目录
一、概述
1.1 综合的分类
1.2 逻辑综合的基本架构
1.3 逻辑综合的内部流程
1.3.1 RTL代码转译(Translation)
1.3.2 逻辑级优化(Optimization)
1.3.3 工艺映射(Mapping)
二、优化策略
2.1 资源共享
2.2 子表达式共享
2.3 时分复用
2.4 展平化与结构化
2.4.1 展平化(Flattening,亦称扁平化)
2.4.2 结构化(Structuring,亦称层次化)
2.5 逻辑重建
2.6 门级优化
2.7 针对建立-保持时间的策略
一、概述
综合是指自动将上一个设计层次的数据转换成下一个层次的设计数据,可大大减少人工消耗,提高设计效率、准确度和复用性。
1.1 综合的分类
- 行为综合:将基于HDL描述的行为级代码自动转换为RTL级代码,只考虑逻辑不考虑延时,发展缓慢。
- 逻辑综合:将基于HDL描述的RTL级代码自动转换为门级网表,所用连线延时是理论预估值,普遍使用(本节之后所称“综合”均指“逻辑综合”)。
- 物理综合:将基于HDL描述的RTL级代码自动转换为门级网表,所用连线延时是布局布线后提取的真实值,运算量巨大。
1.2 逻辑综合的基本架构
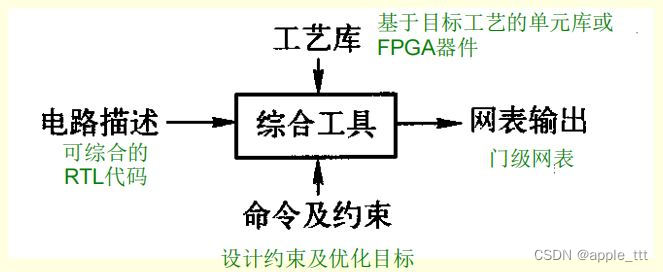
综合优化目标
- 速度:在不出现时序违例的前提下关键路径延时最短
- 面积:在满足时序的条件下面积最小
- 功耗:在满足时序的条件下功耗最低
常用逻辑综合工具
- Synopsys的Design Compiler(DC)
- Cadence的RTL Compiler、BuildGates
1.3 逻辑综合的内部流程
1.3.1 RTL代码转译(Translation)
基于通用元件库(如DC 的Design Ware),将RTL描述转换为门级布尔描述(DC用 Gtech通用网表表征),效果主要取决于RTL编码质量。
1.3.2 逻辑级优化(Optimization)
对布尔函数进行逻辑结构上的优化,效果主要取决于EDA工具。
1.3.3 工艺映射(Mapping)
基于工艺库和约束条件,将优化好的布尔函数转换成实际的门级逻辑电路,并完成门级优化。
二、优化策略
2.1 资源共享
不同的逻辑尽可能共享相同的代码、表达式或元件,以减少芯片的面积,但可能会降低速度。比如下面的这个例子:
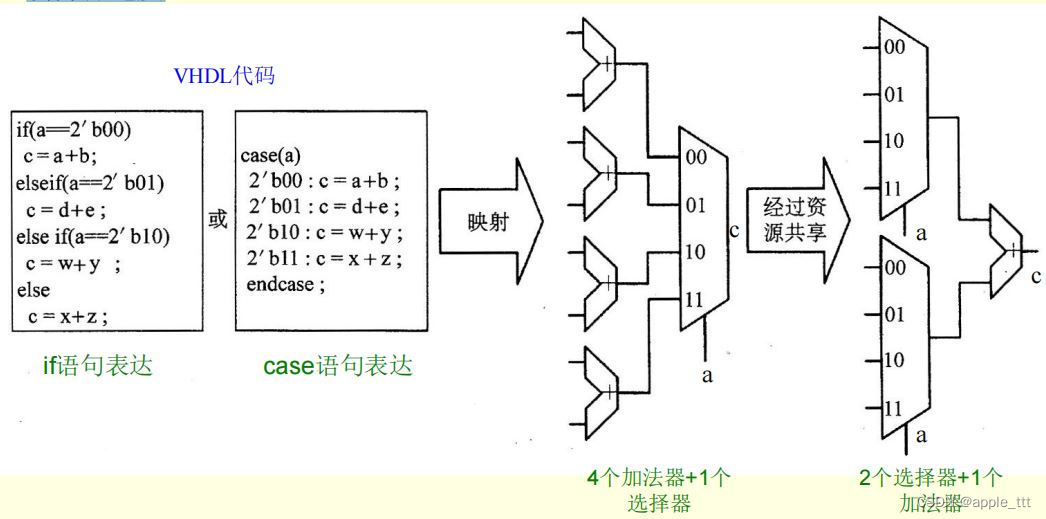
同样的逻辑功能,资源共享后元件数从5个减少到3个,而且选择器的复杂度低于加法器,从而显著减小了芯片面积,而延时没有变化。事实上,在RTL代码设计时也可以使用这样的技巧。
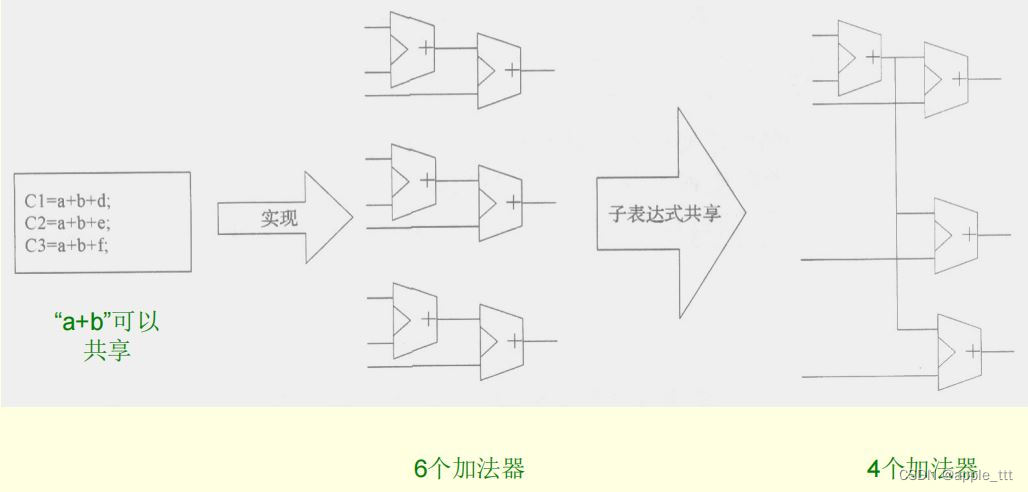
2.2 子表达式共享
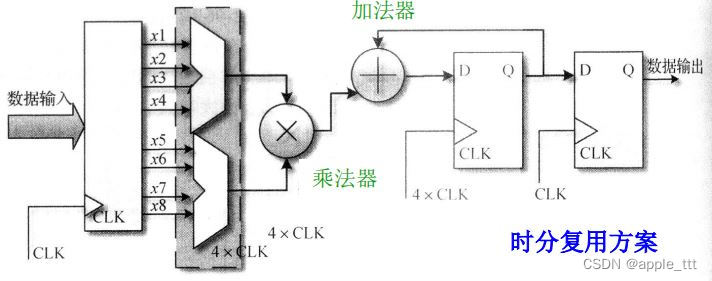
2.3 时分复用
原方案:需要4个乘法器、1个加法器、2组寄存器
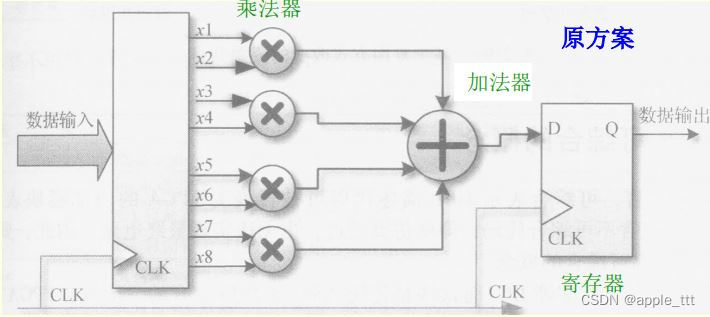
时分复用方案:只需要1个乘法器、1个加法器、2个多路选择器和3组寄存器。如维持原有延时不变,需将时钟频率增加到原来的四倍
2.4 展平化与结构化
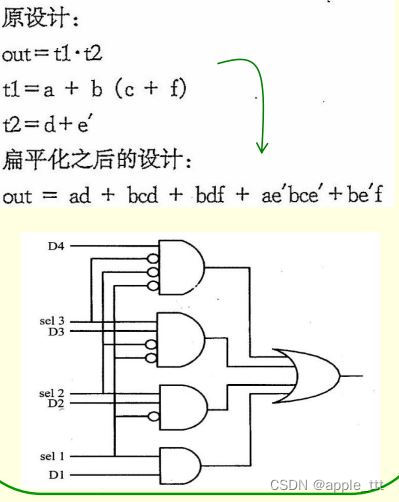
2.4.1 展平化(Flattening,亦称扁平化)
将设计中所有的中间变量和结构转换为只有两级逻辑的乘积和形式,适用于随机逻辑(如指令译码)的优化。
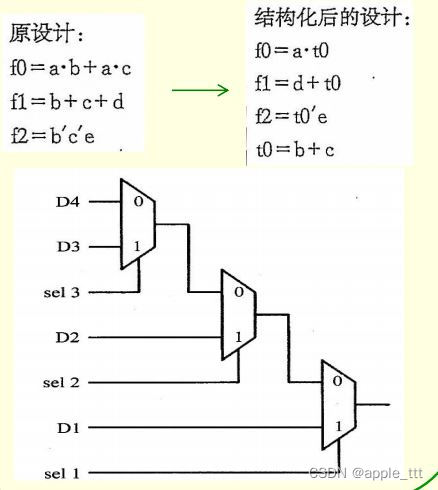
2.4.2 结构化(Structuring,亦称层次化)
人为地给设计增加中间变量和逻辑结构,适应于本身就有很强结构性的单元(如加法器、乘法器和算术单元等)
2.5 逻辑重建
在保证逻辑功能不变的前提下,重新构造布尔关系,来改善性能。例如,重排延时不同的逻辑单元的前后位置,以减少关键路径的延时;减少内部高翻转率(单位时间内电平变化次数)节点数量,从而降低动态功耗。

2.6 门级优化
2.7 针对建立-保持时间的策略
相对于布局布线后的网表,在综合出的网表中,路径的延迟总是偏短,故综合时应选择最慢情况来进行优化。因此
- 如可供综合选用的单元库有慢库(slow,延时最长Max,最坏情况WC(Worst Case))和快库(fast,延时最短Min,最好情况BC(Best Case)),则选用慢库
- 相对于保持时间(hold time),建立时间(set time)违例在综合时更容易出现,因此优化主要针对建立时间而非保持时间
- 综合时消除保持时间违例会让面积急剧增大,而这种违例往往在布局布线后自动消失,因此在综合阶段可暂不消除保持时间违例。