🎬慕斯主页:修仙—别有洞天
♈️今日夜电波:HEART BEAT—YOASOBI
2:20━━━━━━️💟──────── 5:35
🔄 ◀️ ⏸ ▶️ ☰
💗关注👍点赞🙌收藏您的每一次鼓励都是对我莫大的支持😍
目录
如何查看进程?
方法一
方法二
如何理解进程?
创建子进程—fork()
如何理解子进程的创建?
如何理解fork()会有两个返回值?
进程之间的独立性如何保证?
如何理解同一个变量会有不同的值?
如何查看进程?
方法一
ps ajx | head -1 && ps ajx | grep 执行程序的名字 | grep -v grep对于以上指令的解析:
ps ajx 查看当前系统中所有的进程
| 管道 在使用管道符 "|" 时, "|" 左边的进程以写的方式打开管道文件,将标准输出重定向到管道之中, "|" 右边的进程以读的方式打开管道文件,将标准输入重定向到管道之中。
head -1 用于只查看第一行的命令
grep 执行程序的名字 查看对应名字的执行程序
grep -v 执行程序的名字 将除了-v 后面的执行程序的内容都显示出来
显示效果如下:

方法二
ls /proc该指令用于查看进程相关的属性,可以根据是否有对应程序的pid来判断是否有该进程。通过以下的指令可查看对应进程的详细属性:
ls /proc/进程pid也可通过后面加上 -d 或者 -l 指令用于查看对应目录和详细信息

如何理解进程?
创建子进程—fork()
启动一个进程,如何理解这种行为?本质就是多了一个进程,操作系统管理的进程也就多了一个,进程=可执行程序+task_struct对象(内核对象)。
创建一个进程,就是系统中要申请内存,保存当前进程的可执行程序+task_struct对象,并将task_struct对像添加到进程的列表中。
通过fork()创建子进程,当使用fork()后程序会出现两个执行流,分别为一个父进程的执行流还有一个子进程的执行流,看如下例子:
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>int main()
{printf("i am a father process,pid:%d ppid:%d\n",getpid(),getppid());fork();while(1){printf("i am a process,pid:%d ppid:%d\n",getpid(),getppid()); sleep(1);}return 0;
}
可以看到如上的效果,我们也可以得出一个结论:fork()之前的代码只有父进程会执行,而fork()之后的代码则是父子进程都要执行。
需要注意的是fork()有返回值,当我们fork()成功时会返回两个不同的返回值,子进程会返回0,父进程会返回子进程的pid,创建失败则会返回-1。对此我们可以通过判断返回值来执行不同的代码片段!如下代码:
#include<stdio.h>#include<unistd.h>#include<sys/types.h>int main(){pid_t cg=fork();if(cg==0){printf("i am son process: mypid:%d my forkrt:%d \n",getpid(),cg);}if(cg>0){printf("i am father process: mypid:%d my forkrt:%d \n",getpid(),cg); }return 0;}

看到这里你可能会很奇怪,为什么两段程序的执行顺序对不上呢,不是应该先执行son再执行father吗?实际上父进程和子进程是有各自PCB中的调度信息以及调度算法共同决定的!我们不能确定哪一段代码片段先运行!谁先运行主要还是靠调度器来决定!
如何理解子进程的创建?
我们都知道进程=可执行程序+task_struct对象,那么fork创建了一个字进程,系统就会多一个进程,也就是我们的内存中会多一个进程。
而对于子进程的创建会以父进程为模板创建子进程的PCB,这个PCB会拷贝大部分的基础属性,但是小部分是不同的,比如pid、ppid等等。
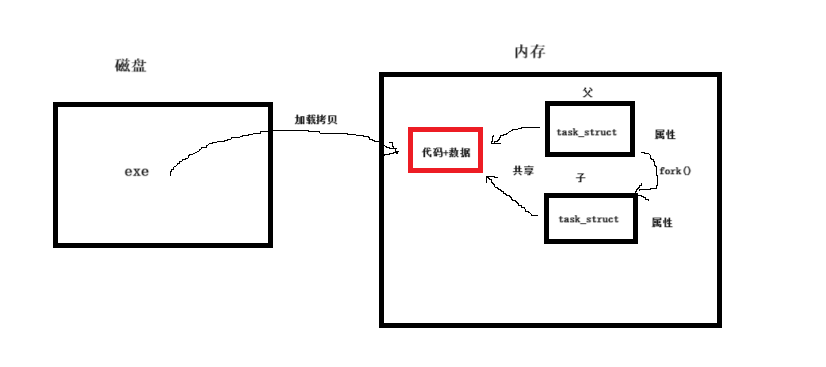
但是,在PCB创建后子进程是没有可执行程序(也就是代码和数据)的,因此,在fork()后,子进程会和父进程共享代码和数据!当然后面数据是可能会各自独立出来一份的!一图让你了解:
如何理解fork()会有两个返回值?
通过上面的理解,我们都知道fork()过后会创建子进程,那么在创建子进程后,父进程和子进程会对代码+数据进行共享。那么也就是说我们的 return 也共享了!因为 return 也是代码啊!所以父进程被调度 会执行return,子进程被调度 也会执行 return!
而实际上,操作系统是通过一些寄存器做到返回值返回两次!
进程之间的独立性如何保证?
进程之间运行的时候,具有独立性,无论是什么关系!
进程的独立性,首先表现在各自的PCB。
进程之不会互相影响!代码本身是只读的,不会影响!但是数据父子是会修改的!
当我们对于一个进程的数据进行修改时,你会发现另外一个进程没有发生改变,这是因为操作系统触发了写时拷贝,确保了每一个进程的数据的独立性。
那什么是写实拷贝呢?
由于fork()后代码共享,对于数据各个进程必须想办法各自私有一份。对此,我们可以理解为C++中的浅拷贝以及深拷贝,对于刚刚开始fork()则是浅拷贝,共享数据和代码。当父或者子要进行修改时,我们就要实现两者的区分,要进行深拷贝。

如何理解同一个变量会有不同的值?
对于fork()进行完后会进行return,也就是fork()函数的返回值。在程序运行到返回时,说明他的程序已经基本完成了,而返回的本质是写入,在返回的时候发生了写实拷贝,对于进程会有各自的数据,所以同一个变量会有不同的值!
感谢你耐心的看到这里ღ( ´・ᴗ・` )比心,如有哪里有错误请踢一脚作者o(╥﹏╥)o!

给个三连再走嘛~