
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点 这里让它成为你的技术宝库!
大家好,我是张晋涛。
前段时间看到了很多关于数据库要不要部署在 Kubernetes 之上的讨论,这些年,这种讨论时有发生。
这个事情并没有绝对的定论,因为每个人都是基于自己的认知,或基于自己过往的经验在进行分析、讨论,每个人的出发点不同,自然得到的结论也是不一样的。
2021 年的时候,我曾经做过一次线上分享: Redis 容器化技术选型,K8S 并非唯一 | MoeLove 在那次分享中,我主要是聊了一些容器化的技术手段,Redis 自身的一些特性,以及基于不同业务场景或者需求时,可以选用的技术方案。
今天这篇,我想再聊聊 Redis 在 Serverless 场景下的应用。
Redis 的特性及应用场景
Redis 是一个开源的,基于内存的数据存储引擎。它非常简洁,但功能全面实用、灵活多变,常被称之为数据库领域的 “瑞士军刀”,被数百万开发者用作数据库、缓存、流引擎和消息代理。

Redis 的主要特点
- 速度快:由于它是一个内存型数据库,数据的读取写入都直接通过内存完成,避免了读写硬盘而可能造成的延迟问题。即使在高频的读写场景下也可以有非常不错的表现;
- 适用场景丰富:Redis 有着丰富的数据类型,可以灵活的用于各类场景中(下文将详细介绍);
- 上手成本低:Redis 的操作指令和使用是非常简单的,包括它的通信协议 RESP 也设计的非常简洁,感兴趣的小伙伴可以参考我之前的文章 理解 Redis 的 RESP 协议 | MoeLove;
- 支持持久化:尽管 Redis 是内存型数据库,但是考虑到实际的应用场景,如果能对数据进行持久化,那么在遇到故障或者数据恢复时则会方便很多。Redis 支持通过 RDB(内存数据快照) 和 AOF (记录 Server 端的命令到文件)的方式进行持久化;
- 生态丰富:Redis 有着 50+ 种语言的 Client library,覆盖了所有的主流编程语言。同时也有很多 CLI 和 GUI 的客户端工具可以使用;
Redis 支持的数据类型及适用场景
前面提到 Redis 有着非常丰富的数据类型,每种数据类型都有特定的应用场景。
- 字符串(string):字符串是 Redis 最基本的数据类型,字符串类型支持的常用命令包括 SET、GET 等;
- 散列(hash):散列表是一种 K-V 型的数据结构,散列类型可以存储多个键值对,并且支持嵌套数据结构。散列类型支持的常用命令包括 HSET、HGET 等;
- 列表(list):列表在每个节点存储了一个字符串,可以在列表的两端进行元素的添加或删除操作。列表类型支持的常用命令包括 LPUSH、RPUSH、LPOP 和 RPOP 等;
- 集合(set):集合是一个不允许有重复元素的无序数据结构,支持取交集、并集和差集等常用操作。集合类型支持的常用命令包括 SADD、SMEMBERS 等;
- 有序集合(zset):有序集合是一个可以排序的集合,每个元素都有一个 score,支持根据 score 进行排序和范围查找。有序集合类型支持的常用命令包括 ZADD、ZRANGE、ZREVRANK 和 ZSCORE 等;
- 位图(bitmap):位图不是个实际的数据类型,是一个由二进制位组成的数组结构,支持位运算操作。位图常用于统计、记录用户的在线状态等场景;
- 位域(bitfield):位域也是一种用于操作二进制位的数据结构和命令集合。允许用户以比特位为单位对字符串进行操作,并且支持多种位操作,例如获取、设置、计数等。位域也可以用于存储和操作布尔值、整数等数据类型;
- HyperLogLog:HyperLogLog 是一种基数算法,用于估算一个集合的基数。它采用的是随机化算法,并且空间复杂度很低。 HyperLogLog 可用于处理大量数据集的场景,例如网站的 UV 统计;
Redis 支持这么多的数据类型和用法,使得它常年稳居 K-V 型存储排行榜的榜首。以下是我新截图的排名:
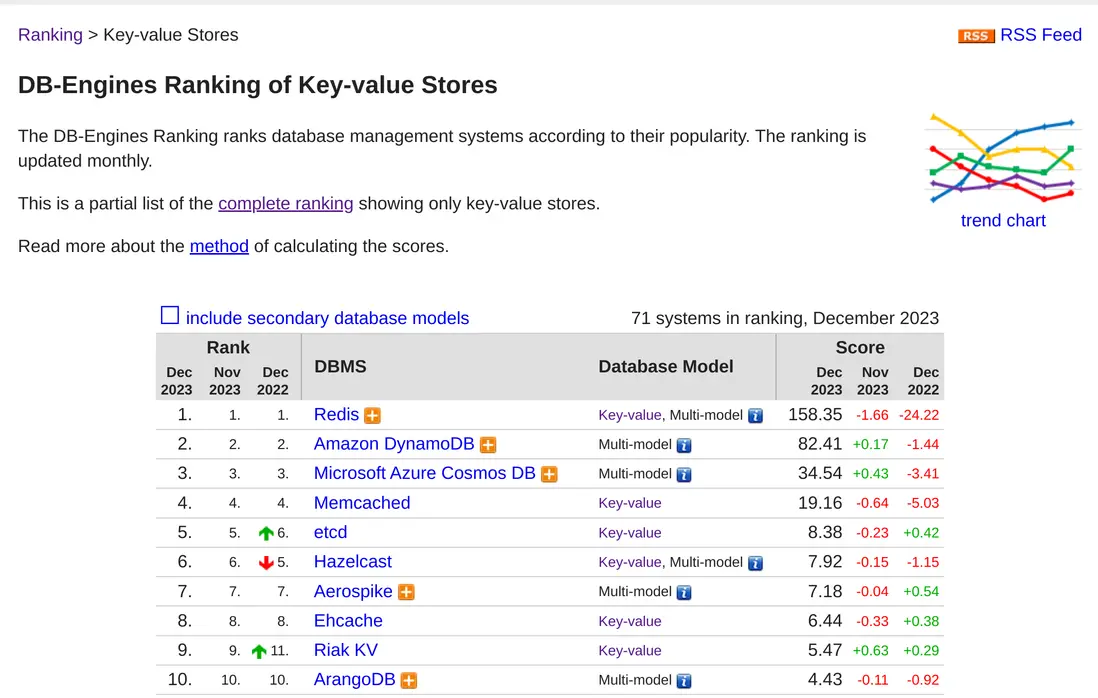
Redis 集群的架构
Redis 除了支持 master-replica 这种简单的主从模式外,也提供了 Cluster 模式。
Redis Cluster 是 Redis 数据库的分布式解决方案。它可以将数据分布在多台服务器上,从而提高 Redis 的可用性和性能。
Redis Cluster 采用了分片的方式来存储数据,将数据分散在多个节点上。每个节点都存储一部分数据,并且每个节点都知道其他节点的信息。这样,当一个节点宕机时,其他节点可以接管它的数据,保证 Redis 集群的可用性。
同时,由于 Redis Cluster 的这种特性,也使得它可以通过增加节点的方式来对集群的容量进行扩展,这解决了单实例或者主从模式下,Redis 受限于所在机器内存容量限制的不足。
并且每个节点仍然可以采用主从的模式,提高其整体的可用性。
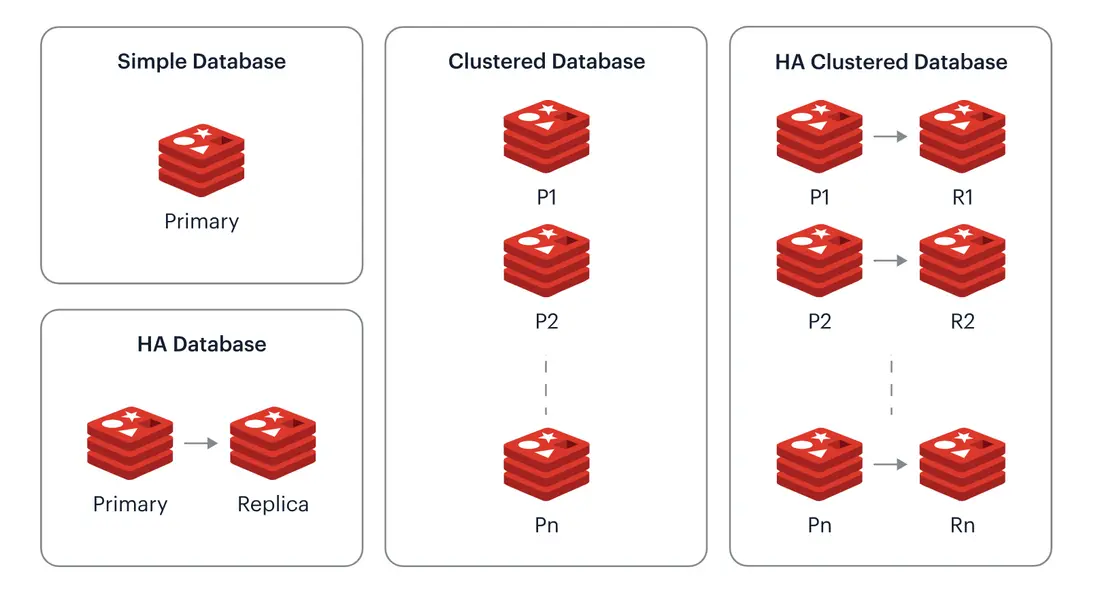
Serverless 化的 Redis 有何优势
前面简单的介绍了下 Redis 的主要特性和它的集群模式。我们会发现 Redis Cluster 有一个天然的优势 -- 它可以进行水平扩展,从而提升集群的整体容量。
在 Redis Cluster 出现之前,我们的大多数生产环境都是在使用 master-replica 这种主从模式。使用主从模式时候存在一些痛点,关于故障转移之类的我这篇文章中就不谈了,我主要谈下关于容量的部分。
在每次业务申请新上 Redis 主从集群的时候,第一件事情就是需要描述清楚业务场景,用途,以及预期的容量(或者预估的增长速度)。这样才能去找到合适的机器进行集群的部署。
在后续使用过程中,正常情况下会为数据设置 TTL 进行过期,但随着业务的发展,仍可能会导致集群容量逐步增加,当它快要达到容量的 80% 时候,就必须要扩容了。如果机器上尚有空余的内存,那么只需要修改 maxmemory 配置即可,但如果机器上内存容量不足,那只能进行集群的迁移了。到迁移时,同样涉及到了容量的规划,机器的采购等一系列繁琐的事情,苦不堪言。
那如果我们采用 Serverless 化的 Redis 能带来哪些优势呢?
无需选择实例大小
无论是使用物理机也好,或者在选择云厂商提供的数据库 / Redis 实例也罢,通常情况下都需要对容量有一个大致的评估,以及增速的评估,然后从一大堆的实例类型的列表中进行选择。
不同的实例类型则对应不同的内存容量,网络吞吐等,这需要耗费很多的时间,而且为了能在保障业务不受影响的同时优化成本,还需要专门对于不同类型的实例进行压测,看看是否能满足预期,最终才能确认选择哪个实例。
另外,业务的增长有时候会存在不确定性,一旦业务出现爆发式增长,有些平台不提供扩容能力,就只能迁移了。另一种情况是,一些平台只允许进行规格升级,不允许降级,这样在业务低峰期的时候,也就造成了浪费。
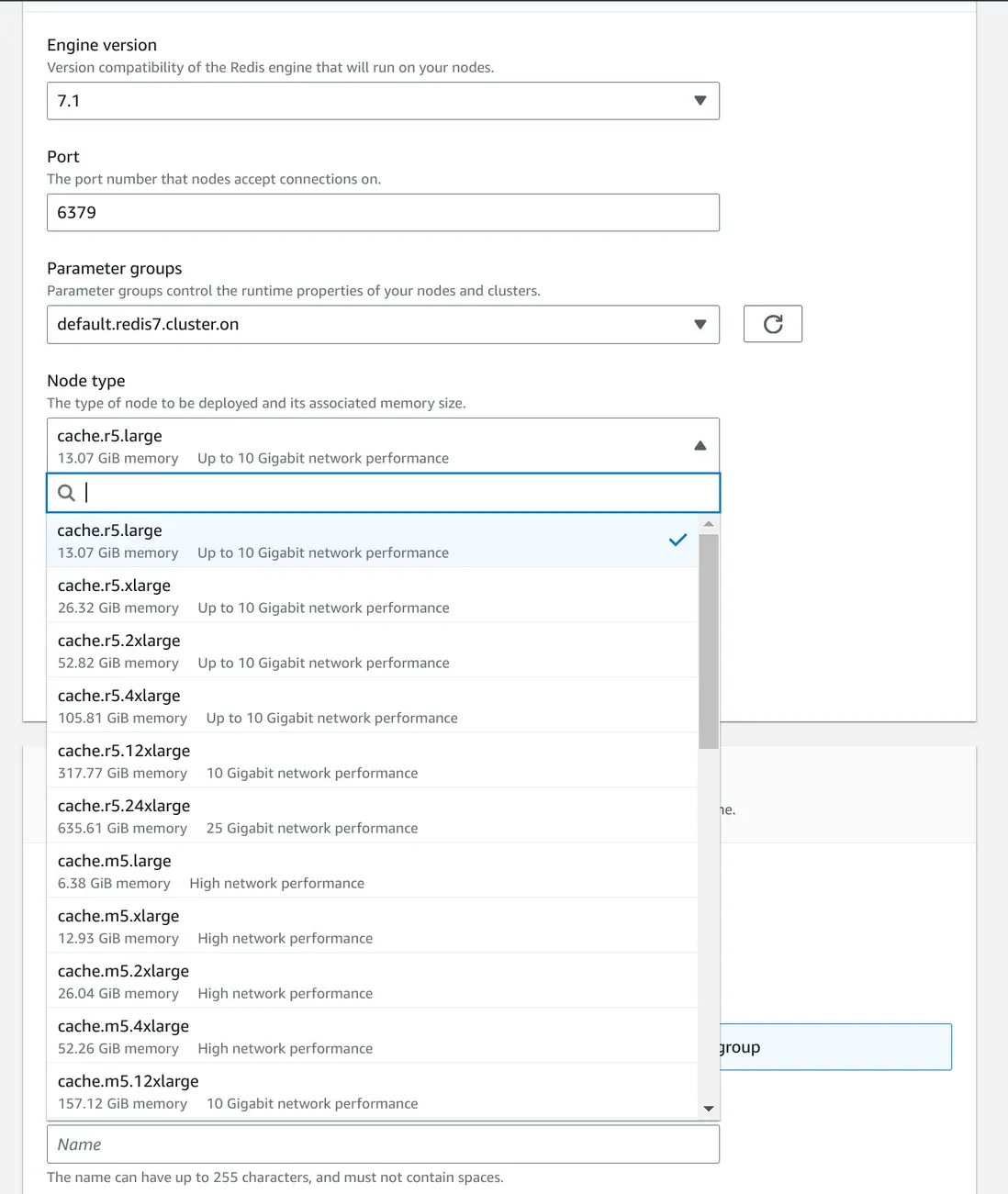
使用 Serverless Redis 就无需花时间去进行这种实例的选择了,它可以根据业务的实际情况,进行动态的水平、垂直伸缩,这就方便很多了。创建时候也只需要指定最基本的信息就足够了。
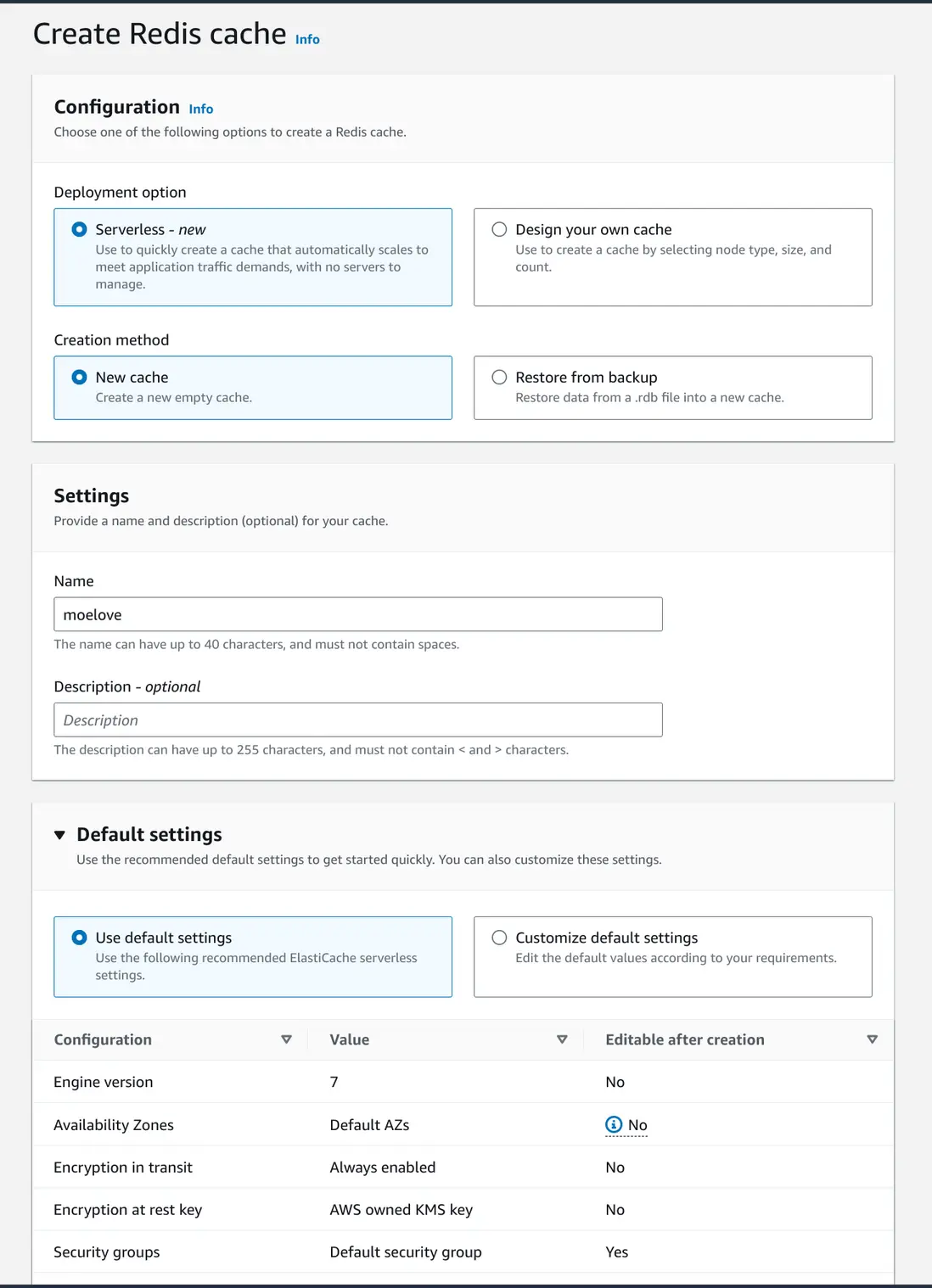
计费灵活
传统的固定实例类型的计费方式,通常都是直接按照选定的实例大小进行计费的。这种模式下,即使用量很少,也需要为尚未使用的资源进行付费。
但是在 Serverless 模式下,则只需要按用量进行付费即可。
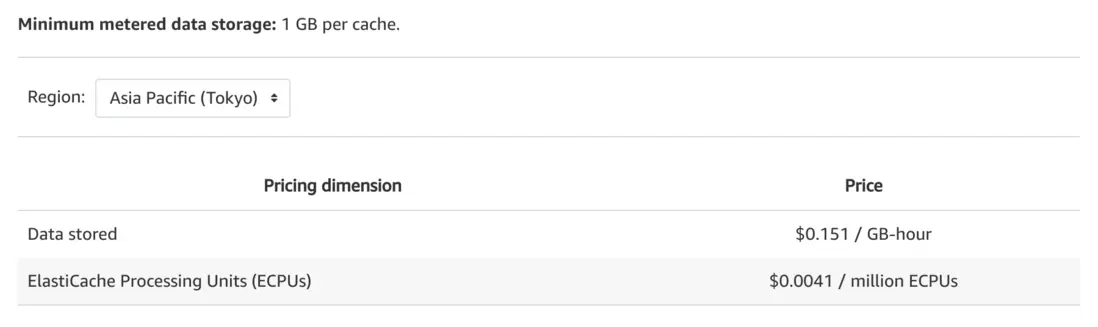
下图是亚马逊云科技 Amazon ElastiCache For Redis (Serverless 版)的计费模式,主要按照两个维度:
- 数据存储:按照数据存储的时间(GB - 小时)进行计费,最小单位是 1 GB;
- ECPUs:指的是 ElastiCache 处理消耗的计算单元,如果在空闲时间是这部分是不产生费用的;
弹性伸缩和高可用
在 Serverless 模式下,一旦发现某个实例的负载较高,或者健康状态异常,则可以立刻进行扩容,保证整体的可用性。而且也无需担心容量限制的问题。
同样的,如果负载较低,则可以进行缩容,来节约成本。
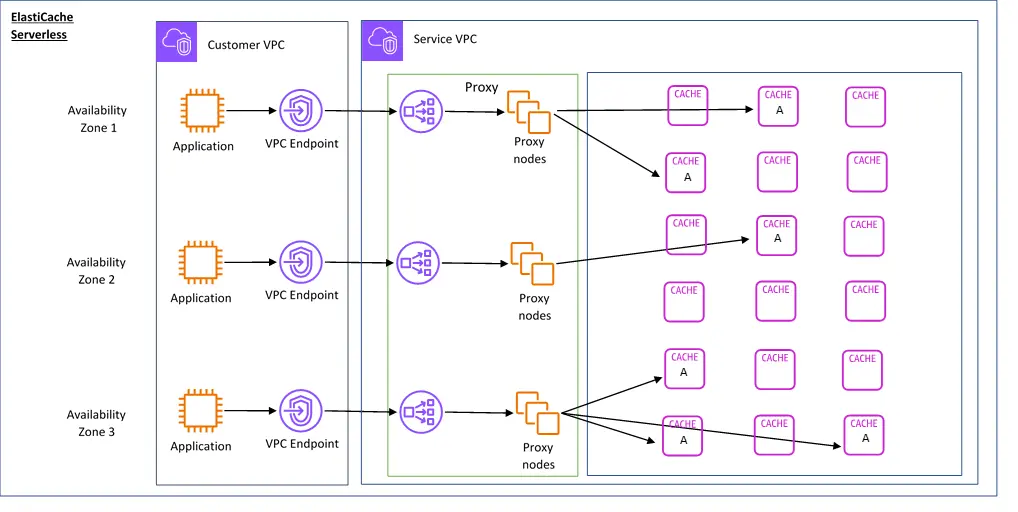
Amazon ElastiCache for Redis (Serverless)
最近在亚马逊云科技 Amazon re:Invent 大会上新推出一款 Amazon ElastiCache for Redis (Serverless 版) 服务,恰好就是我这篇文章中的实践。
我看到这个服务发布后,赶快进行了一些尝试,以下是我个人觉得的一些重点。
TLS 连接
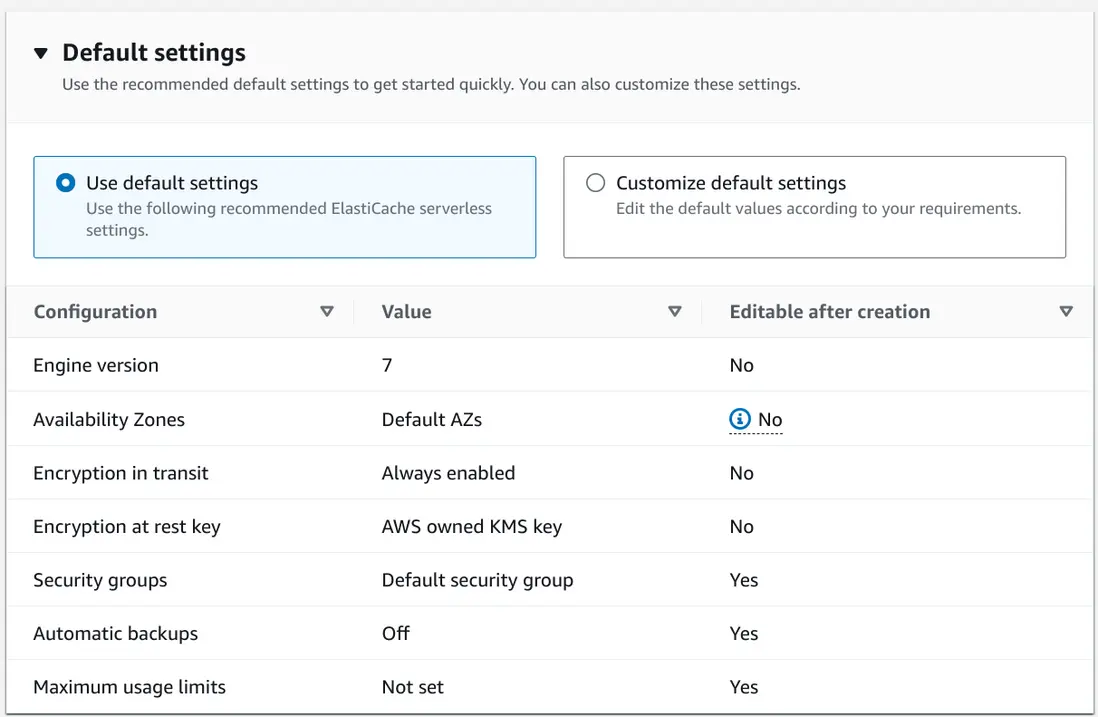
在亚马逊云科技亚马逊云科技上创建这个服务的时候,会有一些选项,其中我注意到有个 Encryption in transit 这个是默认开启的,并且在创建后也是不允许修改的。
这个特性表明在传输时需要使用 TLS 连接,来保证安全。在我们编译安装 redis-cli 工具的时候,就需要使用 make BUILD_TLS=yes 了,这样编译安装后,redis-cli 就可以使用 --tls 参数进行连接了,否则会出现连接失败的情况。
替代的方式可以使用 openssl s_client -connect IP:Port 这样进行连接。
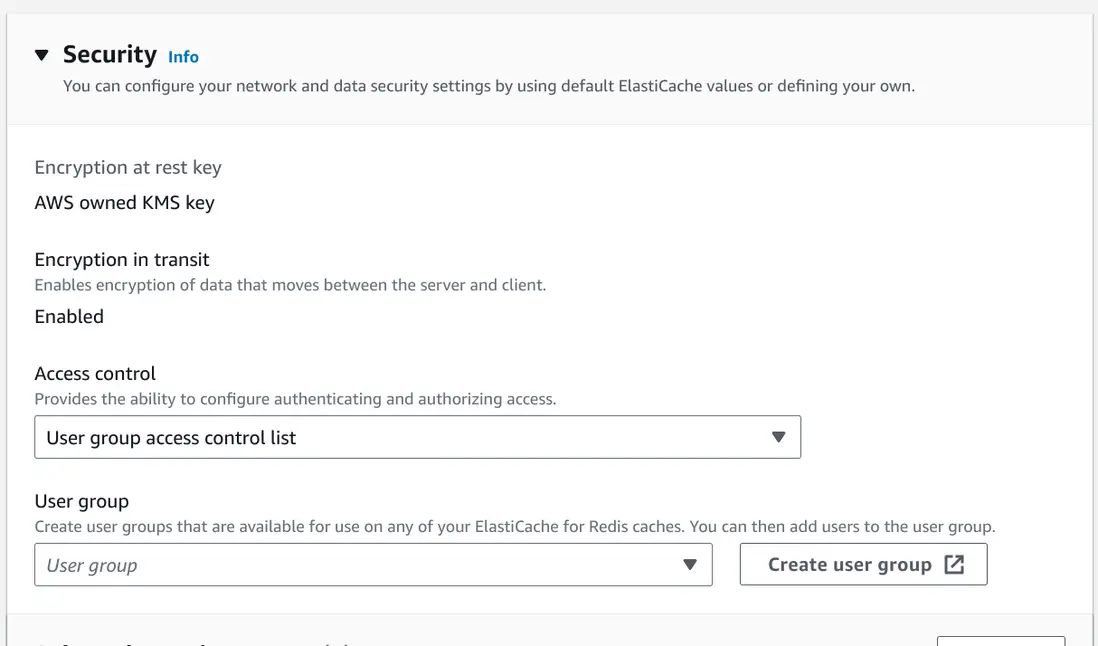
用户权限
在 Security groups 这里,默认是不开启用户认证的。可以在这里修改,创建新的 Security group,并创建用户,这样就可以开启用户认证了。
网络
默认创建后的 endpoint 是一个 VPC 的内网地址,如果需要在外部访问则需要创建 NAT Gateway,或者用其他方式进行转发。
我在相同 VPC 下开了另一个 EC2 实例跑了下 benchmark,效果如下:
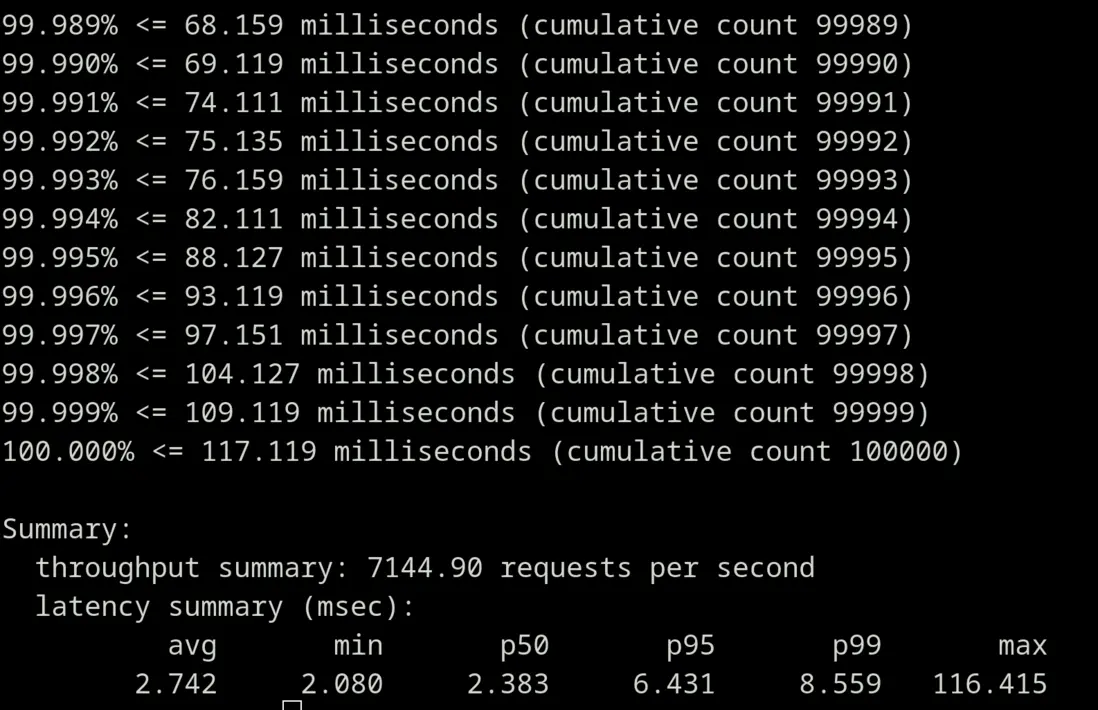
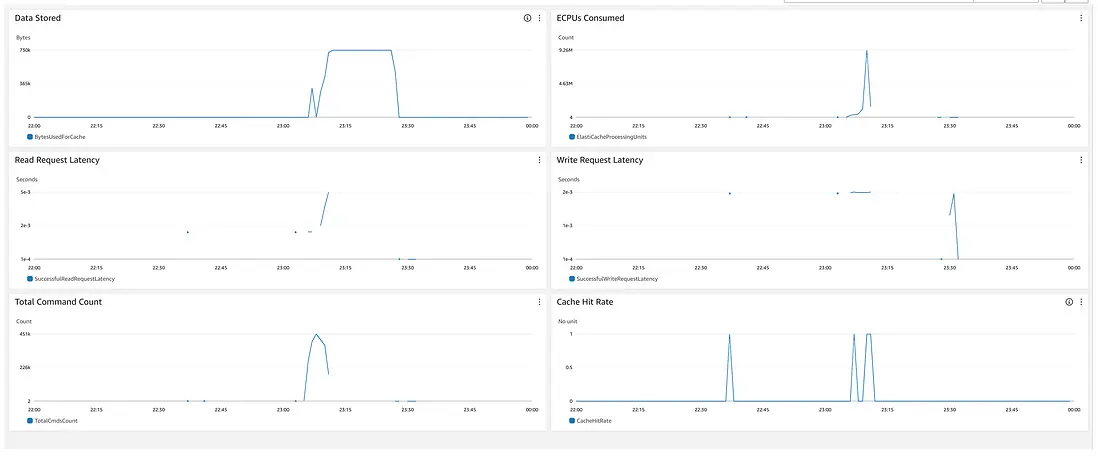
控制台上也有相关指标可以看到完整的 benchmark 后的资源消耗情况:
总结
由于 Redis Cluster 架构的灵活性,如果是将它用作 cache,使用 Serverless 的模式能带来不少的优势,提升整体服务的可用性,并且还可以减少最初容量规划上的耗时。
我觉得这将会是一种趋势。
本文参与了 「构」向云端 | 亚马逊云科技 x 思否 2023 re:Invent 构建者征文大赛,欢迎正在阅读的你也加入。 授权声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 Developer Centre,知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道
文章来源:
https://dev.amazoncloud.cn/column/article/65894c7779476548e3e05c04?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN





![[新版Hi3531DV200 性能强悍]](https://img-blog.csdnimg.cn/direct/12ce4f9a37b44281957b09e3c8943f5e.jpeg#pic_center)




