如何起步使用UCI数据集
这里记录一下如何把带分号的数据变成经常使用的csv形式。这里使用wine的例子
https://archive.ics.uci.edu/dataset/186/wine+quality
原始数据 Wine

UCI数据操作
这种带分号的使用python的不好阅读,可以尝试以下步骤:
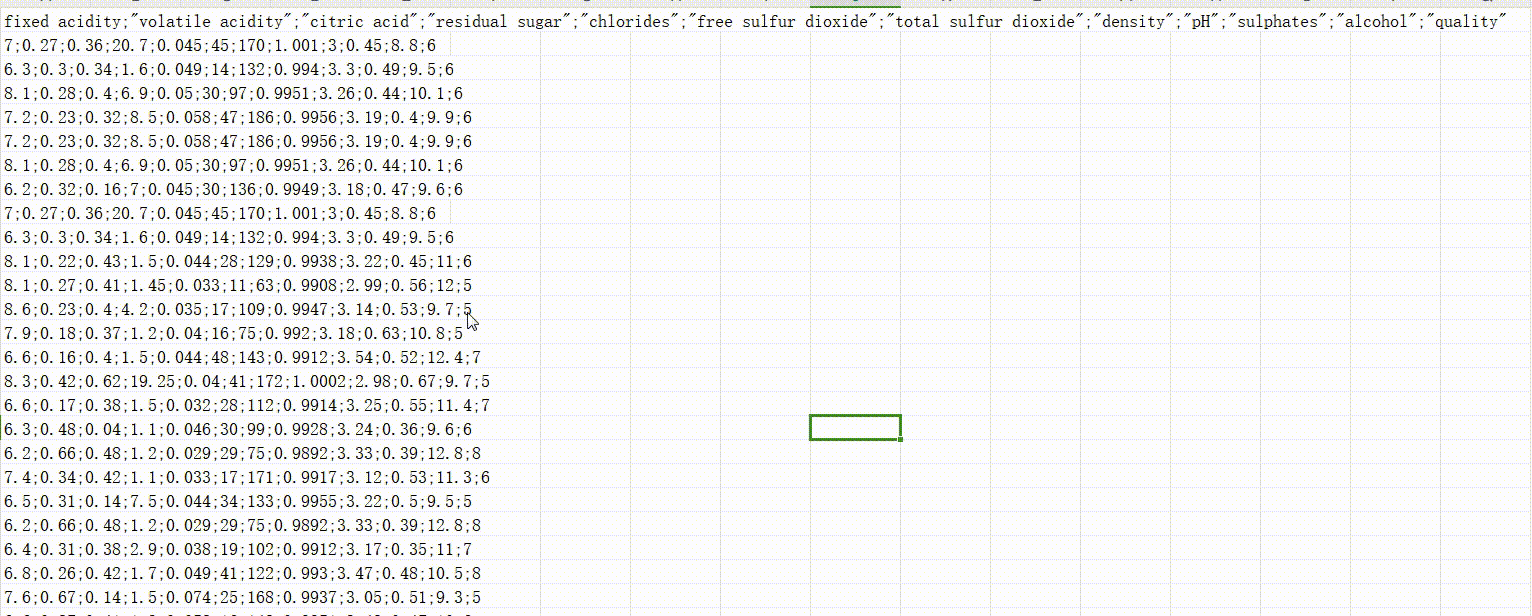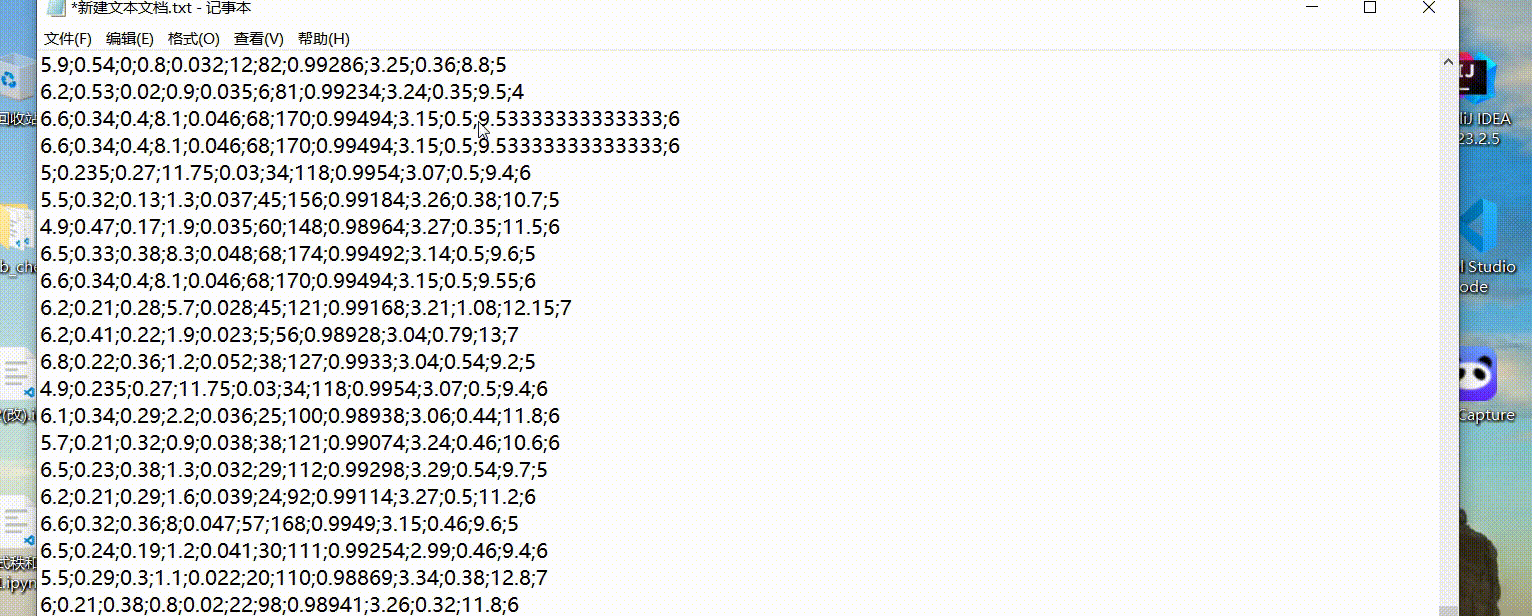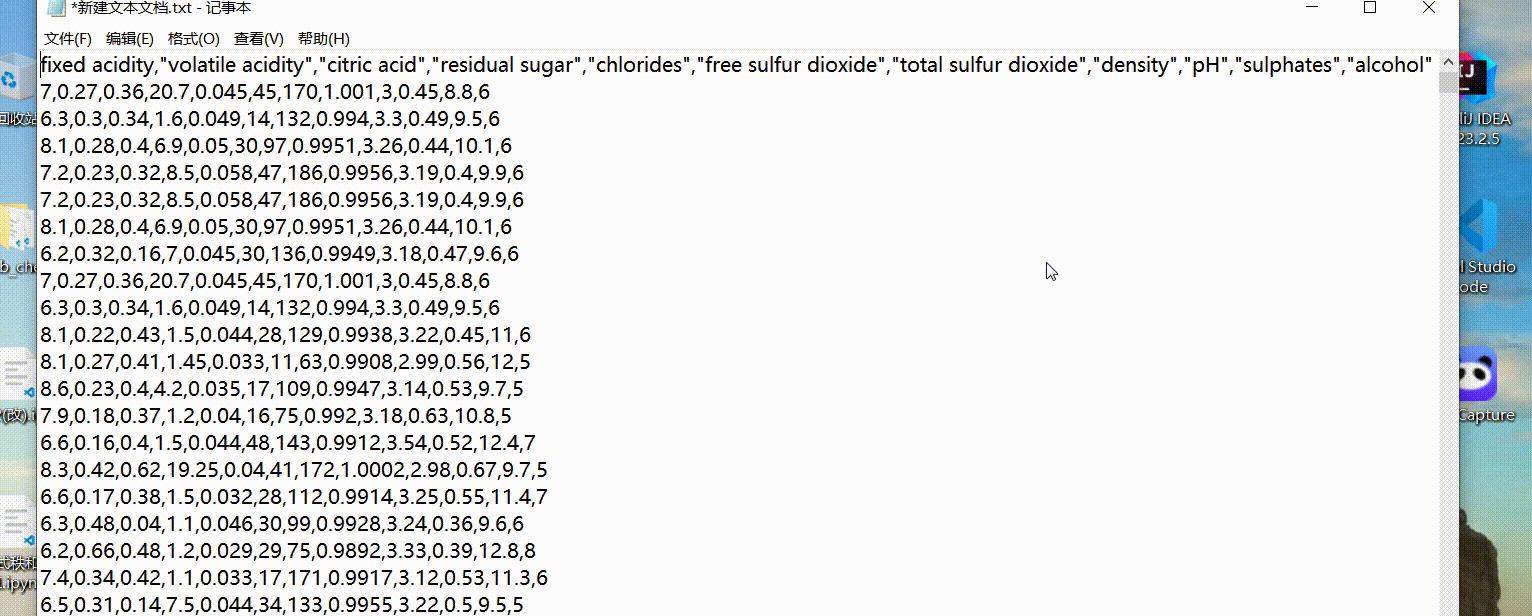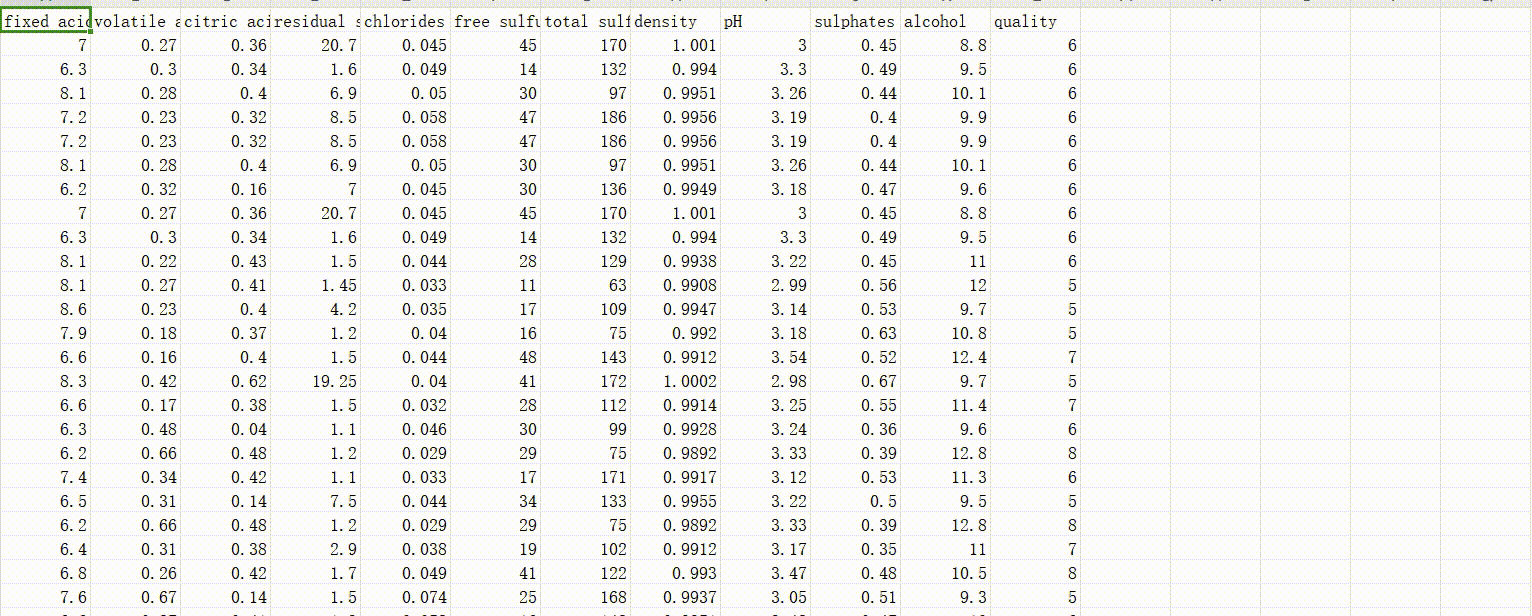
- 转变为txt文件,用替换的形式,将分号替换为逗号。
- 将文件形式转变为csv文件即可。
其次文件的头部可以改成字母。以下是在jupyter的python代码
import heapq
import datetime
import numpy as np
import pandas as pd
from sklearn import svm
from scipy.stats import spearmanr
from sklearn.model_selection import KFold
from sklearn.preprocessing import MinMaxScaler
from sklearn.neighbors import KNeighborsClassifier
from decimal import Decimal# 读取数据 下载的UFD数据没有列名称,它把第一行当作了列名称,这里需要处理一下。
data = pd.read_csv(r"C:\Users\LCC\Desktop\wine.csv")
row1 = data.columns.values
row1
# 将列名字改为字母顺序
columns_name = []
for i in range(len(row1)):columns_name.append(chr(ord('A')+i))
columns_name
#保存 这里默认根路径是桌面
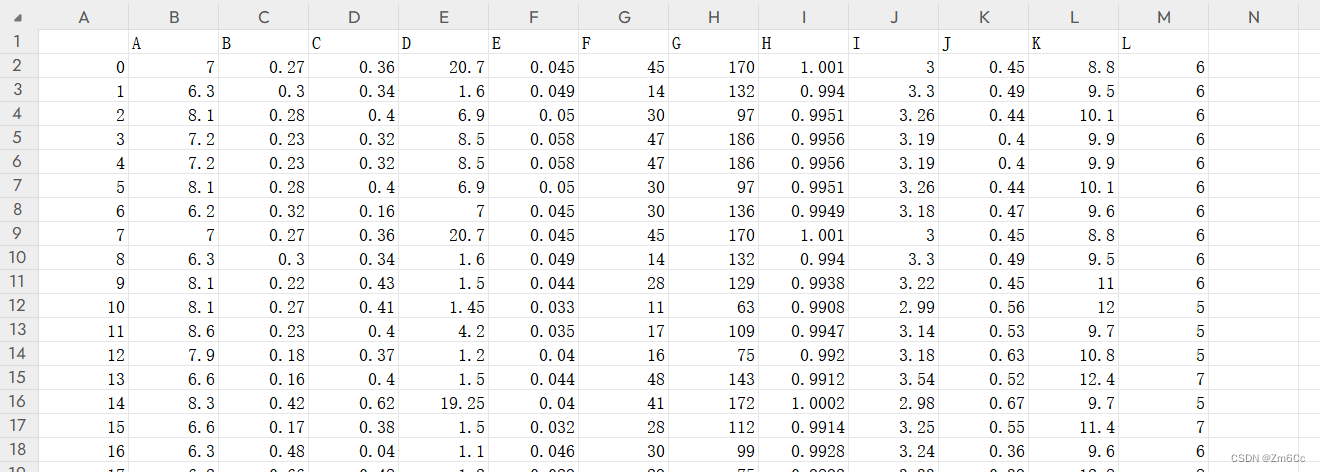
data.columns = columns_name
data.to_csv("wine.csv")
改善后效果图