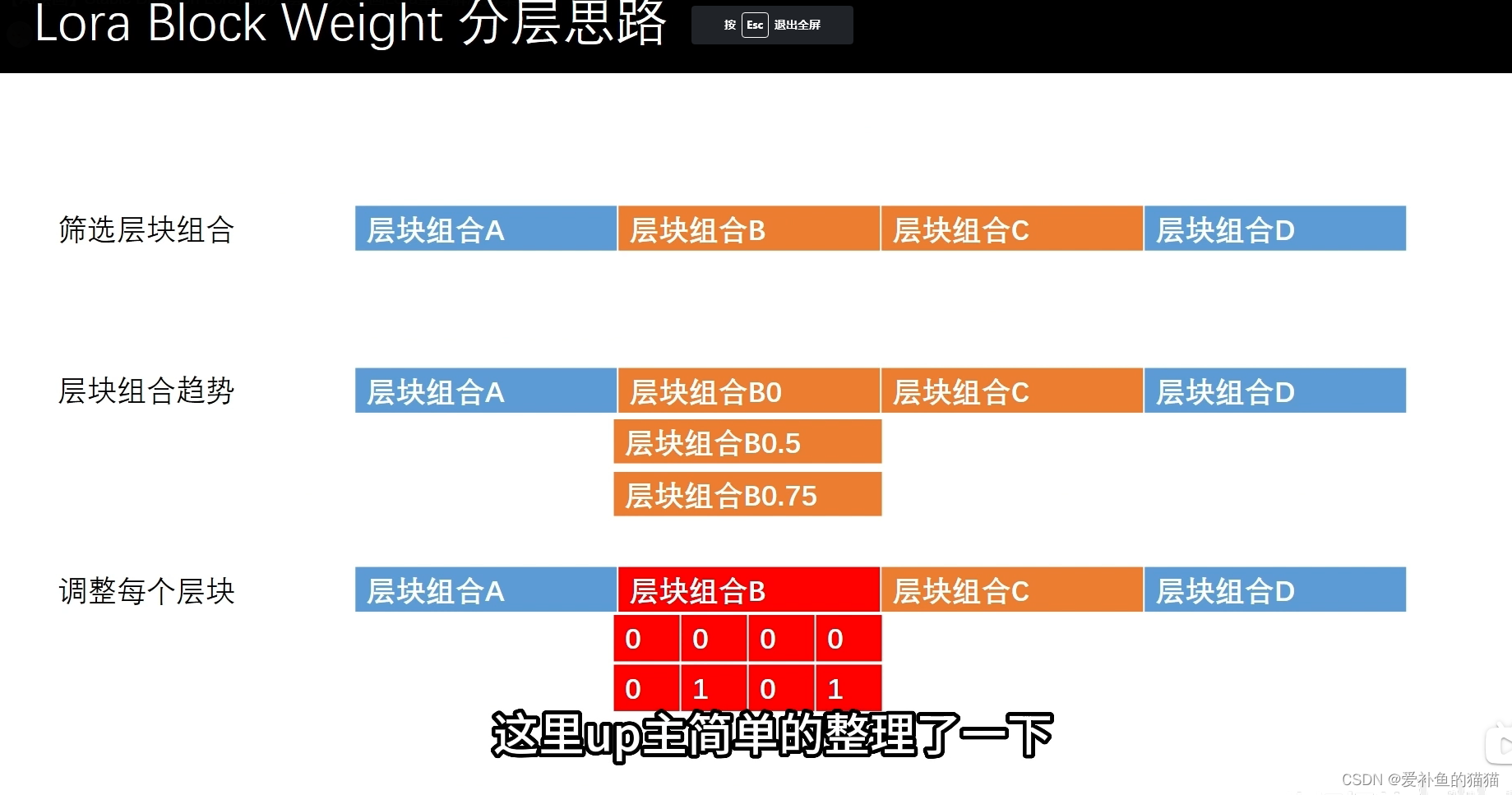
(1)人物和画风
人物预设
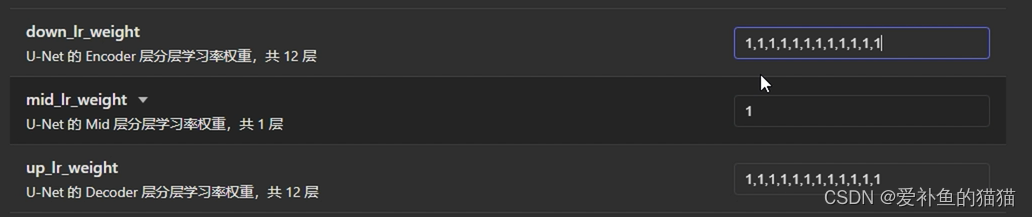
MIDD:1,0,0,0,1,1,1,1,1,1,1,1,0,0,0,0,0(插件自带)
1,0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,01,1,1,1,1,1,1,1,0,0,0,1,1,1,1,1,1
只影响脸部
(强)1,0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,0
(弱)1,0,0,0,0,0,0,0,1,1,1,0.2,0,0,0,0,0
画风预设(慎用,可能造成画风偏移)
1,1,1,1,1,0,0,0,1,1,1,1,1,1,1,0,0
1,0,0,0,0,0,0,0,0,0,0,0.8,1,1,1,1,1
1,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1
1,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1
(2)、服装加角色
1.去除法(人物像服装不像)服装模型去除脸部,人物模型去除服装层
lora:serafuku:0.8:1,1,1,1,1,1,0,1,0,0,0,1,1,1,1,1,1, best quality, 1girl, long hair, blonde hair, blue eyes, (pink japanese school shirt), sailor collar, neckerchief, short sleeves, white skirt, ((upper body)), standing, outdoors, cityscape, streets, buildings, lora:xhcutdef512PH-000011:0.9:1,1,1,1,1,1,0,1,1,1,0,1,1,1,1,1,1
2、去除法:
1,0,0,0,1,1,0,1,1,1,0,1,1,1,1,1,1 去服装
1,1,1,1,1,1,1,1,0,0,0,1,1,1,1,1,1 去脸
3、保留法
1,1,1,1,1,0,0.2,0,0.8,1,1,0.2,0,0,0,0,0 保留服装1
1,1,1,1,0,0,1,0,0,0,1,0,0,0,0,0,0 保留服装2
1,0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,0 保留脸
参考:
2、以下是一些我觉得还不错的预设及介绍:
https://www.bilibili.com/video/BV1Wv4y157NH/?vd_source=1bb2a1943a27115e193397576c3ef83e
影响除脸之外的部分(保持不变脸情况下改变其他部分)
(强)1,1,1,1,1,1,1,1,0,0,0,1,1,1,1,1,1
(弱)1,1,1,1,1,1,0.2,1,0.2,0,0,0.8,1,1,1,1,1影响脸部(脸型、发型、眼型、瞳色等)
(强)1,0,0,0,0,0,0,0,1,1,1,0,0,0,0,0,0
(弱)1,0,0,0,0,0,0,0,0.8,1,1,0.2,0,0,0,0,0服装(搭配tag使用)
1,1,1,1,1,0,0.2,0,0.8,1,1,0.2,0,0,0,0,0动作(搭配tag使用)
1,0,0,0,0,0,0.2,1,1,1,0,0,0,0,0,0,0上色风格(搭配tag使用)
1,0,0,0,0,0,0,0,0,0,0,0.8,1,1,1,1,1角色(去风格化)
1,1,1,1,1,0,0,0,1,1,1,1,1,1,1,0,0背景(去风格化)
1,1,1,1,1,1,0.2,1,0.2,0,0,0.8,1,1,1,0,0减弱过拟合(等同于OUTALL)
1,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1
4、服装
https://www.bilibili.com/video/BV1TV4y1o7rb/?spm_id_from=333.337.search-card.all.click&vd_source=38e7fc10713eca999c22c7ff25f6e6d2
打标时阈值设置

(3)dreambooth
首先,先尝试上述步骤去避免他,如果生成的图片依旧充满噪声。使用 DDIM 调度器或者运行更多推理步骤 (对于我们的实验大概 100 左右就很好了)。这里给出人物训练和物体训练两个不同的测试结果:在我们的实验中,学习率在 2e-6 同时 400 步对于物体已经很好了,但是脸部需要学习率在 1e-6 (或者 2e-6) 同时 1200 步才行。 在训练中使用 Class images 是为了 防止物体的特征 “渗透” 到同一 Class 的其他物体中。如果没有 Class images 作为参考点,AI 会将你的脸与 Class 中出现的其他脸合并。你的脸会渗透进模型生成的其他脸中。
https://zhuanlan.zhihu.com/p/611812910
Set Ratio of Text Encoder Training :面部最佳为0.7。风格最佳为0.2;如果显存不足则设置为0,一般训练 Unet 的效果会更好
准备的图片越多越好,如果训练人像,尽量那个每张图片都不同背景,不同的角度,不同距离,让模型学习到只针对于人像的内容,而不是背景的内容。
(4)模型合并
Stablediffusion这个开源的t2i模型时,不可避免地会碰到两种模型权重的存储格式,即diffusers格式和ckpt格式。
而diffusers格式其实包含:feature_extractor, scheduler, text_encoder, tokenizer, unet, vae这些文件夹以及model_index.json这个文件。大的二进制文件主要位于text_encoder,unet和vae文件夹下。
safetensors是ckpt转换得到的,防止别有用心之人在ckpt文件中加入恶意代码。safetensor和ckpt文件都能直接用于AUTOMATIC111这个为T2I模型开发的WebUI上,而diffusers不行。而diffusers提供的一些代码example又非常有借鉴意义,但一旦使用,其存储类型是一系列目录,这就催生了两种各格式相互转化的需求。

合并LoRA权重,生成全量模型权重
[New] 请优先使用新版合并脚本,所需内存显著降低,只需将以下命令中的脚本替换为scripts/merge_llama_with_chinese_lora_low_mem.py,参数相同。
这一步骤会对原版LLaMA模型(HF格式)扩充中文词表,合并LoRA权重并生成全量模型权重。 此处可以选择输出PyTorch版本权重(.pth文件)或者输出HuggingFace版本权重(.bin文件)。 请优先转为pth文件,比对合并后模型的SHA256无误后按需再转成HF格式。
.pth文件可用于:使用llama.cpp工具进行量化和部署
.bin文件可用于:使用Transformers进行推理、使用text-generation-webui搭建界面
(5)Lora加Adetail
一、风格
1、没用标签
触发词能出发所有数据特征,控制性不稳定,可用于多变风格 结合性不高
2、用标签
触发词只会出发reg正则集效果 要达到训练集效果,需要写具体标签和描述promt 稳定,结合性高
二、人物
1、没用标签
测试一次,感觉相似度比较高,只加触发词 泛化性有限制
2、用标签
抗拟合性比较强,只用出发词,相似度下降一点 泛化性好
三、提高人物相似度
adetail不用裁脸,提高dim训练维度,直接训练或扣除背景减少信息量损失。
其他
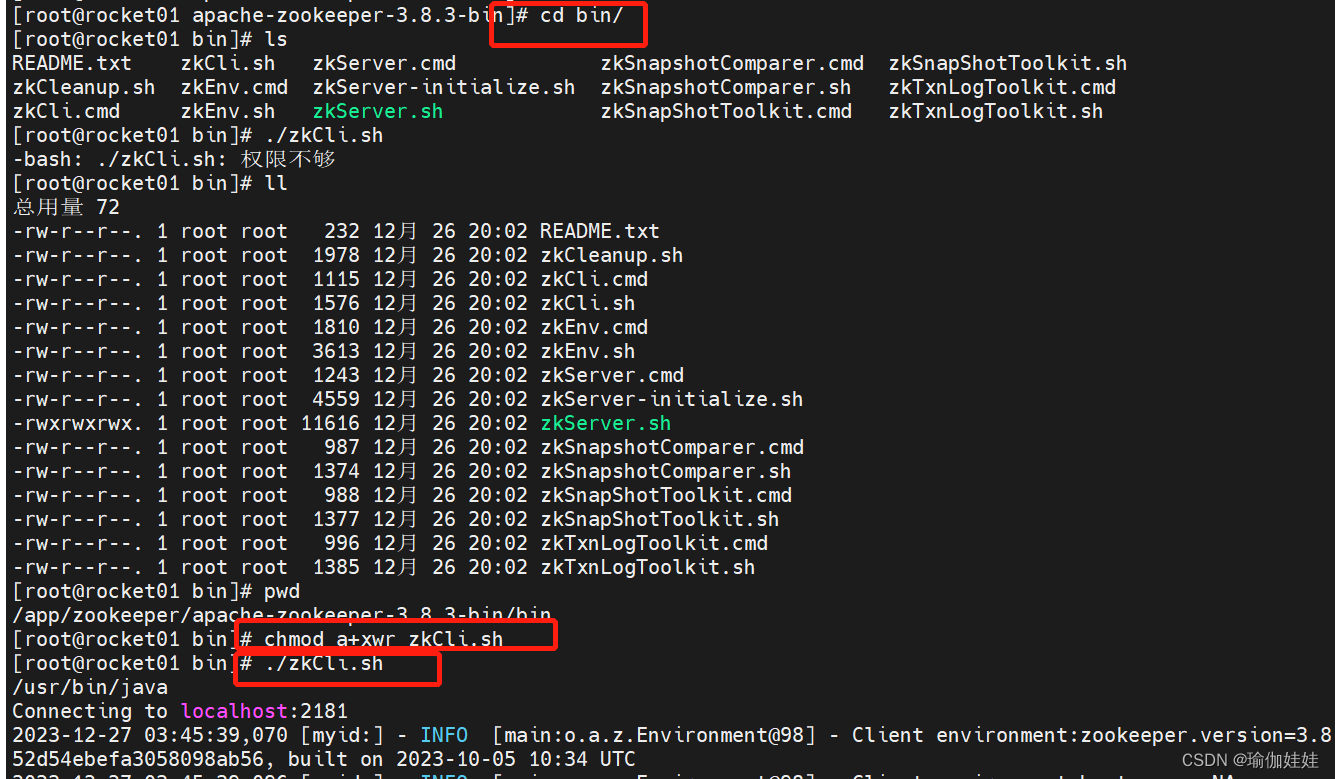
2、文件权限,sh文件没权限
查看linux文件的权限:ls -l 文件名称
chmod +x 和chmod a+x 是一样的,一般没有明确要求,可以就用chmod +x
3、环境变量
no display name and no $DISPLAY environment variable
export DISPLAY=:6.0
xhost +
说明:
# 端口
export DISPLAY=:6.0#激活环境
conda activate kohyass
# 运行
./gui.sh --listen 127.0.0.1 --server_port 6006 --inbrowser --share# 打标签
勾选Overwrite existing captions in folder#训练
取消xformersexport http_proxy=http://192.168.1.174:12798 && export https_proxy=http://192.168.1.174:12798
cd /root/autodl-tmp/Lora/kohya_ss
export DISPLAY=:6.0
source activate kohyass
./gui.sh --listen 127.0.0.1 --server_port 6006 --inbrowser --share什么是CLI(命令行界面)、GUI(图形用户界面)、Terminal(终端)、Console(控制台)、Shell、TTY https://blog.csdn.net/csdn100861/article/details/116414786
4、端口
netstat -a查看所有的服务端口(LISTEN,ESTABLISHED)
查看指定端口,可以结合grep命令:
netstat -ap | grep 8080
也可以使用lsof命令:lsof -i:8888
若要关闭使用这个端口的程序,使用kill + 对应的pid
kill -9 PID号
5、
wget下载文件,git 下载仓库
wget命令
用来从指定的url下载文件,wget非常稳定,对带宽具有很强的适应性。
git clone
git clone 命令将存储库克隆到新目录中(专门用来下载github上东西使用的)
wget可以见用wget下载Github仓库中的脚本等文件
换脸
Avatarify
SimSwap
DeepFaceLab
FaceSwap
Faceplay(app)
换脸api
Face++的API
换衣服
imagen
deepfloyd
视频
TemporalKit
技术:
1、一张图替代 LoRa:ControlNet 发布重大更新 Reference Only
2、多个controlnet
3、control lite
4、种子
5、SD视频
mov2mov
controlnet M2M
multi-frame-rendering脚本
TemporalKit+EbSynth自动化拼接拆分生成风格视频
图生图批量处理制作AI视频(脚本)
photoshop 将视频转成逐帧图片的方法
Deforum根据文本描述词自动生成视频
注意:输出图片的像素也会影响生成效果
-
mutil-control net
1)对于以人物为主的AI动画来说,我们需要使用的就是depth和softedge 。
2)Controlnet第一个选择depth_zoe,模型选择下载的depth新模型,权重为1,其他的不变;Controlnet第二个选择softedge_pidinet或者HED,模型选择softedge,权重在0.6起步,如果测试画面变化较大,则调大该数值,最高到1。 -
Lora
TAG: lora:fashionGirl_v50:1,fashi-g,red lips
负面TAG:easy,nsfw
采样器:Euler a ,DPM ++ SDE Karras 都可以
采样步数:26-32,这里我选的是30
面部修复:勾选
宽度高度:跟随原图,我这里选的是 4K画质 1080*1980
提示词引导系数:7-8 之间,我这里选了7
重绘强度:0.45
模型
去civitai找,里面有分类和hugging face下载链接
写实风模型 #
说到万模型之母,不得不提原始版的Stable Diffusion了,简称SD,是CompVis与合作团队最初发表的模型,不断更新中。
最初 Stable Diffusion v1是使用512x512像素的图片训练的,因此高于此尺寸的生图品质会变差。后来 Stable Diffusion v2的训练图片宽高提升到了768x768像素。
网络上很多模型都基于此模型训练而来。适合画真人、动物、自然、科技、建筑的图像,亦学习过历史上许多画家的画风。
Chilloutmix:写实风格的模型,适合画出2.5次元,融合日韩真人与动漫风格的图像。
Deliberate:基于SD-1.5模型,适合生成精致写实风格的人物、动物、自然风景。
Realistic Vision v1.4:写实风人物与动物模型。
动漫风模型 #
Anything万象熔炉 v4.5适合画动漫图,作者宣称不需要打一堆提示词也能出漂亮的图。
Waifu Diffusion v1.4是纯粹使用Danbooru图库训练而成,适合画动漫图。
Hentai Diffusion适合画动漫图,模型已使用大量负向提示词训练过以排除不良结果,另提供embeddings方便绘图时使用。
DreamShaper是基于SD-1.5模型,生成精细动漫人物与油画风格的模型。
OrangeMix3,混合多种风格的动漫绘图模型,偏写实。
二次元
底模型。一种不错的选择是,二次元选择novelai,训练三次元选择sd1.5,训练人物服装chilloutmix。也可以选择其他模型。使用 SD2.x based model 时,需要勾选 v2 参数。
最近模型的迭代速度越来越快,截止目前效果比较好的二次元模型有:AOM2,pastelmix,anything-v3.0,Counterfeit-V2.5。
推荐链接:https://www.bilibili.com/read/cv20538746
meinaMIX meinaMIX大模型,这个模型非常万能,不需要VAE,不论是挂群机器人api生图,还是自己作图,不需要非常严格的tag都能出非常好的效果,同时对于AI动画来说,是我尝试过无数模型后选择的最优解。 作者:以太之尘丨 https://www.bilibili.com/read/cv23190880/
写实
三、sd api
1、风格模型和风格
“风格模型”不是“风格”,风格模型是指训练的Lora等风格模型;风格在prompt中直接写,逗号分隔即可。(不是先用生成文生成图,再用生成的图用风格模型生成不同风格)
2、#api用listen
python launch.py --share --autolaunch --deepdanbooru --xformers --no-gradio-queue --port 6006 --nowebui --listen
python launch.py --share --xformers --port 6006 --nowebui --listen --allow-code --enable-insecure-extension-access --api-log
python launch.py --share --xformers --port 6006 --nowebui
python launch.py --share --xformers --port 6006 --listen --allow-code --enable-insecure-extension-access --api-log --api
–allow-code 允许从web UI执行自定义脚本
–enable-insecure-extension-access 启用扩展选项卡,而不考虑其他选项。
–api-log 启用所有API请求的日志记录。
1.texttoimg
参数,要删掉或合理设置
“script_name”: “string”,
“sampler_name”: “string”,
2、contronet、基底模型、Lora(只设置txt2img参数)
“module”: None,时input_image可以直接用姿势图
lora不生效:https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/12387/files
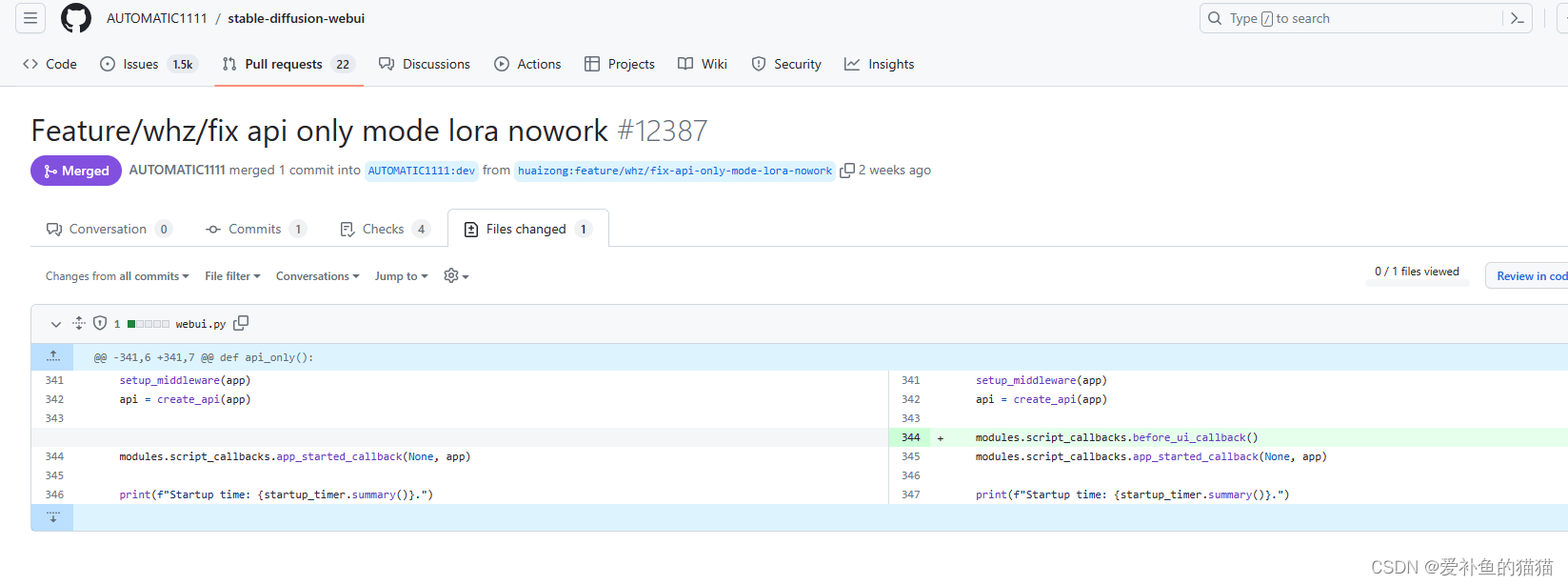
import io
import cv2
import base64
import requestsfrom PIL import Image# A1111 URL
# url = "https://u132133-9d45-09ef11c3.beijinga.seetacloud.com"
url = "http://127.0.0.1:6006"# Read Image in RGB order
img = cv2.imread('./img/xue.jpg')
# img2 = cv2.imread('./img/mask2.png')
# img3 = cv2.imread('./img/black.png')# Encode into PNG and send to ControlNet
retval, bytes = cv2.imencode('.png', img)
encoded_image = base64.b64encode(bytes).decode('utf-8')# retval2, bytes2 = cv2.imencode('.png', img2)
# mask_image = base64.b64encode(bytes2).decode('utf-8')
#
# retval3, bytes3 = cv2.imencode('.png', img3)
# black_image = base64.b64encode(bytes3).decode('utf-8')# A1111 payload
payload = {"prompt": 'LYF@SEAN,(wearing a turtleneck sweater:1.2),(RAW photo, best quality), (realistic, photo-realistic:1.4), masterpiece, an extremely delicate and beautiful, extremely detailed, 2k wallpaper, Amazing, finely detail, extremely detailed CG unity 8k wallpaper, ultra-detailed, highres, soft light, beautiful detailed girl, extremely detailed eyes and face, beautiful detailed nose, beautiful detailed eyes,cinematic lighting,city lights at night,perfect anatomy,slender body,light smile,(close up:1.1) <lora:minnielorashy:1> ',"negative_prompt": "paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), dot, mole, lowers, normal quality, monochrome, grayscale, lowers, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, username, watermark, signature",## "prompt":"cat",# "styles": [# "liuyefeiwithLora"# ],"batch_size": 5,"steps": 20,"cfg_scale": 7,"alwayson_scripts": {"controlnet": {"args": [{"input_image": encoded_image,# "input_image": mask_image,# "mask":black_image,"module": "openpose","model": "control_v11p_sd15_openpose [cab727d4]","pixel_perfect":True,}]}},#"module": None,时input_image可以直接用姿势图# "alwayson_scripts": {# "controlnet": {# "args": [# {## # "input_image": encoded_image,# "input_image": mask_image,# # "mask":black_image,# "module": None,# "model": "control_v11p_sd15_openpose [cab727d4]",# "pixel_perfect":False,# }# ]# }# },"override_settings": {"sd_model_checkpoint": "v1-5-pruned-emaonly.safetensors [6ce0161689]"}, # SakuraMix.safetensors [1fd567aac7] RealisticAsians.safetensors [bc2f30f4ad]"override_settings_restore_afterwards": True,}# Trigger Generation
response = requests.post(url=f'{url}/sdapi/v1/txt2img', json=payload)# Read results
r = response.json()
print('返回:',len(r['images']))result = r['images'][0]
# image = Image.open(io.BytesIO(base64.b64decode(result.split(",", 1)[0])))
# image.save(f'./img/{key}output.png')
print('返回:',len(r['images']))
for key,valu in enumerate(r['images']):image = Image.open(io.BytesIO(base64.b64decode(valu.split(",", 1)[0])))image.save(f'./img/{key}output.png')
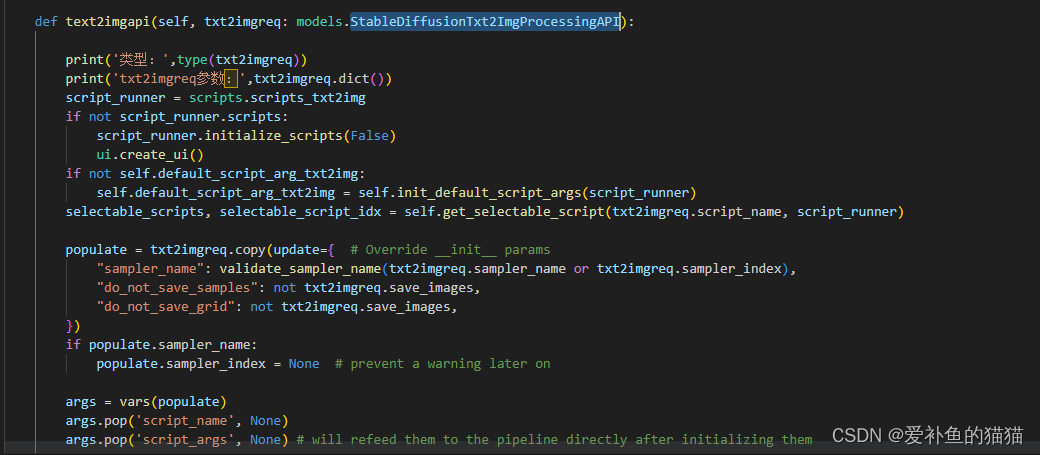
3、api函数
create_model模型函数如何加入json
def text2imgapi(self, txt2imgreq: models.StableDiffusionTxt2ImgProcessingAPI):中的参数StableDiffusionTxt2ImgProcessingAPI返回值是create_model,该对象值设置格式txt2imgreq2(**data)
from pydantic import BaseModel
data1={"prompt": 'LYF@SEAN,(wearing a turtleneck sweater:1.2),(RAW photo, best quality), (realistic, photo-realistic:1.4), masterpiece, an extremely delicate and beautiful, extremely detailed, 2k wallpaper, Amazing, finely detail, extremely detailed CG unity 8k wallpaper, ultra-detailed, highres, soft light, beautiful detailed girl, extremely detailed eyes and face, beautiful detailed nose, beautiful detailed eyes,cinematic lighting,city lights at night,perfect anatomy,slender body,light smile,(close up:1.1) <lora:minnielorashy:1> ',"negative_prompt": "paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), dot, mole, lowers, normal quality, monochrome, grayscale, lowers, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, username, watermark, signature",## "prompt":"cat",# "styles": [# "liuyefeiwithLora"# ],"alwayson_scripts": {"controlnet": {"args": [{"input_image": encoded_image,# "input_image": mask_image,# "mask":black_image,"module": "openpose_full","model": "control_v11p_sd15_openpose [cab727d4]",# "pixel_perfect":False,}]}},"batch_size": 6,"steps": 20,"cfg_scale": 7,"override_settings": {"sd_model_checkpoint": "v1-5-pruned-emaonly.safetensors [6ce0161689]"}, # SakuraMix.safetensors [1fd567aac7] RealisticAsians.safetensors [bc2f30f4ad]"override_settings_restore_afterwards": True,}data2={'enable_hr': False, 'denoising_strength': 0, 'firstphase_width': 0, 'firstphase_height': 0, 'hr_scale': 2.0, 'hr_upscaler': None, 'hr_second_pass_steps': 0, 'hr_resize_x': 0, 'hr_resize_y': 0, 'hr_sampler_name': None, 'hr_prompt': '', 'hr_negative_prompt': '', 'prompt': '', 'styles': ['liuyefeiwithLora'], 'seed': -1, 'subseed': -1, 'subseed_strength': 0, 'seed_resize_from_h': -1, 'seed_resize_from_w': -1, 'sampler_name': None, 'batch_size': 5, 'n_iter': 1, 'steps': 20, 'cfg_scale': 7.0, 'width': 512, 'height': 512, 'restore_faces': False, 'tiling': False, 'do_not_save_samples': False, 'do_not_save_grid': False, 'negative_prompt': None, 'eta': None, 's_min_uncond': 0.0, 's_churn': 0.0, 's_tmax': None, 's_tmin': 0.0, 's_noise': 1.0, 'override_settings': {'sd_model_checkpoint': 'RealisticAsians.safetensors [bc2f30f4ad]'}, 'override_settings_restore_afterwards': True, 'script_args': [], 'sampler_index': 'Euler', 'script_name': None, 'send_images': True, 'save_images': False, 'alwayson_scripts': {}}from modules.api import modelstxt2imgreq=models.StableDiffusionTxt2ImgProcessingAPIfrom modules.processing import StableDiffusionProcessingTxt2Imgtxt2imgreq2=models.PydanticModelGenerator("StableDiffusionProcessingTxt2Img",StableDiffusionProcessingTxt2Img,[{"key": "sampler_index", "type": str, "default": "Euler"},{"key": "script_name", "type": str, "default": None},{"key": "script_args", "type": list, "default": []},{"key": "send_images", "type": bool, "default": True},{"key": "save_images", "type": bool, "default": False},{"key": "alwayson_scripts", "type": dict, "default": {}},]
).generate_model()txt2imgreq3=txt2imgreq2(**data1)print('开始执行:',txt2imgreq3)response=api.text2imgapi(txt2imgreq3)# response=vars(response)# print('结果:',response)print('结果类型:',type(response))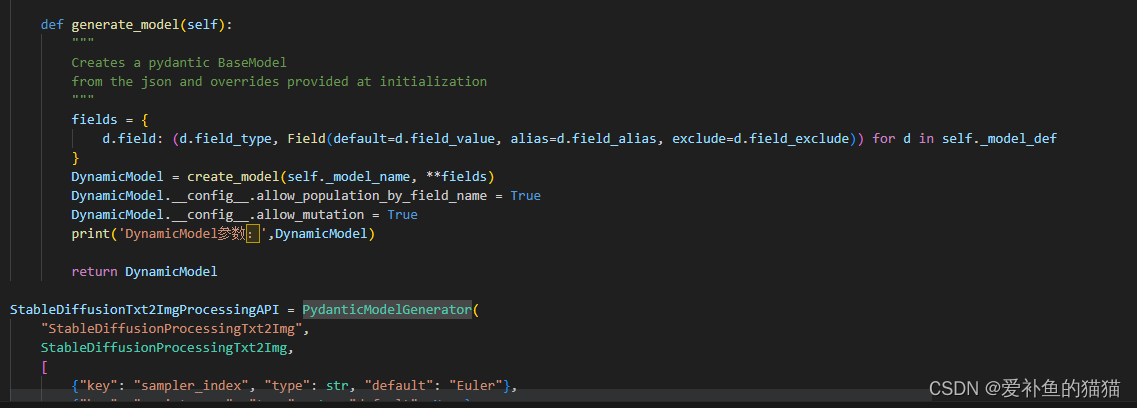
四、ai视频模型
视频风格:
视频转动漫:AnimeGANv3
视频转卡通:White-box-Cartoonization
WebtoonMe:Webtoon,web+cartoon,也就是“网页版漫画”,是漫画的一种呈现形式,出自韩国。
Gen-1的人工智能模型,可以通过应用文本提示或者参考图像所指定的任意风格,将现有视频转换为新视频。
APP:
faceplay
StyleX
wink
illusion style
文生视频
Stable Animation
Gen-2
换脸
Avatarify
SimSwap
DeepFaceLab
FaceSwap
1、deepfacelab
其实知道了差别,就应该大概明白怎么选了。核心原则就是根据自身情况和应用场景选择。比如你的显卡显存只有2G,那么你就直接选择Quick96好了,其他基本没得选了。如果你需要能灵活设置参数,实现高质量的视频换脸,那么肯定用SAEHD。如果你训练模型是为了应用在DeepFaceLive中实现实时换脸,那么推荐AMP。当然,SAEHD其实也是可以用于DeepFaceLvie。
- 应用场景不一样。
Quick96适合入门,适合快速合成的项目。特点就是快,缺点就是质量一般般。
SAEHD用于高质量的视频合成,相应的学习和训练的时间也会被拉长。
AMP为了实时换脸而打造,为了这个目的而做了一些优化。
五、换脸
效果比较好的:facefusion、afterdetail、roop
AI Deepfakes 就是人工智能的深度换脸技术。简单来说就是脸部替换,可以将B的脸换到A的脸上。和PS不同的是,这项技术不仅可以生成图片,还是可以生成视频的,而且你并不需要懂得那么多的技术。只要你收集到足够素材,程序的AI就可以帮你自动完成。举个例子,你可以将自己的脸换到特朗普总统演讲的视频上,这样看上去像是你自己在总统演讲,只要你的脸部表情素材足够多,换完之后表情颜色和口型会非常自然。
Deepfake技术发展过程(截止2020.01,涵盖AI换脸):
2014.06:提出生成对抗网络(GAN),在图片创建方面取得重大突破,之前的AI算法可以较好的分类图片但创建图片困难;
2017.07:提出一种使用RNN 的LSTM(Long Short-Term Memory)学习口腔形状和声音之间关联性的方法,仅通过音频即可合成对应的口部特征;
2017.10:提出一种基于 GAN 的自动化实时换脸技术;
2017.12:出现deepfake色情视频,名人的面孔被换成色情演员的面孔,由Reddit用户使用自动编码器-解码器配对结构开发(FakeApp前身);
2018.04:出现美国前总统奥巴马的deepfake演讲,将声优的口型(含模仿的配音)替换到奥巴马演讲视频中,使用了FakeApp;
2018.08:提出一种将源视频中的运动转移到另一个视频中目标人的方法,而不仅是换脸(效果imperfect);
2019.03:提出一种控制图片生成器并能编辑造假图片各方面特性的方法,比如肤色、头发颜色和背景内容,不同于之前的假人图片生成方法,这是一种重大突破;
2019.05:提出一种真实头部说话神经模型的少样本对抗学习,基于GAN元学习,该模型基于少量图像(few-shot)训练后,向其输入一张人物头像,可以生成人物头像开口说话的动图;
2019.06:出现“一键式”智能脱衣软件 Deepnude,迫于舆论压力,开发者快速下架。
2020:主要进展在提高原生分辨率、提升deepfake制作效果方面。
deepfacelab、FaceSwap或ZAO哪个最适,对比
- DeepFaceLab
优点:
可手动调整每帧中的脸部识别,减少提取脸部时的错误
mt模式下训练出的效果很好,脸部贴合度高
可选择的训练模式较多
有集成环境版本,只需正确安装驱动即可使用,无需单独搭建环境,对非专业人士较友好
缺点:mt模式的训练时间较长,但最后效果最好 - FaceSwap
优点:
模型训练速度较快,同样配置下更快的到达低loss值
有gui界面版本
缺点:
安装环境较复杂,特别是安装vc++2015,如果电脑自带其他vc++版本,清理替换是个比较麻烦的过程
总结
推荐新人直接上手DeepFaceLab的集成环境版本
换脸
Avatarify
SimSwap
DeepFaceLab
FaceSwap
FaceApp和Avatarify
新Make-A-Protagonist
SimSwap:单张图视频换脸的项目(图–>视频)
FaceShifter:一秒换脸的人脸交换模型(图–>图)
DeepFaceLab:视频训练模型,再用模型转换视频(视—>模—>视)
DeepFacelive:直播换脸(模–>视)
Make-A-Protagonist:一张照片即可换脸、换背景(图–>背景)
Avatarify :动画头像(图---->动画)
换脸相关算法:
1、One-Shot Face Video Re-enactment using Hybrid Latent Spaces of StyleGAN2
2、DiffFace: Diffusion-based Face Swapping with Facial Guidance
3、FlowFace: Semantic Flow-guided Shape-aware Face Swapping
4、Landmark Enforcement and Style Manipulation for Generative Morphing
5、SimSwap: An Efficient Framework For High Fidelity Face Swapping
6、FaceDancer: Pose- and Occlusion-Aware High Fidelity Face Swapping
7、StyleMask: Disentangling the Style Space of StyleGAN2 for Neural
8、StyleSwap: Style-Based Generator Empowers Robust Face Swapping
9、Region-Aware Face Swapping
10、MobileFaceSwap: A Lightweight F
扩散模型
【CVPR2022】DiffFace: Diffusion-based Face Swapping with Facial Guidance
GAN
【ACM_2020】SimSwap: An Efficient Framework For High Fidelity Face Swapping
【CVPR_2020(Oral)】FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping
【CVPR_2021】HifiFace: 3D Shape and Semantic Prior Guided High Fidelity Face Swapping
【PAMI_2022】FSGANv2: Improved Subject Agnostic Face Swapping and Reenactment
StyleGAN
【CVPR_2022.6】Region-Aware Face Swapping
【CVPR_2022】High-resolution Face Swapping via Latent Semantics Disentanglement
【CVPR_2023】E4S: Fine-grained Face Swapping via Regional GAN Inversion
【补充精读】Supplement for “ Fine-Grained Face Swapping via Regional GAN Inversion”
测试效果:
1、deepfacelab
1。conda中shell问题
修改shell文件中的conda虚拟环境
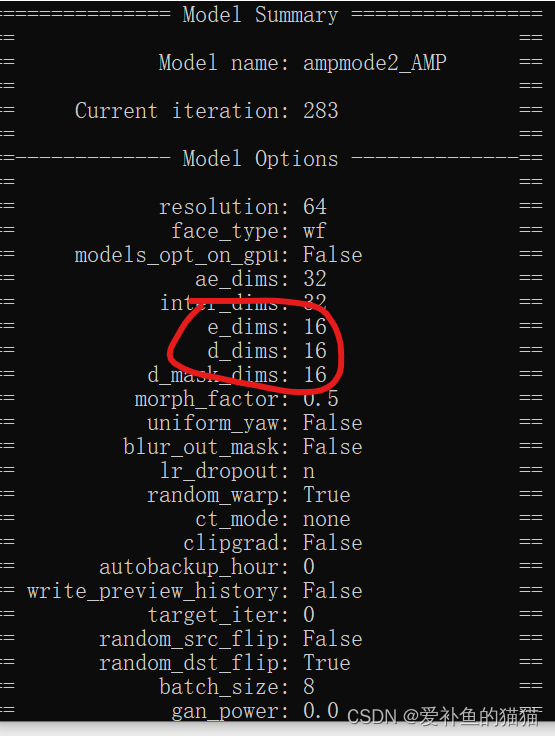
2。SAEHD和AMP(Linux没有amp)
维度参数要合理设置,内存比较小的时候,选最小维度dims
结合gpu内存vram大小设置
2、deepfacelive
使用obs链接直播
3、e4s
效果很差
六、voice2face
三维人脸重建技术
语音驱动三维人脸
简单介绍
Audio2Mesh
2017 英伟达 Audio2Face
CVPR 2019 马普所 VOCA
CVPR 2021 Facebook MeshTalk
CVPR 2022 香港大学 Faceformer
Audio2ExpressionCoefficient
2022 Facegood Audio2Face
参考:https://zhuanlan.zhihu.com/p/484217988#Audio2ExpressionCoefficient
2022 Facegood Audio2Face
Voice2Face是FACEGOOD(量子动力)在2022年年初,开源的一项关于语音驱动三维人脸的项目。
APP
xpression camera
基于视频的三维人脸重建
https://blog.csdn.net/qq_14845119/article/details/112325281
七、clash代理
查看系统架构,uname -a
x86_64 GNU/Linux
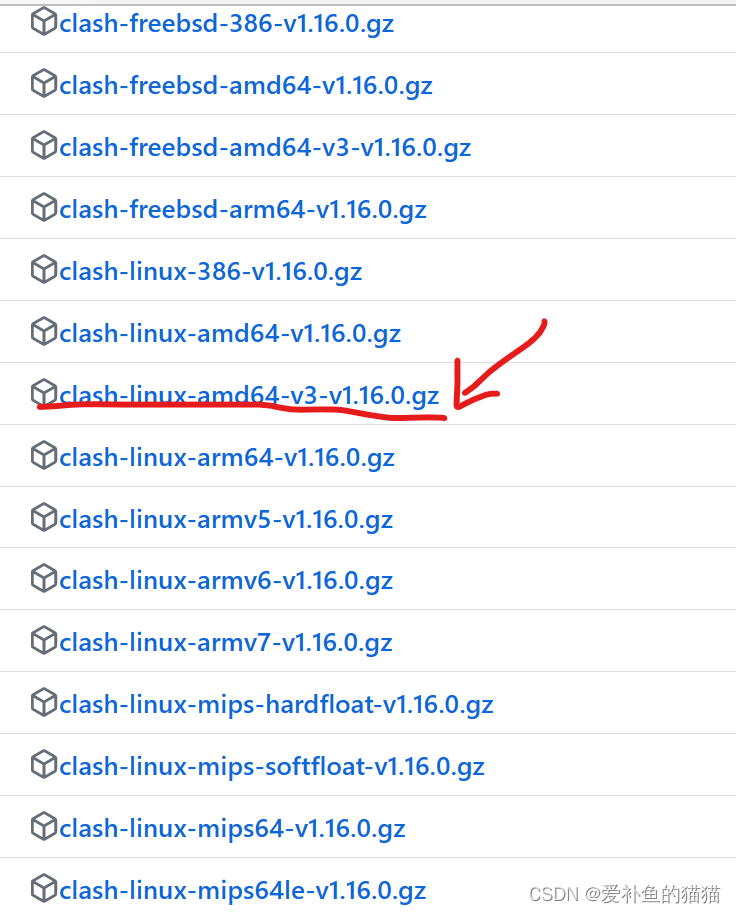
选择你的猫:https://github.com/Dreamacro/clash/releases/tag/v1.16.0
x86_64 GNU/Linux的猫选clash-linux-amd64-v3-v1.16.0.gz
配置参考链接:
https://www.hengy1.top/article/3dadfa74.html
https://opclash.com/fenxiang/302.html
https://dantefung.github.io/2021/08/05/ubuntu20-4%E4%B8%8B%E4%BD%BF%E7%94%A8clash/
.bashrc是home目录下的一个shell文件,用于储存用户的个性化设置。在bash每次启动时都会加载.bashrc文件中的内容,并根据内容定制当前bash的配置和环境。

注意代理错误:alias proxy_on=“export https_proxy=127.0.0.1:7890 && export http_proxy=127.0.0.1:7890”
纠正:export http_proxy=http://代理IP:端口号
export https_proxy=http://代理IP:端口号
# 创建环境
$ mkdir clash
$ cd clash
# 拉取下来
$ wget https://github.com/Dreamacro/clash/releases/download/v1.9.0/clash-linux-amd64-v1.9.0.gz
$ gzip -d clash-linux-amd64-v1.9.0.gz
$ mv clash-linux-amd64-v1.9.0.gz clash
# 这里clash为二进制可以运行文件了
$ chomd 755 clash
chmod +x clash# 生成默认配置
$ ./clash -d . # 默认配置
# 拉取机场配置
$ wget xxxx # 要么拉下来 要么自己拷贝上来
# 注意: 名称为:config.yaml
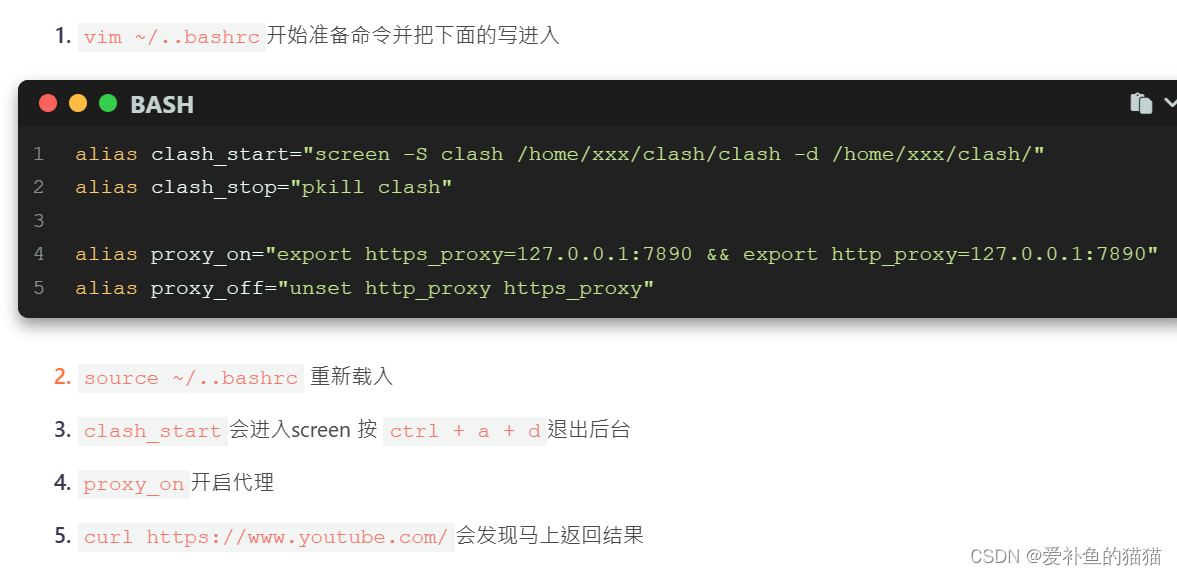
$ ./clash -d . # 就开始加载你的配置了vim ~/..bashrc开始准备命令并把下面的写进入
alias clash_start="screen -S clash /home/xxx/clash/clash -d /home/xxx/clash/" #-d /home/xxx/clash/配置文件位置confi.yaml
alias clash_stop="pkill clash"#alias proxy_on="export https_proxy=127.0.0.1:7890 && export http_proxy=127.0.0.1:7890"
alias proxy_on="export https_proxy=http://127.0.0.1:7890 && export http_proxy=http://127.0.0.1:7890"
alias proxy_off="unset http_proxy https_proxy"
Screen 多窗口操作:通过 Screen 命令,你可以在同一个终端窗口中创建多个窗口,并在这些窗口中同时运行不同的应用程序,而不需要打开多个终端窗口。查看状态:screen -ls
- 临时有效
1、添加代理
export http_proxy=http://proxyAddress:port
export https_proxy=http://proxyAddress:port
export https_proxy=http://127.0.0.1:7890 && export http_proxy=http://127.0.0.1:7890
2、查看代理
env |grep -i proxy
3、清除代理
unset http_proxy
unset https_proxy
unset http_proxy https_proxy
1、Windows
根据网上的文章,在Windows下使用全局代理方式也会对cmd生效(未经验证)。
cmd
set http_proxy=http://127.0.0.1:1080
set https_proxy=http://127.0.0.1:1080
还原命令:
set http_proxy=
set https_proxy=
2、Git Bash
设置方法同"macOS & Linux"
macOS & Linux
通过设置http_proxy、https_proxy,可以让终端走指定的代理。 配置脚本如下,在终端直接执行,只会临时生效:
export http_proxy=http://127.0.0.1:1080
export https_proxy=$http_proxy
参考:https://zhuanlan.zhihu.com/p/357875811
八、3090、cuda和tensorflow 1.x
因为3090只支持cuda11.0+的版本,而tensorflow1.×已经不再维护,没有出支持cuda11.0+的版本了。
nvidia提供了TF1.x对RTX 3090、cuda11等新硬件的支持。卸载已有的tensorflow-gpu包和conda安装的cuda包,安装nvidia版本tensorflow:
pip install nvidia-pyindex
pip install nvidia-tensorflow # 会自动安装相关cuda依赖pip install tensorboard
import tensorflow as tf 和 tf.test.is_gpu_available() 测试,如果出现以下内容WARNING:root:Limited tf.compat.v2.summary API due to missing TensorBoard installation.此时还需要再安装一个.重新安装tensorboard。pip install tensorboard即可解决pip install tensorboard
import tensorflow as tf 和 tf.test.is_gpu_available() 测试,如果出现以下内容WARNING:root:Limited tf.compat.v2.summary API due to missing TensorBoard installation.此时还需要再安装一个。重新安装tensorboard。pip uninstall tensorboard、pip install tensorboard即可解决
注:nvidia-tensorflow仓库提示需要使用Python3.8,但我使用Python3.6,可用。
参考:
https://blog.csdn.net/qq_39543404/article/details/112171851
https://www.cnblogs.com/xikeguanyu/p/16269066.html
https://zhuanlan.zhihu.com/p/521957441
https://blog.csdn.net/znevegiveup1/article/details/115053563
测试TF和cuda
1、
#(1)查看TF版本
import tensorflow as tf
tf.__version__ # 此命令为获取安装的tensorflow版本
print(tf.__version__) # 输出版本
tf.__path__ #查看tensorflow安装路径
print(tf.__path__)#(2)查看cuda是否可用
import tensorflow as tf
print(tf.test.is_gpu_available())#如果结果是True,表示GPU可用import tensorflow as tf
tf.test.is_gpu_available()#(3)查看cuda版本
nvidia-smi #系统中自带的cudaconda list | grep cuda #虚拟环境的cuda或者用pip看包信息2、
import tensorflow as tf
gpu_device_name = tf.test.gpu_device_name()
print(gpu_device_name)
tf.test.is_gpu_available()import tensorflow as tf
tf.test.is_built_with_cuda()
print(tf.test.is_built_with_cuda())#返回true表示可用3、
from tensorflow.python.client import device_lib# 列出所有的本地机器设备
local_device_protos = device_lib.list_local_devices()
# 打印
print(local_device_protos)
# 只打印GPU设备
[print(x) for x in local_device_protos if x.device_type == 'GPU']测试Pytorch和cuda
import torch
print(torch.__version__)
print(torch.cuda.is_available())
- CUDA版本
1.查看当前安装的版本(nvcc -V)
通过nvcc(NVIDIA Cuda compiler driver)命令可查看本机安装的CUDA版本:nvcc -V
nvcc -V查看的是系统自带的cuda的版本,要看虚拟环境中的版本,要导入pytorch和tensorflow库进行测试
pytorch中:print(torch.__version__)与
tensorflow中:conda list | grep cuda直接在终端里,打开相应环境,进行查看
2.查看能支持的最高CUDA版本(nvidia-smi)
通过nvidia-smi 命令可查看本机的Nvidia显卡驱动信息,以及该驱动支持的最高的CUDA版本。nvidia-smi,例如下面的CUDA Version就是我的电脑上面能够安装的最高版本的CUDA,并且该版本号是向下支持的,可以安装低于该版本号的所有CUDA套件
tenserflow卸载
检查:
sudo pip show tensorflow
卸载使用:
pip uninstall protobuf
pip uninstall tensorflow
pip uninstall tensorflow-gpu
pip uninstall tensorflow-cpu
pip wheel 安装 TensorRT:
安装 nvidia-pyindex 包用下面这条命令
pip install nvidia-pyindex
安装装好之后,就可以开始安装 TensorRT 了。使用下面的命令:
pip install --upgrade nvidia-tensorrt
pip install nvidia-pyindex
pip install nvidia-tensorrt==8.2.5.1import tensorrt
print(tensorrt.__version__)
assert tensorrt.Builder(tensorrt.Logger())参考:https://blog.csdn.net/qq_37541097/article/details/114847600
https://www.cnblogs.com/asnelin/p/15929442.html
同时安装tensorflow、pytorch
主要考虑cudnn、tensorflow、pytorch的版本问题,先选cuda的版本和显卡的匹配,再选tensorflow、pytorch的cuda对应版本。
cuda、cudnn、tensorflow(-gpu)、pytorch弄清版本。
参考:https://blog.csdn.net/LIWEI940638093/article/details/113811563
八、 Nvidia显卡驱动、CUDA、cuDNN、Anaconda及Tensorflow-GPU版本
https://blog.csdn.net/qq_28256407/article/details/115548675?ydreferer=aHR0cHM6Ly9jbi5iaW5nLmNvbS8%3D?ydreferer=aHR0cHM6Ly9jbi5iaW5nLmNvbS8%3D
https://blog.csdn.net/m0_45447650/article/details/132058561
2.查看cuda和torch的版本
python -c 'import torch;print(torch.__version__);print(torch.version.cuda)'
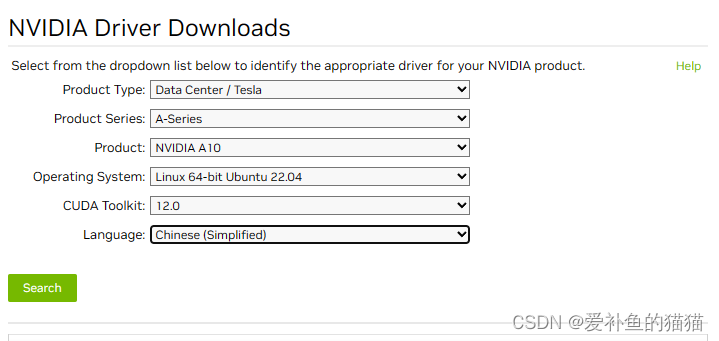
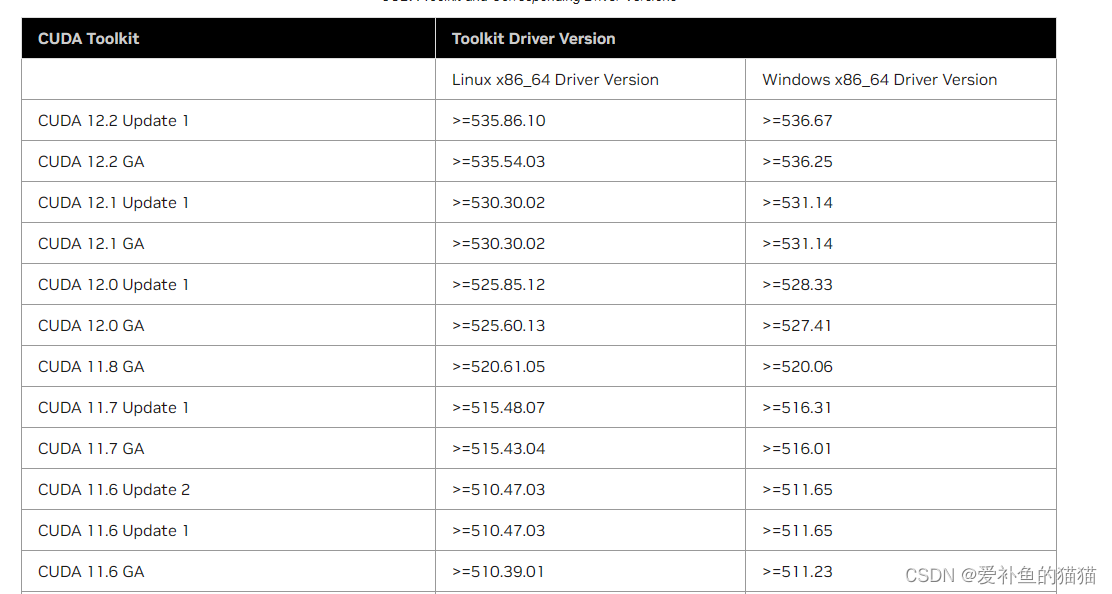
1、CUDA与显卡驱动
https://www.nvidia.com/Download/index.aspx
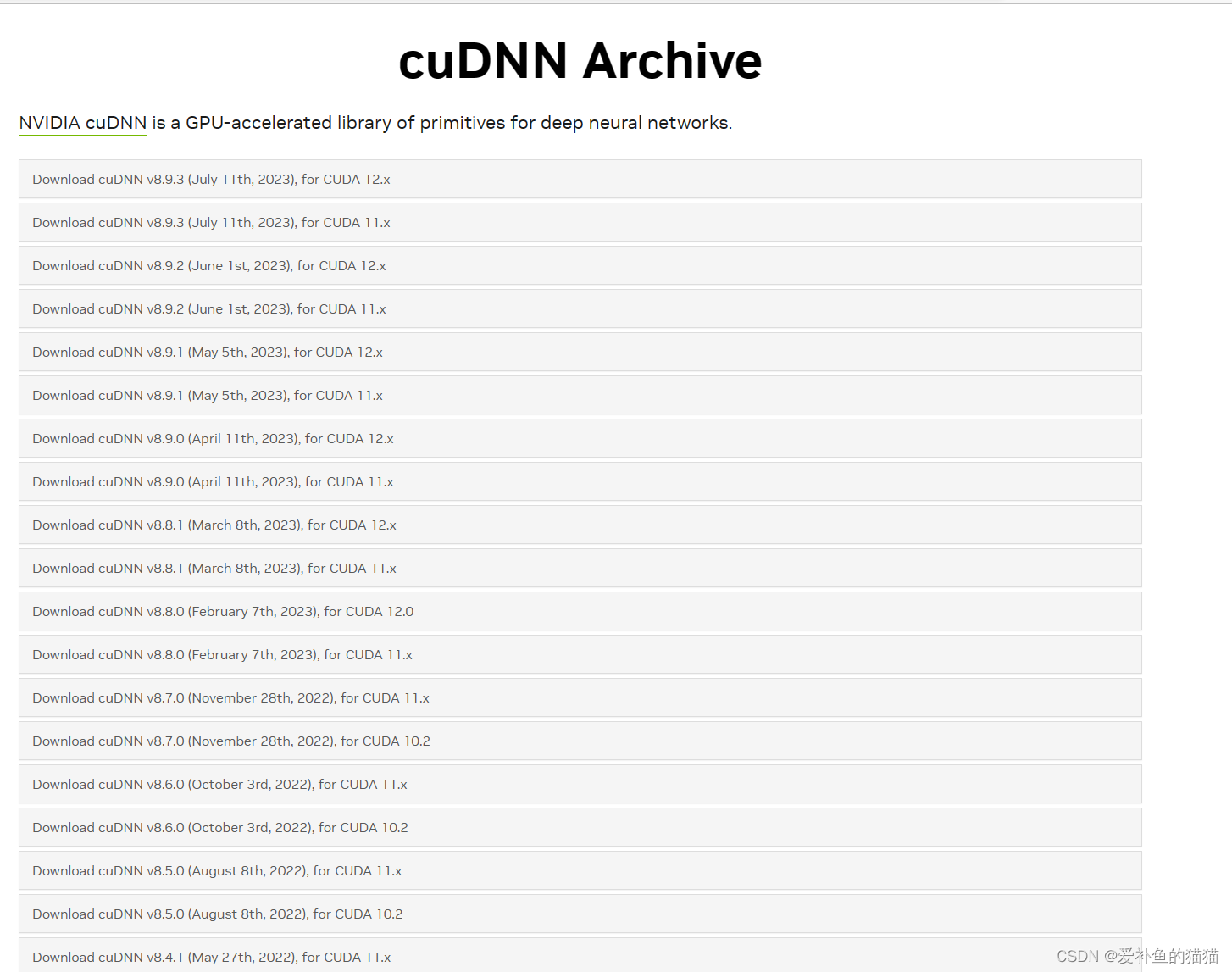
2、cuDNN Toolkit与CUDA版本
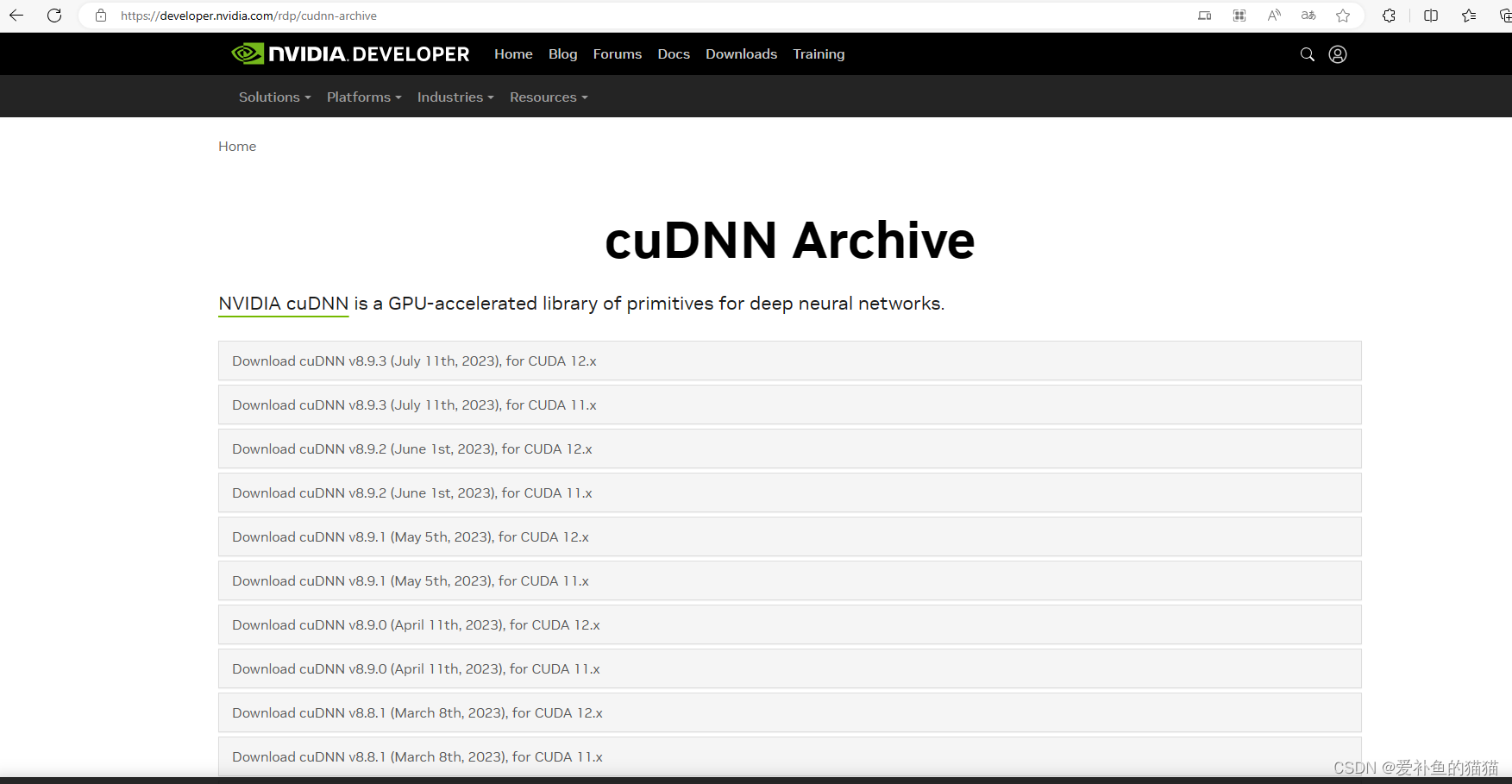
https://developer.nvidia.com/rdp/cudnn-archive
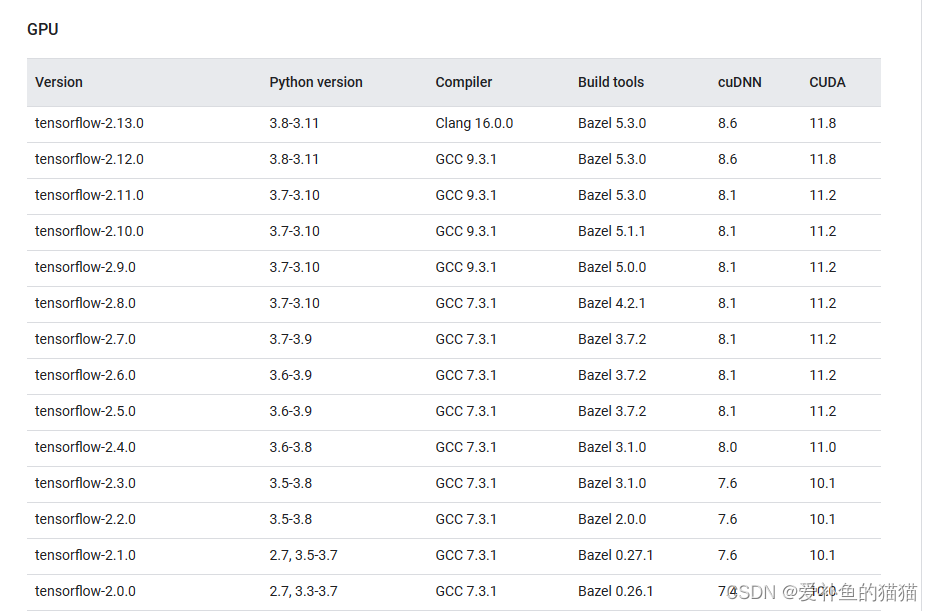
3、TensorFlow与CUDA cuDNN
https://tensorflow.google.cn/install/source?hl=en
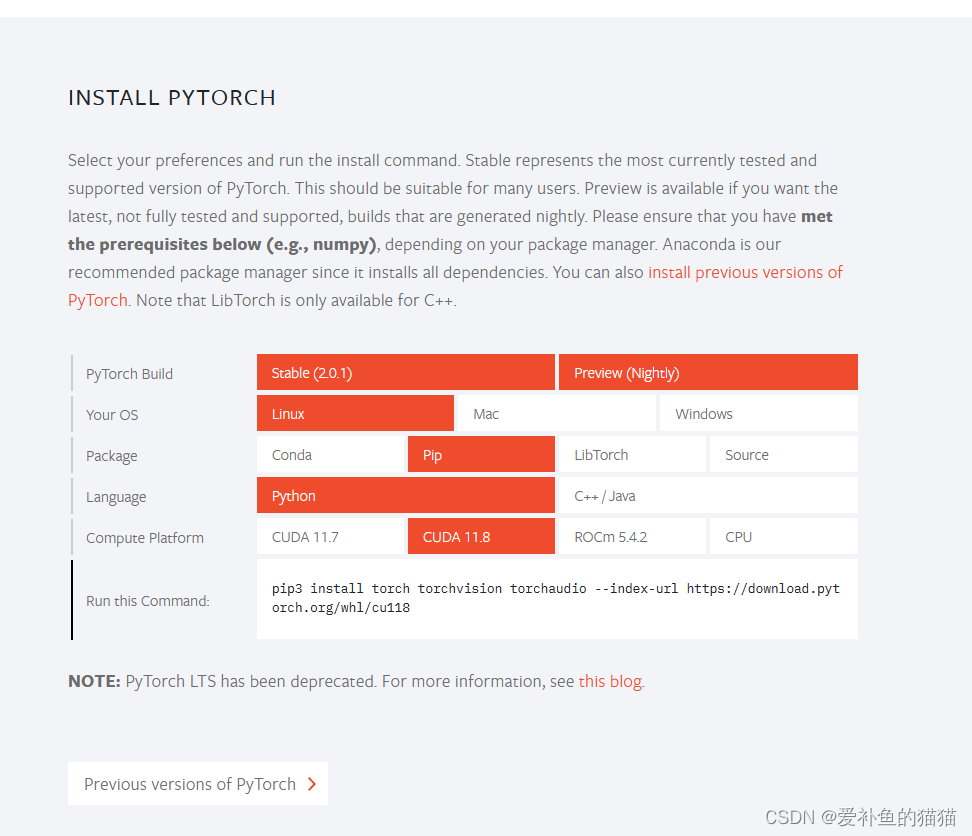
4、Pytorch与CUDA cuDNN
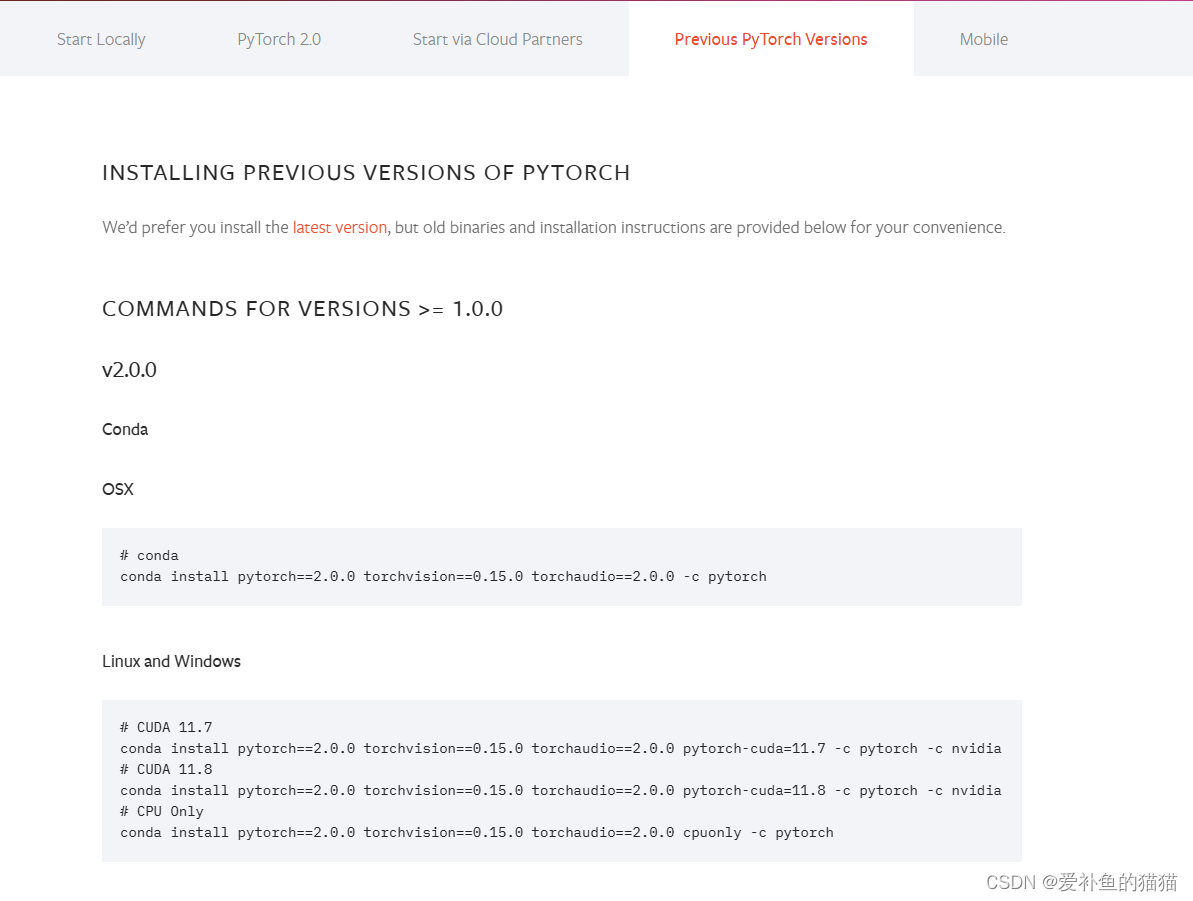
https://pytorch.org/
5、cudnn
https://zhuanlan.zhihu.com/p/639184948
https://blog.csdn.net/Williamcsj/article/details/123514435
官方下载地址:https://developer.nvidia.com/rdp/cudnn-archive
安装TensorFlow
- 安装依赖包
安装 TensorFlow 之前需要我们安装两个个依赖包,这里我的 cuda 版本为 11.1,cudnn 版本为 8.1.0,下载依赖包为
libcudnn8_8.1.0.77-1+cuda11.2_amd64.deb
libcudnn8-dev_8.1.0.77-1+cuda11.2_amd64.deb
官网链接如下:https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/
这里我使用 wget 下载:
参考链接:https://blog.csdn.net/weixin_46584887/article/details/122726278
官方教程:https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html
6、安装过程
参考:
https://blog.csdn.net/m0_45447650/article/details/132058561
https://blog.csdn.net/weixin_46584887/article/details/122726278
1.安装显卡驱动
方法(1)在线安装
1. 卸载旧版本nvidia驱动
如果没有安装nvidia驱动,可直接跳过。$ sudo apt purge nvidia*
1
2. 把显卡驱动加入PPA
$ sudo add-apt-repository ppa:graphics-drivers
$ sudo apt update
1
2
3. 查找版本库中显卡驱动
使用以下命令查看系统版本库中所有nvidia驱动的信息,根据需要选择合适的版本。$ sudo apt-cache search nvidia
1
推荐使用以下命令,查看Ubuntu推荐的驱动版本,从中选择合适的版本。$ ubuntu-drivers devices
参考链接:https://blog.csdn.net/qq_28256407/article/details/115548675
方法(2)下载安装
https://www.nvidia.com/Download/index.aspx
可以参考:https://blog.csdn.net/Perfect886/article/details/119109380,之前是run文件,现在是def文件,Debian安装命令一般sudo dpkg -i 命令。
例如:sudo dpkg -i cuda-repo--X-Y-local_*_x86_64.deb
2、安装CUDA
方法一:用run方式,可以选择是否安装驱动,一般不选
https://developer.nvidia.com/cuda-downloads?
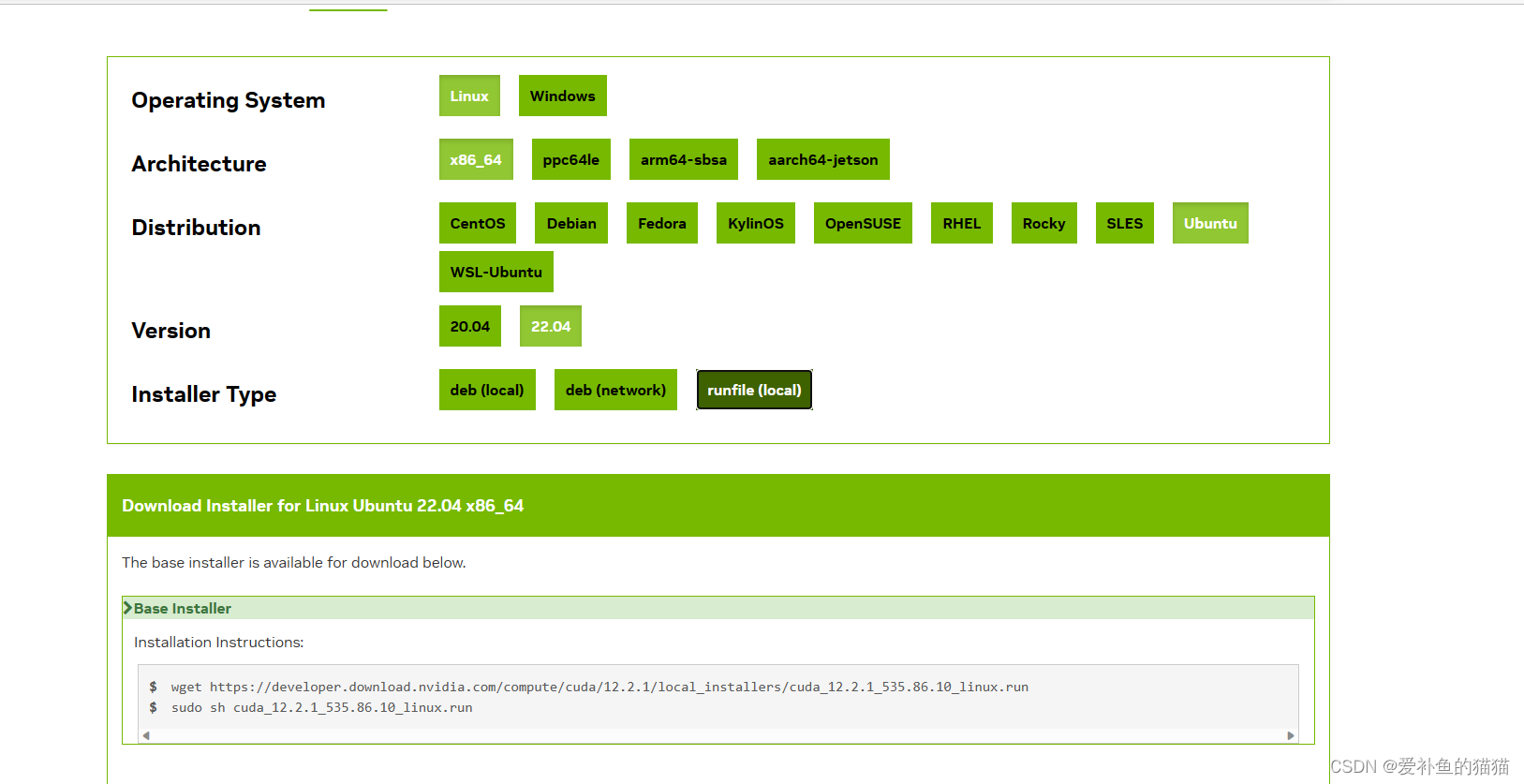
选择是否安装:https://zhuanlan.zhihu.com/p/501473091
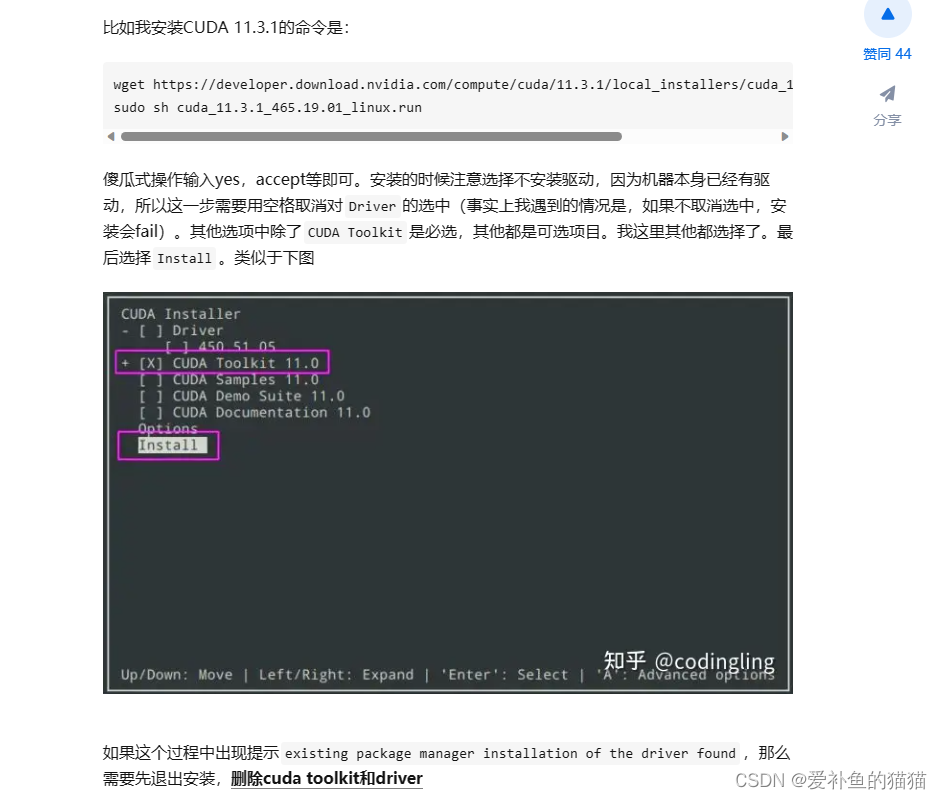
配置环境
配置环境
gedit ~/.bashrc
在打开的文件中添加
export CUDA_HOME=/usr/local/cuda-11.1
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64
export PATH=${CUDA_HOME}/bin:${PATH}
链接:https://blog.csdn.net/qq_39821101/article/details/116092190
方法二:官方教程:https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#
参考:https://blog.csdn.net/qq_39821101/article/details/116092190
https://blog.csdn.net/m0_45447650/article/details/132058561
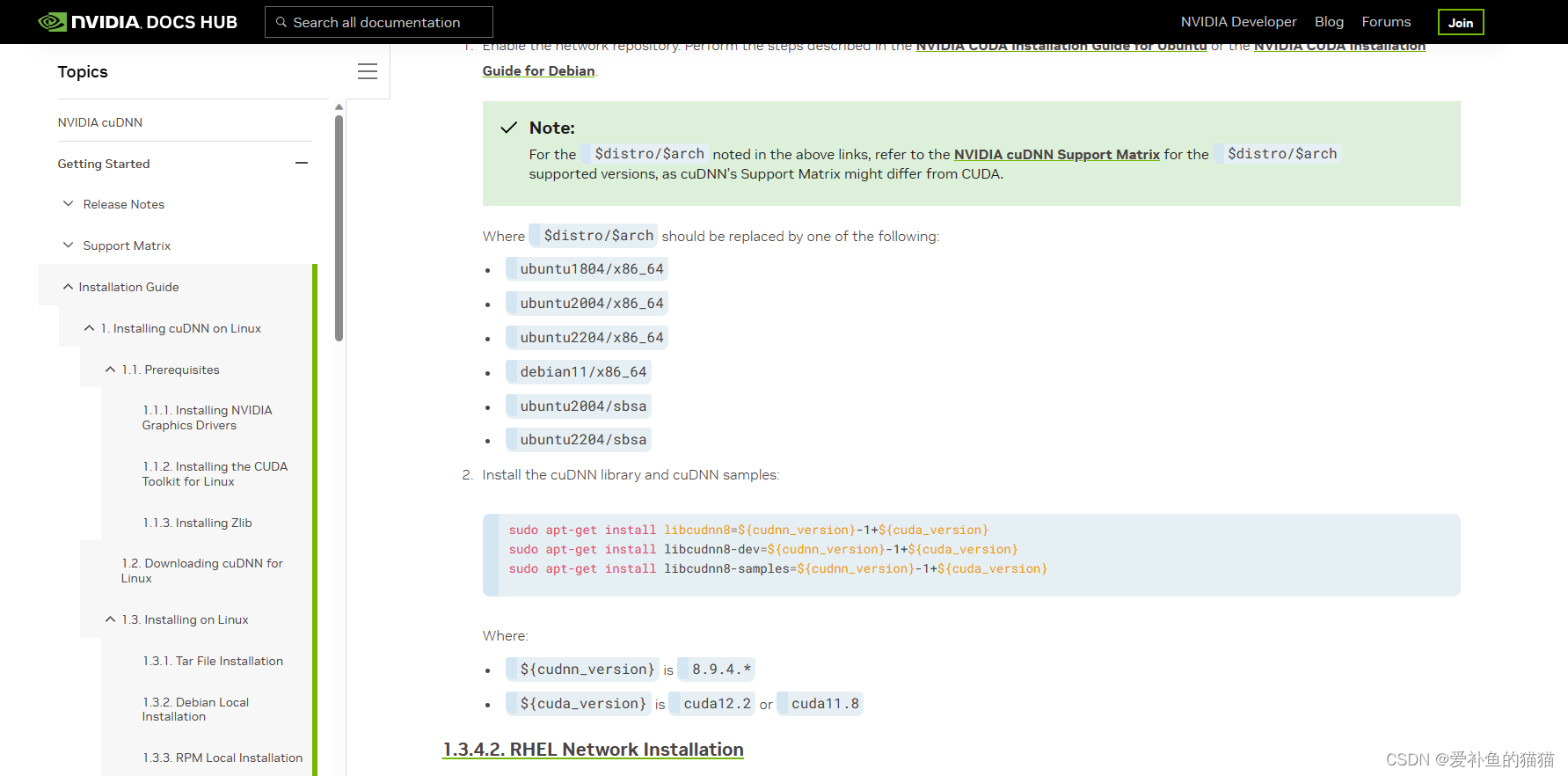
3、安装cudnn
(1)下载安装:cudann
https://developer.nvidia.com/rdp/cudnn-archive
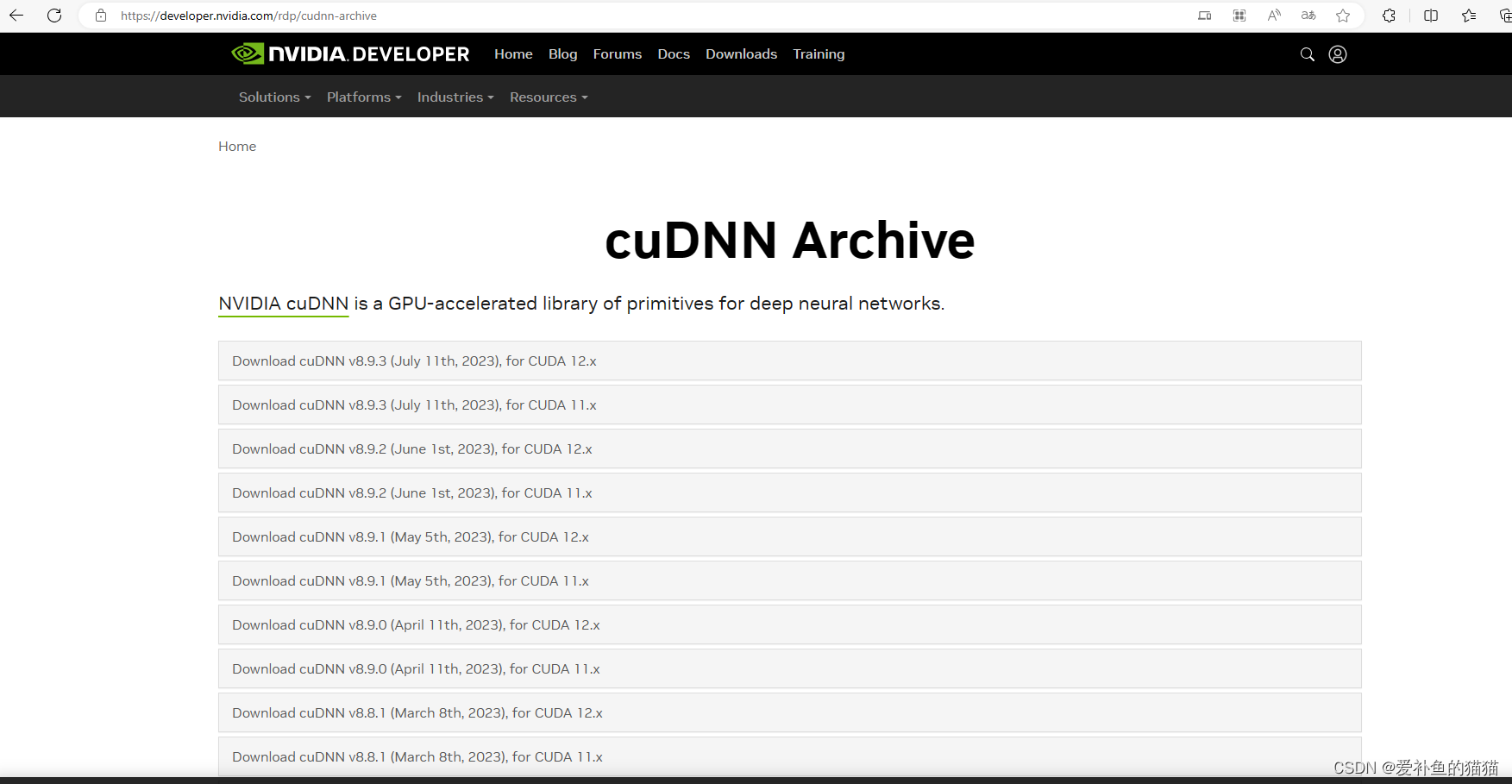
2 安装deb文件(安装 TensorFlow 之前需要我们安装两个个依赖包)
官方下载地址:https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/
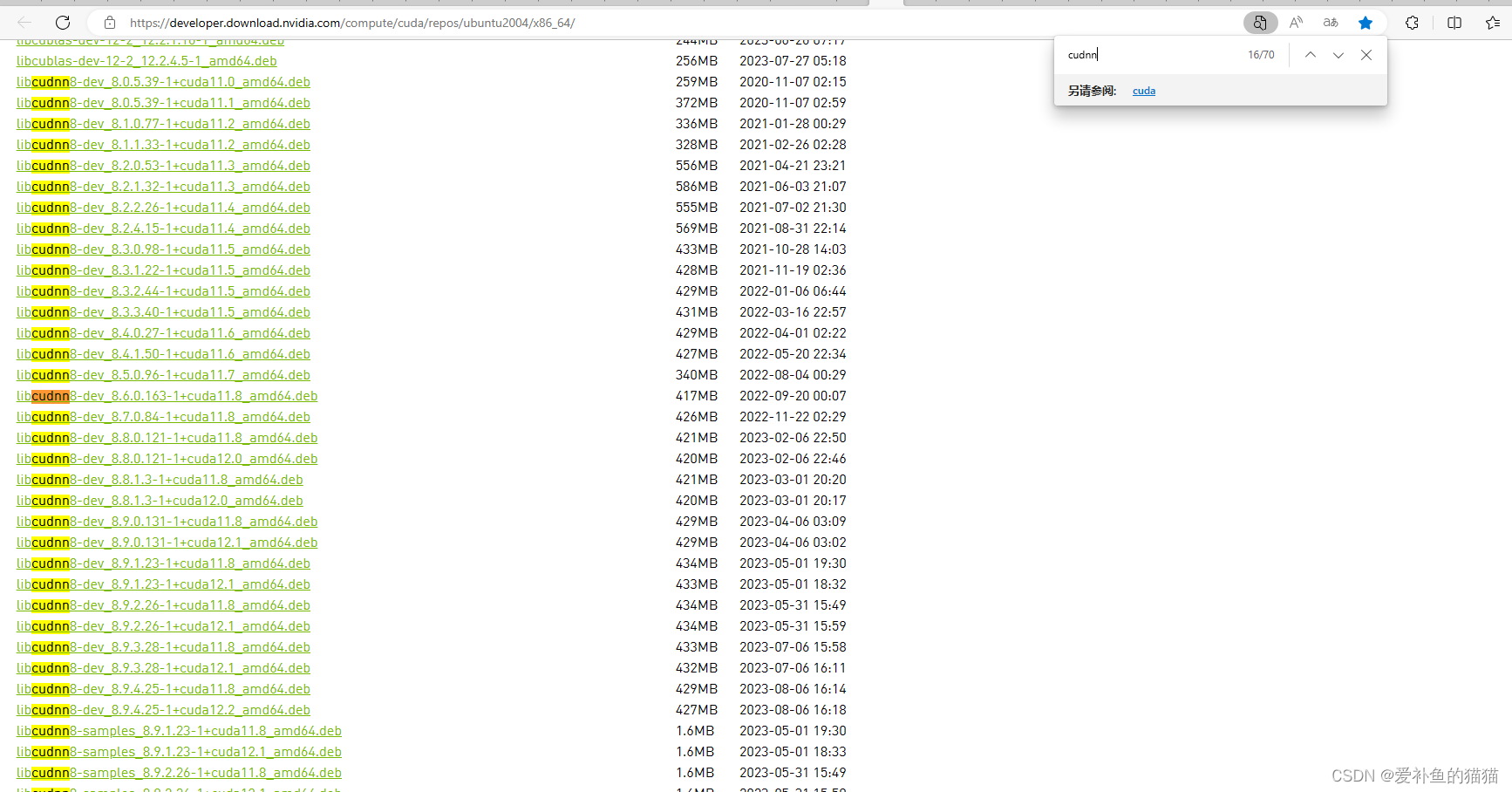
使用如下语句依次安装:(debain命令,Ubuntu也可以)
sudo dpkg -i libcudnn8_8.0.3.33-1+cuda11.0_amd64.deb
sudo dpkg -i libcudnn8-dev_8.0.3.33-1+cuda11.0_amd64.deb
sudo dpkg -i libcudnn8-samples_8.0.3.33-1+cuda11.0_amd64.deb
Ubuntu命令,作为参考
执行以下命令:
sudo apt install ./cudnn-local-repo-ubuntu2004-*amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2004-8.4.1.88/cudnn-local-4B348671-keyring.gpg /usr/share/keyrings/
sudo apt update
#下面自动匹配版本,注意版本不对会出错
sudo apt install libcudnn8
sudo apt install libcudnn8-dev
sudo apt install libcudnn8-samples
参考:https://zhuanlan.zhihu.com/p/126997172
https://zhuanlan.zhihu.com/p/639184948
4、安装TensorFlow
pip install -i https://mirrors.aliyun.com/pypi/simple tensorflow
#(2)查看cuda是否可用
import tensorflow as tf
print(tf.test.is_gpu_available())#如果结果是True,表示GPU可用
6、其他相关操作
卸载
1. 卸载旧版本nvidia驱动
如果没有安装nvidia驱动,可直接跳过。
$ sudo apt purge nvidia*2、卸载cuda
#只执行这条可以
sudo apt-get autoremove nvidia-cuda-toolkitcd /usr/local/cuda-11.1/bin
sudo ./cuda-uninstaller
sudo rm -rf /usr/local/cuda-11.1
从https://developer.nvidia.com/cuda-toolkit-archive下载对应版本的cuda
如果你之前执行过sudo apt-get install nvidia-cuda-toolkit,需要卸载:sudo apt-get autoremove nvidia-cuda-toolkitsudo apt-get install nvidia-cuda-toolkit
# 卸载
sudo apt-get autoremove nvidia-cuda-toolkit
在终端输入
nvcc -V
没有cuda版本信息,则卸载成功
链接:https://blog.csdn.net/qq_39821101/article/details/1160921903、卸载cudnn
查询:
sudo dpkg -l | grep cudnn
将其全部卸载:
sudo dpkg -r libcudnn8-samples
sudo dpkg -r libcudnn8-dev
sudo dpkg -r libcudnn8检查:
输入下面指令后,没有任何输出即卸载成功。
sudo dpkg -l | grep cudnn
接:https://blog.csdn.net/Williamcsj/article/details/123514435九、显卡信息命令/CPU内存/硬盘
1.显卡
nvidia-smi
nvidia-smi(显示一次当前GPU占用情况)
nvidia-smi -l(每秒刷新一次并显示)
watch -n 5 nvidia-smi (其中,5表示每隔6秒刷新一次终端的显示结果)
表头释义:
Fan:显示风扇转速,数值在0到100%之间,是计算机的期望转速,如果计算机不是通过风扇冷却或者风扇坏了,显示出来就是N/A;
Temp:显卡内部的温度,单位是摄氏度;
Perf:表征性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能;
Pwr:能耗表示;
Bus-Id:涉及GPU总线的相关信息;
Disp.A:是Display Active的意思,表示GPU的显示是否初始化;
Memory Usage:显存的使用率;
Volatile GPU-Util:浮动的GPU利用率;
Compute M:计算模式;
下边的Processes显示每块GPU上每个进程所使用的显存情况。
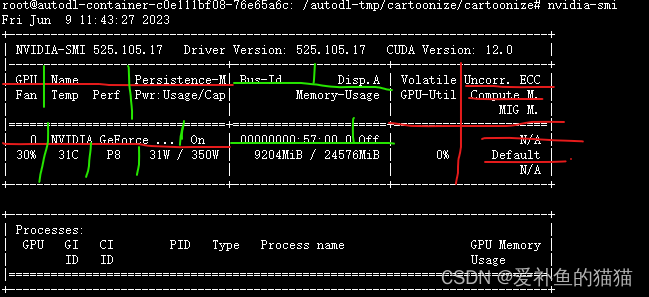

GPU:编号
Fan:风扇转速,在0到100%之间变动,这里是42%
Name:显卡名,这里是TITAN X
Temp:显卡温度,这里是69摄氏度
Perf:性能状态,从P0到P12,P0性能最大,P12最小
Persistence-M:持续模式的状态开关,该模式耗能大,但是启动新GPU应用时比较快,这里是off
Pwr:能耗
Bus-Id:涉及GPU总线的东西
Disp.A:表示GPU的显示是否初始化
Memory-Usage:现存使用率,这里已经快满了
GPU-Util:GPU利用率
Compute M.:计算模式
参考查看Linux服务器内存、CPU、显卡、硬盘使用情况,链接:https://www.jianshu.com/p/0aed4feba213
https://www.cnblogs.com/wsnan/p/11769838.html
- CUDA版本
1.查看当前安装的版本(nvcc -V)
系统自带:通过nvcc(NVIDIA Cuda compiler driver)命令可查看本机安装的CUDA版本:nvcc -V
nvcc -V查看的是系统自带的cuda的版本。
虚拟环境中:要看虚拟环境中的版本,查看pip包或者要导入pytorch和tensorflow库进行测试pytorch中:print(torch.__version__)和tensorflow中:conda list | grep cuda直接在终端里,打开相应环境,进行查看
2.查看能支持的最高CUDA版本(nvidia-smi)
通过nvidia-smi 命令可查看本机的Nvidia显卡驱动信息,以及该驱动支持的最高的CUDA版本。nvidia-smi,例如下面的CUDA Version就是我的电脑上面能够安装的最高版本的CUDA,并且该版本号是向下支持的,可以安装低于该版本号的所有CUDA套件
释放显卡内存
在Ubuntu运行代码的时候,有时会出现代码退出了,显存依然在占用的情况。
1、#批量清理显卡中残留进程:(批量包含其他信息时不行,要用/dev/nvidia*设置成指定哪个进行批量kill如:/dev/nvidia0)
sudo fuser -v /dev/nvidia* |awk '{for(i=1;i<=NF;i++)print "kill -9 " $i;}' | sudo sh#或
lsof /dev/nvidia* | awk '{print $2}' | xargs -I {} kill {}#或
fuser -v /dev/nvidia* | awk '{print $0}' | xargs kill -92、手动
apt-get install psmisc
#查找占用GPU资源的PID
fuser -v /dev/nvidia*
# 解除显存占用
kill -9 ***(PID)
2、CPU内存
- 查看cup使用率、内存
(1)top
(2)htop
$ sudo apt-get install htop
$ htop
(3)free命令
free命令可以显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。在Linux系统监控的工具中,free命令是最经常使用的命令之一。
3、硬盘
(1)df命令
(2)df -h命令,df命令直接执行的效果不好,不能以mb或者gb的形式显示磁盘容量。为了以人性化显示,可以在后面加-h参数,h是human-reading的第一个字母,可以理解为人类能读的格式。
(3)查看分区:sudo fdisk -l
(4)查看目录:du -h --max-depth=1
du -h -d 1: 显示当前目录下所有一级子目录的大小
du -sh: 显示当前目录的总大小
du -h: 显示当前目录下所有子目录的大小,递进到最大深度
4、查看进程
ps命令:可以列出正在运行的进程。
ps -aux 查看所有进程,每行一个程序(常用)ps -A 查看当前系统所有的进程。(常用)ps -A | grep chrome 命令去搜索某个指定进程。(常用)ps -A | less 使用less命令对输出进行管道,可以按 q 退出。执行ps的帮助命令“ps --help a”查看ps命令支持的参数列表
使用ps命令“ps -aux | less”,查看当前系统正在运行的所有进程
使用ps命令“ps -U root -u root -N”,查看当前系统中非root运行的所有进程
使用ps命令“ps -u test”,查看当前系统中test用户运行的所有进程
链接:https://blog.csdn.net/ITBigGod/article/details/85676559
5、释放显存
1、程序中释放
#1、tensorflow、pytorch强制关闭GPU释放显存
from numba import cuda
device = cuda.get_current_device()
device.reset()
cuda.close()#2、开启进程执行
from multiprocessing import Processdef train():...if __name__'__main__': # 在windows必须在这句话下面开启多进程p = Process(target=train)p.start()p.join() # 进程结束后,GPU显存会自动释放p = Process(target=train) # 重新训练p.start()p.join()#3、杀死进程
import os
pid = list(set(os.popen('fuser -v /dev/nvidia*').read().split()))
kill_cmd = 'kill -9 ' + ' '.join(pid)
print(kill_cmd)
os.popen(kill_cmd)#4、Pytorch释放
torch.cuda.empty_cache()
del(model)2、显存信息
import pynvmlpynvml.nvmlInit()handle = pynvml.nvmlDeviceGetHandleByIndex(0)# 这里的0是GPU idmeminfo = pynvml.nvmlDeviceGetMemoryInfo(handle)print('显卡信息:')print(meminfo.total / 1024 /1024) #第二块显卡总的显存大小print(meminfo.used / 1024 /1024)#这里是字节bytes,所以要想得到以兆M为单位就需要除以1024**2print(meminfo.free / 1024 /1024) #第二块显卡剩余显存大小print(pynvml.nvmlDeviceGetCount())#显示有几块GPUprint('显卡信息end')os.system("nvidia-smi")
十、文生视频
早期研究主要使用基于 GAN 和 VAE 的方法在给定文本描述的情况下自回归地生成视频帧 (参见 Text2Filter 及 TGANs-C)。虽然这些工作为文生视频这一新计算机视觉任务奠定了基础,但它们的应用范围有限,仅限于低分辨率、短距以及视频中目标的运动比较单一、孤立的情况。
受文本 (GPT-3) 和图像 (DALL-E) 中大规模预训练 Transformer 模型的成功启发,文生视频研究的第二波浪潮采用transformer 架构。Phenaki、Make-A-Vide、NUWA、VideoGPT 和 CogVideo 都提出了基于 transformer 的框架,而 TATS 提出了一种混合方法,从而将用于生成图像的 VQGAN 和用于顺序地生成帧的时间敏感 transformer 模块结合起来。
第三波也就是当前这一波文生视频模型浪潮主要以基于扩散的架构为特征。扩散模型在生成多样化、超现实和上下文丰富的图像方面取得了显著成功,这引起了人们对将扩散模型推广到其他领域 (如音频、3D ,最近又拓展到了视频) 的兴趣。这一波模型是由 Video Diffusion Models (VDM) 开创的,它首次将扩散模型推广至视频领域。然后是 MagicVideo 提出了一个在低维隐空间中生成视频剪辑的框架,据其报告,新框架与 VDM 相比在效率上有巨大的提升。另一个值得一提的是 Tune-a-Video,它使用 单文本 - 视频对微调预训练的文生图模型,并允许在保留运动的同时改变视频内容。随后涌现出了越来越多的文生视频扩散模型,包括 Video LDM、Text2Video-Zero、Runway Gen1、Runway Gen2 以及 NUWA-XL。阿里达摩院:Text-to-video-synthesis
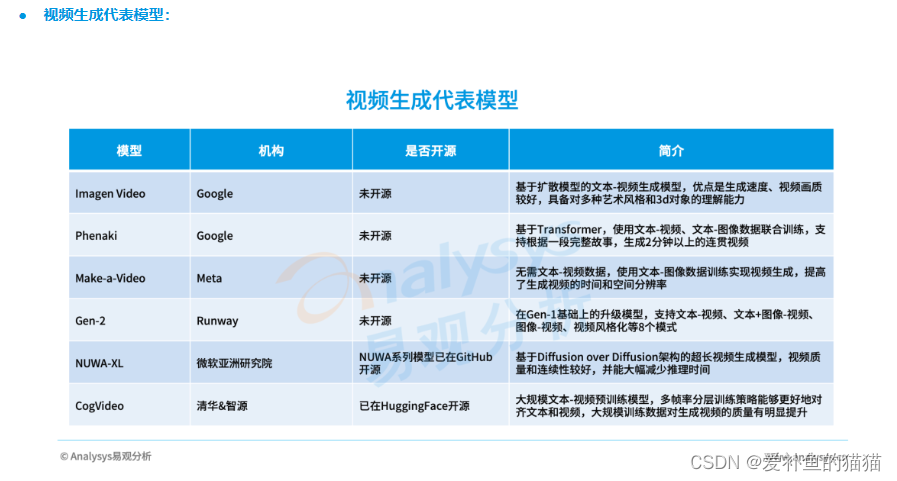

Imagen-Video
1、实现原理:Imagen-Video是在Imagen模型基础上开发的基于文本条件生成视频模型,模型通过多个扩散模型的组合,先根据文本prompt生成初始视频,再逐步提高视频的分辨率和帧数来生成视频。
2、模型优缺点:所生成的视频具有高保真度、可控性和世界知识,支持生成各种艺术风格的各种视频和文本动画,并具有对3D对象理解能力,但级联模型采用的并行训练方式所需要计算资源较高。
Gen
1、实现原理:Gen模型通过潜在扩散模型学习文本-图像特征,可以根据给定的文本提示或参考图像生成新的视频,或根据原始视频+驱动图像进行视频风格转换等多种任务。
2、模型优缺点:模型在视频渲染和风格转换方面具有较好的表现,生成的视频艺术性和图像结构保持能力较强,因此可以更好地适应模型定制要求,但Gen模型在生成结果的稳定性方面仍然存在局限。
CogVideo
1、实现原理:CogVideo是基于自回归方法的大规模文本-视频生成模型,将图像生成模型CogView2应用于文本-视频生成实现高效学习,通过预测并不断拼接前一帧的递归方式来生成视频。
2、模型优缺点:模型支持中文prompt,多帧率分层训练的方法能够更好地理解文本-视频的关系,生成的视频看起来更加自然,但由于模型对输入序列长度存在限制。
参考:
https://my.oschina.net/HuggingFace/blog/8796358
https://www.analysys.cn/article/detail/20021023
十一、数字人
matehuman和ue5数字人效果比较好
2D数字人和3D数字人
方案一:
原文:AI 数字人制作(方案一)_哔哩哔哩_bilibili
AI 文字和图片生成数字人(输入一张图片和一段文字即可生成数字人)
《用三个开源项目整合成可以商用的数字人项目》
文本生成语音开源地址:https://github.com/weineng-zhou/text2voice
语音驱动表情和嘴型开源地址:https://github.com/YuanxunLu/LiveSpeechPortraits
动作迁移开源地址:https://github.com/yoyo-nb/Thin-Plate-Spline-Motion-Model
Text+Image2DigitalPerson (浪子之心科技 卢瑞 )
1、输入文字 ------ 输入" text-input"
2、将文字转化成语音 ------ 输出 “voice-output”
3、输入------"voice-output"到语音驱动嘴唇及表情
4、用语音驱动嘴唇及表情( LiveSpeechPortraits) ------ 输出“LiveSpeech-output”
5、输入图片 ------ 输入“image-input”到Thin-Plate-Spline-Motion-Model 进行动作迁移
6、动作迁移后 ------ 输出 “Moton-output”
7、最后将声音和视频合成 ------ 输出 “result”
备注: 如果要商业,还需要视频融合,超分辨率,界面设计,打包部署等。
方案二:AI 数字人制作
原文:AI 数字人制作(方案二)_哔哩哔哩_bilibili
AI 自制数字人(Wav2Lip-GFPGAN)
Wav2Lip代码地址:https://github.com/Rudrabha/Wav2Lip
GFPGAN代码地址:https://github.com/TencentARC/GFPGAN
Wav2Lip-GFPGAN代码地址:https://github.com/ajay-sainy/Wav2Lip-GFPGAN
2D,2.5D数字人制作我已经出了好几个视频,制作方法也介绍了3个以上,后期将出3D数字人的制作方法视频。
方案三:AI 数字人制作
原文:AI 数字人制作(方案三)_哔哩哔哩_bilibili
AI 图片和语音生成数字人(国产版D_ID)
只需要进行调参就可以平替换DID,效果很好。
来自西安交大和腾讯的SadTalker,CVPR 2023年顶会论文。
开源代码地址:https://github.com/Winfredy/SadTalker
该论文是针对单张图片进行驱动的,涉及到3D人脸重建、wav2lip、face-vid2vid、GFPGAN超分等模块。
连接:https://blog.csdn.net/javastart/article/details/130651625
2023的talk系列:
StyleTalk清华(说话风格)
codetalker(3d)、sadtalker、retalking、wav2lip(基础)
了解:Talking-Face-Generation系列
https://www.zhihu.com/column/c_1626536469543194624
十二、 flask socket
1、版本问题
问题解决
根据官方给定的兼容版本,从socket.io官网CDN下载最新的4.4.1版本js文件,https://cdn.socket.io/。
python-engineio使用版本。需要更新的javascript.socketio包,具体可对照官方文档Requirements部分末尾
https://flask-socketio.readthedocs.io/en/latest/intro.html#requirements
前端加入
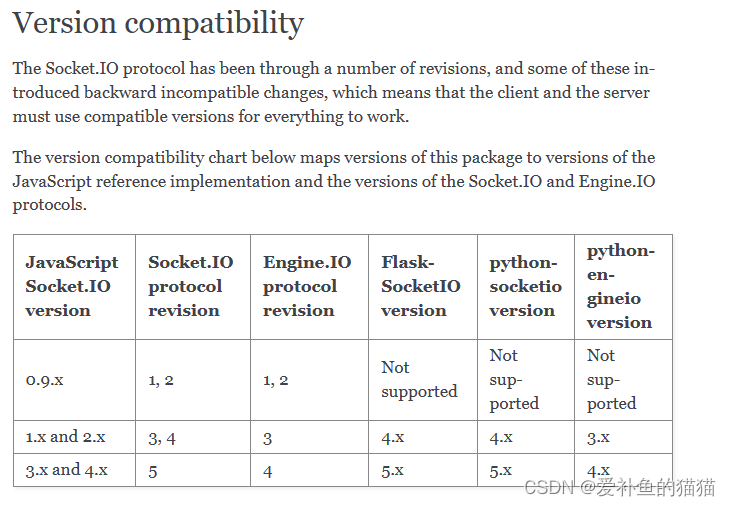
1、版本1(低版本推荐)
解决
以我本机为例,运行下列命令pip3 install --upgrade Flask-SocketIO==4.3.1
pip3 install --upgrade python-engineio==3.13.2
pip3 install --upgrade python-socketio==4.6.0
如果出现
ImportError: cannot import name ‘run_with_reloader’ from ‘werkzeug.serving’
或
ImportError: cannot import name ‘soft_unicode’ from ‘markupsafe’
则运行下面命令
pip3 install --upgrade flask==1.1.4
pip3 install --upgrade Werkzeug==1.0.1
pip3 install --upgrade itsdangerous==1.1.0
pip3 install --upgrade Jinja2==2.11.2
pip3 install --upgrade MarkupSafe==2.0.1
参考链接:https://blog.csdn.net/xiru9972/article/details/125127955bidict==0.22.1
blinker==1.6.2
cachelib==0.10.2
cffi==1.15.1
click==7.1.2
colorama==0.4.6
coverage==7.2.7
dnspython==2.3.0
eventlet==0.33.3
Flask==1.1.4
Flask-Cors==3.0.10
Flask-SocketIO==5.2.0
gevent==22.10.2
gevent-websocket==0.10.1
greenlet==2.0.2
h11==0.14.0
itsdangerous==1.1.0
Jinja2==2.11.2
MarkupSafe==2.0.1
pycparser==2.21
python-engineio==4.4.1
python-socketio==5.8.0
simple-websocket==0.10.1
six==1.16.0
websocket==0.2.1
Werkzeug==1.0.1
wsproto==1.2.0
zope.event==4.6
zope.interface==6.0前端:<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.5.1/jquery.min.js" integrity="sha512-bLT0Qm9VnAYZDflyKcBaQ2gg0hSYNQrJ8RilYldYQ1FxQYoCLtUjuuRuZo+fjqhx/qtq/1itJ0C2ejDxltZVFg==" crossorigin="anonymous"></script><script src="https://cdnjs.cloudflare.com/ajax/libs/socket.io/3.0.4/socket.io.js" integrity="sha512-aMGMvNYu8Ue4G+fHa359jcPb1u+ytAF+P2SCb+PxrjCdO3n3ZTxJ30zuH39rimUggmTwmh2u7wvQsDTHESnmfQ==" crossorigin="anonymous"></script>2、版本2
Flask==2.2.2
Flask-SocketIO==5.2.0
MarkupSafe==2.1.1
Werkzeug==2.2.2pip install simple-websocket
前端:<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.5.1/jquery.min.js" integrity="sha512-bLT0Qm9VnAYZDflyKcBaQ2gg0hSYNQrJ8RilYldYQ1FxQYoCLtUjuuRuZo+fjqhx/qtq/1itJ0C2ejDxltZVFg==" crossorigin="anonymous"></script><script src="https://cdnjs.cloudflare.com/ajax/libs/socket.io/3.0.4/socket.io.js" integrity="sha512-aMGMvNYu8Ue4G+fHa359jcPb1u+ytAF+P2SCb+PxrjCdO3n3ZTxJ30zuH39rimUggmTwmh2u7wvQsDTHESnmfQ==" crossorigin="anonymous"></script>3、版本3
Flask-SocketIO==4.3.1
python-engineio==3.13.2
python-socketio==4.6.0
Flask==2.0.3
Werkzeug==2.0.3pip install gevent-websocket gevent eventlet
前端
<script type="text/javascript" src="//code.jquery.com/jquery-1.4.2.min.js"></script><script type="text/javascript" src="//cdnjs.cloudflare.com/ajax/libs/socket.io/1.3.5/socket.io.min.js"></script>bidict==0.22.1
blinker==1.6.2
cffi==1.15.1
click==8.1.3
colorama @ file:///C:/b/abs_a9ozq0l032/croot/colorama_1672387194846/work
coverage==7.2.7
dnspython==2.3.0
eventlet==0.33.3
Flask==2.0.3
Flask-Cors==3.0.10
Flask-SocketIO==4.3.1
gevent==22.10.2
gevent-websocket==0.10.1
greenlet==2.0.2
h==0.99
h11==0.14.0
itsdangerous==2.1.2
Jinja2 @ file:///C:/b/abs_7cdis66kl9/croot/jinja2_1666908141852/work
MarkupSafe @ file:///C:/ci/markupsafe_1654508036328/work
pycparser==2.21
python-engineio==3.13.2
python-socketio==4.6.0
simple-websocket==0.10.1
six==1.16.0
Werkzeug==2.0.3
wsproto==1.2.0
zope.event==4.6
zope.interface==6.02、跨域问题
在实例化SocketIO时,加上 cors_allowed_origins=""
#解决跨域问题
socketio.init_app(app, cors_allowed_origins='')
十三、图像超分辨率模型( video Super Resolution)
传统CNN
从SRCNN到EDSR
现在gan
SRGAN
ESRGAN
Real ESRGAN
EGVSR
Real-ESRGAN:一种用于一般图像恢复的实用算法
GFPGAN:一种用于真实人脸修复的实用算法
Real-ESRGAN是腾讯ARC实验室发表超分辨率算法
基于ESPCN提出了针对视频重建任务的网络结构VESPCN
Final2x:RealCUGAN, RealESRGAN, Waifu2x, and SRMD.
视频超分:对齐、融合、特征提取、重建,EDVR、BasicVSR、BasicVSR++、RealBasicVSR
视频修复:GFPGAN人脸、Real-ESRGAN图像/视频修复算法、人脸的清晰化算法:codeFormer,GPEN,GFPGAN
CVPR 2023 | 南洋理工、商汤提出E3DGE:2D图片秒出3D形象
https://blog.csdn.net/qq_28941587/article/details/128553869?ydreferer=aHR0cHM6Ly93d3cuYmluZy5jb20v
使用推荐:
codeFormer,GPEN,GFPGAN(对比,codeFormer和真实的比较像)
1、GFPGAN:能修复人脸,包含Real-ESRGAN算法可以设置超分
2、 Final2x:RealCUGAN, RealESRGAN, Waifu2x, and SRMD.这些超分效果都可以
3、BasicVSR:处理慢,会出现胡快,分辨大小不能设置,只能找对应模型,效果4k的感觉还可以。(不推荐)
十四、GUI
1、什么是CLI(命令行界面)、GUI(图形用户界面)、Terminal(终端)、Console(控制台)、Shell、TTY https://blog.csdn.net/csdn100861/article/details/116414786
2、Windows/Linux 通过 ssh 打开 远程服务器 GUI程序(ssh远程显示gui)
背景
在 Windows + ssh(Cygwin) + Linux(运行在虚拟机中的Ubuntu) 是一个很舒服的方案,但是偶尔需要用到 图形界面。
如果需要通过ssh打开远程服务器端的程序,需要X11 forwarding。否则,会显示:
经过搜索,我找到了有关的解决方案,这个方案适用于:
Cygwin
MobaXterm
Putty
从Linux连接到Linux
https://www.cnblogs.com/schips/p/12563373.html
3、Xserver
由于X server是监听在本地的,ssh服务端的远程client想连回本地必须使用remote tunnel,X11 forwarding则可以方便的将X11协议转发到远程主机。转发过程中会自动设置DISPLAY环境变量和Xauth授权信息。
https://www.jianshu.com/p/e6b45bb9c2e9
4、Window下,使用Putty+Xming的方式实现X界面的接收。
1.安装Putty和Xming
2.配置Xming
第一次运行Xming,使用开始菜单里面的XLaunch来启动,产生一个初始的配置文件。对于简单的使用来说,不需要任何特殊的配置,一切使用默认即可。Xming的具体配置和使用可以参考Xming的Manual。需要记住的是下图中标示出的“Display number”中的数字,此处使用默认的0。
https://www.jianshu.com/p/9279b2ed8821
https://blog.csdn.net/xxradon/article/details/86636340
十五、调试
参考:https://blog.csdn.net/jackailson/article/details/101129057
1、 .env文件环境变量文件
项目开发过程中,需要把 .env文件的内容导入到系统环境变量中,以方便程序调用。在 Python 中,可以使用 dotenv 库来读取 .env 文件中的环境变量。该库提供了两个主要的函数:load_dotenv() 和 dotenv_values()。
2、编辑launch.json:将预定义的配置替换为以下内容:
{// 使用 IntelliSense 了解相关属性。 // 悬停以查看现有属性的描述。// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387"version": "0.2.0","configurations": [{"name": "Python: 当前文件","type": "python","request": "launch","program": "${file}","console": "integratedTerminal","justMyCode": true,"python": "/root/autodl-tmp/conda/envs/webui/bin/python3","args": [// "--train_dir", "./input/train_data", // 命令行参数// "--dev_dir", "./input/valid_data","--share","--xformers","--port", "6006","--nowebui"],}]
}
{"version": "0.2.0","configurations": [{"name": "Python: Run My Module", // 配置名称,将在调试配置下拉列表中显示"type": "python", // 调试类型,这里是Python"request": "launch", // 请求类型,这里选择“launch”表示启动调试"module": "my_module", // 要执行的Python模块名称,请替换为实际的模块名称"cwd": "${workspaceFolder}", // 当前工作目录设置为项目文件夹"console": "integratedTerminal", // 使用VSCode的集成终端显示输出"args": [], // 如果需要传递命令行参数,可以在这个列表中添加"pythonPath": "${config:python.pythonPath}", // 指定Python解释器的路径"env": {}, // 环境变量字典,可以在这里添加自定义环境变量"envFile": "${workspaceFolder}/.env", // 如果需要从文件加载环境变量,可以指定.env文件的路径"stopOnEntry": false, // 是否在程序启动时立即暂停,以便在第一行代码之前设置断点"showReturnValue": true, // 是否在调试过程中显示函数的返回值"redirectOutput": true // 是否将程序输出重定向到调试控制台,而不是终端}]
}
链接:https://blog.csdn.net/qq_41236493/article/details/130430899
{// Use IntelliSense to learn about possible attributes.// Hover to view descriptions of existing attributes.// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387"version": "0.2.0","configurations": [{"name": "Python","type": "python","request": "launch","stopOnEntry": false,"pythonPath": "C:\\Users\\hetao\\anaconda3\\python.exe","program": "${file}","cwd": "${workspaceRoot}","env": {},"envFile": "${workspaceRoot}/.env","debugOptions": ["WaitOnAbnormalExit","WaitOnNormalExit","RedirectOutput"]}]
}
3、setting.json
,在setting.json里加上:“python.envFile”: “${workspaceFolder}/.vscode/.env”,如:
{
“python.pythonPath”: “/path/python.exe”,
“python.envFile”: “${workspaceFolder}/.vscode/.env”
}
“cwd”: "${fileDirname}"代码路径
4、setting.json和launch.json
感觉两者差补多,选择一个可以,launch.json一般配置调试,setting设置运行
在vscode中配置Setting.json添加Python路径
"python.pythonPath": "D:\\Anaconda3\\envs\\py37_32\\python.exe","python.autoComplete.addBrackets": true,//忽略pylint检查代码时,出现无谓的波浪线的问题"python.linting.pylintArgs": ["--disable=W,C"],
在vscode中配置launch.json添加Python路径
{// 使用 IntelliSense 了解相关属性。 // 悬停以查看现有属性的描述。// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387"version": "0.2.0","configurations": [{"name": "Python: 当前文件","type": "python","request": "launch","program": "${file}","console": "integratedTerminal","justMyCode": true,"stopOnEntry": false,"python": "D:/Program Files (x86)/Anoconda/envs/demo2/python.exe",//不生效,是在setting.json中设置的// "python.pythonPath": "D:/Program Files (x86)/Anoconda/envs/demo2/python.exe",// "python.autoComplete.addBrackets": true,// //忽略pylint检查代码时,出现无谓的波浪线的问题// "python.linting.pylintArgs": [// "--disable=W,C"// ],}]
}
5、
十六、ftp
参考链接:https://blog.csdn.net/qq_42992084/article/details/127717675
1、安装启动状态
安装
安装 FTP服务,命令行输入:
sudo apt-get install vsftpd
重新加载配置文件
sudo /etc/init.d/vsftpd restart
在加载完后,重启服务器:
sudo systemctl restart vsftpd
查看服务启动状态:
sudo systemctl status vsftpd
设置开机启动:
sudo systemctl enable vsftpd
如果想关闭开机启动:
sudo systemctl disable vsftpd
2、配置
先备份配置文件:
sudo cp /etc/vsftpd.conf /etc/vsftpd.conf.back
vim进入编辑信息:
sudo vim /etc/vsftpd.conf
本地用户:anonymous_enable
匿名用户:local_enable
受限用户:chroot_list_enable
参考:https://www.cnblogs.com/linuxws/p/11006293.html
https://blog.csdn.net/weixin_43759606/article/details/113582776
1.匿名用户相关设置anonymous_enable=YES ,将YES改为NO, 禁止匿名用户登陆#non_mkdir_write_enable=YES ,将#注释去掉,允许匿名用户创建目录#non_upload_enalbe=YES ,将#去掉,允许匿名用户上传anon_world_readable_only=YES ,允许匿名用户下载,默认是禁止的,这个可以自行添加。Anon_other_write_enable=YES ,将其设为YES的话,就除了上传和创建目录外,还可以重命名,删除文件,默认是NOno_anon_password=NO ,将其设为YES,匿名用户不会查询用户密码直接登陆。ftp_username=ftp ,匿名用户登陆系统的账号默认为ftp,此项最好不要改,否则设置不当会给系统的安全带来威胁。2.FTP服务端口的指定listen_port=8021 ,指定命令通道为8021,默认为21listen_data_port=8020 ,指定数据通道为8020,默认为203.上传模式的设置pasv_enable=YES ,是否允使用被动模式,默认是允许的。pasv_min_port=10000 ,指定使用被动模式时打开端口的最小值pasv_max_port=10004 ,指定使用被动模式时打开端口的最大值。4.Vsftp服务器指定IP地址listen_address=192.168.0.21 ,指定FTP,IP地址注:只有当vsftp运行于独立模式时才允许使用指定IP,如果在/etc/xinetd.d目录下已经建立了vsfpd文件,就要将该文件中的disable设置为yes,方可。5. 锁定用户,禁止用户离开用户主目录chroot_local_user=YES ,将其设为YES,就锁定在用户主目录,设为NO,可以切换将指定用户设置为锁定用户主目录:#chroot_list_enable=YES#chroot_list_file=/etc/vsftpd.chroot_list将其改为如下:chroot_list_enable=NOchroot_list_file=/etc/vsftpd/vsftpd.chroot_list将上面保存,再做如下操作:#touch /etc/vsftpd/vsftpd.chroot_list#vi /etc/vsftpd/vsftpd.chroot_list ,在该文件中加入用户名单,如:netseek_com6.FTP服务器的流量控制max_clients=100 ;允许的最大连接数,定义为100,默认为0,表没有限制max_per_ip=5 ;每个IP允许的连接数,0表没有限制,需要运行于独立模式方可anon_max_rate=50000 ;匿名用户最大带宽,单位为bpslocal_max_rate=200000 ;系统用户最大带宽如何对指定用户进行流量限制呢?#vi /etc/vsftpd/vsftpd.conf,添加一行:user_config_dir=/etc/vsftpd/userconf#touch /etc/vsftpd/userconf/netseek_com 为netseek_com这个用户建立一个netseek_com文件#vi /etc/vsftpd/userconf/netseek_com 添加以下内容local_max_rate=100000 保存重启服务即可.7.定制欢迎信息目录说明设置#vi /etc/vsftpd/vsftpd.conf#dirmessage_enable=YES,前的#去掉。然后我们定制一个.message,写上你想写的东西,然后把这个文件复制到各个用户的家目录中,就OK。系统欢迎消息设置ftpd_banner=Welcome to ftp.netseek.com , Yeah!!!系统欢迎消息文件设置banner_file=/etc/vsftpd/welcome 与ftpd_banner相类似,不同之处在于,banner_file指定欢迎文件.
# Example config file /etc/vsftpd.conf
#
# The default compiled in settings are fairly paranoid. This sample file
# loosens things up a bit, to make the ftp daemon more usable.
# Please see vsftpd.conf.5 for all compiled in defaults.
#
# READ THIS: This example file is NOT an exhaustive list of vsftpd options.
# Please read the vsftpd.conf.5 manual page to get a full idea of vsftpd's
# capabilities.
#
#
# Run standalone? vsftpd can run either from an inetd or as a standalone
# daemon started from an initscript.
listen=NO
#
# This directive enables listening on IPv6 sockets. By default, listening
# on the IPv6 "any" address (::) will accept connections from both IPv6
# and IPv4 clients. It is not necessary to listen on *both* IPv4 and IPv6
# sockets. If you want that (perhaps because you want to listen on specific
# addresses) then you must run two copies of vsftpd with two configuration
# files.
listen_ipv6=YES
#
# Allow anonymous FTP? (Disabled by default).
anonymous_enable=NO
#
# Uncomment this to allow local users to log in.
local_enable=YES
#
# Uncomment this to enable any form of FTP write command.
write_enable=YES
#
# Default umask for local users is 077. You may wish to change this to 022,
# if your users expect that (022 is used by most other ftpd's)
local_umask=022
#
# Uncomment this to allow the anonymous FTP user to upload files. This only
# has an effect if the above global write enable is activated. Also, you will
# obviously need to create a directory writable by the FTP user.
anon_upload_enable=YES
#
# Uncomment this if you want the anonymous FTP user to be able to create
# new directories.
anon_mkdir_write_enable=YES
#
# Activate directory messages - messages given to remote users when they
# go into a certain directory.
dirmessage_enable=YES
#
# If enabled, vsftpd will display directory listings with the time
# in your local time zone. The default is to display GMT. The
# times returned by the MDTM FTP command are also affected by this
# option.
use_localtime=YES
#
# Activate logging of uploads/downloads.
xferlog_enable=YES
#
# Make sure PORT transfer connections originate from port 20 (ftp-data).
connect_from_port_20=YES
#
# If you want, you can arrange for uploaded anonymous files to be owned by
# a different user. Note! Using "root" for uploaded files is not
# recommended!
#chown_uploads=YES
#chown_username=whoever
#
# You may override where the log file goes if you like. The default is shown
# below.
#xferlog_file=/var/log/vsftpd.log
#
# If you want, you can have your log file in standard ftpd xferlog format.
# Note that the default log file location is /var/log/xferlog in this case.
xferlog_std_format=YES
#
# You may change the default value for timing out an idle session.
#idle_session_timeout=600
#
# You may change the default value for timing out a data connection.
#data_connection_timeout=120
#
# It is recommended that you define on your system a unique user which the
# ftp server can use as a totally isolated and unprivileged user.
#nopriv_user=ftpsecure
#
# Enable this and the server will recognise asynchronous ABOR requests. Not
# recommended for security (the code is non-trivial). Not enabling it,
# however, may confuse older FTP clients.
#async_abor_enable=YES
#
# By default the server will pretend to allow ASCII mode but in fact ignore
# the request. Turn on the below options to have the server actually do ASCII
# mangling on files when in ASCII mode.
# Beware that on some FTP servers, ASCII support allows a denial of service
# attack (DoS) via the command "SIZE /big/file" in ASCII mode. vsftpd
# predicted this attack and has always been safe, reporting the size of the
# raw file.
# ASCII mangling is a horrible feature of the protocol.
#ascii_upload_enable=YES
#ascii_download_enable=YES
#
# You may fully customise the login banner string:
#ftpd_banner=Welcome to blah FTP service.
#
# You may specify a file of disallowed anonymous e-mail addresses. Apparently
# useful for combatting certain DoS attacks.
#deny_email_enable=YES
# (default follows)
#banned_email_file=/etc/vsftpd.banned_emails
#
# You may restrict local users to their home directories. See the FAQ for
# the possible risks in this before using chroot_local_user or
# chroot_list_enable below.
#chroot_local_user=YES
#
# You may specify an explicit list of local users to chroot() to their home
# directory. If chroot_local_user is YES, then this list becomes a list of
# users to NOT chroot().
# (Warning! chroot'ing can be very dangerous. If using chroot, make sure that
# the user does not have write access to the top level directory within the
# chroot)
chroot_local_user=YES
#chroot_list_enable=YES
# (default follows)
#chroot_list_file=/etc/vsftpd.chroot_list
#
#allow_writeable_chroot=YES ## 添加allow_writeable_chroot=YES# You may activate the "-R" option to the builtin ls. This is disabled by
# default to avoid remote users being able to cause excessive I/O on large
# sites. However, some broken FTP clients such as "ncftp" and "mirror" assume
# the presence of the "-R" option, so there is a strong case for enabling it.
#ls_recurse_enable=YES
#
# Customization
#
# Some of vsftpd's settings don't fit the filesystem layout by
# default.
#
# This option should be the name of a directory which is empty. Also, the
# directory should not be writable by the ftp user. This directory is used
# as a secure chroot() jail at times vsftpd does not require filesystem
# access.
secure_chroot_dir=/var/run/vsftpd/empty
#
# This string is the name of the PAM service vsftpd will use.
pam_service_name=vsftpd
#
# This option specifies the location of the RSA certificate to use for SSL
# encrypted connections.
rsa_cert_file=/etc/ssl/certs/ssl-cert-snakeoil.pem
rsa_private_key_file=/etc/ssl/private/ssl-cert-snakeoil.key
ssl_enable=NO#no_anon_password=YES #匿名登录是否需要密码
anon_root=/NAS/ftp/nologin
local_root=/NAS/ftp/login#
# Uncomment this to indicate that vsftpd use a utf8 filesystem.
#utf8_filesystem=YES
#
#
3、创建用户 与 目录的分配
创建用户:Linux useradd 命令
以多用户为例,单用户操作方法一样
创建用户ming1,ming2和对应密码,-m创建该用户文件夹,-d指定该用户文件夹
useradd -m -d /home/ming1 -s /bin/bash ming1
passwd ming1
useradd -m -d /home/ming2 -s /bin/bash ming2
passwd ming2sudo useradd -d /home/ftp/ftp_root -m ftpadmin
sudo passwd ftpadmin
输入密码:
再次输入密码:
chmod -R 777 /home/ftp/ftp_rootsudo useradd -m ftpuser
sudo passwd ftpuser
New password:
Retype new password:
passwd: password updated successfully本地用户:anonymous_enable
匿名用户:local_enable
受限用户:chroot_list_enable
切换:
su 命令的基本格式如下:
[root@localhost ~]# su [选项] 用户名
选项:
-:当前用户不仅切换为指定用户的身份,同时所用的工作环境也切换为此用户的环境(包括 PATH 变量、MAIL 变量等),使用 - 选项可省略用户名,默认会切换为 root 用户。
-l:同 - 的使用类似,也就是在切换用户身份的同时,完整切换工作环境,但后面需要添加欲切换的使用者账号。
-p:表示切换为指定用户的身份,但不改变当前的工作环境(不使用切换用户的配置文件)。
-m:和 -p 一样;
-c 命令:仅切换用户执行一次命令,执行后自动切换回来,该选项后通常会带有要执行的命令。
查看:
cat /etc/passwd 可以查看所有用户的列表
w 可以查看当前活跃的用户列表
cat /etc/group 查看用户组
groups 查看当前登录用户的组内成员
groups gliethttp 查看gliethttp用户所在的组,以及组内成员
whoami 查看当前登录用户名
一个简明的layout命令
cat /etc/passwd|grep -v nologin|grep -v halt|grep -v shutdown|awk -F":" ‘{ print $1"|“$3”|"$4 }’|more
目录分配:
1)若配置全部用户只访问同一目录,比如用户ming1和用户ming2都默认访问/home/ming的目录,则需要添加配置
local_root=/home/ming/
并建立对应的目录给予权限
mkdir /home/ming
chmod -R 777 /home/ming
以上也适用单个用户的配置
2)若每个用户默认只访问自己对应的目录,比如用户ming1只访问/home/ming1目录,用户ming2只访问/home/ming2的目录,则需要删除local_root或在前面加#注释掉即可
参考链接:https://blog.csdn.net/weixin_36185028/article/details/80969672
4、windows远程连接
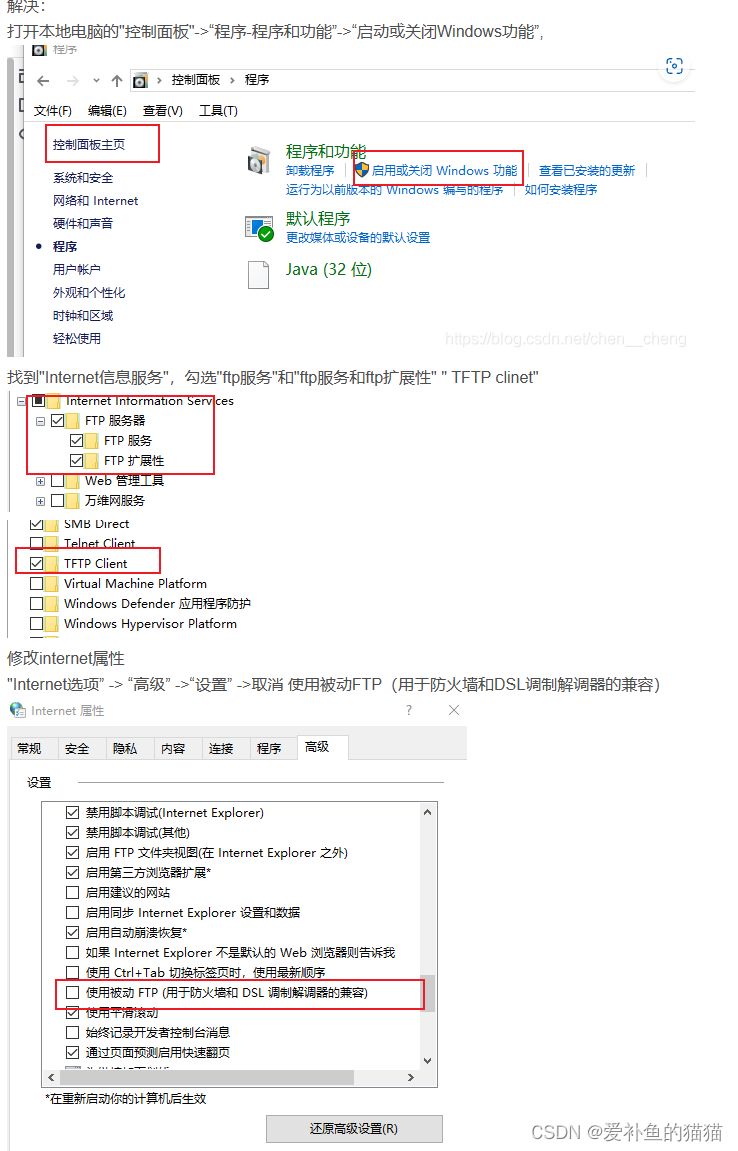
5、PASV模式
解决办法:
1、首先确保服务器支持PASV模式,并且您的客户端正在设置PASV模式,如果服务器不支持被动模式,则防火墙必须支持主动模式FTP传输。
2、或者加入以下代码ftp.set_pasv(False) # 如果被动模式由于某种原因失败,使用主动模式。
1.被动模式
在/etc/vsftpd/vsftpd.conf中添加或修改:
pasv_enable=YES
pasv_min_port=3000
pasv_max_port=30052.主动模式
在/etc/vsftpd/vsftpd.conf中添加或修改:
connect_from_port_20=YES
pasv_enable=NO参考:https://blog.csdn.net/weixin_43759606/article/details/113582776
2.FTP服务端口的指定listen_port=8021 ,指定命令通道为8021,默认为21listen_data_port=8020 ,指定数据通道为8020,默认为203.上传模式的设置pasv_enable=YES ,是否允使用被动模式,默认是允许的。pasv_min_port=10000 ,指定使用被动模式时打开端口的最小值pasv_max_port=10004 ,指定使用被动模式时打开端口的最大值。4.Vsftp服务器指定IP地址listen_address=192.168.0.21 ,指定FTP,IP地址
FTP port(主动模式) pasv(被动模式),
FTP协议有两种工作方式:PORT方式和PASV方式,中文意思为主动式和被动式。
PORT(主动)方式的连接过程是:客户端向服务器的FTP端口(默认是21)发送连接请求,服务器接受连接,建立一条命令链路。当需要传送数据时,客户端在命令链路上用PORT命令告诉服务器:“我打开了XXXX端口,你过来连接我”。于是服务器从20端口向客户端的XXXX端口发送连接请求,建立一条数据链路来传送数据。
PASV(被动)方式的连接过程是:客户端向服务器的FTP端口(默认是21)发送连接请求,服务器接受连接,建立一条命令链路。当需要传送数据时,服务器在命令链路上用PASV命令告诉客户端:“我打开了XXXX端口,你过来连接我”。于是客户端向服务器的XXXX端口发送连接请求,建立一条数据链路来传送数据。
从上面可以看出,两种方式的命令链路连接方法是一样的,而数据链路的建立方法就完全不同。而FTP的复杂性就在于此。
6、报错
ftplib.error_perm: 553 Could not create file.
(1)文件路径没填对,检查路径 (2)目录权限
十七、TTS
视频:https://www.bilibili.com/video/BV1Cg4y1X7J3/?spm_id_from=333.788&vd_source=38e7fc10713eca999c22c7ff25f6e6d2
https://search.bilibili.com/all?keyword=%E6%96%87%E5%AD%97%E8%BD%AC%E8%AF%AD%E9%9F%B3ai%E6%A8%A1%E5%9E%8B&from_source=webtop_search&spm_id_from=333.788&search_source=2
1、微软
https://github.com/coqui-ai/TTS
https://github.com/mozilla/TTS
https://github.com/Plachtaa/VALL-E-X(效果一般,操作方便,不用训练)
2、Openai (效果最好)
openai api接口
Whisper模型
whisper是OpenAI公司出品的AI字幕神器,是目前最好的语音生成字幕工具之一,开源且支持本地部署,支持多种语言识别(英语识别准确率非常惊艳)。 作者:略懂的大龙猫 https://www.bilibili.com/read/cv23995720/ 出处:bilibili
3、
https://github.com/Stardust-minus/Bert-VITS2
4、Bark模型 (英语效果还可以,中文不行)
https://github.com/suno-ai/bark
5、达摩院 (只能中文,效果中等)
达摩院语音实验室设计了SAMBERT
6、对比
https://github.com/KevinWang676/Bark-Voice-Cloning
Bert-VITS2训练
参考:https://blog.csdn.net/lsb2002/article/details/134294018
预训练模型train_ms.py已有,或者从https://github.com/srcres258/Bert-VITS2下载
1、训练前,还要生成emo文件,运行:python emo_gen.py
Emotional VITS情感控制项目:https://github.com/innnky/emotional-vits
常用Linux命令
1、 conda复制环境
复制环境
一,在本机上,直接使用 conda create -n new_env --clone old_env 复制既有环境
二,如果要复制到其他机器,就要考虑导出当前环境到文件,利用文件再次创建环境
1) 首先需要进入某个环境中
导出环境
conda env export > ~/env.yaml
或者 conda env export > environment.yaml
利用conda env export 导出的是个yaml格式的文件,该文件记录了环境名,软件源地址以及安装包列表
2) 使用yaml配置文件创建新环境
conda env create -f ~/env.yaml
或者 conda env create -f environment.yaml
在新的机器中可直接执行上述命令,生成的环境与复制源完全一样(包括环境名),如果想在同一台机器上复制,需要把yaml文件中的环境名修改为一个新的名字,否则会冲突。
conda env create -f environment.yaml -n environment_name
【注】还有一种复制环境的方式
conda list --explicit > env.txt
conda create -n newenv -f env.txt
这种方式只能复制环境中以conda install安装的包,不能复制pip install安装的包,因此不建议使用。
参考https://zhuanlan.zhihu.com/p/153498612
其他方法:
复制包:pip3 freeze > requirements.txt
pip list --format=freeze > requirements.txt
遇到问题:
yaml内部就是pip来,还是用pip方便解决版本问题
设置environment.yaml源
包版本会有问题,要修改
https://blog.csdn.net/NOVAglow646/article/details/126937509
解决方案
可以尝试对environment.yml文件进行以下修改,添加镜像源即可:
将channels改为(注意要把default去掉):channels:- conda-forge- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
1
2
3
4
5
6
7
并在pip的依赖包里添加上镜像源(加上最后一行)。- pip:- addict==2.4.0- anyio==3.3.0.......- websocket-client==1.1.0- widgetsnbextension==3.5.1- sapien==1.1.1- -i https://pypi.tuna.tsinghua.edu.cn/simple
————————————————
版权声明:本文为CSDN博主「NOVAglow646」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/NOVAglow646/article/details/126937509
2、压缩
zip 压缩命令的第一个参数指定压缩文件名, 后面的所有参数指定待压缩的文件或目录
压缩文件: zip xxx.zip file …
压缩目录: zip -r xxx.zip dir …
把文件解压到当前目录下
unzip xxxxx.zip
如果要把文件解压到指定的目录下,需要用到-d参数(-d指定目标路径,file.zip是需要解压的,destination_folder是指定的目录下)。
unzip file.zip -d destination_folder
2、hunggingface安装这个?sudo apt-get install git-lfs
git lfs install
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5 models/StableDiffusion/
参考:https://github.com/guoyww/animatediff/
3、ffmpeg
$ sudo apt update
$ sudo apt upgrade
sudo apt-get install ffmpeg
4、conda换源
https://blog.csdn.net/KIK9973/article/details/118776314
https://blog.csdn.net/weixin_44942303/article/details/121977449
5、conda相关命令
升级:conda update -n base conda
删除:
1、:删除环境
conda remove -n 需要删除的环境名 --all
2、:删除环境
conda env remove -p 要删除的虚拟环境路径
conda env remove -p /home/kuucoss/anaconda3/envs/tfpy36 #我的例子
6、shell启动python虚拟环境
https://zhuanlan.zhihu.com/p/422365954
https://blog.csdn.net/weixin_44966641/article/details/119853359
#!/bin/sh
source /home/bruce/anaconda3/bin/activate your_env_name
python test.py
run.sh
#!/usr/bin/env bash
source /root/miniconda3/bin/activate kohyass
python test.py \
-u 小红 \
-p 12345 \
test.py
if __name__ == '__main__':import sysprint(sys.path)print('当前 Python 解释器路径:')print(sys.executable)import argparse# 定义一个ArgumentParser实例:parser = argparse.ArgumentParser(prog='backup', # 程序名description='Backup MySQL database.', # 描述epilog='Copyright(r), 2023' # 说明信息)# 允许用户输入简写的-u:# parser.add_argument( '--user',default='name')# parser.add_argument('--password', default='word')parser.add_argument('-u', '--user',default='name')parser.add_argument('-p', '--password', default=123,type=int)# 解析参数:args = parser.parse_args()print('解析完参数:',args)print('类型:',type(args))print("python环境测试")python = ["优雅","明确","简单"]for linian in iter(python):print(linian)
#! /bin/bash
#### 这里在/usr/local里面创建文件夹是想看是否有执行的权限
#### 事实证明是有的
mkdir /home/Meger/shelltest/temp
echo "test auto bootstrap" > /home/Meger/shelltest/temp/2023.log
echo "test auto 开机测试" > /home/Meger/shelltest/temp/23.log
echo "输出完成"time3=$(date "+%Y-%m-%d %H:%M:%S")
echo $time3 > /home/Meger/shelltest/temp/test.log方案一:(生效)
https://blog.csdn.net/Perfect886/article/details/117119231
编辑 /etc/rc.local文件,在最后加上你的脚本即可。
比如:我已经编写了一个脚本apk.sh,存放在/home/apk/下面
在Ubuntu终端输入: sudo nano /etc/init.d/rc.local
在结尾出加入: sh /home/apk/shell.sh //即可开机自动加载脚本
注意:编辑时需要root权限,如果该方法没有正确启动,检查log内容。需要注意的一个点:rc.local中的脚本会在系统登录前执行,这是我们还没进入桌面,因此有可能会执行失败
链接:https://blog.csdn.net/marujunyy/article/details/8466255
1、修改system下的rc-local.service
vim /lib/systemd/system/rc-local.service
然后在 rc-local.service中最后面添加如下代码:
[Install]
WantedBy=multi-user.target
Alias=rc-local.service2、 /etc/rc.local
#!/bin/sh
echo "看到这行字,说明添加自启动脚本成功。" > /usr/local/test.log
#中间这一段就是脚本的内容
exit 03、systemd 默认读取 /etc/systemd/system 下的配置文件, 所以还需要在 /etc/systemd/system 目录下创建软链接方案二:
/etc/init.d方法
sudo mv test.sh /etc/init.d/
sudo chmod 777 test.sh
sudo update-rc.d test.sh defaults
如果需要设置启动优先级: bash # 100表示优先级,数越大,执行的越晚 sudo update-rc.d test.sh defaults 100
如果要移除脚本:
cd /etc/init.d
sudo update-rc.d -f test.sh remove
链接:https://blog.csdn.net/weixin_43455581/article/details/107815743
7、终端目录说明界面(terminal)
# 打开配置文件
vi ~/.bashrc
# 使配置文件生效
source ~/.bashrc
8、修改huggingface 目录
参考:https://www.cnblogs.com/kongaobo/p/17528720.html
Huggingface 默认下载位置更改
Ubuntu 系统中 Huggingface 模型等默认的下载位置如下:~\.cache\huggingface\hub
通过修改环境变量更改默认下载位置:# 打开配置文件
vi ~/.bashrc
# 添加下述变量
export HF_HOME="目标地址"
# 使配置文件生效
source ~/.bashrc
Python 常用操作
1.清空文件夹
shutil.rmtree() 表示递归删除文件夹下的所有子文件夹和子文件。
2.格式化字符串f() python中 r’‘, b’‘, u’‘, f’’ 的含义
用法,f-string在功能方面不逊于传统的%-formatting语句和str.format()函数,同时性能又优于二者.
out_path = f’{output_dataset_dir}/{i:03d}.jpg’
3、python设置临时环境变量
PYTHONPATH=. sh train_lora.sh “ly261666/cv_portrait_model” “v2.0” “film/film” “./imgs” “./processed” “./output”
https://blog.csdn.net/weixin_45019478/article/details/113574529
4、vars将类转成字典
eavl转字符串

5、交互窗口,jupy

6、数据保存json
1、对象——pickle和json
pickle模块是以二进制的形式序列化后保存到文件中(保存文件的后缀为".pkl"),不能直接打开进行预览。而python的另一个序列化标准模块 json,可以直接打开查看(例如在notepad++中查看)。
使用总结:
pickle保存成二进制序列,json保存成json格式的可读文本,显然json文件可读性更强;
pickle保存的对象只能用于python,且不同版本可能不通用;
pickle用来载入自定义的类实例时,必须先导入相应类型;
dump、load用来操作文件流,dumps、loads用来操作对象
pickle操作文件时,要以’b’二进制打开文件;
json本身有自己定义的一些数据格式,所以存储时需要确保存储对象在json中有对应的类型
json使用时参照以下的对应表,如果想要序列化的数据类型不在这些里面,则保存时会报错
参考链接:https://blog.csdn.net/jonathanzh/article/details/107382056
2、json存储问题
1、python去除字符串中的转义字符:
data = {“datas”: ‘[{“name”: “菜鸟”}]’}
我们使用json的dumps方法将这个字典转为字符串,
res = json.dumps(data, ensure_ascii=False)
再打印这个res的时候会发现输出的字符串里包含有转义字符,即反斜杠:
{“datas”: “[{\“name\”: \“菜鸟\”}]”}
这里有两种方法可以去除反斜杠,首先第一种比较简单暴力,直接:
data = res.replace(“\”, “”)即可,但是各位在使用中要注意,处理之后的数据是否还能正常使用,因为当处理的数据量很大时,无法确定在其他地方反斜杠是否还有用处,所以这种方法适合数据量小,且没有特殊情况的问题使用。
第二种方法使用eval函数处理,即:
data = eval(res)
打印这个data,会发现{‘datas’: ‘[{“name”: “菜鸟”}]’}反斜杠没有了,原理是eval首先将res这个变量里的字符串引号剥去,然后得到的是一个字典,显然这个是不可以进行计算的,那么它就开始查找这个字典是否是一个变量,然后它一查找,找到了data,于是输出了data里的原始内容。
import json
data = {“datas”: ‘[{“name”: “菜鸟”}]’}
res = json.dumps(data, ensure_ascii=False)
print(res)
data = eval(res)
print(data)
参考链接:https://blog.csdn.net/qq_20997219/article/details/116269570
import json
class Student(object):def __init__(self):self.name = ""self.age = 0self.causes = []class teacher(object):def __init__(self,name,age,score):self.name = nameself.age = ageself.score = scoredef ParseJsonToObj(jsonStr, yourCls):parseData = json.loads(jsonStr.strip('\t\r\n'))result = yourCls()result.__dict__ = parseDatareturn resultdef ParseObjToJson(yourObj):return yourObj.__dict__.__str__().replace("\'", "\"")if __name__ == '__main__':#1、没构造类测试jsonStr = '{"name": "ww", "age": 99, "causes": ["A","B"]}'stu = ParseJsonToObj(jsonStr, Student)print("result={}, type={}".format(stu, type(stu)))print("name={}, age={}, causes={}".format(stu.name,stu.age,stu.causes))# result=<__main__.Student object at 0x0000028343AE2198>, type=<class '__main__.Student'># name=ww, age=99, causes=['A', 'B']print("stu json={}".format(ParseObjToJson(stu)))# stu json={"name": "ww", "age": 99, "causes": ["A", "B"]}Stuobj = Student()Stuobj.name="小红"print(Stuobj.__dict__)print("stu json={}".format(ParseObjToJson(Stuobj)))Stustr=ParseObjToJson(Stuobj)# Stustr=Stustr.replace("\\", "/")Stustr=eval(Stustr)with open("savejson/save2.json", "w", encoding='utf-8') as f: ## 设置'utf-8'编码# f.write(json.dumps(Stustr,ensure_ascii=False))json.dump(Stustr, f,ensure_ascii=False) # 保存到文件## 如果ensure_ascii=True则会输出中文的ascii码,这里设为Falsewith open("savejson/save2.json", "r", encoding='utf-8') as f:load_dict = json.load(f)print('load_dic值:',load_dict)fr = open("savejson/save3.json", 'w',encoding='utf-8')json.dump(Stustr, fr,ensure_ascii=False) # 保存到文件fr.close()#2、构造类测试# teaobj = teacher('hello', 20, 80)# print("teacher json={}".format(ParseObjToJson(teaobj)))# teastr = ParseObjToJson(teaobj)## tobj = ParseJsonToObj(teastr, teacher) #报错,必须要实例化# print("result={}, type={}".format(tobj, type(tobj)))# print("name={}, age={}, causes={}".format(tobj.name, tobj.age, tobj.score))7、python 环境变量设置PYTHONPATH
python sys.path.append()和sys.path.insert()
https://zhuanlan.zhihu.com/p/385287537
import sys
import osprint('当前 Python 解释器路径:')
print(sys.executable)
r"""
当前 Python 解释器路径:
C:\Users\jpch89\AppData\Local\Programs\Python\Python36\python.EXE
"""print()
print('当前 Python 解释器目录:')
print(os.path.dirname(sys.executable))
r"""
当前 Python 解释器目录:
C:\Users\jpch89\AppData\Local\Programs\Python\Python36
"""
import os
import sys# 设置PYTHONPATH
sys.path.insert(0, "/path/to/your/module_or_package")import sys
sys.path.append("/path/to/directory")
7、任意路径导包
sys.path.append(r"stable-diffusion-webui")
注意:有同名文件会出错,这只是把路径名加入环境变量
8、Python 全局异常处理 sys.excepthook (路由和进程捕获不了)
python中如何用sys.excepthook来对全局异常进行捕获、显示及输出到error日志中
python中logging(日志)配置三种方式
python logger 全局捕获异常/错误信息
Python中的traceback
异常层次:https://cloud.tencent.com/developer/section/1366492
9、将Python控制台输出保存到文件的方法
参考: https://blog.csdn.net/qq_39564555/article/details/112135970
在 PyCharm 中或者说运行 python 程序时会使用 print 输出些过程信息、 traceback 异常信息 到控制台,但是程序运行结束后记录就没有了,所以想着每次运行将信息显示在控制台的同时记录到文件中。
记录正常的 print 信息
sys.stdout = Logger(log_file_name)
# 记录 traceback 异常信息
sys.stderr = Logger(log_file_name)
在sys模块中,stderr用来表示标准错误输出去向,stdout表示标准输出去向,通过修改这两个值,可以实现把程序的错误输出和标准输出的内容都写入文件。
sys.stdout = open(‘alog.txt’, ‘a’)
sys.stderr = open(‘aerrorlog.txt’, ‘a’) #将后续的报错信息写入对应的文件中,模式,有w和a,w就是写模式,每次都会重新写日志,覆盖之前的日志, a是追加模式,默认如果不写的话,就是追加模式
- 使用Python将Exception异常错误堆栈信息写入日志文件
- python logger 全局捕获异常/错误信息
Python 将控制台输出另存为日志文件
需求
方法一:使用 Logger 类(推荐)
方法二:仅使用 sys
方法三:使用 logging 模块
手动控制日志文件大小
除了上述两种方法外,我们还可以通过编写代码手动控制日志文件的大小。我们可以在记录每条日志之前先检查日志文件的大小,如果超过了指定的限制,则将其备份并创建一个新的日志文件。
import logging
import os# 创建日志记录器
logger = logging.getLogger('my_logger')
logger.setLevel(logging.DEBUG)# 设置日志文件路径和大小
log_file = 'my_log.log'
max_log_size = 1024*1024 # 限制日志文件大小为1MB# 检查日志文件大小并备份
def check_log_file_size():if os.path.exists(log_file):log_size = os.path.getsize(log_file)if log_size >= max_log_size:backup_file = log_file + '.bak'os.rename(log_file, backup_file)with open(log_file, 'w') as f:f.write('')# 检查日志文件大小并备份
check_log_file_size()# 创建FileHandler对象
handler = logging.FileHandler(log_file)# 设置日志记录的格式
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)# 将handler添加到logger中
logger.addHandler(handler)# 输出日志信息
logger.debug('This is a debug message')
logger.info('This is an info message')
logger.warning('This is a warning message')
logger.error('This is an error message')
logger.critical('This is a critical message')
限制大小保存日志
import sys
import os
import time# 控制台输出记录到文件
class Logger(object):def __init__(self, file_name="Default.log", stream=sys.stdout):self.terminal = streamself.log = open(file_name, "a")def write(self, message):self.terminal.write(message) #输出到控制台self.log.write(message)def flush(self):passif __name__ == '__main__':# 自定义目录存放日志文件log_path = './Logs/'if not os.path.exists(log_path):os.makedirs(log_path)# 日志文件名按照程序运行时间设置# log_file_name = log_path + 'log-' + time.strftime("%Y%m%d-%H%M%S", time.localtime()) + '.log'log_file_name1 = log_path + 'logyes-' + time.strftime("%Y%m%d-%H%M%S", time.localtime()) + '.log'log_file_name2 = log_path + 'logerro-' + time.strftime("%Y%m%d-%H%M%S", time.localtime()) + '.log'# 记录正常的 print 信息sys.stdout = Logger(log_file_name1)# 记录 traceback 异常信息sys.stderr = Logger(log_file_name2)for i in range(1,1000000):try:fsize = os.path.getsize(log_file_name2) # 返回的是字节大小print('文件大小:',fsize)if fsize >= 1024*20:print('清空文件')backup_file = log_file_name2 + '.bak'# os.rename(log_file_name2, backup_file)import shutilshutil.copyfile(log_file_name2, backup_file)with open(log_file_name2, 'w') as f:f.write('')# f.truncate(0)print(5555)print(2 / 0)except Exception as e:sys.stderr.write(f'{i}:{e}\n')fsize = os.path.getsize(log_file_name2) # 返回的是字节大小print('文件大小B:', fsize)print('文件大小KB:', fsize/1024)print('文件大小M:', fsize/1024/1024)10、python info日志
1、longging保存日志到文件
https://blog.csdn.net/Runner1st/article/details/96481954
方法一:使用 logging
方法二:logger模块化
2、Python 如何限制Python中的日志文件大小:
https://geek-docs.com/python/python-ask-answer/901_python_how_to_limit_log_file_size_in_python.html
方法一:使用RotatingFileHandler模块
方法二:使用TimedRotatingFileHandler模块
方法三:手动控制日志文件大小
3、logger 全局捕获异常/错误信息
import sys
import logging
import os
import timelogger = logging.getLogger(__name__)# handler = logging.StreamHandler(stream=sys.stdout)
# logger.addHandler(handler)logger.setLevel(level=logging.INFO)
# 创建一个 handler,写入日志文件
log_path = './Logs/'
if not os.path.exists(log_path):os.makedirs(log_path)
log_file_name = log_path + 'log-' + time.strftime("%Y%m%d-%H%M%S", time.localtime()) + '.log'
logfile = log_file_name
handler = logging.FileHandler(logfile, mode='a+')
# 输入到日志文件中的日志等级
handler.setLevel(logging.DEBUG)
# 设置 handler 中日志记录格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
# 将 handler 添加到 logger 里面
logger.addHandler(handler)def handle_exception(exc_type, exc_value, exc_traceback):if issubclass(exc_type, KeyboardInterrupt):sys.__excepthook__(exc_type, exc_value, exc_traceback)returnlogger.error("Uncaught exception", exc_info=(exc_type, exc_value, exc_traceback)) # 重点sys.excepthook = handle_exception # 重点if __name__ == "__main__":# raise RuntimeError("Test unhandled")print(5555555555)print(5 / 0)11、 traceback 异常信息 到控制台
12、多队列线程
用一个Queue来实现线程间数据共享,根据线程数和队列数,计算出每次喂给线程的数量。用一个长队实现多个队列。
queue_per_future = max(len(temp_frame_paths) // facefusion.globals.execution_thread_count * facefusion.globals.execution_queue_count, 1) #取整://; 对于//,是向下取整,即不会进行四舍五入
13、python执行脚本当前相对目录
export PYTHONPATH=$PYTHONPATH:${cur_dir}
附: python代码常用函数
1、importlib.import_module动态导入模块
hasattr判断对象是否包含对应的属性
2、opennsfw2对图片/视频进行鉴黄识别
3、insightface.app.FaceAnalysis识别脸,及其对应的性别、年龄
4、subprocess 模块允许我们启动一个新进程,并连接到它们的输入/输出/错误管道,从而获取返回值。
5、ffmpeg 压缩图片大小(压缩图片文件大小)
注意:使用 -quality 选项的数值越小,图片的质量就越低,文件的大小也就越小。但是,过低的质量会导致图片质量下降,甚至出现噪点等现象。因此,你需要根据实际情况来决定使用的质量。
6、ffmpeg处理视频的拆分
7、ffmpeg处理音频和视频的拆分
python模型库
1、accelerate
accelerate 是huggingface开源的一个方便将pytorch模型迁移到 GPU/multi-GPUs/TPU/fp16 模式下训练的小巧工具。和标准的 pytorch 方法相比,使用accelerate 进行多GPU DDP模式/TPU/fp16/bf16 训练你的模型变得非常简单(只需要在标准的pytorch训练代码中改动不几行代码就可以适应于cpu/单GPU/多GPU的DDP模式/TPU 等不同的训练环境),而且速度与原生pytorch相当,非常之快。
平时阅读大佬们的代码 (pytorch),由于他们都是多机多卡训练的,代码中使用的都是分布式并行计算,需要定义一系列的参数,显得非常复杂。而HuggingFace的Accelerate就能很好的解决这个问题,只需要在平时用的DataParallel版代码中修改几行,就能实现多机多卡、单机多卡的分布式并行计算,另外还支持FP16半精度计算。

加速参数设置:
方法一:通过配置文件设置
设置加速的默认参数:accelerate config方法二:命令行设置
accelerate launch --num_cpu_threads_per_process=12 "./train_network.py" --enable_bucket2、os.system和subprocess(多进程模型训练1)
raise ValueError(‘参数错误’)抛出的异常不可以捕获,只能查看状态码
(1)、os.system(捕获不了异常)
该变量返回当前操作系统的类型,当前只注册了3个值:分别是posix , nt , java, 对应linux/windows/java虚拟机,print(os.name)。
if os.name == 'posix':os.system(run_cmd)else:subprocess.run(run_cmd)
异常处理:
os.system方式
返回值:0(成功),1,2
为同步调用,直到命令执行结束才会返回是否成功标志,并不能反馈信息。
(2)subprocess.run(捕获不了异常)
subprocess.run() Python 3.5中新增的函数。执行指定的命令,等待命令执行完成后返回一个包含执行结果的CompletedProcess类的实。.check:如果该参数设置为 True,并且进程退出状态码不是 0,则弹 出 CalledProcessError 异常。如果 capture_output 设为 true,stdout 和 stderr 将会被捕获。在使用时,内置的 Popen 对象将自动用 stdout=PIPE 和 stderr=PIPE 创建。stdout 和 stderr 参数不应当与 capture_output 同时提供。如果你希望捕获并将两个流合并在一起,使用 stdout=PIPE 和 stderr=STDOUT 来代替 capture_output。
subprocess.check_call() Python 2.5中新增的函数。 执行指定的命令,如果执行成功则返回状态码,否则抛出异常。其功能等价于subprocess.run(…, check=True)
参考:
https://blog.csdn.net/mouday/article/details/86367256
https://www.cnblogs.com/ccorz/p/Python-subprocess-zhong-derun-fang-fa.html
https://www.runoob.com/w3cnote/python3-subprocess.html
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, timeout=None, check=False)
args是所有调用所必需的,应该为一个字符串或一个程序参数序列。通常倾向提供参数序列,因为它允许这个模块来处理任何所需的转义和引用参数(例如,允许文件名中的空格)。如果传递单个字符串,shell必须为True(见下文),否则字符串必须简单地命名要执行的程序而不指定任何参数。
run_cmd='python apptest1.py' print(run_cmd)print('subprocess执行命令')subprocess.run(run_cmd,shell=True, check=True)
异常捕获
(1)
import subprocess
def runcmd(command):ret = subprocess.run(command,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE,encoding="utf-8",timeout=1)if ret.returncode == 0:print("success:",ret)else:print("error:",ret)runcmd(["dir","/b"])#序列参数
runcmd("exit 1")#字符串参数(2)try:# print('subprocess执行命令')# ret = subprocess.run(run_cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE,encoding="utf-8",timeout=1)# if ret.returncode == 0:# print("success:",ret)# else:# print("error:",ret)# print('sub执行结束,没有异常')print('subprocess执行命令')process = subprocess.run(run_cmd,shell=True, encoding="utf-8")# process = subprocess.run(run_cmd,shell=True, check=True, capture_output=True,encoding="utf-8")print('类型:',type(process))print('process值:',process)print('状态码为0成功',process.returncode)print('sub执行结束,没有异常')except Exception as e:# process.kill()print('捕获异常:')print(e, e.__traceback__.tb_lineno, '行')Python try块不会捕获os.system异常
ut_eos 发布于 2019-02-01 • 在 except • 最后更新 2019-02-01 09:20 • 983 浏览我有这个Python代码:import os
try:os.system('wrongcommand')
except:print("command does not work")
代码打印:
wrongcommand: command not found
而不是command does not work。有谁知道为什么它不打印我的错误信息?
4 个回复
reum 2019-02-01如果要在命令不存在时抛出异常,则应使用subprocess:import subprocesstry:subprocess.call(['wrongcommand'])except OSError:print ('wrongcommand does not exist')
想想看,你应该使用subprocess而不是os.system ..
3、多进程spawn、fork、forkserver (多进程模型训练2)
raise ValueError(‘参数错误’)抛出的异常可以捕获
Python 多进程编程:创建进程的三种模式之spawn、fork、forkserver
首先fork和spawn都是构建子进程的不同方式,区别在于:
fork:除了必要的启动资源外,其他变量,包,数据等都继承自父进程,并且是copy-on-write的,也就是共享了父进程的一些内存页,因此启动较快,但是由于大部分都用的父进程数据,所以是不安全的进程
spawn:从头构建一个子进程,父进程的数据等拷贝到子进程空间内,拥有自己的Python解释器,所以需要重新加载一遍父进程的包,因此启动较慢,由于数据都是自己的,安全性较高
raise ValueError(‘参数错误’)抛出的异常可以捕获
多进程调用训练模型
报错:Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the ‘spawn’ start method
import torch
torch.multiprocessing.set_start_method('spawn',force=True)
#解决不了
# print(multiprocessing.get_start_method())
# multiprocessing.set_start_method('spawn', force=True)try:print('subprocess执行命令')core.testtrain('我是主线程')print('sub执行结束,没有异常')except Exception as e:print("Couldn't parse")print('捕获异常Reason:', e)4、python multiprocessing 如何在主进程中捕获子进程抛出的异常
https://blog.csdn.net/lixiaowang_327/article/details/81319923
5、requests和request
(1)requests
Python request里面data、json、params传参方式的不同
1、json.dumps()和json.loads()是json格式处理函数(可以这么理解,json是字符串)
(1)json.dumps()函数是将一个Python数据类型列表进行json格式的编码(可以这么理解,json.dumps()函数是将字典转化为字符串)
(2)json.loads()函数是将json格式数据转换为字典(可以这么理解,json.loads()函数是将字符串转化为字典)
2、json.dump()和json.load()主要用来读写json文件函数
requests模块发送请求有data、json、params三种携带参数的方法。
params在get请求中使用,data、json在post请求中使用
文链接:https://blog.csdn.net/Jason_WangYing/article/details/108256804
(2)request
flask中request对象中的form、data、json这三个属性其实是flask根据不同的content-type类型将HTTP请求体进行转换而来的数据,这几个属性的类型一般都是字典或者是字典的子类。
https://zhuanlan.zhihu.com/p/551703472
附:
论文:cvpr
6、gradio UI库
gradio Python项目常用的ui库
launch(server_name=“0.0.0.0”, server_port=1234)
ui.launch(show_api = False, share = True,server_port=6006)
参数:https://www.gradio.app/docs/interface