一、概述
布隆过滤器(Bloom Filter)主要用来检索一个元素是否在一个集合中。它是一种数据结构bitMap,优点是高效的插入和查询,而且非常节省空间。缺点是存在误判率和删除困难。
二、应用场景
1、避免缓存穿透,当redis做缓存,没有命中会查询数据库,若量很大,流量打在数据库,会造成压力。若缓存空值避免穿透,量大需要缓存大量的key,若空值过期,造成不一致情况,故不推荐。另外一种用hashMap存储,但是key值量大,会占用内存飙升,也不建议。推荐使用 Bloom Filter,节省空间,也是当前主流做法
2、判断用户是否是刷单用户,是否在黑名单池内。如1一亿 个垃圾 email ,5kw+黑名单池。存数据库耗空间,查询速度慢且高频查询。哈希表查询效率O(1),哈希表的做法:首先,哈希函数将一个email地址映射成8字节信息指纹;考虑到哈希表存储效率通常小于50%(哈希冲突);因此消耗的内存:8 * 2 * 1亿 字节 = 1.6G 内存。非常大,故布隆过滤器(Bloom Filter)就解决此类问题
3、RocketMQ通过布隆过滤器防止消息重复消费:防止RocketMQ消息重复消费,我们发送消息时可以对每个消息设置唯一的key,然后在消费者处利用布隆过滤器对消息的key检索,如果存在则说明消息已经消费过,不消费。不存在则进行消费,然后插入布隆过滤器
二、布隆过滤器Bloom Filter原理和数据结构
数据结构:
布隆过滤器是由很长的二进制向量(即可以理解成很长的0、1数组)与一系列随机映射函数(Hash函数)构成。BloomFilter 是由一个固定大小的二进制向量或者位图(bitmap)和一系列映射函数组成的。在初始状态时,对于长度为 m 的位数组,它的所有位都被置为0。因此我们可以将布隆过滤器理解成下图这种很长的一个二进制数组:
优点:布隆过滤器的数据结构仅需要存储“0”或“1”,因此所占用内存极少
检索和插入原理:
1、Hash函数:把输入值通过特定方式(hash函数) 处理后 生成一个值,这个值等同于存放数据的地址
2、插入(增加)数据的原理:Hash函数是 y=x²&(len-1),这里y是指最终在布隆过滤器的数据结构(二进制数组)中存放的下标位置,x指我们传入的值,len指数组的长度。那么如果当数组长度为100(举个例子,实际上数组长度是很长的),传入的值为5,则我们通过Hash函数得到的下标为25。那么此时我们便将下标25的值从0标为1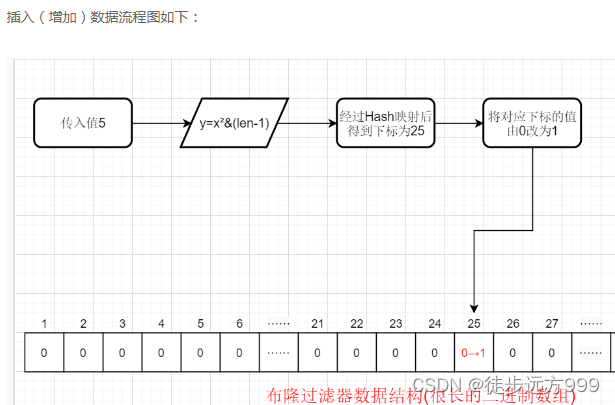
3、检索原理:当我们下次再输入这个值的时候,我们会得到当前数组对应下标的值为1,说明我们有这个数字
误判原理:
Hash函数F(key)得到的结果的作为地址去存放当前的value值,但是却发现算出来的地址上已经被占用了,这就是所谓的hash冲突
在经过上述流程后,我们数组下标为25的值是1。此时我们传入一个值25,那么通过我们上述举例的Hash算法计算后得到的数组下标值也为25,那么此时布隆过滤器是不是就会认为值25是存在的!但是实际上是因为5和25经过Hash映射后得到同一个地址,导致了误判!
误判率:
布隆过滤器会有一定误判率。当一个不存在的元素,对应的一系列映射后的地址的值为1,即出现误判
布隆过滤器参数:
布隆过滤器的时候能通过设置两个参数:①预期数据量 ②误判率期望值。我们可以通过设置“误判率期望值”来达到我们能接受的误判率
三、布隆过滤器代码实现
布隆过滤器-使用原理和场景
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/311776.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
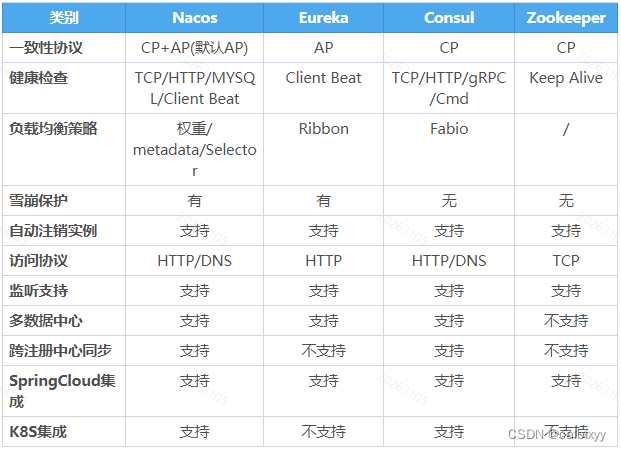
SpringCloud(H版alibaba)框架开发教程,使用eureka,zookeeper,consul,nacos做注册中心——附源码(1)
源码地址:https://gitee.com/jackXUYY/springboot-example
创建订单服务,支付服务,公共api服务(共用的实体),eureka服务
1.cloud-consumer-order80 2.cloud-provider-payment8001 3.cloud-api-commons 4.…

Java多线程<三>常见的多线程设计模式
多线程的设计模式
两阶段线程终止 park方法 interrupted() 会让他失效。 使用volatile关键字进行改写 单例模式 双锁检测
保护性暂停 实现1:
package threadBase.model;/*** author: Zekun Fu* date: 2022/5/29 19:01* Description:* 保护性暂停,* …

Mysql实时数据同步工具Alibaba Canal 使用
目录 Mysql实时数据同步工具Alibaba Canal 使用Canal是什么?工作原理重要版本更新说明 环境准备安装Canalwindow Java : Canal Client 集成依赖编码 工作流程开启原生MQRocketMQ 安装部署 canal配置说明1.1 canal.properties常用配置介绍:2.common参数定…

2023-12-20 LeetCode每日一题(判别首字母缩略词)
2023-12-20每日一题
一、题目编号
2828. 判别首字母缩略词二、题目链接
点击跳转到题目位置
三、题目描述
给你一个字符串数组 words 和一个字符串 s ,请你判断 s 是不是 words 的 首字母缩略词 。
如果可以按顺序串联 words 中每个字符串的第一个字符形成字符…

【深度学习】Normalizing flow原理推导+Pytorch实现
1、前言 N o r m a l i z i n g f l o w \boxed{Normalizing \hspace{0.1cm} flow} Normalizingflow,流模型,一种能够与目前流行的生成模型—— G A N 、 V A E \boxed{\mathbf{GAN、VAE}} GAN、VAE相媲美的模型。其也是一个生成模型,可是…

ZYNQ 7020 之 FPGA知识点重塑笔记一——串口通信
目录
一:串口通信简介
二:三种常见的数据通信方式—RS232串口通信
2.1 实验任务
2.2 串口接收模块的设计
2.2.1 代码设计
2.3 串口发送模块的设计
2.3.1 代码设计
2.4 顶层模块编写
2.4.1 代码设计
2.4.2 仿真验证代码
2.4.3 仿真结果
2.4.4…
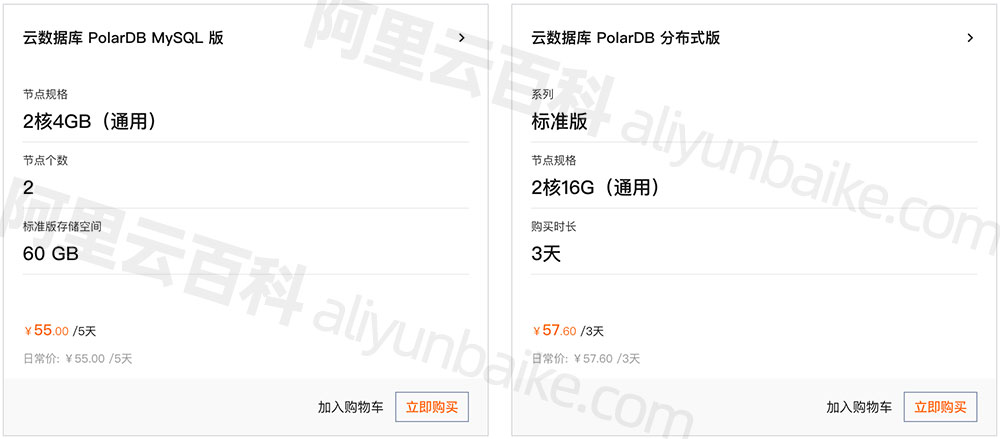
阿里云PolarDB数据库优惠价格表11元一天起
阿里云数据库PolarDB租用价格表,云数据库PolarDB MySQL版2核4GB(通用)、2个节点、60 GB存储空间55元5天,云数据库 PolarDB 分布式版标准版2核16G(通用)57.6元3天,阿里云百科aliyunbaike.com分享…

uni-app js语法
锋哥原创的uni-app视频教程:
2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中..._哔哩哔哩_bilibili2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中...共计23条视频,包括:第1讲 uni…
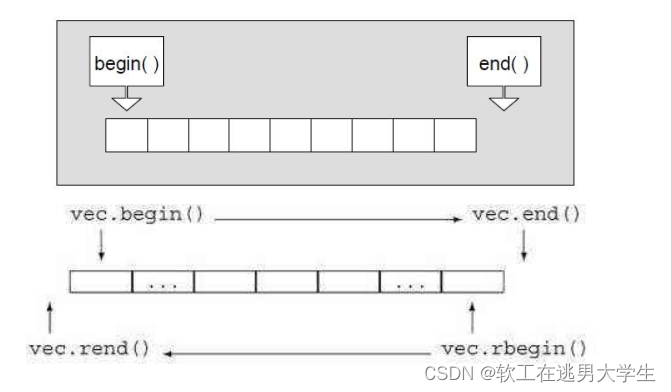
Lesson 06 vector类(上)
C:渴望力量吗,少年? 文章目录 一、vector是什么?二、vector的使用1. 构造函数2. vector iterator3. vector 空间增长问题4. vector增删查改 三、vector实际使用 一、vector是什么? vector是表示可变大小数组的序列容器…
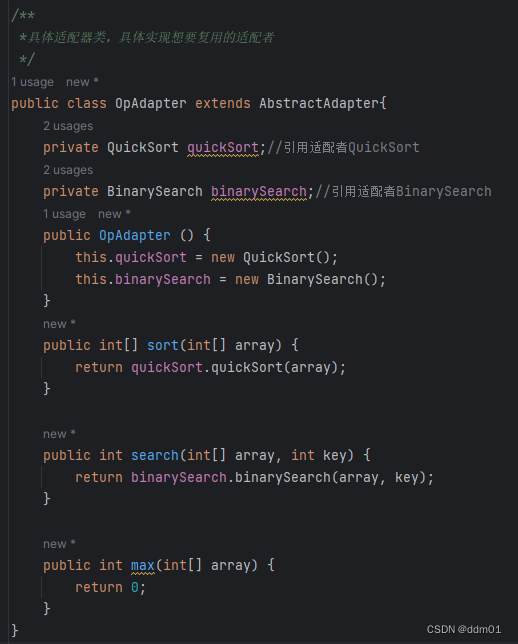
设计模式——适配器模式(Adapter Pattern)
概述 适配器模式可以将一个类的接口和另一个类的接口匹配起来,而无须修改原来的适配者接口和抽象目标类接口。适配器模式(Adapter Pattern):将一个接口转换成客户希望的另一个接口,使接口不兼容的那些类可以一起工作,其别名为包装…

UE蓝图 RPG动作游戏(一) day15
角色状态制作
制作角色动画混合空间
创建一个动混合空间 添加动作在混合空间
动画蓝图
创建一个动画蓝图 先使用混合空间进行移动,后续优化后再使用状态机 编写垂直水平速度逻辑初始化,获取到此动画的角色组件 获取Horizontal与Vertical的速度逻辑 …