1 Vit简介
1.1 Vit的由来
ViT是2020年Google团队提出的将Transformer应用在图像分类的模型,虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究。
论文地址:https://arxiv.org/pdf/2010.11929.pdf
Visual Transformer (ViT) 出自于论文《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》,是基于Transformer的模型在视觉领域的开篇之作。ViT模型是基于Transformer Encoder模型的。
1.2 Vit如何工作
我们知道Transformer模型最开始是用于自然语言处理(NLP)领域的,NLP主要处理的是文本、句子、段落等,即序列数据。但是视觉领域处理的是图像数据,因此将Transformer模型应用到图像数据上面临着诸多挑战,理由如下:
-
与单词、句子、段落等文本数据不同,图像中包含更多的信息,并且是以像素值的形式呈现。
-
如果按照处理文本的方式来处理图像,即逐像素处理的话,即使是目前的硬件条件也很难。
-
Transformer缺少CNNs的归纳偏差,比如平移不变性和局部受限感受野。
-
CNNs是通过相似的卷积操作来提取特征,随着模型层数的加深,感受野也会逐步增加。但是由于Transformer的本质,其在计算量上会比CNNs更大。
-
Transformer无法直接用于处理基于网格的数据,比如图像数据。
为了解决上述问题,Google的研究团队提出了ViT模型,它的本质其实也很简单,既然Transformer只能处理序列数据,那么我们就把图像数据转换成序列数据就可以了呗。下面来看下ViT是如何做的。
1.3 ViT模型架构
我们先结合下面的动图来粗略地分析一下ViT的工作流程,如下:
-
将一张图片分成patches
-
将patches铺平
-
将铺平后的patches的线性映射到更低维的空间
-
添加位置embedding编码信息
-
将图像序列数据送入标准Transformer encoder中去
-
在较大的数据集上预训练
-
在下游数据集上微调用于图像分类

模型由三个模块组成:
- Linear Projection of Flattened Patches(Embedding层)
- Transformer Encoder
- MLP Head(最终用于分类的层结构)

Embedding层
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim],如下图,token0-9对应的都是向量,以ViT-B/16为例,每个token向量长度为768。

对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。如下图所示,首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到196个Patches。接着通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(后面都直接称为token)。[16, 16, 3] -> [768]
在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
Transformer Encoder
Transformer Encoder其实就是重复堆叠Encoder Block L次,主要由Layer Norm、Multi-Head Attention、Dropout和MLP Block几部分组成。


MLP Head
上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。

2 ViT工作原理
我们将上图展示的过程近一步分解为6步,接下来一步一步地来解析它的原理。如下图:

2.1 步骤1、将图片转换成patches序列
这一步很关键,为了让Transformer能够处理图像数据,第一步必须先将图像数据转换成序列数据,但是怎么做呢?假如我们有一张图片,patch大小为
,那么我们可以创建
个图像patches,可以表示为
,其中
,
就是序列的长度,类似一个句子中单词的个数。在上面的图中,可以看到图片被分为了9个patches。
2.2 步骤2、将Patches铺平
在原论文中,作者选用的patch大小为16,那么一个patch的shape为(3,16,16),维度为3,将它铺平之后大小为3x16x16=768。即一个patch变为长度为768的向量。不过这看起来还是有点大,此时可以使用加一个Linear transformation,即添加一个线性映射层,将patch的维度映射到我们指定的embedding的维度,这样就和NLP中的词向量类似了。
2.3 步骤3、添加Position embedding
与CNNs不同,此时模型并不知道序列数据中的patches的位置信息。所以这些patches必须先追加一个位置信息,也就是图中的带数字的向量。实验表明,不同的位置编码embedding对最终的结果影响不大,在Transformer原论文中使用的是固定位置编码,在ViT中使用的可学习的位置embedding 向量,将它们加到对应的输出patch embeddings上。
2.4 步骤4、添加class token
在输入到Transformer Encoder之前,还需要添加一个特殊的class token,这一点主要是借鉴了BERT模型。添加这个class token的目的是因为,ViT模型将这个class token在Transformer Encoder的输出当做是模型对输入图片的编码特征,用于后续输入MLP模块中与图片label进行loss计算。
2.5 步骤5、输入Transformer Encoder
将patch embedding和class token拼接起来输入标准的Transformer Encoder中。 Transformer Encoder其实就是重复堆叠Encoder Block L次,主要由Layer Norm、Multi-Head Attention、Dropout和MLP Block几部分组成。
2.6 步骤6、分类
注意Transformer Encoder的输出其实也是一个序列,但是在ViT模型中只使用了class token的输出,将其送入MLP模块中,去输出最终的分类结果。
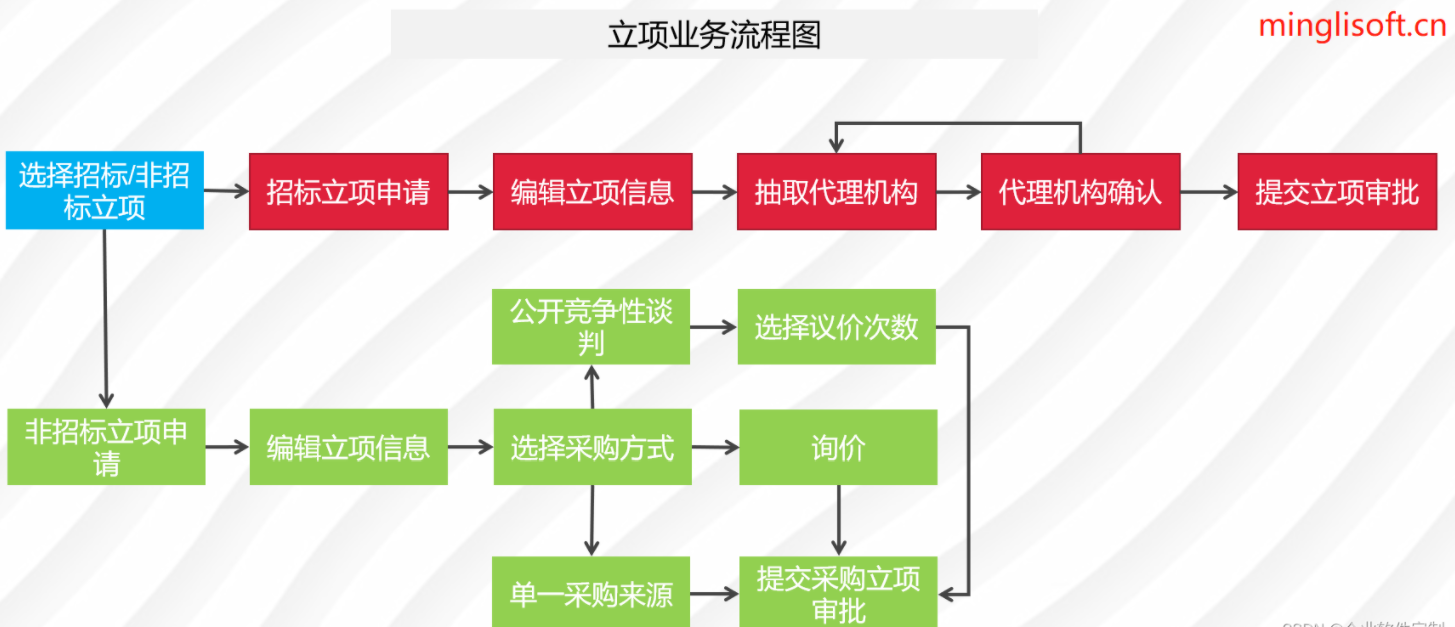
3 模型搭建参数
在论文的Table1中有给出三个模型(Base/ Large/ Huge)的参数,在源码中除了有Patch Size为16x16的外还有32x32的。

其中:
Layers就是Transformer Encoder中重复堆叠Encoder Block的次数 L。
Hidden Size就是对应通过Embedding层(Patch Embedding + Class Embedding + Position Embedding)后每个token的dim(序列向量的长度)
MLP Size是Transformer Encoder中MLP Block第一个全连接的节点个数(是token长度的4倍)
Heads代表Transformer中Multi-Head Attention的heads数。
4 结果分析
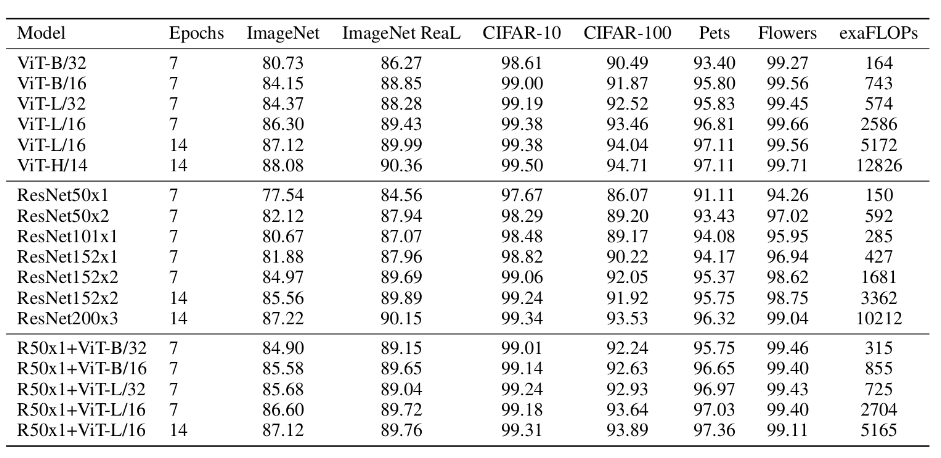
上表是论文用来对比ViT,Resnet(和刚刚讲的一样,使用的卷积层和Norm层都进行了修改)以及Hybrid模型的效果。通过对比可得出结论:
- 在训练epoch较少时Hybrid优于ViT -> Epoch小选Hybrid
- 当epoch增大后ViT优于Hybrid -> Epoch大选ViT