文章摘要
随着互联网的普及和发展,大量的新闻信息涌入我们的生活。然而,这些新闻信息的质量参差不齐,有些甚至包含虚假或误导性的内容。因此,对新闻进行有效的分类和筛选,以便用户能够快速获取真实、有价值的信息,成为了一个重要的课题。在这个背景下,机器学习技术应运而生,其中贝叶斯估计作为一种强大的概率推断方法,在新闻分类任务中发挥着重要作用。
在本篇文章中,使用搜狗实验室提供的新闻数据集,并且通过贝叶斯估计来对整理后的新闻数据集进行分类任务,大体流程如下:1、新闻数据集处理。2、文本分词。3、去停用词。4、构建文本特征。5、基于贝叶斯算法来完成最终的分类任务。
另外,本文除了列出了核心代码外,还给出了可执行代码以及所用到的数据源,具体看附录。
知识准备
1.朴素贝叶斯算法
输入:训练数据,其中
,是第
个样本的第
个特征,
,
是第
个特征可能取的第
个值,;;实例
输出:实例的分类,其中
代表分类的种类有多少。
为了避免极大似然估计中概率值为0的那种情况,这里引入了常数。具体地,条件概率的贝叶斯估计是
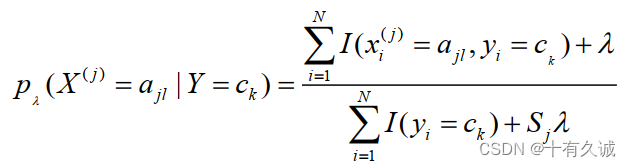
式中。等价于在随机变量各个取值的频数上赋予一个正数
。上式为一种概率分布。取常数
时,这是称为拉普拉斯平滑。显然对任何
,有
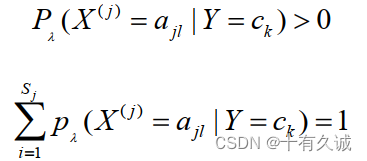
同样,先验概率的贝叶斯估计是

2.停用词(库)
这里我们得先考虑一个问题,一篇文章是什么主题应该是由其内容中的一些关键词来决定的,比如这里的‘车展’,‘跑车’,‘发动机’等,这些词我们一看就知道跟汽车相关的。但是另一类词,‘今天’,‘在’,‘3月份’等,这些词给我们的感觉好像既可以在汽车相关的文章中使用,也可以在其他类型的文章使用,就把它们称作停用词,也就是我们需要过滤的目标。在data文件夹中,给出了多个停用词库,在源码中,我使用了stopwords.txt中停用词。可以通过以下代码来读取停用词。
# 读取停用词库
#如果没有词表,也可以基于词频统计,词频越高的成为停用词的概率就越大
stopwords=pd.read_csv("stopwords.txt",index_col=False,sep="\t",quoting=3,names=['stopword'], encoding='utf-8')
stopwords.head(20)
实验步骤
1.读取数据源
# 给出属性,这里使用的是基于内容来进行分类(加上主题分类会更简单些,这里为了增加难点使用内容分类)
df_news = pd.read_table('./data/data.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna()
#查看前5条新闻
df_news.head()
# df_news.tail() 
输出结果如上图所示
标签解释:
Category:当前新闻所属的类别,一会我们要进行分别任务,这就是标签了。
Theme:新闻的主题,这个咱们先暂时不用,大家在练习的时候也可以把它当作特征。
URL:爬取的界面的链接,方便检验爬取数据是不是完整的,这个咱们暂时也不需要。
Content:新闻的内容,这些就是一篇文章了,里面的内容还是很丰富的。
2.中文分词
#用于保存结果
content_S = []
for line in content:
# line为每一篇文章 current_segment = jieba.lcut(line) #对每一篇文章进行分词 if len(current_segment) > 1 and current_segment != '\r\n': #换行符
# 该篇文章词的个数>1,而且不是简单的换行才保留下来 content_S.append(current_segment) #保存分词的结果 用pandas展示分词结果
df_content=pd.DataFrame({'content_S':content_S}) #专门展示分词后的结果
df_content.head() 前五条新闻分词结果

查看第1000条新闻分词结果
df_content.iloc[1000] ![]()
3.去停用词
def drop_stopwords(contents,stopwords): contents_clean = [] all_words = [] for line in contents: line_clean = [] for word in line: if word in stopwords:
# 如果这个词不在停用词当中,就保留这个词 continue line_clean.append(word) all_words.append(str(word)) contents_clean.append(line_clean) return contents_clean,all_words contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
contents_clean,all_words = drop_stopwords(contents,stopwords) #df_content.content_S.isin(stopwords.stopword)
#df_content=df_content[~df_content.content_S.isin(stopwords.stopword)]
#df_content.head() 用pandas过滤掉停用词的结果
df_content=pd.DataFrame({'contents_clean':contents_clean})
df_content.head() 前五天新闻过滤掉停用词的结果

4.构建文本特征
一些要考虑的问题
这里我们需要到一些问题:
问题1:特征提取要考虑到词与词之间的顺序,而不是只考虑了这个词在这句话当中出现的次数。
问题2:一般语料库的词是非常多的,比如说语料库向量长度4000;那对于每句话,也要有对应的4000维向量,但是里面很多词是没有出现的,所以4000维的向量里面很多值为0,也就是每句话对应的词向量是一个“稀疏向量”。
问题3:同义词也被认为了不同的词,但很多时候同义词在句子的意思是相同的。
用一个例子理解
from sklearn.feature_extraction.text import CountVectorizer
# 拿这四个词作为例子去理解这个计算思路
texts=["dog cat fish","dog cat cat","fish bird", 'bird'] #为了简单期间,这里4句话就当做4篇文章
cv = CountVectorizer() #词频统计
cv_fit=cv.fit_transform(texts) #转换数据 # 获得语料库
print(cv. get_feature_names_out())
# 得到每句话在每个词中出现的次数
print(cv_fit.toarray())
print(cv_fit.toarray().sum(axis=0)) 
取词频大的词
from sklearn.feature_extraction.text import CountVectorizer vec = CountVectorizer(analyzer='word',lowercase = False)
feature = vec.fit_transform(words)
feature.shape
# 结果:(3750, 85093)解释:3750为文章数;85093为语料库;每篇文章对应85093维的向量 只取词频前4000的
from sklearn.feature_extraction.text import CountVectorizer #只统计频率前4000的词,要不每篇文章对应的向量太大了
#这个操作之前需要先过滤掉停用词,要不然这里得到的都是没有意义的停用词了
vec = CountVectorizer(analyzer='word', max_features=4000, lowercase = False)
feature = vec.fit_transform(words)
feature.shape
# 结果:(3750, 4000)解释:3750为文章数,4000为给文章词频最多的数 5.通过贝叶斯预测结果
在贝叶斯模型中,选择了MultinomialNB,这里它额外做了一些平滑处理主要目的就在我们求解先验概率和条件概率的时候避免其值为0。
from sklearn.naive_bayes import MultinomialNB #贝叶斯模型
classifier = MultinomialNB()
# y_train为标签
classifier.fit(feature, y_train)
获得准确率
# 查看测试集的准确率
classifier.score(vec.transform(test_words), y_test)
结果准确率为:0.804参考文献
- 李航。 (2019). 统计学习方法[M]. 北京: 清华大学出版社。
- 凌能祥,&李声闻。 (2014). 数理统计[M]. 北京: 中国科学技术大学出版社。
附录(代码)
本文用到的所有可执行代码和数据源在下面链接给出
Machine_learning: 机器学习用到的方法